
참고. 이번 블로그는 LINE DEVELOPER DAY 2018에서 Yoshihiro Saegusa 님이 발표한 'LINE's Infrastructure Platform: How It Scales Massive Services and Maintains Low Operational Cost' 세션을 기록한 내용을 각색하여 옮긴 글입니다(원문 기록 및 제공: logmi).
들어가며
안녕하세요. 저는 작년에 LINE 프라이빗 클라우드를 개발하는 부서로 이동해서 현재 인프라 관련 과제를 플랫폼 수준에서 해결하는 역할을 맡고 있는 Yoshihiro Saegusa라고 합니다. 저는 이번 글에서 LINE의 인프라에 관한 이야기를 하고자 합니다.

이야기를 시작하기 전에 우선 제가 이야기하려는 인프라의 범위에 관해 말씀드리겠습니다.
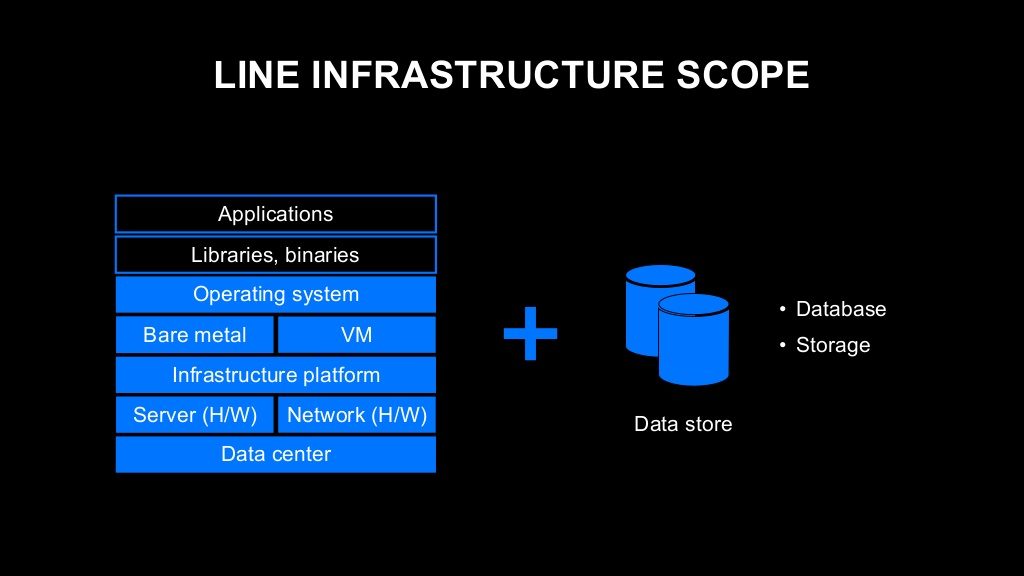
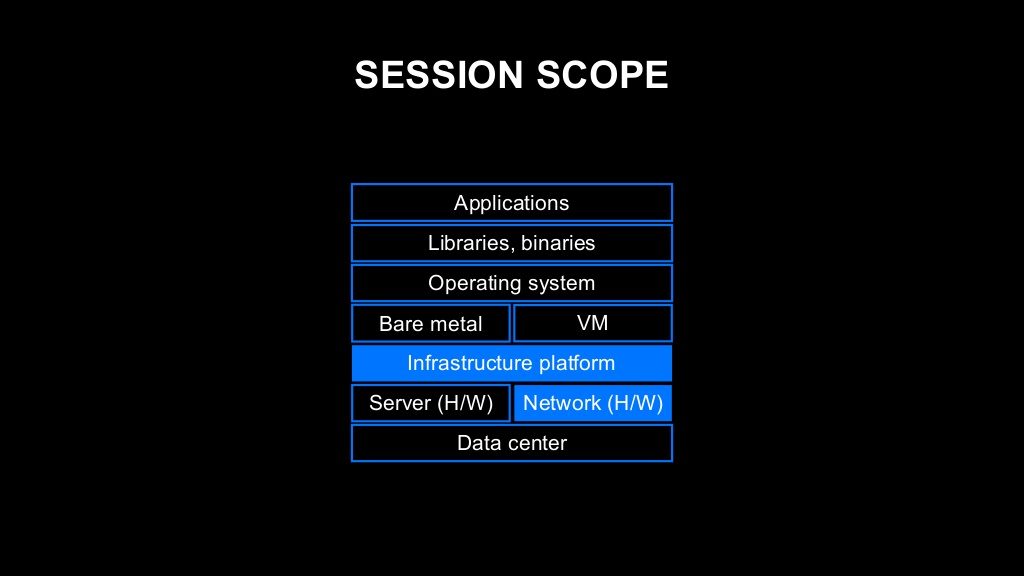
LINE에서는 데이터 센터부터 OS까지의 레이어를 '인프라'라고 합니다. 그리고 데이터베이스, 스토리지 등 데이터 저장 관련 컴포넌트도 인프라 부서에서 운영하고 관리하고 있습니다. 저는 오랜 기간 네트워크 관련 일을 해왔고, 지금은 인프라 플랫폼 관련 일을 하고 있어서 주로 이 2가지 부분에 초점을 맞춰 이야기하겠습니다.
