
こんにちは、LINE でスタンプ・着せかえショップのバックエンド開発をしている川田 (@hktechno) です。
この記事は、LINE Advent Calendar 2016 の 6 日目の記事です。
今年の4月に、Java も Elasticsearch もまともに知らなかった新卒エンジニアが Elasticsearch クラスタの管理を突然任されて苦労した話をしようと思います。
Elasticsearch とは
Elasticsearch は、Elastic 社が開発している検索・分析エンジンおよびそのストレージを担うソフトウェアです。簡単に言えば、検索に特化したクエリを投げることができるデータベースのようなものです。No-SQL 型の DB といっても良いと思います。
Elasticsearch のすごいところは、大量のドキュメントの中から形態素解析や n-gram など自然言語的な解析を行った上で、素早く検索クエリを処理でき、かつノードを増やすことで簡単にスケールアウトすることができることです。最近では、Elasticsearch は様々なログの収集・分析にも使われるようになっていて、どちらかと言うとログ収集で苦労した話が多いと思います。ちなみに、私の所属しているチームでは、ログ収集・メトリック分析ツールとしても Elasticsearch を利用しています。
しかし、今回はログ収集ではなく、実際にプロダクション環境で検索エンジンおよびデータベースとして利用した場合の Elasticsearch の苦労した点について書こうと思います。このような情報はあまり多くないので、参考になれば幸いです。
LINE Shop とは
ところで、私達のチームは LINE Shop と呼ばれていて、主に LINE 内のスタンプや着せかえを担当する部署となっています。LINE を利用したことのある方であれば、有料スタンプや着せかえを販売している LINE 内のショップを見たことのある方も多いと思います。
この2つのショップと、Web 上でスタンプや着せかえを購入することができる LINE STORE は共通のバックエンドを共有しています。LINE Shop では、Elasticsearch を広範囲に利用していて、実際にみなさんがスタンプショップなどへアクセスする際の殆どのレスポンスは Elasticsearch を利用したものとなっています。
具体的にどの部分かというと...
- スタンプ・着せかえ検索
- 人気ランキング・新着などのリスト生成
- カテゴリーリスト生成
- あなたへのおすすめ

など、ただのキーワード検索用途だけではなく、ほぼすべてのリスト表示系のデータベース用途として利用しています。
LINE Shop 内部は、Armeria を使ったマイクロサービスとなっていて、大幅に単純化して説明すると以下のような構造になっています(Armeria について詳しくは LINE Developer Day の発表スライド LINE Shop powered by Armeria をご覧ください)。

内部にSearchFe というサービスが存在し、このサービスが Elasticsearch へのリクエストのフロントエンドとなってリクエストの変換やクエリ生成及びキャッシュを担当しています。
また、スタンプ向けの MySQL と着せかえ向けの MongoDB も内部では利用しており、詳細表示や購入系などのリクエストはこちらのデータベースが担当しています。
なぜ Elasticsearch を使うのか
LINE Shop で Elasticsearch を利用するモチベーションとしては、様々ではありますが代表的なものは以下の2点です。
- 内部的にスタンプと着せかえで利用しているデータベースの種類が異なる (MySQL と MongoDB) ので、これらのクエリを共通化するため
- LINE Shop で表示するリストの掲載・ソート条件は、国やデバイスタイプ、その他属性により複雑なため、柔軟なクエリを処理できる必要がある
LINE Shop の場合は、それほどドキュメント数が多くない (商品情報は 500,000 程度) こともあり、Elasticsearch の filter は柔軟にクエリを書くことができてかなり高速に動作します。
