
はじめに
こんにちは.2021年の4月からITSC Verda室のネットワーク開発チームでアルバイトをしている菅原大和(@drumato)と申します.本記事では,約半年間私が取り組んできたタスクである,「SDNによって自動的に仮想ルータクラスタをメンテナンス,ローリングアップデートする仕組みの検討と実装」についての成果をご紹介します.また,ここまでの活動で現在の実装が抱える問題点もわかったので,それも合わせて共有します.最後に,今後の私達のSDNシステムに必要な機能について取り上げます.
背景
KloudNFVプロジェクトについて
LINEのほとんどのサービスは,自社で開発/運用されているプライベートクラウドのVerda上で開発/ホスティングされています.その中には,ネットワーク的かつセキュリティ的に高い要件を持つサービスが存在します.これに対し私達は著名なパブリッククラウドにおけるVPCと同等の機能を提供する必要があります.ここでのVPCとは,隔離されたネットワークと,NATやNetwork ACLなどのNFVサービスを連携して提供するものです.このうち前者に関しては,インハウスで開発されているNeutronプラグインを利用して,既にSRv6のプライベートネットワークが実現されていました.詳細はJANOG44の公開資料を御覧ください.
https://www.janog.gr.jp/meeting/janog44/program/srv6/
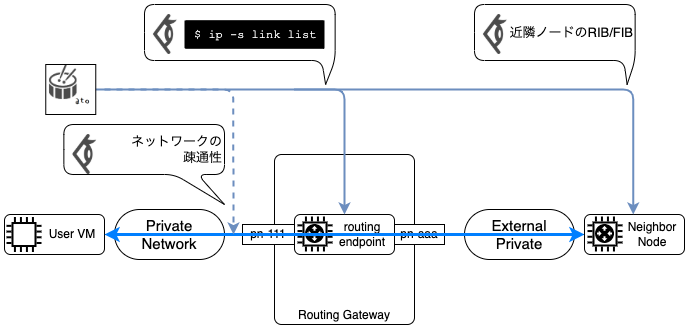
一方,後者のNFVサービスについては提供できていませんでした.そこで,プライベートネットワークと連携し,様々なNFVサービスを高機能でロバストな仮想ネットワークインフラとして提供するために発足されたのがKloudNFVプロジェクトです.以降KloudNFVと略称します.ここでは,本記事の理解に最低限必要な範囲で,KloudNFVを解説します.下に図を用意したので,そちらと合わせてご覧ください.まず,KloudNFVでは現状,"プライベートネットワークに対する疎通性を提供するNFVサービス"と,"その他のNFVサービス"に分かれます.前者は仮想ルータクラスタや仮想ルーティングテーブルが該当し,これらにはRoutingやRouteという名前がついています.それらはデータプレーンノードとしてOpenStack VMを利用します.NfvMachineというリソースがOpenStack VMに対応しています.一方,その他のNFVサービスには,ネットワークインタフェースの統計情報を扱うLinkStatsや,BGPのRIBを扱うRibEntryなどが存在します.他にもNfvMachine上では,ルーティングプロトコルスイートのFRRoutingや,私達がスクラッチで開発しているデータプレーンエージェントなどが動作します.このエージェントを,本記事ではNFV agentと呼ぶことにします.

最後に,私達のSDNにおいてネットワークのスペックや状態を格納するストレージをNIBと呼ぶことにします.KloudNFVではKubernetesリソースもNIBに格納されます.KloudNFVの詳細については以下の資料が参考になります.
問題意識
上記の資料に記載の通り,KloudNFVではKubernetesのカスタムコントローラを疎結合に組み合わせてNFVサービスを実現しています.その結果,それぞれのNFVサービスを独立的に開発できます.また,カスタムコントローラはKubernetes Deploymentとして扱っており,開発スピードに合わせてデプロイもスマートに行えます.インタフェースとなるリソースデザインが変わらない限り,データプレーンとは独立してコントローラをアップデートでき,Kubernetesの恩恵をうまく享受できています.
