
미국에는 머스타드 박물관이 있다고 합니다. 무려 머스타드를 위한 박물관도 있는데! '헨리 밀러'나 '어니스트 헤밍웨이' 등 훌륭한 작가와 오랜 세월 전세계적으로 사랑받고 있는 작품을 쏟아낸 나라에 작가를 위한 박물관이 없다는 사실에 개탄을 금치 못한 사람들이 의기투합하여 2009년 재단을 설립하고 2017년, American Writers Museum(AWM)을 탄생시켰습니다. 그리고 바로 이 AWM이 위치한 시카고에서 API the Docs Chicago 컨퍼런스가 개최되었습니다. 그러고 보니 어니스트 헤밍웨이도 시카고 출신이네요(시카고 여행지 추천 목록에 헤밍웨이 생가가 있다는 사실!). 그동안 유럽에서만 개최되어 온 API the Docs가 처음으로 미국에서 개최된 것도 뜻깊은데 장소까지 테크니컬 '라이터'에게 의미있는 장소였던 이번 API the Docs Chicago에 참석하게 된 후기를 늦게나마 여러분과 나누고자 합니다.

API the Docs는 Write the Docs의 스핀오프 버전 행사로 여러 기술 문서 중 특히 API 문서에 대한 필요와 관심이 높아 탄생하게 된 모임입니다. 이미 2018년에 세리자와 님이 여러분께 API the Docs Paris 2018 참관 후기를 공유하기도 하셨지요.
행사 구성
사흘 정도 진행되는 Write the Docs 행사와는 달리 API the Docs 행사는 하루 짜리 행사입니다. 그 때문인지 하루가 알차게 구성되었습니다. 아침 9시부터 총 11개의 세션으로 구성되었으며 각 세션의 주제는 다음과 같습니다.
- (Re)designing a Developer Portal that your developers will want to use
- Devportal Information Architecture: a 4-step method
- Driving A DocOps Based Approach To APIs at Ford Motor company
- Making Great Documentation: Seven steps that go beyond autogeneration
- One size still doesn't fit all
- The UX of DX: User testing in the invisible world of APIs
- Sauntering beyond swagger with open source tools
- Case study: Integration and automation create delightful API docs
- Write your docs like nobody reads them
- Gateways to Gateways: API development in the cloud
- The inverted funnel of developer documentation
세션 목록을 보면 API를 주제로 하는 행사지만 API를 벗어난 듯한 내용, 즉 개발자 사이트 개편에 대한 세션이나 '문서'와 무슨 관계가 있는지 의아해지는 '클라우드에서 API 개발하기' 같은 세션도 있습니다. 앞선 행사를 참가해 보지 못해 이것이 보편적인 구성인지는 모르겠습니다만 이번 행사에서는 API나 문서화와 관련된 내용만 다루지 않았습니다. 그 때문일까요? 모든 발표자가 테크니컬 라이터는 아니었습니다. 테크니컬 라이터와 더불어 에반젤리스트, 개발자, 정보 설계자, 콘텐츠 전략가 등 다양한 직군의 발표자들이 참여했습니다.
API 문서의 주체가 테크니컬 라이터만은 아니라는 사실을 이번 행사를 통해 문득 깨닫게 되었습니다. 여러분이 혹 개발자 사이트 기획자나 서드파티를 위해 API를 구현해서 제공하는 개발자라면 API the Docs 행사에 꼭 참가해 보시기를 추천합니다. 내가 걸어갈 길을 이미 경험한 이들의 이야기를 듣고 어려움을 겪고 있는 부분에 대해 직접 질문해 볼 수 있는 좋은 기회이자 내가 보지 못했던 관점으로 문제를 바라볼 수 있는 시각을 얻게 되는 기회라 생각합니다. 특히 API 문서는 테크니컬 라이터만 잘 한다고 양질의 문서가 되는 것은 아니니까요.