인프라 규모를 확장하면서 발생한 문제
LINE이 출시된 지 벌써 8년이 지났습니다. 당연하지만, 지금까지 다양한 과제에 직면해 왔습니다. 서비스가 성장하면서 인프라의 규모가 확대되었고 이를 서포트하는 엔지니어의 규모와 거점 수도 늘어났습니다. 현재 사용자 트래픽은 1Tbps 이상이고, 데이터 센터의 서버 수는 3만 대를 넘었으며, 약 2,300명의 엔지니어가 전 세계 10개 이상의 거점에서 근무하고 있습니다.

이렇게 규모가 커지면서 발생한 문제를 아래와 같이 크게 3가지로 나눌 수 있습니다. 첫 번째는 수용력(capacity) 부족 문제, 두 번째는 아키텍처 문제, 그리고 세 번째는 운영 비용이 증가하는 문제였습니다. 각 문제를 하나씩 살펴보도록 하겠습니다.

네트워크 수용력 부족과 비효율적인 아키텍처 문제
먼저 네트워크 수용력 문제입니다. 조금 전에 사용자 트래픽 이야기를 했는데요. 실제로 트래픽 규모로는 데이터 센터 안에서 발생하는 서버 간 통신이 압도적으로 많습니다. 따라서 네트워크를 설계할 때 이 데이터 센터 간의 서버 간 통신을 어떻게 처리할지에 주안점을 두어 설계하고 있습니다. 기존 설계에서는 1개의 네트워크 단위로 3,200대의 서버를 수용할 수 있었고, 서버는 1대당 10G 네트워크 인터페이스를 가지고 있습니다. 네트워크 팟(pod) 전체로는 16,000G의 수용력이었는데요. 이를 '2N'이라고 부르는 2대 1세트로 이중화 구성하여 인프라를 제공했습니다. 아래 이미지를 참고하시기 바랍니다.
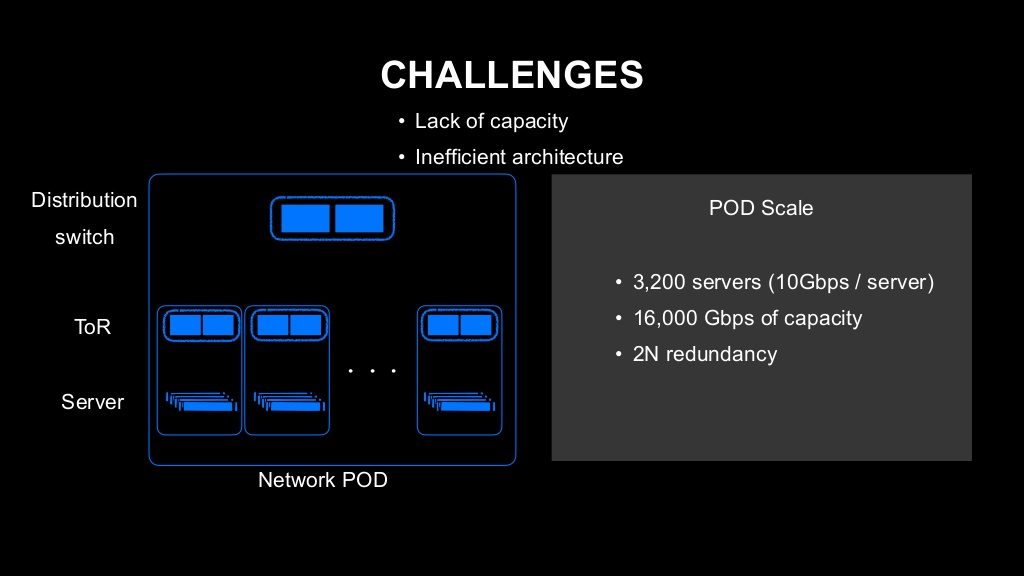
이와 같은 구조에서 10G를 모두 사용하는 서버가 많이 발생하면 구조적으로 네트워크에 병목 현상이 발생하여 통신이 불안정해졌습니다. 그래서 트래픽이 많이 발생하는 서버끼리는 가능한 한 네트워크에서 가까운 곳에 배치하는 방식으로 운영했는데요. 서버 수가 늘어나면서 이런 방식의 운영이 굉장히 힘들어졌습니다.
