
들어가며
안녕하세요. Social Integrations Platform Dev 팀에서 'LINE Integrated Notification Center'(LIN 혹은 알림 센터) 개발을 담당하고 있는 김진수입니다.
LIN 프로젝트를 간단히 설명드리자면, 프로젝트 명에서 알 수 있듯 LINE 통합 알림 센터 제공을 목표로 진행하고 있는 프로젝트입니다. 사용자에게는 알림 센터로서 다양한 알림을 통합된 공간에 제공해 편의성을 높이는 것이 목적이며, 사내로는 여러 서비스에서 알림 센터를 별도로 구축할 필요 없이 LIN과 연동해 쉽고 편하게 알림 센터의 기능을 사용할 수 있도록 만드는 것이 목적입니다.
현재 LIN을 이용해 서비스하고 있는 알림 센터는 두 곳이 있습니다. 첫 번째는 LINE 홈 탭(첫 번째 탭)의 우측 상단에 위치한 종 모양의 홈 탭 알림 센터로 LINE에서의 사용자와 친구들의 전반적인 활동과 관련된 알림을 사용자에게 제공합니다.
두 번째는 LINE VOOM 탭(세 번째 탭) 우측 상단에 위치한 프로필 버튼 내의 소셜 알림 센터입니다. LINE의 SNS인 LINE VOOM에서의 사용자와 팔로워 간의 활동과 관련된 알림을 이 소셜 알림 센터에서 사용자에게 제공합니다.
추가로, 내년 상반기에 릴리스할 예정인 LINE VOOM Studio 알림 센터가 있습니다. LINE VOOM에 다양한 콘텐츠를 제공하는 전문 크리에이터를 위한 전용 알림 센터입니다.
이와 같이 LIN은 LINE 내 여러 서비스에서 사용자에게 보다 쉽게 알림 센터를 제공할 수 있도록 계속해서 정진하고 있는 프로젝트입니다. 이런 LIN에서 올해 초에 메인 스토리지를 Redis에서 MongoDB로 전환하게 되었습니다. 이번 글에서는 이 전환 스토리를 가볍게 공유해 보려고 합니다. 글은 다음과 같은 순서로 진행합니다.
MongoDB로 전환한 배경
우선 가장 궁금하신 게 '왜'일 것입니다. '잘 운영하던 스토리지를 왜 굳이 Redis에서 MongoDB로 옮겼을까?'가 제일 궁금하실 것 같습니다.
기존에 LIN은 Redis를 메인 스토리지로 사용하면서 알림 관련 주요 데이터를 Redis에 저장해 서빙하고 있었습니다. 하지만 늘어가는 알림 종류와 스펙, 새 계정 유입 등의 영향으로 Redis 사용률이 지속적으로 증가하면서 결국 가용량의 80% 이상을 사용하는 상황까지 도달했습니다. 이에 따라 스왑 인/아웃(swap in/out)이 발생하면서 Redis 페일오버(failover) 또한 발생하는 상황이었고요.
급한 대로 메모리 용량 확보를 위해 아래와 같은 여러 작업을 진행해서 다행히 위험한 상황을 잠시나마 피할 수 있었습니다.
- Redis 스케일아웃
- 리스타트를 통한 메모리 파편화 해소
- 데이터 압축(gzip)
- Redis의 sortedset 데이터 구조 변경(skiplist → ziplist)
- 만료된 데이터 주기적 삭제 처리
하지만 이는 임시방편일 뿐 근본적으로 해결할 방법이 필요했습니다. 서비스 성장에 따라 스토리지 용량에 대한 우려가 지속될 것이기 때문이었습니다. 계속 증설하기에는 Redis 비용이 만만치 않은 것도 문제였고요.
마침 서버 데이터 센터 이전이 필요한 상황이 겹쳤습니다. 이번 기회에 스토리지를 변경해 이 상황에서 벗어나 보자고 결정하고 메인 스토리지를 변경하게 되었습니다.
MongoDB를 선택한 이유
이제 '스토리지 전환 배경은 알겠다. 그럼 왜 MongoDB를 선택했을까?'라는 궁금증이 생기셨을 거라고 생각합니다. 크게 두 가지 이유가 있습니다.
문서 데이터베이스(document database)
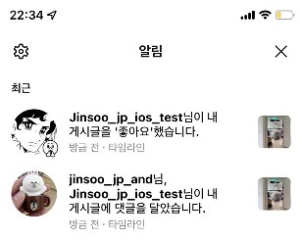
첫 번째 이유는 알림의 데이터 형태가 문서 데이터베이스에 적합하기 때문입니다. 아래는 현재 표시되고 있는 여러 알림의 모습입니다.
그리고 하나의 알림을 표현하는 데 필요한 데이터는 아래와 같습니다.
{
"owner": "-",
"notificationId": "-",
"serviceType": "-",
"categoryType": "-",
"notificationType": "-",
"templateType": "-",
"itemKey": "-",
"originsCount": 1,
"origins": [
{
"createdTimeMsec": -,
"createdDate": -,
"sender": {-},
"landing": "-",
"component": {
"profile": {-},
"preview": {-},
"buttons": {-},
"icon": {-},
"like": {-}
},
"searchKeys": {-},
"messageArguments": {-}
}
]
}이 알림 데이터가 문서 데이터베이스에 적합한 이유는 아래와 같이 정리할 수 있습니다.
- 애플리케이션에서 위 데이터 전체가 하나의 알림 객체 그 자체입니다. 위 데이터를 부분적으로 사용하는 경우는 없습니다.
- 각 알림 데이터는 상호 간 독립적입니다. 즉, 중복되는 데이터가 없으며 이는 별도 정규화가 필요 없다는 것을 의미합니다.
- 알림 관련 스펙은 형태가 변한다거나 예상치 못한 기능이 추가되는 등의 변화 가능성이 큽니다.
- 따라서 데이터 추가 및 변경이 자유로워야 하기 때문에 스키마리스(schemaless) 구조가 좋습니다.
- 실제로 현재 아래와 같은 여러 스펙 추가를 고려하고 있는 상황입니다.
현재의 알림 
버튼 기능 추가 
기존 알림과 전혀 다른 형태 
클릭 위치마다 다른 랜딩페이지 기능 
- 위와 같이 다양한 기능을 계속 추가하기 위해서는 데이터 구조 변경이 불가피합니다. 스키마리스 구조는 이와 같은 스펙 추가 및 변경을 자유롭게 할 수 있게 합니다.
- 다양한 데이터 타입과 그 타입에 맞는 다양한 쿼리를 지원합니다. 이는 추후 어떤 스펙이 신규로 요구될지 모르는 상황에 대응할 수 있는 유연함을 제공합니다.
리치 인덱스(rich index)
두 번째 이유는 아래와 같이 풍부한 인덱스 기능을 제공하기 때문입니다.
- 여러 개의 인덱스(secondary index)를 구성할 수 있습니다.
- LIN에서는 아래와 같이 요구 사항에 맞게 하나의 컬렉션에서 여러 쿼리를 사용하고 있으며, 그에 맞게 인덱스들을 구성해 사용하고 있습니다.
index: "{owner}:{createdTimeMsec}:{revision}" - findItemsByRevisionAndCreatedTime db.notification_item.find({"owner": "-", "createdTime": {$gte: 150198105205602, $lte: 160198105205642}, "revision": {$gte: 150198105205602, $lte: 160198105205642}}).sort({"createdTime": -1}) index: "{owner}:{revision}" - findOneItemByRevision db.notification_item.findOne({"owner": "-", "revision": "160198105205642"}) - findAndReplaceItemByRevision db.notification_item.findOneReplace({"owner": "-", "revision": "160198105205642", document: item) - removeItemsByRevision db.notification_item.remove({"owner": "-", "revision": {$in: [150198105205602, 160198105205642]}) index: "{owner}:{itemKey}" - findOneItemByItemKey db.notification_item.findOne({"owner": "-", "itemKey": "3003:10231921301213"}) index: "{owner}:{categoryType}:{createdTimeMsec}" - findItemsByCategory db.notification_item.find({"owner": "-", "category": "ladm", "createdTime": {$gte: 150198105205602, $lte: 160198105205642}).sort({"createdTime": -1})
- LIN에서는 아래와 같이 요구 사항에 맞게 하나의 컬렉션에서 여러 쿼리를 사용하고 있으며, 그에 맞게 인덱스들을 구성해 사용하고 있습니다.
- 복합 인덱스(compound index)를 지원합니다.
- 자유롭게 인덱스를 추가할 수 있습니다.
- 앞서 언급한 것처럼 알림 센터는 스펙 추가 및 변경 가능성이 크기 때문에 변화에 대응하기 위해서는 신규로 데이터를 추가하는 것뿐 아니라 추가 인덱스 생성도 필요합니다.
- MongoDB는 인덱스 생성에 따른 제약이 적고, 인덱스를 백그라운드로 생성할 수 있어서 서비스 중에도 부담 없이 인덱스를 추가할 수 있습니다.
- 참고로, 서비스 운영 중에는 백그라운드 인덱스 생성을 권장합니다. 만약 포그라운드(foreground)로 인덱스를 생성하면 해당 컬렉션의 작동들은 인덱스 생성이 완료될 때까지 모두 블록되는 상황이 발생합니다.
