
この記事は、 LINE Engineering Blog 「夏休みの自由研究 -Summer Homework-」 の 12 日目の記事です。
こんにちは、LINE Ads Platformの開発チームに所属している新卒1年目の佐藤邦彦です。
本記事では、Pythonを使って任意のSignal-to-Noise比(SN比)の音声波形を作る方法を紹介します。なお、本記事の内容は、Clova等の弊社音声事業とは関係ありません。
音声のDeep Learning
画像処理分野においてDeep Learningが技術革新を起こしてから久しいですが、同様のことが音声処理の分野においても起きています。Deep Learningによって音声認識の精度は格段に上がり、Amazon EchoやGoogle Home, LINE ClovaなどのAIスピーカーが市場に普及しました。また、コンピュータによる音声生成(Text-to-Speech)の精度も上がり、その質は人間の声と区別が付きづらいほどです。
Deep Learningで音源分離したい
上記に挙げた音声処理以外にもDeep Learningによって格段に精度が上がっている音声分野があります。
そのひとつが音源分離です。
音源分離とは、複数の音源が混ざった入力波形を各音源の波形に分離することです。
例えば、音声と雑音が混ざった入力波形を音声と雑音のそれぞれの波形に分離するのが音源分離です。音声と雑音に分離する処理は「音声強調」あるいは「雑音除去」とも言われます。また、あるいは、入力音源にピアノとトランペットとギターの音が混ざっており、これら3つの波形を分離することも音源分離と言います。下記の図は音源分離のイメージ図です。

これら音源分離の処理はDeep Learningによって精度が格段に上がっています。以下はその一例の紹介です。
訓練データを作りたい
Deep Learningで音源分離を実現するためには学習用のデータセットを用意する必要があります。本記事の内容は、学習用の訓練データセットを作るのに役立ちます。
話をわかりやすくするため、本記事では音声波形から雑音を除去し音声のみを抽出する「音声強調(雑音除去)」の音源分離について考えていきます。まず、ニューラルネットワークの学習のイメージは以下のようになります。
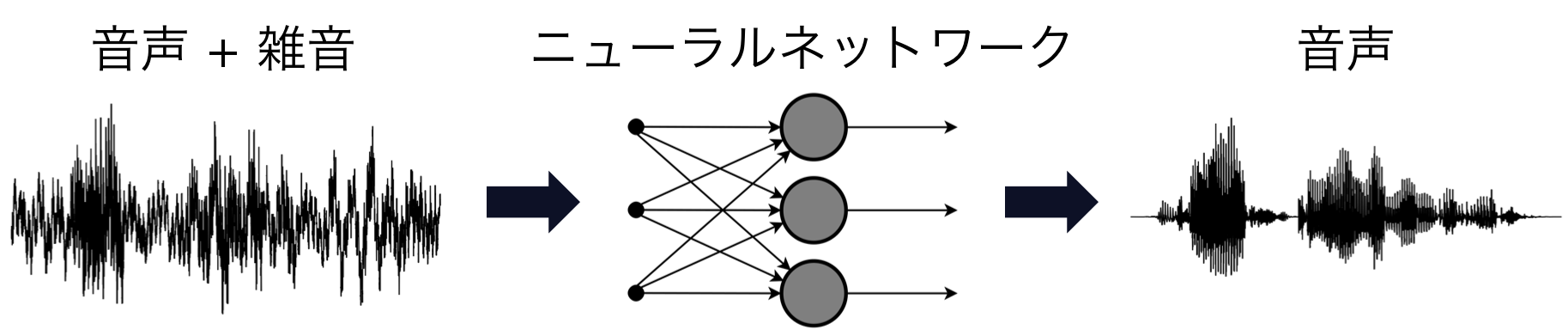
訓練データには音声と雑音が混ざった波形が必要です。また、教師データには音声のみの波形が必要です。ニューラルネットワークは雑音が混ざった音声波形から音声のみを抽出するように訓練されます。音声のみのデータセットはTIMITコーパスなど有名な音声コーパスがいくつもあります。しかし、雑音を含んだ音声データと音声のみのデータが対になっているデータセットはあまりありません。したがって、開発者自身が要件に合わせてデータセットを作る必要があります。いくつか既存のデータセットも存在しますが、開発者が各々で任意のSN比の波形を合成できるようになれば、音声と雑音だけではなく複数の楽器音を混合したデータセットなど、開発の要件に合わせてデータセットを作ることが可能になります。
Signal-to-Noise比とは
Signal-to-Noise比(Signal-to-Noise ratio、SN比、信号雑音比)とは、信号の大きさが雑音の大きさに比べてどのくらい大きいかを表す比率です。音声信号におけるSN比の単位はdB(デシベル)です。本記事ではSignalを音声、Noiseをそれ以外の音(ホワイトノイズ、環境音など)として説明します。
SN比はその数値が高いほど音声のほうが雑音よりも大きいことを意味します。例えば、5dBよりも20dBのほうが音声が大きく聞こえ、雑音が小さく聞こえます。0dBは音声と雑音の大きさがちょうど同じことを意味します。音声よりも雑音のほうが大きい場合は、-10dBのようにマイナスの値をとります。
