
안녕하세요, LINE에서 LIVE 서비스를 개발하고 있는 moznion입니다.
저희 팀에서는 'LIVE'라는 동영상 송출 서비스를 개발하고 있습니다. LIVE는 연예인과 유명인의 라이브 방송이나 콘서트 상황 중계 등 다양한 영상 콘텐츠가 매일 방송되고 있는 인기 서비스이며, iOS/Android 앱과 PC 브라우저를 지원합니다.
이번 블로그에서는 LIVE에서 연타(연속 탭)를 지원하는 기술에 대해 소개하겠습니다.
배경
iOS/Android 버전 LIVE 앱에는 동영상 플레이어에 있는 '하트'를 눌러서 송출자를 응원할 수 있는 시스템이 있습니다(아래 그림 1번 부분). 시청자는 이 '하트'를 연속해서 탭할 수 있으며, 이에 따라 플레이어 화면에 표시되는 카운트, 즉 "모든 시청자가 누른 '하트' 수"가 증가하는 인터랙션이 일어납니다(아래 그림 2번 부분). 이 수치가 올라가면 송출자는 팬들이 보내 주는 응원을 직접 실감할 수 있고, 시청자는 계속 늘어나는 카운트를 보면서 방송을 함께 한다는 일체감과 열광적인 분위기를 느낄 수 있습니다.

개발자들 사이에서는 이 '하트' 기능을 통틀어 "love"라고 부르고 있기 때문에, 이번 블로그에서도 "love"라는 표현을 사용하겠습니다.
서비스의 특성상 인기 아이돌의 라이브 방송 등에서는 엄청난 양의 love가 순간적으로 수신되기 때문에, 서비스가 중단되지 않도록 리퀘스트를 효율적으로 분산시켜야 합니다. 이처럼 아주 많은 유저가 연타할 수 있고 점점 증가하는 카운터를 높은 가용성과 어느 정도의 즉시성을 확보하여 LIVE에서 구현한 방법을 소개하겠습니다.
아키텍처
전체 개요도는 다음과 같습니다. 이제부터 이 그림이 나타내는 내용을 자세하게 설명하겠습니다.
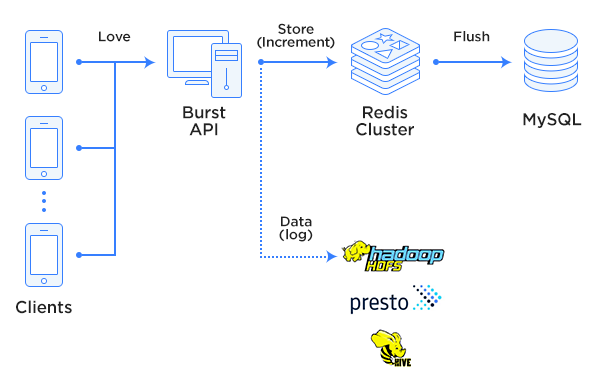
첫 단계
서비스를 안정적으로 제공하기 위한 방법 중 하나로 '리퀘스트 수 줄이기'가 있습니다. 이 방법은 많은 경우에 적용할 수 있는 본질적인 해결책입니다.
예를 들어 love가 한 번 탭될 때마다 하나의 리퀘스트를 발행하고, 서버에 질의하여 제반 처리를 한 후에 리퀘스트를 반환하는 형태로 구현하면, 지나치게 낭비가 많고 스케일링이 힘들어집니다. 상황에 따라 네트워크 계층에서 정체가 발생하게 될 수도 있습니다.
이런 문제를 해결하기 위해 클라이언트 측에서 여러 리퀘스트를 모아 한꺼번에 보내도록 하여 리퀘스트의 총수를 줄이는 방법이 나오게 된 것은 자연스러운 결과라고 할 수 있습니다. 예를 들어 '특정 시간대(time window)에 love가 몇 번 탭되었는지'를 클라이언트 측에서 버퍼링하고, 그 시간대에서 벗어날 때 카운트된 수치를 포함한 리퀘스트를 서버에 전달하도록 하는 소박한 방법을 고안했습니다. 서버는 그 수치를 받아 저장된 카운터를 그만큼 증가시키는 방식입니다.
