
こんにちは、LINEのメッセンジャーアプリのサーバサイドエンジニアをしている'18卒のエンジニアのbitter_foxです。この記事はLINE Advent Calendar 2018の18日目の記事です。
弊社では夏休みの1ヶ月間〜2ヶ月間、学生に実際の業務を体験してもらう就業型のサマーインターンシッププログラムを実施しております。 弊社の就業型インターンでは社内のチームにジョインし、ある程度大きめのプロジェクトに1ヶ月間〜2ヶ月間、取り組んでもらいます。
私の所属するチームでも今夏、学生を受け入れ、「HBaseをJDK 11で動かしZGCを評価する」というプロジェクトに1ヶ月間取り組んでもらいました。 本記事ではそのインターンシッププロジェクトの紹介をいたします。
HBase v.s. GC
HBaseはGoogle File System上で動作するデータベースであるGoogle Bigtableを参考に開発されたOSSのデータベースです。 HBaseはスケールアウトが容易であり、レイテンシが低く、可用性も高いという特徴があるため、LINEのメッセンジャーアプリではユーザ情報やメッセージなどの各種データをHBaseに書き込み、永続化しています。
HBaseはJavaアプリケーションですので、GCがHBase運用上の重大な問題になることがあります。
分散アプリケーションであるHBaseでは、各ノードと一定時間通信ができないとそのノードを死んだとみなしFailoverを行う仕組みがあります。 こうした仕組みは運用コストを低下させ、可用性を向上させられるので非常に有用です。 しかし、GCと組み合わさることでJuliet Pauseと呼ばれる問題を引き起こしてしまうことがあります。 GCには一般にSTW(Stop The Worldの略)と呼ばれるアプリケーションのスレッドをすべて停止させるフェーズがあります。 長時間のSTWが発生すると、そのノードが死んだと見なされFailoverが発生してしまうという問題です(ロミオとジュリエットで死んだと思われていたジュリエットが実際には一時的に眠っていただけだったことに見立てて、Juliet Pauseと呼ばれているらしいです)。
CMSやG1GCと呼ばれるSTW時間を制御でき、コンカレントな(アプリケーションと並行、マルチコア環境でコア数が十分なら並列に動く)GCの利用や、一部のキャッシュをOff-heapに配置するというようなHBaseの改善により、こうした問題は現在では起こりにくくはなっています(CMSやG1GCでもFullGCが発生すると長時間のSTW生じるため、上記問題が起きる可能性はあります)。
しかし、それでもGCのSTWによりHBaseの99.9%tileレスポンスタイムが悪化してしまうという問題があります。 DBであるHBaseのレスポンスタイムの悪化はサービス全体のレスポンスタイムの悪化を招きます。 より良いUXをユーザに提供するため、HBaseの99.9%tileレスポンスタイムを改善することは重要です。
ところで、Java 11ではZGCという興味深いGCがExperimental FeatureとしてJEP 333で導入されました。 ZGCはヒープが数TBであっても、各STWを10ms以下で終わらせることを目指しています。 しかも、Oracleが行ったベンチマークではスループットの低下は15%以下だったそうです。 詳細は後述しますが、ZGCの特徴から、LINEのメッセンジャーアプリのHBaseクラスタ環境との相性が極めて良いのではと考えました。
こうした背景を元にインターン生にはHBaseをJDK 11で動かし、ZGCとHBaseの性能、相性を評価してもらいました。
HBaseをJDK 11で動かすには