- TTL(time to live) 인덱스를 지원합니다.
- LIN의 알림 데이터는 만료 기한이 존재합니다. 현재 한 달로 잡고 있는데요. 만료된 불필요한 데이터를 굳이 보관할 필요는 없을 것입니다. 알림 센터에서는 TTL 인덱스를 통해 만료 기한이 지난 알림들을 스토리지 레벨에서 정리해서 유용하게 사용하고 있습니다.
이 외에도 아래와 같은 사항들을 고려해 MongoDB로 결정했습니다.
- 고가용성(high availability)
- 확장성(scalability)
- DB 팀에서의 지원이 있는지
- Reactive MongoDB 클라이언트가 있는지
- 등등
이렇게 메인 스토리지를 MongoDB로 전환함으로써 그동안 겪어왔던 Redis에서의 용량 문제에서 벗어날 수 있었습니다. 빠른 접근이 필요한 간단한 데이터만 Redis에 남겨두고 알림을 구성하는 주 데이터는 모두 MongoDB로 옮겼습니다.
MongoDB로 트래픽을 수용하며 겪은 네 가지 이슈 사례
MongoDB로 전환하기 위한 개발과 개발 환경 내 테스트까지 문제없이 완료했습니다. 계획했던 방향대로 원활하게 진행됐고, Redis 용량 문제로 그동안 추가하지 못했던 스펙들도 추가할 수 있었기에 MongoDB를 선택한 것이 매우 탁월한 결정이었다고 생각하던 차였습니다.
하지만 역시 어떤 일이든 마냥 생각대로만 될 수는 없겠죠? 문제는 실제로 서비스 트래픽을 수용하면서 발생했습니다. 네 가지 이슈 사례를 공유하겠습니다.
문서가 커지며 발생한 oplog 보관 기간(retention) 부족 현상
우선, LIN 알림 센터에서는 '알림 병합 기능'을 제공하고 있습니다. 여러 발송자의 알림을 하나의 알림으로 표현해 주는 기능입니다. 예시를 보겠습니다.
| 병합되지 않은 알림: 한 명으로부터 수신 |  |
| 병합된 알림: n명 이상으로부터 수신 |
|

위와 같이 여러 발송자에게서 수신한 동일한 문구의 알림을 각각 표기하는 것이 아니라 병합해서 하나의 알림으로 표기해 줍니다.
또한 이렇게 수신된 알림을 특정 상황에 따라서 삭제해 주는 '알림 소급 기능'도 제공하고 있습니다. 예를 들어 '진수-베타q'가 댓글을 작성해서 게시글 작성자가 알림을 수신한 후에, '진수-베타q'가 작성한 댓글을 삭제하면 발송된 알림을 삭제해 주는 기능입니다.
하지만, 이 '알림 소급 기능'에는 기능적 제한이 있었습니다. 기존에 Redis로 운영했을 때는 스토리지 용량 한계 때문에 병합된 알림에 대해서는 소급 기능을 지원하지 못하고 있었습니다. 예를 들어 아래와 같이 '옥스안드' 외 3명이 댓글을 작성해서 병합된 알림을 받은 경우를 생각해 보겠습니다.

만약 '옥스안드' 또는 세 명 중 한 명이 댓글을 삭제한 상황에서 소급 기능을 적용한다면 아래와 같이 댓글을 삭제한 사용자가 제외된 알림으로 새로 표기해 줘야 하겠죠.
- '옥스안드'가 댓글을 삭제한 경우 → "{두 번째 발신자} and 2 others commented on your post"
- '옥스안드' 외 사용자가 댓글을 삭제한 경우 → "옥스안드 and 2 others commented on your post"
위와 같이 완전한 '알림 소급 기능'을 지원해 주고 싶었지만 이를 지원하기 위해서는, 비록 위 예시에서는 '옥스안드' 외 3명뿐이었지만, n명의 경우 n명의 알림 데이터를 모두 보관해야 했습니다. 그래야만 병합된 알림 내의 n명 모두가 댓글을 삭제하는 모든 과정에서 소급 기능을 지원해 줄 수 있기 때문입니다. 각 알림에 따른 n명의 데이터를 전부 보관하려면 큰 저장 공간이 필요한데 기존 스토리지는 이미 용량 문제를 겪고 있던 상황이라 이를 지원할 수 없었습니다.
하지만, MongoDB로 전환하면서 충분한 용량을 확보할 수 있었기에 이를 지원하기 위해 최대 100명으로 제한을 두고 데이터를 보관하면서 지원하고자 했습니다. 개발 후 예상대로 용량 문제는 없었습니다. 오히려 넉넉했습니다. 문제는 미처 고려하지 못했던 부분에서 발생했습니다. 바로 아래와 같은 형태로 최대 100명의 알림 데이터를 하나의 문서에 보관하게 되면서 비대해진 문서 때문에 oplog 보관 기간 문제가 발생한 것입니다.
{
"owner": "-",
"notificationId": "-",
"serviceType": "-",
"categoryType": "-",
"notificationType": "-",
"templateType": "-",
"itemKey": "-",
"originsCount": n,
"origins": [ // n명(최대 100명) 각 발신자의 알림 데이터 저장
{
"createdTimeMsec": -,
"createdDate": -,
"sender": {-},
"landing": "-",
"component": {
"profile": {-},
"preview": {-},
"buttons": {-},
"icon": {-},
"like": {-}
},
"searchKeys": {-},
"messageArguments": {-}
},
{
"createdTimeMsec": -,
"createdDate": -,
"sender": {-},
"source": {-},
"landing": "-",
"component": {
"profile": {-},
"preview": {-},
"buttons": {-},
"icon": {-},
"like": {-}
},
"searchKeys": {-},
"messageArguments": {-}
}
...
]
}우선 oplog가 무엇인지 설명드리자면, oplog는 복제 세트(replica set) 내 프라이머리(primary)에서 세컨더리(secondary)로 비동기적으로 데이터를 동기화하기 위한 로그입니다. 문서가 생성되거나 수정되면 이를 세컨더리로 반영하기 위해 저장하는 일종의 기록입니다(참고로 oplog는 MongoDB를 복원할 때에도 사용합니다).
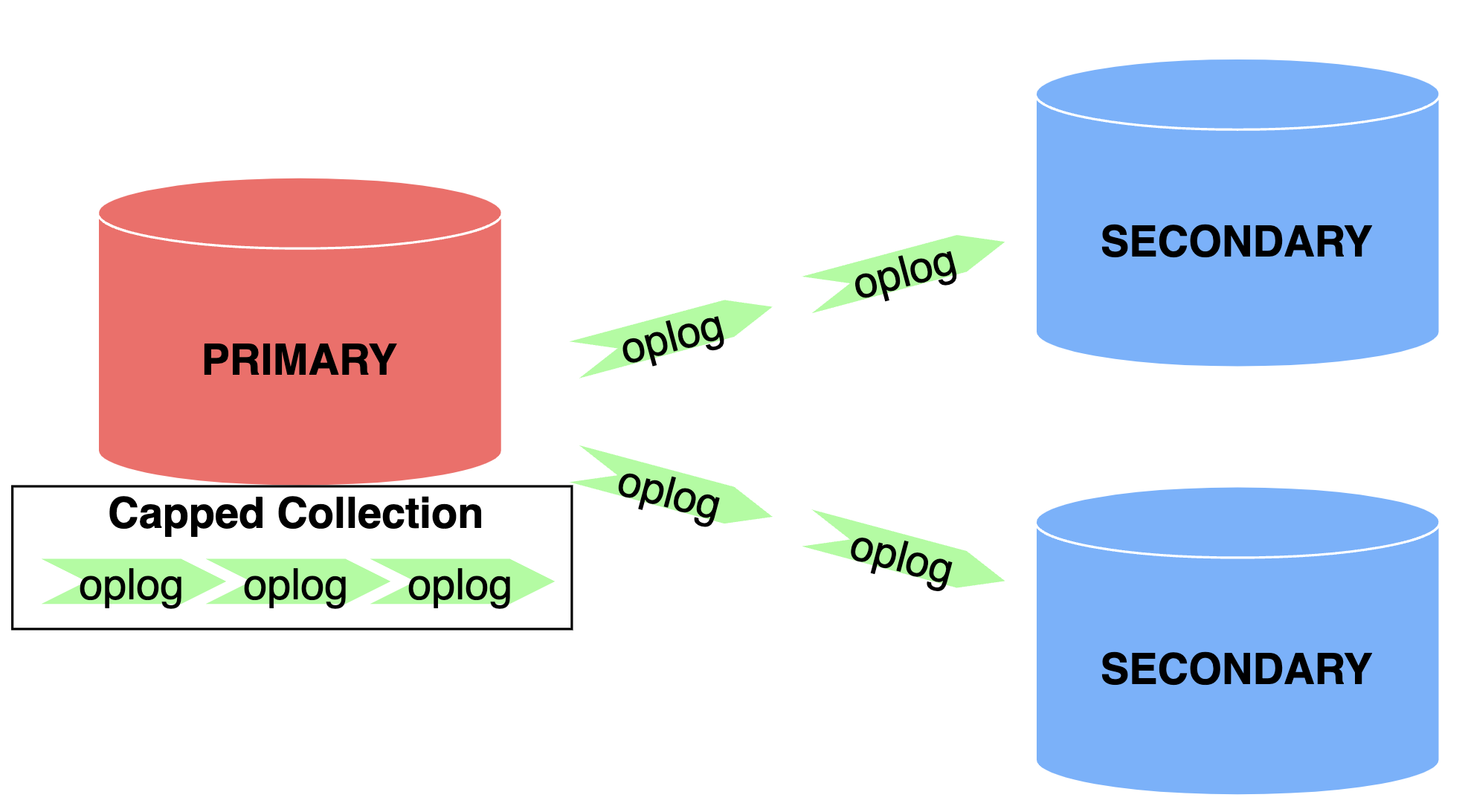
여기서 중요한 점은, oplog는 MongoDB에서 지원하는 특수 컬렉션인, 크기가 고정된 'capped collection'에 저장되는데 컬렉션 크기가 고정돼 있어서 보관할 수 있는 만큼만의 oplog만 보관되며 이를 초과하면 가장 오래된 oplog부터 버리는 형태(automatic removal of oldest documents)로 작동한다는 것입니다. 예를 들어 oplog는 아래와 같은 형태입니다.
