
Data Labs データサイエンティストのIdeです。
Data LabsはLINEのメッセンジャーを含めた全ファミリーサービスのデータの分析・研究・応用のための専門的な開発組織です。私の所属するData Scienceチームでは、最新の知見を業務に取り入れるべく論文の紹介や研究会への参加などを積極的に行なっています。
その一貫として、技術に関連する海外カンファレンスに会社負担で参加できる制度を利用して、2019年5月13日〜17日に開催された国際会議The Web Conference 2019に聴講参加してきた内容について報告します。
Overview
The Web Conferenceは、web分野のトップカンファレンスです。International World Wide Web Conference(通称WWW)が2018年の開催から改称されました。28回目の開催にあたる今年のThe Web Conference 2019はサンフランシスコで開催されました。

The Web Conferenceでは、コンピュータサイエンス、計算社会科学、経済学、政策、その他多くの研究分野の視点から、Webの現状と発展に焦点を当てた研究が発表されます。会議スケジュールは、前半2日間に23のWorkshopと22のTutorial、後半3日間に12のResearch TrackやPoster Session、Keynoteが開催される構成でした。
Opening Ceremonyにて発表された今年の採択率が以下です。フルペーパーは18.04%、ショートペーパーは19.94%の採択率でした。投稿件数の多いトピックは「Web Mining and Content Analysis」、「Social Network Analysis and Graph Algorithms」、「User Modeling, Personalization, and Experience」でした。

Closing CeremonyではAwardの発表がありました。
Best Paperは「Emoji-Powered Representation Learning for Cross-Lingual Sentiment Classification」「OUTGUARD: Detecting In-Browser Covert Cryptocurrency Mining in the Wild」の2件、Best Short Paperは「ViTOR: Learning to Rank Webpages Based on Visual Features」でした。Best Posterは「Demographic Inference and Representative Population Estimates from Multilingual Social Media Data」でした。
以下で、参加したTutorial・Keynoteの内容とResearch Track・Poster Sessionで気になった発表を紹介します。
Tutorial
Tutorial: A/B Testing at Scale: Accelerating Software Innovation
1日目はMicrosoftのAnalysis&ExperimentationチームがオーガナイズするA/B Testing at Scale: Accelerating Software Innovationというチュートリアルに参加しました。
データサイエンティストの業務の一つとしてA/Bテストの設計や評価があります。A/Bテストの結果はサービスの意思決定に直結するため、非常に重要な業務の一つです。2017年のKDDでは、MicrosoftのA/Bテストで得られた知見からA/Bテストにまつわる陥りやすい12個の誤解について言及した「A Dirty Dozen: Twelve Common Metric Interpretation Pitfalls in Online Controlled Experiments」という論文が発表されています。この論文の著者の方は、今回のチュートリアルのオーガナイザーに含まれています。以前から本論文をA/Bテストの設計・評価時に参考にしていた背景もあり、更なるアップデートを期待しこのチュートリアルに参加しました。