「任意のSignal-to-Noise比の音声波形を作る」とは、例えば、5dBの割合で音声と雑音が混ざった音声波形を作るということです。
Sinal-to-Noise比の計算方法
SN比は以下の式で求めることができます。

AsignalとAnoiseはそれぞれ音声と雑音の「大きさ」あるいは「強さ」を表します。「強さ」の定義はいくつかありますが、本記事では振幅値の二乗平均平方根(Root Mean Square, RMS)をそれぞれの音の強さとします。
振幅値の二乗平均平方根は以下の手順で求めることができます。まず、下記の図を見てわかる通り、音声の振幅値はマイナスの値も取ることがあるので振幅値を二乗します。二乗した値を足し合わせたあと、その値の平均を計算します。最後に、平均した値の平方根を計算することで音の強さを求めることができます。
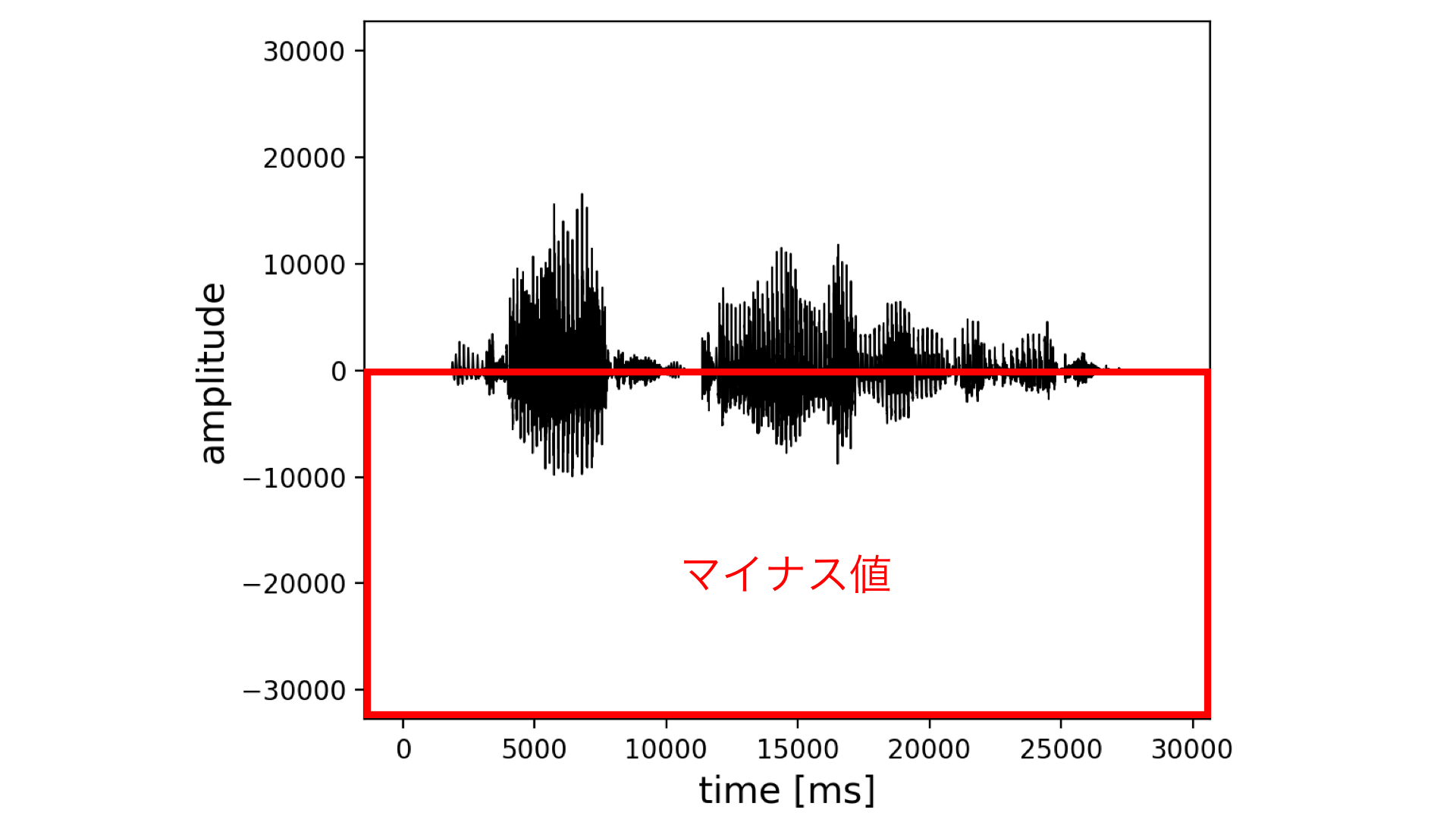
波形中のすべての振幅値を利用した二乗平均平方根の値が音の強さとして使えない場合もあります。それは波形に無音区間が多かったり、ある区間だけ異常に振幅値が大きい場合です。これらの場合、振幅値の二乗平均平方根の表す値と人が知覚する音の強さに乖離が出てしまいます。よって、無音区間を取り除いたり、短時間ごとにSN比を計算したりする必要があります。また、ここで紹介した以外にもSN比を求める方法があると思いますのでぜひ調べてみてください。
Pythonで任意のSignal-to-Noise比の音声波形を作る
それでは実際に、音声に対して任意の大きさの雑音を重畳するプログラムをPythonで実装していきます。
先に完成したコードのリンクを貼っておきます。
https://github.com/Sato-Kunihiko/audio-SNR
また、上記のプログラムによって生成された音声の例は以下のようになります。左上から順に、SN比が-20、-5、0、5、20dBの音声波形です。数値が大きくになるにつれて雑音が小さくなり、音声がはっきり聞こえると思います。
※上記のプログラムを実行しても、動画ファイルは生成できません。音声ファイルを生成します。当ブログの仕様では音声ファイルをブログ内に埋め込めないので、YouTubeにアップロードした動画を埋め込んでいます。
準備
実行環境
- Python3系
- MacOS
音声ファイルのフォーマット
音声ファイルは拡張子が.wavのものを必ず使用してください。また、wavファイルのフォーマットを以下のように設定してください。
- 量子化ビット数は16bit
- 音声用のファイルと雑音用のファイルのサンプリングレートを同じにする
量子化ビット数はデフォルトで16bitになっていることが多いです。サンプリングレートはファイルによって異なることが多いので注意してください。16000Hzや44100Hz、48000Hzになっていることが多いです。サンプリングレートの変更はSoXなどの音声編集ソフトウェアを使えばコマンドラインからも行うことができます。
使用データセット
今回の実装では音声のみのwavファイルと雑音のみのwavファイルを使用します。
音声のみのファイルはCMU ARCTICコーパスを使用しました。
雑音のみのファイルはDEMANDを使用しました。DEMANDは18種類の環境音を収録したデータセットです。
wavファイルを読み込む
まず、wavファイルを読み込む実装をします。Pythonでwavファイルを扱うためのライブラリはいくつかありますが、今回はwaveライブラリを使います。
import argparse
import array
import math
import numpy as np
import random
import wave
