
はじめに
こんにちは、LINEで機械学習エンジニアを担当している久保です。この記事はLINE Advent Calendar2016の14記事目です。 今回の記事は、機械学習の(勾配などの)基本的な知識を持ち、Sparkにおける機械学習に興味がある人向けの内容となっています。
Sparkは大規模なデータのための分散処理フレームワークとして人気があり、弊社でも機械学習関連の開発において利用しています。 弊社では機械学習の特徴量の元となるデータがHDFSに格納されているため、それらを容易に読み込むことができる親和性の高さと、分散処理のコードが容易に実装できる所がSparkを利用する上での大きな魅力となっています。
具体的な利用方法として、例えば機械学習エンジンに入力する特徴量を作成するためのETL(抽出、変換、ロード)処理に利用しています。 また、LINE STOREにおける着せ替えの商品ページの右枠にあるアイテムベースのレコメンドやLINEアプリ内でLINE NEWSを立ち上げた際にトップ画面に出てくる「FOR YOU」枠のためのユーザベースのレコメンドなどにおいて、Sparkの機械学習ライブラリであるMLlibを用いてモデルの学習を行っています。
しかし、機械学習の扱うモデルのパラメータが巨大であったり、オンライン学習やミニバッチ学習により短い時間で良いモデルを求めたいケースにおいて、Sparkの分散処理フレームワークだけで機械学習手法を実装することが難しくなります。本記事では、まずSparkの分散処理フレームワーク上で実装できる機械学習の実装パターンを取り上げます。そして、それらの実装パターンにおいて払わなければならないデータ転送のコストに触れ、Sparkによる機械学習において向いている手法と向いていない手法を解説します。また、向いていない手法を実現するという課題に対してLINEにおけるMPI(Message Passing Interface)を使った事例をご紹介したいと思います。なお、こちらに記載されている内容はSpark 1.6に基づいています。
Sparkの分散処理フレームワークにおける機械学習
Sparkの分散処理フレームワーク上で実装できる機械学習の実装パターンを以下のテーブルに示します。 また、それらの実装パターンがSparkの機械学習ライブラリであるMLlibに実装されている手法のどれに採用されているかも示します。 ちなみに、Sparkは複数のTaskをWorkerに発行して、その結果を受け取る一台のSpark Driver(以後、Driver)と、Workerの役割を果たし、一台で複数のTaskを処理する複数台のSpark Executor(以後、Executor)からなります。
