
Decaton 소개
얼마 전, LINE에서 개발한 라이브러리 Decaton이 오픈소스로 공개됐습니다. Decaton은 Kafka를 이용한 비동기 처리 작업 큐(queue) 라이브러리로 LINE에서 널리 사용하고 있습니다.
사실 Kafka에서 스트림을 다루는 공식 라이브러리로 Kafka Streams를 이미 제공하고 있습니다. 하지만, Kafka Streams가 당시 저희 요구 사항에 맞지 않아 별도로 Kafka를 이용한 라이브러리인 Decaton을 개발하게 되었습니다. Decaton은 Kafka Streams보다 효율적으로 메시지를 처리하면서 프로그램 자체도 간단하게 구성할 수 있습니다. 이번 글에서는 LINE에서 Decaton을 어떻게 활용하고 있는지 사례를 통해 공유하려고 합니다.
적용 사례 소개
이번 글에서 적용 사례로 소개할 프로젝트는 현재 일본과 대만, 태국에서 서비스하고 있는 '스마트 채널'입니다. 스마트 채널은 LINE으로 메시지를 주고받을 때 대화 탭 최상단에 일기 예보나 뉴스 등의 콘텐츠를 노출시키는 기능입니다. 사용자가 요청하면 콘텐츠 후보 중에서 각 사용자에게 최적화된 콘텐츠를 실시간으로 계산해서 제공하는데요. 트래픽이 많이 발생하는 서비스이기 때문에 일부 작업을 비동기로 실행하고 이벤트 로그를 수집하기 위해 Decaton을 사용하고 있습니다.
스마트 채널 개발 과정은 【Product Story #3】ユーザー調査とテストを徹底的に繰り返し、反対派も巻き込みローンチに至った「スマートチャンネル」開発プロジェクトの裏側 – LINE ENGINEERING(일본어) 블로그 글을 참고하시기 바랍니다.
작업 큐 구현
Decaton을 이용하면 Kafka를 백엔드로 삼는 작업 큐를 간단하게 구현할 수 있습니다. 스마트 채널에서는 사용자에게 전달되는 콘텐츠를 업데이트하기 위한 작업을 실행할 때 Decaton을 이용하는데요. 사용자에게 전달될 콘텐츠를 사전에 배치(batch)로 가져온 뒤, 가져온 콘텐츠에 업데이트가 발생했을 때 Decaton을 이용합니다.
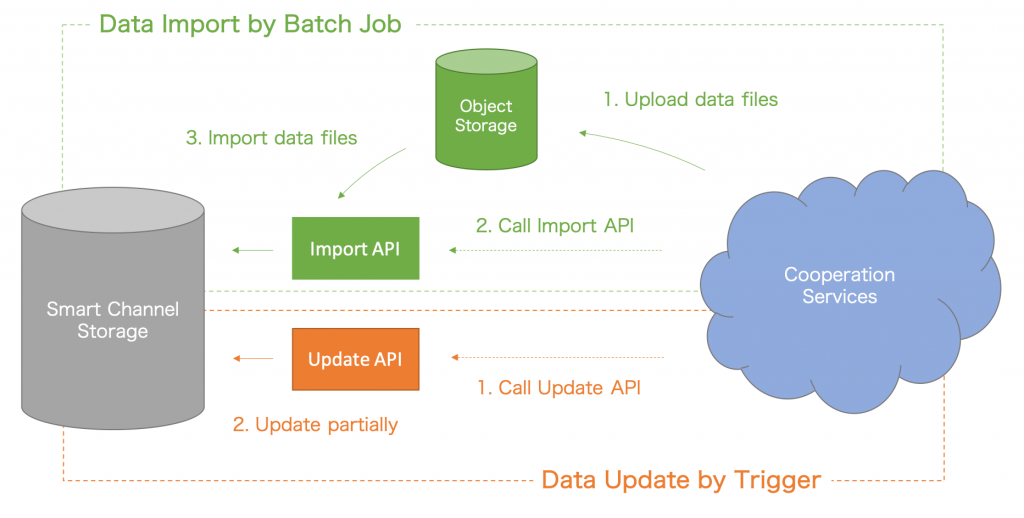
스마트 채널에서는 뉴스나 일기 예보 등을 전달합니다. 관련 콘텐츠는 LINE NEWS 등 스마트 채널과 연계된 각 서비스에서 API로 연동하여 불러옵니다. 콘텐츠가 업데이트되면 스마트 채널 측의 REST API가 실행되는데요. 이때 실제 업데이트를 처리하진 않고 Decaton 작업으로 Kafka에 저장만 합니다. 실제 업데이트 처리는 별도로 준비한 워커 프로세스가 Kafka에 저장된 Decaton 작업을 받아서 진행합니다.

