
안녕하세요? LINE에서 Clova의 자연어 이해(NLU, Natural Language Understanding) 유닛을 개발하고 있는 Hattori(keigohtr)입니다. 바야흐로 머신 러닝 붐이 일고 있습니다. 여러분도 이미 머신 러닝을 활용하고 있거나, 상사나 주위 동료로부터 적용해보라는 권유를 받고 있지 않으신가요? 다행히 요 몇 년 머신 러닝이 유행하면서 관련 툴이나 프레임워크가 굉장히 다양해졌습니다. 덕분에 선형 회귀나 로지스틱 회귀와 Perceptron, Adaboost, Random Forest, Support Vector Machine, XGBoost 등 기타 여러 가지 딥러닝 알고리즘을 누구나 손쉽게 접할 수 있게 되었습니다. '학습(learning)' 관련 도구나 프레임워크는 풍부해진 반면, 구축한 머신 러닝 모듈의 '운영'에 관한 도구나 프레임워크는 아직 많지 않은 편입니다. 그래서 오늘은 여러분께 LINE의 AI 플랫폼 Clova에서 사용하는 머신 러닝 모듈 관리 플랫폼인 Rekcurd를 소개해 드릴까 합니다.
이 글은 2018년 여름에 처음 발행되었으나 플랫폼 명칭이 변경되어 수정 후 다시 발행되었습니다. 현재 플랫폼 명칭을 Drucker에서 Rekcurd로 바꾸는 작업이 진행되고 있으며 이 글에서 제공하는 저장소 URL과 예제 코드는 이전 이름을 포함할 수 있습니다.
머신 러닝
머신 러닝을 도입하는 작업은 크게 머신 러닝 모델 구축과 머신 러닝 모델 배포, 두 작업으로 구성됩니다.
머신 러닝 모델 구축
머신 러닝 모델을 구축하는 작업은 다음의 목록에서 다루듯이 데이터 수집이나 데이터 정제(data cleansing), 학습 특성(feature) 설계, 알고리즘 선택, 네트워크 디자인(딥러닝 모델 구축 시), 파라미터 튜닝, 머신 러닝 모델 평가 등의 작업으로 구성됩니다. 머신 러닝 엔지니어나 데이터 사이언티스트는 전문성을 총동원하여 이러한 작업을 해결하기 위해 노력하고 있습니다.
- Data
- Collection (supervised learning, unsupervised learning, distant supervision)
- Cleaning/Cleansing (outlier filtering, data completion)
- Features
- Preprocessing (morphological analysis, syntactic analysis)
- Dictionary (wordnet)
- Training
- Algorithms (regression, SVM, deep learning)
- Parameter tuning (grid search, Coarse-to-Fine search, early stopping strategy)
- Evaluation (cross validation, ROC curve)
- Others
- Server setup
- Versioning (data, parameters, model and performance)
몇 년 사이 관련된 도구나 프레임워크도 많아졌는데요, 가령 Python으로 개발을 한다면 scikit-learn, gensim, Chainer, PyTorch, TensorFlow, Keras 등의 머신 러닝 관련 라이브러리를 이용할 수 있습니다. 또 학습 진척 상황 모니터링이나 리포팅용으로는 Jupyter Notebook, JupyterLab, ChainerUI, TensorBoard 등을 이용할 수 있습니다.
얼마 전에는 Google이 개발 환경을 구축하기 위한 도구로 kubeflow를 선보였는데요, kubeflow는 Kubernetes 환경에서 구축하는 머신 러닝 플랫폼으로 병렬 계산 환경을 제공합니다. 이처럼 머신 러닝 엔지니어와 데이터 사이언티스트의 업무를 도와주는 편리한 도구와 프레임워크는 점점 많아지고 있습니다.
머신 러닝 모듈 배포
머신 러닝 모듈을 배포하는 작업은 머신 러닝 모듈의 서비스화, 서비스의 이중화, 기존 시스템과 통합하기(integration), 머신 러닝 모델이나 서비스 업데이트, 서비스 상태 모니터링 등의 작업이 있습니다. 이에 기반하여 머신 러닝 모듈 배포를 돕는 프레임워크가 기본적으로 제공해야 하는 기능은 다음과 같습니다.
- High Availability
- Management
- Uploading the latest model
- Switching a model without stopping services
- Versioning models
- Monitoring
- Load balancing
- Auto-healing
- Auto-scaling
- Performance/Results check
- Others
- Server setup
- Managing the service level (e.g. development/staging/production)
- Integrate into the existing services
- AB testing
- Managing all ML services
- Logging
서버 관련 작업은 인프라 엔지니어나 서버측 엔지니어의 업무에 해당하지만, 머신 러닝 관련 작업은 그렇지 않습니다. 또 머신 러닝 모델별로 특화된 전처리나 후처리가 필요할 때가 있기 때문에 머신 러닝 서비스를 구축하려면 어느 정도는 머신 러닝 엔지니어가 담당해야 합니다. 가끔은 머신 러닝 엔지니어가 담당 모듈을 직접 서비스화하기도 하는데, 아무래도 전문 분야가 아니다 보니 담당자에 따라 서비스 품질에 편차가 생기기도 하고 서버 구축 및 모듈 점검/운영 작업이 지속적으로 발생하면서 주 담당 분야인 머신 러닝 모델 구축 작업에 전념할 수 없게 되는 등 많은 문제가 발생할 수 있습니다.
이러한 문제를 해결하기 위한 하나의 방법으로 TensorFlow Serving이 있습니다. TensorFlow Serving을 이용하면 TensorFlow의 모델을 자동으로 gRPC 서비스로 배포할 수 있습니다. 하지만 전처리나 후처리를 서비스에 포함시킬 수 없고, TensorFlow 모델만 대상이 된다는 점(2018년 7월 기준) 때문에 우리의 요구 사항이 모두 충족되지는 않았습니다. 우리는 특화된 전처리와 후처리를 머신 러닝 모델과 한 세트로 배포하고 싶었고, scikit-learn이나 gensim 등으로 만든 머신 러닝 모델도 배포하고 싶었습니다. 그래서 Clova에서는 이러한 요구 사항을 충족시켜줄 솔루션으로 Rekcurd와 Kubernetes를 도입하여 머신 러닝 모듈의 관리 운영 플랫폼을 구축하였습니다.
Rekcurd란?
Rekcurd는 머신 러닝 배포 프레임워크로서 다음의 주요 특징을 가지고 있습니다.