具体的な事例を交えたA/Bテストの概要説明から指標設計、経験ベイズまで、A/Bテストに関連する幅広いトピックが取り上げられました。複数のトピックで正しいOEC(Overall Evaluation Criteria: A/Bテストの結果を評価するメトリクス)の重要性が強調されていたのが印象に残っています。また、A/Bテストでの判断基準として用いられる統計的仮説検定(NHST:Null Hypothesis Significance Testing)に関して、ベイズ的アプローチによるp-valueのcalibrationや、リアルタイムでの意思決定を可能にするベイジアン仮説検定に関する話題があり、今後A/Bテストをよりロバストに実施していくにあたって、興味深い内容でした。
一方で、チュートリアル中には、2つのUIに対してOECが高いと思われる方に全員が挙手をして予想を示し、正解した人から座るという和やかなシーンもありました。3回のクイズを終えても3分の1程度の方が起立しており、最適なUIを主観的に判断することの難しさを実感できる機会でした。Microsoftが提供する検索エンジンBingでは月に1,000以上のA/Bテストが走っているとのことで、チュートリアルでは多くのユーザーを抱えるサービスの裏側に徹底的なデータに基づいた改善を垣間みることができました。
Tutorial: Online User Engagement: Metrics and Optimization
2日目はSpotifyのリサーチディレクターとエンジニアリングディレクターによるOnline User Engagement: Metrics and Optimizationというチュートリアルに参加しました。
サービス改善において、ユーザーエクスペリエンスの質の定量化は不可欠です。しかし、サービスの特性によって測定するべきエンゲージメントの指標は異なるため、ナレッジの共有が難しいトピックでもあります。このチュートリアルはオンラインのユーザーエンゲージメントの定量化に関して体系的にまとまっており、KPIモニタリングやA/Bテストの指標設計に参考になる内容でした。ケーススタディも検索・ニュース・EC・エンタメ・広告まで幅広く、Spotifyの事例も登場しました。

Metricsのトピックでは、耐久性を測定するセッション内指標と習慣やロイヤリティを測定するセッション間指標の2つの枠組みで、オンラインユーザーの指標の体系的な整理が行われました。各指標に関して具体的な事例が用意され、事例をもとに各指標がどういったエンゲージメントを測定しているのか緻密な議論が行われました。
Optimizationのトピックでは、人手による最適化(仮説-実験-評価のサイクルを行うA/Bテスト)と自動最適化(オンライン学習・多腕バンディット・強化学習)、加えて両者を組みわせた最適化手法について取り上げられました。A/Bテストにおけるテスト開始から意思決定までの時間コストや、ユーザーを静的に割り当てることに対する機会損失に対して、この問題の解決にあたる逐次検定と多腕バンディットを組み合わせた方法論(WSDM2019にて発表された論文)が紹介されました。Optimizationは機械学習、統計、経済学、制御理論など複数分野の方法論が活用され、得られる知見が多いトピックです。紹介された論文についても引き続きチーム内で共有したいと考えています。
Research Track
Track: Recommendation
GhostLink: Mining Latent Influence Networks for Influence-aware Item Recommendation(Slides)
Amazonとミュンヘン工科大学の著者による、ユーザー間の潜在的な影響ネットワークをレビュー投稿から学習する確率的グラフィカルモデルGhostLinkが提案されました。
どんなものか
ユーザーが他人の好みや評価に影響を受けるように、オンラインでも社会的影響力は重要な役割を果たします。既存研究にソーシャルネットワークを利用した推薦システムはあるものの、Amazonを始めとした多くのオンラインサイトでは明示的なユーザー間のリンクはありません。この研究では、レビュー投稿の内容とレビュー時のタイムスタンプから確率的グラフィカルモデルを構築し、レビューコミュニティに存在する影響ネットワークの学習をします。4つのデータセット(BeerAdvocate、RateBeer、Amazon Movies、Amazon Food)で検証された結果、ユーザーのアイテム評価の予測について既存手法から23%の改善があったと報告され、ユーザーの影響ネットワークが推薦システムの精度向上に有用であることが分かりました。