さて、ZGCとHBaseの性能や相性を評価するためには、HBaseをJDK 11で動かす必要があります。 インターンを行った8月時点ではJDK 11はGenerally Availableではなかったですが、Early Accessビルドが提供されていたため、JDK 11 EAを用いてHBaseを動かしてもらいました。 Javaの次期バージョンのEarly accessは http://jdk.java.net/ で公開されていますので、新しいバージョンを試してみたいという方はそちらからダウンロードしてみてください。
LINEのメッセンジャーアプリで使っているHBaseはJDK 8で動かしているので、簡単のために、JDK 8でビルドしたバイナリをJDK 11で動かすという方針にしました。 ですが、JDK 8とJDK 11の間には多くの変更が加えられており、いくつかの非後方互換性が知られています。 そうした互換性の問題が起きる可能性があったため、インターン生には互換性の問題が起きたら調査を行い、都度JDKやHBaseなどを直してもらう様にお願いしました。
互換性の問題によっては泥沼にハマってZGCの評価まで辿り着けない可能性があったので、内心はヒヤヒヤしていました。 幸いにもバージョン表記に関する非互換性(HBase-17944、Hadoop 2.7.2でJavaバージョンが2文字だと死ぬ奴)やHBaseのshellツールが古いJRubyに依存していて動かない(HBASE-18162)など、すでにパッチ、回避策がある、もしくはHBaseを試す上ではあまり支障にならない問題にしか引っかからなかったです。
ZGCとは
ここでZGCについてもう少し詳しく説明し、なぜHBaseとの相性が良いと考えたのかを説明します。
多くのGCには、死んでいるオブジェクトを見つけるためのマークフェーズや、メモリ上のデフラグを解消するコンパクションフェーズと呼ばれるいくつかのフェーズがあります。 コンカレントなGCはこうした各フェーズの一部をアプリケーションスレッドと並行して実行します。 逆に言うと各フェーズの一部で整合性、安全性を確保するために、STWを伴う(アプリケーションスレッドを停止する必要がある)処理があります。
ZGCはコンカレントGCで、マークやコンパクション(ZGCではRelocation)のフェーズがあるのですが、すべてのフェーズにおいてSTWが10ms以下で終わるような設計になっています。 具体的には各フェーズの冒頭で行うルートオブジェクトに対する処理だけをSTWで行います。 そのため、STW時間はルートオブジェクトの数に依存します。 Javaではルートオブジェクトの数はヒープサイズに依存せず、主にスレッド数やローカル変数の数などに依存するため、同様にSTW時間もヒープサイズに依存しません。
ちなみに、GCがアプリケーションと並行に動くので、整合性を確保するためにアプリケーションがオブジェクトを参照するときにLoad/Read Barrierが必要なため、僅かながらのスループット低下が発生します。 先程も述べましたがこのスループットの低下は15%以下だそうです。
HBaseと相性が良いと考えた理由は大きく以下の4つです。
- 99.9%tileのレスポンスタイム改善は重要である
先程も述べたとおりGCによるSTWを極力避けたいアプリケーションです。 - CPUリソースが余っている
ZGCはコンカレントGCなためCPUリソースに余裕がないとアプリケーション全体のパフォーマンスが悪化します。
運用しているHBaseではCPUリソースが余っています。 ある程度CPUに余裕を持たせているという理由もありますが、HBaseならではの理由もあります。 一般にDBでCPUに負荷が掛かるのはSQLの処理、特にテーブル結合や集約によるところが大きいと思います。 一方でPureなHBaseはSQLをサポートしておらず、データの追記、取得、削除などの単純な処理が主です(Phoenixを組み合わせればSQL-Likeなことができますが、LINEのメッセンジャーアプリではPhoenixを使っていないので、ここでは考えません)。 そのため、SQLをサポートするDBと比べてCPU負荷が高くなりにくい特徴があります。 - より大きなヒープをHBaseのキャッシュとして与えられることによるパフォーマンス向上が望める
