
들어가며
안녕하세요. 작년 8월에 LINE에 합류해 주로 서버 구축 및 관리를 담당하고 있는 Yasunori Kuji입니다. Elasticsearch와 Kibana의 조합은 로그 분석할 때 많이 사용하는데요. 이번 글에서는 각각의 특성을 살려 엑셀 피벗 테이블의 대용으로 사용할 수는 없는지 시도해 본 결과를 말씀드리려고 합니다.
시도하게 된 배경
이번에 시험 대상으로 삼은 프로젝트는 사내 설문조사 프로젝트인 'Low Usage Project'입니다. 저희 부서에서는 수만 대가 넘는 서버를 관리하고 있는데요. 모든 서버가 다 효율적으로 활용되고 있지는 않았습니다. 구축하다가 사용하지 않게 된 서버도 있었고, 서비스가 분할되었는데도 여분의 서버 클러스터가 계속 유지되고 있기도 했습니다. 그래서 사용하고 있는 자원에 여유가 있는 서버군의 자원을 축소하거나 VM(Virtual Machine)으로 이관하려고 했는데요. 그에 앞서 서버 관리자에게 현재 이용 상황을 알려달라고 했더니 이용 상황 집계 리포트를 아래와 같이 다양한 기준으로 준비해달라는 요청이 돌아왔습니다.
- 어느 부서가 답변하지 않았는지 알고 싶다
- 서버의 감가상각을 기준으로 집계해줬으면 좋겠다
- 서버 모델별로 확인하고 싶다
- 담당자 상사의 연락처를 알고 싶다
- 등등
저는 주어진 지시를 최대한 빨리 수행하기 위해 일단 전부 다 엑셀로 처리하기로 했습니다. 엑셀 피벗 테이블은 필요한 데이터를 간편하게 테이블과 그래프 형태로 가시화할 수 있는 아주 편리한 기능입니다. 엑셀 피벗 테이블을 이용해 필요한 결과물을 거의 다 준비할 수 있었는데요. 곧 아래와 같은 문제에 부딪쳤습니다.
- 필요한 데이터를 여러 DB에서 취득한 후 엑셀 VLOOKUP 기능을 이용해 머지(merge)하는데, 데이터가 5개라면 5개를 매일 다운로드해서 엑셀에 붙여넣기하고 그래프를 업데이트해야 해서 결합하는 과정이 번거로움
- 엑셀 계산 시간이 날로 늘어남
- 정형화된 작업 순서를 문서화하는 게 어려움
- 매일 같은 작업을 반복해야 함
물론 VBA(Visual Basic for Applications)를 사용하면 자동화가 가능하지만, Kibana를 피벗 테이블 대신 사용할 수 없는지 궁금해서 한번 시도해 보기로 했습니다.
엑셀 피벗 테이블이란?
엑셀 피벗 테이블에 대해 간략하게 설명드리겠습니다. 엑셀 피벗 테이블은 쉽게 말해 key=value 형태의 단순한 행이 나열된 데이터에 같은 값이 몇 개 있는지 헤아리거나, 그런 데이터를 기반으로 그래프를 만들 수 있는 기능입니다. 중요한 점은 '한 행에 하나의 데이터'라는 점입니다. 여러 행에 걸쳐있는 데이터는 입력할 수 없고, 이 규칙은 절대로 변경할 수 없습니다. 사용법은 아래와 같습니다.
1. key=value의 단순한 데이터를 준비해서 '피벗 그래프'를 삽입합니다. 이번 글에서는 한 행에 하나의 데이터가 입력된 설문조사 답변을 준비했습니다.
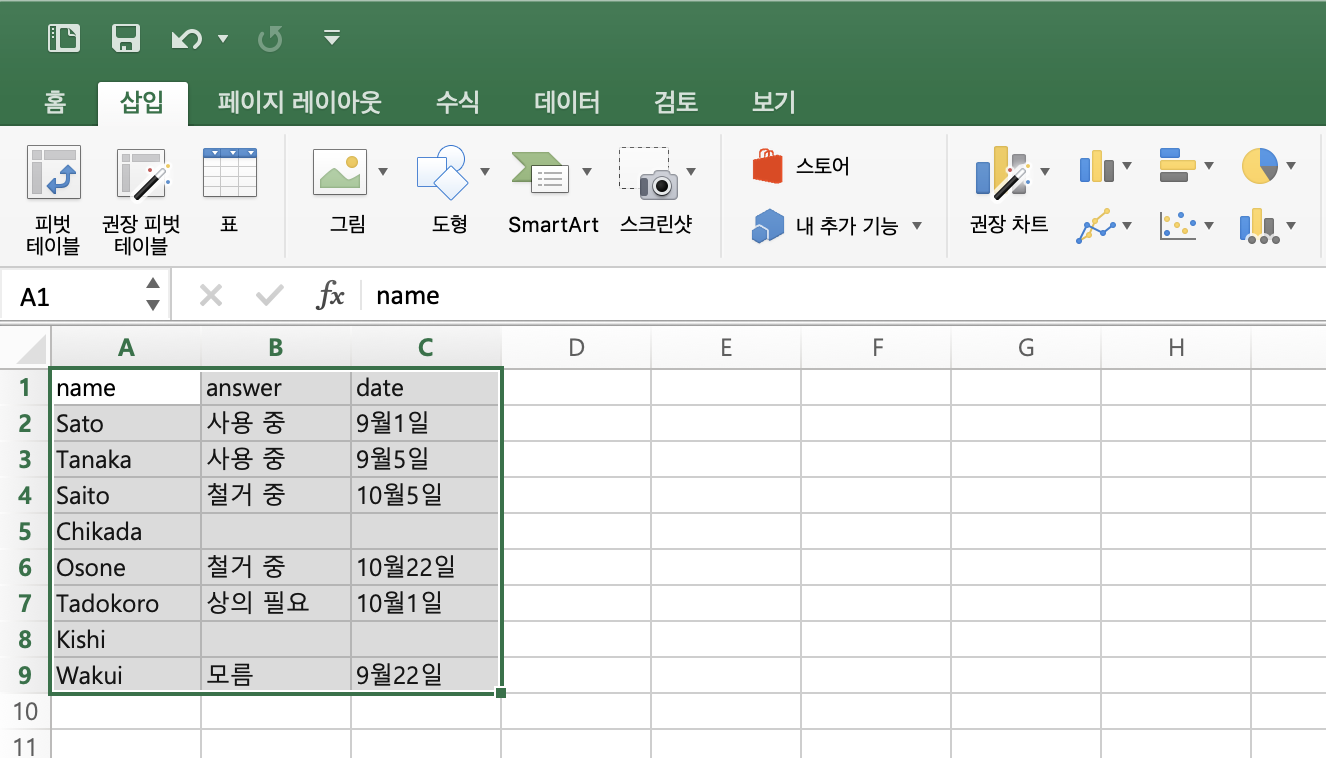
2. 데이터의 범위를 정합니다.