REST API가 호출된 시점에 바로 업데이트를 처리하지 않고 Decaton 작업으로 저장한 뒤에 처리하는 방식에는 몇 가지 장점이 있습니다.
- 일시적으로 접근이 몰리면서 부하가 높아지는 상황을 피할 수 있습니다. 일시적으로 업데이트 작업이 증가하더라도 부하가 쉽게 높아지지 않는 구조이기 때문에 업데이트를 진행하는 REST API가 다운되어 업데이트 자체를 접수하지 못하는 최악의 사태를 막을 수 있습니다.
- 작업(job) 재시도 처리를 추가로 구현하지 않아도 됩니다. Kafka에서는 메시지 전달만 하기 때문에 작업 재시도를 처리하고 싶다면 자체적으로 구현해야 하는데요. Decaton을 사용하면 그럴 필요가 없습니다. Decaton은 재시도용 Kafka topic을 별도로 두고 재시도 작업을 관리하며, 라이브러리 사용자는 이를 딱히 신경 쓰지 않고 하나의 Kafka topic을 처리하는 코드로 작성할 수 있습니다.
- 마지막으로, 단일 Kafka 파티션을 여러 스레드에서 병렬로 처리할 수 있기 때문에 Kafka를 그대로 사용하는 것보다 더욱 효과적으로 작업을 처리할 수 있습니다.
스마트 채널 프로젝트에서는 작업 큐로 Decaton을 사용하면서 이와 같은 장점에 힘입어 신뢰성 높은 프로그램을 만들 수 있었습니다.
이벤트 로그 수집
Decaton에는 어떤 처리를 지정된 시간만큼 지연시킨 후에 실행하는 작업 처리 지연 기능이 있습니다. 스마트 채널에서는 이를 이용해 노출된 콘텐츠에서 발생한 여러 이벤트를 수집하여 어떤 콘텐츠를 내보내는 것이 최적인지 학습하는 데 사용합니다. 이벤트를 바탕으로 학습하기 위해선 노출된 콘텐츠가 최종적으로 어떤 결과를 가져왔는지 파악해야 합니다. 콘텐츠가 노출된 뒤 발생할 수 있는 사용자의 주요 동작으로는 아래 3가지가 있습니다.
- 콘텐츠 노출 → 콘텐츠 클릭
- 콘텐츠 노출 → 콘텐츠 뮤트(닫기)
- 콘텐츠 노출 → 아무것도 하지 않음

1번과 2번 동작은 사용자가 구체적인 액션을 실행하기 때문에 해당 이벤트를 수집하면 바로 파악할 수 있습니다. 하지만 3번 동작은 구체적으로 실행되는 액션이 없습니다. 따라서 어떠한 경우가 3번에 해당하는지 명시적으로 정의할 필요가 있는데요. 여기서는 콘텐츠 표시 후에 10분 동안 아무 액션이 없다면 3번에 해당한다고 정의하겠습니다.
