
こんにちは、LINE の Android Client を開発している munetoshi です。
この記事は LINE Advent Calendar2016 の 2 日目の記事です。
レビュアーを探すスクリプトを作りました
皆さん、元気にコードレビューをしていますか?レビューはしっかり行いたいものですが、適したレビュアーを見つけるのって面倒ですよね。 特にチームの人数が多い場合、私みたいな引きこもり系エンジニアには、誰が何を担当しているのかを完全に把握するのは難しいです。その割に、私は広く浅くコードに触れることも多いので、"これって誰にレビューしてもらえばいいのかなー" と途方に暮れることもあります。弊社ではコード管理に git/GitHub を使っているので、git history や blame を見ればいいのでしょうけれど、プルリクエストを作るたびにその作業をするのは骨が折れます。
そこで、 git history をたどってレビュアーに適した人を探し出すスクリプト"suggest_reviewer" を作ることにしました。
で、どうやってレビュアーを探すのさ
基本的には、git history を使ってレビュアー探すのですが、このとき以下の条件を満たすようにします。
- 変更されたファイルに詳しい人が、レビュアーとして選出される。
- 変更されたすべてのファイルで、レビュアーの誰かがレビューできる。
- 無駄にレビュアーを増やさない。
これを実現する方法を大雑把に説明します。まず 1 を満たすため、ファイルごとにコミット数が多い人を何人か選び、その人をレビュアー候補とします。次に 2 を満たすため、各ファイルのレビュアー候補から一人ずつレビュアーとして選出します。このとき 3 を満たすように、多くのファイルに詳しい人を優先的に選出します。
例えば、 file1 と file2 が変更された場合を想定します。ここで、A さんが両方のファイルにたくさんコミットしているなら、 A さんがレビュアーとして選出されれば十分です。もし、 file1 は A さんだけが、 file2 は B さんだけがコミットしている場合、A さんと B さんの両方がレビュアーとして選出される必要があります。
これを、あまり時間をかけずにサクッと作りたいので、git の他、ruby や基本的な UNIX コマンドは使えることを前提にします。ただ、やはりサクッと他の人 (含む Jenkins) に使ってもらうため、 RubyGems とかは使わないようにします。
で、サクッと作りました
ここに ruby スクリプトをおいておきました。なかなかふんわりサクサクに仕上がったと思います。使い方は suggest_reviewer --help を見てください...ではあんまりなので、軽く説明します。
まず、 git のレポジトリに移動します。ここで、 HEAD~3 から HEAD の差分に対応するレビュアーを探したい場合、
suggest_reviewer HEAD~3 HEADとすれば、
author1@example.com
dir1/file1
dir1/file2
author2@example.com
dir2/file3とか出力されるはずです。これの意味するところは、 author1 は file1 と file2 をレビュー可能で、 author2 は file3 をレビュー可能ということです。 このスクリプトは内部的に git diff を使っているので、 リビジョン番号 0123ab を使って suggest_reviwer 0123ab としたり、ブランチ名 branch1, branch2 を使って suggest_reviwer branch1..branch2 とすることも可能です。
もし、author1 と author2 が休暇中でレビューできない場合は、-e オプションを使って
suggest_reviewer -e author1,author2 HEAD~3 HEADとカンマ区切りで指定すれば、author1 と author2 を除外してレビュアーを選出します。部分一致なので気をつけてください。
また、特定のディレクトリやファイルに対してレビュアーを探したい場合は、
suggest_reviewer -p dir1/file1 dir1/file2と、-p オプションでパスを指定できます。
本来の使い方とは異なりますが、以下のようにすると近々 1000 コミットでのコミット数ランキングを表示できます。
suggest_reviewer -p . -m -d -h 1000各オプションの説明は --help を見てください。. をテストディレクトリに変えて、テストをよく書く人ランキングを見たりすると面白いかもしれません。
で、これどうやって実装したの?