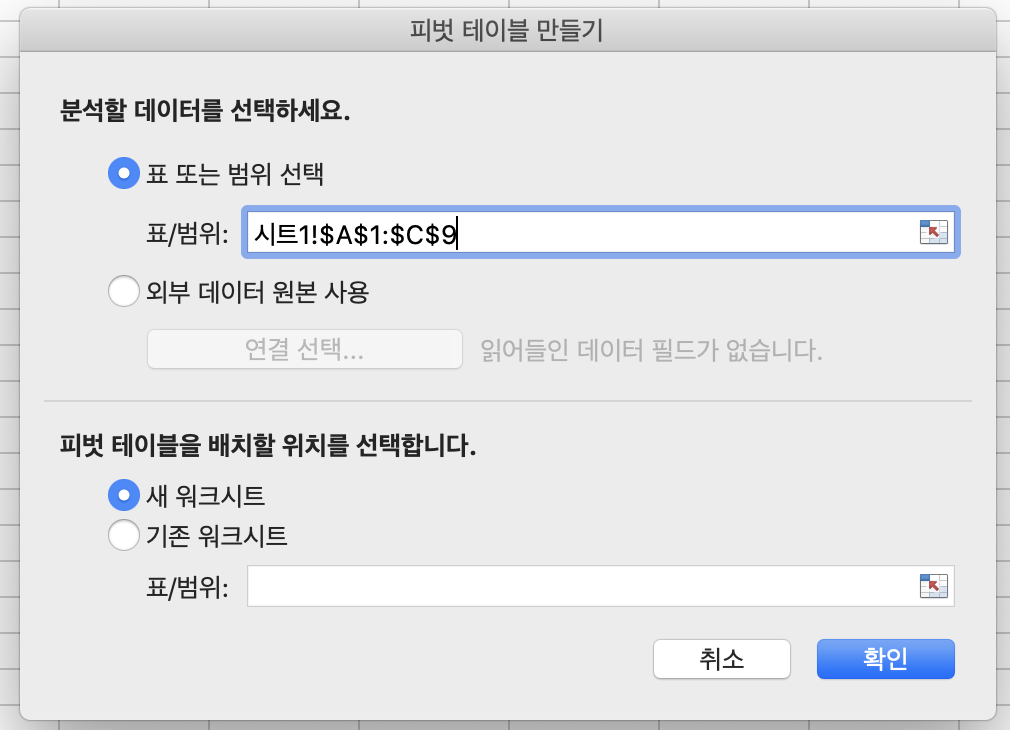
3. 그래프 또는 테이블로 만들 데이터를 선택하면 완성됩니다.
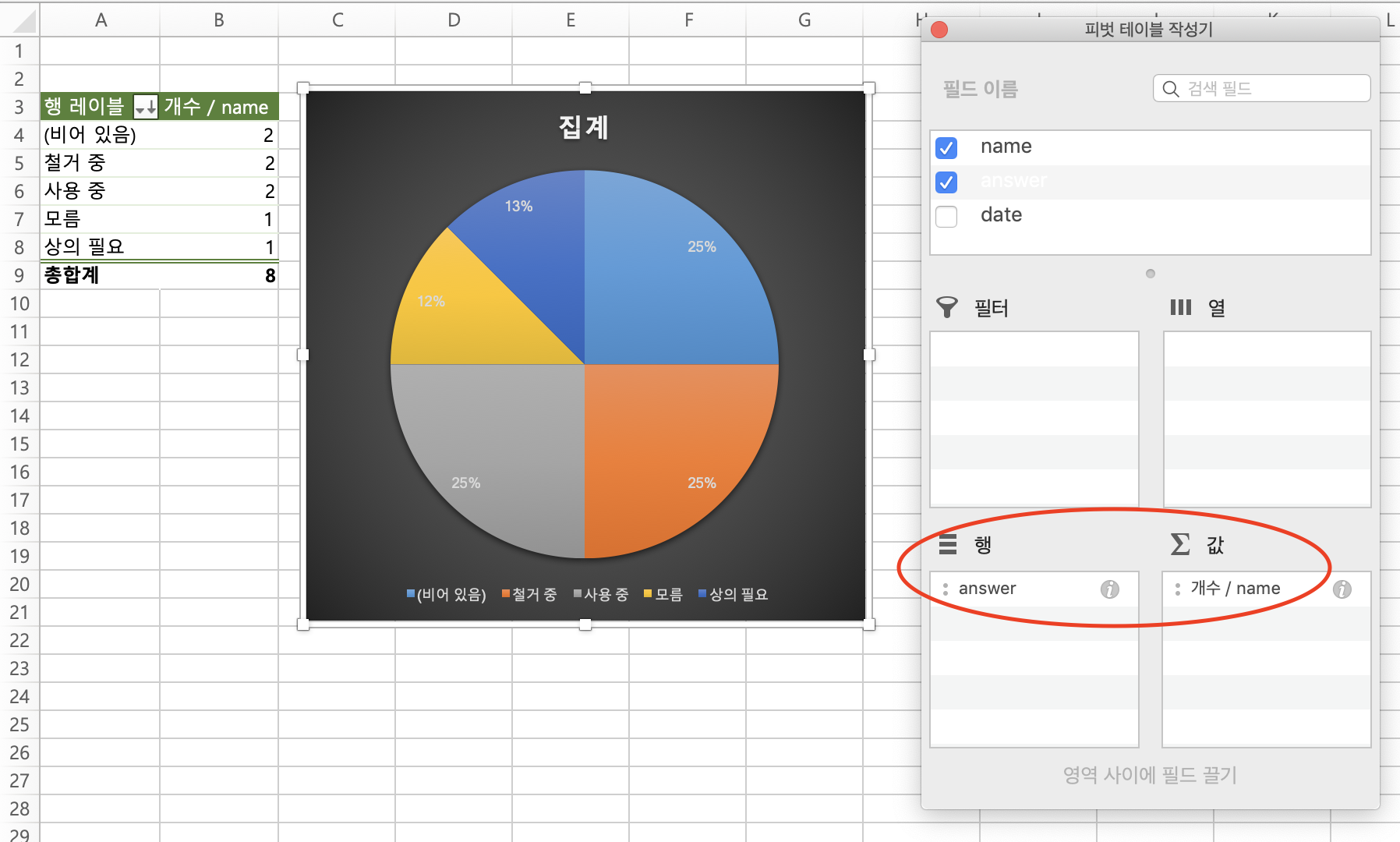
한 행에 하나의 데이터라는 법칙은 로그(log)에 가장 적합한 조건이라서 지금도 로그 분석용으로 엑셀 피벗 테이블을 사용하는 분들이 많이 계실 겁니다. 이 '한 행에 하나의 데이터, 비관계형'이라는 조건은 Elasticsearch에서도 기본적으로 동일합니다.