이제 이벤트를 처리하는 방법에 대해 이야기해 보겠습니다. 이벤트를 처리할 때 발생한 이벤트를 어딘가에 저장한 뒤 처리하는 방법을 생각할 수 있는데요. 이때 단순히 이벤트를 저장하는 것만으로는 3번의 경우를 쉽게 판정할 수 없습니다. 또한 저장해야 하는 데이터도 너무 방대합니다. 그래서 스마트 채널에서는 각 동작이 어디에 해당하는지 결정할 때 Decaton의 작업 처리 지연 기능을 활용했습니다. 아래는 Decaton을 이용한 이벤트 수집 아키텍처입니다.

스마트 채널에선 사용자 이벤트가 발생했을 때 HTTPS 요청으로 알립니다. API로 전달된 이벤트는 다시 Kafka로 전달되고, 이후 각 이벤트에 대응하는 워커에서 발생한 이벤트를 처리합니다. 콘텐츠 클릭이나 뮤트 이벤트는 Redis에 저장하고, 구체적 액션이 없는 임프레션(impression) 이벤트는 Decaton의 작업 처리 지연 기능을 활용, 10분 후에 처리할 작업으로 다시 한 번 Kafka에 저장합니다. 임프레션 이벤트는 10분간 지연된 뒤 다시 1번과 2번, 3번 동작 중 어디에 해당하는지 판정받는데요. 클릭이나 뮤트 이벤트에는 고유 ID를 할당하기 때문에 임프레션 이벤트 정보에서 Redis에 저장된 클릭이나 뮤트 이벤트 정보를 조회할 수 있습니다. 따라서 조회한 결과 클릭이나 뮤트 이벤트가 발생하지 않았다면 3번 동작이라고 판정할 수 있습니다. 실제 코드에서는 아래와 같이 Decaton 작업을 생성할 때 얼마나 지연해서 실행할지 지정합니다.
long timestamp = clock.millis(); // Get current UNIX timestamp in milliseconds
Duration delay = Duration.ofMinutes(10L); // Run the task after 10 minutes
TaskMetadata metadata =
TaskMetadata.newBuilder()
.setTimestampMillis(timestamp)
.setScheduledTimeMillis(timestamp + delay.toMillis());
.build()
Task task = new Task(); // Task is a class generated by protobuf.
Serializer<Task> serializer = new ProtocolBuffersSerializer<>();
DecatonTaskRequest taskRequest =
DecatonTaskRequest.newBuilder()
.setMetadata(metadata)
.setSerializedTask(ByteString.copyFrom(serializer.serialize(task)))
.build();
// After creating a Decaton task, submit it to Kafka topic.
producer.send(new ProducerRecord<>("topic", "key", taskRequest));사실 처음에는 위에서 언급한 처리를 Kafka Streams를 이용해서 구현하려고 했습니다. 하지만 조사해 보니 Kafka Streams에서 이와 같은 처리를 효율적으로 구현하는 건 어려웠습니다. 그래서 위와 같이 Decaton과 Redis를 조합해 시도해 본 결과, 간단하게 프로그램을 조합하는 것만으로 목적을 달성할 수 있었습니다. Decaton의 작업 지연 기능은 이번에 소개한 이벤트 수집 외에도 다양한 경우에 적용할 수 있는 편리한 기능이라고 생각하며, 상황에 맞게 잘 활용할 수 있을 것 같습니다.
마치며
이번 글에서는 스마트 채널에서 Decaton을 활용한 사례를 소개했습니다. 현재 스마트 채널에는 Kafka Streams를 사용하고 있는 곳이 많은데요. 재시도 처리를 깔끔하게 할 수 있고 단일 파티션을 여러 스레드에서 병렬 처리할 수 있는 등의 장점을 고려해 순차적으로 바꿔 나가려고 합니다. 폭넓게 활용할 수 있는 라이브러리라고 생각하니 기회가 된다면 오픈소스로 공개된 Decaton을 꼭 한 번 사용해 보시기 바랍니다.