정보는 나눌수록 좋다는 신념을 둔 Write the Docs와 API the Docs는 행사 각 세션의 영상을 무료로 공유합니다. 이번 시카고 행사의 발표 자료와 영상을 보려면 이곳을 확인해 보세요. 비록 한국어가 아닌 영어 자막이긴 해도 자막이 함께 제공되니 영상 시청을 추천합니다(자동 생성된 자막이라 군데군데 이상한 단어가 나오긴 합니다). 주제별로 요약도 무척 잘 되어 있어서, 저는 이번 글에서는 모든 세션을 다루는 대신 두 세션에 집중하여 자세히 나누고자 합니다.
Making great documentation: seven steps that go beyond autogeneration
자동화를 도입하지 않으면 테크니컬 라이터로서 똑똑하게 일하고 있지 않다는 느낌이 들 만큼 문서 자동화는 어느덧 테크니컬 라이팅 작업의 일부가 되었습니다. 워드 같은 도구로 문서를 작성해 별도의 공간에 보관하던 때와 달리, 문서는 코드에 가까울수록 좋다는 지론에 힘입어 근래에는 많은 문서가 깃 저장소에 위치하며, 아예 문서가 코드 속에 존재하기도 합니다. 주석이나 어노테이션을 사용하여 API 문서를 자동 추출하는 방식을 사용할 때처럼요. 이 세션에서 발표자가 말하는 자동화(automation)란 바로 이렇게 코드에서 문서를 추출하는 것을 의미합니다.
그런데 본인을 '프로그래머-라이터'(programmer-writer)로 소개한 발표자는 우리가 너무 자동화에 심취되어 있다고 지적하며 세션을 시작했습니다. 자동 추출이 꽤 편하긴 합니다만, 때론 자동화로 채우지 못하는 부분들이 있어 불편하다고 느끼던 찰나, 모두가 '네!'라고 할 때 '아니오'라고 하는 발표의 서두가 무척 흥미로웠습니다. 또한 발표자는, 테크니컬 라이터는 최소의 인원만 고용해 놓고 그들이 수많은 개발자를 지원할 수 있다고 생각하는 사장님들이 문제의 원인이라고도 했는데요(API 문서가 자동으로 추출되니 최소의 인원만 투입해도 충분히 문서를 만들어낼 수 있다고 생각한다는 뜻으로 해석됩니다). 문서 자동화가 편리하긴 하지만 그 결과물이 충분하진 않아서 결국 문서의 품질은 불만족스러운 수준이 되고, 그에 따라 우리가 제공하는 DX(developer experience) 수준은 기대 이하가 된다고 하였습니다.
Great documentation
첫 번째 꼭지로 나눈 것은 '훌륭한 문서'입니다. 문서를 작성하는 것은 컴퓨터가 아닌 사람이며 우리가 당면한 문제는 문서의 품질이라고 했습니다. 이 문제는 문서를 작성하는 사람이 해결해야 하는 것이지요. 문서를 작성하는 사람의 목표는 훌륭한 문서를 만드는 것인데 이를 위해 필요한 것은 '개발자처럼 생각하기'라고 제안했습니다. 개발자처럼 생각한다는 것은 무엇일까요? 그것은 개발자에게 중요한 것이 무엇인지 이해하고 개발자가 무엇을 궁금해 할지 예측하는 것이라고 했습니다(여기서 말하는 개발자는 API를 만든 개발자가 아닌 사용하는, 즉 API를 호출하는 개발자를 의미합니다).
스웨거(swagger)를 사용해 봤다면 아래 화면에 익숙하실 텐데요. 스웨거에서 샘플로 제공하는 프로젝트인 펫스토어 프로젝트의 일부입니다. 발표자는 아래 화면을 토대로 문서의 품질에 대한 이야기를 이어나갔습니다.