Elasticsearch와 Kibana의 조합이란?
Elasticsearch는 Elastic사가 개발한 데이터베이스의 일종입니다. 비관계형 데이터베이스라는 점에서 관계형 데이터베이스인 MySQL이나 Microsoft SQL Server와는 차이가 있습니다. 검색 속도가 매우 빠르기 때문에 각종 분석에서 기본이 되는 엔진입니다. Elasticsearch는 데이터를 넣으면 API로도 바로 데이터를 사용할 수 있다는 점이 장점이며, 구축한 Elasticsearch에 브라우저로 접속하면 json 형식의 서버 정보가 표시된다는 특징이 있습니다.
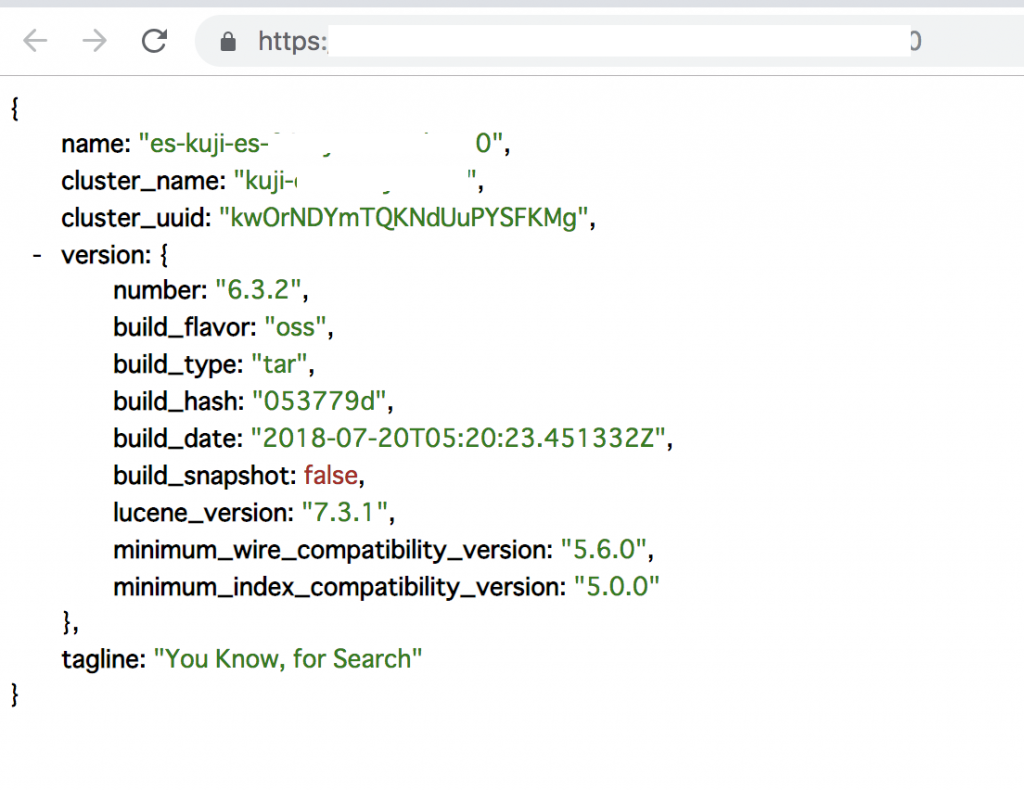
Kibana는 Elasticsearch와 마찬가지로 Elastic사에서 개발한 데이터 가시화 도구입니다. 데이터 추출 쿼리를 브라우저에서 실행하여 테이블이나 그래프 형식으로 저장할 수 있으며, 기본적인 조작은 SQL을 몰라도 할 수 있습니다. 데이터만 준비하면 내가 아닌 다른 사람도 보고서를 만들 수 있다는 점 역시 Kibana를 선택하게 된 중요한 이유입니다.
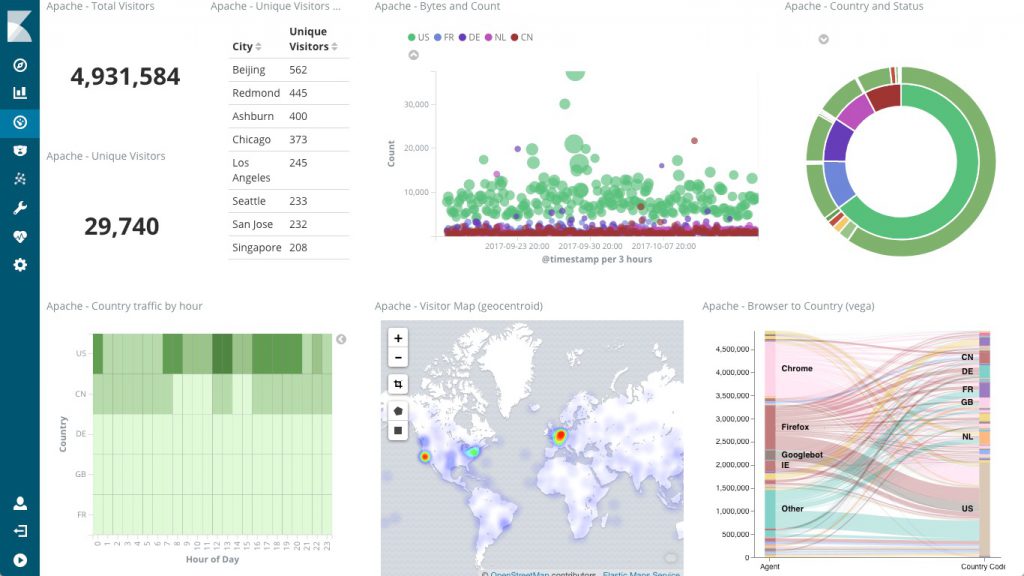
LINE의 사내 폐쇄형 클라우드(private cloud)인 Verda에 VES(Verda Elasticsearch)라는 서비스가 있는데요. Kibana도 세트로 같이 묶어서 쉽게 실행할 수 있기 때문에 이번에는 VES를 이용했습니다. AWS, GCP, Azure 등의 공개형 클라우드(public cloud)에도 Elasticsearch와 Kibana를 조합한 서비스가 있습니다. 이런 서비스를 사용하면 구축할 때 실패하는 경우는 없으리라고 생각합니다.