技術・手法のポイント
ベースとなる考え方はLDA(Latent Dirichlet Allocation)に従っており、LDAで文書の生成過程の背後にあるとするトピック分布を、GhostLinkではファセットプリファレンス(文書から抽出される嗜好性)分布として言い換えています。ユーザーが他のユーザーから影響を受ける時、その影響はファセットプリファレンスに反映されます。この前提をもとに、ユーザーのレビューが自身のファセットプリファレンス分布または、以前に書かれていたレビューのファセットプリファレンス分布から生成されるとしたトピックモデルを提案しています。
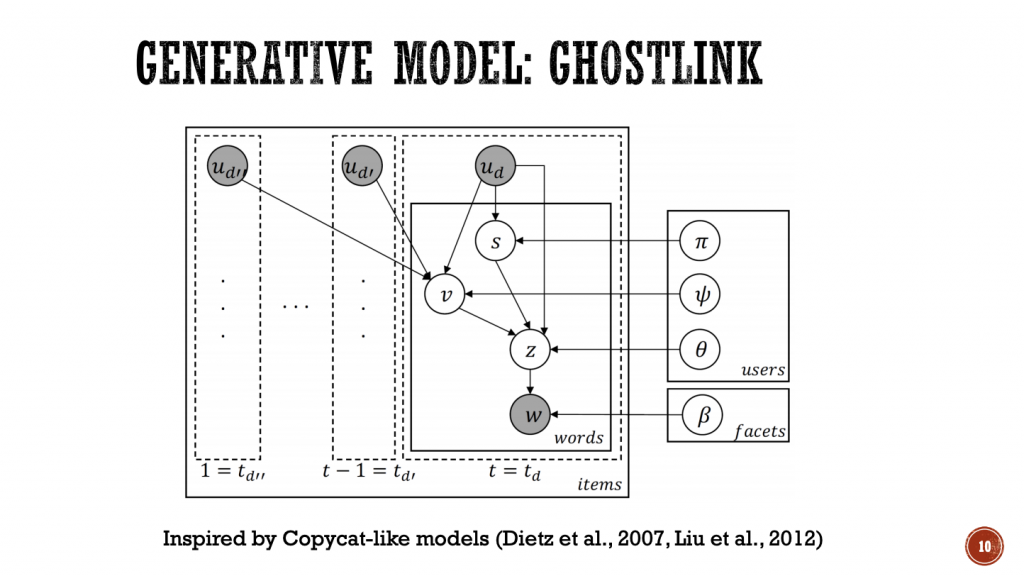
ユースケース
ユーザー発信のコンテンツは増える一方であり、個人ユーザーの影響力がパーソナライズされたリコメンドよりも強力にコンバージョンに効いてくるケースも今後増えるように思います。そういった流れの中、推薦システムのトラックでユーザーの影響力に言及した発表があったのは非常に印象的でした。また、ユーザー間のネットワークデータがないデータに対して潜在的なネットワークを学習している点も応用性が高いと感じました。ユーザー同士が影響する現象は現実世界でも多く、そういった現象に対しても本論文を応用して潜在的なネットワークを学習することができるのではないかと期待が高まりました。
Track: Knowledge Analysis and Querying
Google Dataset Search: Building a search engine for datasets in an open Web ecosystem
Googleから2018年9月にリリースされたデータセット検索エンジンGoogle Dataset Searchについて内側の仕組みを解説する論文が発表されました。
どんなものか
Web上には何千ものアクセス可能なデータセットリポジトリが存在しますが、膨大さと専門性故に通常の検索エンジンからアクセスされるデータセットは一部に集中し、検索結果に上がらないデータセットが多く存在しました。Web上で公開されるデータセットの多くは提供者によってメタデータが付与されており、本研究ではこのメタデータを集計、正規化、調整することで、散在するデータセットを一つのプラットフォームで容易に検索することが可能になりました。
技術・手法のポイント
メタデータの正規化では、提供者によって形式が異なる(ex.日付の形式、緯度経度の混同など)メタデータを、形式の異なるパターンを把握して同じ形式に変換するアダプタを作成しています。また、複数リポジトリに同一のデータが存在する場合は、クラスター化しメタデータをグラフ上に保持することによって、ユーザーがデータに対してリポジトリの選択をすることを可能にしています。
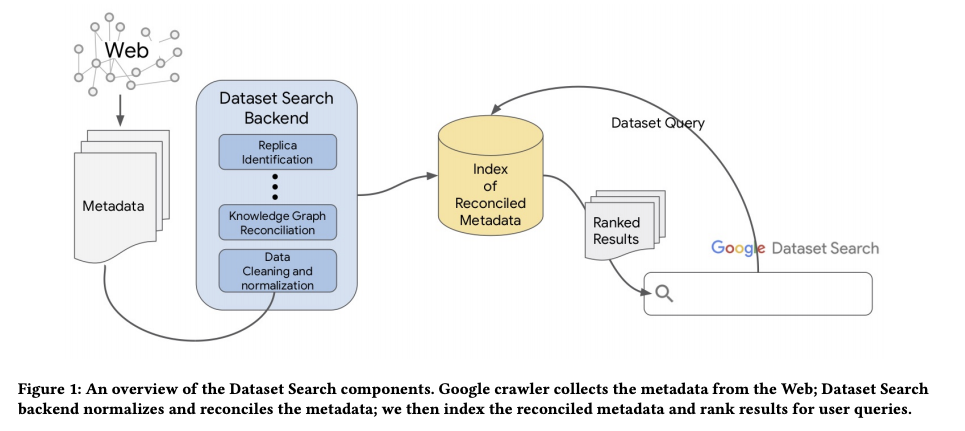
研究のインパクト
研究データリポジトリのレジストリであるre3data.orgに登録されているだけでも、その数は2,000リポジトリを超えています。リポジトリ間の枠を超えた検索によって、よりデータセットへのアクセスが容易になり、既存研究の再現やニッチなデータセットへの研究の開拓など、多くの研究の可能性が拓かれた発表でした。
Track: Personalization
Dynamic Ensemble of Contextual Bandits to Satisfy Users' Changing Interests
バージニア大学とSnap Inc.の著者による論文で、ユーザーの関心の非連続な変化に適応するコンテキスチュアルバンディットの提案がされました。
どんなものか
既存研究における非連続な変化に対応するバンディットアルゴリズムでは、定常状態のコンテキスト情報は活用できていませんでした。この論文では、定常状態のコンテキスト情報も報酬推定に使うと同時に不連続な変化にも適応できる、よりロバストなコンテキスチュアルバンディットの提案がされました。