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--clean_file', type=str, required=True)
parser.add_argument('--noise_file', type=str, required=True)
parser.add_argument('--output_clean_file', type=str, default='')
parser.add_argument('--output_noise_file', type=str, default='')
parser.add_argument('--output_noisy_file', type=str, default='', required=True)
parser.add_argument('--snr', type=float, default='', required=True)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
clean_file = args.clean_file
noise_file = args.noise_file
snr = args.snr
clean_wav = wave.open(clean_file, "r")
noise_wav = wave.open(noise_file, "r")
上記のプログラムではPythonファイルの実行時に以下の引数を含める必要があります。
- 音声のみのファイルの絶対パス
--clean_file - 雑音のみのファイルの絶対パス
--noise_file - 処理後の音声のみのファイルの絶対パス。これはオプションです。
--output_clean_file - 処理後の雑音のみのファイルの絶対パス。これはオプションです。
--output_noise_file - 任意のSN比の音声ファイルの絶対パス
--output_noisy_file - 合成したいSN比の大きさ
--snr
実際に実行した場合のスクリプトは以下のようになります。ファイル名やフォルダのパスは任意のものに書き換えてください。
python3 create_noisy_minumum_code.py --clean_file ~/Desktop/test_source/arctic_b0001.wav --noise_file ~/Desktop/test_noise/0ch01.wav --output_clean_file ~/Desktop/clean.wav --output_noise_file ~/Desktop/noise.wav --output_noisy_file ~/Desktop/noisy.wav --snr 0
音声波形の振幅値を取得する
wavファイルを読み込んだあと、そのwavファイルの振幅値を取得します。
def cal_amp(wf):
buffer = wf.readframes(wf.getnframes())
amptitude = (np.frombuffer(buffer, dtype="int16")).astype(np.float64)
return amptitude
if __name__ == '__main__':
(中略)
clean_amp = cal_amp(clean_wav)
noise_amp = cal_amp(noise_wav)
wf.readframes(n)は最大n個のオーディオフレームを読み込んで、bytesオブジェクトを返します。wf.getnframes()はオーディオフレーム数を返します。つまり、wf.readframes(wf.getnframes())でwavファイルのすべての振幅値を取得しています。
その後、(np.frombuffer(buffer, dtype="int16")).astype(np.float64)でbytesオブジェクトを最終的にnp.float64にキャストしています。