その一方で,仮想ルータで動作するNFV agent等のコンポーネントをアップデートする際には,ユーザトラフィックの損失が発生しないように注意する必要があります.ここでは,実際にネットワークオペレータが行わなければならなかった作業を解説します.ここで,対象以外の仮想ルータは省略しています.まず,それぞれのノードにSSHでログインして,各種ステータスやネットワークの疎通性をモニタリングします.同時に,仮想ルータ上のマイクロサービスにアクセスし,BGPコンフィグを変更したり,Kubernetesコントロールプレーンに送るハートビートを停止します.モニタリング内容に問題がないことを確認した後,マイクロサービス,もしくは仮想ルータ自体を再起動します.その後仮想ルータのBGPコンフィグ等を書き戻し,正しくN台のルータに対するマルチパスがワークしていることを確認します.
このようにして,一つの仮想ルータのアップデートが完了します.ですが,クラスタを構成するN台の仮想ルータに対して上記操作を行うことを考えると,これは複雑なオペレーションだといえます.結果的に,NFVサービスの開発サイクルとデプロイサイクルにギャップが生じてしまっていました.現状,KloudNFVのアーキテクチャが持つ有用性を十分に発揮できていないといえます.
ここまでの背景から,私達はローリングアップデートに責任を持つSDNアプリケーションを実装し,上記オペレーションを安全に自動化したいと考えました.具体的には,kubectlを実行するだけで仮想ルータクラスタがダウンタイムゼロに更新できることが目標です.私は,このローリングアップデートのタスクを2つに分割できると考えました.まず,一つの仮想ルータに対するトラフィックを迂回させる経路制御メカニズムの実装です.これをMaintenance Modeと呼びます.Maintenance Modeの実装によってサービスアウトをSSHログインせずに行えるようになります.そして,Maintenance Modeを利用して仮想ルータクラスタ全体をアップデートする仕組みの実装です.これをRolling Updateと呼びます.これはカスタムリソース + カスタムコントローラというパターンで実装し,リソース1つを作成するとアップデート完了までが全て自動化される,という世界観を実現するのが目的です.本記事ではこれら2つのフェーズのそれぞれについてフォーカスし,本タスク自体を指すローリングアップデートとは区別することにします.
Maintenance Mode
Maintenance Modeの要件を整理します.まず1つ目に,仮想ルータを経由する経路を制御して,仮想ルータをサービスアウトするメカニズムです.これは私達がSSHログインして行っていたオペレーションをコントローラで自動化するものです.2つ目に,Maintenance Modeの有効化はkubectlで行えるようにします.KloudNFVの既存コンポーネントと同じように扱えるのが目的です.最後に,Maintenance Modeの状態はKubernetesネイティブな方法で管理し,SDNドメインのどこからでも簡単に確認できるようにします.これはコンポーネントの状態を集中的に管理する,SDNの根幹思想に従ったものです.
最終的な実装結果として,実際に仮想ルータのmaintenance modeを切り替える様子をご紹介します.labelアップデートによってリコンサイルがトリガーされ,NFV agent側で検知してサービスアウトを行う,という動作になっています.KubernetesのカスタムリソースではPrint Columnを独自に設定できることを活かしてMaintenance Modeを扱っています.次のセクションからMaintenance Modeのコンセプトを検討し,実装するまでのプロセスをご紹介します.
## Before Maintenance
$ kubectl get routingendpoints.verda.linecorp.com -o wide
NAME READY MAINT AGE
test-endpoint1 True False 4d21h
test-endpoint2 True False 4d21h
## Enable Maintenance Mode
$ kubectl label routingendpoints.verda.linecorp.com test-endpoint1 maintenance=True --overwrite
routingendpoint.verda.linecorp.com/test-endpoint1 labeled
## Under the Maintenance
$ kubectl get routingendpoints.verda.linecorp.com -o wide
NAME READY MAINT AGE
test-endpoint1 True True 4d21h
test-endpoint2 True False 4d21hメンテナンス時の経路制御
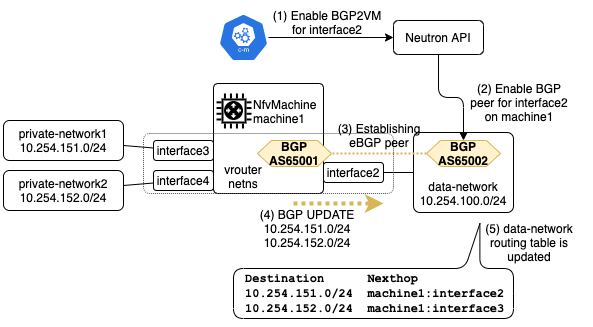
ここではサービスアウトの前段階として,現在仮想ルータがどのようにして経路広報を行っているのかについて説明します.仮想ルータは,2種類のネットワークインタフェースを持ちます.1つ目は,アンダーレイネットワークに接続するネットワークインタフェースです.これをExternal I/Fと呼びます.2つ目は,SRv6オーバーレイネットワークに接続するネットワークインタフェースです.これをPrivate I/Fと呼びます.それではまず,プライベートネットワークへのインバウンドトラフィックについて説明します.ここで interface2 が External I/F に相当し,interface3, 4が Private I/F に相当します.それぞれの仮想ルータ上ではBGPデーモンが動作し,外部ネットワークとピアを確立してプライベートネットワークの経路を広報し,インバウンドトラフィックを引き込みます.仮想ルータ自身でBGPデーモンを動作させる仕組みについてはこちらの資料が参考になります.