技術・手法のポイント
コンテキスチュアルバンディットモデル(論文中のBandit expert)の集合を保持し、各expertの報酬評価の推定品質をモニタリングするBandit auditorを導入した点です。コンテキスチュアルバンディットの集合を利用して、定常状態の報酬分布を保持し続けています。一方で、各expertの報酬推定の品質をモニタリング(論文中のBandit auditor)し、閾値を超えた推定ができている場合のみexpertを採用し、選ばれたexpertの集合によって最も推定報酬の高いアームが選ばれます。このBandit auditorによって不連続な変化を速やかに検出しモデルに反映することができています。提案手法であるDenBand(Dynamic Ensemble of Bandit Experts)がその他のアルゴリズムと比較して大幅にCTRが改善される結果が、3つのデータセットを用いた検証で得られていました。

ユースケース
ニュースを始めマンガやミュージックなどトレンドに左右されるコンテンツでは、いち早くユーザーの関心の変化に気付き反映する必要があります。合成データでのbaselineとの比較では、変化点の検出が実際の変化とほぼ一致しており、かつ適応のスピードも早く、トレンドの変化が速い領域においても効率良く最適なコンテンツを表示できる期待が高まる発表でした。
Track: Text Classification and Relation Extraction
Emoji-Powered Representation Learning for Cross-Lingual Sentiment Classification
今年のBest Paperを受賞した論文です。北京大学、カリフォルニア大学、ミシガン大学の共著論文です。
どんなものか
この問題の背景は、感情分類に利用されるラベル付きのデータの量が言語ごとに不均衡であるが故に異なる言語間で感情分類に品質の偏りが生じていることです。既存研究では、豊富なラベル付きのデータがある言語からラベル付きのデータが少ない言語へ機械翻訳ツールを通して表現を転送していましたが、対象言語固有の感情の知識を捉えることができない課題がありました。この論文では、絵文字予測を用いた表現学習を行い、学習された表現を利用して異なる言語間での感情分類のパフォーマンスを改善しました。
技術・手法のポイント
絵文字による表現学習のフレームワークELSA(Emoji-powered representation learning for cross-Lingual Sentiment Analysis)が提案されました。まず最初にソース言語(豊富なラベル付きのデータがある言語)とターゲット言語(ラベル付きのデータが少ない言語)で表現学習をしています。具体的には、この表現学習でツイートからWord Embedding(単語をベクトル空間に写像する)を行い、さらに絵文字を抽出したツイートを使って文中で使用される絵文字を予測しています。このプロセスで絵文字を代替感情ラベルとしてみなすことができるようになります。最終的に、2つの言語の学習された表現を利用してターゲット言語の感情ラベルを予測し、分類器として機能します。
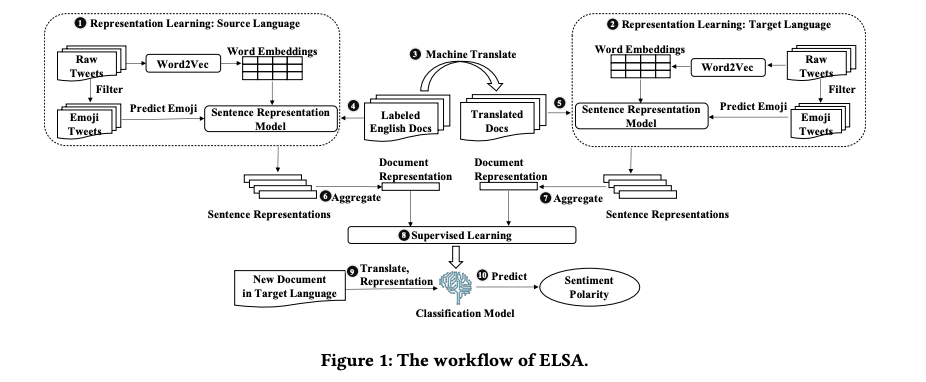
研究のインパクト
N-ELSA(ELSAから絵文字予測のプロセスを排除したもの)との結果の比較では、attentionの高い単語がN-ELSAでは中立的な単語に集中している一方で、ELSAでは感情的な単語に集中していたことから、絵文字を利用したことが感情表現の学習に効果的であったことが分かります。カンファレンス中にはEmoji 2019: 2nd International Workshop on Emoji Understanding and Applications in Social Mediaというワークショップもありました(1回目の昨年度はAAAI(アメリカ人工知能学会)のワークショップとして開催されました)。本論文がBest Paperを受賞したことも含め、絵文字に関する学術研究がトップカンファレンスで存在感を増していることを再認識しました。

Poster Session
