
Verda室ネットワーク開発チームの田口です。私は2019年にLINEに新卒入社して、プライベートクラウド「Verda」に関わるネットワークの開発・運用を行なっています。先日、8月19日に開催されたLINE Developer Meetup #67では、『ネットワーク機能のベンチマーク自動化』というタイトルで発表を行いました。発表では、以下の3点に関してご紹介をしました。

上記のうち、1つ目の『ロードバランサのベンチマーク自動化』に関しては、過去のブログポストに背景からシステム概要まで説明していますので、そちらをご参照ください。この記事は、主に3つ目の『性能問題の切り分けにもベンチマークが役に立つ』のフォローアップを目的としており、当日紹介した内容に加えて、TSOの基本動作の解説と、D-Plane検証ツールの使い方にも触れています。どちらも、Meetup本編では省略した部分ですので、当日参加して頂いた方は、その部分だけでも見て頂けますと嬉しいです。
背景
Verdaでは、金融系などのセキュリティ要件が高いサービス等をネットワーク的に分離するため、マルチテナンシー機能をサポートしています。そして、このマルチテナンシー機能では、SRv6を利用してオーバレイを実現しています。また、VerdaのSRv6データプレーンにはトラフィックの中継を行う「ネットワークノード」と「ハイパーバイザノード」の二種類があり、どちらも、LinuxカーネルのSRv6実装を利用しています。(LINEでのSRv6導入事例はLINE Developer DayやJANOGで詳しく説明されていますのでそちらの資料もご参照ください)本記事では、主にハイパーバイザノードを対象にしています。
SRv6の性能問題
SRv6のマルチテナンシー環境は、パケット転送性能が低いことがローンチ前から既に分かっていました。実際に計測してみると転送速度は1 Gbps程度で、従来のシングルテナント環境(*1)の1/10程度の性能でした。このままでは、ネットワークヘビーなアプリケーションをマルチテナント環境で動作させるのは難しいような状況でした。
そのような状況もあり、どうにかして性能向上が達成できないかと、SRv6高速化の候補の検証を行うことになりました。候補には、以下のようなものがありました。
- VPP
- XDPのデータプレーンを自作(*2)
- ハードウェアオフローディング
ベンチマークを行なった結果、VPPやXDPを利用することで性能向上は期待できることは確認できましたが、ハイパーバイザノードでは既存のC-Planeとの連携問題があり、切り替えが難しいことが分かりました。
その後、ちょうどNICベンダの協力により、新たにSRv6パケットのTCPセグメンテーションオフロード(TSO)機能が追加されました。TSO機能は、パケットをMTU以下に分割するTCPセグメンテーション処理をNIC上で行う機能です。通常、TSOはカーネルで実行されますが、NICが対応することでオフロード出来ます。TSOを有効にできれば、既存のC-Planeを変更せずに性能向上が期待できるため、TSOの動作検証を行うことなりました。
(*1): SRv6を利用していないPure L3ネットワーク
(*2): https://engineering.linecorp.com/ja/blog/intern2019-report-infra/
TSOの基礎
検証の詳細に入る前に、TSOの基本をおさらいしたいと思います。アプリケーションから送信されたデータのサイズがMTUを超えている場合、そのままのサイズではネットワーク上に送出できないので、事前にパケットを分割する必要があります。この分割処理をセグメンテーションと呼びます。そして、TSOはこの分割処理をカーネル内で行う代わりに、NICハードウェアにオフロードするものです。SRv6パケットに対するTSO処理を以下の概念図にまとめました。

通常は、Appから送信されたデータは、アプリケーションに近い位置でセグメンテーションされ、各レイヤのパケット処理が適用されます。(図の左側)。しかし、この方式には問題があります。パケットは早い段階で分割されるので、ノード内で処理するパケット数が増加し、合計の転送オーバヘッドが増加してしまうのです。そこで、TSOに対応したNICを利用していれば(図の右側)、ノード内ではセグメンテーションせず、最後にNIC上でハードウェアTSOされます。これで、ノード内での転送オーバヘッドを削減できます。