上記の実装パターンはパラメータや木の構造などを繰り返し更新していく手法を対象としており、 例外として繰り返しパラメータを更新する必要がないMLlibのNaive Bayesなどがあります。 モデルの情報を繰り返し更新する必要がない手法は計算量が比較的少ないため、今回の記事では取り扱いません。
Sparkのデータ転送の実装とコスト
上記の表のNo. 1、2、4の実装パターンではDriverとExecutorとの間でモデルのパラメータや勾配などの情報をやり取りすることが多くなり、No. 3、4ではExecutor間でやり取りすることが多くなります。Sparkにおける各転送方向ごとの実装について簡単にまとめた表を以下に示します。NはExecutorの数を表します。
| 転送方向 | 実装 | ディスクIO | 転送元と転送先の関係 |
|---|---|---|---|
| Driver→Executor | Broadcast、Closure | 無(場合により有) | 1:N |
| Executor→Driver | Aggregation Function | 無(関数により有) | N:1 or log(N):1 |
| Executor→Executor | Shuffle | 有 | N:N |
1対NやN対1の転送では1台のサーバに高い負荷がかかる一方で、log(N)対1やN対Nの転送ではディスクへのアクセスが起こってしまうというトレードオフがあります。以下において、より詳細な転送方向ごとの実装と掛かるコストについて解説します。
DriverからExecutorへの転送 - Broadcast、Closure
BroadcastはTask間で共通のデータ(現在のパラメータなど)をDriverから各Executorに一つだけ転送するSparkの機能です。Taskとして実行されるClosure(関数オブジェクト)に共通のデータを直接埋め込むと、Executorに対してTaskの数だけ共通データが転送されることになるため、これを避けるためにBroadcastが利用されます。
Broadcastでモデルのパラメータを転送する場合、Driverと各Executorのメモリ上でそれを持つ必要があり、サーバ1台に収まらないような巨大なパラメータ数は扱えません。また、単純なBroadcastの実装だとDriverから全Executorにデータを転送しないといけないため、1台しかないDriverの通信コストが高くなります。前者の問題は後述するShuffleの利用を考えないといけません。後者はSparkにすでに実装され、デフォルトになっているTorrentBroadcastにより改善されます。