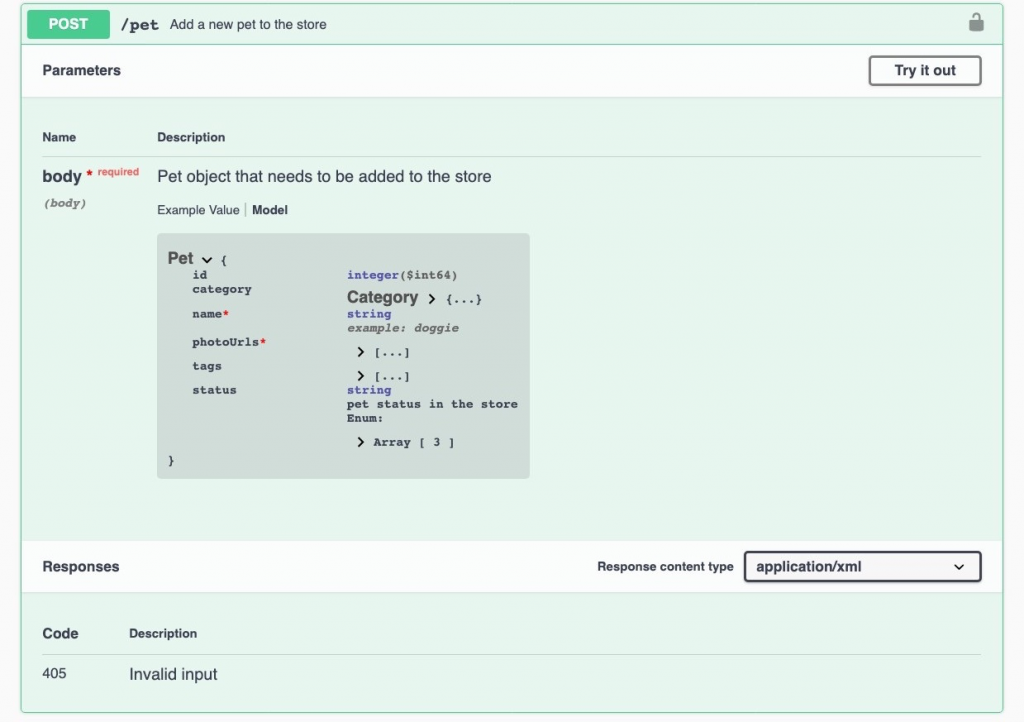
저도 API 작업을 하면서 늘 마음이 걸렸던 부분인데요. 위 그림에서 리퀘스트 바디(body) 파라미터는 단 한 줄로만 설명(description)되어 있습니다. 애플리케이션이 펫스토어만큼 단순하다면 괜찮겠지만, 현실에선 펫스토어보다는 복잡한 애플리케이션을 만들게 될 테니 API 설명이나 파라미터 설명이 이보다는 자세해야 한다는 점을 피력했습니다. 적어도 문단 하나 정도의 분량은 있어야 하며, 파라미터 예제 값과 엔드포인트를 호출하는 예제 코드도 함께 있어야 한다고 말했습니다. 발표자는 위 그림의 API 문서를 개발자가 작성했을 것이라 추측하며, 테크니컬 라이터가 작업했다면 이와는 다른 결과물이 나왔을 것이라고 말했습니다(API를 만든 개발자가 관련 정보를 많이 제공해주거나, 테크니컬 라이터의 문의에 자세하게 답변해 주지 않으면 내용을 풍성하게 만들긴 어려운 게 현실입니다).
이어서 발표자는 훌륭한 문서를 만들기 위해 개발자가 무엇을 궁금해 할지 예측해야 한다며, 과연 개발자가 어떤 것을 궁금해 할지에 대해 다뤘습니다. 먼저 리퀘스트 바디의 첫 번째 필드인 id를 보겠습니다. 이 파라미터는 시리얼 번호의 성격을 가질 것 같은데 여기서 궁금한 점이 생긴다고 했습니다. 대부분의 데이터베이스는 '키'라는 이름으로 시리얼 번호를 자동으로 발급하며, 개발자는 이렇게 시리얼 번호를 자동으로 발급받는 것에 익숙해져 있다고 했습니다. 그런데 위 API를 사용하려면 개발자가 아이디(id) 파라미터 값을 직접 생성해서 입력해야 합니다. 즉 개발자가 보편적으로 작업해 오던 방식과는 다른 방식으로 작업을 해야하는 상황인데요. 이럴 때는 개발자가 모를 수 있는 부분을 명시해야 하고, 더불어 알고 있을 것 같은 내용도 함께 명시하라고 안내했습니다.