https://www.janog.gr.jp/meeting/janog43/application/files/7915/4823/1858/janog43-line-kobayashi.pdf
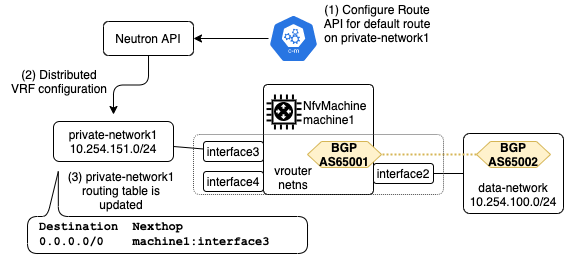
続いてアウトバウンドトラフィックについて解説します.ここで,デフォルトルートのネクストホップとして仮想ルータクラスタを指定するRouteリソースが作成されていると仮定します.Routeコントローラはリソースの更新を監視して,Neutron APIを呼び出します.それによってプライベートネットワークに接続するハイパーバイザに,分散的にVRF tableを設定します.Routeコントローラは指定された仮想ルータクラスタ(に所属する仮想ルータ)のアドレスを解決して,それぞれのVRF tableでデフォルトルートのネクストホップアドレスに指定します.プライベートネットワーク内のパケットは,このVRF tableをルックアップして転送されます.このように,2つの独立したメカニズムが協調動作することで仮想ルータへのトラフィックを引き込んでいます.
仮想ルータのサービスアウト
Maintenance Modeを実装するためには,先程紹介した2つのメカニズムを改良する必要があります.まずアウトバウンドトラフィックに対してですが,NfvMachineに"Maintenance Modeが有効かどうか"を表すステータスを持たせ,先述したRouteコントローラのネクストホップ解決アルゴリズムでそれを回避します.このステータスにはConditionというデータ構造を利用していますが,Conditionを利用するメリットと動機については記事の終盤で解説します.そしてインバウンドトラフィックに対しては,自身を動作させるNfvMachineの状態をNFV agentが確認し,経路フィルタリングを実行します.実際には,よりプラクティカルなBGP経路制御を行う必要がありますが,発展的な話題なので記事末尾で扱います.
Kubernetes Label
上記のようにコアロジックを設計したあとは,そのロジックとユーザ(ここでは私達オペレータ)のインタフェースをどう設計するか,という議論が必要です.私はKubernetes LabelによってMaintenance Modeの切り替えを行うことにしました.このようにKubernetes Labelでカスタムリソースの情報を管理する手法はcert-managerなどの著名なKubernetes add-onで用いられており,APIアクセスコントロールで自由な書き換えを禁じるといった仕組みを適用可能という点が決定打となりました.labelの読み書きはAPI clientで行えるので,他のSDNアプリケーションからlabelを読み書きしてより高度なNFVサービスを実現する際にも利用できるかもしれません."ネットワークオペレータからもプログラムからもアクセスできるインタフェースで管理する"という点が,Kubernetes Labelを採用した大きな理由です.
LinkStats
ここでは関連する話題として,仮想ルータが持つネットワークインタフェースの統計情報を扱うLinkstatsというSDNアプリケーションをご紹介します.これはメンターの城倉さんから開発方針と動作原理の説明を受けて,私がローリングアップデートより前に開発したものです.背景のチャプターでも述べましたが,私達は仮想ルータに直接SSHしてネットワークインタフェースのトラフィックを確認していました.これに置き換わり,NFV agentの1機能として動作し,統計情報をNIBにプッシュします.私達が実現したい"仮想ルータにログインせずに各種メトリクスが取得でき,またメンテナンスが行える世界"には必要不可欠だといえます.ネットワークオペレータがメンテナンスする場合でも,後述するRolling Updateによって自動的にMaintenance Modeに切り替わる場合でも,ネットワークモニタリングの項目としてLinkStatsを利用できます.カスタムコントローラはPrometheus Exportをサポートしているため,Maintenance Modeの切り替えによってエラーパケットの量が増加した,などのイベントを確認することもできます.
kubectlを用いてLinkStatsを表示した結果を以下に示します.