従来は、スタンプのキーワード検索用途のみに Elasticsearch を利用しており、それ以外のリスト表示には MySQL や MongoDB を利用していました。その後、僕が入社して初めて行った仕事が、着せかえの検索機能の実装だったのですが、その過程でスタンプと着せかえのデータが Elasticsearch 上で共通化されました。紆余曲折を経て、現在は検索以外のクエリもほとんど Elasticsearch に共通化され、コードもきれいになりました。
現在では、LINE Shop では 35 台のリスト表示・検索用クラスタ、9 台のログ・メトリック収集用クラスタを運用しています。リスト表示・検索用クラスタは、リクエストが多い日で Search が 1500 QPS (うち、キーワード検索は 300 QPS), Get が 400 QPS ほどのリクエストを捌いています。SearchFe で大きな割合がキャッシュされているので、実際に Elasticsearch へ向かうリクエスト数はそれほど多くはありません。
Elasticsearch 運用の注意点
さて、これまで Elasticsearch を採用した経緯について説明してきましたが、実際この移行は問題なく行われたわけではありませんでした。検索エンジンおよびデータベースとして Elasticsearch を、検索リクエストが多めの環境で運用する際の注意点を幾つか紹介したいと思います。
ここに書かれていることは、あくまで LINE Shop での環境を想定したもので、他の環境では上手くいかない、または逆効果になる場合もあるかもしれません。また、Elasticsearch のバージョンは 2.4 を前提にお話をします。
Elasticsearch クラスタのモニタリング
開発元の Elastic では、Elasticsearch をモニタリングできるソフトウェアである Marvel をリリースしています。Marvel は、シングルクラスタで運用する場合であれば、商用利用でも無料で利用できます。使ってみると Marvel は確かに便利なツールで、Search Rate や Search Latency などを監視することができます。
Marvelを運用しはじめて数日後、過負荷で Elasticsearch のレイテンシが悪化する、Slow Log が大量に発生するような状況が発生しました。ただ、残念なことに、このような時に Marvel はほとんど役に立ちませんでした。Search Latency は平均レイテンシのようで、確かに若干上昇しているように見えましたが、特に問題のあるようなグラフには見えませんでした。また、Marvel では Slow Log の回数や、エラーレートを監視することはできません。
その他の Marvel の問題点として、Elasticsearch 自体が異常に過負荷な状態になると、これすらも見ることができなくなってしまうという問題があります。そこで、我々は Marvel による監視を諦め、独自に Elasticsearch をモニタリングするスクリプトやライブラリを作って対応しています。
レイテンシに関しては、すでに LINE Shop では内部の RPC を Armeria と Dropwizard Metrics を利用してすべて Percentile のメトリックを取得し、モニタリングできるような環境が整っています。レイテンシは平均の値で見てもあまり意味がないと言うのは基本中の基本ですね。しかし、これではキャッシュされたあとの SearchFe のメトリックしか見ることができないため、Elasticsearch の Java ライブラリをラップするクラスを書いて、Percentile ごとのレイテンシが見れるような環境を整えました。
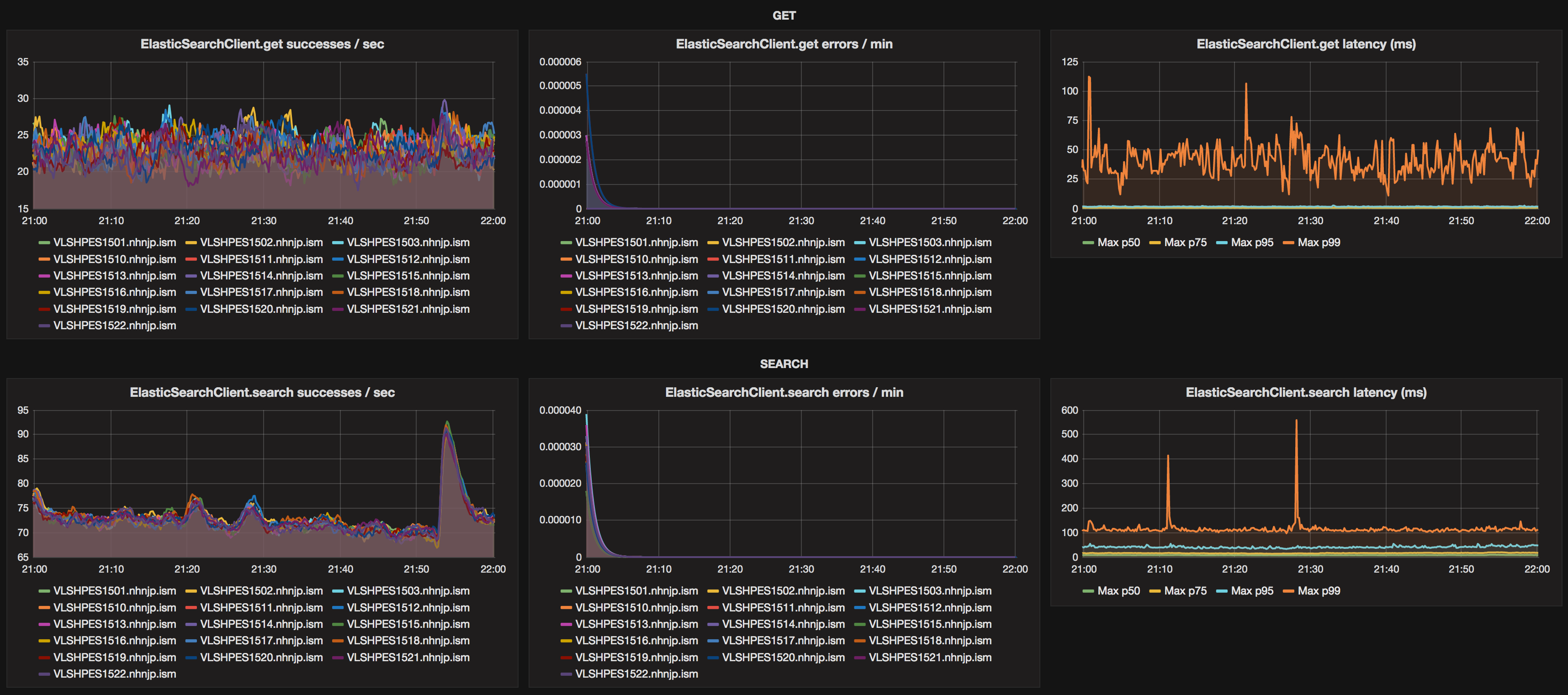
また、Slow Log は既存の社内独自のモニタリング・アラート管理ツールと連携して、Elasticsearch の Slow Log と Node Stats, GC をモニタリングするようなスクリプトを書いて対応しています。このあたりは、もっと簡単に Elasticsearch 本体で対応できるようにならないかな、と思っています。その他、クラスタの管理は kopf というプラグインを使っています。普段の管理やメンテナンスでは、非常に役に立っています。
Elasticsearch と GC