- 머신 러닝 모듈 배포 쉬움
- 머신 러닝 모듈 관리 및 운영도 쉬움
- 기존 시스템에 머신 러닝 모듈을 통합하는 것도 쉬움
- Kubernetes에서(도) 구동 가능
Clova의 머신 러닝 배포 플랫폼
Clova에서는 Rekcurd와 Kubernetes를 결합하여 다음과 같이 구성된 머신 러닝 배포 플랫폼을 구축하였습니다.
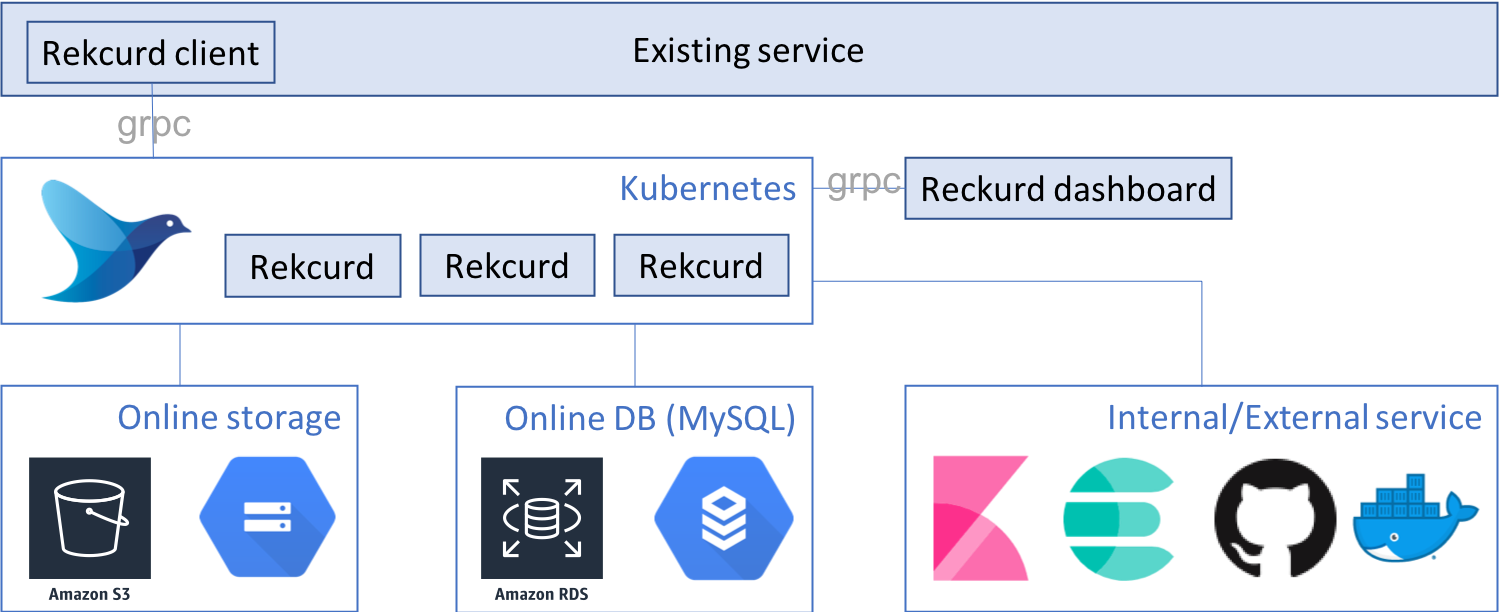
그럼 각각의 구성 요소를 살펴보겠습니다. 이하, 머신 러닝 모듈을 Rekcurd 애플리케이션, 해당 머신 러닝 모듈의 웹 서비스는 Rekcurd 서비스, 이 웹 서비스의 이중화로 생성된 컨테이너는 Rekcurd Pod라고 정의합니다.
- Rekcurd
- Kubernetes
- Load balancing - nghttpx
- Rekcurd Dashboard
- Rekcurd Client
- Logging - fluentd-kubernetes
- Docker registry x Git repository
- Online storage
- MySQL
Rekcurd
Rekcurd는 gRPC 서버의 템플릿입니다. 이 템플릿에 머신 러닝 모듈을 넣으면 모듈을 gRPC의 마이크로 서비스로 만들 수 있습니다. Rekcurd를 사용하는 방법은 Django나 Flask 등 WebAPI 프레임워크와 비슷합니다. 구체적으로는 다음의 코드와 같이 Rekcurd의 PredictInterface 클래스의 implementation 클래스를 만드는 것입니다. gRPC의 사양은 Rekcurd에 정의되어 있기 때문에, gRPC에 익숙지 않은 사용자라도 Rekcurd로 gRPC 서버를 구축할 수 있습니다.
아래 predict 메서드의 input 필드는 머신 러닝에 값을 입력할 때 주로 사용되는 데이터형인 string, bytes, list[int], list[float], list[string] 중 하나를 취합니다. 장치 정보나 사용자 ID 등 추가 정보를 보내고자 할 경우에는 option 필드를 사용할 수 있습니다. option 필드는 dictionary 데이터형으로 단계(depth)에 제한 없이 자유롭게 사용할 수 있습니다. 자세한 예시는 이곳에서 확인하실 수 있습니다.
class Predict(PredictInterface):
def __init__(self):
super().__init__()
self.predictor = None
self.load_model(get_model_path())
def load_model(self, model_path: str = None) -> None:
assert model_path is not None,
'Please specify your ML model path'
try:
self.predictor = joblib.load(model_path)
except Exception as e:
print(str(e))
os._exit(-1)
def predict(self, input: PredictLabel, option: dict = None) -> PredictResult:
try:
label_predict = self.predictor.predict(
np.array([input], dtype='float64')).tolist()
return PredictResult(label_predict, [1] * len(label_predict), option={})
except Exception as e:
print(str(e))
raise e
Kubernetes
Kubernetes는 컨테이너 관리 도구로 이미 유명한 시스템이니 따로 소개는 하지 않겠습니다. Kubernetes를 저희 플랫폼에 이용하면 다음과 같이 크게 다섯 가지의 이점이 있습니다.
