
안녕하세요. LINE에서 클라이언트 보호 솔루션인 AIR ARMOR 개발을 담당하고 있는 정상민입니다. 이전 글, 'iOS 코드 서명에 대해서'에서는 심민영 님이 iOS 앱의 무결성과 서명자를 검증할 수 있는 iOS 코드 서명에 대해서 설명했는데요. 이번 글에서는 앱의 위변조 및 도용 방지를 위해서 자체 개발 중인 난독화 도구를 소개하려고 합니다. 예제 소스 코드를 이용해 컴파일러 동작의 각 단계를 확인하면서 난독화가 어떻게 수행되는지 살펴보겠습니다.
오크(ORK)란?
소프트웨어를 보호하기 위한 법과 제도적인 보호 장치들이 이미 존재하며 정비도 되고 있지만, 기술과 서비스의 발전 속도를 따라오지는 못하고 있습니다. 그래서 앱의 위변조 및 도용 문제를 기술적으로 해결하기 위해서 다양한 시도를 하고 있는데요. 오크 프로젝트도 그런 시도 중 하나입니다.
오크는 LLVM 컴파일러 인프라 기반으로 LINE에서 자체 개발하고 있는 난독화 도구로, 'Obfuscated Representation Kaleidoscope'의 줄임말입니다. C/C++와 같이 LLVM 기반에서 처리할 수 있는 프로그래밍 언어들을 컴파일 단계에서 난독화해 주는 컴파일러 도구입니다.
실행 파일 보호 기술인 패커의 한계
모든 실행 코드는 메모리에 적재되고 중앙 처리 장치(CPU)에서 실행되기 때문에 언젠가는 역공학(reversing, reverse engineering)으로 분석될 수밖에 없습니다. 그나마 다행인 점은, 역공학 과정이 CPU가 실행 코드(instruction)을 직접 처리하는 시간과는 비교할 수 없을 만큼 오래 걸린다는 점입니다. 그래서 실행 코드 보호 기술은 바로 이 '시간'이라는 비용을 높이는 방식으로 개발되고 있는데요. 다양한 기술이 존재하고 상호 보완적으로 사용되기 때문에 어느 하나를 딱 집어 설명하긴 어렵지만, 일반적으로 실행 압축(executable compression) 기술을 많이 사용하고 있습니다.
실행 압축 기술은 원본 실행 코드를 압축된 형태로 저장하고 실행 시점에 메모리에 복원해 실행 흐름을 바꾸는 기술입니다. 이름에서 알 수 있듯이 실행 파일의 크기를 줄이는 압축 기능을 위해 개발되었지만, 원본 실행 코드가 숨겨진다는 부가적인 장점 때문에 실행 파일 보호 기술로 더욱 주목받게 되었습니다. 실행 압축 기술은 세부적인 동작 방식에 따라 여러 가지로 구분하기도 하는데요. 대체로 실행 패커(executable packer) 또는 줄여서 패커(packer)라는 기술로 부르고 있습니다. 아래 이미지는 실행 압축 전후를 나타냅니다.

실행 압축은 어셈블리 언어와 실행 파일 포맷, 링커 등 시스템 전반에 대한 이해가 필요하며, 안정성 확보를 위해 많은 검증 과정을 거쳐야 하기 때문에 구현이 쉽지 않습니다. 그럼에도 컴파일된 실행 파일에 바로 적용할 수 있다는 편리함과 다른 보호 기술을 쉽게 추가할 수 있다는 장점 때문에 실행 코드를 보호하기 위한 기술로 많이 사용하고 있습니다. 그래서 매우 다양한 무료 혹은 상용 실행 패커들이 존재하는데요. LINE에서도 일부 서비스의 실행 코드를 보호하기 위해 자체적으로 실행 패커 기술을 개발해서 사용하고 있습니다.
패커는 매우 효과적인 보호 기술입니다. 하지만, 단점이 있습니다. CPU에서 처리되는 실행 코드는 반드시 메모리에 적재되는데요. 이때 메모리에 적재된 실행 코드가 노출될 가능성이 있으며, 실행 패커의 동작 원리 또한 한 번 파악되면 그다음부터는 보호 효과를 얻기 어렵다는 한계가 있습니다. 이를 보완하기 위해 코드 가상화나 안티-메모리 덤프(anti-MemoryDump) 등의 다른 보호 기술을 함께 사용하기도 하지만, 이런 보호 기술들 역시 비슷한 문제점이 있습니다.
저희는 이런 한계를 효율적으로 극복하기 위해서 소프트웨어 업데이트 주기에 주목했습니다. 특히 게임의 경우 신규 콘텐츠를 공급하기 위한 주기적인 업데이트가 필수인데요. 업데이트할 때마다 매번 다른 형태로 난독화한 실행 코드를 배포하여 이전의 분석 내용을 쓸모없게 만드는 방법으로 실행 파일을 보호하는 것입니다. 이른바 '난독화 생명 주기(obfuscation life cycle)'를 관리하는 방법인데요. 컴파일 시점의 난독화 기술을 적용하면 이것이 가능합니다.