HBaseに限らず、DBのパフォーマンス改善においてメモリ上のキャッシュは重要です。 今まではGCの問題からJavaのヒープサイズを31GB、Off Heapキャッシュを30GBなどとして運用していましたが、ZGCによってより大きなキャッシュを与えられるかもしれません。
Javaのヒープサイズを31GBとしていたのはCompressedOopsを有効にするためでしたが、ZGCの実装の都合上、CompressedOopsは自動的に無効になります。 そのため、CompressedOopsを無効にしても問題ないぐらいにヒープを割り当てられる程のメモリが搭載されているかも、ZGCを検討する際には重要なポイントになるでしょう。 ちなみに、LINEのHBaseクラスタは各ノードに256GBのメモリが乗っているのでその点も大丈夫そうでした。
余談ですが、GCを避けるために一部のキャッシュをOff Heap上に配置するという実装がHBaseにはあります。 メモリの管理をHBaseが行うとメモリ管理に伴うバグが混入してしまうだけでなく、HBaseの実装自体が複雑になりメンテナンス性が低下してしまいます。 キャッシュのメモリ管理を問題なくJVMに任せられるとHBase自体の実装にも嬉しいことがありますね。 - スループット低下の問題にはスケールアウトで対応できる
ZGCによるスループットの低下は15%以下と言われています。 仮にZGCによるスループット低下が各ノードの処理能力上の問題になったとしても、HBaseだとスケールアウトすることで対応することができます。
また、スループットの低下は平均応答時間の悪化を招く可能性もあります。 15%のスループット低下であれば、99.9%tileレスポンスタイムの改善を天秤にかければ許容できる範囲だと考えられます。
ちなみにG1GCを使っている場合だとG1GCによるスループット低下がすでに起きているため、G1GCからZGCへ変更したときの実際のスループット低下は15%よりも小さいと思います。
評価と結果
さて、こうしたZGCの詳細を調べてもらいながらHBaseとZGCの組み合わせの性能評価をしてもらいました (ZGCの詳細はインターンをしてもらった時点では僕もあまり知らなかったので一緒に勉強しました(๑•̀ㅂ•́)و✧)。 比較としてHBase+G1GCの組み合わせでも評価をしてもらいました。
性能評価にはNoSQL DBの性能評価におけるデファクトスタンダードであるYCSBを用い、色々なデータアクセスパターンやヒープサイズなどでSTW時間やSlow Response、スループットなどの評価を行ってくれました。 ここではその結果を要約して紹介します。
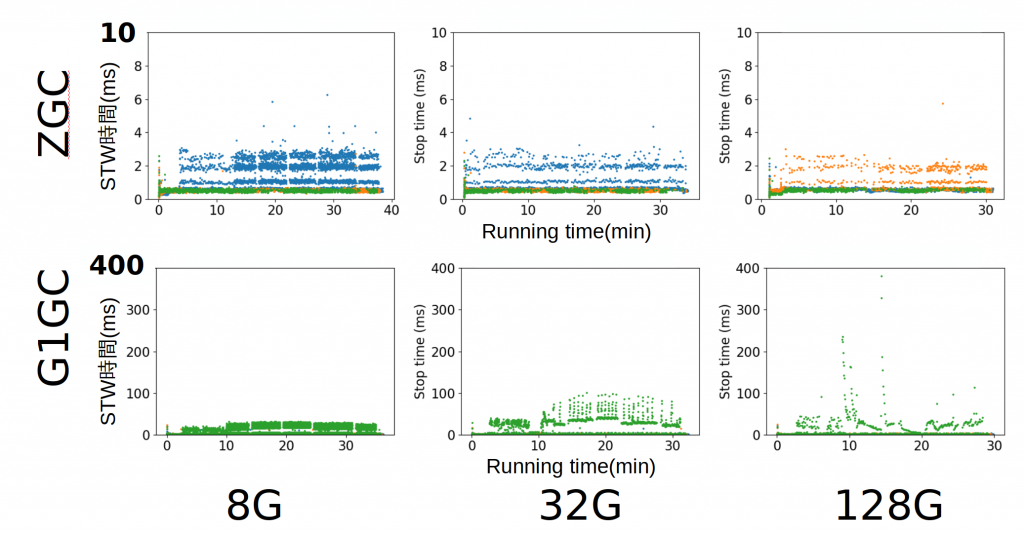
上の図はHBaseを動かして評価したときに発生したGCのSTW時間をプロットした散布図です。 上の3つの図がZGC、下の3つがG1GCでHBaseを動かしたときの結果です。 また、左から順にヒープサイズが8GB、32GB、128GBで動かしたときの結果です。 X軸がHBaseが起動してからの時間(分)、Y軸がSTW時間(ms)、各点がSTWを表します(以下、単位は同様)。 Y軸の最大値がZGCに対しては10ms、G1GCに対しては400msであることに注意してください。
ZGCでは前評判通り、ヒープサイズが増えたとしてもSTW時間が10msを超えていないことがわかります。 一方で、G1GCではヒープサイズが増えるとともに最悪のSTW時間も増加しています(128GBの15分ぐらいを見ると300ms〜400msのSTWが発生しています)。 この評価でのG1GCの目標Pause Timeは10msでしたが、他の場合でも同様の傾向があります。
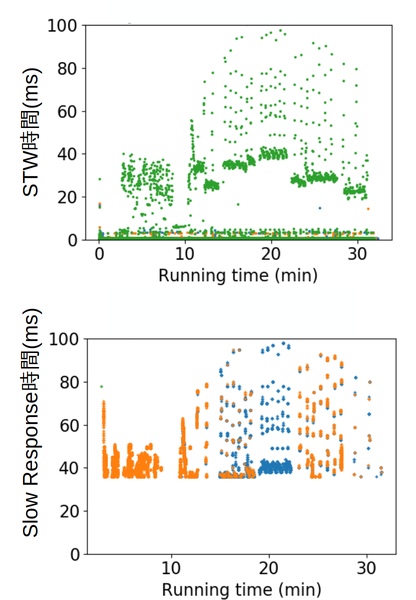