TorrentBroadcastは、まずDriver側で転送対象のオブジェクトをシリアライズして複数のpieceに分割します。そして、あるデータがどのノードにあるかを知らせるBlockManagerMasterに対してDriverが各pieceを所持していることを伝えます。各Executorはランダムな順番でpieceを取得していきます。BlockManagerMasterに現在対象のpieceを持つ全ノードを聞き出し、ランダムで取得するノードを選んでpieceを取得します。その後、そのpieceを所持していることをBlockManagerMasterに伝えます。全てのpieceを取得した後、それらを合わせてデシリアライズして転送オブジェクトを取得します。各Executorがpieceを取得していくにつれ、Executorがまだ取得していないpieceを他のExecutorが所持している可能性が高まるため、Driverの通信負荷が小さくなるという仕組みです。
TorrentBroadcastは分割されたpieceと転送オブジェクトの二つを最終的にメモリ上に持つ必要があります(足りない場合はディスクに書き込まれます)。機械学習のモデルのパラメータは浮動小数点の巨大な配列で表されるため、シリアライズによるメモリ削減は期待できず、pieceの合計サイズと転送オブジェクトのサイズは同じくらいになり、転送オブジェクトのおよそ2倍のデータ量をDriverと各Executorで持つというコストを払わなければなりません。
ExecutorからDriverへの転送 - Aggregation Function
ここでAggregation FunctionとはSparkが提供しているreduce関数やaggregate関数のことで、これらはまずExecutor内で各Taskの結果を指定した方法で集約していき、その集約結果をDriverに送ります。Driverはこの集約結果をExecutorの数だけ受け取り、指定された方法でそれらを集約してきます。そのため、Executorの数が多くなり、また結果のデータが大きくなればなるほど、Driverにそれを受け取る通信コストと、結果をデシリアライズして集約していく計算コストが大きく掛かります。
