
들어가며
LINE에서는 개발자가 개발에만 집중할 수 있도록 개발 외의 인프라 관련 업무를 대신 수행해 주는 Kubernetes 기반 서비스 Nucleo를 자체 개발하여 LINE 내부용으로 사용하고 있습니다. Nucleo에는 현재 800여 개의 앱이 약 4,000개의 pod로 서비스되고 있는데요. 앱의 개수는 계속 빠르게 증가하고 있습니다. 모든 워크로드는 개발 구역(region)에 약 60대, 운영 구역에 약 80대가 설치된 PM(physical machine)과 VM(virtual machine)으로 운영하고 있으며, 그 외에 Nucleo 개발용 클러스터가 약 3~40개, feature 테스트용 노드 3개로 이루어진 미니 클러스터 약 20~30개 가량이 구동되고 있습니다. 이렇게 다수의 Kubernetes 클러스터를 운영하기 위해서는 빠르고 안정적으로 Kubernetes 클러스터를 설치하고 운영할 수 있는 방법이 필요한데요. 그래서 Nucleo 팀에서는 Kubernetes 클러스터 프로비저닝을 목적으로 'Caravan'이라는 도구를 개발하여 사용하고 있습니다. 최근에 팀에서는 이 Caravan이 앞으로 늘어날 앱의 수요에 대응할 수 있는지 알아보기 위해 많은 양의 Kubernetes 클러스터를 생성하고 테스트해 보았는데요. 이번 글에선 이 테스트의 상세한 내용과 테스트를 통해 배운 점에 대해 설명하겠습니다.
Caravan이란?
Caravan은 그간 Nucleo 서비스를 개발하고 운영하면서 얻은 노하우를 표준화한 Kubernetes 클러스터 프로비저닝 서비스입니다.
Nucleo에서는 새로운 커밋이 생성될 때마다 Kubernetes 클러스터에서 통합 테스트를 수행합니다. 각 통합 테스트는 Kubernetes 클러스터에 새로운 API를 생성하거나 기존의 배포를 삭제하는 등의 변경을 수반하기 때문에 테스트 이후의 Kubernetes 클러스터는 테스트 이전과 다른 상태값을 갖게 됩니다. Caravan에선 이러한 snowflake 문제를 별도의 클러스터를 사용해 각 커밋이 생성될 때 통합 테스트를 수행하고 테스트 후 상태값이 변경된 클러스터를 삭제하는 방식으로 해결했습니다.
Caravan phase 1
최초의 Caravan은 여러 테스트용 Kubernetes 클러스터의 풀(pool)을 유지하려는 목적이었습니다. 풀 내의 클러스터는 테스트가 시작할 때 할당되고, 테스트가 끝나고 일정 시간이 지난 후 자동으로 삭제되었습니다. Kubernetes 클러스터 프로비저닝에는 Rancher를 사용했는데요. Rancher에 IaaS(Infrastructure as a service) 서비스용 노드 템플릿을 만들고, 이 노드 템플릿으로 클러스터를 만들었습니다. 그리고 유휴 클러스터 풀의 개수를 유지하기 위해 10분 주기로 구동되는 cron job을 사용하였습니다.
그런데 Rancher를 사용하다 보니 몇 가지 문제점이 발견되었는데요. 그중 가장 큰 문제는 RKE를 사용한다는 점이었습니다. Rancher는 Docker Machine 기반의 RKE를 사용하여 클러스터를 생성하며, RKE는 Docker Machine 드라이버를 만들어서 확장할 수 있습니다. 하지만 팀 내 차기 Kubernetes 아키텍처에서 container runtime으로 containerd를 사용하기로 결정하면서, Docker만 사용할 수 있는 RKE의 확장성이 문제가 되었습니다.
또한, Rancher의 기본 설계상 모든 클러스터에는 하나의 cattle-cluster-agent가 설치되며, 클러스터의 모든 노드에는 cattle-node-agent가 설치되는데요. 이 두 에이전트는 'secure WebSocket'(WebSocket over TLS)을 통해 중앙 Rancher로 클러스터의 상태를 보고합니다(이 구조는 kubelet이 kube-apiserver로 노드의 상태를 보고하는 방식과 유사합니다). 이때 Rancher에 다수의 하위 클러스터나 다수의 노드를 갖는 대형 클러스터를 생성할 경우, 수많은 에이전트가 보내는 보고를 처리하는 과정에서 Rancher 서버에 지나친 부하가 발생하여 실제로는 문제가 없는 클러스터를 문제가 있다고 판단하고 Kubernetes API 요청에 오류를 반환하는 경우가 자주 발생하는 문제점이 있었습니다.