$ kubectl get linkstats.verda.linecorp.com -o wide
NAME RX BYTES TX BYTES RX PACKETS TX PACKETS
test-endpoint1-int1 312522 4732 3091 100
test-endpoint1-int2 106521 415696 1328 4070
test-endpoint2-int1 566542 338324 5550 3579
test-endpoint2-int2 609266 865620 6934 8339Rolling Update
Rolling Updateの要件を整理します.まず1つ目に,Maintenance Modeの仕組みを利用して仮想ルータを1台ずつアップデートできることです.これはローリングアップデートのタスクそのものを表します.2つ目に,実行に関わる様々なパロメータがマニフェストファイルで調整可能であることです.ローリングアップデートは一度トリガーされると実行に失敗するまで全自動的に動作しますが,様々なケースで実行されることを想定して,その挙動が外部から渡されるようになっていたほうが便利です.詳細は後述しますが,ローリングアップデートの各フェーズでインターバルを設けたり,ローリングアップデートの失敗条件を記述できるようになっています.3つ目に,ローリングアップデート中の様々なイベントが確認できることです.これはMaintenance Modeと同じくオブサーバビリティの観点で重要であり,特にシステムに大きな影響を与えるというローリングアップデートの特性上これは必須だと考えられます.最後に,現状のシステムで確保できる安全性は可能な限り確保することです.
最終的に私が実装したRolling Updateの動作をご紹介します.まずRollingUpdateは以下のようなスキーマで設計しました.アップデートの実行者はこのマニフェストをもとにリソース作成を行うだけで,ローリングアップデートに関わるすべてのタスクが自動的に実行されることになります.
apiVersion: verda.linecorp.com/v1alpha1
kind: RollingUpdate
metadata:
name: rollingupdate-sample
namespace: test # 対象となる仮想ルータクラスタが存在するnamespace
spec:
target:
type: RoutingGateway # 仮想ルータクラスタとなるKindを指定
name: test
filters: # アップデート対象となる仮想ルータに対し条件を適用する
- Healthy # すべての仮想ルータが正常に動作することを強制するFilter
parameters:
waitingTimeoutMinutes: 10 # ある仮想ルータがアップデート後Healthyになるまでにコントローラが許容する制限時間
newNFVMachineUpSeconds: 30 # ある仮想ルータがアップデートされた後,次の仮想ルータをアップデートするまでのインターバル
serviceOutSeconds: 30 # 仮想ルータをサービスアウトしてから,実際に再作成されるまでの待ち時間
reconcileErrorLimit: 1 # 許容するリコンサイルエラーの上限
ttlAfterFinishedSeconds: 10 # Jobリソースのように,正常終了後一定秒数経つと削除されるようにするまた,例えば1つ目の仮想ルータのアップデートが終わった段階では,次のステータスを持っています.ステータスは実行タイミングやリコンサイルの回数によって異なる挙動を起こさないように,コントローラがどのタイミングでこのリソースを観測してもリコンサイルアルゴリズムを決定できるように注意しました.
apiVersion: verda.linecorp.com/v1alpha1
kind: RollingUpdate
metadata:
name: rollingupdate-sample
namespace: test
spec: # omitted
status:
conditions: []
currentUpdateTask: test-endpoint2 # 現在アップデート対象としている仮想ルータ
failedCount: 0 # 発生したリコンサイルエラーの数
state: WAITING # RollingUpdateリソースが持つ状態
stateTrantisionTime: "2021-10-07T04:54:10Z" # 状態遷移のタイムスタンプ
updateTasks: # アップデート対象となる,列挙された仮想ルータ
- done: true # すでにアップデートが終了している
extension: {}
kind: RoutingEndpoint
name: test-endpoint1
- done: false # まだアップデートが完了していない
extension: {}
kind: RoutingEndpoint
name: test-endpoint2正常に動作した場合,以下のようなevent sequenceを発行しながら動作します.一方,例えばアップデート対象となる仮想ルータクラスタ内に,Unhealthyな仮想ルータが存在した場合,それを示すEventを発行して実行を中止します.