上の図はG1GCでHBaseを動かしたときのGCのSTW時間(上)とHBaseのSlow Responseログ(下)を先ほどと同様にプロットした散布図(ただし、hbase.ipc.warn.response.time(Slow Responseログの閾値)は35ms)です。 GCのSTW時間がResponse Timeにも影響を及ぼしていることがわかります。 わかりやすくするために、100ms以下のSTWとSlow Responseを切り出していますが100msを超えるSTWでも同様のことが見受けられました。
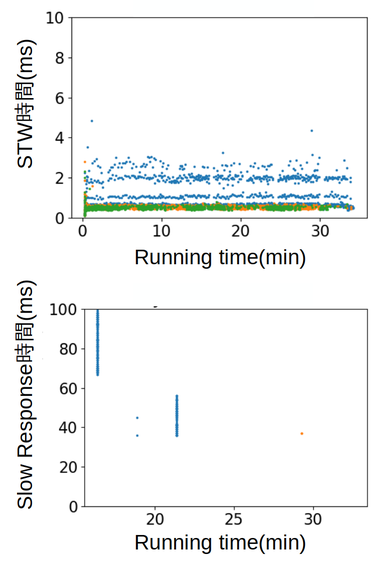
一方、ZGCでHBaseを動かしたときの同様の散布図が上の図です。 ご覧のようにGCのSTWが10ms以下のため、明らかにSlow Responseが減っていることが分かります。 縦に並んだ点はG1GCで動かしたときにも発生していたので、HBaseのGC以外の要因によるSlow Responseと見られますが、調査しきれておらず、ここでは扱いません。
気になるスループットの比較を下の表に示します。 31GB Heapでは大きな差は見られず、128GB HeapではややZGCのほうがスループットが良い傾向が見受けられました。 太字は同じサイズのヒープにおける別のGCアルゴリズムよりもスループットが良いことを表します。 ただし、下の表におけるWorkloadのA〜D、FはそれぞれYCSBのCore Workload A〜D、Fに対応します。 各Workloadの詳細はCore Workloadsを参考にしてください。
| Workload pattern/Throughtput(ops/sec) | ZGC 31G | G1GC 31G | ZGC 128G | G1GC 128G |
|---|---|---|---|---|
| A: Update heavy workload | 42425 | 42506 | 49298 | 48883 |
| B: Read mostly workload | 26668 | 26930 | 41763 | 39236 |
| C: Read only | 24443 | 23949 | 43050 | 39180 |
| D: Read latest workload | 42925 | 42820 | 48118 | 54313 |
| F: Read-modify-write | 17871 | 18698 | 30080 | 29171 |
まとめと今後の展望
ここまでがインターン生が行ったプロジェクトの紹介でした。 HBaseやJava、GC、性能評価は普段行わない分野だったようで、難しい部分もあったと思いますが、自ら積極的に考えながら進められていて良かったです。 特に1ヶ月間で性能評価を行おうとすると時間との戦いになるのですが、帰る前にベンチマークを動かして、翌日に結果を解析するといったように工夫をして時間を効率的に使えていて良かったです。
さて、ご覧のように実験環境においてはZGCとHBaseとの相性がよく、スループットの問題も無く、早いレスポンスタイムを実現できていることが分かりました。 今後の展望ですが、本番環境への導入を目指し、引き続き評価を進めていきます。 現在はBETA環境にてHBaseをJDK 11で動かし長時間動かしたときや、オペレーションを行ったときの安定性を確認しています。 今回の実験では本番環境で使われるサーバと近しいスペックのサーバを用いて、擬似的な負荷を掛けることでパフォーマンスを評価しました。 今後はより実際の負荷に近い環境で評価するために、JDK 11とZGCで動かしたHBaseクラスタ環境に対して本番環境とほぼ同じ数、もしくは数倍のトラフィックを再現することで、安定性やレスポンスタイムの改善などを確認していきます。 その環境でも良さそうな結果が得られたら新しく構築するクラスタから順次適用していけると良いですね。
明日はKunihiko Satoさんによる「Clova + firebase + vue.js」です。お楽しみに!