Elasticsearch와 Kibana를 조합해 엑셀 피벗 테이블로 사용하기
드디어 이번 글의 핵심 내용입니다. Elasticsearch와 Kibana를 조합해 엑셀 피벗 테이블로 사용하는 방법에 대해 알아보겠습니다. 그런데 Kibana를 엑셀 피벗 테이블로 사용하기 전에 해결해야 할 문제점이 하나 있습니다.
Kibana의 컨셉과 맞지 않는 데이터를 Kibana에서 사용하기 위한 방법
Kibana를 피벗 테이블로 사용할 때 어떤 점이 문제가 되는 걸까요? 바로 Kibana는 어디까지나 '살아 있는 데이터를 취급'하기 위해 만들어진 소프트웨어라는 점입니다. 이런 Kibana의 특징은 화면 오른쪽 상단에 자리한 Time Range 설정 메뉴를 통해 잘 드러납니다.
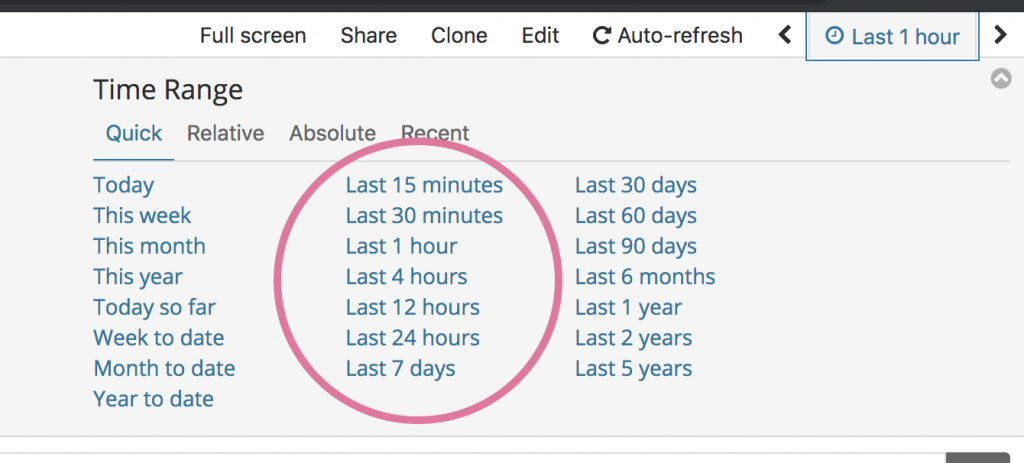
Kibana는 분석을 시작하기 전에 '어느 시점의 데이터를 확인하고 싶은지'를 지정해서 사용합니다. 예를 들어 '최근 15분 동안의 데이터'와 같은 형태가 됩니다. Google Analytics의 기간 설정 기능이라고 생각하시면 좀 더 쉽게 이해하실 수 있습니다.
Kibana에서 예상한 사용 방법은 '하나의 데이터는 한번만 import'하는 것입니다. 하지만 이번에 제가 만들고자 했던 설문조사 시스템에는 나중에 답변을 교체할 수도 있다는 조건이 필요했습니다. A라는 호스트명을 가진 서버에 대한 레코드가 여러 개 존재할 수 있는거죠. 이는 앞서 설명한 '하나의 행에 하나의 데이터(바꿔 말하면 하나의 호스트에 하나의 데이터)'라는 조건에 부합하지 않는 조건입니다. 이 문제에 대한 예시를 아래 그림을 통해 살펴보겠습니다.
- Kibana에서 예상하는 데이터의 예

- 제가 보유한 데이터의 예

- 심각한 문제
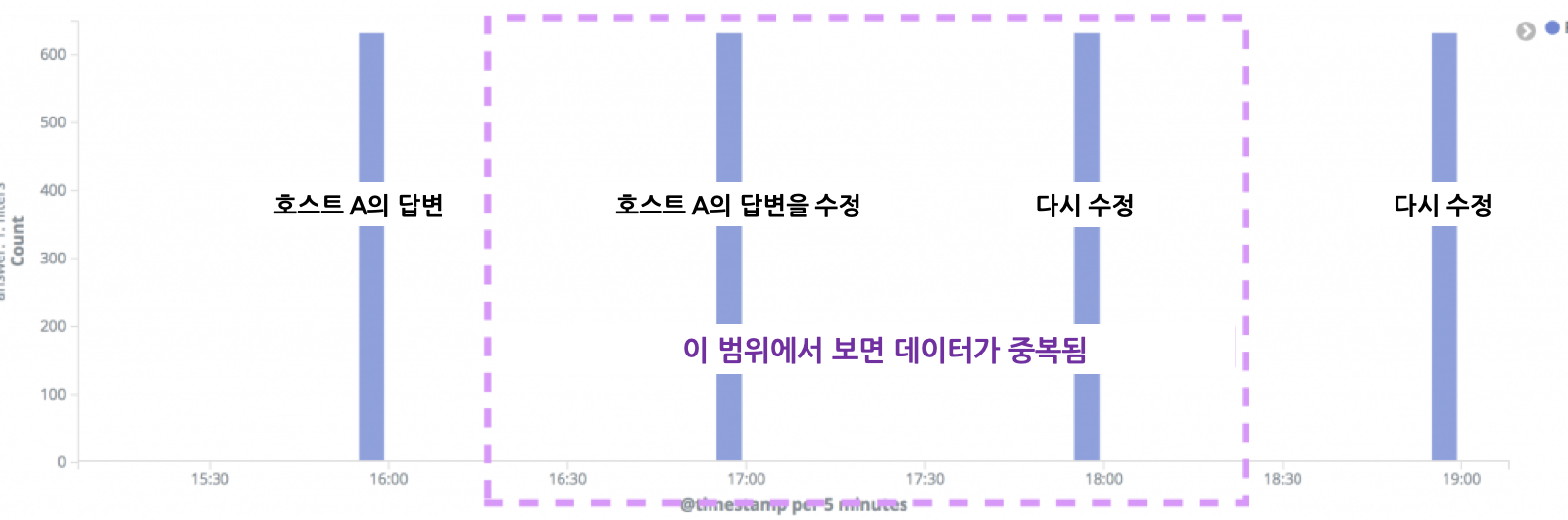
저는 이 문제를 다음과 같은 방법으로 해결했습니다.
- 1시간 간격으로 모든 답변을 다시 import합니다.
- 열람할 때는 반드시 '최신 1시간'으로 기간을 고정해서 열람합니다.
1시간 간격으로 DB 전체의 스냅샷을 Elasticsearch에 저장한다고 보시면 됩니다.