또 제공해야 하는 네트워크가 늘어나면 그 두 배에 해당하는 네트워크를 구축해야 하는 2N 방식의 아키텍처의 효율도 문제가 있었습니다. 이 아키텍처에서는 16,000G를 제공하려면 32,000G의 네트워크 인프라를 구축해야 합니다.
연결(connetion) 수와 관련된 문제도 있었습니다. LINE을 주로 사용하는 일본, 대만, 태국, 인도네시아 4개국에서 월간 활동 사용자 수는 총 1억 6,400만 명입니다. 그중 일일 활동 사용자의 비율이 79% 이상이므로, LINE 인프라는 항상 몇 천만에 달하는 사용자의 TCP 연결을 동시에 처리해야 합니다. 해당 TCP 연결은 로드 밸런서를 경유해서 '메시징 게이트웨이(Messaging Gateway)'라고 불리는 서버에 할당됩니다. 하나의 TCP 연결은 같은 서버에 할당해야 통신이 이루어지기 때문에 로드 밸런서는 이를 구현하기 위해 세션 테이블이라고 불리는 것을 관리하고 있습니다. 이 세션 테이블을 어떤 식으로 관리하며 확장해 나갈 것인지가 로드 밸런서 운영의 핵심입니다. 세션 테이블의 크기는 로드 밸런서의 각 노드 메모리의 크기에 좌우됩니다. 메모리 크기는 한정되어 있으므로 세션 테이블의 용량도 한정적입니다. 따라서 세션 테이블 적재 용량을 초과해 버리면 그 테이블에 해당하는 통신은 이루어지지 않기 때문에 LINE 사용자가 일부 서비스를 사용할 수 없는 상황이 발생합니다.

이를 피하고자 로드 밸런서를 여러 개 나열하여 용량을 확보합니다. 로드 밸런서는 DSR(Direct Server Return)이라고 불리는 방식으로 운영됩니다. DSR 방식에선 클라이언트에서 서버로 가는 통신만 로드 밸런서를 경유하고 서버에서 클라이언트로 되돌아오는 통신은 경유하지 않습니다. 위 이미지를 참고해주시기 바랍니다. 보통 클라이언트에서 서버로 향하는 트래픽이 서버에서 되돌아오는 트래픽에 비해 적습니다. 따라서 적은 트래픽에 맞춰서 로드 밸런서의 용량을 설계할 수 있는 장점이 있습니다만, 단점은 아까 설명드린 세션 테이블을 섬세하게 제어하기 어렵다는 점입니다. 예를 들어 LINE 사용자가 많이 이용하는 통신 사업자 측에 큰 장애가 발생하거나 LINE 사용자 자체에 문제가 발생하면, LINE 클라이언트가 서버와 통신하려고 TCP 연결 재시도를 많이 발생시킵니다. 이러한 통신 재시도 하나하나가 로드 밸런서의 세션 테이블에 적재되고, 이런 상황이 지속되면 결국에는 로드 밸런서 세션 테이블의 용량을 초과하는 일이 발생하기 쉽습니다.
운영 비용 증가 문제
다음 문제는 개발자의 수와 거점의 증가에 관련된 문제입니다. LINE에는 각 인프라 레이어에 해당 레이어를 전담으로 담당하는 인프라 팀이 있습니다. 이전에는 개발자가 애플리케이션을 운영 환경에 배포하고 싶을 때 각 인프라 팀에 요청하는 방식으로 진행했습니다. 이 방법은 개발자 수가 적고 거점도 많지 않았을 때는 괜찮았는데요. 개발자가 2,000명 이상으로 늘어나자 문제가 발생했습니다. 모든 개발자가 어떤 인프라 팀에 어떤 요청을 어떻게 전달하면 내가 원하는 인프라 리소스를 얻을 수 있는지를 이해하고 학습해야 했는데요. 그 학습 비용이 매우 부담스러웠습니다. 또한 2,000명의 개발자가 보내오는 요청을 처리하는 운영자의 부담도 나날이 증가했습니다.

문제 해결 방법
앞서 설명한 문제를 어떤 방식으로 접근해서 해결했는지 설명하기 전에, 저희가 문제를 해결할 때 기준으로 삼은 2가지 원칙을 소개하겠습니다.

첫 번째로 문제를 근본적으로 해결해야 합니다. 표면적인 대처는 하지 않습니다. 필요하다면 아키텍처 수준에서 대처하고 개선합니다. 두 번째로 운영 부하를 줄일 수 있어야 합니다. 설령, 충분히 큰 수용력을 가진 인프라가 구축되고 그 인프라가 대단히 효율적인 구조라고 하더라도, 운영이 어렵고 번거롭다면 적극적으로 채택하진 않을 생각이었습니다.
