
2018年の夏インターンに参加し、その延長としてResearch Labsでアルバイトをしている中込 優です。アルバイトでは、「複数人の発話から目的の人の発話のみを取り出す技術」について研究しています。
インターンで取り組んだ内容を2019年3月度 音声(SP)・応用/電気音響(EA)・信号処理(SIP)研究会で発表し、音声研究会学生ポスター賞を頂くことができました[1]。その研究内容について紹介します。

背景
近年、スマートフォンやスマートスピーカーや車、会議システムなどに音声認識技術が多く実用化されています。しかし、雑音が多い状況や複数人が同時に話している状況では、音声認識の性能は大きく劣化することが知られています。
そこで、音声認識の前段階として、目的の話者の音声のみを歪みなく抽出する(音声強調)ことが重要になり、盛んに研究されてきました。特に、複数人が同時に話している音声などでは、話者の違いなどに基づき、それぞれの話者の音声を分離し、その後に目的の話者の音声を抽出する技術が研究されてきました。
しかし、全ての話者を分離するには繰り返し計算や数秒間の入力信号が必要になったり、また話者数が増えた場合に精度が悪くなるなどします。この問題を解決するために、事前に分かっている目的の話者の情報を補助情報として利用することで、目的の話者のみを抽出する技術が注目を集めています。
例えば口元の画像情報や、事前に収録した目的の話者の音声などを利用するものについて、その有効性が示されています。また、一般にロボットやテレビ会議といった状況ではカメラの情報を用いて目的の話者の方向が得ることができるため、マイクに対する話者の方向も目的の話者の補助情報の1つとして挙げられます。音源の方向は、画像などの別センサの情報を必要とせず、事前に目的の話者の音声を録音する必要もない、簡単に入手可能な情報といえます。
そこで、本研究では、目的の話者の方向情報を用いることで、複数人の声や雑音が混ざった音から目的の話者の声だけを綺麗に歪みなく取り出すことを目指した音源分離手法の検討を行っています。
問題設定
今回は多チャンネルのマイクロホンで収録した、複数人の話者が異なる方向から同時に話している音声を扱います。目的話者の方向は事前に得られているとし、それを用いて目的の話者の音声だけを抽出します。
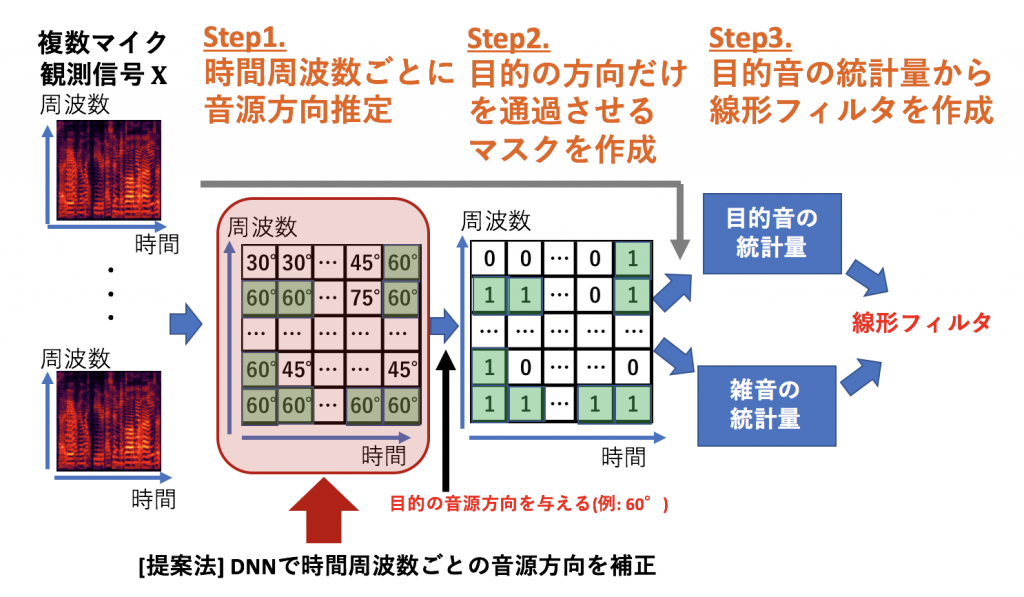
提案手法
多チャンネルで観測した場合、音源が左側にある場合、音は左側のマイクロホンに先に届き、右側のマイクロホンに遅れて届く、といったマイクロホンへの到達時間の差を元に、観測した信号がどの方向から来たか推定することができます。
よって、到達時間差を用いた音源方向推定に基づき、以下の図に示すように目的の方向から到来する音のみを通過させるマスクを推定します。