방금 살펴본 파라미터 id의 데이터 타입은 int64라고 나와있습니다. 매우 큰 범위의 수를 표현할 수 있는 타입인데 아이디가 이렇게 큰 값이 되어야 하는 이유가 무엇인가 물었습니다. 이어 또 다른 질문을 던졌습니다. 시리얼 번호라면 이 값은 0이 될 수 있는가? 음수가 될 수 있는가? 고유의 번호여야 하는가? 고유 번호라면 개발자가 이것을 어떻게 관리해야 하는가? 그런데 이런 질문에 대한 답을 위 API 문서에서는 찾아볼 수 없습니다.
name이라는 파라미터를 보시면 예제 값이 나와 있긴 합니다. 한국어로 하자면 '멍멍이'격인 'doggie'라는 값입니다. 발표자는 아주 어리석은 예제라며 값이 문자열이기에 유효한 값이긴 하나, 해당 파라미터의 역할을 제대로 보여주지는 못하는 예제라고 했습니다. 예제 값뿐 아니라 파라미터의 이름조차 아쉽다며 예제의 역할은 파라미터의 역할을 알려주는 것임을 강조했습니다. 더불어 예제 값을 제공할 때는 실제로 활용할 수 있는 값을 제공하라 조언했습니다.
What computers can't do
두 번째 꼭지에선, 코드에서 API를 자동으로 추출해 낼 수는 있지만 컴퓨터가 채울 수 없는 부분, 즉 우리 테크니컬 라이터가 채워야 할 일곱 가지를 정리해서 공유했는데요. 저는 그중 샘플 코드의 중요성을 강조하는 부분과 cURL 예제를 지양하라는 부분에 공감했습니다. API 문서를 작업하면서 샘플 코드가 없어 아쉬움을 느낀 적이 많기 때문입니다(자세한 내용이 궁금하신 분은 발표자의 자료를 읽어보시기 바랍니다).
발표자는 예제를 가급적 많이, API를 호출하는 개발자가 필요한 만큼 제공하라고 조언했습니다. API를 호출하는 예제 코드와 리퀘스트 바디에 포함되는 JSON 오브젝트 예제 등 여러 종류의 예제를 간단한 수준에서부터 복잡한 수준까지 제공하여 개발자에게 선택지를 많이 주라고 권했습니다. 또한 제공한 예제를 개발자가 볼 때 스크롤 없이 볼 수 있도록 제공하라고 덧붙였습니다.
지금까지 제가 작업해 온 API 문서의 샘플 코드란에서 주로 본 예제는 cURL 명령어를 사용하는 예제입니다. 여러 파라미터를 조합해 테스트해보는 용도로는 cURL이 편리하나, cURL은 테스트 도구일뿐임을 강조했습니다. 샘플 코드를 생성해 주는 도구도 있으니 활용해 보라며 여러 언어(예: 파이선, C#)로 샘플을 제공할 것을 당부했습니다.
생각 하나
공감이 되는 주옥같은 말씀을 많이 해주셨는데 아쉽게도 본 세션은 발표 자료 화면에 문제가 있어 녹화본이 제공되지 않습니다. 하지만 라이터답게 본인의 발표 내용을 멋지게 글로 풀어 정리하여 공유해 주셨습니다.