{
"ts": { ~ },
"t": { ~ },
"h": { ~ },
"v": -,
"op": "i", // i: insert, u: update, d: delete 등
"ns": "-",
"ui": { ~ },
"wall": { ~ },
"lsid": { ~ },
"txnNumber": { ~ },
"stmtId": -,
"prevOpTime": { ~ },
"o": { ~ } // operation의 구체적인 작업 내용
}insert("op": "i") 시에는 세컨더리에 신규 문서 삽입을 반영하기 위해서 oplog 내 "o" 필드에 문서 전체가 기록되며, update("op": "u") 시에는 변경되는 작업 내용이 "o" 필드에 기록됩니다.
이는 삽입되는 문서의 크기 혹은 변경되는 문서의 정도에 비례해서 oplog의 크기가 커진다는 것을 의미합니다. oplog를 보관하는 컬렉션의 크기는 고정돼 있으므로 각 oplog의 크기가 커진다면 보관할 수 있는 oplog의 개수가 줄어들게 되고, 결과적으로 생성된 oplog의 보관 기간(생존 기간)이 짧아지는 문제로 이어집니다.
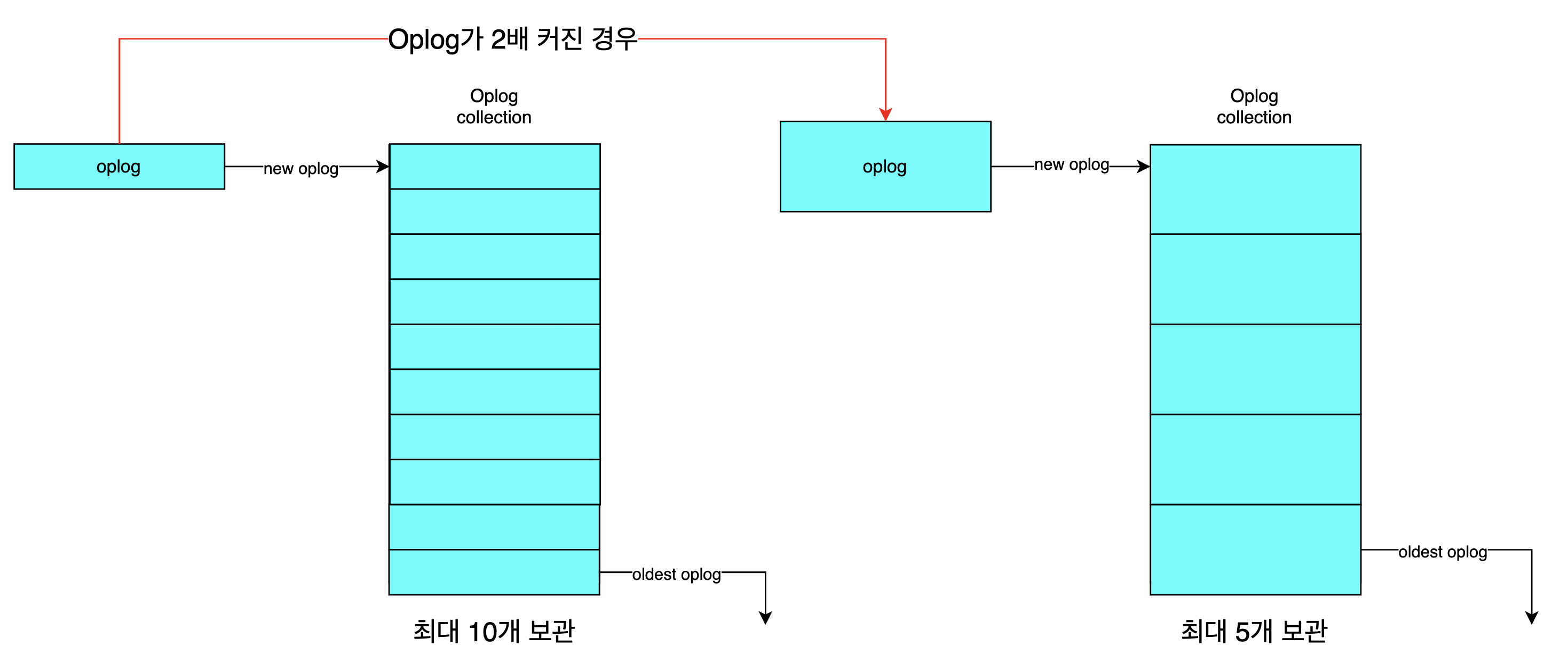
말씀드렸다시피 oplog는 세컨더리 동기화를 위한 로그이기 때문에 세컨더리가 장애(failure) 발생 후 재투입되는 경우 그 시간동안 동기화하지 못했던 오퍼레이션을 프라이머리에서 받아와 세컨더리를 복구하는 데 사용됩니다. 따라서 정상적으로 복구하기 위해서는 장애 시간동안 동기화하지 못한 oplog가 모두 존재해야 하고, 장애가 발생한 서버는 oplog가 유실되지 않기 위해 보관 기간 내에 복구돼야 합니다. 즉, oplog의 보관 기간이 짧아진다는 것은 서버를 복구하는 데 사용할 수 있는 시간이 짧아진다는 것을 의미합니다. 사내 MongoDB 지원 팀에서는 서버를 복구하는 데 최소 24시간 정도의 여유는 있어야 하기에 24시간 확보를 권장하고 있습니다.
하지만 '병합된 알림에 대한 소급 기능'을 위해서 문서 내 최대 100명의 알림 데이터를 저장하는 작업은 문서를 비대해지게 만들었습니다. 알림 생성 요청이 많은 홈 탭 알림 센터의 경우 oplog 수까지 매우 많았는데요. 비대해진 oplog 때문에 보관할 수 있는 oplog 수도 적어진 상황에서, 홈 탭 알림 센터에서 단 기간에 생성한 많은 양의 oplog는 생성된 oplog가 더더욱 빠르게 'oldest oplog'가 되도록 만들어 oplog의 보관 기간이 매우 짧아져 버렸습니다. 아래 그래프와 같이 홈 탭 알림 센터는 oplog의 보관 기간이 대략 3-10시간 정도에 불과하게 됐고, 이는 세컨더리 장애 발생 후 서버를 복구하기까지 걸리는 시간을 고려하면 너무나도 아슬아슬한 보관 기간이었습니다.

해결 방법 - '병합 알림 소급 기능' 지원 보류
만약 특정 oplog들이 유실된 이후에 서버가 복구돼 투입된다면 세컨더리 복구가 정상적으로 진행되지 않기 때문에 이는 피해야만 했습니다. 결국 아쉽게도 이를 방지하기 위해 '병합 알림 소급 기능' 지원은 추후 개선 작업으로 미루게 되었고, '병합 알림 소급 기능'을 위해 추가했던 데이터를 삭제하면서 현재는 약 50시간의 보관 기간을 안정적으로 유지하며 서비스하고 있습니다.
사례 회고
이 사례를 통해 배운 MongoDB를 운영할 때 고려해야 할 사항은 아래와 같습니다.
- 문서가 너무 크지 않은지 확인
- 문서가 크다면 insert와 update 오퍼레이션이 많지 않은지 확인
만약 위 두 사항에 해당한다면 문서 크기를 줄일 수 있는 방법을 고민해야 합니다. 예를 들어 oplog는 컬렉션별로 보관되기에 문서를 쪼개거나 자주 변경되는 필드를 별도의 컬렉션으로 분리하는 등의 방법이 있을 것입니다. LIN에서도 이번에 지원하지 못한 '병합 알림 소급 기능'을 지원하기 위해서 문서 크기를 줄이는 방법을 강구해 볼 예정입니다.
쓰기 배타적 락(write exclusive lock)에 따른 읽기 지연
oplog 관련 문제를 해소한 후에 알림을 생성하고 수정, 삭제하는 요청을 문제없이 원활하게 수용하고 있었습니다. 하지만 이번에는 읽기 요청에서 또 다른 문제가 발생했습니다.
문제는 사용자가 알림 센터에 들어온 상황에서 사용자의 알림 리스트를 제공하는 fetch API가 호출될 때 발생했습니다. 아래와 같이 fetch API가 호출될 때 일정한 주기 없이 불규칙적으로 타임아웃이 발생하고 있었습니다.