このマスクを観測信号にかけるだけでは、パワーが小さい時間周波数が0になってしまうなど、歪みが大きく生じてしまいます。そのため、マスクと観測信号を用いて得られる目的音と雑音の統計量を元に、目的音をより歪みなく抽出するフィルタ(線形ビームフォーマ)を求め、このフィルタを元の観測信号にかけることで、複数の人の声が混ざった音声から目的の音声のみを歪み少なく取り出すことができます。
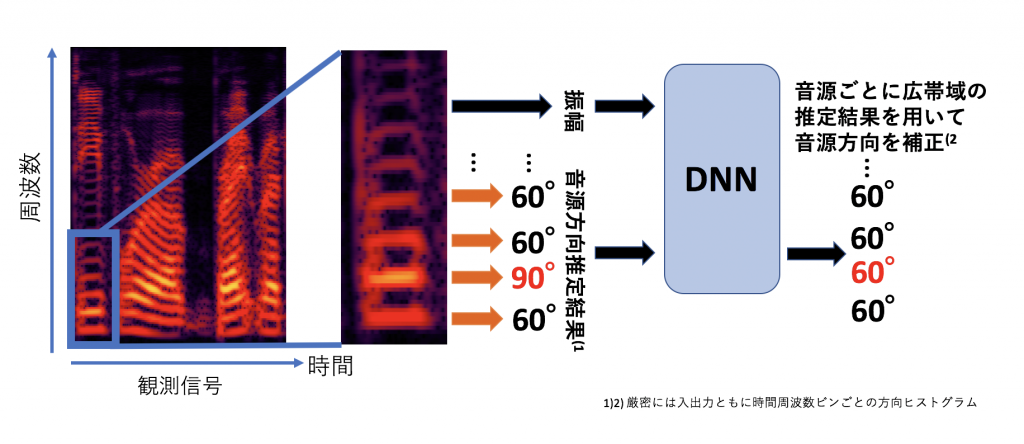
しかし、時間周波数ごとの音源方向推定は部屋の壁に反射して別の方向から音が到来しているように推定されるなど、マイク間隔のズレ、ロボットの頭部での回折などにより、精度が大きく劣化するという問題がありました。
そこで、本研究では、下の図でも見られるように、人の声は基本周波数の倍音に強いパワーを持つ(調波構造)などの特徴的な周波数特性を有していることに注目し、そのような周波数特性をニューラルネットワークで学習することにより、時間周波数ごとの音源方向の補正を行いました。
下の図のように、同じ音源ごとの広帯域の音源方向推定結果を用いて、誤った推定結果の補正をニューラルネットワークで学習していると解釈できます。
実験の結果、提案法による音源方向の補正を用いることで、目的音に対する雑音抑圧率(SNR)を3.2dB、 歪み度合い(SDR)を5.8dB、音声認識率に寄与する指標(MFCC距離)を0.4程度改善することができました。話者が様々な方向の場合のデータを学習していることで、目的方向に偏りなく目的の音声を抽出できます。
また、提案するニューラルネットワークではマイク配置固有の情報を用いた形式で情報を入力しているため、学習で用いていないマイク配置を用いても再学習せず、同じモデルを適用できることを確認しました。
今回の構成はリカレントニューラルネットワークなどの時間方向に再帰的な構造を有しておらず、ニューラルネットワークに1フレーム分のデータしか与えていないため、リアルタイムで適用できると考えられます。
来場者からは、マイク配置を変えてもニューラルネットワークの再学習を必要としない構成になっているのが良い、信号処理部分とデータでモデルを学習させる部分の使い分けが良い、などのコメントを頂きました。
まとめ
本記事では、自分がアルバイトで取り組み、音声研究会学生ポスター賞を頂いた研究について紹介しました。メンターの方を始め多くの社員の方々からアドバイスを受けながら研究を進めることができました。今後も引き続きアルバイトを続け、研究を進めていきます。
[1]中込 優, 戸上真人, ”ニューラルネットワークによる音源方向補正に基づく目的音源抽出のための適応ビームフォーマ,” 信学技報, vol. 118, no. 497, SP2018-85, pp. 143-147, 2019年3月.