- 서비스를 정지하지 않고 업데이트 가능(rolling update)
- 서비스 자동 복원(auto healing)
- 서비스 자동 스케일링(auto scaling)
- 서비스 레벨 관리(development/staging/sandbox/production)
- 서비스 실행 제어(서비스 레벨이 다른 Pod를 같은 노드에서 실행하지 않기, 같은 Pod를 같은 노드에서 실행하지 않기)
Rekcurd는 Kubernetes 환경을 지원하기 때문에 이 둘을 결합하면 강력한 머신 러닝 배포 플랫폼을 구축할 수 있습니다. Kubernetes 모듈은 Google GKE이나 Amazon EKS와 같은 기존 서비스를 이용하거나 Rancher 등을 통해 직접 구축합니다. Rancher를 이용한 Kubernetes 클러스터 구축 방법에 관해서는, Rancher 공식 문서 또는 Rekcurd 문서를 참조하시기 바랍니다.
Load balancing - nghttpx
Kubernetes 외부에서 내부로 접근할 때는 Kubernetes의 ingress 기능을 이용합니다. 먼저 할 일은 Kubernetes 클러스터의 전체 또는 일부 노드에 DNS(예: example.com)를 할당하는 것입니다. 이어서 해당 DNS의 서브도메인에 Rekcurd로 구축한 머신 러닝 모듈의 이름과 ID를 할당한 뒤 ingress에 등록합니다(예: http://-.example.com). 자, 이제 서브도메인에서 접속하는 머신 러닝 모듈을 변경할 수 있습니다. 이 엔드포인트는 나중에 언급할 Rekcurd 클라이언트를 이용하여 머신 러닝 모듈에 접속합니다.
로드 밸런서는 nghttpx ingress controller를 사용합니다. nghttpx는 http2 프로토콜을 지원하는 라이브러리로, nghttpx ingress controller는 포트 80번으로의 http2 요청을 로드 밸런싱합니다. Kubernetes 공식 저장소에 있는 nginx ingress controller는 포트 80번에서 http2를 지원하지 않기 때문에(※ nginx 1.13.10 이후는 지원됨), 현재로서는 nghttpx ingress controller를 사용하는 것이 최선의 방법입니다.
Rekcurd-dashboard
Rekcurd-dashboard는 앞서 언급한 Rekcurd에 연결됩니다. 여기에서 모든 Rekcurd 서비스가 종합적으로 관리됩니다. Kubernetes에 접속할 수도 있고, Kubernetes 상에서 작동하는 Rekcurd 서비스를 관리할 수도 있습니다. 대시보드에서 수행할 수 있는 작업은 다음과 같습니다.
- 머신 러닝 모델 업로드
- 머신 러닝 모델 버저닝
- 머신 러닝 모듈의 로딩 모델 변경
- 머신 러닝 모델의 성능 평가 및 가시화(구현 중)
- Kubernetes에 접속해서 Rekcurd 실행하기
장점으로는 머신 러닝 모델 관리를 일원화하여 WebUI로부터 원활하게 전환된다는 점, 또 Kubernetes를 잘 몰라도 Kubernetes에서 Rekcurd를 실행할 수 있다는 점을 들 수 있습니다. 반면 과제도 있습니다. 이를테면 Rekcurd-dashboard v0.2.0은 성능 평가 기능과 가시화 기능, 그리고 Kubernetes의 대시보드처럼 Alive/Dead 상태나 CPU/메모리 사용량 같은 서비스 현황을 모니터링하는 기능이 구현되어 있지 않다는 점, 사용자 인증 기능이 없다는 점 등 아직 기능면에서 부족한 부분이 많이 있습니다. 앞으로 개발되었으면 하는 바람입니다.

Rekcurd-client
Rekcurd-client는 Rekcurd에 접속하기 위한 SDK입니다. Rekcurd는 gRPC를 사용하므로, gRPC 사양에 따라 임의의 언어로 SDK를 자동 생성할 수 있습니다. Rekcurd-client는 gRPC 사양에 따라 자동 생성된 Python SDK를 확장한 것이 됩니다. Kubernetes 상의 Rekcurd에 접속할 때는 클라이언트를 다음과 같이 사용합니다.
logger = SystemLogger(logger_name="drucker_client")
domain = 'example.com'
app = 'drucker-sample'
env = 'development'
client = DruckerWorkerClient(logger=logger, domain=domain, app=app, env=env)
input = [0,0,0,1,11,0,0,0,0,0,
0,7,8,0,0,0,0,0,1,13,
6,2,2,0,0,0,7,15,0,9,
8,0,0,5,16,10,0,16,6,0,
0,4,15,16,13,16,1,0,0,0,
0,3,15,10,0,0,0,0,0,2,
16,4,0,0]
response = client.run_predict_arrint_arrint(input)Logging - fluentd-kubernetes
Fluentd가 제공하는 공식 Kubernetes 지원 시스템인 fluentd-kubernetes를 사용합니다. fluentd-kubernetes를 Kubernetes에서 실행해두면 Kubernetes 상의 모든 Pod의 표준 출력과 표준 오류 출력을 임의의 서버로 전송할 수 있습니다. Clova에서는 Rekcurd의 로그를 Kibana & ElasticSearch 서버로 전송하고 있습니다.
Docker registry x Git repository
Kubernetes를 이용해 서비스를 관리할 때 일반적으로 컨테이너 이미지를 업데이트하는 방식으로 서비스를 업데이트하며, 사용자는 컨테이너 이미지를 능숙하게 다룰 줄 알아야 합니다. Rekcurd는 기본적인 컨테이너 이미지를 제공하기 때문에 사용자가 컨테이너 이미지 작성 방법을 잘 몰라도 Kubernetes에서 서비스를 제공할 수 있습니다. 컨테이너를 실행할 때 Rekcurd의 코드를 깃에서 풀(pull)하여 서비스를 실행합니다. ssh를 통한 git pull도 지원됩니다. Rekcurd Pod는 Kubernetes 노드의 /root/.ssh/를 마운트하고 있기 때문에, 노드에 ssh 키를 저장해두면 Pod가 ssh를 이용해 접속할 수 있습니다.
Online storage
머신 러닝 모델은 AWS EBS나 GCS, WebDAV 같은 온라인 저장소에 저장합니다. 구조상 Rekcurd Pod는 Kubernetes 노드를 마운트(디폴트: /mnt/drucker-model/)하고 있기 때문에, Kubernetes 노드의 해당 디렉터리에 온라인 저장소를 마운트하면 모든 Pod가 온라인 스토리지를 마운트할 수 있게 됩니다. 이런 방식으로 모든 머신 러닝 서비스가 머신 러닝 모델 전체를 공유하고 있습니다.