Rancher를 사용하면 손쉽게 Kubernetes 기반의 클러스터를 만들 수 있으며, 추가로 AuthNZ, Catalog, CI 등의 다양한 부가 기능을 사용할 수 있습니다. 그러나 이런 간편한 API와 여러 기능이 정작 팀에 필요했던 안정성과 확장성에 비해 큰 장점이 되지 못했고, 오히려 이런 다양한 기능을 지원하기 위해 코어 기능의 안정성이 희생되고 개발이 지체되는 느낌을 받았습니다. 그래서 저희는 안정적이고 확장 가능한 클러스터 관리 도구를 직접 개발하기로 결정했습니다.
Caravan phase 2
Caravan phase 2의 목적은 확장 가능하고 안정적인 클러스터 프로비저닝이었으며, 최종적으로 kubeadm과 ansible, CRD를 조합하는 형태의 솔루션으로 개발하게 되었습니다. 실제 솔루션의 목적에 가장 부합하는 프레임워크는 Kubernetes 클러스터 API였는데요. Phase 2개발 시점에는 아직 OpenStack 표준 구현체(implementation)가 개발 단계여서 이 부분을 별도로 구축하였습니다.
Kubeadm은 Kubernetes의 공식 설치 도구입니다. 확장성이 뛰어나며 지속적으로 개발되고 있습니다. 또한 ansible은 절차적이라는 특성상 선언적인 terraform보다 snowflake 문제에 더 취약하지만, 기존에 사용하던 ansible playbook을 재활용하기 좋고 팀 내 엔지니어들의 숙련도가 더 높았으며, 무엇보다 terraform이 회사 내 IaaS와 연동하는 데 문제가 있었기 때문에 ansible을 선택하게 되었습니다.
Phase 2에서의 작업 흐름은 다음과 같습니다.
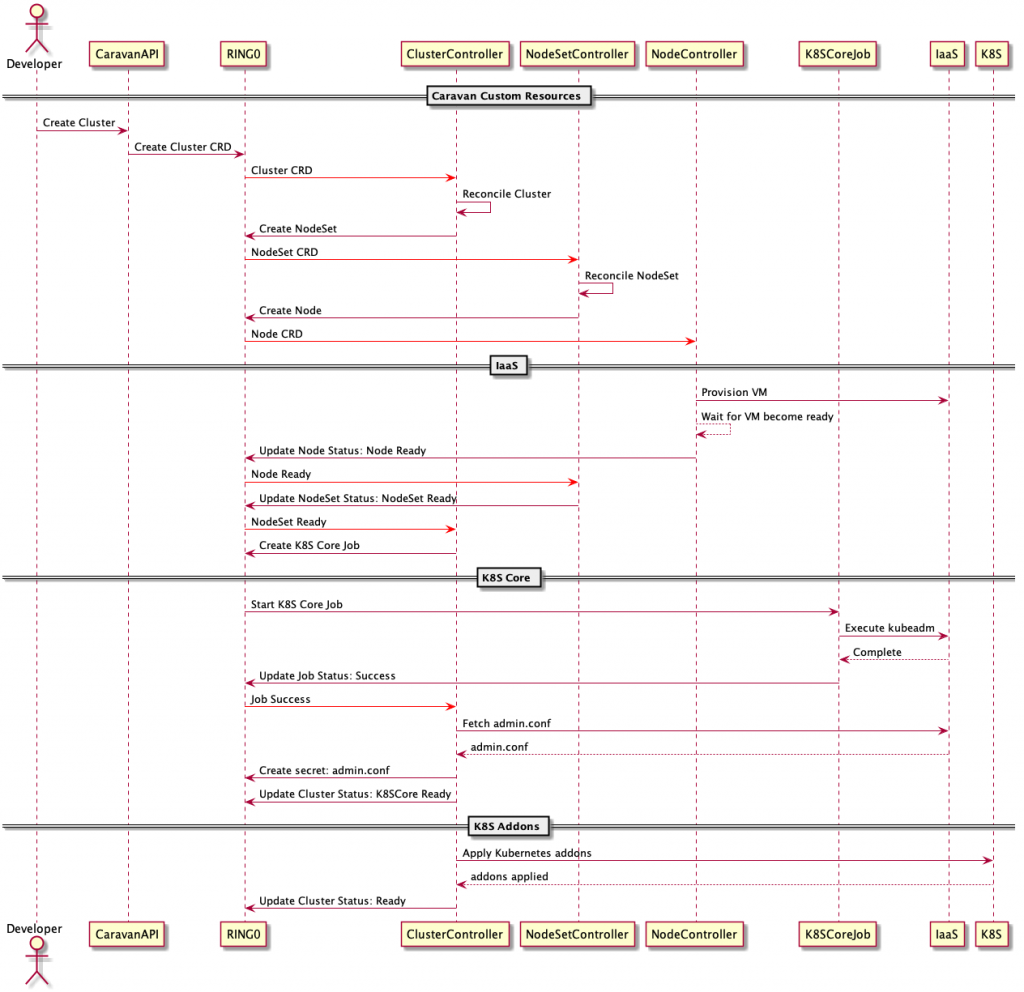
사용자가 API 또는 UI를 통해 클러스터 CRD를 생성하거나 변경할 때 해당 커스텀 컨트롤러(ClusterController, NodeSetController 등)에서 요청된 변경 내역을 실제 클러스터에 반영합니다. 하위 클러스터와 클러스터 내 노드의 상태 확인(health check)은 별도의 에이전트 대신 하위 클러스터의 Kubernetes API를 직접 감시하는 방식으로 수행합니다.