이렇게 문제를 근본적으로 해결하면서 운영 부하를 줄이는 것을 과제 해결의 원칙으로 삼았는데요. 이런 관점에서 문제 해결의 기본적인 3가지 요건을 정했습니다.

첫 번째는 향후 수용력 문제로 고민하지 않도록 압도적인 수용력을 제공하는 것입니다. 두 번째는 2N 방식이 아니라 N+1로 스케일 아웃이 가능하도록 구현하는 것입니다. 마지막으로 세 번째는 운영 비용을 줄이는 것입니다. 이 기본적인 요건을 바탕으로 각 문제를 해결한 방법을 말씀드리겠습니다.
네트워크 수용력 부족과 비효율적인 아키텍처 문제 해결 방법
일단 병목 현상이 없는 네트워크를 만들고자 했습니다. 모든 서버가 10G의 트래픽을 다 사용해 버리더라도 원리적으로 막히는 곳이 없는 네트워크를 구축하고자 했습니다. 이를 구현하려면 아키텍처 수준에서 개선이 필요했습니다.

새로운 아키텍처 채택
기본이 되는 아키텍처는 타사에서 대규모 데이터센터 네트워크를 구축할 때 채택한 사례가 있는 Clos network로 정했습니다. Clos Network는 모든 네트워크 레이어에서 N+1로 스케일 아웃이 가능한 아키텍처입니다. 다음으로 운영 부하를 줄이기 위해 Clos Network를 화이트박스 스위치를 이용해서 구현할 수 없을지 고민했습니다. 화이트박스 스위치는 리눅스 기반의 OS에서 작동되기 때문에 스위치 관리 방식을 서버 관리와 같은 기법으로 전환할 수 있습니다. LINE에서는 이미 수만 대 규모의 서버를 관리하는 기법이 확립되어 있어서, 화이트박스 스위치를 이용하면 그 기법을 활용할 수 있을 거라고 생각했습니다.
마지막까지 네트워크 디자인 부분에서 고민한 게 이 서버를 수용하는 ToR 스위치와 서버 간의 네트워크 구성이었습니다. LINE에서는 ToR 스위치를 이중화했습니다. 기존 방법은 L2로 서버와 ToR를 연결하는 방법이었지만, 아래와 같이 L3로 연결하는 방법도 고려해 보았습니다.

이 2가지 방법의 결정적인 차이는 유지보수의 용이함입니다. L2로 연결하면 ToR 스위치를 'graceful'하게 전환할 수 없습니다. 전환할 때 반드시 패킷 손실(packet loss)이 발생합니다. 반면 L3로 연결하면 라우팅 기술을 사용해서 스위치 조작만으로 ToR 스위치 간의 'graceful failover'를 구현할 수 있습니다. 이런 점이 굉장히 매력적이어서 L3로 연결하는 방법으로 검토했습니다. 이 방법을 선택하면 서버의 네트워크 구성을 변경해야 했습니다. 그런데 이런 변경이 애플리케이션에 영향을 주어서는 안되겠죠. 그래서 개발자의 협조를 받아 주요 애플리케이션을 테스트해 본 후에, L3로 연결하여 화이트박스 스위치를 사용하는 Clos Network를 채택하기로 결정했습니다.
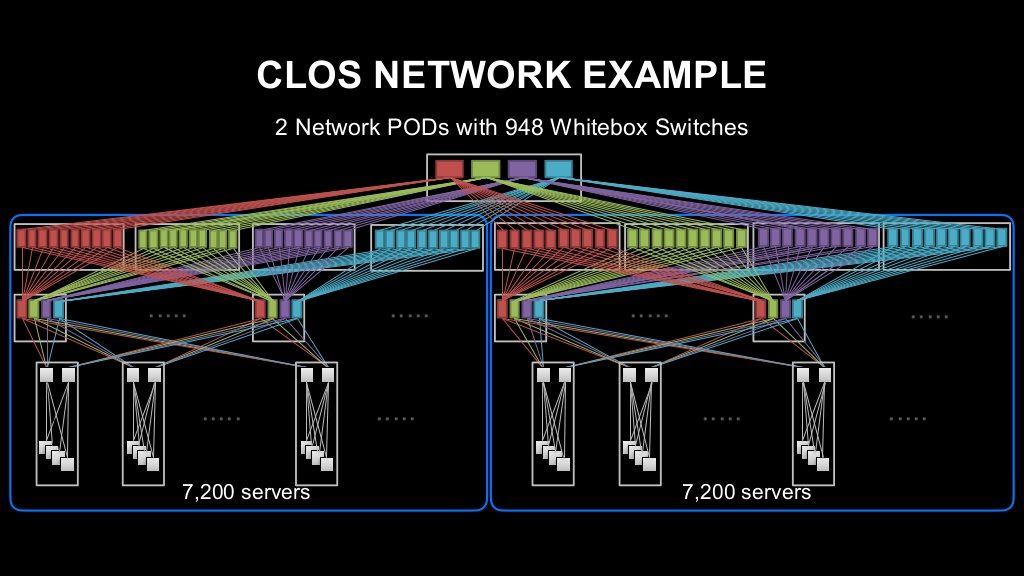
아래 그림은 실제로 한 사이트에서 동작하고 있는 Clos Network 구성입니다. 하나의 팟 당 서버 7,200대를 수용할 수 있고, 서버 7,200대 전부에서 10G의 트래픽이 발생한다고 해도 병목 현상이 없는 네트워크입니다. 이런 팟이 2개 있고, 총 948대의 화이트박스 스위치로 구성되어 있습니다. Clos Network라면 이 정도 규모의 인프라로 충분히 확장할 수 있습니다.