MySQL
MySQL은 Rekcurd가 로딩할 머신 러닝 모델의 할당을 관리합니다. Rekcurd는 실행 시 MySQL을 참조하여 어떤 머신 러닝 모델을 로딩할지 파악합니다. Kubernetes에서는 장애나 업데이트 시에 현행 Pod를 폐기하고 새로운 Pod를 실행합니다. 따라서 외부에서 제어하는 파라미터는 참조할 곳을 외부에 두어야 합니다.
머신 러닝 모듈 관리 방법
Rekcurd 대시보드를 이용한 머신 러닝 모듈의 관리 방법을 소개하겠습니다. Rekcurd & Kubernetes 환경 구축에 대한 자세한 내용을 원하시는 분은 공식 문서를 참조하시기 바랍니다.
대시보드 접속
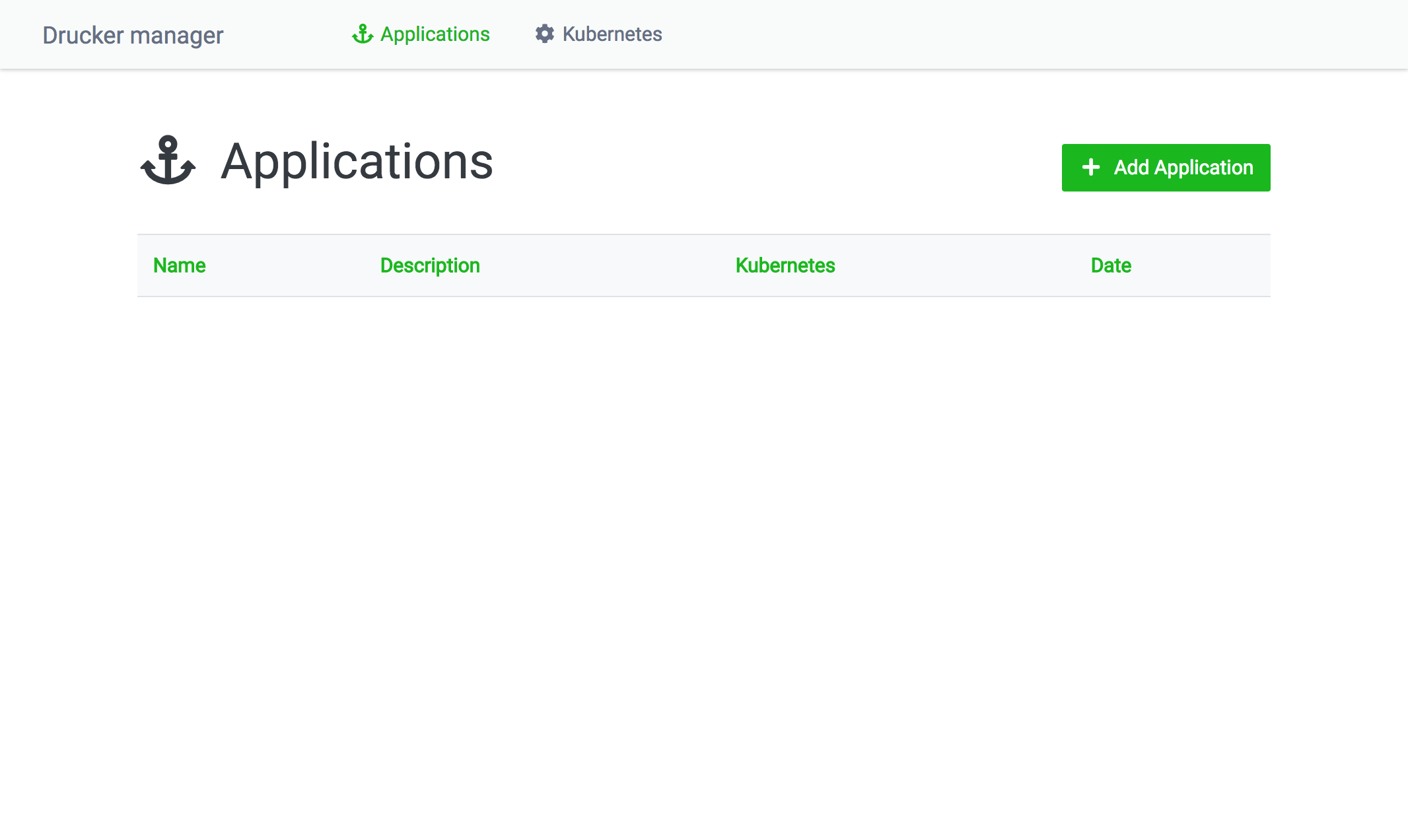
Rekcurd-dashboard를 실행한 뒤 http://localhost:8080/ 등의 URL로 대시보드에 접속하면 대시보드에서 관리 중인 Rekcurd 애플리케이션의 목록을 첫 화면에서 볼 수 있습니다.