이는 아래에서 볼 수 있는 것처럼 MongoDB에서 알림 리스트를 읽어올 때 읽기 지연 시간이 불규칙적으로 증가하는 현상 때문이었습니다.
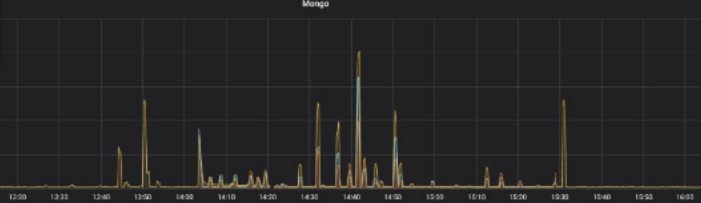
무엇이 MongoDB의 읽기 지연 시간을 증가시키는지 알아내기 위해 아래와 같이 원인을 파악하기 시작했습니다.
- 읽기 지연 시간이 급격히 증가하는 주기가 불규칙적이다.
→ 특정 상황에서 발생 - 그 특정 상황이 무엇일까?
→ MongoDB에서 읽기 지연 시간이 증가해 타임아웃이 발생하는 사용자들을 확인
→ 해당 사용자들은 일반 사용자보다 소유하고 있는 알림이 매우 많고, 알림을 단 시간에 많이 받는다는 특징이 있다는 것을 확인
'알림을 많이 받는 사용자'에게 읽기 지연 시간이 급격히 증가하는 상황이 어떤 이유로 발생하는지 확인하기 위해 기존 fetch API의 작동 형태를 다시 한 번 검토했습니다. 아래 이미지와 같이 먼저 MongoDB에서 알림의 최대 보관 개수만큼 읽어들인 후, WAS에서 만료된 알림인지 또는 다른 조건에 따라 제외해야 하는 알림인지 확인 및 필터링 후 페이징 처리해 클라이언트에 제공하고 있었습니다.
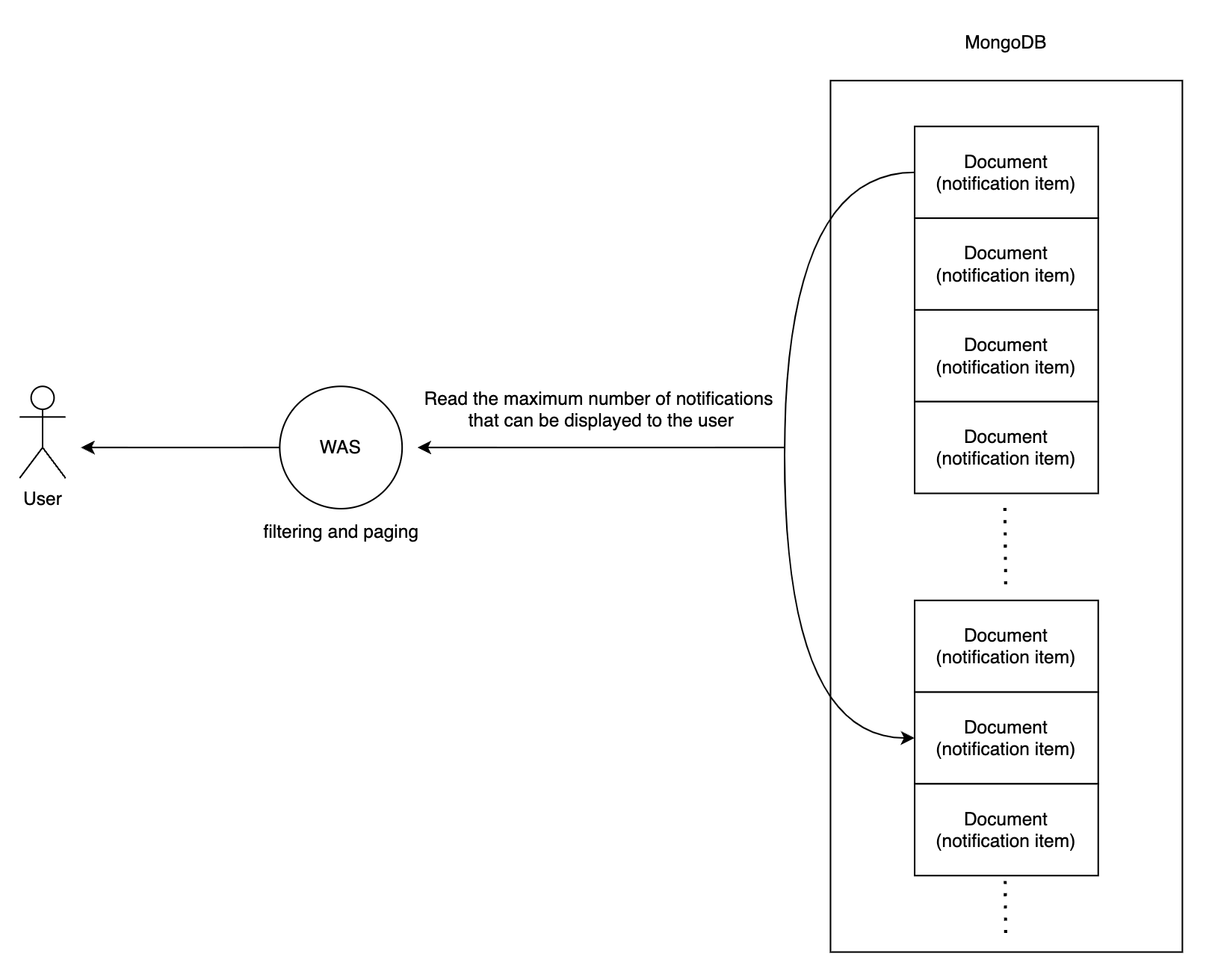
이는 스펙으로 정의된 사항으로, 사용자가 가질 수 있는 알림의 최대 개수가 무제한이 아닌 100개로 비교적 적은 수이며, 이 최대 개수를 유지하기 위해 만료되거나 최대 개수를 초과한 알림들을 지속적으로 삭제 처리도 하고 있었습니다. 그렇기에 DB에서는 간단하게 최대 보관 개수만큼의 알림을 가져온 뒤, 필터링이나 페이징 등의 관련 작업은 WAS에 모두 위임하고자 했던 선택이었습니다.
하지만 이 선택 때문에 문제가 발생했습니다. 바로 아래와 같은 상황 때문이었습니다.
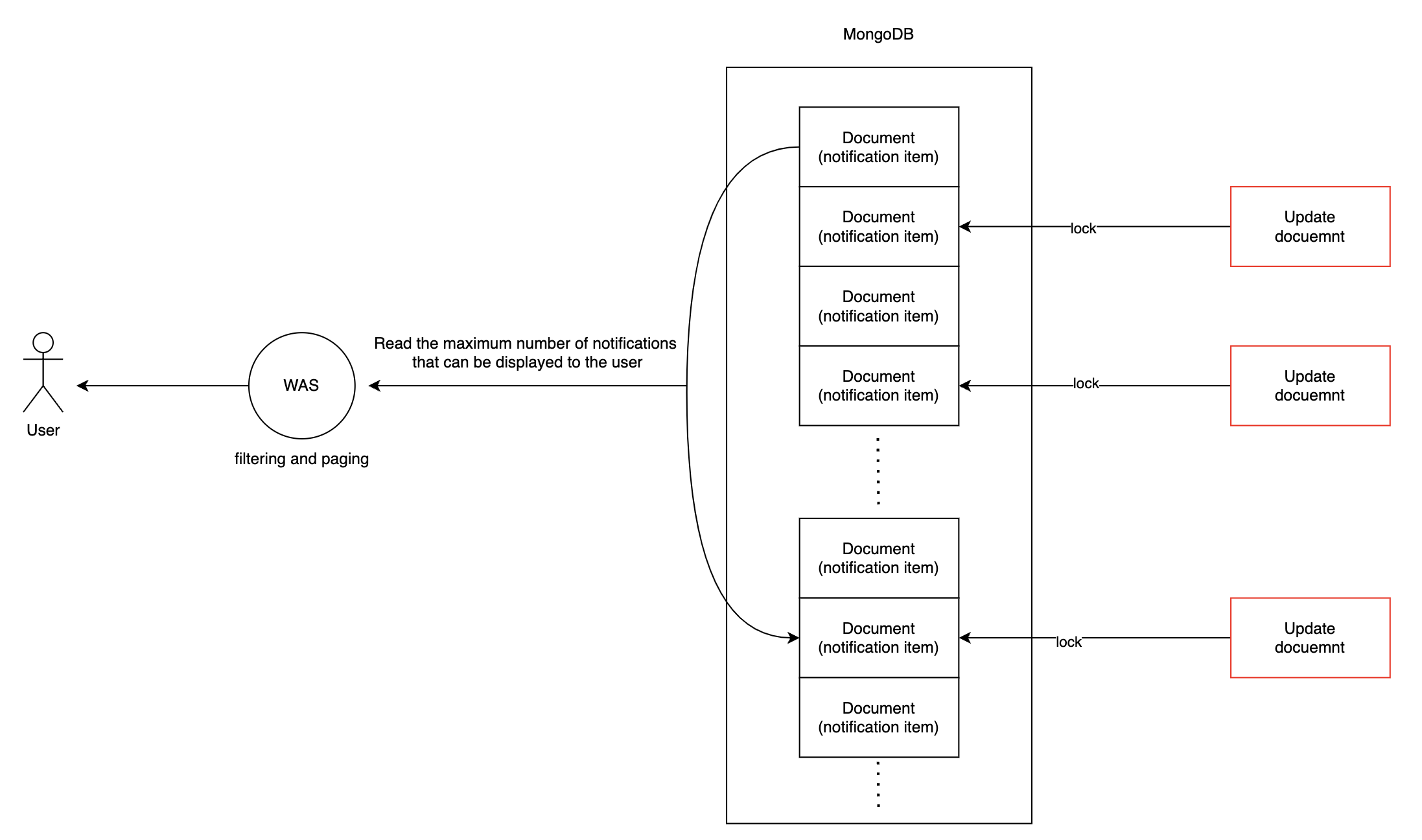
문서 범위 검색(document range scan)을 할 때, 범위 내에 속한 문서 중 쓰기 작업(write operation)이 진행되고 있는 문서에는 쓰기 배타적 락(write exclusive lock)이 걸리면서 읽을 때 지연이 발생하고 있었습니다. 알림을 많이 받는 사용자는 알림을 최대 개수만큼 소유하고 있을 뿐 아니라 알림 생성 및 수정에 따른 쓰기 작업 요청도 많아 많은 문서가 쓰기 작업 대상이 됩니다. 이에 따라 락이 걸린 문서가 많은 것이 원인이었습니다.