사실 컴파일러를 이용한 난독화는 오래전부터 시도되어 온 발상입니다. 하지만, 구현하는 게 쉽지 않았습니다. 기존 컴파일러는 워낙 방대하고 복잡하기 때문에 구현하기가 어렵고 개념 증명에 사용하기에 적합하지 않았기 때문입니다. 하지만 컴파일러의 구조가 개선되고 발전하면서 가능성이 열렸고, LLVM 컴파일러 인프라(infrastructure)가 등장하면서 개념 증명뿐 아니라 상용 수준의 컴파일러도 쉽게 구현할 수 있게 되었습니다.
LLVM 컴파일러 인프라
LLVM은 컴파일에 필요한 여러 기술과 도구를 모아놓은 컴파일러 프레임워크 프로젝트입니다. LLVM 컴파일러 인프라는 3단계 구조로 되어 있는데요. 각각 구문 분석과 최적화, 기계어(machine code) 생성 역할을 수행하고 있습니다. 이렇게 잘 구조화되어 있는 덕분에 필요한 기능을 컴파일러에 쉽게 추가할 수 있습니다.

LLVM 컴파일러 인프라의 핵심은, 구조적으로 소스(source)와 대상(target)으로부터 독립적인 최적화(optimizer) 기능을 제공한다는 것입니다. 이런 구조는 프로그래밍 언어와 기계어 사이에서 LLVM IR(Intermediate Representation)이라는 중간 언어를 사용하고 있기 때문에 가능합니다. 최적화 단계에선 오직 LLVM IR만을 처리하기 때문에 프로그래밍 언어와 기계어로부터 완전히 독립적이고 투명하게 동작할 수 있습니다. LLVM 컴파일러 인프라는 GNU 컴파일러인 GCC뿐만 아니라 Microsoft 컴파일러인 MSVC와도 호환되기 때문에 LLVM 기반으로 여러 개발 환경을 지원할 수 있습니다. 주요 모바일 플랫폼 개발 도구인 Xcode는 4.2 버전부터, Android NDK는 r13b 버전부터 기존의 GCC를 대신해 LLVM이 기본 컴파일러로 선택되었습니다. 이제 LLVM 컴파일러 인프라는 그 대안을 찾기 어려울 정도이며, 많은 프로젝트가 LLVM을 기반으로 진행되고 있습니다.
LLVM 컴파일러 인프라는 GCC 프론트엔드를 대체해 C/C++ 형식의 프로그래밍 언어를 지원하기 위해서 Clang이라는 하위 프로젝트를 포함하고 있습니다. Clang은 다른 도구 및 컴파일러에 호환성을 제공하는 컴파일러 드라이버(driver)로서의 기능과, C/C++ 형식의 프로그래밍 언어를 해석하는 프론트엔드로서의 기능을 수행합니다.
참고. Clang은 LLVM과 함께 버전이 관리되고 있는 핵심 프로젝트인 만큼, LLVM 컴파일러 인프라를 사용하려면 http://clang.llvm.org에서 관련 내용을 확인해보는 걸 추천합니다.
LLVM 컴파일러 인프라 기반 난독화 도구, 오크
오크 프로젝트는 LLVM 컴파일러 인프라를 기반으로 구현한 공유 라이브러리이며, 소스 코드는 LLVM 프로젝트와 분리, 별도의 프로젝트에서 관리하고 있습니다.
오크는 다음 두 가지 사항에 중점을 두고 프로젝트를 설계 및 구현했습니다.
- 매번 새로운 난독화 결과물 생성
- 기존 개발 환경과 쉽게 통합 가능
난독화 생명 주기에서 가장 중요한 부분은 매번 다른 형태로 실행 코드를 난독화하는 것입니다. 이를 위해서 모든 난독화 기능은 원본 소스 코드의 내용이나 컴파일 시점에 따라서 임의의 분기와 변수, 조건으로 LLVM IR을 변경하거나 추가하도록 설계했습니다. 여기에 기존 프로젝트의 컴파일 설정을 변경하지 않아도 되도록 독립적인 난독화 설정 기능을 제공하고 있습니다. 또한 Xcode나 Android NDK와 같은 개발 환경에 통합하기 위해 필요한 여러 수정 작업을 자동화한 통합 기능을 제공하고 있습니다.


오크는 공유 라이브러리 형태로 빌드하고 있으며, clang 또는 opt 명령어 도구의 실행 시점에 적재되어 동작합니다.
clang -Xclang -load -Xclang libORK.dylib아래 opt 명령어로 오크가 제공하는 난독화 기능을 확인할 수 있습니다.
opt -load libORK.dylib -help오크는 LLVM 컴파일러 인프라를 기반으로 동작하므로 오크를 이해하기 위해선 컴파일 과정을 이해할 필요가 있습니다. 따라서 오크를 살펴보기에 앞서 컴파일 과정을 먼저 살펴보겠습니다.