LIVE에서는 순수 카운트 대신에 '동영상의 몇 초 지점에서 love가 탭되었는지'를 표시한 동영상의 타임스탬프를 리스트로서 버퍼링하여 클라이언트에서 수신하는 방식을 사용하였고, 이를 통해 시청자 1명 당 리퀘스트 수를 줄이는 데 성공했습니다. 또한, '탭된 타임스탬프 리스트'를 송신하는 이유는 나중에 분석용으로 이용하기 위해서입니다. 분석에 대해서는 아래에서 설명하겠습니다.
그리고 이런 방식을 사용할 때는 치팅 행위에 대한 대책도 잘 마련해 두어야 합니다. 예를 들어, 악의적인 유저가 하나의 리퀘스트 안에 대량의 카운트를 포함시켰을 경우, 이를 액면 그대로 받아 들이면 차마 눈 뜨고 볼 수 없는 사태가 벌어지게 됩니다. LIVE에서는 치팅 행위에 대해서도 확실한 대책을 세워 놓았습니다.
고속 스토리지 사용
라이브 송출 중에는 해당 방송에 접속이 집중되기 때문에 동시 접속 시청자 수가 많아집니다. 그리고 동시 접속 시청자 수가 많아질수록 love에 대한 리퀘스트 수도 늘어납니다.
그래서 LIVE에서는, RDB(LIVE에서는 MySQL을 이용합니다)에 love 카운트를 저장하고 love 리퀘스트를 받을 때마다 증가시켜 매번 DB 접속을 발생시키는 방식보다는, 인메모리 기반 KVS에 카운터를 두고 거기에 액세스 인크리먼트를 해서 효율적으로 IO를 처리하는 방식을 채택했습니다.
LIVE에서는 Redis의 버전 3부터 지원되는 클러스터링 기능을 사용하여 Redis Cluster를 구축했으며, love의 카운터에서도 해당 Redis Cluster를 사용합니다. Redis Cluster는 스펙에도 나와 있듯이, 고성능, 고가용성, 그리고 스케일 아웃 용이성을 자랑하는 인메모리 기반 KVS입니다. LIVE에서는 love 외에도 다양한 용도로 Redis Cluster가 사용됩니다.
내부 처리 방식을 보면, 리퀘스트를 통해 받은 타임스탬프 리스트의 사이즈를 취득하고, 송출에 해당되는 Redis 내의 love 카운터를 그 사이즈만큼 INCRBY로 증가시키게 되어 있습니다.
또한, 라이브 송출 종료 시에 그 방송에 해당되는 카운터의 내용을 Redis에서 MySQL로 flush하고, 그 후에 Redis에서 그 카운터는 삭제합니다. 이렇게 하는 이유는 Redis에는 데이터를 영속적으로 저장하지 않고 최소한으로 사용하기 위해서입니다. 영속적인 데이터는 RDB에 맡기고, 휘발되어도 문제 없고 높은 처리량이 필요한 경우(예를 들어 캐시나 이번 love와 같은 용도)에는 Redis를 사용하도록 분리되어 있습니다.
주제와는 관련 없지만, 저희 팀에서는 Redis를 사용할 때 엔트리 key 앞에 name space를 부여하여 운용하고 있습니다. 예를 들어, '[service-name]|[phase]|[entry-key]' 형식으로 표현합니다(phase 부분에는 실제 환경일 경우 "release", 스테이징 환경일 경우 "staging" 등의 문자열이 들어갑니다). 이렇게 하면 key 이름만 봐도 어떤 서비스이고 어떤 phase인지를 한 눈에 파악할 수 있고, 실수로 다른 서비스나 phase의 엔트리가 섞여도 서비스 자체에 영향을 미치지 않는다는 이점도 있습니다.
단순한 데이터 구조 사용
저장하는 데이터 구조와 리퀘스트에 담는 데이터 구조를 단순하게 유지하는 것은 높은 처리량을 얻기 위해 필요한 요소 중 하나입니다. 특히 인메모리 기반 KVS는 데이터 구조가 복잡해질수록 스토리지에 보관하기가 힘들어지고, 원하는 데이터를 쉽게 참조하거나 추출하는 것도 어려워집니다.
그래서 LIVE에서는 Redis 내에 단순한 카운터만 생성하고, 그 엔트리에 대해 INCRBY 명령으로 값 업데이트, GET 명령으로 값 취득, DEL 명령으로 카운터 파기를 하는 형태를 통해 간단한 조작으로 필요한 기능을 실현할 수 있게 구현했습니다.
또한, 적절한 데이터 구조를 선택하는 것도 중요합니다.