$ kubectl get events --field-selector involvedObject.name=rollingupdate-sample --sort-by='.lastTimestamp'
LAST SEEN TYPE REASON OBJECT MESSAGE
10m Normal RollingUpdateChangeState rollingupdate/rollingupdate-sample Change State to=PREPARE
10m Normal Collected rollingupdate/rollingupdate-sample Target names={test-endpoint1, test-endpoint2}
9m38s Normal MaintenanceLabelEnabled rollingupdate/rollingupdate-sample Endpoint name=test-endpoint1
9m8s Normal DeleteNfvMachineForUpdating rollingupdate/rollingupdate-sample Deleted NFV-Machine name=test-endpoint1
5m33s Normal RollingUpdateChangeState rollingupdate/rollingupdate-sample Change State to=UPDATE
5m33s Normal Confirmed rollingupdate/rollingupdate-sample Updated Endpoint(name=test-endpoint1) is now on ready!
5m3s Normal MaintenanceLabelEnabled rollingupdate/rollingupdate-sample Endpoint name=test-endpoint2
4m32s Normal RollingUpdateChangeState rollingupdate/rollingupdate-sample Change State to=WAITING
4m32s Normal DeleteNfvMachineForUpdating rollingupdate/rollingupdate-sample Deleted NFV-Machine name=test-endpoint2
36s Normal RollingUpdateChangeState rollingupdate/rollingupdate-sample Change State to=SELECT
36s Normal Confirmed rollingupdate/rollingupdate-sample Updated Endpoint(name=test-endpoint2) is now on ready!
35s Normal RollingUpdateChangeState rollingupdate/rollingupdate-sample Change State to=FINISHED
25s Normal TTLExceeded rollingupdate/rollingupdate-sample TTLAfterFinished 10 secs is exceeded
次のセクションからは,Rolling Updateを実現するためのコンセプトや検討についてご紹介します.
Deploymentのアップデートストラテジ
Kubernetesの世界でのシステムアップデートは,KloudNFVに限っただけではありません.例えばDeploymentもアップデートの仕組みを実現していますが,私達がアップデート対象とする仮想ルータクラスタには適用できません.カスタムリソースのレプリケーションを実現するCRDの仕組みとしてscaleがありますが,サービスアウトなどの細かい制御をフックできるかが不明瞭でした.Finalizer等の仕組みをフル活用すれば可能かもしれませんが,ニッチな検証で多くの時間を費やすことになるだろう,という肌感覚がありました.私達のチームはカスタムコントローラの実装に対する知見が十分にあったので,独自に開発するのが難しくないと判断しました.事実,Rolling UpdateコントローラのコードはGo言語で1000行程度であり,これは十分に小さな規模で開発できたと考えられます.
RoutingGatewayのアップデートストラテジ
一口に"仮想ルータクラスタをアップデートする"と言っても,そのやり方には様々なものがあります.ここでは,一般的なシステムアップデートにおいて意識しなければならないポイントのうち一部を紹介します.
| 項目 | 概要 |
|---|---|
| オーグメンテーション | アップデートの前段階として,対象の数を増やし,コンポーネント単位の負荷を軽減する |
| アップデートの同時実行数 | システムのうち,利用不可となるコンポーネントの割合をどれだけ許容するか |
| アップデート失敗時の挙動 | 前のバージョンにロールバックしたり,失敗したままにしておいたり |
| バージョン情報の取り扱い | アップデートに用いるバージョンをどう指定するか |
| カナリアリリース | システムを段階的にアップデートする手法 |
これらのポイントに対し,私が採用した現段階でのポリシーをご紹介します.まずオーグメンテーションについてですが,これはひとまず考えないことにします.もちろんRoutingGatewayのスペックを書き換えることで仮想ルータを増やすことは可能です.しかし,増えた仮想ルータに対しても取り除くときにはサービスアウトを必要とします.そもそも仮想ルータクラスタに所属する仮想ルータの数を多くしておけば,暫定的には問題ないと考えました.次に同時実行数についてですが,これは必ず1台ずつ行うようにしました.Kubernetes Deploymentではこれもスペックで制御できるようになっていますが,私達はロールバックの仕組みを提供していないので,アップデートによって仮想ルータが正常に動作しないとき,それが2台以上同時に存在する状態がありえるのは不安です.必ず1台ずつアップデートするようにすれば,異変を確認した時点でローリングアップデートを終了させられます.次にバージョン情報ですが,これは敢えて実行パラメータに含めないことにしました.マイクロサービスのバージョンを実行時に渡せるようにすると,コントローラは古いけどデータプレーンだけどんどん新しくなったり,逆に古いイメージタグでアップデートしてしまうオペレーションミスを誘発します.検証済みであるコントローラとマイクロサービスのペアで必ずアップデートするのが最も堅牢であり,そのイメージタグはコントローラからのみ渡されるようにすれば一貫性を実現できます.そして最後にカナリアアップデートですが,これも同様にサポートしないことにしました.ルータはECMPでトラフィックを分散して吸い込みますが,この重みを制御するのは簡単ではないからです.