Caravan 커스텀 컨트롤러는 Kubernetes의 Deployment, ReplicaSet, Pod 구조를 차용하여 클러스터, 노드셋(NodeSet), 노드(Node), 이 세 가지의 커스텀 자원을 제어합니다. 또한 위 그림에는 나타나지 않았지만 ClusterController에서 하위 클러스터용 DNS(Domain Name System) 생성과 하위 클러스터용 kubeconfig 관리(참고) 등을 수행합니다.
Caravan UI
아래는 Caravan의 클러스터 목록 화면입니다. 클러스터의 개략적인 정보와 상태, 접속 정보를 확인할 수 있습니다.

다음은 클러스터 생성 화면입니다. 기본적인 Kubernetes 드라이버를 설정할 수 있으며, 각 노드는 LINE 내부 IaaS에 맞춰 설정되었습니다.
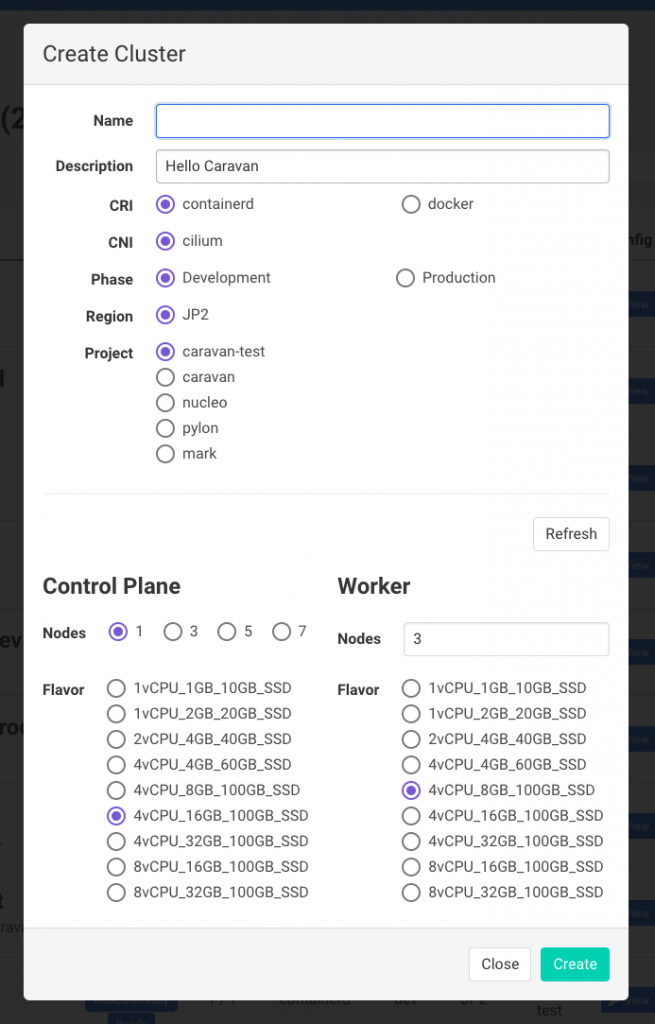
마지막으로 클러스터 상세 화면입니다. 클러스터와 노드의 자세한 정보를 알 수 있습니다.

테스트를 위한 배포 사양
Kubernetes를 구동할 노드는 총 1,019개입니다. 마스터 노드 20개, 워커 노드 999개로 구성했습니다. 마스터 노드는 8 core CPU에 32GB의 메모리를 갖는 VM이고, 워커(worker) 노드는 1 core CPU에 2GB의 메모리를 갖는 VM입니다. 한 노드당 대략 50개의 pod을 구동하며, 테스트를 위해 낮은 사양의 VM으로 만들었습니다.
테스트 방법
위와 같은 사양의 클러스터에 50,000개의 nginx pod을 만들어서 동작을 확인하였습니다.

테스트로 드러난 문제점과 개선 방안
테스트 후 etcd 성능, 스케줄링, cilium etcd에서 문제점이 나타났습니다. 각각의 문제점과 그에 대한 개선 방안을 설명하겠습니다.
etcd 성능
참고. etcd는 데이터 분산 키 값 저장소입니다.
Caravan에서는 기본값으로 아래 이미지와 같은 stacked etcd topology를 사용합니다.