해결 방법 - 문서 범위 검색과 문서 수정 동시 발생 최소화
이제 문제의 원인을 파악했으니 해결책을 강구해야 했습니다. 서비스 기능 때문에 문서 범위 검색과 문서 수정이 동시에 발생하는 것은 유지할 수밖에 없는 사항이었습니다. 따라서, 동시에 발생하는 경우를 최소화시키는 방법을 해결책으로 채택했습니다.
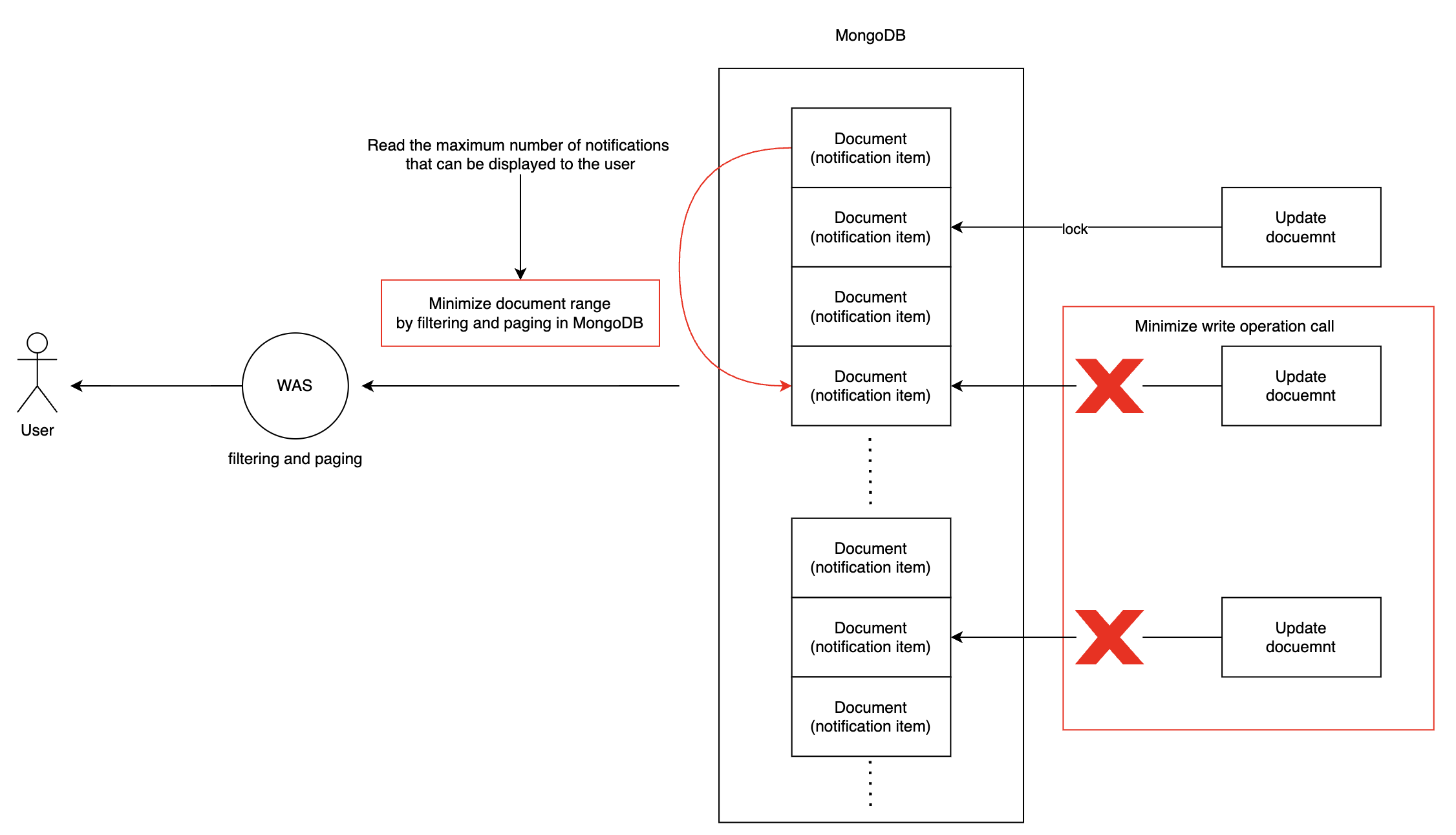
첫 번째로 읽는 문서들의 범위가 크면 클수록 락에 걸려 있는 대상이 많아질 것이므로 범위를 최소화했습니다. 알림 리스트를 읽을 때 기존에 WAS에서 처리해 왔던 알림이 만료됐는지 혹은 조건을 충족하는지 등의 필터링과 페이징 처리를, 쿼리를 보다 구체화해서 MongoDB로 위임했습니다. 이를 통해 MongoDB에서 읽어오는 대상 문서의 범위를 축소했습니다.
두 번째로 만료되거나 최대 개수를 초과한 알림을 삭제하는 처리를 배치로 전환했습니다. 앞서 언급한 것처럼 그동안 이 처리를 실시간으로 진행하고 있었는데요. 이 작업이 과도한 쓰기 작업을 호출하면서 문서가 락에 걸리는 빈도수를 증가시켰습니다. 실시간으로 진행할 필요가 없는 처리였기에 사용자들의 알림 생성 트래픽이 적은 새벽 시간에만 작동하는 배치로 개발해 쓰기 작업에 따른 락 발생 빈도수를 줄였습니다.
문제의 원인 파악과 해결이 제대로 됐다는 것을 아래 성능 테스트 결과에서 확인할 수 있었습니다.
| 처리 전: 지연시간의 증가에 따른 처리량의 감소 | 처리 후: 안정적인 처리량 |
 |
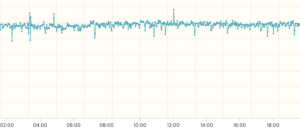 |
하지만, 눈치채셨겠지만 이는 완벽한 해결책은 아닙니다. 만약 읽기 요청을 지연시킬 만큼의 과도한 쓰기 트래픽이 들어오는 경우 같은 상황이 발생할 여지가 아직 남아 있습니다. 예를 들어 짧은 시간에 많은 양의 알림을 받을 가능성이 있는 인플루언서 사용자들이 있습니다. 아직 소셜이나 홈 탭 알림 센터에는 이런 문제를 발생시킬 정도로 쓰기 트래픽이 단기간에 들어오는 경우는 없는 상황이긴 하지만, 곧 릴리스할 LINE VOOM Studio 알림 센터에는 인플루언서 사용자가 존재하기 때문에 발생할 가능성이 많습니다. 이에 인플루언서 사용자를 미리 감지해서 이 경우에 해당하면 쓰기 요청을 큐를 통해 지연 처리하는 형태로 대비하고자 합니다.
사례 회고
이 사례를 통해 배운 MongoDB를 운영할 때 고려해야 할 사항은 아래와 같습니다.
- 문서 범위 검색을 하는지 확인
- 범위 검색을 한다면 검색 대상이 되는 문서에 쓰기 작업 빈도가 잦지는 않는지 확인
만약 위 두 사항에 해당한다면 반드시 성능 테스트를 선행해야 하며, 유사한 문제가 발생한다면 위와 같이 각 서비스마다 적절한 해결책을 강구할 필요가 있겠습니다.
참고로, 위 사례는 MongoDB 4.2 버전에서 발생하는 상황이며, 5.0부터는 'lock-free read operations'을 지원한다고 합니다. 따라서 5.0부터는 위와 같은 문제를 스토리지 레벨에서 해결할 수 있을 것 같습니다.