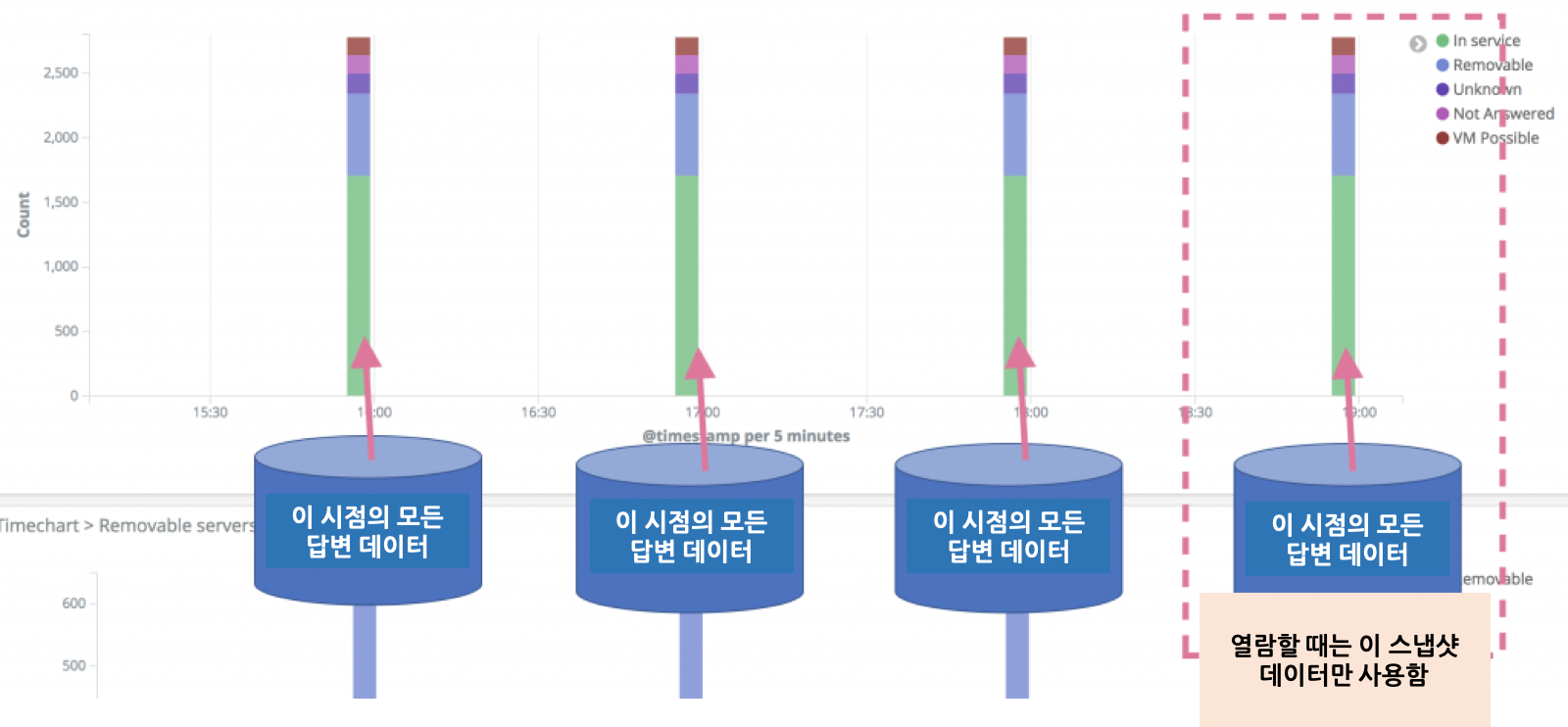
이 기법엔 다음과 같은 장점이 있습니다.
- 특정 일자, 특정 시점의 응답 상황을 쉽게 재현(recall)할 수 있습니다. 이력을 고려한 시스템이 아니라면 이런 재현이 쉽지 않습니다.
- 데이터의 움직임을 추적할 수 있습니다. 재답변 데이터를 덮어쓰는 방식의 시스템이나 삭제 동작으로 레코드를 실제로 삭제해 버리는 시스템에서도 움직임이 기록됩니다.
이 기법의 단점으로는 데이터의 양이 많아진다는 점을 들 수 있는데요. 이 부분은 import 기간을 늘리거나 오래된 데이터를 골라내는 방식을 해결할 수 있습니다. 또한 반드시 최신 1시간으로 고정해서 열람해야 하는 제약사항도 단점이 될 수 있는데요. 이 단점도 Kibana 대시보드에서 제공하는 기간을 고정하는 기능을 이용해서 멤버들에게 미리 기간을 고정해놓은 대시보드 URL을 공유하는 방법으로 해결할 수 있었습니다.
바로 위 기법이 이 글을 통해 제가 전하고 싶은 메시지인, '데이터 전체 스냅샷을 Elasticsearch에 남기면 편리하다'는 것을 구현하는 방법의 핵심입니다. EC(E-commerce) 사이트에서는 상품 판매 현황이나 재고수 조사를 Google Analytics 등의 기능을 사용해서 매일 분석할텐데요. 이 기법을 사용해서 DB 전체의 스냅샷을 남기기만 하면, 앱을 수정하지 않고도 쉽고 자유롭게 일정 수준의 분석을 할 수 있으며 시각화까지 가능합니다. Kibana는 카테고리별 재고 수 데이터 합계를 표로 만들기, 데이터 비율을 원그래프로 나타내기, 데이터 변동 추이를 그래프로 가시화하기 등의 작업에 특화되어 있습니다. 앱이나 관리 화면에서 고생할 필요 없이 데이터만 가져오면 되니 분석에 공수를 들여야 하는 EC 사이트에서 환영받지 않을까 생각합니다. 이와 비슷한 작업이 가능한 서비스가 시중에 나와 있을텐데요. 대다수의 서비스들에선 과거의 움직임을 확인하기가 힘들 겁니다. 그래서 사내에 있는 Elasticsearch를 한번 활용해 보려고 시도한 방법이기도 한데요. 시도해 본 결과에 매우 만족합니다.
Elasticsearch로 데이터 가져오기
이제 Elasticsearch와 Kibana의 조합을 어떻게 사용할 지 방침은 정해졌는데요. 실제로 기존 데이터를 어떻게 Elasticsearch으로 가져올지가 고민이었습니다. 제가 가지고 있는 원본 데이터는 MySQL에 로드(load)되어 있거나 MySQL 데이터를 export한 csv 파일이었습니다. 간편하게 csv로 업로드할 수 있는 방안을 마련해 엔지니어가 아닌 분들도 편리하게 사용할 수 있도록 만들고 싶었는데요. 원래 Kibana에서 제공했던 csv 가져오기 기능이 현재 공개 중단된 상태였습니다. 그래서 트위터에 이런 고민을 올렸더니 Elasticsearch 일본어 버전을 번역하신 분께서 바로 아래와 같은 내용의 답장을 주셨습니다.