分散システムの困難性とワークアラウンド
VerdaのSDNは多くのシステムが相互に関わりあって実現されているために,それぞれのコンポーネントで何か問題が発生することを考慮して設計する必要があります.OpenStackのコアコンポーネントや内製のNeutronプラグイン,KubernetesコントロールプレーンやKloudNFVを構成するそれぞれのコントローラなど,障害が発生するポイントは分散して存在します.このような分散システムの上でシステムを設計する場合には,本質的な困難性がつきまといます.ある時点でNfvMachineの状態をGETしてHealthyだとしても,UPDATEするまでにUnhealthyになっているかもしれません.VMの再作成をリクエストしても,延々と立ち上がらないかもしれません.データプレーンはうまく動いているが,コントロールプレーンの障害によって情報のやり取りに失敗するかもしれません.ローリングアップデートではシステムに大きな影響を与える操作を行います.様々な特殊ケースを想定して,できる限りロバストに動作するよう注意してプログラミングを行う必要がありますが,実際に運用を開始することで初めて発現するケースもあるために,すべてを予測することは困難です.
私はワークアラウンドとして,RollingUpdateリソースにポーリングインターバルなどの実行パラメータを設けることで対応することにしました.これはアドホックでいくつかの問題を孕んでいますが,開発環境でたくさんローリングアップデートを実行することでバグを見つける前段階としては,十分だと考えています.
結果
ここからはローリングアップデートのタスク全体を総覧して得られた経験や気付きを共有します.
オペレーション
問題意識のセクションで触れたように,私達の手動オペレーションは複雑で,デプロイサイクルを遅らせる原因となっていました.これがRollingUpdate機能のリリースによって,"Kubernetes Eventsやモニタリングダッシュボードを監視しつつRollingUpdateリソースを作成して見守る"というシンプルなものに集約されました.これはオペレーションを簡潔にするという当初の目的を達成しただけではなく,Maintenance Modeによって,SDNドメインで管理されるNFVサービスの状態を新たに広げたという点に価値があると考えています.インタフェースに注意を向けて開発したので,Maintenance Modeは他のSDNアプリケーションから一貫して扱えます.
オブザーバビリティ
Kubernetesリソースでは,"xx状態であるか否か"を扱うためのデータ構造としてConditionがあります.また,カスタムコントローラが任意のタイミングに発行できるEventというリソースも存在します.これは組み込みのリソースで扱われている一般的な仕組みであり,カスタムリソースに対してもリーズナブルに適用可能という特徴があります.これらはkubectl describeで統一的に確認可能であり,オペレーションをシンプルにします.私は"Maintenance Modeであるかどうか"の情報を,このConditionで表現しました.また,ローリングアップデート中の様々なイベントをそのままEventに整形して発行しています.これにより,ローリングアップデートの実行後,本当に期待通り分散システムが動いているかどうか確認できます.Eventは一定のライフタイムを持ち,その間NIBに残り続けます.もしローリングアップデートが失敗した際には,Event Sequenceを確認することでその原因究明に役立ちます.このように,インフラソフトウェアの開発にはコアとなる機能の開発以外にも,運用をシンプル/高効率にするための仕組みが必要ですが,それを再認識する非常に良い例となりました.