TSOの仕組み
Linuxカーネルは、sk_buffに付与されているTSOフラグと、ネットワークインタフェース (net_device) 側のフィーチャーフラグを突き合わせて、TSOが可能かを判断しています。このTSOフラグとは、内部的にはgso_typeと呼ばれており、「どの種類のTSO/GSOでパケットをセグメンテーションすることを期待しているか」を示しています。一方、net_device側は、どのgso_typeをサポートしているかの情報をフィーチャーフラグとして持っています。SRv6パケットは、実際にはIPv4(v6)パケットがIPv6ヘッダによってカプセル化されているものとみなすことができます。そして、この形式のパケットのgso_typeはSKB_GSO_IPXIP6という名前で登録されています。つまり、net_deviceが、SKB_GSO_IPXIP6をサポートしていれば、カーネルはSRv6パケットに対してTSOを行おうとします。
なお、net_deviceが、パケットに付与されているgso_typeをサポートしていない場合、セグメンテーション処理はKernelによってソフトウェアで処理されます。この、Kernel内部で行われるTSOは、GSOと呼ばれています。
受信側のTSO
Linuxでは、送信パケットだけでなく、受信パケットに対しても同様にTSO機能が働いています。受信パケットはまずキューイングされ、複数TCPセグメントを一つの大きなパケットに集約してから受信処理されます。この処理はLarge Receive Offload (LRO) と呼ばれています。集約されたパケットは、できる限り集約されたまま転送されますが、ノード内のnet_deviceが特定のgso_typeをサポートしていない場合は、GSOにフォールバックされ、セグメンテーションされる可能性があります。例えば、適切に設定されたハイパーバイザでは、受信パケットはNICで集約され、そのままVMまで集約されたラージパケットのまま転送することが出来ます。
ベンチマークでTSOの効果を確認
本題に戻ります。TSOの効果を確認するため、検証環境を用意してベンチマークを行いました。テストにはトラフィックジェネレータ(iperf)と、SRv6ノードを用意し、各インターフェースのTSO設定やMTUを変更しながら転送性能を計測しました。パラメータの組み合わせは膨大で、手動変更するのは現実的ではなかったため、全てAnsibleを使ってテストを自動化しました。
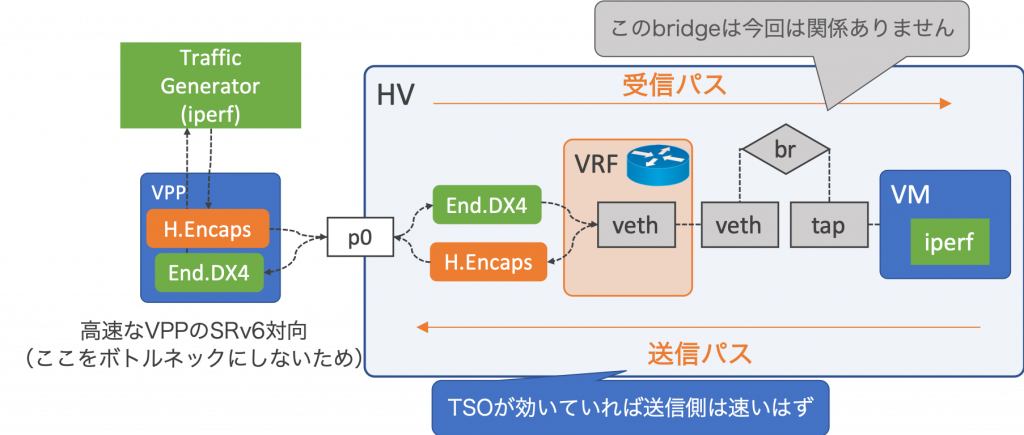
テスト環境の概要は以下の通りです。これは、Verdaのハイパーバイザを模した環境を再現したもので、受信性能と送信性能を別々に計測できるため、通信のボトルネックを見つけやすくなっています。
もし、TSOが期待通り動作していれば、送信性能が向上しているはずです。では、実際の計測結果を見てみます。緑色の囲み部分が、マルチテナント環境の性能です。
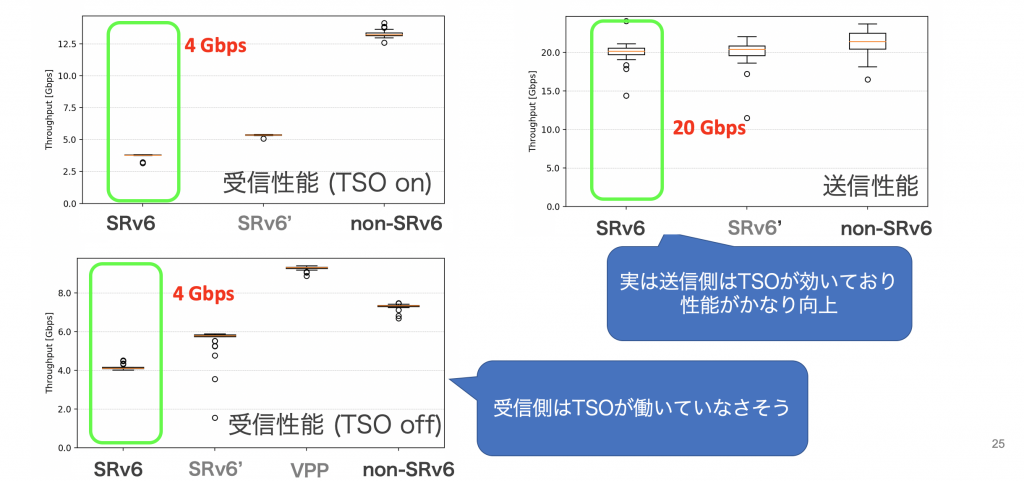
受信性能と送信性能を比較してみると、送信性能は十分に高く、TSOがちゃんと動作していることが分かりました。一方で、受信側は、TSO有効・無効にかかわらず性能が低く、こちらがボトルネックになっていることが判明しました。その後、パケットサイズをトレースすることで、受信パケットがSRv6のDecap処理後に予期せずセグメンテーションされていることがわかりました。どうやら、これが受信側のボトルネックの原因です。
さらに、根本的な問題を特定するために、カーネル内部のトレーシングを行うことにしました。
ipftrace2
ちょうどこの検証を行っていた際、私と同じネットワーク開発チームの同僚が、ipftrace2(link: https://github.com/YutaroHayakawa/ipftrace2)というツールをOSSとして開発していました。ipftrace2はeBPFを利用したLinux Kernelのトレーサで、以下の特徴があります。
- パケットが処理された関数呼び出しをトレースできる
- sk_buffに付与されているメンバをダンプできる
今回の検証では、「TSOフラグが意図した通りに設定されているか」を調査するためにこのipftraceを利用しました。
ipftrace2の使い方
ipftrace2を使って効率よくトレースする際には、以下の3点を意識する必要があります。