새로운 로드 밸런서 개발
로드 밸런서 문제와 관련해서도 아키텍처 차원에서 개선을 시도했습니다. 기본적인 아키텍처는 L3, L4, L7의 Multi-Tier 구성으로 생각했습니다. 여기서 L7은 위에서 설명드린 메시징 게이트웨이가 위치하는 곳입니다.
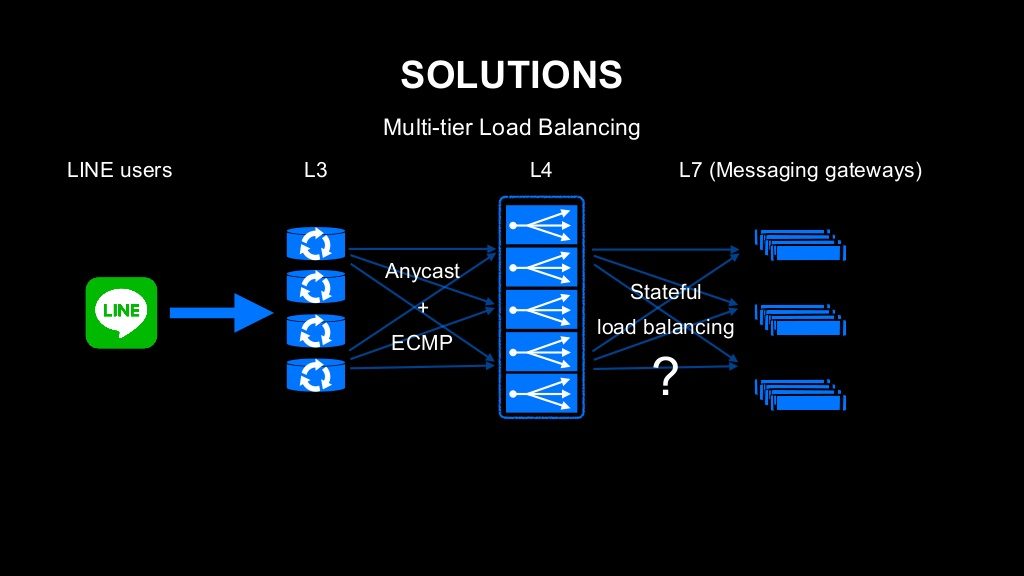
각 레이어에서 N+1로 스케일 아웃이 가능하도록 구현하려고 했습니다. L3에선 ECMP(equal-cost multi-path routing)와 Anycast와 같은 라우팅 기술을 사용하면 N+1로 쉽게 분산할 수 있습니다. 고민되는 쪽은 L4 레이어였는데요. 기존과 같이 상태 기반(stateful) 방식으로 진행하면 유지보수할 때 사용자 영향을 줄이기 위해 모든 L4 노드가 같은 세션 정보를 가지고 있어야 합니다. 그렇지 않으면 사용자에게 영향을 끼치게 됩니다. 모든 L4 노드가 모든 정보를 가지고 있는 건 세션 테이블의 크기가 한정적인 것을 생각하면 전혀 현실적인 방법이 아닙니다. 따라서 무상태(stateless) 방식으로 개선할 수 없을지 고민했습니다. 하나의 TCP 흐름를 판별하려면 소스 IP 주소 정보, 목적지 IP 주소 정보, 소스 포트 번호, 목적지 포트 번호, 그리고 프로토콜 번호까지 총 5가지의 데이터가 있으면 됩니다. 따라서 이 5가지 데이터를 기반으로 해시를 계산해서 그 해시값으로 서버를 할당하면, 같은 TCP 연결은 같은 서버에 할당될 것으로 생각했습니다. 그리고 L4 노드가 모두 같은 해시 알고리즘으로 동작한다면, 유지보수할 때 사용자에 끼치는 영향을 줄일 수 있습니다.