振幅値の二乗平均平方根(Root Mean Square, RMS)を求める
振幅値のRMSを求める前に注意すべきことがあります。
DEMANDから取得した雑音データは1ファイルあたり5分の長さがあります。一方、CMUコーパスの音声データは1ファイルあたり2~5秒です。そのため、雑音データの波形を音声データの波形の長さに切り出す必要があります。最終的には、下記の図のように、元の雑音データから切り出した波形と音声データの波形のそれぞれのRMSを計算し、任意のSN比になるように重畳します。

実際のコードでは、雑音の切り出す位置をランダムに決定し音声の長さ分だけ切り出します。
def cal_rms(amp):
return np.sqrt(np.mean(np.square(amp), axis=-1))
if __name__ == '__main__':
(中略)
start = random.randint(0, len(noise_amp)-len(clean_amp))
clean_rms = cal_rms(clean_amp)
split_noise_amp = noise_amp[start: start + len(clean_amp)]
noise_rms = cal_rms(split_noise_amp)
Signal-to-Noise比の計算式を利用して任意の大きさで波形を合成する
SN比の計算式は以下のようになります(再掲)。
上記の式を利用して、音声に対して任意のSN比になるような雑音のRMSを求めます。求めたい雑音のRMSは上記の式を変形し以下の式で求めることができます。
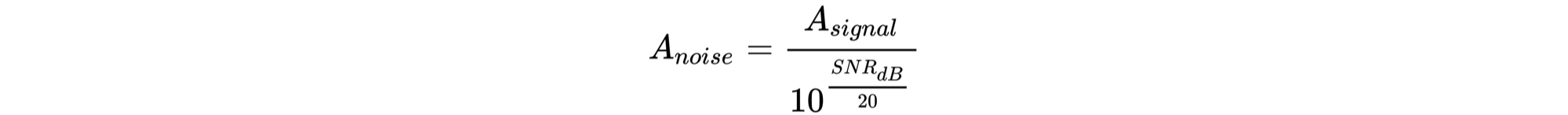
以下の図で示すように、上記の式で導出したRMS(Anoise)と元の雑音のRMSの比率を計算し、その比率分だけ元の雑音の振幅値を調整します。その後、調整した雑音の振幅と音声のみの振幅を足します。

def cal_adjusted_rms(clean_rms, snr):
a = float(snr) / 20
noise_rms = clean_rms / (10**a)
return noise_rms
if __name__ == '__main__':
(中略)
adjusted_noise_rms = cal_adjusted_rms(clean_rms, snr)
adjusted_noise_amp = split_noise_amp * (adjusted_noise_rms / noise_rms)
mixed_amp = (clean_amp + adjusted_noise_amp)
振幅を足し合わせたあと、注意点があります。それぞれの振幅が十分に大きかった場合、足し合わせた振幅の値はwavファイルの量子化ビット数16bitの最大値(二進数で32767)を超えてしまう可能性があります。最大値を超えた波形は、いわゆる「音割れ」を引き起こします。したがって、足し合わせた値が16bitの最大値を超えた場合、足し合わせた値の最大が32767に収まるように正規化します。
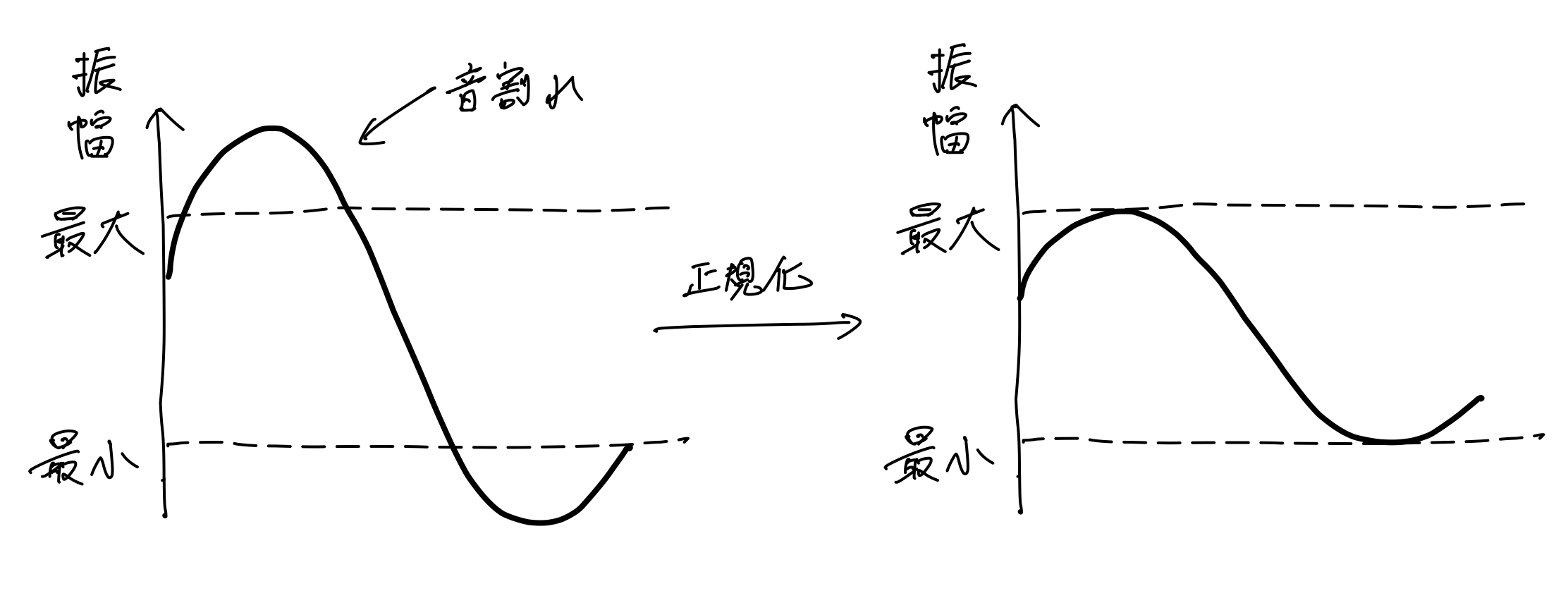
if (mixed_amp.max(axis=0) > 32767):
mixed_amp = mixed_amp * (32767/mixed_amp.max(axis=0))
clean_amp = clean_amp * (32767/mixed_amp.max(axis=0))
adjusted_noise_amp = adjusted_noise_amp * (32767/mixed_amp.max(axis=0))
波形をwavファイルで保存する