確かに便利ですね。まぁ、CSVにしろRDBにしろ、Logstashでデータ取り込むことができるんで、とりあえずLogstash触ってみていただくのをお勧めしますー
— Jun Ohtani (@johtani) October 24, 2018
(확실히 편리하긴 하죠. 그래도 뭐 CSV든 RDB든 Logstash를 사용해서 데이터를 가져올 수 있으니까 일단 Logstash로 해 보시는 걸 추천합니다~)
트위터한 보람이 있었습니다. xls나 csv 파일 혹은 다른 MySQL 등 여러 개의 데이터 소스를 MySQL로 머지하고 싶었기 때문에 MySQL → Logstash → Elasticsearch의 흐름으로 데이터 가져오기를 진행하기로 방침을 정했습니다. 원본 데이터를 MySQL로 선택한 이유는 다음과 같습니다.
- 기존 설문조사 시스템이 MySQL기반이다.
- 개발자인 내가 MySQL에 익숙하다.
- 사내에 MySQL 기반 서비스가 많을 것 같다.
- 그중 Elasticsearch로 교체하면 속도가 향상될 것 같은 서비스가 있다.
- MySQL에서 Elasticsearch로 마이그레이션하는 프로세스를 만들면 좋겠는데 이 시도가 첫 단추가 될 수 있을 것 같다. Elasticsearch는 데이터만 넣으면 API가 만들어지니 유용할 것 같다.
- Elasticsearch에 막연한 거부감을 가지고 있는 사람에게 이 시도가 Elasticsearch를 사용하게 되는 계기가 되었으면 좋겠다.
- MySQL의 스냅샷을 Kibana에서 보니 행복했다는 내용의 글을 쓸 수 있을 것 같다.
Logstash란?
Logstash란 데이터 인풋(파일이나 MySQL 등 다양한 형태 가능)과 아웃풋(Elasticsearch 서버의 url, port 등)만 지정하면 데이터를 감쪽같이 Elasticsearch로 보내주는 도구입니다. Fluentd를 아신다면 그와 유사한 도구라고 생각하시면 됩니다. 이번에는 jdbc input plugin을 이용해 Logstash와 MySQL에 있는 데이터를 Elasticsearch로 로드했습니다. 쉽게 말하면 MySQL에서 SELECT문을 실행한 결과를 Elasticsearch로 가져온 것입니다.
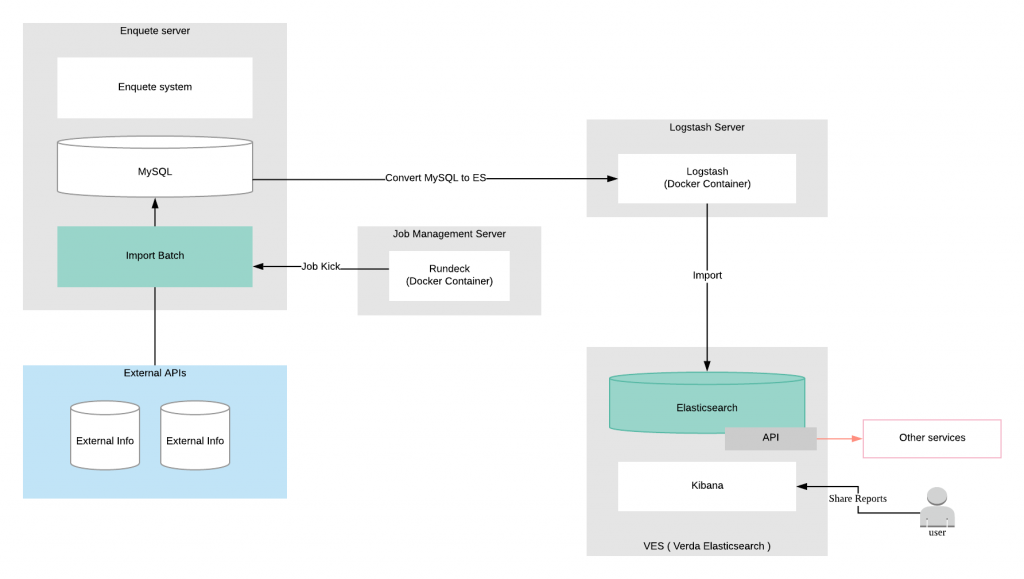
시스템 구성
전체 시스템 구성은 다음과 같습니다. 서버에서 Logstash 컨테이너를 실행한 뒤 Elasticsearch로 가져오기를 실행합니다.
MySQL 설정
MySQL에 SELECT 권한만 가진 Logstash user를 생성해서 Logstash가 구동되는 서버에 접근하는 것을 허가했습니다. 그 외 특별히 언급할 만한 내용은 없습니다.
Logstash 설정
Docker Compose를 사용하여 컨테이너를 실행하는 예시는 이곳에서 볼 수 있습니다. 실행하기 전에 Logstash의 가져오기 설정을 나에게 맞는 설정으로 바꿉니다. 이곳에 예시가 준비되어 있습니다.
Logstash의 설정 파일은 크게 3개(input, filter, output) 섹션으로 나뉩니다.
input section
가져올 데이터가 위치한 MySQL 서버의 설정 정보를 입력합니다.
input {
jdbc {
jdbc_driver_library => "/tmp/mysql-connector-java-8.0.13-1.el7.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://YOUR_MYSQL_SERVER:3306/YOUR_DATABASE_NAME" <-----------
jdbc_user => "YOUR_MYSQL_USER" <-----------
jdbc_password => "YOUR_MYSQL_PASSWORD" <-----------
statement => "SELECT * from YOUR_MYSQL_TABLE" <----------- SELECT문을 작성한다
type => "my_index"
## schedule을 활성화하면 cron처럼 정해진 시간에 작업을 수행할 수 있다
#schedule => "00 * * * *"
}statement에 넣은 SELECT문의 결과가 Elasticsearch에 로드됩니다. 제 실제 설정에서는 연동할 데이터베이스 등의 정보를 UNION하고 다중 JOIN해서 관계를 해제한 상태로 '한 개의 행에 전부 다 모아놓은 데이터'를 추출했습니다. 덕분에 600개가 넘는 칼럼이 생겼지만, 이렇게 해 두면 Kibana를 사용할 때 정말 좋습니다. SELECT문의 결과가 반환되었을 때 가져오기만 실행될 뿐이라서 쿼리 속도는 신경 쓸 필요가 없을 겁니다.