これに関して、一台しかないDriverへの高負荷を避けるために、treeReduce関数やtreeAggregate関数がSparkで提供されています。これはDriverをRoot Node、結果を所持するExecutorをLeaf Nodeとして、木構造のように段階的に集約を行っていく関数です。Internal NodeはExecutorになるため、Driverに送られる集約結果の数が少なくなります。しかし、Executor間での転送が起こるため、代償としてこの後紹介するShuffleによる高コストをExecutor側が払わないといといけないトレードオフがあります。
ExecutorからExecutorへの転送 - Shuffle
Shuffleの説明の前に、Sparkの分散処理の実行について説明します。ユーザは分散処理の手続きを書き、それを一つのJobとしてSparkに実行させます。 1つのJobは1つ以上のStageからなり、1つのStageは複数のTaskからなります。同じStage内の各Taskは互いに依存せずExecutorにおいて並列に実行されます。しかし、同じJob内の各Stageは依存関係を持っており、あるStageの全Taskが終わらないと、それに依存するStageの実行は開始されません。
Shuffleは依存関係のあるStage間で行われます。Shuffleのために、依存されているStageのTaskではKey-Value形式のデータを返すIteratorを生成し、そのKey-ValueデータをシリアライズしてShuffleファイルとしてディスクに書き込みます。依存しているStageのどのTaskに送るかはKeyによって決まるため、書き込みの際、転送先のTask(いわゆるReducer)が同じKey-ValueをSortまたはHashを使ってまとめておきます。Stageの全Taskが終了するとそれに依存しているStageのReducerの役割を果たすTaskを開始できます。それらのReducerは担当のKey-Valueデータをディスクに所持している各Executorに対してリクエストを投げ、それらを取得、デシリアライズしながら処理を適用していきます。
上記からShuffleはシリアライズ・デシリアライズのコストやディスク書き込み・読み込みコスト、帯域コストが掛かり、また転送はStageの全Taskが終了して、それに依存するStageが開始されるまで行われないため同期コストが掛かります。また、ShuffleがSortかHashかによってもコストは変わってきます。