이제 남은 문제는 L4 노드의 성능이었습니다. 압도적으로 좋은 성능을 제공한다는 요건에 기반해 L4 노드의 성능 요건을 '1초에 700만 패킷을 처리할 수 있는 능력'으로 정했습니다. L4 노드는 비용이나 운영 관점에서 리눅스 서버에서 작동하는 소프트웨어로 구현했습니다. 다만, 일반적인 리눅스 커널의 네트워크 스택으론 1초에 700만 패킷은 너무 큰 부하라서 구현이 어렵다는 것을 알게 되었습니다. 그래서 패킷을 고속으로 처리하기 위한 방법을 고민했는데요. 마침 그 시점에 리눅스 커널에 XDP(eXpress Data Path)라고 불리는 기능이 추가되었습니다. XDP는 일반적인 리눅스 네트워크 스택으로 패킷이 넘어가기 전에 NIC(Network Interface Controller) 드라이버 단계에서 직접 패킷을 고속으로 처리할 수 있는 기능입니다. 이걸 이용하면 원하는 성능 요건을 달성할 수 있지 않을까 싶어서 XDP를 이용한 테스트를 시작했고, 1초 동안 700만 패킷이라는 처리 능력을 어렵지 않게 달성할 수 있다는 걸 알게 되었습니다. 그래서 'XDP를 사용한 소프트웨어 기반 무상태(stateless) 로드 밸런서'를 개발했습니다. 이 로드 밸런서는 작년 8월에 운영 환경에 적용 완료했고, LINE 광고 플랫폼에서 실제로 사용하고 있습니다.
운영 비용 증가 문제 해결 방법
마지막 문제는 개발자와 거점 수가 증가하면서 LINE 인프라 사용자의 사용 비용과 운영자의 운영 비용이 증가하고 있다는 문제였습니다.

이를 해결하기 위해 '인프라 플랫폼'이라는 레이어를 추가해서 인프라 자동화를 진행하는데요. 나아가 개발자가 인프라를 불필요하게 많이 신경쓰지 않도록 API와 웹 UI를 이용해서 인프라를 운영하는 방식으로 접근했습니다. 극단적으로 말하면, LINE 인프라를 프라이빗 클라우드화한 것입니다. 이런 프라이빗 클라우드를 사내에서 'Verda'라는 이름으로 개발했습니다(Verda에 대한 자세한 내용을 알고 싶으신 분은 슬라이드와 영상을 참고하시기 바랍니다). 여기선 Verda가 사용자가 필요 이상으로 인프라를 신경쓰지 않게 만드는 구조를 어떻게 구현했는지 소개하려고 합니다.
먼저 VM을 여러 개 배치해서 그에 대해 로드 밸런서의 VIP(Virtual IP)를 할당하는 경우를 생각해 봅시다.
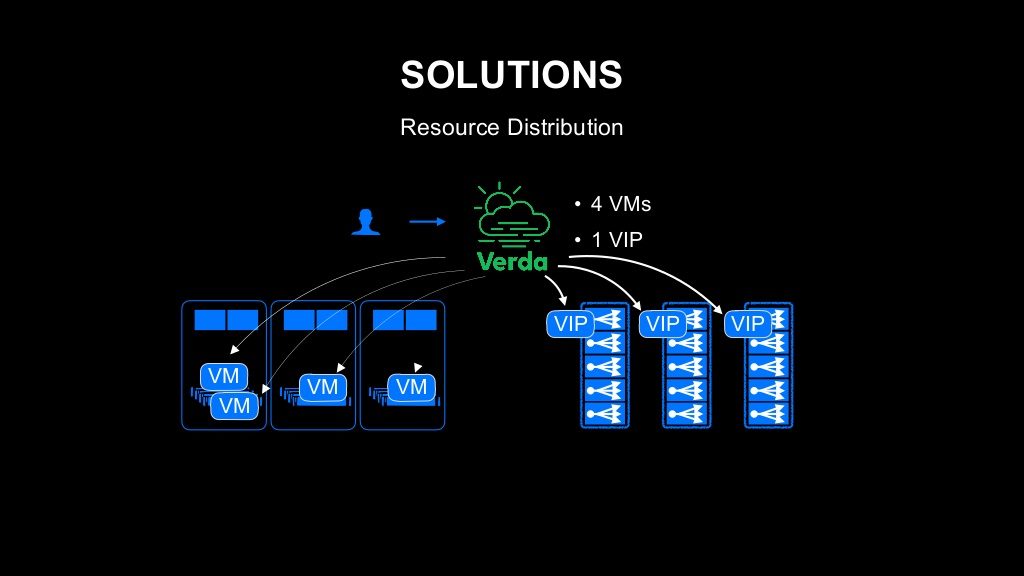
VM을 여러 대 배치할 때 1개의 장애 도메인에 배치해서는 의미가 없습니다. 여러 대의 VM을 여러 장애 도메인에 분산해서 배치해야 합니다. 기존에는 이런 운영을 인프라 운영자가 개발자 요청을 받아서 요청 내용을 보고 어떤 방식으로 배치할지 결정했습니다. 이런 운영을 Verda를 통해서 개발자에게 그대로 해달라고 하면 단순히 운영 주체를 교체하는 것에 불과하므로, Verda 플랫폼의 로직으로 구현했습니다. 이를 통해 개발자는 관련해서 전혀 신경쓸 필요 없이 적절하게 배치된 인프라 자원을 손에 넣을 수 있는 구조가 되었습니다. 로드 밸런서도 마찬가지입니다. VIP를 여러 로드 밸런서 클러스터에 분산해서 배치하면, 로드 밸런서에 대한 가용성이 높아집니다. 이것도 개발자가 일부러 신경써서 운영하는 게 아니라 Verda 플랫폼에서 알아서 운영해 주는 구조입니다.