Kubernetes 호스트 추가
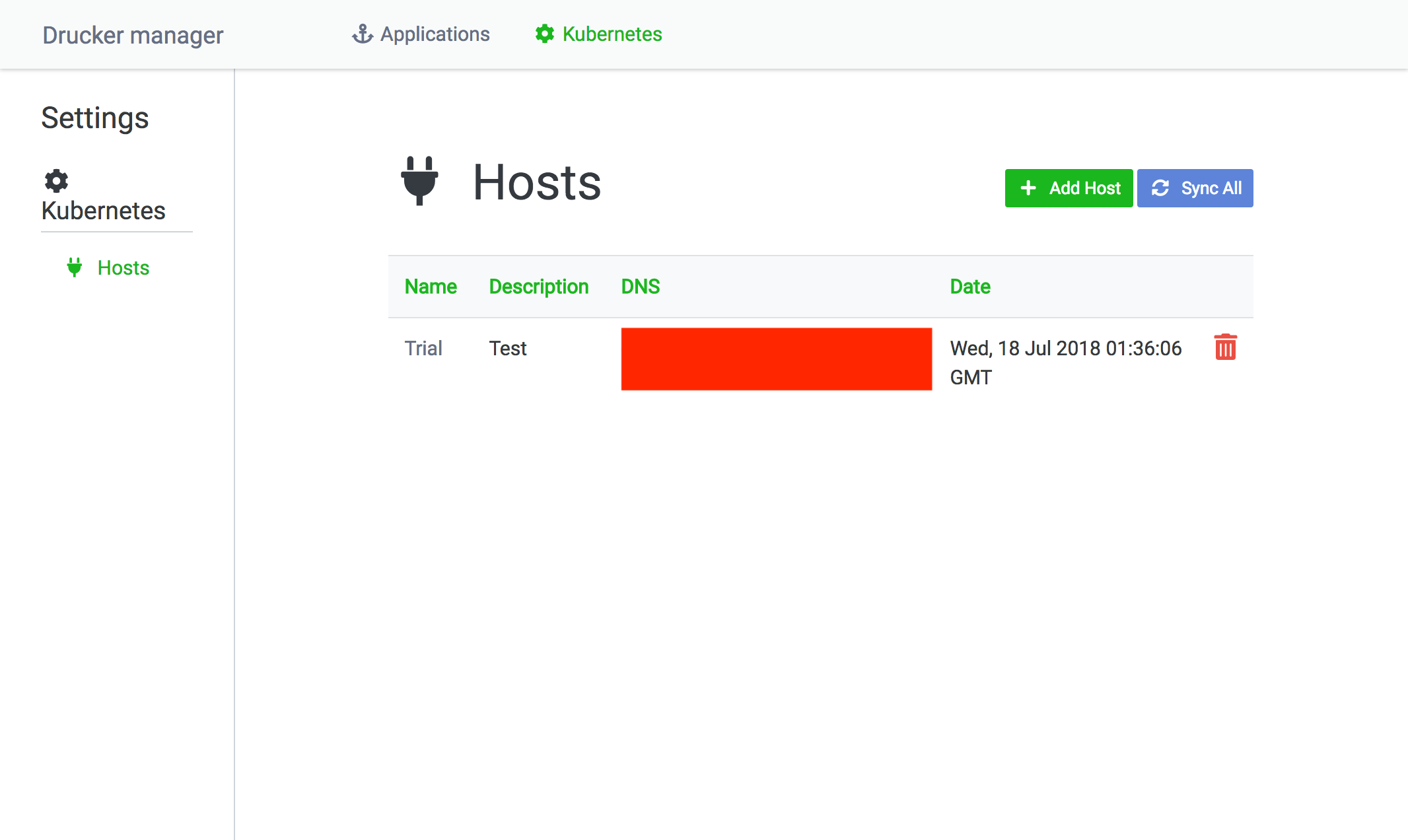
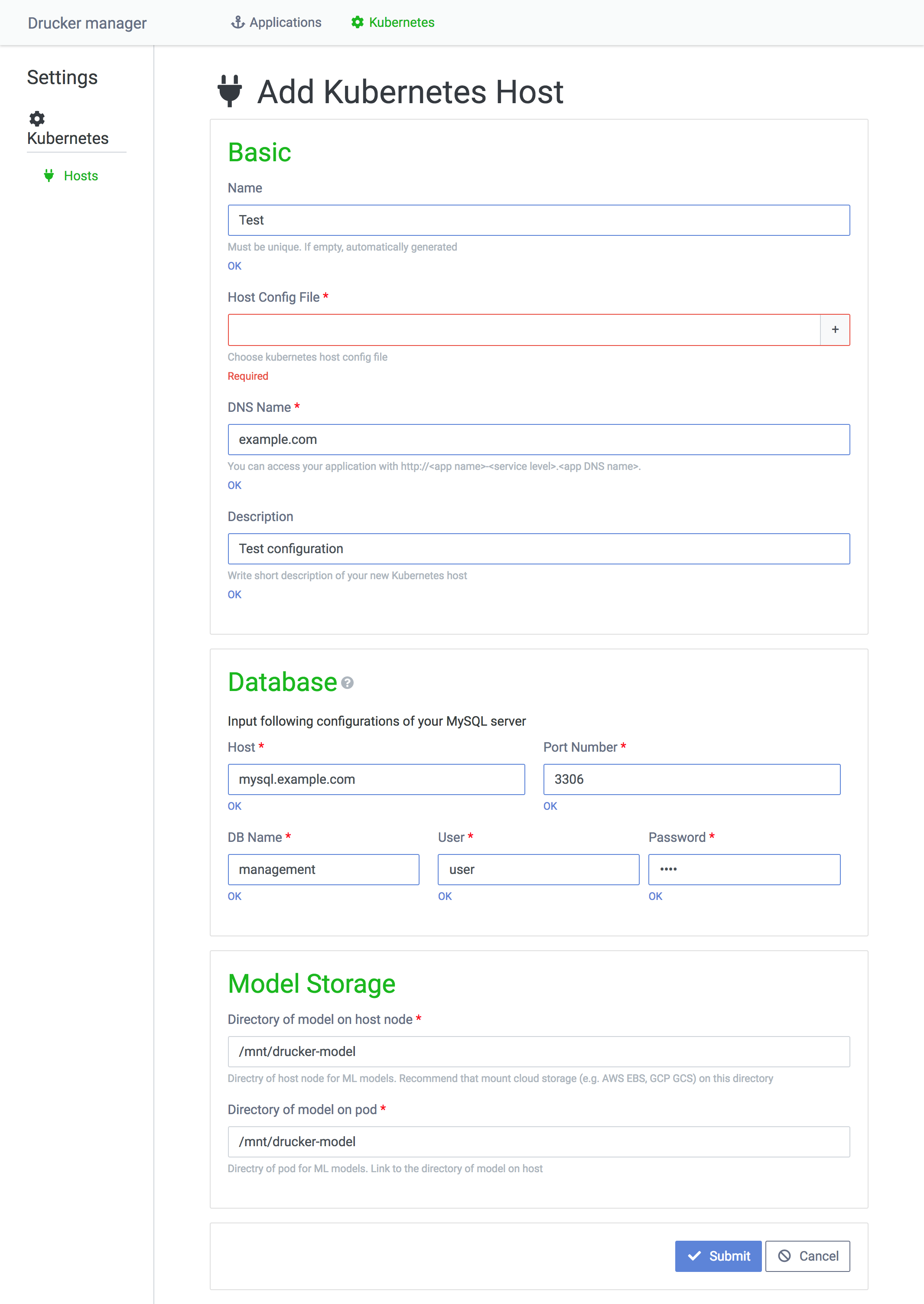
Rekcurd 대시보드 첫 화면에서 Kubernetes 메뉴를 선택하면 다음 그림과 같이 대시보드에서 관리 중인 Kubernetes 클러스터의 목록을 확인할 수 있습니다. Add Host 버튼을 클릭하면 신규 Kubernetes 클러스터 등록 화면이 나타납니다. Sync All 버튼을 클릭하면 대시보드에 등록되어 있는 Kubernetes 클러스터에 조회 요청을 보내어 실행 중인 Rekcurd 서비스의 정보를 취득하게 됩니다. Sync All은 Rekcurd-dashboard를 이용하지 않고 Kubernetes를 작동시켰을 경우에도 Rekcurd 대시보드의 정보를 최신 상태로 유지하기 위한 기능입니다.