SortによるShuffle(Default)はIteratorの要素を全て実体化し、Sortを行い、Sort済みのデータを格納したDataファイルとそのファイルのどの位置からどの位置までがどのReducerにあたるかを格納したIndexファイルの二つを各Taskにおいて作成します。この方法は要素を全て実体化するためメモリに負荷が掛かります。メモリが限界に来た時は、Spill機能により途中までのSort済みのデータをディスクに一時ファイルとして書き込み、後でMerge SortによりSpillされたSort結果を統合していきながら全体がSortされたファイルを作成します(この後一時ファイルが削除されます)。一方でHashによるShuffleは各Taskにおいて、Iteratorの要素を一つずつ実体化していき、Hash Tableに格納された対応するファイルに書き込んでいくため、メモリ負荷がSortに比べて小さくなります。しかし、各Taskごとに最大で全Reducerの数だけファイルを作成し、ランダムで要素の書き込みを行うので、シーケンシャルに書き込めるSortと比べて書き込み速度が遅くなります。また、ファイルシステムによってはファイル数の増大による性能低下が無視できなくなります。こうなるとディスクに書き込まずメモリ内だけでShuffleして欲しいと思うのですが、SPARK SUMMIT EUROPE 2016において In-memory Shuffleが提案されており、まだ研究段階であるようです。このことから、現段階においてShuffle(ExecutorからExecutorへの転送)はできるだけ避けるのが定石となっています。
ちなみにJobが終了するまでディスクに書き込まれたShuffleのファイルは削除されません(正確にはJob終了後、GCがDriverにおいて行われたタイミングで削除されます)。例えばアイテムのレート情報などユーザのExplicit feedbackを学習するALSでは現在のパラメータから新しいパラメータを更新するために学習回数に比例して再帰的にShuffleを繰り返す巨大な一つのJobを実行したりします。このJobにおいてパラメータの更新のたびにパラメータが書かれたShuffleファイルが作成され、それが削除されないままディスクを圧迫していくという問題が起こります。ディスクの圧迫を避けるため、Checkpoint(モデルの途中結果の保存)を定期的にいれて、Jobをこまめに実行する必要があったりします。
向いている手法、向いていない手法