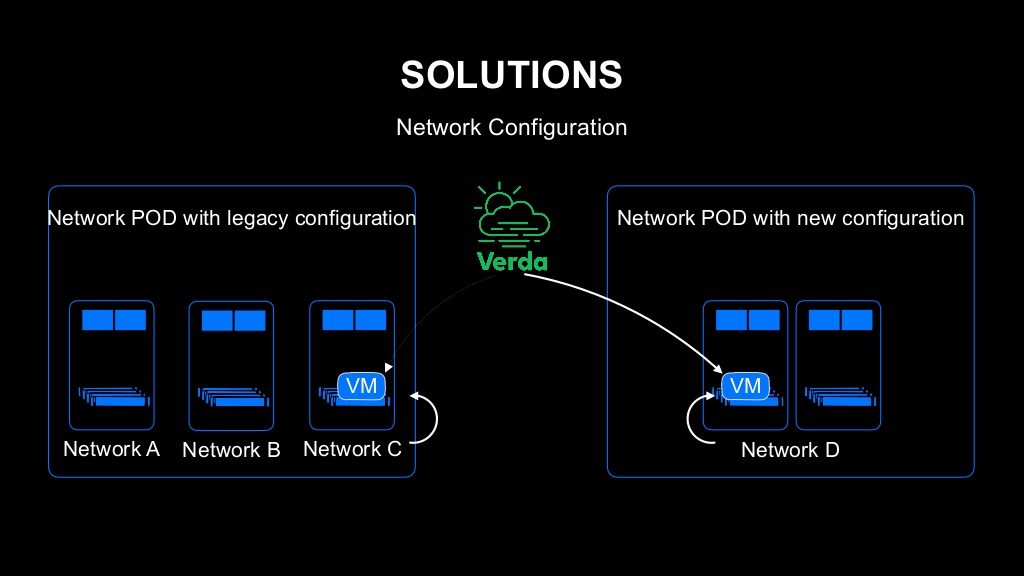
네트워크 설정에 관해서도 완전히 동일한데요. 기존의 오래된 아키텍처의 네트워크와 새로운 아키텍처의 네트워크는 설정이 다릅니다. 이걸 사용자가 오래된 네트워크에 배치되었으니깐 그쪽 네트워크 설정을 적용해야 한다고 판단한다면, 굉장히 이용 비용이 많이 드는 인프라가 될 것입니다. 이 부분 역시 개발자가 전혀 신경쓰지 않아도 VM 네트워크가 알아서 설정되도록 만들었습니다.
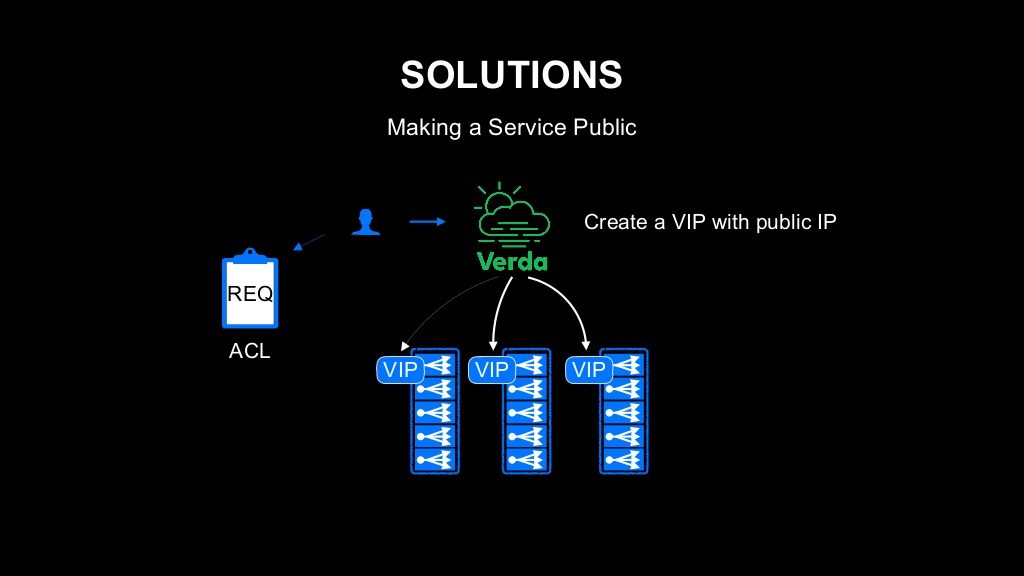
그런데 반대로 인프라에 신경쓰도록 만들어야 하는 부분도 있습니다. 외부에 서비스를 공개할 경우가 이에 해당합니다. 따라서 로드 밸런서의 VIP를 단순하게 글로벌 IP, 퍼블릭 IP로 설정하는 것만으로는 외부에 서비스가 공개되지 않도록 되어 있습니다. 사용자가 이 서비스는 외부에 공개한다는 요청을 한 뒤, 필요한 승인 과정을 통과한 후에야 외부에 공개됩니다. 이를 통해 의도치 않게 내부 대상 서비스가 외부에 공개되는 것을 막을 수 있습니다.