このスクリプトで行っていることをおさらいすると、"各ファイルごとにレビュアー候補を決め、多くのファイルに詳しい候補をレビュアーとして選出する"となります。これを実装するには、以下のことを決めなくてはいけません。
- 各ファイルのレビュアー候補の決め方
- "多くのファイルに詳しいレビュアー候補" の定義
- レビュアー候補からレビュアーを選出するアルゴリズム
今回はこれらを愚直な方法で実装しました。つまり、次節以降はその愚直な方法を説明するだけです。読み飛ばしても構いません。
まずは、各ファイルのレビュアー候補の決め方を説明します。
1. 各ファイルのレビュアー候補の決め方
先述したとおり、各ファイルごとの git history を使って、コミット数の多い人をレビュアー候補にします。このとき、以下のしきい値をつかいます。
h: git history の深さ(リビジョンの数)。デフォルトで 100。c: 各ファイルごとのレビュアー候補の上限。デフォルトで 10。
h と c を使ってレビュアー候補の決め方を説明すると、次のようになります。
- 目的のファイルの git history を近々
h件取得し、コミットした人ごとにコミット数を求める。 - 1 をソートし、コミット数上位
cに入る人をレビュアー候補とする。
h を使っているのは、全履歴を取得すると時間がかかるのに加え、"昔よく触っていたファイルのレビュアーになったけれど、その後他の人がたくさん変更したからレビューできない!"という状況を防ぐ意味があります。また、 c を使っているのも、"フォーマッタをかけたら、たくさんのファイルを変更した扱いになって、レビュアーとして選出されてしまった!"という状況を回避する目的があります。
今回、git blame の行数ではなく git history のコミット数を使っているのも同じ理由です。そうしないと、フォーマッタをかけたり、表面的なリファクタリングをした場合、blame の行数が大きくなってしまい、詳しくないファイルのレビュアーとして選出されてしまいます。こうなると、私みたいなリファクタリング大好き人間がとばっちりを喰らいます。
これで、各ファイルのレビュアー候補が決まりました。ここから、レビュアーを選出するためには"多くのファイルに詳しいレビュアー候補"を探さなくてはいけないため、それを次節で定義します。
2. "多くのファイルに詳しいレビュアー候補" の定義
やはり愚直に決めましょう。レビュアー候補 candidate のファイルの集合 Files に対するスコア score(candidate, Files) を定義し、その値が大きい人が "多くのファイルに詳しい" とします。そのお膳立てとして、まずは commits(candidate, file) と top_commits(file) を以下のように定義します。

コミットという単語がゲシュタルト崩壊しそうですが、基本的にはコミット数を表しているだけです。 commits(candidate, file) 関数において、レビュアー候補でない場合も定義しているのは、後の一巡を買うためです。
この commits(candidate, file) を使って、 単一のファイル file に対する candidate のスコア score(candidate, file) を次のように定義します。
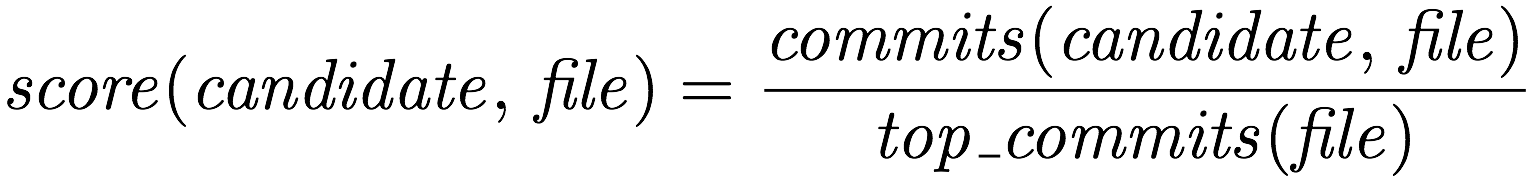
この score(candidate, file) を一言で言うと、 "最大値が 1 になるようにコミット数を正規化している" という意味になります。 特に深い意味はないので、適当に変えても良いと思います。 例えば、対数をとってみても良いかもしれません。