다음은 Kubernetes 클러스터를 등록하는 페이지입니다. 입력 항목 중 몇 가지를 소개해 드리겠습니다. 먼저 Host Config File 항목은 Kubernetes 클러스터 접속용 토큰을 보유한 파일을 의미합니다. Kubernetes 클러스터의 접속 토큰 취득 방법에 대한 자세한 내용을 보려면 이곳을 참조하세요. Database 섹션에서 설정하는 MySQL은 Rekcurd Pod가 실행될 때 참조하는 데이터베이스로, Rekcurd Pod가 로딩할 머신 러닝 모델을 할당합니다. Model Storage 섹션은 머신 러닝 모델이 저장되는 곳으로, Rekcurd Pod가 Kubernetes 노드의 디렉터리를 마운트합니다. 모든 Pod에서 머신 러닝 모델을 공유하려면 Kubernetes 노드의 해당 디렉터리는 온라인 저장소를 마운트하고 있어야 합니다.
신규 머신 러닝 모듈 실행
신규 머신 러닝 모듈을 Kubernetes에서 실행하려면 모듈을 대시보드에서 애플리케이션으로 추가해야 합니다. 대시보드 첫 화면의 Add Application 버튼을 클릭하면 다음의 페이지가 나타납니다.
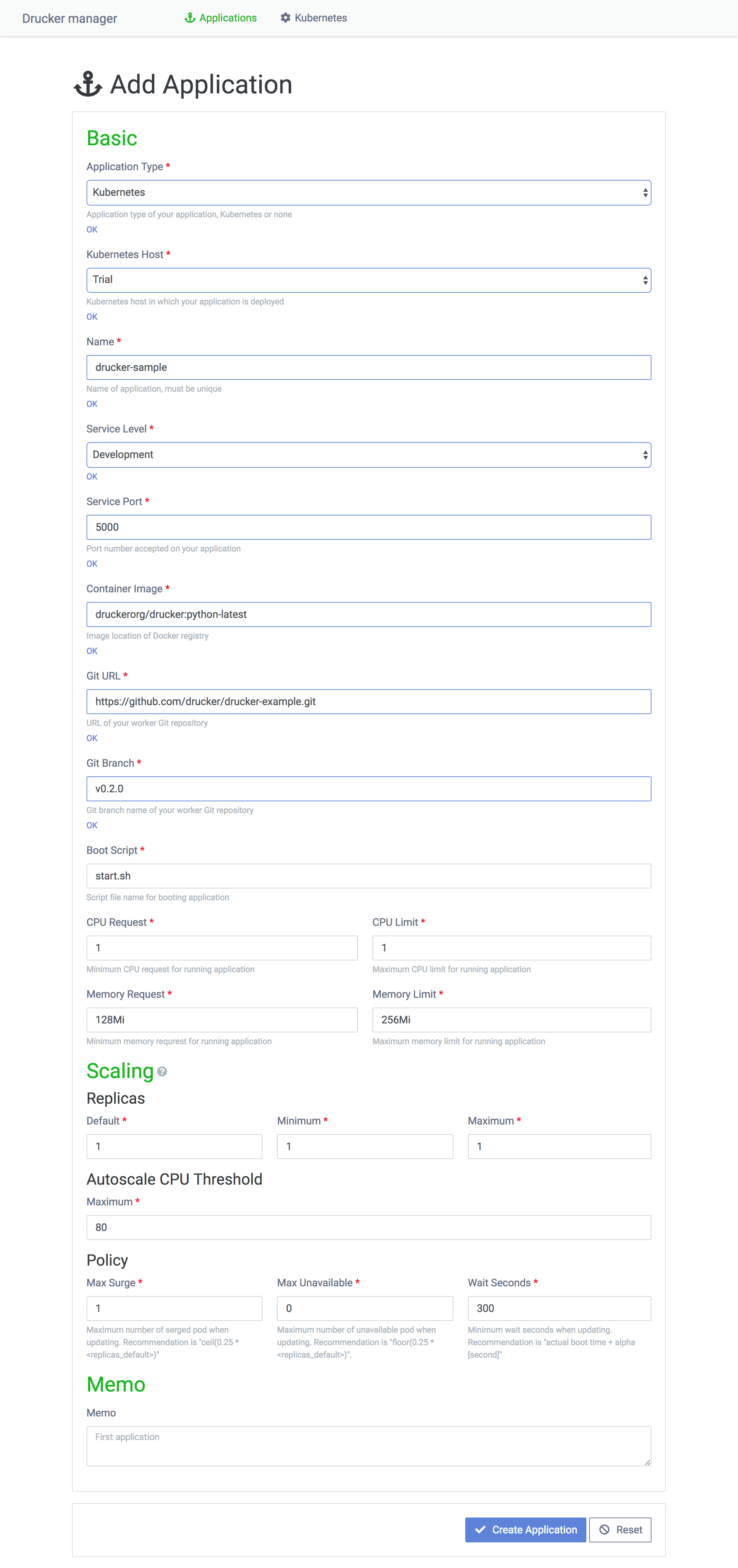
애플리케이션 생성 페이지의 각 항목에 어떤 값을 입력해야 하는지 간략하게 소개해 드리겠습니다.
- Application Type: Kubernetes를 선택하고, Kubernetes Host로는 실행하고자 하는 Kubernetes 클러스터를 지정합니다.
- Name: Rekcurd 애플리케이션의 이름을 입력합니다. Rekcurd 대시보드는 머신 러닝 모듈을 애플리케이션이라는 단위로 관리하며, 머신 러닝 모델이나 서비스 레벨이 각각 다른 Rekcurd 서비스가 애플리케이션에서 관리됩니다.
- Service Level: Development, production 등 적절한 서비스 레벨을 지정합니다. Service Port는 서비스가 Kubernetes Pod에서 실행될 때의 Port로, 여기에 임의의 Port를 지정해 둡니다.
- Container Image: Rekcurd Pod가 실행되는 컨테이너 이미지를 뜻합니다. Rekcurd가 제공하는 공식 Docker 이미지, 혹은 이를 확장한 자체 이미지를 사용할 수도 있습니다. 컨테이너 이미지는 Docker Hub, 또는 Private Docker registry에 등록합니다.