참고. 난독화 컴파일러의 개념은, 일부 오류가 존재하긴 하지만 오픈 소스로 공개된 Obfuscator-LLVM을 살펴보면 확인할 수 있습니다.
Clang의 컴파일 과정
일반적인 프로젝트에선 통합 개발 환경(Integrated Development Environment, IDE)에서 자동으로 컴파일을 수행하고 관리하기 때문에 각 컴파일 단계를 확인하기 어렵습니다. 그래서 직접 Clang을 사용해서 각 컴파일 단계를 살펴보고 오크가 어느 시점에 난독화를 수행하는지 확인해 보겠습니다.
아래 예제 소스 코드를 이용해 Clang의 컴파일 과정을 살펴볼 건데요. 아래 예제는 피보나치수열을 확인해 주는 프로그램으로, 확인하려는 항과 피보나치 수를 입력하면 정답을 알려주도록 구현되어 있습니다(일부 예외 처리가 부족할 수 있습니다).
#include <stdio.h>
#include <stdlib.h>
int main (int argc, char *argv[]) {
if (3 != argc) {
return 0;
}
const int Question = atoi( argv[1] );
if (Question <= 0) {
return 0;
}
const int Answer = atoi( argv[2] );
// Calculate Fibonacci number
int Prev = 0, Fibo = 1, Temp = 0;
for ( int Index = 1 ; Index < Question ; Index++ ) {
Temp = Fibo;
Fibo = Prev + Fibo;
Prev = Temp;
}
if (Answer == Fibo) {
printf("Correct : %d
", Answer);
} else {
printf("Incorrect : %d != (%d)
", Answer, Fibo);
}
return 0;
}아래 명령어로 예제 소스 코드를 컴파일할 수 있습니다. -v 설정을 추가하면 상세 컴파일 정보가 출력됩니다.
clang test.cpp컴파일된 예제 실행 파일의 제어 흐름 그래프(control flow graph)는 아래와 같습니다.
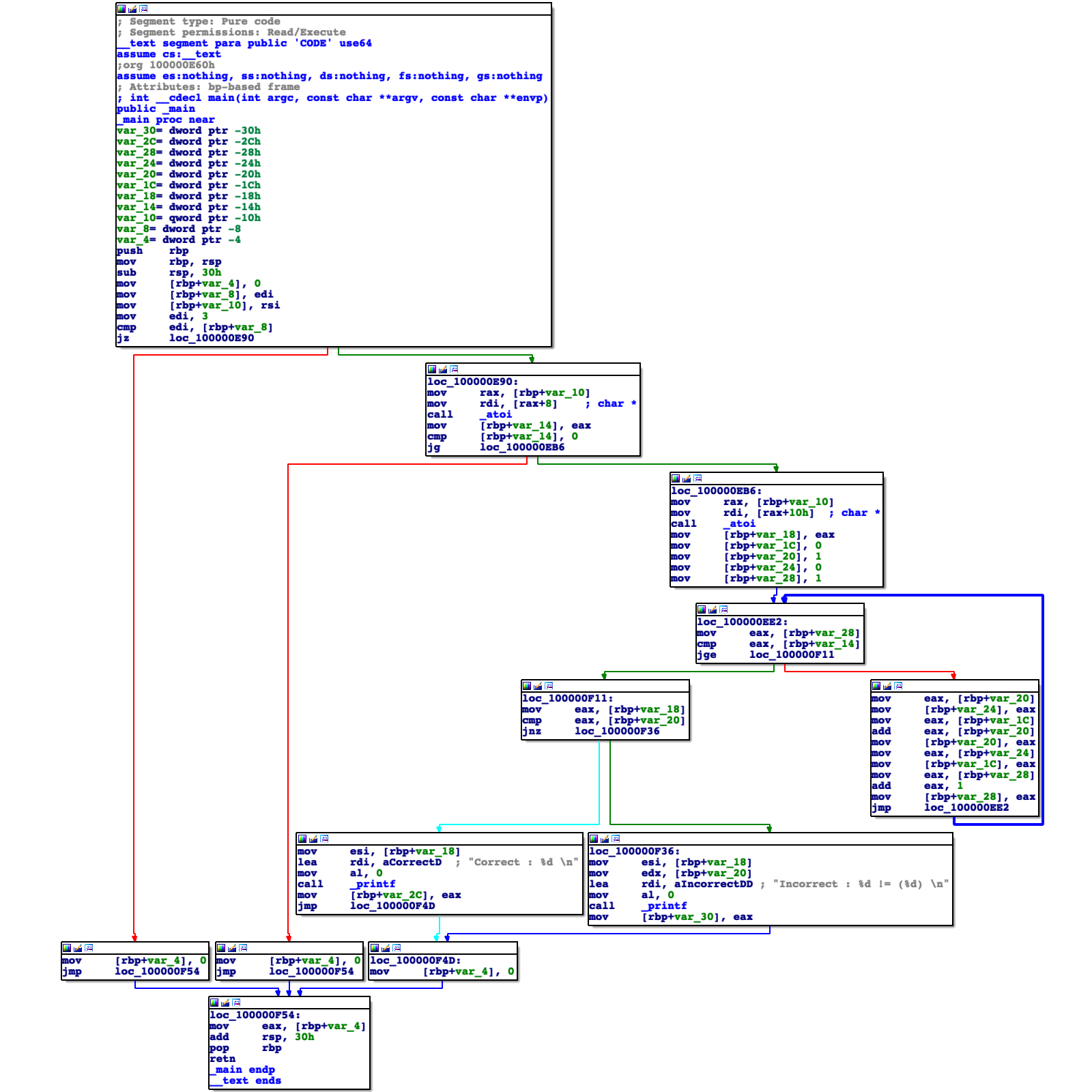
아래와 같이 예제 실행 파일이 정상적으로 실행되는 것을 확인할 수 있습니다.