前節のコストを基に考えると、Driverを動かすサーバが高スペックまたは他の負荷が高いプログラムが同時刻に動いていない状態で、かつ帯域を大きく使ってもいい環境であれば、各TaskでGradientを求めてDriverにおいてパラメータを更新するバッチ学習(No. 1の実装パターン)が向いている手法として挙げられます。この場合、モデルパラメータがBroadcast可能なサイズである必要があります。また、Executorにおいて書き込み・読み込み性能が高いディスクを使っており、複数のディスクをShuffleの書き込み先として指定している環境であればNo. 3の実装パターンによる手法も向いていると思います。
No. 1、3が向いている環境であればNo. 4の実装パターンによる手法も向いていると思います。一方で、向いていない手法としてはオンライン学習・ミニバッチ学習や、ディスクへの書き込み・読み込みの性能が高くない環境でのNo. 3、4の実装パターンによる手法が挙げられます。No. 2の実装パターンではオンライン学習またはミニバッチ学習を各Taskで行っていますが、局所解が多く存在する複雑なモデルでは各Taskが別々の局所最適解に向かう可能性が高くなり、Driver側でそれを統合するとそれぞれ目指していた局所最適解から遠のくため収束が遅くなり、得られる精度も低くなる可能性があります。これを防ぐため、各Task間でモデルのパラメータの同期を細かく行い、向かうべき局所解を合わせたいところです。しかし、SparkはTaskの処理途中でのExecutor間のデータの転送手段を提供していないため、これを実現できません。そのため、Sparkはこの手法には向いていないと考えられます。
Spark+MPI+ZeroMQによる機械学習
Sparkが向いていない機械学習手法を実現するために、機械学習チームの並川が開発したSpark+MPI+ZeroMQによる機械学習をご紹介したいと思います。
MPIは分散メモリ間の通信規格であり、これを用いて並列処理を行うプロセスをここではMPIプロセスとします。 ここで紹介する実装ではSparkのExecutorをデータ提供者として、組み込みネットワークライブラリZeroMQにより、MPIプロセスに学習データを送信し、MPIプロセス上でパラメータの学習を行います。
MPIはNode間をまたいで学習に関する情報(パラメータや勾配)を任意のタイミングでやり取りできるため、ShuffleによるDiskアクセス、Spark Driverへのパラメータや勾配の集約を避けることができ、こまめにパラメータを同期することも可能です。 これによりパラメータ数が膨大であったり、オンライン学習またはミニバッチ学習で学習速度を速めたいケースであっても柔軟に対応することができます。また、学習処理をExecutorから切り離すことで、データのETL処理を行うExecutorには通常のコモディティ化されたサーバを使い、 パラメータの学習を行うサーバでは例えばGPUが搭載された機械学習用サーバを選択することも可能になります。
