
참고. 이번 블로그는 LINE DEVELOPER DAY 2018에서 Yuto Kawamura 님이 발표한 ‘Multi-Tenancy Kafka cluster for LINE services with 250 billion daily messages’ 세션을 기록한 내용을 각색하여 옮긴 글입니다(원문 기록 및 제공: logmi).
들어가며
안녕하세요. LINE에서 소프트웨어 엔지니어로 일하고 있는 Kawamura Yuto입니다. 지난 글에서 LINE에서 Kafka를 사용하는 방법(1편)과 실제 저희 운영 환경에서 발생했던 문제(2편)를 공유드렸는데요. 이번 글에서는 2편에서 설명드렸던 문제를 해결한 방법과 그 방법을 적용한 결과를 말씀드리겠습니다.
해결 방법 검토
2편에서 설명드렸던 문제를 요약하면 다음과 같습니다.
- 브로커가 Fetch 요청 처리 → sendfile 호출 시 디스크 읽기가 필요하면 네트워크 스레드의 이벤트 루프가 차단됨 → 같은 네트워크 스레드로 처리되는 후속 응답과 다른 관련 없는 API의 응답까지 모두 차단됨
결국 디스크 읽기 때문에 발생한 지연이 처리 대기 중이던 모든 응답에 영향을 끼치는 상태였습니다. 이 문제를 해결하기 위해 저희는 여러 가지 방법을 고민했는데요. 최종 결론은 원래 차단 대상이 아닌 이벤트 루프가 차단되지 않게 수정하는 방법이었습니다.
이를 위해 sendfile이 네트워크 스레드 내에서 호출될 경우 대상 데이터가 반드시 페이지 캐시에 존재하도록 브로커를 개선하기로 했습니다. 방법은 현재 차단(blocking)이 발생한 네트워크 스레드 내에서 이루어지는 디스크 데이터 로딩을 요청 핸들러 스레드 쪽으로 옮기는 것입니다.

요청 핸들러 스레드는 하나의 큐를 전체가 폴링(polling)하는 모델이기 때문에 차단이 발생해도 다른 스레드에 전혀 영향을 주지 않아서 다른 스레드는 그동안 계속 후속 요청을 처리할 수 있습니다. 따라서 스레드 하나에서 발생하는 차단은 문제가 되지 않습니다.
이때 웜업(warm-up)된 페이지 캐시는 이후 네트워크 스레드가 다시 가져가서 클라이언트에 입력되는데요. 이 과정에서 차단은 발생하지 않습니다.
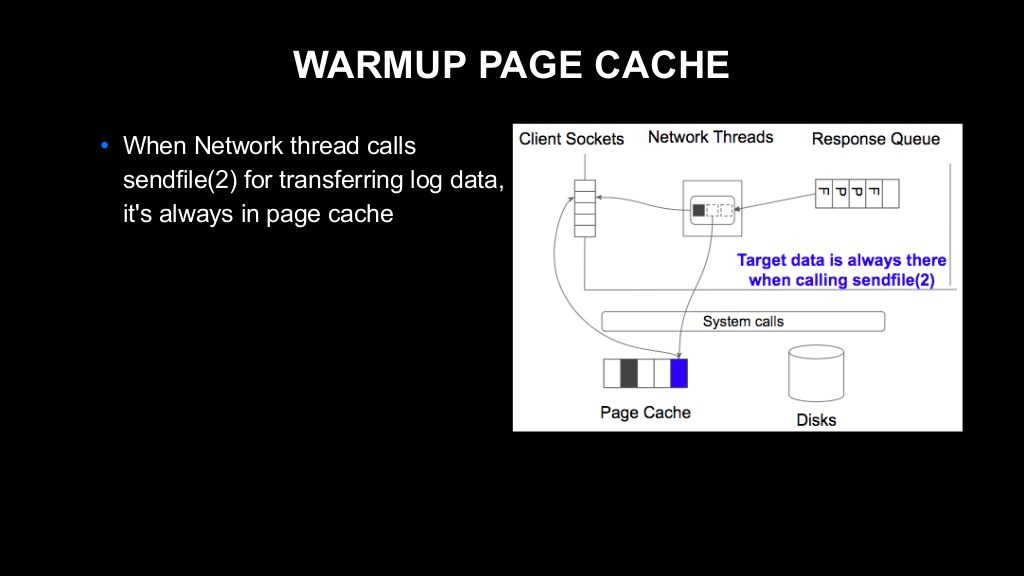
따라서 위와 같이 문제를 해결하려면 페이지 캐시를 웜업 처리할 필요가 있어서 웝업을 어떤 방식으로 처리할지 고민했습니다. 가장 쉬운 방법으로는 대상 데이터에 '읽기'를 호출하는 방법이 있는데요. 이 방법에는 우려되는 점이 있었습니다. 대상 데이터에 읽기를 호출하면 그 데이터가 디스크에서 로딩된 다음에 사용자 공간의 버퍼에 복사되어 버립니다. 원래 Kafka가 sendfile이라는 시스템 콜을 사용하는 이유는 대량의 데이터 메모리 복사 오버헤드를 피하기 위해서입니다. 이 방법을 사용하면 Kafka가 원래 가지고 있던 매우 효율적인 특성이 사라지게 될 가능성이 있는 거죠. 그래서 다른 방법을 고민해야 했습니다.