Clang은 컴파일러 드라이버로 먼저 실행되어 다른 컴파일러와 호환 가능한 설정으로 프론트엔드와 링커를 실행하며 일련의 컴파일 과정을 처리합니다. 이 과정에서 Clang은 C/C++ 형식의 언어를 지원하는 프론트엔드 기능으로도 실행되는데요. clang 명령어 도구에 -cc1 설정을 추가하면 바로 프론트엔드로 실행할 수 있습니다. -### 옵션을 사용하면 프론트엔드를 실행하기 위해 필요한 설정을 미리 확인할 수 있습니다.
clang -### test.cpp
Apple clang version 11.0.0 (clang-1100.0.33.17)
Target: x86_64-apple-darwin19.3.0
Thread model: posix
InstalledDir: /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
"/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/clang" "-cc1" "-triple" "x86_64-apple-macosx10.15.0" "-Wdeprecated-objc-isa-usage" "-Werror=deprecated-objc-isa-usage" "-emit-obj" "-mrelax-all" "-disable-free" "-disable-llvm-verifier" "-discard-value-names" "-main-file-name" "test.cpp" "-mrelocation-model" "pic" "-pic-level" "2" "-mthread-model" "posix" "-mdisable-fp-elim" "-fno-strict-return" "-masm-verbose" "-munwind-tables" "-target-sdk-version=10.15" "-target-cpu" "penryn" "-dwarf-column-info" "-debugger-tuning=lldb" "-ggnu-pubnames" "-target-linker-version" "530" "-resource-dir" "/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/clang/11.0.0" "-isysroot" "/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk" "-I/usr/local/include" "-stdlib=libc++" "-internal-isystem" "/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1" "-Wno-framework-include-private-from-public" "-Wno-atimport-in-framework-header" "-Wno-extra-semi-stmt" "-Wno-quoted-include-in-framework-header" "-fdeprecated-macro" "-fdebug-compilation-dir" "/Users/iwillhackyou/Desktop/test" "-ferror-limit" "19" "-fmessage-length" "186" "-stack-protector" "1" "-fstack-check" "-mdarwin-stkchk-strong-link" "-fblocks" "-fencode-extended-block-signature" "-fregister-global-dtors-with-atexit" "-fobjc-runtime=macosx-10.15.0" "-fcxx-exceptions" "-fexceptions" "-fmax-type-align=16" "-fdiagnostics-show-option" "-fcolor-diagnostics" "-o" "/var/folders/cd/3y8qt76x6sd058d073qwp8cw0000gn/T/test-fa24a6.o" "-x" "c++" "test.cpp"
"/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ld" "-demangle" "-lto_library" "/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/libLTO.dylib" "-no_deduplicate" "-dynamic" "-arch" "x86_64" "-macosx_version_min" "10.15.0" "-syslibroot" "/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX.sdk" "-o" "a.out" "/var/folders/cd/3y8qt76x6sd058d073qwp8cw0000gn/T/test-fa24a6.o" "-L/usr/local/lib" "-lSystem" "/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/clang/11.0.0/lib/darwin/libclang_rt.osx.a"이제 Clang 프론트엔드에서 시작되는 각 컴파일 단계를 살펴보겠습니다. 컴파일은 전처리 → 구문 분석 → LLVM IR → 최적화 → 컴파일러 백엔드 → 어셈블러 → 링커의 순서로 진행됩니다.
전처리(preprocessor)
Clang 프론트엔드가 가장 먼저 수행하는 작업은 소스 코드에서 사용된 #include, #define 등을 확장하는 전처리 과정입니다. 아래 명령어를 실행해 소스 코드의 전처리 결과를 출력할 수 있습니다.
clang -E test.cpp구문 분석(parsing)
구문 분석 단계는 입력된 소스 코드의 구문과 어휘를 분석하고, 분석된 내용을 '추상 구문 트리(AST, Abstract Syntax Tree)'라는 자료 구조 형태로 저장하는 단계입니다. 또한 컴파일 속도를 높이기 위해서 중복 참조되는 헤더 파일이나 모듈에 대한 '미리 컴파일된 헤더(PCH, Precompiled headers)' 또는 '미리 컴파일된 모듈 파일(PCM, Precompiled module files)'을 생성합니다. 입력이 헤더 파일인 경우는 이 단계까지 수행됩니다.