- schedule
저는 1시간 간격으로 가져오기 작업을 할 때 jbdc input plugin의 schedule 기능을 사용했습니다.
## schedule을 활성화하면 cron처럼 정해진 시간에 작업을 수행할 수 있다
schedule => "00 * * * *"위 예시와 같이 컨테이너를 실행시켜 놓으면 매시 정각(00분)에 가져오기 작업을 수행합니다. 아주 편리합니다.
filter section
예시에서는 모두 주석으로 처리했습니다. 여기에서 key를 동적으로 추가하거나 문자열을 교체할 수 있는데요. 새로운 데이터를 분석하려면 MySQL과 filter 중 더 편한 방법을 사용해서 칼럼을 추가하면 됩니다.
output section
데이터를 넣을 Elasticsearch의 접속 정보를 작성합니다.
# elasticsearch 서버 설정
output {
if [type] == "my_index" {
elasticsearch {
manage_template => false
hosts => ["https://YOUR_ELASTICSEARCH_SERVER:9200"]
user => ["YOUR_ELASTICSEARCH_USER"]
password => ["YOUR_ELASTICSEARCH_PASSWORD"]
## 이 부분이 중요. 이 부분이 elasticserch의 index = mysql에서 말하는 테이블이 된다
index => "my_index"
document_type => "%{type}"
#document_id => "%{id}"
}
stdout {codec => rubydebug {metadata => true }}
}
}가져오기 실행

컨테이너를 실행하면 Logstash가 실행된 후 가져오기가 시작됩니다. 제 환경에서는 실행하는 데 1분 가까이 걸립니다(중간에 몇 번 멈춘 것처럼 보이는데 기다리면 작동합니다). 아래 로그가 나왔다면 컨테이너 실행에 성공해서 job이 수행되고 있는 상태입니다.
[INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}MySQL이나 Elasticsearch와 연결되지 않은 에러는 콘솔에 표시되니 콘솔을 잘 살펴보며 에러가 있는지 확인해야 합니다. 한 가지 주의할 점은, 입력한 설정 정보에 문법 오류가 있다면 Logstash 실행에 실패하여 컨테이너가 다운됩니다. statement에 입력한 SQL 구문에 에러가 있을 때도 같은 현상이 발생하는 듯 하니 주의하시기 바랍니다. 실행이 완료되면 statement에 기술된 MySQL 쿼리가 표시되고 가져오기가 시작됩니다. 가져오기는 매우 빠른 속도로 진행되는데요. 출력되는 로그를 보면 어떤 데이터가 로드되고 있는지 파악할 수 있습니다.
Kibana에서 데이터 확인하기
Elasticsearch는 index라고 부르는 식별자를 사용해 표시할 데이터 덩어리(chunk)를 선택합니다. Index는 MySQL의 database나 table 같은 것입니다. 사용자는 index가 어떤 칼럼을 가지고 있는지 처음에 등록해 놓아야 합니다. Kibana를 실행해 Management > Create Index Pattern에서 index pattern을 등록하면 데이터를 사용할 수 있는 상태가 됩니다. Discover 메뉴에서 index와 기간을 선택한 후 데이터가 표시되면 준비가 다 된 것입니다. 이어서 Visualize 메뉴에서 데이터를 그래프로 만들고 Dashboard 메뉴에서 만든 그래프를 적당히 배치하면 됩니다(참고). 아마 큰 어려움 없이 작업하실 수 있을거라고 생각합니다.
데이터가 표시되지 않는다면?
Kibana의 'Dev Tools'를 사용하면 데이터 로드 여부를 쉽게 확인할 수 있습니다.
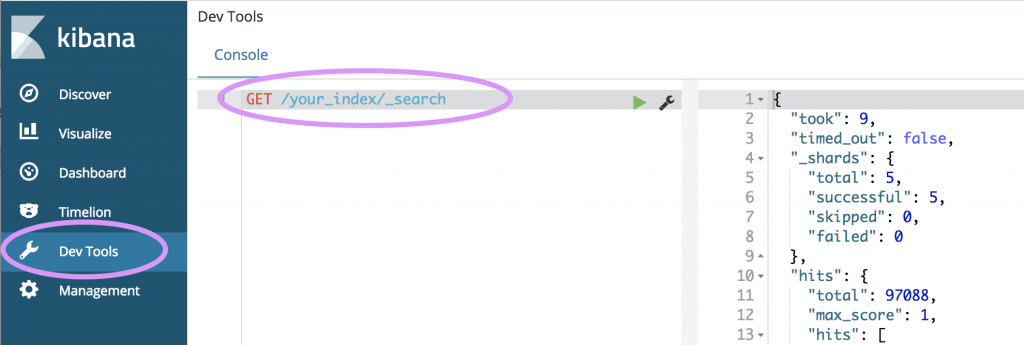
GET /<index명>/_search로 데이터를 가져와서 확인할 수 있고, DELETE /<index명> 으로 가져온 데이터를 모두 삭제할 수도 있습니다.
MySQL을 잘 모르겠다면?
가지고 있는 데이터가 xls나 csv 파일 형태밖에 없다고 하더라도 phpMyAdmin을 이용하면 MySQL로 쉽게 가져올 수 있습니다.
또는 Logstash에서 csv filter plugin을 사용하면 csv 파일을 Elasticsearch로 바로 넣는 것도 가능하다고 합니다. 그럼 MySQL을 준비할 필요도 없겠죠. 데이터를 한번 import한 다음에는 정해진 시간에 가져오기를 실행할 필요 없이 '전체 기간 데이터'로 열람해서 '온라인 피벗 테이블'을 자유롭게 사용할 수 있습니다.
결과 확인
완성된 결과물을 보여드리겠습니다. 아래와 같은 엑셀 데이터를 시스템에 간편하게 import한 후 브라우저에서 엑셀 피벗 그래프를 만들어 정렬했습니다.