발표자는 모든 것을 컴퓨터에게 맡길 수는 없고 테크니컬 라이터가 채워 넣을 수 있는 부분이 분명히 존재한다는 점을 강조하며, 그 일을 감당해야 하는 테크니컬 라이터가 어떤 마음 가짐으로 접근해야 하는지 가르쳐 주셨습니다. 기본적으로 알고 있는 내용도 이렇게 들으니 한번 더 마음을 가다듬게 되었고, 설명을 한 줄 이상 채우기 위해 어떤 내용을 넣을지 고민될 때 API를 만든 개발자에게 어떤 질문을 하면 좋을지 배울 수 있었던 좋은 기회였습니다.
From zero to six: Driving a DocOps based approach to APIs at Ford motor company
청중이 이 세션을 기대하고 흥미를 가진 이유는, 문서 관련 행사에서는 대부분 외부 개발자를 대상으로 하는 문서를 다루는 데 반해 본 세션은 내부 개발자를 대상으로 하는 문서를 다룬다는 점이었습니다. 발표자인 셸커스키 씨는 자동차 회사인 포드가 API와 무슨 관계가 있는지 궁금해 하는 청중을 위해 2016년에 설립된 포드 스마트 모빌리티라는 자회사를 소개하며 발표를 시작했습니다. 당 회사에서 이미 제공하고 있는 서비스로 의료 관련 운송 및 이송, 전동 스쿠터, 월마트 배송, 라이드 셰어링, 운전 기사 보험 등을 소개하며 다양한 소프트웨어 기반의 서비스를 제공하는 회사로서 포드는 'API 중심의 회사'라는 점을 강조했습니다.
발표자는 내부용 개발자 포털이 외부 개발자를 위한 것보다 훨씬 어렵다고 했습니다. 사외에 API를 제공하는 많은 회사가 서드파티 개발자 대상 문서에는 집중하고 노력하는 반면, 내부 개발자용 문서에는 그만큼의 노력을 기울이지 않으리라 추측한다며, 아예 내부 개발자용 문서 자체가 존재하지 않는 곳도 있을 거라고 했습니다. 포드처럼 직원수가 많고 세계 곳곳에 지사를 가지고 있는 글로벌 기업이라면 내부 개발자용 문서가 단순히 존재하는 것만으로는 부족하고, 문서를 필요한 곳에 제공하는 것까지 '잘' 돼야 할 듯 합니다. 포드 직원수는 166,000명이라는데요. 발표자는 이 수치를 '116년 어치의 기술 부채'로 칭한다면서, 지금 몸담고 있는 모빌리티 회사가 신생 기업이긴 하지만 이 기술 부채는 그대로 존재하기 때문에 반드시 처리해야 하는 일이라고 했습니다. '기술 부채'의 정의가 궁금하신 분은 강정일 님이 기고하신 Write the Docs Prague 2018 방문기를 읽어 보시길 추천합니다.
회사 규모가 클수록 회사를 보호하기 위한 장치가 얼마나 복잡하게 구성되어 있는지도 소개했습니다. 계약 단계에서부터 설계, 구매, 오픈소스, 재정 정책, 정보 보안에 이르기까지 절차가 다소 번거로워보여도 회사를 보호하는 든든한 장치라며 내부 개발자용 포털이나 프로젝트를 오픈소스화할 때 신경써야 하는 부분이 상당히 많다는 점을 설명했습니다. 또한 원하는 콘텐츠를 찾기 어렵다는 점을 토로했습니다. 정보가 방대해 원하는 정보를 쉬이 찾지 못하는 문제도 있지만, 정보를 찾았다고 그 정보를 그대로 사용할 수 없다는 문제점도 짚었습니다. 특히 오래된 정보일수록 활용하기가 더 어렵다고 합니다.
DevOps는 들어봤는데 DocOps?