아래 명령어로 확장자가 '.ast'인 AST 파일을 생성할 수 있습니다.
clang -emit-ast test.cpp아래 명령어를 실행하여 생성되는 AST 파일의 정보를 출력할 수 있습니다.
clang -cc1 -ast-dump test.cpp아래 명령어를 사용해 이번 단계의 결과를 출력할 수 있습니다.
clang --precompile test.cppLLVM IR(Intermediate Representation)
LLVM IR 단계는, AST 형태로 저장된 소스 코드를 최적화(optimizer)하기 위해 LLVM IR 형식으로 변환하는 단계입니다. LLVM IR은 모든 고급 언어를 나타낼 수 있는 표현 방식과 타입 확장, 타입 정보를 제공하는 중간 언어입니다.
LLVM의 최적화와 오크의 난독화는 모두 LLVM IR 분석과 생성, 수정, 삭제 과정을 통해서 이루어집니다. 이 과정을 이해하려면 LLVM IR을 구성하는 모듈(module)과 함수(function), 기본 블록(basic block), 명령어(Instruction) 등의 구조적인 측면과 함께, 타입(Type) 요소와 SSA(Static Single Assignment) 등과 같은 기능적인 측면을 이해할 필요가 있는데요. 이와 관련해선 LLVM IR 중간 언어의 명세 페이지를 참고하기 바랍니다.

LLVM IR은 두 가지 형식으로 표현될 수 있는데요. 하나는 사람이 읽을 수 있는 문자열로 표현되는 LLVM 어셈블리 언어(LLVM assembly language) 형식이고, 다른 하나는 바이너리로 표현되는 LLVM 비트코드(bitcode) 형식입니다. LLVM IR을 파일로 저장하면, LLVM 어셈블리 언어 형식은 '.ll' 확장자인 텍스트 파일로 저장되고, LLVM 비트코드 형식은 '.bc' 확장자인 바이너리 파일로 저장됩니다.
아래 명령어를 사용해 LLVM 어셈블리 언어를 컴파일 단계에서 저장할 수 있습니다.
clang -S -emit-llvm test.cpp'.ll' 파일을 열어보면 예제 소스 코드로 생성한 LLVM 어셈블리 언어의 특징을 확인할 수 있습니다.
; ModuleID = 'test.cpp'
source_filename = "test.cpp"
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.15.0"
@.str = private unnamed_addr constant [15 x i8] c"Correct : %d 0A00", align 1
@.str.1 = private unnamed_addr constant [25 x i8] c"Incorrect : %d != (%d) 0A00", align 1
; Function Attrs: noinline norecurse optnone ssp uwtable
define i32 @main(i32, i8**) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i8**, align 8
%6 = alloca i32, align 4
%7 = alloca i32, align 4
%8 = alloca i32, align 4
%9 = alloca i32, align 4
%10 = alloca i32, align 4
%11 = alloca i32, align 4
store i32 0, i32* %3, align 4
store i32 %0, i32* %4, align 4
store i8** %1, i8*** %5, align 8
%12 = load i32, i32* %4, align 4
%13 = icmp ne i32 3, %12
br i1 %13, label %14, label %15
; <label>:14: ; preds = %2
store i32 0, i32* %3, align 4
br label %53
; <label>:15: ; preds = %2
%16 = load i8**, i8*** %5, align 8
%17 = getelementptr inbounds i8*, i8** %16, i64 1
%18 = load i8*, i8** %17, align 8
%19 = call i32 @atoi(i8* %18)
store i32 %19, i32* %6, align 4
%20 = load i32, i32* %6, align 4
%21 = icmp sle i32 %20, 0
br i1 %21, label %22, label %23
; <label>:22: ; preds = %15
store i32 0, i32* %3, align 4
br label %53
; <label>:23: ; preds = %15
%24 = load i8**, i8*** %5, align 8
%25 = getelementptr inbounds i8*, i8** %24, i64 2
%26 = load i8*, i8** %25, align 8
%27 = call i32 @atoi(i8* %26)
store i32 %27, i32* %7, align 4
store i32 0, i32* %8, align 4
store i32 1, i32* %9, align 4
store i32 0, i32* %10, align 4
store i32 1, i32* %11, align 4
br label %28
; <label>:28: ; preds = %38, %23
%29 = load i32, i32* %11, align 4
%30 = load i32, i32* %6, align 4
%31 = icmp slt i32 %29, %30
br i1 %31, label %32, label %41