Demographic Inference and Representative Population Estimates from Multilingual Social Media Data
Poster会場で常に人集りが絶えることのない一際注目度の高いポスターがあったのが印象に残っておりますが、今回そのポスターがBest Posterを受賞していました。
Twitterのプロフィール情報(プロフィール画像・ユーザー名・スクリーン名・プロフィール文)から属性情報(性別・年代・個人or組織)を推定し、その推定した属性情報に基づいてヨーロッパ地域の人口推定を行なった研究です。特筆すべき点は、既存の属性推定の技術の大半は入力となるプロフィール情報が単一言語に限定されるものでしたが、この研究では32の言語で動作するアーキテクチャを作成したという点です。多言語のプロフィールから属性推定を行うM3モデルと、地域による属性の偏りを補正するマルチレベルの回帰モデルを組み合わせ、より正確な人口推定に成功したという内容です。実際にTwitterアカウントから属性情報の推定を行うDemoページも公開されています。ポスターは人口推定を行なったヨーロッパ地域の地図を背景にしたデザインでした。
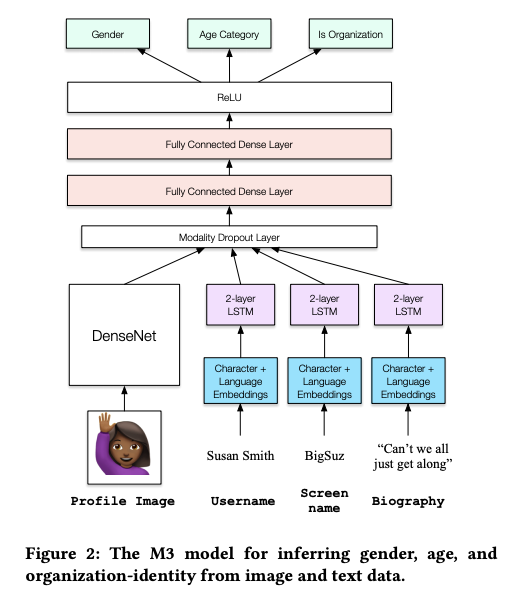
Keynote
Keynoteでは、Google AIのリードであるJeff Deanから「Deep Learning for Solving Important Problems」というタイトルで講演が行われました。直近数年間のGoogle AIから発表された論文やオープンソースを振り返る内容でした。以下に講演内で取り上げられた話題を抜粋して紹介します。
- JAMA(The Journal of the American Medical Association)にて掲載された研究成果:ヘルスケア領域でのディープラーニング活用例として、糖尿病網膜症の病変検出の精度向上に貢献した論文が紹介されました。
- BERT(Bidirectional Encoder Representations from Transformers):昨年Googleから公開され、自然言語処理の研究タスクに汎用的に使える言語モデルであると大きな話題となりました。
- AutoML(Automated Machine Learning):機械学習の専門知識を持たずとも適切なモデル構築を可能とする研究領域です。Googleが提供するCloud AutoMLも話題に上がりました。
- TPU(Tensor Processing Unit):ディープラーニングには計算環境が重要であるという話題と共に、ディープラーニングの高速化を目的としてGoogleが開発したプロセッサが紹介されました。
このKeynoteはカンファレンス会場の最も広い会場で開催されましたが、会場の後方には入り口から溢れるほどの聴衆が集まり、その注目度の高さがうかがえました。YouTubeでも動画が公開されています。興味がある方はこちらKeynote : Jeff Deanも併せてご参照ください。

おわりに
WWWは毎年面白い研究が発表される場として学生時代から憧れていたカンファレンスだったので、企業にいながら聴講という形でも参加することができ、非常に貴重な経験となりました。
今回The Web Conferenceに参加して強く印象に残っているのは、多くの発表が大学と企業の共同研究であった点です。上記のResearch Trackの論文紹介においても大学と企業の共同研究の論文を2件紹介しましたが、企業のデータがアカデミックな場所で研究対象として発表されるのは非常にいい流れだと感じました。スポンサーにも日常的に利用しているサービスの企業が多く名を連ねていました。企業が積極的にこういったカンファレンスを支援し、企業と大学の垣根無く最新のリサーチについてディスカションされる場が成熟している点に強く刺激を受けました。変化の速い業界であるからこそ、今後もあらゆるサービスや研究動向に触れることで幅広い視野を保っていきたいと思います。

Data LabsのData Scienceチームでは、データサイエンティストを積極的に募集しています。最新の研究動向を学んで業務に活かせる機会がたくさんありますので、興味のある方はぜひ応募をご検討ください。