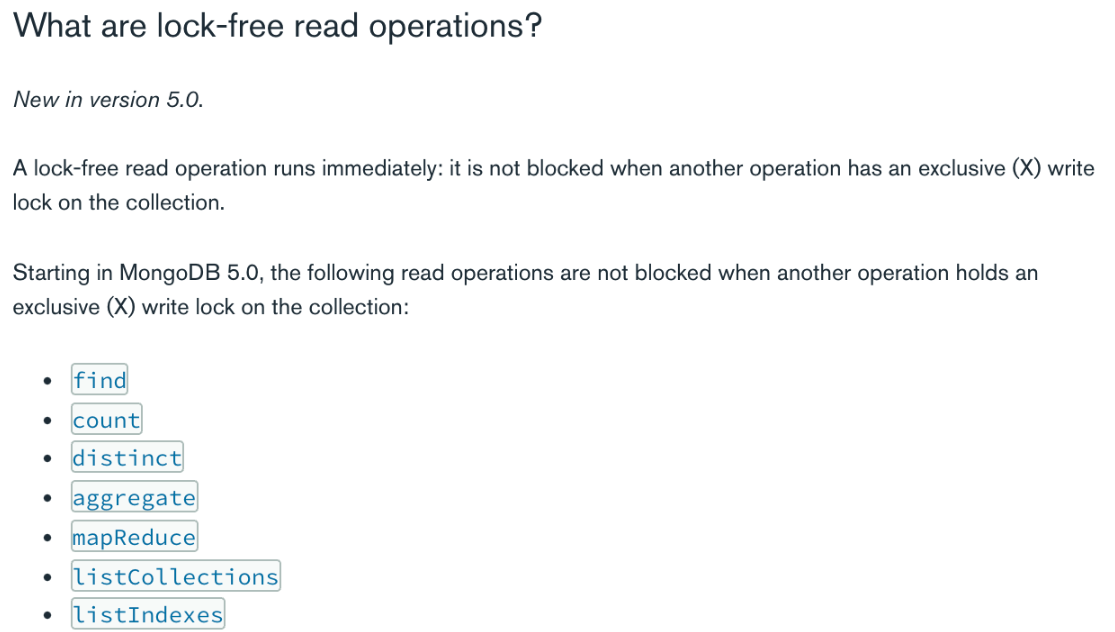
MongoDB 클라이언트의 디폴트 배치 크기
이번 사례는 비교적 간단합니다. MongoDB 클라이언트는 기본 배치 크기(default batch size)가 설정돼 있고, 필요에 따라 이 값을 변경해 성능을 향상시킬 수 있다는 것을 알게 된 사례입니다.
이 옵션을 미처 발견하지 못하실 수도 있으니 먼저 옵션에 대해 간단히 공유하겠습니다. 배치 크기란 MongoDB 클라이언트가 MongoDB로부터 한 번의 요청과 응답으로 전달받을 수 있는 문서의 최대 개수를 의미합니다. 예를 들어 문서 100개를 가져오려고 하는데 배치 크기가 50이라면 두 번의 요청과 응답을 통해 100개를 모두 가져옵니다. 이는 MongoDB로 다녀오는 네트워크 라운드 트립(round trip) 수에 영향을 끼치고, 당연히 성능에도 직접적인 영향을 미칩니다.
초기에는 저희도 해당 옵션의 존재 여부를 모르고 있다가 디버깅 도중 예상치 못한 로그를 확인하면서 알게 됐습니다. 알림 리스트를 가져오기 위해 한 번의 find 요청을 보냈는데 클라이언트 내부에서 find 명령뿐 아니라 getMore 명령도 사용하는 것을 아래와 같이 확인할 수 있었습니다.
DEBUG|SLF4JLogger.java:56 - Sending command '{"find": "notification_item", "readConcern": {"level": "local"}, "filter": {"owner": "-", "createdTimeMsec": {"$gte": 1638651548436, "$lte": 9223372036854775807}, "sort": {"owner": 1, "createdTimeMsec": -1}, "limit": 100, "batchSize": 32, "$db": "social_noticenter", "$clusterTime": {"clusterTime": {"$timestamp": {"t": 1641243070, "i": 1}}, "signature": {"hash": {"$binary": {"base64": "XoUnxuidtnBvqMRmK0K0QZJ0IrA=", "subType": "00"}}, "keyId": 7020318976697696257}}, "lsid": {"id": {"$binary": {"base64": "FPHq5uAKRQ2h4p7D89Mz0Q==", "subType": "04"}}}, "$readPreference": {"mode": "secondaryPreferred"}}' with request id 989 to database social_noticenter on connection
DEBUG|SLF4JLogger.java:56 - Sending command '{"getMore": 7037728393869463019, "collection": "notification_item", "batchSize": 24, "$db": "social_noticenter", "$clusterTime": {"clusterTime": {"$timestamp": {"t": 1641243076, "i": 4}}, "signature": {"hash": {"$binary": {"base64": "D08DAVT17EdSbzQLmVgkcqBtHoM=", "subType": "00"}}, "keyId": 7020318976697696257}}, "lsid": {"id": {"$binary": {"base64": "FPHq5uAKRQ2h4p7D89Mz0Q==", "subType": "04"}}}}' with request id 990 to database social_noticenter on connection총 56개의 알림을 가져오는 상황에서 find를 통해 32개, getMore를 통해 나머지 24개의 알림을 가져오면서 총 두 번의 요청을 보내는 것을 확인할 수 있었습니다.
이는 저희가 현재 사용하고 있는 spring-data-mongodb 라이브러리의 클라이언트가 기본 배치 사이즈를 32로 설정하고 있었기 때문입니다. 이 상황에서 알림 100개를 가지고 있는 사용자에게 알림 리스트를 제공한다면 총 4번의 라운드 트립이 발생합니다.
애플리케이션의 메모리와 처리 성능은 한 번에 100개의 알림 리스트를 가져와서 처리하는 데 문제가 없었기에 쿼리 제한(limit)을 100으로 설정하고 있었습니다. 하지만 숨겨져 있던 100보다 작은 배치 크기 설정 때문에 불필요하게 반복적인 요청과 응답이 발생하면서 성능 저하를 유발하고 있었습니다.
해결 방법 - 배치 크기 변경
성능 저하를 막기 위해 배치 크기를 쿼리 제한과 동일하게 100으로 변경했습니다. 그 결과 로그에서 단 한 번의 find 요청만 있는 것을 확인할 수 있었습니다.
배치 크기를 100으로 조정한 후에는 단 한 번의 요청으로 알림 리스트 GET
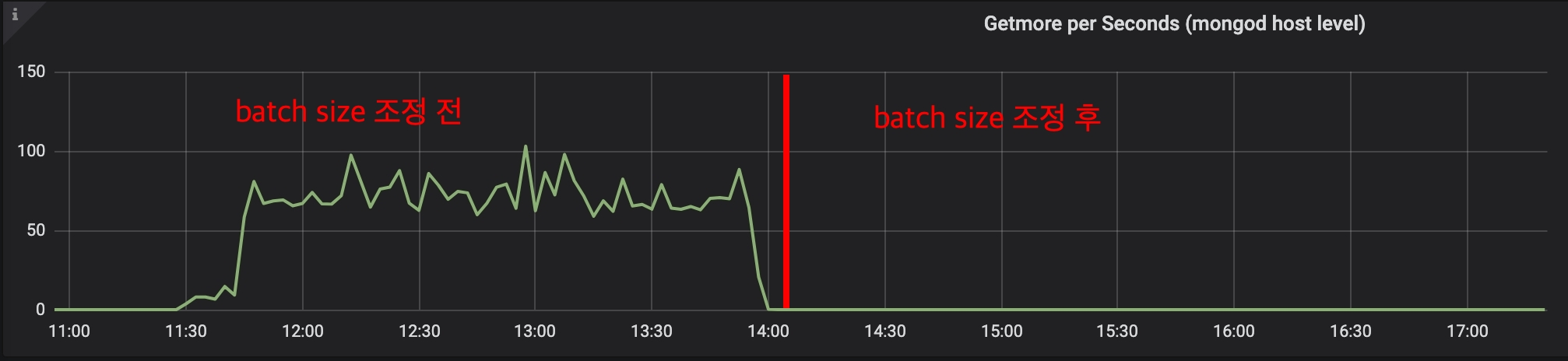
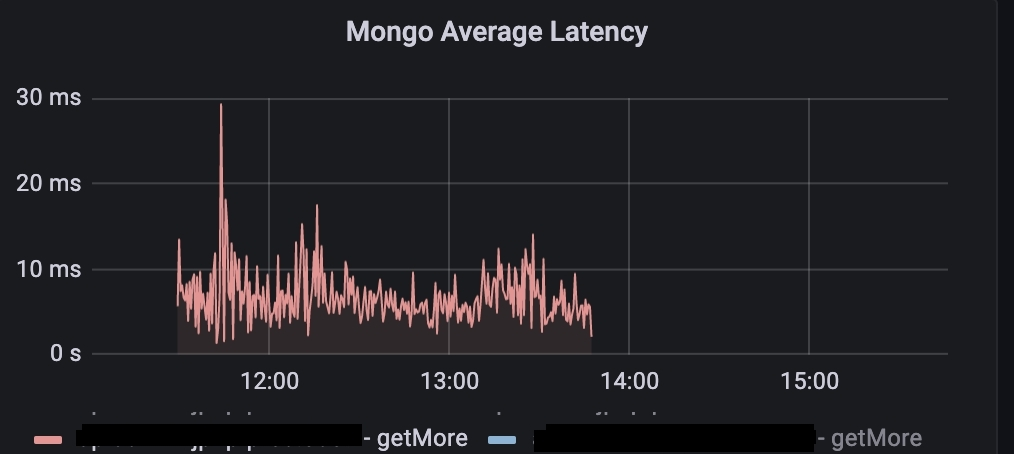
DEBUG|SLF4JLogger.java:56 - Sending command '{"find": "notification_item", "readConcern": {"level": "local"}, "filter": {"owner": "-", "createdTimeMsec": {"$gte": 1638651548436, "$lte": 9223372036854775807}, "sort": {"owner": 1, "createdTimeMsec": -1}, "limit": 100, "batchSize": 100, "$db": "social_noticenter", "$clusterTime": {"clusterTime": {"$timestamp": {"t": 1641243545, "i": 1}}, "signature": {"hash": {"$binary": {"base64": "L9Gb65b3d1yVSl2Y+2MFk4l/jI0=", "subType": "00"}}, "keyId": 7020318976697696257}}, "lsid": {"id": {"$binary": {"base64": "wwx3JiKtSzWERDNJnIvhAg==", "subType": "04"}}}, "$readPreference": {"mode": "secondaryPreferred"}}' with request id 159 to database social_noticenter on connection아래 그래프를 보면 배치 크기 조정 후 getMore 호출이 사라지면서 지연 시간도 함께 사라지는 것을 확인할 수 있습니다.