; <label>:32: ; preds = %28
%33 = load i32, i32* %9, align 4
store i32 %33, i32* %10, align 4
%34 = load i32, i32* %8, align 4
%35 = load i32, i32* %9, align 4
%36 = add nsw i32 %34, %35
store i32 %36, i32* %9, align 4
%37 = load i32, i32* %10, align 4
store i32 %37, i32* %8, align 4
br label %38
; <label>:38: ; preds = %32
%39 = load i32, i32* %11, align 4
%40 = add nsw i32 %39, 1
store i32 %40, i32* %11, align 4
br label %28
; <label>:41: ; preds = %28
%42 = load i32, i32* %7, align 4
%43 = load i32, i32* %9, align 4
%44 = icmp eq i32 %42, %43
br i1 %44, label %45, label %48
; <label>:45: ; preds = %41
%46 = load i32, i32* %7, align 4
%47 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([15 x i8], [15 x i8]* @.str, i32 0, i32 0), i32 %46)
br label %52
; <label>:48: ; preds = %41
%49 = load i32, i32* %7, align 4
%50 = load i32, i32* %9, align 4
%51 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([25 x i8], [25 x i8]* @.str.1, i32 0, i32 0), i32 %49, i32 %50)
br label %52
; <label>:52: ; preds = %48, %45
store i32 0, i32* %3, align 4
br label %53
; <label>:53: ; preds = %52, %22, %14
%54 = load i32, i32* %3, align 4
ret i32 %54
}
declare i32 @atoi(i8*) #1
declare i32 @printf(i8*, ...) #1
attributes #0 = { noinline norecurse optnone ssp uwtable "correctly-rounded-divide-sqrt-fp-math"="false" "darwin-stkchk-strong-link" "disable-tail-calls"="false" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { "correctly-rounded-divide-sqrt-fp-math"="false" "darwin-stkchk-strong-link" "disable-tail-calls"="false" "less-precise-fpmad"="false" "no-frame-pointer-elim"="true" "no-frame-pointer-elim-non-leaf" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="false" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "unsafe-fp-math"="false" "use-soft-float"="false" }
!llvm.module.flags = !{!0, !1, !2}
!llvm.ident = !{!3}
!0 = !{i32 2, !"SDK Version", [2 x i32] [i32 10, i32 15]}
!1 = !{i32 1, !"wchar_size", i32 4}
!2 = !{i32 7, !"PIC Level", i32 2}
!3 = !{!"Apple clang version 11.0.0 (clang-1100.0.33.17)"}아래 명령어로 LLVM 비트코드를 어셈블(assemble) 단계에서 저장할 수 있습니다.
clang -c -emit-llvm test.cppLLVM 어셈블리 언어와 LLVM 비트코드는 표현 형식만 다르고, 서로 간에 자유롭게 전환할 수 있습니다. LLVM 명령어 도구인 llvm-dis를 사용해 LLVM 비트코드를 LLVM 어셈블리 언어로 전환할 수 있으며, 반대로 llvm-as를 사용해서 LLVM 어셈블리 언어를 LLVM 비트코드로 전환할 수 있습니다.
LLVM IR은 opt 명령어로 최적화하거나, llc 명령어로 특정 CPU 아키텍처에 해당하는 기계어를 생성할 수 있습니다.
최적화(optimizer)
최적화와 관련된 작업은 LLVM IR과 함께 최적화 작업을 위한 핵심 구조인 LLVM 패스(pass)라는 단위로 관리합니다. LLVM 패스는 등록된 우선순위에 따라 순차적으로 LLVM IR을 전달받습니다. 각각의 최적화 패스는 전달받은 LLVM IR을 최적화한 뒤, 최적화한 LLVM IR을 그다음 패스로 전달합니다.
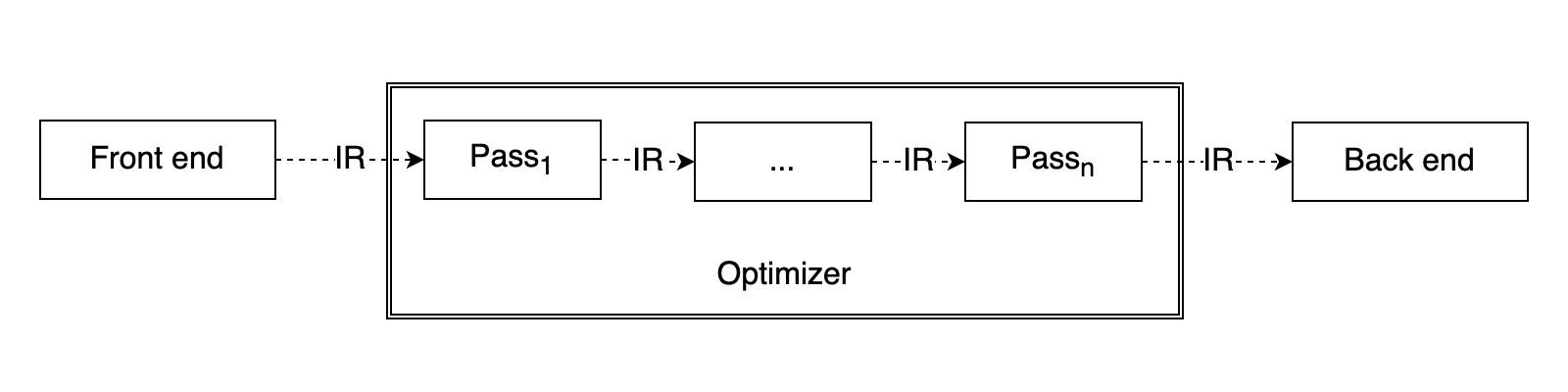
오크의 모든 난독화 기능도 LLVM 패스로 구현했습니다. 최적화 패스와 같이 등록되어 LLVM IR을 난독화하는 구조입니다. 오크의 난독화 패스는 최적화 패스 순서에 영향받지 않고, 중복으로 적용할 수 있도록 구현했습니다.