DocOps를 하는 이유는 사내 개발자들이 DocOps를 중요하다고 인식하기 때문이라는데요. 포드 스마트 모빌리티를 구성하는 인력 중 가장 큰 비율을 차지하고 있는 직군은 개발자이며, 현재 약 2천 여명의 소프트웨어 개발자가 있다고 합니다. 근래 사내 해커톤을 개최하면서 API를 대내외로 제공할 때 무엇이 중요하다고 생각하는지 개발자를 대상으로 설문을 진행했다고 합니다. 외부에 제공하는 문서에서는 높은 완성도와 정확한 내용을 중요하다고 여겼는데요. 내부 문서에서 중요하게 생각한 요소는 전제 조건(prerequisite)과 종속성(dependency) 정보였다고 합니다. 즉, 개발 전이나 개발과 관련된 작업을 하기 위해 미리 충족시켜야 하는 환경이나 조건 정보, 그리고 종속성이나 의존성이 있는지, 있다면 어떤 것이 존재하는지에 관한 정보였습니다. 이어서 다음 두 요점에 대해 간략하게 설명했습니다.
DX(Developer Experience)는 콘텐츠가 좌우한다: 우리는 요즘 CX(Customer Experience)를 너무 중요시한 나머지 CX에 숨겨져 있는 다른 의미의 C, '콘텐츠'를 망각하는 우를 범한다고 합니다. 결국은 콘텐츠 싸움인가 봅니다. 발표자는 스웨거를 포털에 적용해 달라는 개발자를 예로 들었는데요. 단순히 스웨거를 도입한다고 포털을 떠났던 개발자들이 다시 돌아오지는 않는다는 것이지요. 도구보다는 콘텐츠, 즉 알맹이가 중요하다는 점을 강조했습니다.
애자일 기법은 좋은 문서의 적이 될 수 있다: 애자일 메니페스토 사이트에 가면 아래와 같은 내용이 있습니다. 볼드 처리한 왼쪽의 내용을 오른쪽에 있는 내용보다 더 중요하게 여긴다는 문구입니다. 발표자는 많은 개발자가 이 메니페스토를 보고 따르면서 '오른쪽 내용을 무시할 수 있는 자격증'을 취득한다고 꼬집었습니다. 문제가 되는 내용은 두 번째 줄입니다. 이해하기 쉬운 문서를 만드는 것 보다 제대로 동작하는 소프트웨어를 만드는 것을 더 가치있게 여긴다는 내용인데요. 이에 따라 DocOps가 희생되고 있습니다.
Individuals and interactions over processes and tools
출처: https://agilemanifesto.org/
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change over following a plan
That is, while there is value in the items on
the right, we value the items on the left more.
포드 모빌리티는 DocOps에 어떻게 접근했는가?
포드 모빌리티는 DocOps를 다음 단계로 나누어 접근했다고 합니다.
- API scavanger hunt: 각 API 제품군이 어떤 상태인지와 어떤 형태로 구성되어 있는지 파악하는 일입니다.
- Expose hidden factories: 개발자가 경험한 불편한 점(pain point)을 해소하기 위해 그들이 사용한 대책을 파악하는 일입니다.
- Change the view of content: 정적인 문서만 콘텐츠로 보지 않고 실시간적인 요소와 동적인 요소를 콘텐츠에 포함시킵니다. 실시간적인 요소로는 개발자들이 API 상태를 알 수 있는 대시보드를, 동적인 요소로는 API 사용 빈도와 사용 패턴, 시간 등의 정보를 예로 들었습니다.
- Expose APIs with meaningful metrics: KPI(Key Performance Indicator)로 활용될 수 있는 정보를 자동 추출하고 시각적으로 제공하여 API 개발자가 이 정보를 알 수 있도록 하는 일입니다. API를 만든 개발자는 API를 호출하는 고객이 누구인지, 어떤 API를 얼마만큼 사용하는지, API를 호출했을 때 발생하는 에러율이 얼마나 되는지 알지 못했다고 합니다.
- Enable self service API on-boarding: 당사의 어떤 API를 처음 사용하는 사람이 API를 실질적으로 활용할 수 있는 시점까지 소요된 시간이 원래 28일이었다고 합니다. 현재는 1시간까지 줄였으나 앞으로 더 감소시킬 계획이라고 합니다.