예를 들어 특정 방송에 대한 love를 '시청자별 송신 수 랭킹'으로 표시하는 등 복잡한 용도로 사용할 경우, 단순한 카운터를 사용해서 애플리케이션 측에서 집계한 후 랭킹을 구성하는 방법보다는 Redis가 보유한 Sorted Set을 1건의 방송과 매칭시킨 후 score를 love의 카운트, member를 시청자 ID로 설정하여 ZRANGE 또는 ZREVRANGE를 사용해서 쉽게 랭킹 구조로 가져오는 방법이 더 간편하고 효율적입니다.
도메인에 따라 용도에 맞는 가장 단순한 데이터 구조를 선택하는 것이 높은 처리량을 유지하기 위한 중요한 조건이라고 할 수 있습니다.
데이터 분석
LIVE는 love의 카운트를 증가시킬 때 동시에 fluentd를 통해 사내 HDFS 스토리지에 분석용 로그를 전달합니다. 로그에는 '동영상의 어느 지점에서 love가 탭되었는지'를 비롯한 다양한 데이터가 있습니다. 그리고 수집된 로그를 Hive나 Presto를 사용해서 분석하여 서비스 품질을 향상시키는 데 활용하고 있습니다.
앞서 말한 '단순한 데이터 구조 사용'은 서비스의 처리량을 향상시키기 위해 필요한 요소였지만, 그래도 그 데이터를 분석해 보고 싶어지는 것이 사람 마음이지요. 하지만, 이를 동시에 만족시키려고 하면 어딘가에서 문제가 발생하거나, 그에 상응하는 비용을 지불하여 해결해야만 합니다. 그래서 LIVE에서는 주요 처리와 병행하여 복잡한 데이터를 logger(이번 경우에는 fluentd)로 수집해서 HDFS에 저장한 후, 저장된 내용을 다른 컴포넌트에서 별도로 분석하도록 구성했습니다.
이와 같이 서비스를 제공하는 컴포넌트와 데이터를 분석하는 컴포넌트를 분리하면 데이터를 분석할 때 고부하가 발생해도 서비스에 영향이 가지 않고, 그 반대의 경우도 마찬가지입니다. 그리고 서비스 측에서 필요해졌을 때 데이터 분석 컴포넌트에 리퀘스트를 보내서 분석결과를 취득하는 방법을 사용하여, 분석결과를 On-Demand 방식으로 가져옵니다.
서비스 특성상 실시간 분석의 필요성이 그렇게까지 크지 않기 때문에 이러한 방식으로 진행됩니다.
서버 분리
LIVE에서는 일반적인 API 서버와 love 등의 고부하를 견뎌야 하는 컴포넌트가 사용하는 API 서버를 분리하여 운용하고 있습니다. 저희는 이런 고부하용 API 서버를 Burst API 서버라고 부릅니다.
모든 작업을 같은 API 서버로 처리할 경우, 특정 컴포넌트의 부하가 심해지면 다른 컴포넌트까지 영향을 받게 되어 최악의 경우 서비스 제공이 불가능해질 수도 있습니다. 고부하가 예상되는 컴포넌트를 미리 별도 서버로 분리해서 운용하면 이러한 사태를 막을 수 있습니다.
또, 부하가 높아지면 해당 서버를 증강해서 스케일 업, 스케일 아웃하는 것도 가능합니다. 예를 들어 갑자기 부하가 상승한 경우, 애플리케이션 엔지니어가 부재 중이더라도 인프라를 담당하는 엔지니어나 오퍼레이션 엔지니어만 있으면 바로 대응할 수 있게 되는 등 유연한 운용이 가능해질 것입니다.
맺음말
이상으로 요점을 정리하면 아래와 같습니다.
- 리퀘스트 수를 근본적으로 줄인다. 치팅 행위에 대한 대책도 확실하게 준비한다.
- 상황에 따라 고속 스토리지를 사용한다.
- 높은 처리량을 실현시키기 위해 단순한 데이터 구조를 사용한다.
- 실시간 데이터 분석이 불필요한 경우에는 데이터만 계속 저장하여 다른 컴포넌트에서 분석을 진행한다.
- 고부하가 예상되는 컴포넌트는 별도 서버로 분리하여 운용한다.
이상으로 LIVE의 연타 지원 방식에 대한 설명을 마치겠습니다.
끝으로, LINE에서는 다양한 분야의 엔지니어를 모집하고 있습니다. 많은 관심과 지원 바랍니다!