Elasticsearch のモニタリング環境が整ってくると、実際にいろいろな問題が見えるようになります。特に GC の問題が大きいです。やはり、Elasticsearch は JVM 上で動くソフトウェアですので、GC の問題は避けては通れない道です。よく問題となりそうな点や基本的なことは、Elasticsearch の公式ドキュメントでもよく解説されていますが、それ以外にも問題となる点はいくつかあります。
まず、Elasticsearch では最大 32GB のメモリをヒープに割り当てることができます。UseCompressedOops によるパフォーマンスの問題 があるため、逆にそれ以上割り当ててはいけないようです。しかし、まるまる 32GB を割り当てたとき、特に JVM のオプションをいじらずに運用すると、我々の環境では Full GC が発生した時に1 ~ 2秒ほどの STW が発生しました。これらの GC によるレイテンシの低下は、やはり Marvel ではほとんど見ることができず、Percentile でメトリックを取って p75 以上で跳ねるような形で初めて観測することができました。
実際のサービスで、レスポンスが 1 ~ 2秒返せない状態になってしまうというのは、あまり許されるような状況ではありません。特に、LINE SHop では Armeria を使って内部の RPC をほぼ非同期で行っており、レイテンシの低下を常時監視しているので、負荷が高いときは GC のたびにアラートが発生するようなことになり、非常に困りました。よく見てみると、Elasticsearch の Old 領域に貯まるオブジェクトは多くなく、それほど大きな領域は必要が無いことがわかりました。基本ではありますが、無駄にヒープを大きくするのは良くないです。適切なサイズを割り当てましょう。
また、Young GC が発生する回数やそれにかかる時間の問題も発生してきます。高負荷時は、CPU やストレージはまだまだ使い切っていないのに、Young GC 回数が上昇してクエリが詰まり始める現象に遭遇しました。そこで、様々な検証の結果、我々の環境ではNew 領域のメモリを大きめに割り当てることが良いということがわかりました。Elasticsearch は、リクエストに応じて短命なオブジェクトを大量に生成します。リクエストが多いときには、いかにこのゴミを短時間で素早く処理できるかが問題となります。我々の環境では、Eden 領域に 10 ~ 20 GB 程度のヒープを割り当てています。大きすぎるのではないかと思われる方もいるかもしれませんが、100ms ~ 200ms 程度の停止時間を許容できるのであれば、現代のマシンではこの程度でも特に問題となりません。
Elasticsearch の GC の挙動を観察していると、ほぼ Eden -> Survivor への Young GC で死に、Survivor で消滅するオブジェクトはほぼありませんでした。また Survivor は非常に少なくても問題になりませんでした。
以下は、GC をチューニングする過程で観察した GC の挙動です。Eden に 8GB 強を割り当てていますが、3秒ほどで Young GC が発生してしています。リクエスト数が増えると Eden の消費量が上昇するので、余裕を見て更にヒープサイズを拡大することになりました。
[www@LNSHPES1522:~]$ jstat -gcnew -h20 88720 1000
S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT
1083520.0 1083520.0 34973.8 0.0 6 6 541760.0 8668224.0 4373271.1 245240 16395.238
1083520.0 1083520.0 34973.8 0.0 6 6 541760.0 8668224.0 7017216.8 245240 16395.238
1083520.0 1083520.0 0.0 36451.1 6 6 541760.0 8668224.0 1208752.6 245241 16395.330
1083520.0 1083520.0 0.0 36451.1 6 6 541760.0 8668224.0 4029157.2 245241 16395.330