最後に波形をwavファイルとして保存します。wavファイルの書き込みもwaveライブラリを使用します。
noisy_wave = wave.Wave_write(args.output_noisy_file)
noisy_wave.setparams(clean_wav.getparams())
noisy_wave.writeframes(array.array('h', mixed_amp.astype(np.int16)).tostring() )
noisy_wave.close()
clean_wave = wave.Wave_write(args.output_clean_file)
clean_wave.setparams(clean_wav.getparams())
clean_wave.writeframes(array.array('h', clean_amp.astype(np.int16)).tostring() )
clean_wave.close()
noise_wave = wave.Wave_write(args.output_noise_file)
noise_wave.setparams(clean_wav.getparams())
noise_wave.writeframes(array.array('h', adjusted_noise_amp.astype(np.int16)).tostring() )
noise_wave.close()
setparams()はwavファイルのフォーマットを指定するメソッドです。特に問題なければ、入力に使用した音声ファイルのフォーマットをそのまま使ってよいと思います。writeframes()で振幅値を指定します。Stringにキャストする必要があります。
コード全体
最後にコード全体を載せておきます。Gihubにもあげておきました。
# -*- coding: utf-8 -*-
import argparse
import array
import math
import numpy as np
import random
import wave
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--clean_file', type=str, required=True)
parser.add_argument('--noise_file', type=str, required=True)
parser.add_argument('--output_clean_file', type=str, default='')
parser.add_argument('--output_noise_file', type=str, default='')
parser.add_argument('--output_noisy_file', type=str, default='', required=True)
parser.add_argument('--snr', type=float, default='', required=True)
args = parser.parse_args()
return args
def cal_adjusted_rms(clean_rms, snr):
a = float(snr) / 20
noise_rms = clean_rms / (10**a)
return noise_rms
def cal_amp(wf):
buffer = wf.readframes(wf.getnframes())
amptitude = (np.frombuffer(buffer, dtype="int16")).astype(np.float64)
return amptitude
def cal_rms(amp):
return np.sqrt(np.mean(np.square(amp), axis=-1))