getMore 호출 수 변화
getMore 호출이 사라지면서 함께 사라진 지연 시간
참고로, 배치 크기는 아래와 같이 간단하게 쿼리로 조정할 수 있습니다.
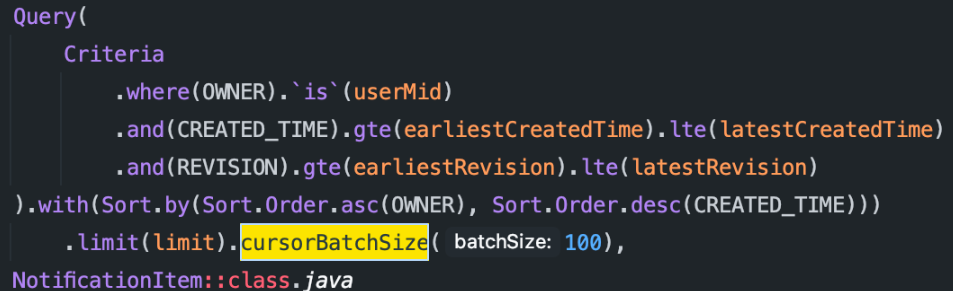
배치 크기와 성능의 상관 관계와 관련해 좋은 글이 있어 링크를 공유합니다.
사례 회고
이 사례로 통해 배운 MongoDB를 운영할 때 고려해야 할 사항은 아래와 같습니다.
- 문서 범위 스캔을 한다면 현재 클라이언트에서 사용하는 배치 크기가 각 서비스에 적합한지 확인
읽기 트래픽에 따른 부하
앞서 소개한 여러 문제를 해결하고 소셜 알림 센터를 문제없이 릴리스 완료한 상황이었습니다. 하지만 홈 탭 알림 센터를 릴리스하면서 또 다른 문제가 발생했습니다.
홈 탭 알림 센터는 소셜 알림 센터보다 서비스 트래픽이 7배 이상 많은데 이에 따른 프라이머리 부하로 읽기 요청 타임아웃이 발생했습니다.
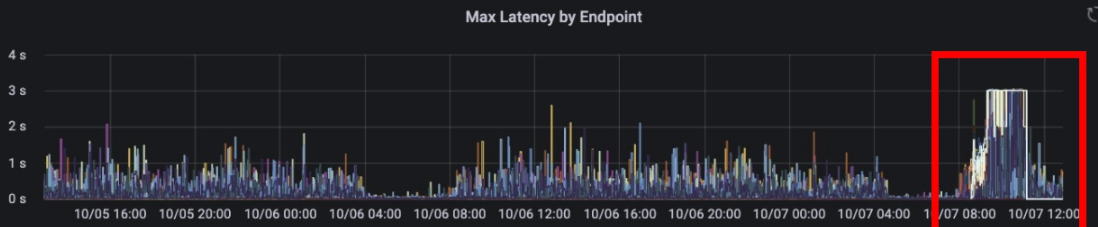
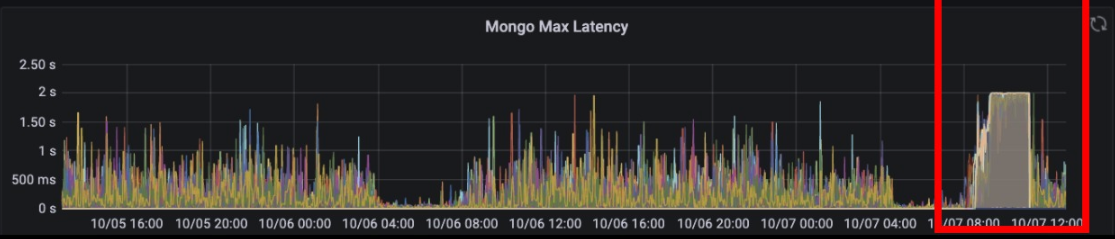
기존에는 모든 읽기 요청을 프라이머리로 보냈습니다. 세컨더리에서 알림을 읽어오는 경우, 프라이머리에서 세컨더리로 데이터를 동기화하는 지연 시간 때문에 아래와 같은 문제 상황이 발생할 수 있다고 판단했기 때문입니다.
문제 상황
문제가 될 수 있는 상황은 사용자가 앱 푸시를 확인해 새로운 알림을 수신한 것을 인지했는데 막상 알림 센터를 확인하니 아직 세컨더리로 데이터가 동기화되지 않아서 해당 알림이 보이지 않는 상황입니다. 참고로 여기서 앱 푸시란 아래 이미지와 같이 사용자에게 기기 팝업으로 메시지를 표시해 주는 기능입니다.
LIN에서는 알림이 프라이머리와 두 개의 세컨더리 중 하나의 세컨더리에 저장된 것이 확인되면 앱 푸시를 발송하도록 구현돼 있습니다. 만일 모든 세컨더리에 반영하는 것을 기다린다면 세컨더리 중 하나라도 문제 발생 시 해당 세컨더리가 복구될 때까지 알림 생성이 불가능하기 때문입니다.
따라서 세컨더리에 항상 최신 데이터가 존재한다는 것을 보장할 수 없습니다. 앱 푸시 발송 후 사용자가 알림 센터에 들어와서 세컨더리에서 알림을 가져온다면, 최신 데이터가 반영되지 않았을 경우에는 앱 푸시로 발송했던 알림이 알림 센터에서는 보이지 않는 현상이 발생할 수 있습니다. 이런 현상을 막기 위해 알림 리스트를 가져오기 위한 읽기 요청을 모두 프라이머리로 요청했고, 이로 인해 프라이머리에 과도한 부하가 발생했습니다.
해결 방법 - 실제 발생 가능성 확인 후 세컨더리로 분산
부하를 해소하기 위해서는 읽기 요청을 세컨더리로 분산해야 했습니다. 그래서 먼저 위에서 우려한 상황이 실제로 발생할 가능성이 있는지 확인하기 위해 프라이머리와 세컨더리 간 동기화 지연 시간을 확인했습니다. 그 결과 아래 그래프와 같이 최대 2초였습니다.

다행히도 최대 2초라는 짧은 시간 동안에는 앞서 우려했던 상황이 발생할 가능성이 없었습니다. 알림이 프라이머리에 저장된 후 앱 푸시로 발송되는 과정과, 사용자가 앱 푸시 확인 후 직접 LINE 앱을 실행해 알림 센터를 확인하는 일련의 과정들이 절대 2초 내에 진행될 수 없었기 때문입니다.
이런 사실을 확인한 뒤 기존에 프라이머리로 요청하던 읽기 요청을 세컨더리로 변경했고, 이를 통해 부하가 해소돼 아래 그래프와 같이 타임아웃 문제를 해결할 수 있었습니다.