- Git URL, Git Branch: Rekcurd를 이용해 머신 러닝 서비스화한 코드의 git 저장소를 지정합니다. Boot Script에서는 해당 git 저장소 하위에 있는 실행 셸 스크립트를 지정합니다. Rekcurd 공식 Docker 이미지는 컨테이너 실행 시에 Git URL과 Git Branch에서 코드를 풀(pull)하며, Boot Script를 사용해서 Rekcurd Pod를 실행합니다.
- CPU Request, CPU Limit: 각 Rekcurd Pod에서 사용하는 CPU 요구량과 최대치를 float형으로 입력합니다. 예를 들어 1.0은 CPU 1대를 의미합니다.
- Memory Request, Memory Limit: 각 Rekcurd Pod에서 사용하는 메모리의 요구량과 최대치를 문자열형(예: 128Mi, 1Gi)으로 입력합니다.
- Scaling > Replicas: Rekcurd 서비스 이용 빈도와 Kubernetes 클러스터의 규모를 감안하여 Pod 수를 입력합니다. Default, Minimum, Maximum은 각각 초기 실행 Pod 수, 최소 실행 Pod 수, 최대 실행 Pod 수를 의미합니다.
- Scaling > Autoscale CPU Threshold: 자동 확장의 트리거입니다. 이 부분이 '80'으로 설정되어 있으면 CPU 사용량이 80%를 넘을 때 자동 확장이 실행됩니다.
- Scaling > Policy:
- Max Surge: 롤링 업데이트 시 동시에 실행되는 신규 Rekcurd Pod 수를 뜻합니다.
- Max Unavailable: 롤링 업데이트 시 동시 삭제되는 현행 Rekcurd Pod 수입니다.
- Wait Seconds: 롤링 업데이트 시에 실행한 Pod가 안정화될 때까지 걸리는 시간을 뜻합니다. 너무 짧게 설정되어 있으면 Rekcurd Pod 실행 실패를 인지하지 못한 채 현행 Pod를 계속해서 삭제해 버리기 때문에 최악의 경우 서비스가 정지됩니다. 따라서 주의가 필요합니다.
- Memo: 자유 기입란입니다. 예를 들어 '언제 릴리스했는지', '어떤 변경 사항 때문에 업데이트했는지' 등 부가 정보를 입력합니다.
애플리케이션 생성에 필요한 항목을 입력한 후 Create Application 버튼을 클릭하면 애플리케이션 생성 과정이 마무리됩니다.
머신 러닝 모델 추가 및 변경
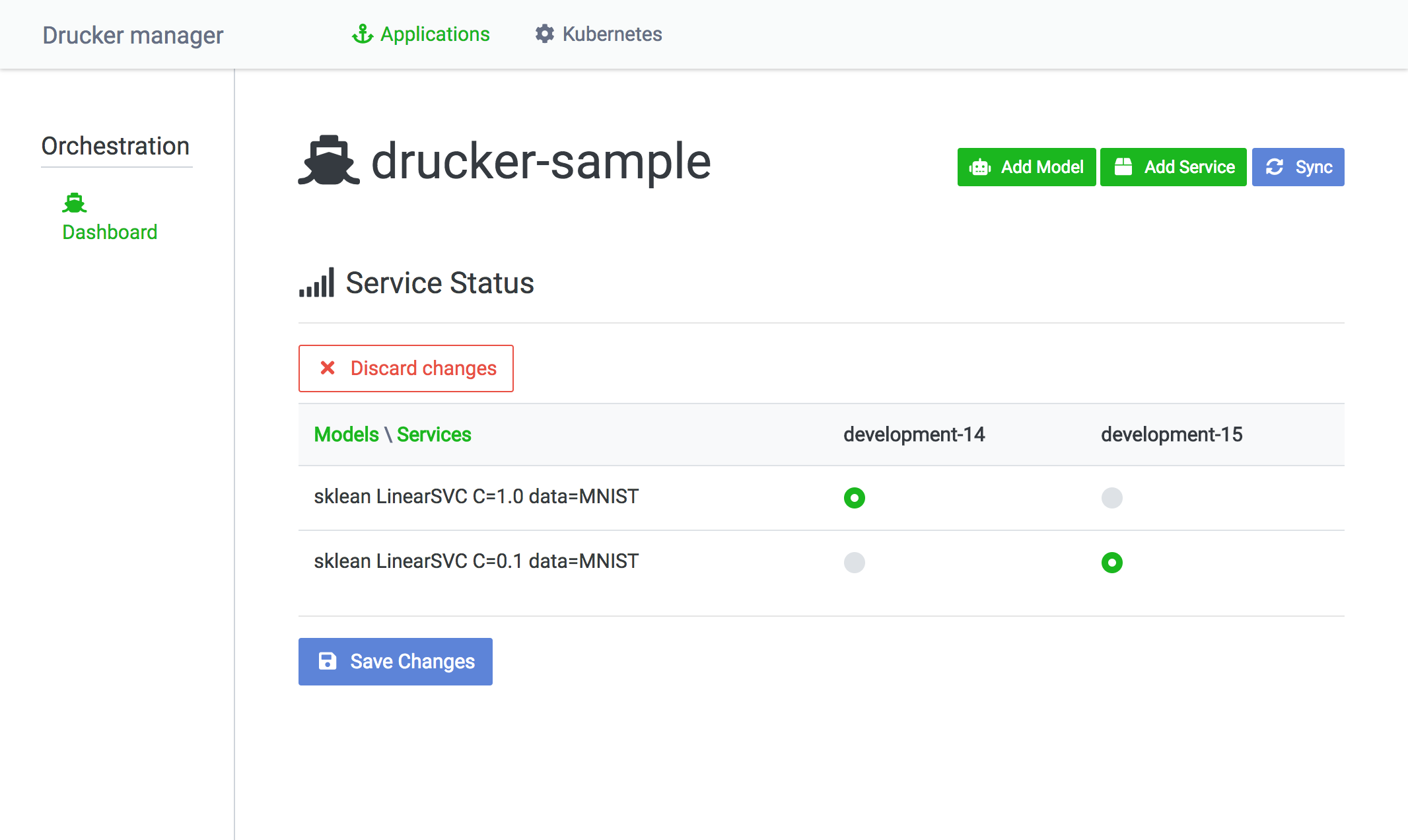
Rekcurd 서비스가 어떤 머신 러닝 모델을 사용하는지 확인하거나, 새로운 머신 러닝 모델을 추가하거나 혹은 기존 서비스의 머신 러닝 모델을 변경해야 할 때가 있을 텐데요, 먼저 변경하고자 하는 서비스가 속한 애플리케이션의 서비스 목록을 확인해야 합니다. Rekcurd 대시보드 상단의 Applications 메뉴를 클릭하면 해당 애플리케이션의 Rekcurd 서비스 목록을 볼 수 있습니다. 서비스 목록은 표로 되어 있는데, 세로 항목이 머신 러닝 모델이고 가로 항목이 Rekcurd 서비스입니다. 표에서 어느 Rekcurd 서비스가 어느 머신 러닝 모델을 로딩했는지 일괄적으로 확인하고 관리할 수 있습니다.