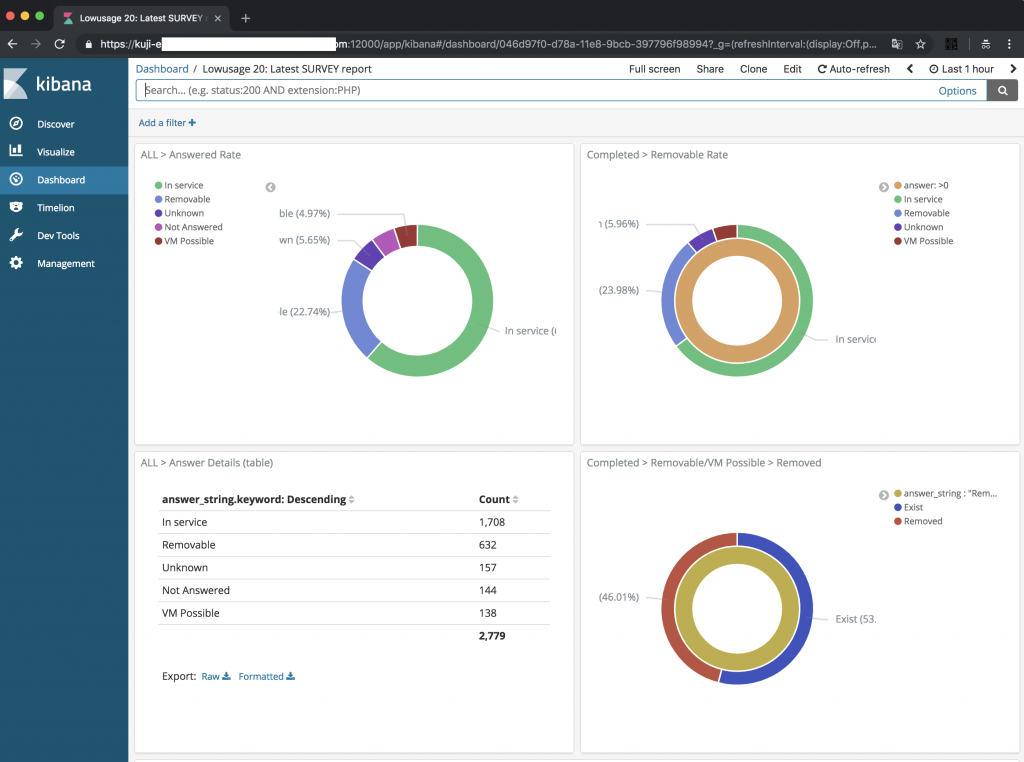
매일 자동으로 엑셀 데이터가 업데이트되는 '온라인 피벗 테이블'(무려 데이터 자동 업데이트!)입니다. 보통 피벗 테이블은 한 시트에 하나만 삽입할 수 있기 때문에 이런 식으로 배열할 수 없습니다.
좀 더 범용성을 높이는 방법
데이터를 Elasticsearch에 import했기 때문에 데이터를 추출할 수 있는 고속 API가 자동으로 생성되어 있습니다. 바로 이 부분이 Elasticsearch의 매력입니다. MySQL의 복잡한 SELECT문이 빠른 속도로 json으로 반환된다고 생각하시면 됩니다. 아래와 같은 URL로 접속하면 API를 사용할 수 있습니다.
http://<Elasticsearch-domain>/<index명>/_search?pretty
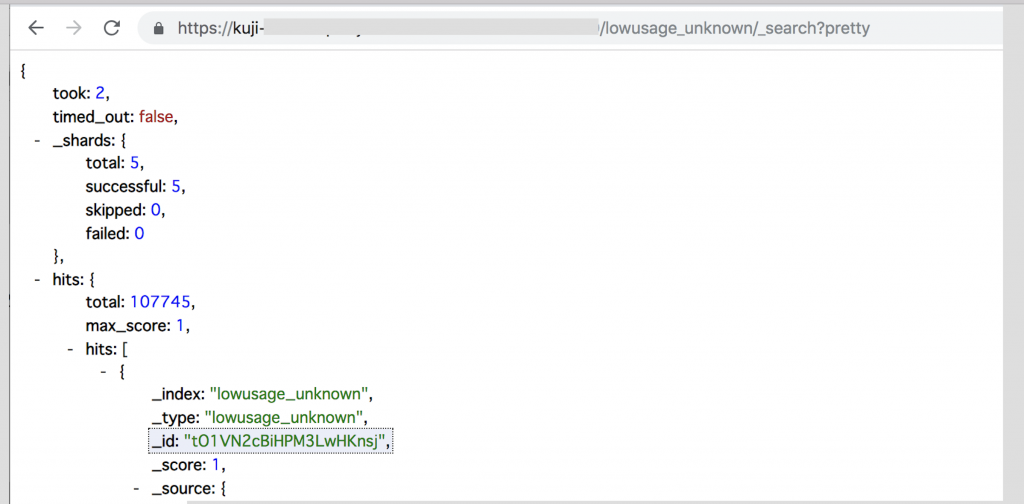
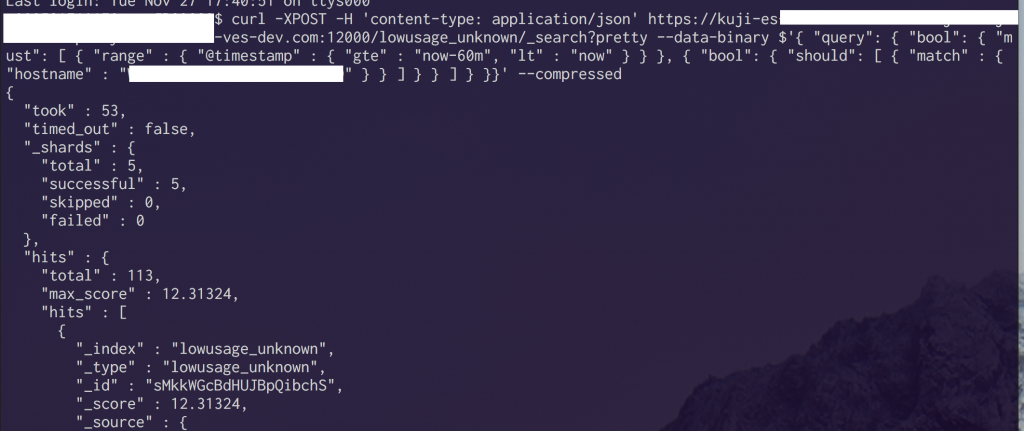
다양한 데이터를 join한 API가 쉽게 만들어졌습니다. 다른 서비스에서도 활용할 수 있을 것 같지 않나요?
마치며
어떠셨나요? 설정 파일이나 코드를 거의 작성할 필요 없이 MySQL의 데이터를 Elasticsearch로 가져올 수 있다는 점이 잘 와닿으셨나요? 이번 포스팅은 일반적으로 용도가 정해져 있는 서비스일지라도 어떻게 바라보느냐에 따라 다른 용도로도 활용할 수 있을 것이라는 관점에서 시작했습니다. 포스팅 관련하여 의견이나 더 좋은 아이디어가 있으시면 Kuji(@uturned0)로 알려 주세요.
마지막으로 LINE에서는 실력있는 개발자들을 적극적으로 채용하고 있습니다. 관심 있으신 분들은 여기를 통해 지원하시기 바랍니다. 혹시 궁금한 점이 있으시면 Kuji(@uturned0)에게 부담 없이 문의해 주세요.