인프라 개선 과정에서 힘들었던 점
지금까지 인프라 규모가 확장되면서 발생했던 문제와 관련 대처 사례를 소개해 드렸습니다. 이렇게 말로만 하면, 굉장히 순조롭게 문제를 해결한 듯이 들릴 수 있겠지만 실제로는 전혀 그렇지 않았습니다. 고생이 끊이질 않았습니다.
가장 고생했던 부분은 문제 해결에 수반되는 변화였습니다. 지금까지 해왔던 방식을 그대로 적용해서는 문제를 해결할 수 없습니다. 네트워크 운영 부하를 줄이기 위해 화이트박스 스위치를 사용한 네트워크를 도입하려면 그때까지 사용하던 네트워크 운영 방식을 바꿔서 서버를 관리하는 방식의 기법으로 바꿔야 합니다. 인프라 플랫폼 단계에서 진행한 자동화도 기존 업무의 부분적인 자동화뿐 아니라 전체적으로 일관된 정책을 가진 소프트웨어 시스템으로 재구축할 필요가 있었습니다. 어떤 것이든 그때까지 하던 방식으로 성취할 수 있는 것은 없습니다. 매우 큰 변화가 필요합니다. 그런 변화를 톱다운 방식으로 무조건 따르게 진행할 수도 있습니다만, 그런 방식은 단기적으로는 잘 통할지 몰라도 언젠가 반발을 초래하게 됩니다. 실제로 이번 프로젝트를 진행하는 과정에서 몇 번이고 그런 경험을 했습니다. 큰 변화를 추구할 때는 목표를 명확하게 설정하고, 그 목표에 모두 공감할 수 있게 충분히 설명하고 하나하나 관련된 일을 차근차근 진행하는 것이 중요하다는 것을 경험했습니다.
또 한 가지는 시점인데요. 아키텍처 수준의 큰 규모로 개선을 진행할 때는 라이프사이클에 맞춰서 도입하는 것이 굉장히 중요합니다. 특히 인프라는 하드웨어도 관련되어 있기 때문에 이 라이프사이클이 굉장히 깁니다. 짧아도 3년이고, 데이터센터 같은 경우엔 10년, 15년도 흔합니다. 개선 시점을 놓치면 다음 기회는 먼 훗날이 되어버립니다. 따라서 시점을 놓치지 않는 것이 매우 중요한데요. 새로운 기술이나 새로운 접근을 적용하기 위해선 요소 기술 연구와 필요한 인재 육성, 혹은 인재 채용 등 하루 아침에 되지 않는 일이 많이 필요합니다. 문제 해결 시점을 놓치지 않기 위해서 평소에 이런 기본 바탕을 만들어 나가는 노력 역시 대단히 중요하다는 걸 이번 프로젝트를 통해서 배웠습니다.
마치며
여기까지 LINE의 대처 사례를 소개했습니다. 간단히 정리하자면, 네트워크 문제와 관련해서는 Clos Network와 Multi-Tier의 로드 밸런서라는 아키텍처 수준의 개선을 진행했습니다. 그리고 Verda라는 플랫폼에선 사용자와 운영자 모두의 부담을 줄여나가려고 노력하고 있습니다.
아직 개선해야 할 부분과 해결해야 할 문제가 많이 있습니다. 이를 해결하기 위해 근본적인 수준에서 운영 부하를 줄인다는 원칙 아래 끊임없이 도전해 나가고 있다는 사실이 여러분께 조금이라도 전해지면 좋겠습니다. 긴 글 읽어주셔서 감사합니다.