시행착오 끝에 저희가 찾아낸 방법은 약간 교묘한 방법인데요. 대상 데이터에 sendfile을 호출하면서 목적지를 /dev/null로 설정하는 겁니다.
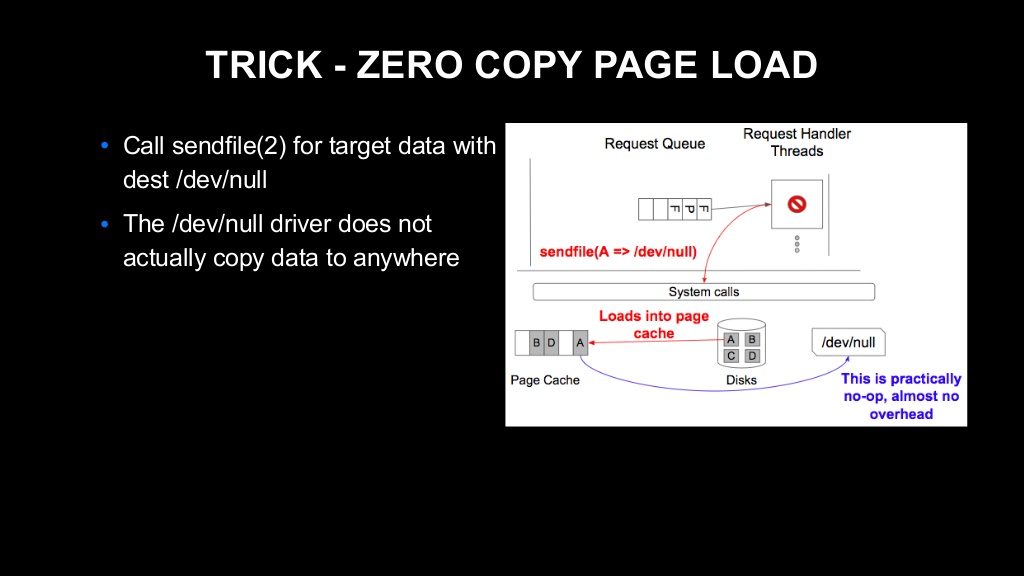
리눅스 커널은 sendfile이 /dev/null을 목적지로 호출되었을 때는 메모리 복사를 하지 않게 구현되어 있습니다. 그래서 디스크에서 페이지 캐시로는 데이터가 로딩되지만 그 이후 메모리 복사는 진행되지 않는, 저희에게 아주 이상적인 동작이었던 것이죠.

매우 흥미로운 동작이었기 때문에 저희는 좀 더 깊이 들어가서 리눅스 커널 코드를 읽어가며 그 근거를 찾아 보았습니다. 자세한 설명은 생략하겠지만, sendfile이라는 API는 리눅스 커널 내부에서는 splice라는 처리에 매핑되는데요. 이 splice는 디바이스 드라이버별로 다르게 구현되어 있습니다.
위 이미지에 보이는 'null' 디바이스의 디바이스 드라이버에 구현된 splice_write_null이라는 함수는 내부적으로 pipe_to_null이라는 함수를 호출하는데요. 이 pipe_to_null 내에서는 메모리 복사가 전혀 이루어지지 않는다는 점을 확인할 수 있습니다. 이로써 확증을 얻을 수 있었습니다.
레이턴시 단축 효과
이제 페이지 캐시의 웜업 처리를 브로커에 구현해야 합니다. 방법은 아주 간단합니다. 아래는 페이지 캐시의 웜업을 처리하는 prepareForRead라는 부분만 발췌한 내용입니다. /dev/null에 파일을 열고 그 파일에 FileChannel의 transferTo라는 메서드를 호출하는 것이 전부입니다.