今後の展望
Admission Control
現状KloudNFVリソースを操作する権限を持っているのはVerdaを運用するインフラチームに限られていますが,それでもオペレーションミスが発生する可能性があることを考えると,APIリクエストを適切にバリデーションする仕組みが必要になってきます.Kubernetesで一般的に用いられるAPIリクエストの制御方式には,RoleBindingやAdmission Webhook, Gatekeeperなどのソリューションが存在します.これはローリングアップデートに限らず,KloudNFV全体で採用できる非常に強力なソリューションである一方,コントローラ間のやり取りや既存オペレーションがワークしなくなる可能性もありますし,cert-managerなどのクラスターアドオンが前提となっている等の条件から,導入に先立って注意深く検証する必要があります.後述するインテグレーションテストとともに検討する必要があるでしょう.
インテグレーションテスト
Kubernetesカスタムコントローラの開発では,envtestというパッケージを利用したインテグレーションテストを設計するのがベストプラクティスとされています.特にRollingUpdateのようにリコンサイルアルゴリズムが複雑なものや,私達のKloudNFVにおける各コントローラのように"それぞれが正しく動くことを前提にオーケストレーションされる"場合には,インテグレーションテストの恩恵が顕著に現れます.KloudNFVでは一部のコンポーネントに対しenvtestを利用したコントローラテストを導入していますが,網羅的にテストできているわけではありません.これは,先述したようにKloudNFVが多くの外部システムに依存して動作しているために,その依存をテストから注入できるようにした上で,責任範囲を分離する必要があるからです.現在私はKloudNFVのソフトウェアアーキテクチャを根本から見直しつつ,OpenStack API等の抽象化レイヤを導入して,"コントローラアルゴリズムはすべてenvtestで完結する"世界観を目指しています.そうすればAnsibleやシェルスクリプトを使った"フルインテグレーションテスト"は,OpenStackコンポーネントなど,Kubernetesの外の世界との連携部分に集中できることになります.
Smart Way
私達は,現状のMaintenance ModeとRolling Updateを"Rough"と呼んでいます.これは,いくつかの懸念事項をあえてワークアラウンドでアドホックに対応し,なるべく早くこのメカニズムを運用して,その有用性を実感したいという強いモチベーションがあったためです.ローリングアップデートのストラテジ一つを例にとっても,まだまだ考えなければならないことがたくさんあります.このセクションでは今後の展望として,これから私達が取り組まなくてはならない問題のうちいくつかについて議論することにします.
まずMaintenance Modeについてですが,本記事ではサービスアウトの方法についての議論をご紹介します.すでに述べたとおり,現状私はBGPの経路広報にプレフィックスベースのフィルタリングを適用して制御しています.これによりインバウンドトラフィックの経路を制御していますが,これはBGP運用におけるプラクティカルな経路制御の方法ではありません.私はこのネットワークサービスアウトを更に二分割して,経路フィルタリングの前にAS_PATH prependを行い,一定秒数待つ必要があると考えています.これはリコンサイルアルゴリズムを準手続き的にするという点でチャレンジングであり,いくつかのコントローラアーキテクチャからどれかを採用する必要があります.1つ目のアーキテクチャは,Maintenance Modeを扱うSDNアプリケーション(カスタムリソース+カスタムコントローラ)を作ってしまう,というものです.2つ目は,一つのリソースを複数のコントローラで調整する,というものです.これはcert-managerなどの著名なクラスターアドオンでも採用されているアーキテクチャです.この責任の分離が正しくワークするかについては検討不足ですが,私達はSDNアーキテクチャの設計を0から行い挑戦しつづけるモチベーションがあり,これはその一つに含まれます."カスタムコントローラでネットワークオペレーションをどこまで自動化できるのか"という限界に挑戦する上で,この議論は必要不可欠です.
次にRolling Updateについてですが,ここでは分散システムの困難性にどのようにして立ち向かうか,という議論についてお話します.先程述べた困難性が関わってくる本タスクにおいて,"経路迂回をどのポイントで決定づけるか"というポイントが論点になってきます.例えば近隣ノードの持つ経路情報やBGPピアの状態をNIBにプッシュできれば,Rolling Updateコントローラ側でそれをチェックして意思決定に使用できる,と考えられます.しかし,何らかの問題によりピアのアクティブ/インアクティブが頻繁に切り替わるかもしれません.このようなタイミング問題を解決するのは容易ではありません.また,CLOSのトップまで経路迂回が伝わっているかはわかりませんので,SDNドメイン全体での経路収束を検知するのは現実的ではありません.もちろんすべてのネットワークスイッチにプログラマビリティを設けてすべての状態をNIBに引き上げることはできるかもしれませんが,そこまでストリクトに検証しても,やはりタイミング問題はつきまといます.同じようにLinkStatsの統計情報の増加量をモニタリングしてユーザトラフィックの迂回を検出すること事も考えられますが,これも正しいしきい値を設定するのは簡単ではなく,同じく現実的ではありません.ネットワークを分散システムで実現する私達は,常に"どこまで突き詰めるか"をせめぎ合う必要があります.