1083520.0 1083520.0 0.0 36451.1 6 6 541760.0 8668224.0 6662526.2 245241 16395.330
1083520.0 1083520.0 35460.5 0.0 6 6 541760.0 8668224.0 853257.6 245242 16395.413
1083520.0 1083520.0 35460.5 0.0 6 6 541760.0 8668224.0 3341362.3 245242 16395.413
1083520.0 1083520.0 35460.5 0.0 6 6 541760.0 8668224.0 6372255.3 245242 16395.413
1083520.0 1083520.0 0.0 36655.6 6 6 541760.0 8668224.0 526428.3 245243 16395.503
よって、以下のようなちょっと危なげに見える設定でも、十分に運用可能でした。これにより、高負荷時でも 5 ~ 10 秒に1回程度、100ms の Young GC が発生する程度に抑えることができました。
ES_JAVA_OPTS="-XX:NewSize=16g -XX:MaxNewSize=16g -XX:MaxTenuringThreshold=2 -XX:SurvivorRatio=30"また、Old 領域も小さくなるので、Full GC の時間も削減されます。ただし、GC のチューニングは環境によって全く異なる場合もあります。この記事を鵜呑みにせず、それぞれの実環境で、ベンチマークとモニタリングを行いながら調整することをおすすめします。
Elasticsearch と G1GC
上記の話は、Concurrent Mark and Sweep (CMS) GC においての話で、G1GC については、公式ドキュメントは利用しないように書かれています。
(https://www.elastic.co/guide/en/elasticsearch/guide/2.x/_don_8217_t_touch_these_settings.html)しかし、私達の環境で G1GC をテストしてみた所、特に悪い結果は発生せず、良い結果のように見えました。現在は、G1GC も安定しているようですし、LINE および LINE Shop では本番環境でも G1GC を一部のサーバーで採用しています。特に、G1GC は目標停止時間を設定すると自動的にチューニングしてくれるので、面倒くさい設定があまり必要ない点が素晴らしいです。
ES_JAVA_OPTS="-XX:-UseParNewGC -XX:-UseConcMarkSweepGC -XX:+UseG1GC"ちなみに、実際上記のようなオプションで運用した際、New 領域はかなり大きめに確保され、それを維持し続けていました。また、Old 領域の GC が劇的に早くなるので、ヒープを大きく割り当てている環境では非常に有効ではないでしょうか。もしかすると、これからは G1GC でも問題ないかもしれません。ただし、実運用に適用する際には、公式としておすすめしないと言っている以上、避けるべきであるかもしれません。
※ 追記: 現在のバージョンの Elasticsearch で G1GC 利用すると、Lucene の Index が壊れる場合があるようです。G1GC の利用は避けましょう。 (A Heap of Trouble - Garbage First(https://www.elastic.co/blog/a-heap-of-trouble)
急激なトラフィックに対する対応
その他に、LINE Shop 特有の問題として、急激なトラフィックに対する対応があります。LINE のスタンプは、テレビなどで特定のスタンプやスタンプの種類などが取り上げられ話題にされることもよくあり、その際には大量の急激な検索トラフィックが集中することになります。しかも、このトラフィックは 1 ~2 分の間に通常の3〜4倍のトラフィックが集中することになります。

キャッシュにヒットするようなものであればよいのですが、最近は名字・名前スタンプなどが流行しており、これらはほとんどキャッシュヒットしません。この時に、Elasticsearch のレイテンシが急激に悪化して、正常にレスポンスを返せないことが発生する問題がありました。平常時であればかなり余裕を持った台数で処理しているのですが、このような場合では 16 台のデータノードを持つクラスタでも厳しい状況で、クラスタを 32 台へ増強しました。