처리 전
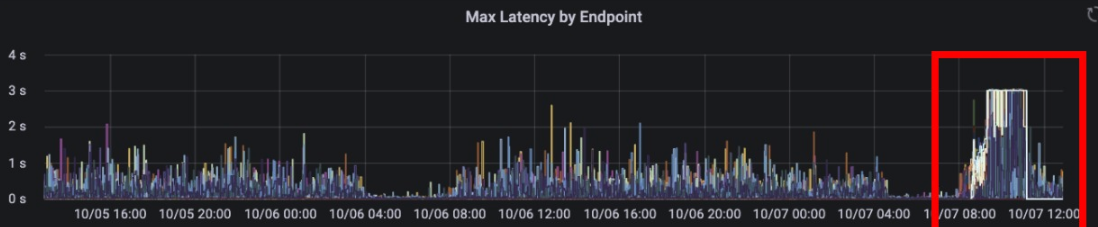
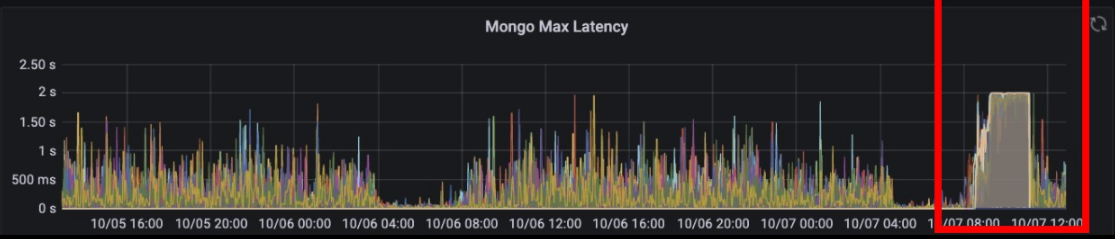
처리 후

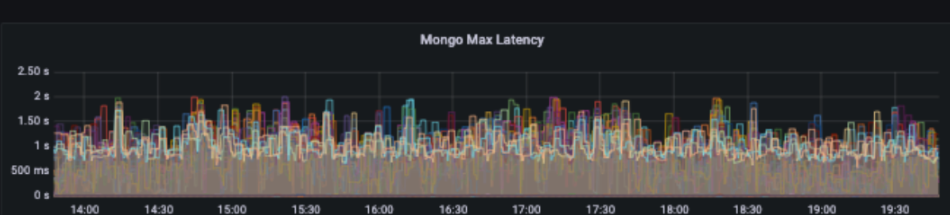
사례 회고
이 사례를 통해 배운 MongoDB를 운영할 때 고려해야 할 사항은 아래와 같습니다.
- 읽기 요청 트래픽을 세컨더리로 분산할 수 있는지 확인
- 세컨더리에서 읽은 데이터가 최신 데이터라는 것을 보장하지 못할 때 서비스 기능에 문제가 없는지 확인
이 사례는 각 서비스마다 상황이 다를 것이기 때문에 각 서비스에 맞게 검토해야 할 사항입니다.
MongoDB 전환 후 장단점
위와 같이 다양한 이슈를 해결해 나가면서 보다 안정적으로 MongoDB로의 전환을 완료할 수 있었습니다. 위 사례를 읽으면서 결국 Redis에서 MongoDB로 전환 후 얻은 것이 무엇인지 궁금하실 거라고 생각합니다. MongoDB로 전환 후 느낀 장점과 단점을 말씀드리겠습니다.
장점
먼저 MongoDB로 전환 후 가장 크게 와닿았던 두 가지 장점을 말씀드리겠습니다.
적은 비용으로 넉넉한 용량 확보
첫 번째 장점은 MongoDB로 전환하게 된 근본적인 이유였던 적은 비용으로 넉넉한 용량을 확보하는 것입니다. MongoDB로 전환하면서 대략 75% 정도의 비용을 절감할 수 있었습니다. 기존에 Redis를 사용할 때는 가용량이 5.3TB였던 반면에, MongoDB로 전환한 후 동일한 비용으로 20TB 이상의 용량을 확보할 수 있었습니다. 덕분에 Redis를 운영하면서 겪었던 용량 걱정과는 이별할 수 있었습니다.
MongoDB의 인덱스 사용
두 번째 장점은 MongoDB로 전환하면서 사용할 수 있게 된 인덱스를 통해 얻은 이점들입니다. 우선, 인덱스 덕분에 기존에 Redis로 운영할 때보다 데이터 모델을 조금 더 간단하게 구성할 수 있었습니다. Redis로 운영할 때는 인덱스 역할을 하는 키들을 별도로 구성할 수밖에 없었는데요. 이를 MongoDB에서는 문서 내 필요한 필드에 인덱스를 설정하는 것으로 대체할 수 있었기 때문에 데이터 모델을 별도로 구성할 필요가 없어졌습니다.
간단한 사례 하나를 말씀드리자면, 기존에는 알림을 위한 데이터 모델을 아래와 같이 구성했습니다. 첫 번째 키가 인덱스를 위한 키로, 특정 itemKey를 가진 NotificationItem(알림)을 추출하기 위해서, 첫 번째 키를 통해 itemKey에 대응하는 알림의 revision을 얻어온 후, 그 revision을 통해 특정 알림만을 가져오는 방식이었습니다.
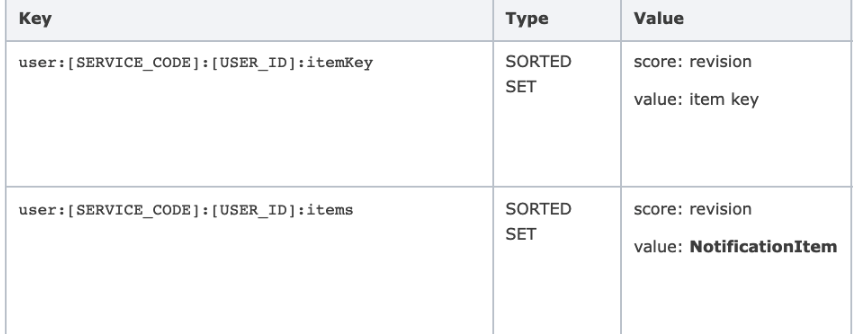
MongoDB로 전환하면서 이런 추가 데이터 구성이 필요 없어졌습니다. 문서 내 itemKey 필드에 인덱스를 설정하면 그뿐이었죠.
또한, 여러 세컨더리 인덱스를 자유롭게 추가할 수 있기에 추후 다양한 스펙에 대응하기에도 매우 유용합니다. 저희 또한 기존에 없던 스펙인 '알림을 카테고리 별로 분류'하는 기능 요청에 간단히 인덱스를 추가함으로써 대응할 수 있었습니다. Redis로 운영했다면 이를 지원하기 위한 별도의 키 추가가 필요했을 상황입니다.
알림 카테고리별 분류 스펙
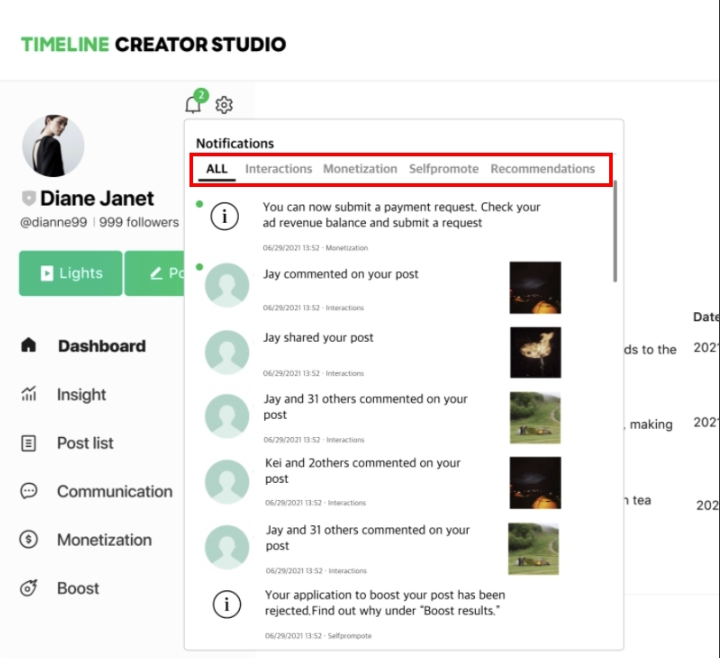
또한 Redis는 키 단위의 TTL만 설정할 수 있는 반면에 MongoDB는 TTL 인덱스를 통해 문서 단위로 TTL을 설정할 수 있습니다. 이는 각 알림에 만료 기한이 있는 LIN에서 매우 유용하게 사용하고 있습니다. LIN에서는 TTL 인덱스를 이용해 만료된 알림을 스토리지 레벨에서 삭제 처리하고 있습니다. 만약 LIN과 같이 만료 기한이 존재하는 데이터가 있는 서비스라면 유용하게 사용할 수 있을 것이라고 생각합니다.
단점
Redis에서 MongoDB로 옮기면서 얻은 것만 있는 것은 아닙니다. 당연하게도 요청 지연 시간 증가가 뒤따라왔습니다. 디스크 사용에 따른 지연 시간 증가로 Redis로 운영할 때보다 일반적으로 지연 시간이 2배~2.5배 정도 증가했습니다. 그뿐 아니라 위에서 언급했던 쓰기 배타적 락에 따른 지연 시간의 불규칙적인 증가에 따라서 최대 지연 시간이 크게 증가했는데요. 최대 5배 정도 증가했습니다. 아래 그래프를 보시면 대략적인 변화를 확인할 수 있습니다.
Redis로 운영했을 때

MongoDB로 운영했을 때

알림 센터는 서비스의 특성상 Redis로 운영해야 할 만큼 지연 시간에 민감하지 않아서 MongoDB로 전환할 수 있었지만, 지연 시간에 민감한 서비스라면 반드시 고려하고 성능 테스트도 충분히 진행해야 할 사항입니다.
마치며
여기까지 LIN에서 메인 스토리지를 Redis에서 MongoDB로 전환하게 된 배경과 그 과정에서 부딪친 이슈 및 해결 과정, 전환 후 장단점을 말씀드렸습니다. 이 글이 저희와 같은 고민을 하고 계신 분들께 도움이 되기를 바라며 글을 마치겠습니다. 긴 글 읽어주셔서 감사합니다.