- どのフローのパケットをトレースするか
- どの関数をトレースするか
- どのsk_buffのメンバをトレースするか
まず1について、目的のパケットのみをトレース対象とすることで、動作を高速化したり、トレース結果を目視しやすくします。ipftrace2では、sk_buffのmarkというメンバに任意の値が設定されているパケットのみをトレース対象とします。このmarkはiptables(もしくはtcなど)を利用して変更できます。
今回の例では、トラフィックジェネレータから送信されたTCPパケット(src_ip: 172.19.0.1)のみを対象とすれば良いので、以下のようなmark付与ルールを作っておきます。
$ sudo iptables -A PREROUTING -t raw -s 172.19.0.1 -j MARK --set-mark 0xdeadbeef2つ目は、トレースする関数を制限することです。以下のように正規表現で関数名をマッチさせることで、トレースする関数をフィルターでき、高速化できます。今回の例ではなるべく多くの関数を表示させたかったので、フィルターは使用しませんでした。
# 例です。今回はフィルターは利用していません。
$ sudo ipft -m 0xdeadbeef -r "ip_.*"3つ目にあげた、sk_buffのメンバの確認を行うには、基本的にカスタムスクリプトを作成する必要がありますが、幸いなことに、TSOに関するフラグはgso.luaというモジュールを利用することで確認可能です。
トレース開始のコマンドは以下のようになります。
$ sudo ipft -m 0xdeadbeef -s scripts/gso.luaトレース結果
実際にipftrace2を使ってトレースした結果を抜粋して掲載します。なお、トレースされているパケットはSRv6のDecap処理が終わった後の、*通常のTCP/IPパケット*であることに注意してください。
(これは旧バージョンでのトレース結果です。最新版ではトレースの見た目が異なります。)
172.21.0.2:9999
Time Stamp Function Custom Data
(省略)
1532576675752 dev_queue_xmit (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576677842 netdev_core_pick_tx (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576679916 validate_xmit_skb (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576681597 netif_skb_features (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576683369 skb_network_protocol (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576685820 __skb_gso_segment (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576687404 skb_mac_gso_segment (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576688856 skb_network_protocol (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576690916 inet_gso_segment (len: 4148 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576692727 tcp_gso_segment (len: 4128 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576694495 skb_segment (len: 4096 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576695977 skb_network_protocol (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576702708 consume_skb (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576704340 skb_release_head_state (len: 4162 gso_size: 1448 gso_segs: 3 gso_type: SKB_GSO_TCPV4|SKB_GSO_IPXIP6)