さらに調査してみると、急激なトラフィック流入時にクエリが急激に遅くなり、キューが詰まってリクエストが受け付けられなくなることがわかりました。また、一度キューに積まれたクエリは、それが実行されるまでキューから抜けることはありません。
遅くなる原因としては、前述の Young GC の頻発によるものや、そもそもリクエスト多すぎ問題がありますが、Elasticsearch はだんだん遅くなるのではなく、ある閾値を超えると急激に遅くなる傾向があると感じています。本当は、すべてのクエリを適切な時間で処理したいのですが、急激なトラフィック流入時には、その影響を最小限に抑える方法も重要です。よって、プロダクションで運用する際には、タイムアウトをきちんと設定すると良いでしょう。過負荷になったときは、それほど重要でないクエリや遅いクエリをバシバシ切っていくことも必要です。
タイムアウトを数 100 ms 程度に設定して、遅くなった場合に素早くエラーを返す・または一部の結果だけを返す処置をすることで、その影響を長引かせず収束させることができます。特に、LINE Shop では検索と、訪れた人がかならず見るであろうランキングや新着などのリストのクエリが混在しているので、それぞれの重要性を鑑みて影響を最小限にするタイムアウトの値を設定しています。検索のキューサイズの初期値は 1000 ですので、これを増やしてみるのも良いと思いますが、クエリが詰まっている状況ではあまり効果が期待できないと思います。
また、Elasticsearch は、ノードを増やすことで気軽にスケールアウトできるシステムですので、このような場合には素直にノードを増やしましょう。
Shard と Replica
これは、Elasticsearch の基本の話となりますが、Elasticsearch がスケールするための仕組みに、Shard と Replica があります。Index を作る際に、この数を自由に設定することができるのですが、どのように設定しているでしょうか?
なんとなく、Shard をノードの数、冗長性のために Replica を 1 に設定している方が多いと思います。しかしこの設定は、Indexing が多い環境と Search が多い環境では設定が異なり、これに設定すれば絶対安全という設定はありません。基本的には、調整しながらベンチマークを行う必要があるのですが、大体の傾向としては以下の様なシンプルなものです。
- まず、Indexing が多くて問題になる場合には Shard の数を増やしましょう、Replica の数は最小限にしましょう。
- 逆に、Search が多くて問題になる場合には、Replica の数を増やしましょう。
LINE Shop で運用しているクラスタでは、ほぼ検索クエリであるため、32 台のデータノードを持つクラスタで Shard の数を 2, Replica の数を 32 に設定しています。検索対象の Document の量が、メモリ上に乗り切る数 GB 程度なので、このような設定が一番良いパフォーマンスを示しました。このような環境では、Shard の数を増やすと検索パフォーマンスが悪化します。Document の量が多くなると、全く状況は異なると思うので、環境に応じたチューニングが必要だと思います。
まとめ
- LINE スタンプ・着せかえショップは Elasticsearch を様々な場面で利用しています。
- Elasticsearch は、気軽に扱えて、柔軟な検索機能を簡単に提供できるデータベースで、スケールするので、大変使いやすいです。
- ただし、実運用では色々問題にも遭遇するので、モニタリングがしっかりできる環境を整えると良いと思います。
- 最近 Elasticsearch 5.0 がリリースされました。こちらにも期待ですね。
また、LINE では新卒エンジニアを募集しています。LINE では、新卒でも十分に実務で実力を発揮でき、LINE のコアな開発に携わることができる環境が整っています。LINE Shop でも、2人の新卒入社のエンジニアがコードレビューで日々熱い戦いを繰り広げています。ぜひエントリーしてね!
明日は Inami さんによる「SwiftでElmを作る」についての記事です。お楽しみに!