この score(candidate, file) を、変更されたファイルの集合 Files で合計したものを、score(candidate, Files) と定義します。形式的には次のようになります。
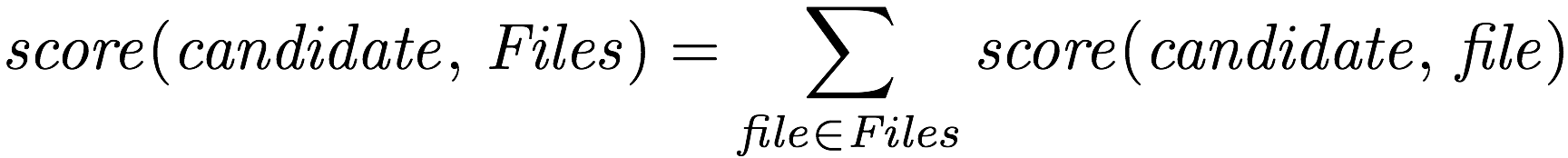
たくさんのファイルにたくさんのコミットをするとこのスコアが上がるはずなので、 "多くのファイルに詳しい" を定義できたといえます。 そうです。この節は、コミット数をスコアにしているということを、 回りくどく言っているだけでした。
この score(candidate, Files) 関数を基準に、レビュアーを選出するのですが、そのアルゴリズムを次節で説明します。
3. レビュアー候補からレビュアーを選出するアルゴリズム
レビュアーを選出するときに気をつけることは、"変更されたすべてのファイルで、レビュアーの誰かがレビューできる" という条件です。この条件は、 score(candidate, file) と、レビュアー集合 Reviewers、変更されたファイルの集合 Files を使うと次のように表せます。

なんか変な記号が出てきましたが、この式は "どんなファイルについても、誰かしらは正のスコアをもっている" という意味です。これをさらに言い換えると、ある要素 (= file ) をすべて被覆するような族 (= reviewer ) の集合を求めるという問題 "集合被覆問題" になります。この集合被覆問題は計算困難問題といわれるもので、例えば族の集合を最小化したい場合は NP 困難であることが知られています(Wikipediaを参照)。幸い、集合被覆問題は単純な貪欲法でもいい感じの近似解が得られることが多いです。例えば、族の集合を最小化する問題なら、上界保証付きの近似解が得られます。
よって、レビュアーの選出には貪欲法を使うことにします。前段落でごちゃごちゃ言っていたのは、単にその言い訳 正当な理由を述べたまでです。まあ、今回は集合を最小化するわけではなく、より適したレビュアーを探すという問題なので、本当にうまくいくかは知りませんが。
これを擬似コードで書くと以下のようになります。

これでレビュアーを探せます!すごく短い!第3節、完!
これ、似たようなのありそうじゃない?
はい、皆さん考えることは同じみたいで、例えば Facebook の mention-bot があります。隣の席の人に教えてもらいました。ただ、こちらは git blame を使っているので、上述したとおりフォーマッタや単純なリファクタリングなどに弱い...はずです。 ちゃんと読んでないので誰か教えてください。
今後どうするの?
レビュアー候補の選出に使う h や c を定数にしているのですが、これだと、履歴が浅いファイルや、コミットしている人が極端に多い/少ない場合だとうまくいかないはずです。その辺をファイルごとに動的に変えられたらなーと考えています。
他には、弊社のビルドの王子様と名高い Shoji (12/7 の記事担当者) が Jenkins 上で動かして、GitHub 連携をしてくれるはずです。 あと、 IntelliJ / Android Studio のプラグインがほしいと言っている人もいるので、誰かなんとかしないかなーと口を開けて待っています。
おわりに
やっていることは単純なのですが、いくらでも大仰に書くことってできますね。
週明け月曜日は@dxhuyさんによる「LINEのエンジニアリングを支える社内ツール」についての記事です。お楽しみに!