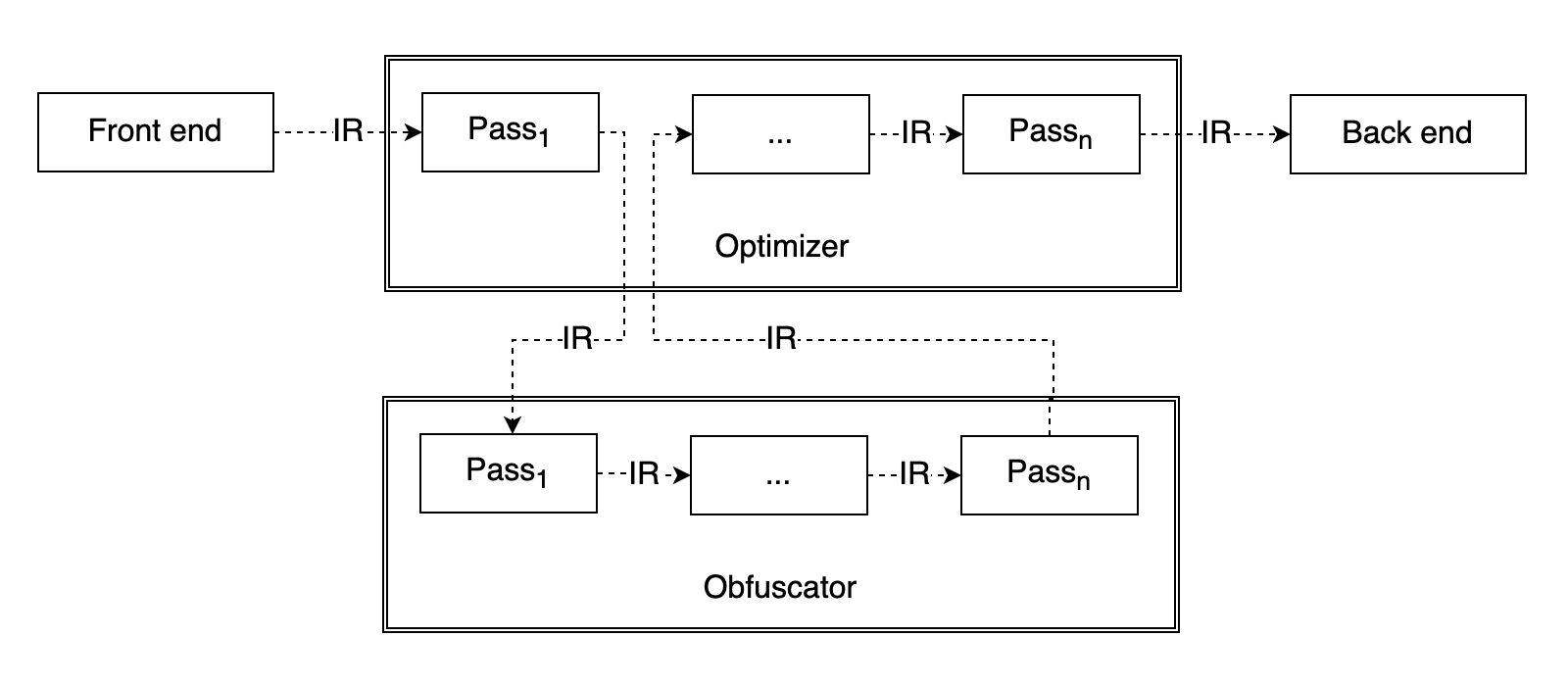
난독화 패스가 최적화 패스에 영향받지 않게 하려면 고려해야 할 요소들이 많이 있습니다. 예를 들어 난독화하기 위해 추가한 가비지(garbage) 코드나 정크(junk) 코드 또는 일부 난독화 로직은 다른 최적화 패스에서 언제든지 제거될 수 있습니다. 그렇기 때문에 해당 난독화 코드가 외부에서 참조되는 것처럼 연결 속성(linkage type)을 지정하는 방법으로 최적화를 우회할 수 있게 고려해야 합니다. 또한 난독화는 소스 코드의 범위를 넘어서는 기능이나 특정 CPU 아키텍처에 밀접한 기능을 구현할 수 없다는 한계도 있는데요. 그럼에도 LLVM의 최적화와 동일하게, 프로그래밍 언어와 기계어에 독립적인 난독화 기능을 제공할 수 있다는 장점만으로도 구현 가치는 충분합니다.