if __name__ == '__main__':
args = get_args()
clean_file = args.clean_file
noise_file = args.noise_file
snr = args.snr
clean_wav = wave.open(clean_file, "r")
noise_wav = wave.open(noise_file, "r")
clean_amp = cal_amp(clean_wav)
noise_amp = cal_amp(noise_wav)
start = random.randint(0, len(noise_amp)-len(clean_amp))
clean_rms = cal_rms(clean_amp)
split_noise_amp = noise_amp[start: start + len(clean_amp)]
noise_rms = cal_rms(split_noise_amp)
adjusted_noise_rms = cal_adjusted_rms(clean_rms, snr)
adjusted_noise_amp = split_noise_amp * (adjusted_noise_rms / noise_rms)
mixed_amp = (clean_amp + adjusted_noise_amp)
if (mixed_amp.max(axis=0) > 32767):
mixed_amp = mixed_amp * (32767/mixed_amp.max(axis=0))
clean_amp = clean_amp * (32767/mixed_amp.max(axis=0))
adjusted_noise_amp = adjusted_noise_amp * (32767/mixed_amp.max(axis=0))
noisy_wave = wave.Wave_write(args.output_noisy_file)
noisy_wave.setparams(clean_wav.getparams())
noisy_wave.writeframes(array.array('h', mixed_amp.astype(np.int16)).tostring() )
noisy_wave.close()
clean_wave = wave.Wave_write(args.output_clean_file)
clean_wave.setparams(clean_wav.getparams())
clean_wave.writeframes(array.array('h', clean_amp.astype(np.int16)).tostring() )
clean_wave.close()
noise_wave = wave.Wave_write(args.output_noise_file)
noise_wave.setparams(clean_wav.getparams())
noise_wave.writeframes(array.array('h', adjusted_noise_amp.astype(np.int16)).tostring() )
noise_wave.close()
終わりに
Deep Learningによってさまざまな音声処理の精度が上がっている一方、音声処理の分野は前提知識が複雑であったりドキュメントが少なかったりするような気がします。本記事によってより多くの人が音声処理に興味を持つようになれば幸いです。
記事の内容に何か間違い・コメントがありましたら、Github or twitterまでお願いいたします。
明日の記事は同期の玉木くんによる「SPAJAM2018 参加レポート、そしてその後の開発」です。お楽しみに!