Kubernetes를 stacked etcd topology로 배포하면 Kubernetes control plane(kube-apiserver, kube-controller-manager, kube-scheduler)과 Kubernetes가 사용하는 etcd가 같은 마스터 노드에 배포되며, 이 etcd 노드들은 같은 노드에 위치한 kube-apiserver의 요청만 허용합니다. 이 방식은 설치가 간단하고 control plane 노드의 복제 노드를 관리하기 쉽습니다. 그러나 대규모 클러스터에서는 control plane 서비스와 etcd가 같은 노드의 리소스를 공유하기 때문에 리소스가 부족하여 장애가 발생할 수 있습니다. 또한, stacked etcd topology에서는 etcd가 마스터 노드의 정적(static) pod을 사용하기 때문에 마스터 노드의 숫자만큼 etcd 인스턴스가 구동되며, control plane의 인스턴스 개수와 etcd 인스턴스의 개수를 다르게 하기 어렵습니다.
이 문제를 해결하기 위해 필요할 때 etcd를 외부 노드에 설치하여 운영할 수 있도록 Caravan에 external etcd topology 지원을 추가하였습니다.
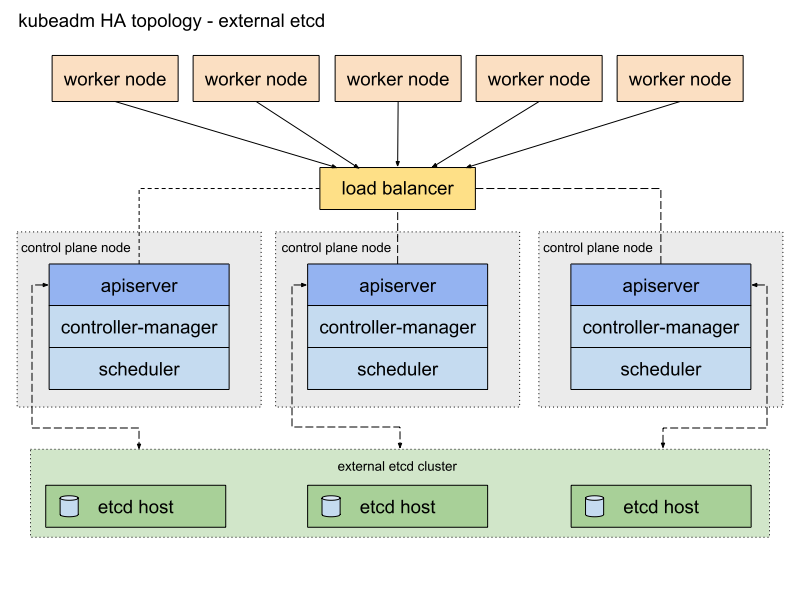
external etcd는 kubeadm의 클러스터 설정에서 etcd.external.endpoints에 외부 etcd의 엔드포인트 목록을 지정하여 사용할 수 있습니다. Caravan의 기본 CNI인 cilium에도 전용 etcd가 필요하므로, external etcd를 사용하는 경우에는 etcd 노드에 cilium-etcd도 같이 설치하도록 변경하였습니다.
스케줄링
대규모 클러스터에 워크로드를 생성할 때 전체 노드의 상태를 파악하고 최적의 노드를 찾는 데 지나치게 많은 시간이 소요되는 문제가 있었습니다. 이 문제는 KubeSchedulerConfiguration의 percentageOfNodesToScore 옵션을 통해 전체 노드가 아닌 일부 노드를 샘플링하여 스케줄링하도록 변경하여 처리하였습니다(참조).
- 스케줄러 사양
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
...
percentageOfNodesToScore: 10cilium etcd
다수의 복제 노드로 이루어진 애플리케이션을 변경하면 대단위 네트워크 변경이 수반되는데요. 이러한 변경을 수행하는 cilium 에이전트가 중지되는 경우가 자주 발생하였습니다. 조사결과 cilium 에이전트에서 Kubernetes core etcd를 직접 감시하는 것이 의심되어, cilium의 enable-k8s-event-handover 옵션을 설정하여 이벤트 처리를 최적화하였습니다. enable-k8s-event-handover 옵션을 설정하면 Kubernetes 이벤트를 operator에서 직접 감시하고 cilium kvstore에 미러링하며, cilium 에이전트에서는 cilium kvstore만 감시하므로 Kubernetes core etcd의 부하를 줄일 수 있습니다.
맺음말
대규모 Kubernetes 클러스터를 설치하고 테스트해 보는 과정에서 많은 Kubernetes 운영 노하우를 얻게 되었으며, 이러한 지식은 앞으로 Nucleo 서비스를 개발하고 운영하는 데 밑거름이 될 것입니다. 긴 글 읽어주셔서 감사합니다.