Java 표준 라이브러리에 포함되어 있는 FileChannel의 transferTo 메서드는 내부적으로 사용 가능할 경우 sendfile을 사용하도록 구현되어 있습니다. 따라서 저희는 JNI(Java Native Interface)를 사용하는 것과 같은 플랫폼 고유의 구현을 추가할 필요 없이 순수한 Java 코드만 사용해서 구현을 완료할 수 있었습니다. 이 내용을 실제로 운영 시스템에 적용해서 배포해 보았습니다. 그 결과 문제가 완전히 해결되었습니다.
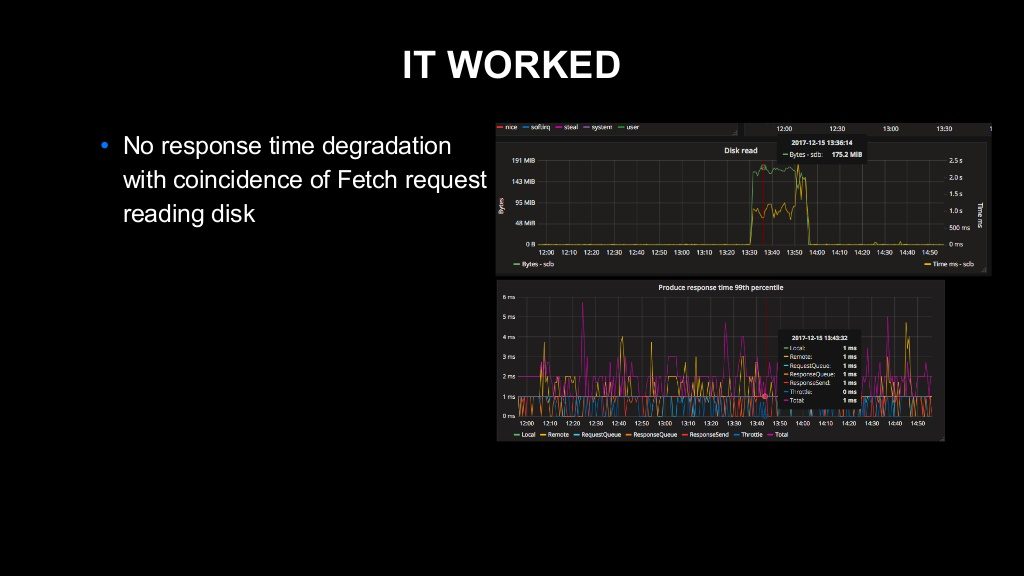
보시는 바와 같이, 문제가 되었던 부분인 디스크 읽기를 유발하는 Fetch 요청을 처리하는 과정에서도 아무 관련 없는 Produce API의 응답 시간이 전혀 느려지지 않았다는 것을 확인할 수 있습니다.
오픈소스에 기여하기
저희는 이런 성과를 내면 그 내용을 오픈소스 커뮤니티에 환원하는 작업을 매우 자주 합니다. 이번 경우도 예외 없이 이미 업스트림에 티켓을 생성한 상태고, 현재 논의 중이기는 하지만 이 내용이 머지되면 Kafka의 레이턴시가 50배에서 100배 단축될 것으로 기대됩니다. 이미 이전에도 수많은 성능 개선 관련 패치에 기여한 바 있는데요. LINE에선 이런 활동을 통해서 전 세계의 Kafka 사용자에게 기여하고 있습니다. 자세한 내용이 궁금하신 분은 이슈 ID를 검색하시면 업스트림 티켓을 보실 수 있습니다.

마치며
그럼, 정리하겠습니다. Kafka의 쿼터(Quota)라는 기능과 SystemTap이라는 툴을 잘 활용하고, 시스템을 깊이 있게 이해해서 만든 패치를 적용해서 각종 문제를 해결한 결과, 대규모 Kafka 플랫폼이 매우 잘 운영되고 있습니다. 데이터 허브로서의 콘셉트를 그대로 유지하면서, 지원하는 서비스와 시스템 수에 비례해서 운영 비용이 증가하지 않는 효율적인 플랫폼입니다. 또한 그 과정에서 발생한 성능 개선 등의 성과를 오픈소스 커뮤니티에도 환원함으로써 전 세계의 Kafka 사용자에게도 기여하고 있습니다.
총 3번에 걸쳐 LINE에서 운영하고 있는 전사용 대규모 Kafka 플랫폼의 뒷단에서 저희가 어떻게 엔지니어링을 하고 있는지에 대해 말씀드렸습니다. 이번 글을 통해 LINE에서 Kafka를 어떻게 사용하는지는 물론 평소에 LINE에서 어떤 방식으로 엔지니어링을 하는지도 잘 전달되었으면 좋겠습니다. 긴 글 읽어주셔서 감사합니다.