以下で流れを解説します。 ちなみに弊社では機械学習用のSparkのCluster ManagerとしてMesosを採用しているため、Cluster ManagerをMesosとして解説します。
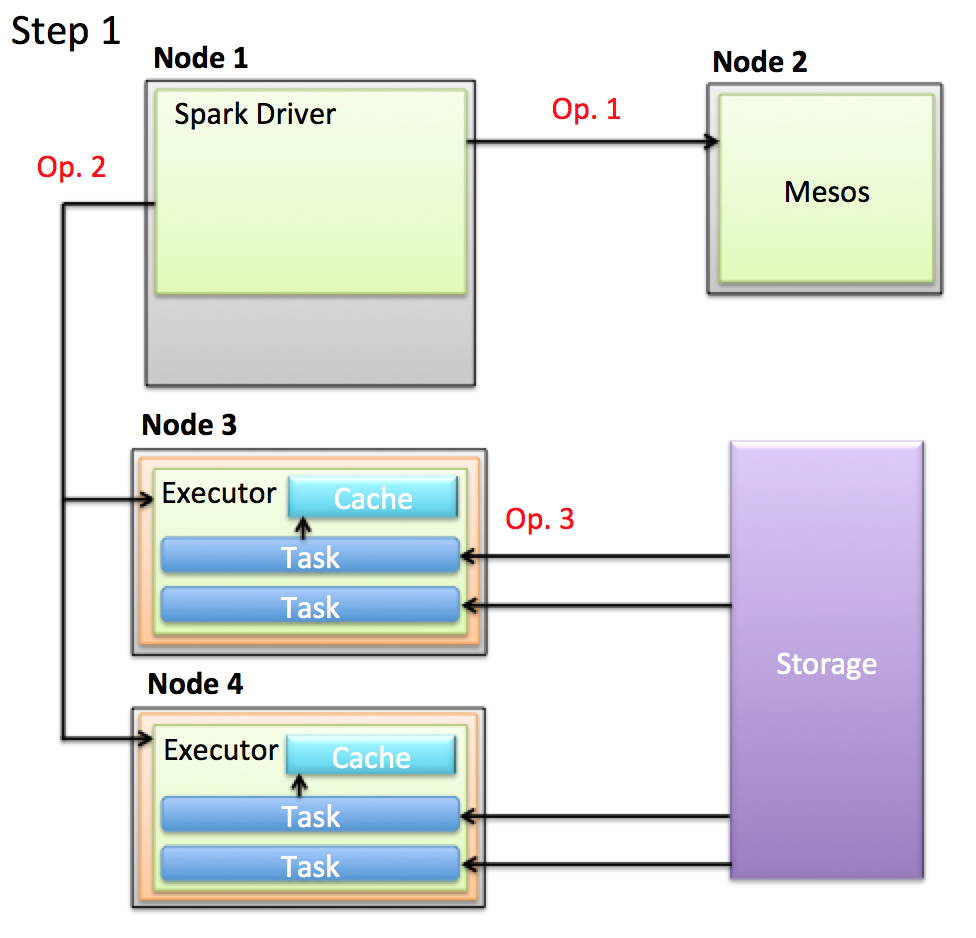
- Op. 1: Driverが新しいCPUとメモリが制限されたNode(以後、Resource)をMesosから取得し、Executorを起動します。
- Op. 2: DriverがExecutorにTaskを発行します。
- Op. 3: 各TaskはHDFSなどのStorageから学習に扱うデータを取得、ETL処理を行い、それをCacheします。
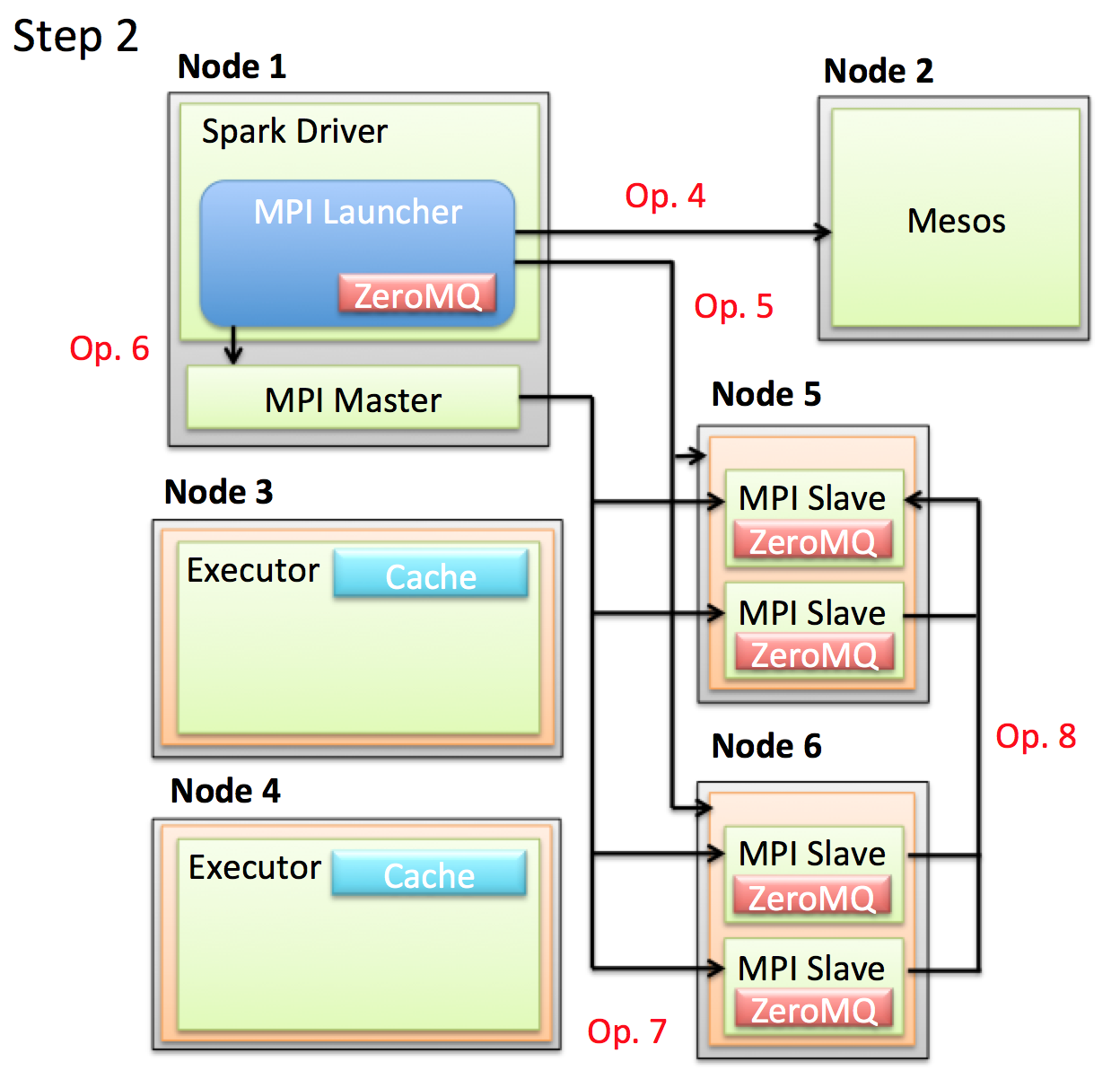
- Op. 4: Driver内でMPI Masterを起動するためのインスタンス(左図のMPI Launcher)を生成します。 これはSparkの機能を使わずにMesosからResourceを取得します。
- Op. 5: MPI Master起動のため指定した数のResourceを全て取得するまで待ちます。一定時間で指定した数のResourceが取得できない場合は、すでに取得したResourceを一旦解放して再リトライします。
- Op. 6: 指定した数のResourceを取得できるとMPI Masterを起動します。
- Op. 7: MPI Masterは取得したResource上でMPI Slaveを起動させます。
- Op. 8: MPI Slaveは起動するとZeroMQを立ち上げ、自身のZeroMQのAddressを代表のMPI Slaveに送ります。
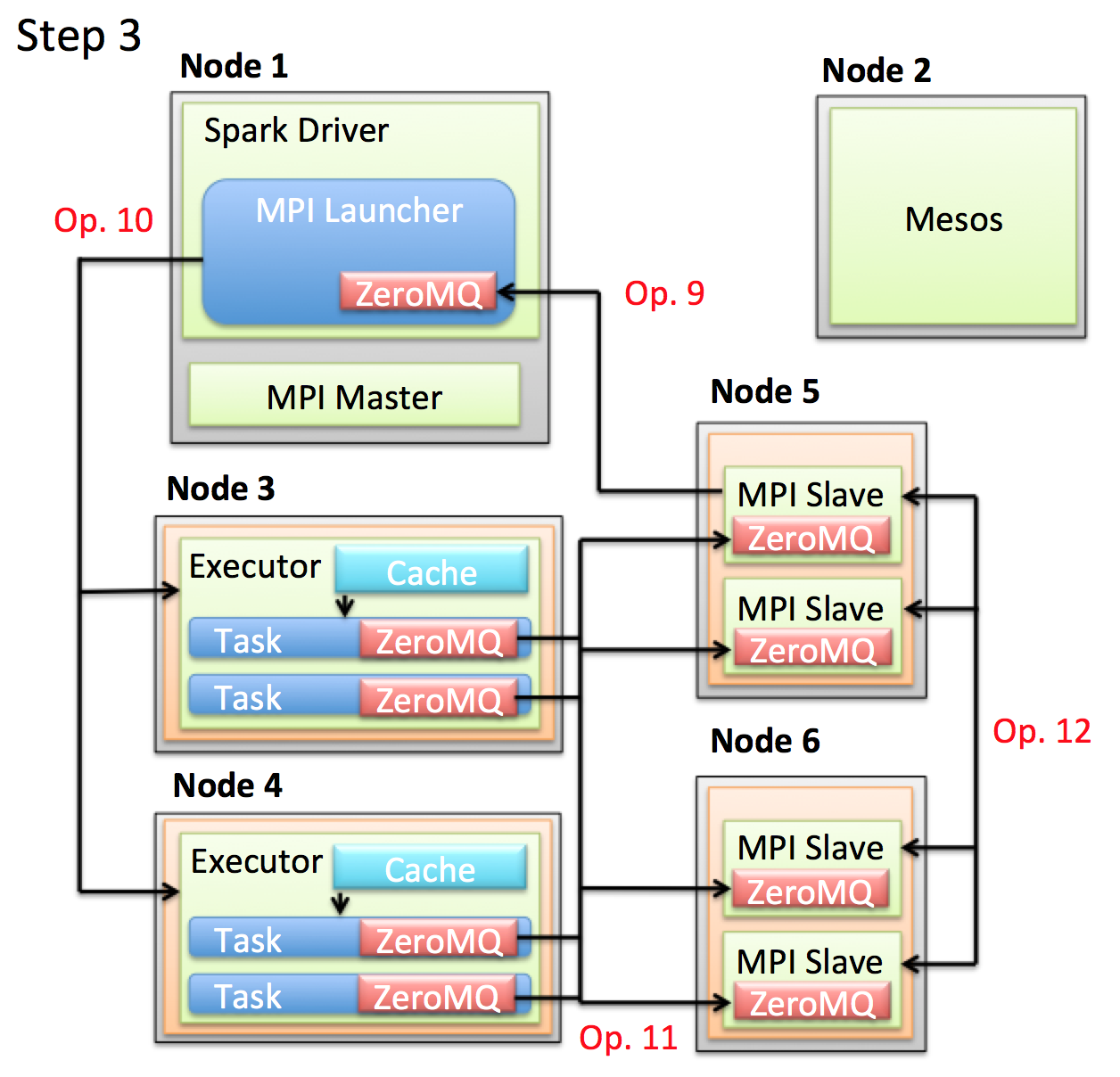
- Op. 9: 代表のMPI Slaveが各MPI Slaveから送られてきたAddress をDriverに送ります。DriverはResponseとしてMPIを使用したモデルを学習するための関数を返し、代表のMPI Slaveはこの学習関数を他のMPI Slaveに送信します。
- Op. 10: Driverは送られてきた全AddressをExecutorに送ると共に新しいTaskを発行します。