- Provide meaningful developer assistance: 자동화와 교육을 제공함으로써 개발자의 피로도를 줄이고 생산성을 높이는 일입니다. 일례로 개발 환경을 2분 안에 구축할 수 있도록 개선하여 생산성을 높였다고 합니다.
발표자가 나눈 일련의 작업을 보면 결국 현장을 파악하는 일이 중요한 듯 합니다. 문서든지 API 제품이든지 현상을 제대로 파악해야 하고, 또한 릴리스 이후 고객이 API와 문서를 어떻게 소비하는지도 알아야 고객이 겪는 어려움을 파악하고 개선할 수 있습니다. DocOps는 문서와 문서를 제공하는 서비스, 이 둘을 제공하는 것을 넘어 문서를 어떻게 소비하는지도 고려해야 하는 방대한 범위를 포함합니다.
지금까지의 성과
앞서 소개한 작업을 진행한 후 얻게 된 성과를 공유했습니다. 먼저 API 표준으로 OpenAPI Specification을 선택했는데, 이렇게 어떤 표준안을 선택하고 나면 이를 사람들에게 알려야(evangelize) 한다고 말했습니다.
표준을 정한 다음 내부 개발자용 MVP(Minimum Viable Product) 포털을 만들었다고 했는데요. 다른 외부 개발자 사이트처럼 메인 페이지와 시작하기, 개발하기 문서와 더불어 금주의 API(API of the week)와 같은 지표 등을 확인할 수 있는 모니터링 도구를 제공하고 개발자들이 소통할 수 있는 장을 마련했다고 합니다. 포드에서 소통을 위해 사용하는 도구로는 Skype와 TeamViewer, Slack 등 여러가지가 있는데 소통을 위해 도구를 단일화하고 모두가 그 도구를 쓰기를 바라면 실패할 것이라는 얘기를 덧붙였습니다.
발표자가 이번에 구축한 개발자 포털의 중요한 요소로 소개한 것은 통합 API 카탈로그입니다. 포드는 기술 부채도 많고, 연계된 에코시스템의 규모도 크고, 유럽이나 중국 등 여러 곳에 API 게이트웨이가 분산되어 있기 때문에 기존의 API 카탈로그가 상당히 지저분한 상태였다고 하는데요. DocOps를 통해 분산되어 있는 API 접근 채널을 단일화시켰다고 했습니다. 여기서 API별 담당 관리자 정보도 찾을 수 있고, 담당 관리자가 할당되지 않은 API도 찾을 수 있다고 합니다.
이 작업을 하면서 어려웠던 점을 소개하기도 했습니다. 레거시(legacy) 애플리케이션에는 REST 기반이 아닌 API도 많이 숨어있어 일일이 찾기가 어려웠고, 특히 포드의 '구전(word-of-mouth)' 문화(정보가 입에서 입으로 전해지는 문화) 때문에 더욱 정보 찾기가 어려웠다고 합니다. 이런 작업에 큰 힘이 되는 것이 바로 협업하는 사람들의 도움일 텐데요. 발표자는 조직원을 설득해 API 카탈로그가 필요한 이유를 납득시키기 위해 Google Maps를 예로 들었다고 합니다. Google에서 Google Maps API를 사용하려는 한 사람, 한 사람에게 일일이 사용법을 가르쳐 주거나, 문제점을 해결하기 위해 사용자와 직접 대화를 해야 했다면 어땠을지 생각해 보라고 했다고 말했습니다. Google은 사용자가 Google Maps API를 활용하기로 한 시점부터 실제 활용할 수 있는 시점까지의 과정을 자동화했다고 공유하며 자사의 개발자들에게 그들도 역시 그런 일을 해야만 한다고 설득했다고 합니다.
이어서 소개한 것은 페이지 설계입니다. API를 쉽게 탐색할 수 있도록 API별로 관련 정보를 한 눈에 볼 수 있는 페이지를 설계했다고 합니다. 이 페이지는 앞서 언급한 내부 문서에 있어 개발자들이 제일 중요하다고 생각했던 전제 조건 정보와 종속성 정보뿐 아니라 제한사항, API 담당자 연락처, 주요 정보 링크, 대역폭 정보 같은 현황 정보, API가 지원되는 지역 정보까지 제공합니다.