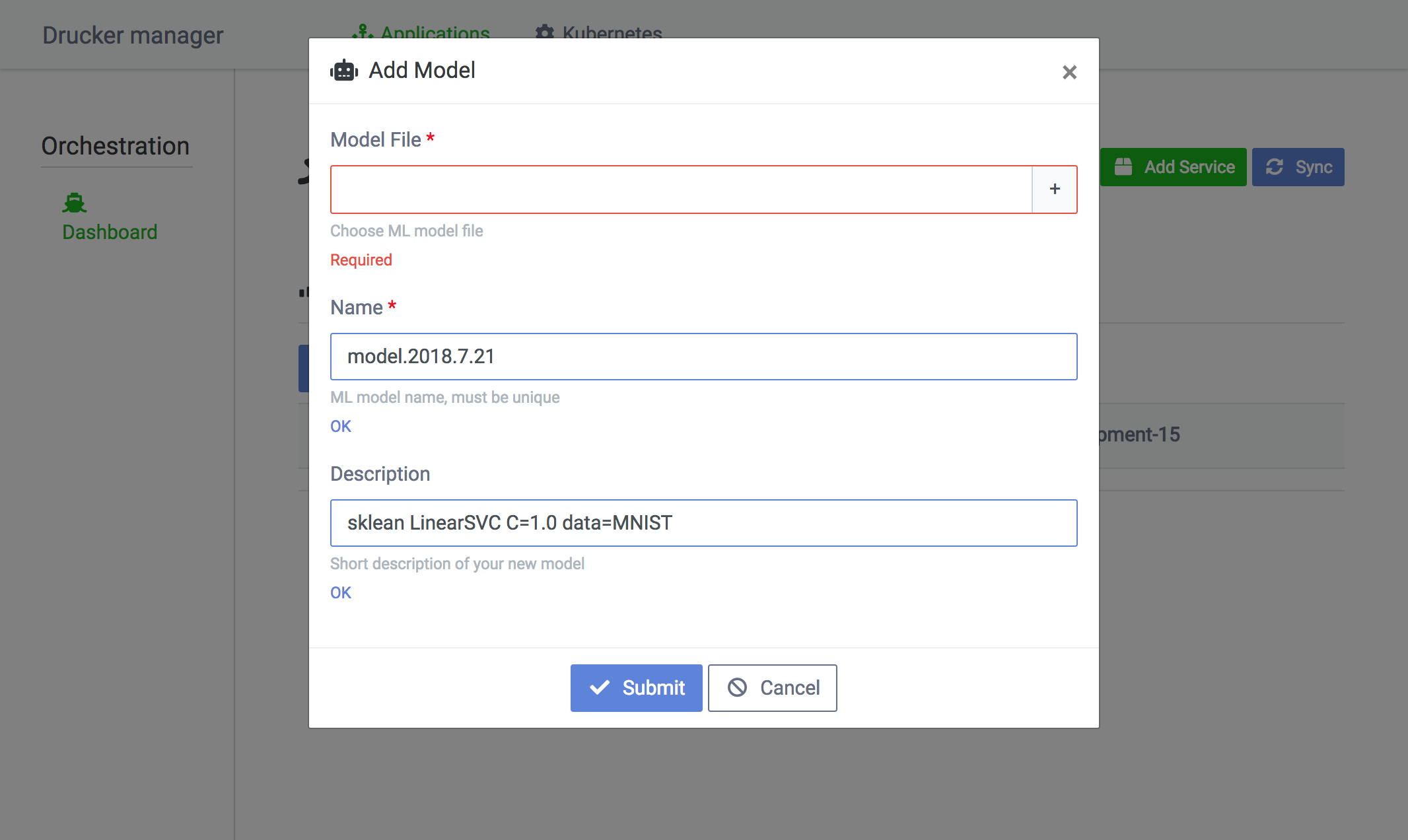
새로운 머신 러닝 모델을 추가하려면, 서비스 목록 화면에서 Add Model 버튼을 클릭해서 머신 러닝 모델을 업로드합니다. Description란에 모델 생성일과 설정 등을 입력해 두면 모델 관리에 도움이 됩니다.
서비스의 머신 러닝 모델을 변경하려면 서비스 목록 화면에서 Switch models 버튼을 클릭하여 손쉽게 변경할 수 있습니다.
필요한 내용을 수정한 뒤, Save Changes 버튼을 클릭하면 Kubernetes에서 롤링 업데이트가 진행됩니다.
맺으며
이번 글에서는 Clova 머신 러닝 모듈의 관리 운영 플랫폼인 Rekcurd를 소개해 드렸습니다. Rekcurd는 유연한 구성으로 다양한 종류의 알고리즘을 배포할 수 있으며, WebUI 기반의 대시보드를 이용해 머신 러닝 모델을 쉽게 관리하고 운영할 수 있습니다. 백엔드로 Kubernetes를 이용함으로써 서비스 모니터링과 확장을 자동화할 수도 있습니다. 또한 Rekcurd는 gRPC 서비스이기 때문에 SDK가 전 세계 언어로 자동 생성됩니다. 그뿐만 아니라, Rekcurd 클라이언트에 앱 이름을 지정하면 접속할 머신 러닝 모듈을 변경할 수 있기 때문에 단 하나의 클라이언트를 이용하여 Rekcurd & Kubernetes로 배포하는 모든 머신 러닝 모듈에 접속할 수 있습니다. Rekcurd는 지금도 개발이 한창 진행 중인 프로젝트로 기능면에서 아직 부족한 점은 많지만, 적극적인 커밋들을 통해 더욱 강력한 OSS(Open Source Software)로 발전시켜 갔으면 하는 마음입니다.