- Op. 11: 各Taskは担当のデータをCacheから取り出し、送られてきたAddressに対してそれらを送信します。
- Op. 12: 事前に受け取った学習関数と受け取ったデータによりパラメータを学習します。
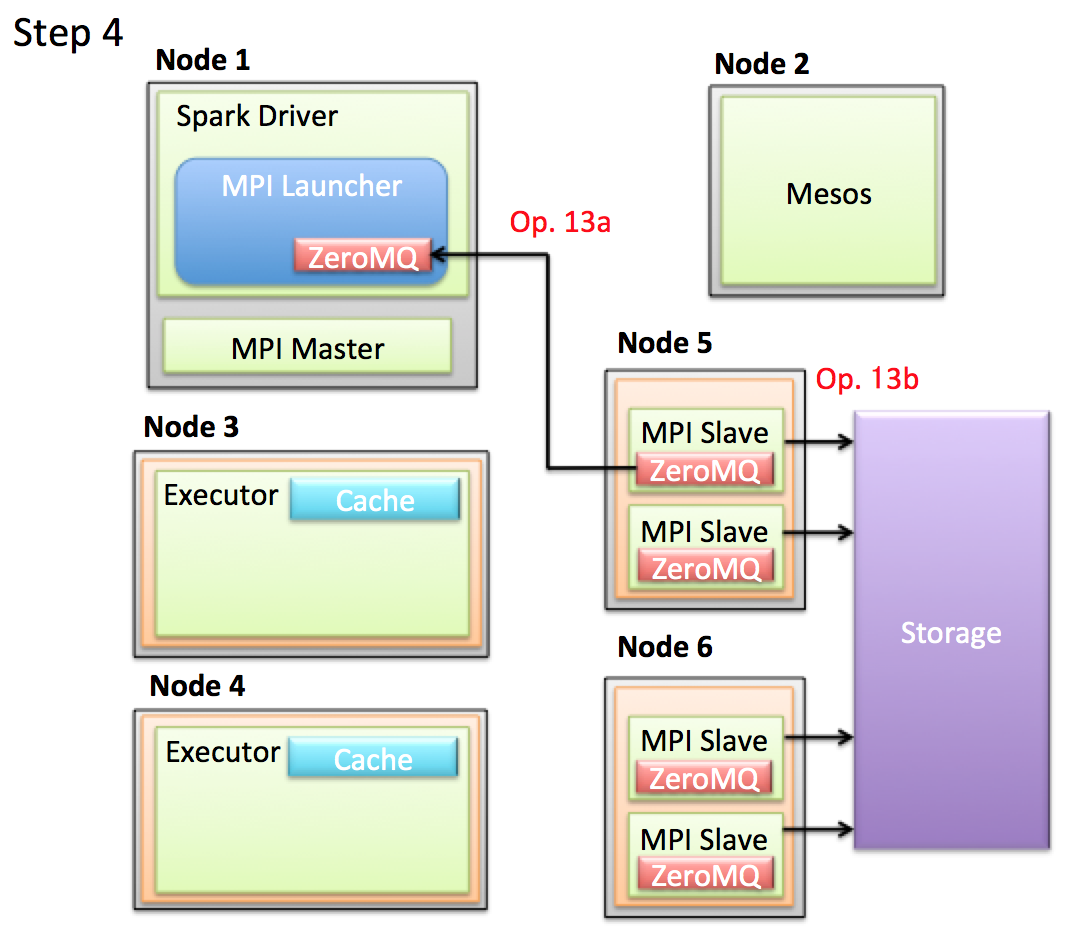
- Op. 13a: 代表のMPI Slaveが学習後のパラメータをZeroMQ経由でDriverに返します。その後このパラメータを使って予測などを行います。
- Op. 13b: パラメータがDriverに送れないほど巨大なケースでは、各MPI Slaveが担当のパラメータをHDFSなどのStorageに保存し、その後各Executorが担当のパラメータを読みだして予測するなどの方法をとることも可能です。
上記の解説の通り、MPIにより分散処理化された機械学習アルゴリズムを実装し、それをOp. 9においてSlaveに送ることで、Sparkが向いていない機械学習手法を実現することができます。
おわりに
今回はSparkにおける機械学習の実装において、その実装パターンと払わなければならないデータ転送のコスト、Sparkによる機械学習において向いている手法と向いていない手法を解説しました。 また、向いていない手法を実現するという課題に対してSpark+MPI+ZeroMQをご紹介しました。
Spark+MPI+ZeroMQでは学習部分を完全にMPIに委譲しています。このケースにおいても、Sparkを利用するのは特徴量を準備するためのETL処理が簡単に書けて手放せなくなっているということと、予測時は学習時と比べてExecutor間でパラメータをやり取りするケースが少ないため、Sparkの分散処理フレームワークを使って簡単に実装することができることが理由として挙げられます。
今後に関して、2016年に開催されたSPARK SUMMITとSPARK SUMMIT EUROPEを見ると、今回実装した方法以外にParameter Serverという別のアプローチで同じ課題に取り組んでいる発表がいくつか見られます。 そのため、Future WorkとしてこのParameter Serverの実装と評価を行えたらなと考えております。
ここまで読んだ忍耐力のある機械学習好きの方、弊社では機械学習エンジニアを募集しております。 是非ご応募ください。
明日は@overlastさんによる記事「新語・固有表現に強い「mecab-ipadic-NEologd」の効果を調べてみた」です。お楽しみに!