배포 작업도 공유했는데요. 시스템을 Jenkins와 연결시켜 API 배포를 자동화한 것뿐 아니라, 당사의 스타일 가이드를 토대로 하는 API Linter도 연동시켰다고 합니다. 각 API나 서비스, 제품군의 현황과 성능 정보를 가시화한 자료를 볼 수 있는 시스템을 모두가 볼 수 있도록 마련하였으며 해커톤을 통해 실제 API를 호출하는 개발자들을 더 자세히 알 수 있는 기회를 만들었다고 합니다.
Wrap up
발표자는 마지막으로 DocOps를 진행하며 배운 점을 나눴습니다. DocOps는 변화와 변경 사항이 가득한 작업이며 이 변경 사항을 어떻게 관리하느냐가 핵심이라고 말했습니다. 어려운 일이지만 포기하지 말라고 당부하였습니다. 그리고 우리가 당면한 에코시스템은 살아있는 상태라는 점을 강조했습니다. 정적인 문서를 제공하는 것만으로는 불충분하며, 특히 스웨거가 만능이 아니라는 점을 강조했습니다. 또한 사람들의 마음을 움직이기 위해선 유머를 활용하라는 조언과 함께 너무 완벽함을 추구하지 말라고 조언했는데요. 변경 사항을 마주하는 것은 우리의 숙명이고, 완벽한 도구를 찾아낸다 해도 그 사이 뭔가 바뀌기 마련이라고 했습니다.
생각 둘
테크니컬 라이터로 일하며 다른 회사에서는 어떤 도구를 사용할까, 이 문제에 어떻게 접근할까 등이 종종 궁금했습니다. 하지만 이런 건 상대방이 먼저 공유하지 않는 이상 알기 어려운 정보인데요. 포드 같은 큰 회사에서 이런 문제에 어떻게 접근했는지 알 수 있는 좋은 기회였습니다. 어딜가나 결국 비슷한 문제를 안고 있다는 생각도 하게 되었고요. DocOps는 단순히 문서를 작성하는 것을 넘어 서비스를 개발하는 사람과 개발된 서비스를 활용하는 사람 모두를 고려하여 이를 문서와 문서 제공 시스템에 녹여내는 방대한 작업이라는 것을 알게 되었습니다. LINE은 메신저 서비스 외에도 다양한 서비스를 제공하는데요. 그에 따라 제공하는 API도 많습니다. LINE은 주로 서비스별로 외부 개발자용 포털을 통해 API를 제공하고 있는데요. 언젠가 이 많은 API에 하나의 채널을 통해 접근할 수 있도록 내부 개발자용 포털이 생기면 좋지 않을까 생각해 봅니다.
생각+
이 글을 정리하는 지금도 처리해야 하는 API 작업이 쌓여 있는데요. 이렇게 정리하고 나니 그간 미뤄왔던 API 작업에 영혼을 불살라 봐야겠다는 도전 의식이 생깁니다.
LINE에는 내외부 개발자를 위해 다양한 분야에서 '훌륭한 문서'를 만들고 있는 테크니컬 라이터가 여럿 있습니다. 그들의 이야기가 궁금하신 분들은 아래 글도 함께 읽어 보시면 어떨까요?
- 문서 엔지니어링과 API 문서화
- 테크니컬 라이팅 컨퍼런스: Write the Docs Prague 2018 방문기
- API the Docs 컨퍼런스 참관기
- ‘문서’로 세상에 도움을 주는 테크니컬 라이터, 강정일
몇 개월 후 네덜란드에서 API the Docs Amsterdam 2019가 개최됩니다. 현재(2019.8.9. 기준) 얼리버드 티켓 구매가 가능하니, 가볼까하는 생각이 싹튼 분들은 주저없이 신청하세요!