등록된 모든 패스가 수행되면 LLVM IR 최적화가 완료됩니다. 아래 opt 명령어를 사용해서 각 패스에서 수정된 LLVM IR을 출력할 수 있습니다.
opt -O3 -print-after-all test.ll컴파일러 백엔드(compiler backend)
이 단계에선 최적화된 LLVM IR을 특정 CPU 아키텍처에 의존적인 어셈블리(assembly) 언어로 변환합니다. 아래 명령어를 사용해서 확장자가 '.s'인 어셈블리 언어 파일을 저장할 수 있습니다.
clang -S test.cpp저장한 파일은 아래와 같습니다.
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 10, 15 sdk_version 10, 15
.globl _main ## -- Begin function main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
subq $48, %rsp
movl $0, -4(%rbp)
movl %edi, -8(%rbp)
movq %rsi, -16(%rbp)
movl $3, %edi
cmpl -8(%rbp), %edi
je LBB0_2
## %bb.1:
movl $0, -4(%rbp)
jmp LBB0_12
LBB0_2:
movq -16(%rbp), %rax
movq 8(%rax), %rdi
callq _atoi
movl %eax, -20(%rbp)
cmpl $0, -20(%rbp)
jg LBB0_4
## %bb.3:
movl $0, -4(%rbp)
jmp LBB0_12
LBB0_4:
movq -16(%rbp), %rax
movq 16(%rax), %rdi
callq _atoi
movl %eax, -24(%rbp)
movl $0, -28(%rbp)
movl $1, -32(%rbp)
movl $0, -36(%rbp)
movl $1, -40(%rbp)
LBB0_5: ## =>This Inner Loop Header: Depth=1
movl -40(%rbp), %eax
cmpl -20(%rbp), %eax
jge LBB0_8
## %bb.6: ## in Loop: Header=BB0_5 Depth=1
movl -32(%rbp), %eax
movl %eax, -36(%rbp)
movl -28(%rbp), %eax
addl -32(%rbp), %eax
movl %eax, -32(%rbp)
movl -36(%rbp), %eax
movl %eax, -28(%rbp)
## %bb.7: ## in Loop: Header=BB0_5 Depth=1
movl -40(%rbp), %eax
addl $1, %eax
movl %eax, -40(%rbp)
jmp LBB0_5
LBB0_8:
movl -24(%rbp), %eax
cmpl -32(%rbp), %eax
jne LBB0_10
## %bb.9:
movl -24(%rbp), %esi
leaq L_.str(%rip), %rdi
movb $0, %al
callq _printf
movl %eax, -44(%rbp) ## 4-byte Spill
jmp LBB0_11
LBB0_10:
movl -24(%rbp), %esi
movl -32(%rbp), %edx
leaq L_.str.1(%rip), %rdi
movb $0, %al
callq _printf
movl %eax, -48(%rbp) ## 4-byte Spill
LBB0_11:
movl $0, -4(%rbp)
LBB0_12:
movl -4(%rbp), %eax
addq $48, %rsp
popq %rbp
retq
.cfi_endproc
## -- End function
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "Correct : %d
"
L_.str.1: ## @.str.1
.asciz "Incorrect : %d != (%d)
"
.subsections_via_symbols어셈블러(assembler)
어셈블러는 어셈블리 언어를 기계어로 변경해 확장자가 '.o'인 오브젝트(object) 파일로 저장합니다. Clang은 기본적으로 내부에 통합된 어셈블러를 사용하지만, 설정을 통해서 GNU 어셈블러와 같은 외부 도구를 사용할 수도 있습니다.
clang -c test.cpp링커(linker)
링커는 컴파일의 마지막 단계로, 참조 관계를 확인하고 저장된 오브젝트 파일들을 하나로 묶어서 실행(executable) 파일 또는 공유 라이브러리(shared object) 파일을 생성합니다. 이 단계에서 링크 시점 최적화(LTO, Link Time Optimizer)도 수행될 수 있습니다. 호스트 시스템의 링커 외에 다른 링커들도 있는데요. LLVM엔 자체 링커 프로젝트, LLD가 있습니다.
참고. LLVM 명령어 가이드 문서에서 LLVM의 다양한 명령어 도구들을 확인할 수 있습니다. 또한 Clang에서 제공하는 설정은
clang -help또는clang -cc1 -help명령어로 확인할 수 있습니다.
마치며
이번 글에선 예제 소스 코드의 컴파일 과정을 살펴보며 난독화가 실행되는 단계를 확인했습니다. 다음 글에선 오크의 난독화가 어떻게 동작하는지 예제 실행 파일을 통해서 살펴보려고 합니다. 많이 기대해 주세요!