1532576706183 dev_hard_start_xmit (len: 1514 gso_size: 0 gso_segs: 0 gso_type: ) <= SKB_GSO_IPXIP6が消えた。つまりIPXIP6のGSOが働いた
1532576707746 vrf_xmit (len: 1514 gso_size: 0 gso_segs: 0 gso_type: ) <= 別のVRFにルーティング
上記の結果から、以下のようなことが言えます。
- vrfデバイスにフォワーディングされるところまでトレースされている
- dev_hard_start_xmitまでSKB_GSO_TCPV4とSKB_GSO_IPXIP6フラグが付与されている
- dev_hard_start_xmitでセグメンテーションされ、パケットサイズが小さくなっている
ここで注目するべきは、gso_typeです。設定されている2つのフラグはそれぞれ、以下のような意味を持っています。
- SKB_GSO_TCPV4: TCPパケットに対するTSOを期待する
- SKB_GSO_IPXIP6: IPv6でカプセル化されたパケットに対するTSOを期待する
SKB_GSO_TCPV4が付与されていることは問題ありませんが、SKB_GSO_IPXIP6が付与さていることは問題です。なぜなら、このパケットは既にDecap処理された後のIPv4パケットで、SRv6パケットではないからです。
問題解決 & Contribution for Linux Kernel
最後は、カーネルのソースコードを確認しました。ソースコードを確認すると、以下の2点が、根本的な問題であることが分かりました。
- SRv6のEnd.DX4処理中で本来行うはずのSKB_GSO_IPXIP6フラグの削除処理が存在しない
- VRFデバイスはSKB_GSO_IPXIP6フラグが付与されたパケットのTSOをサポートしていない
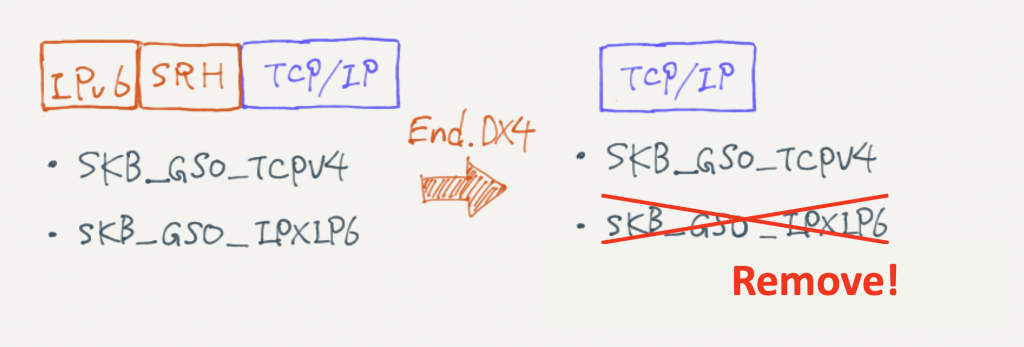
作成した修正パッチは数行でした。下の図のように、End.DX4の処理後に、IPトンネリングに関するTSOフラグを削除するような処理を入れることで、VRFでの意図しないセグメンテーションを防ぐことが出来ました。このパッチはKernelにアップストリームして、既に取り込まれています。(https://github.com/torvalds/linux/commit/62ebaeaedee7591c257543d040677a60e35c7aec)
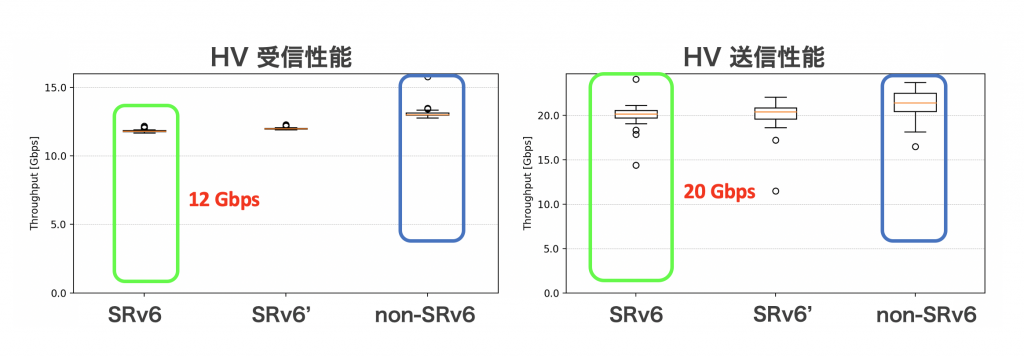
このパッチを適用することで、パケットはVMまでセグメンテーションされずに到達することが可能になりました。パッチ適用後に改めてベンチマークした結果を掲載します。iperfで計測した単一TCPフローの性能です。結果から、マルチテナント環境の性能(左図の緑枠)が約3倍の12 Gbpsまで向上しています。これは、Pure-L3のシングルテナント環境の性能(青色)と同程度です。
まとめ
この記事では、SRv6の検証を通して、TSOの詳細やKernelネットワークのトレース方法に関して説明しました。TSOは、ハードウェアやLinux Kernelに密接に関わる部分なので検証が難しく、十分な検証を行わないまま無効化してしまう例が多いと思います。しかし、今回の事例から、ベンチマークやKernel内部のトレースを的確に行うことで、TSOが性能向上に役立てられることを示せたと思います。
Verdaネットワークでは、SRv6に限らず、Kernelベースの比較的新しい機能を利用しており、この記事で紹介したようなKernel内部の検証を行うことがあります。この記事を通して、Verdaに関連したネットワーク開発に興味を持っていただけると嬉しいです。