このように,私達はインフラソフトウェアを開発するだけでなく,それらをどこまで洗練させるかというところまで,オペレーションや開発コストとすり合わせながら考える必要があります.
最後に
LINEが既存技術をどのように使っているのか,その技術自体がどういうものか,という勉強から始まり,KloudNFVにダイブしていって挑戦的なリコンサイルアルゴリズムを実装するというタスクは,インフラソフトウェアエンジニアを目指す者として貴重な経験をさせていただいたと思っています.ローリングアップデートの仕組みには紹介しきれていない改善点がまだまだありますが,それらを含め,これからもKloudNFVが目指すゴールに貢献していければと思っています.
アルバイト活動をさせていただくにあたって,Verda室のネットワーク開発チームの方々には技術的な議論や大規模なインフラで動作するソフトウェアを開発する上で必要なマインドや観点からご指摘いただきました.特にメンターの城倉さんからは,開発方針のディレクションや様々な知識と技術を教えてくださいました.改めて感謝いたします.
知識ゼロから多くのサービスを支える大規模なDCNを触るまで
私はネットワークやインフラについての知識がほぼ0の状態でアルバイトを始め,多くのサービスを支える大規模なDCNを運用し,仮想ネットワークに関わるソフトウェアエンジニアリングチームに所属することになりました.この経験はとても貴重なものだったという感覚があるので,ここで共有させていただきます.
採用された時点では,大まかに次のスキルを持った状態でした.
- プログラミングについての抵抗は全く無く,またコードを書き始めるまでのフットワークには自信があった
- 実際に2万行程度の開発を趣味にしていた経験から,何から手を付ければいいかわからない,という経験はあまりない
- Linuxの基本的な操作は習得していた
- 知らない技術を目にしたとき,調査によって用語・概念の依存関係をラフにマッピングし,学習の順序を組み立てることはできた
控えめに言っても,今のチームで使っている技術の90%以上はほぼ触れたことがない,もしくは名前だけ知っている程度の知識量でした.その中でソフトウェアエンジニアとしてパフォーマンスを出さなければなりませんでした.この半年間で私が取り組んできたタスクを紹介します.
- LinkStatsの実装
- Kubernetes Admission Webhookの検証とKloudNFVへの導入
- Kubernetesカスタムコントローラのインテグレーションテストでよく使われるenvtestの検証とKloudNFVへの導入
- Maintenance Modeの実装
- Rolling Updateの実装
- Kubernetes cert-managerアドオンの調査と検証
これらに取り組む過程で,ネットワークレイヤのトラブルシューティングが必要になったり,また,そもそもFRRoutingでどのようなコンフィグを適用しているか知る必要があるなど,自分の知識を補填しながらタスクに取り組んでいく,という並行的な作業が必要でした.そのような私がここまでのタスクを達成できたのは,"興味のある技術に対する貪欲さ"があったからだと感じています.LINEにアルバイトとして採用される際,私は"これまでやっていたことが全く通用しない世界に立たされたとしても,インフラ/ネットワークに全身浸かってエンジニアリングするんだ"という強い覚悟がありました.
実際にチームに入っていって,右も左も,自分の足元すら見えない状況に立たされたタイミングで,ネットワークの最も初歩的な知識について横着せずに勉強し始め,とにかくメンターの城倉さんに恥ずかしがらずに質問しつづけました.この"わからないことをわからないと言う"力が役立って,少しずつパフォーマンスを出せるようになったのかな,と思っています.これは,LINE Verda ネットワーク開発チームという環境そのものが"日本で大規模なDCNを触れる稀有な環境"だった,というのも大きいと思っています.
現在はよりルーティングプロトコルの根幹にコントリビューションしたいので,FRRoutingを用いて検証してみたり,実際にコードを読んで理解する,という勉強を行っています.このように"インフラ/ネットワーク領域に対してソフトウェアエンジニアの側からアプローチ"する手法が向いていたのかもしれません.