
こんにちは。LINE Fukuoka でデータ分析やその基盤作りをしている tkengo です。この記事は LINE Advent Calendar 2016 の 12 日目の記事です。
2016 年の 11 月下旬、LINE Fukuoka で 2 日間の社内ハッカソンが開催されました。その時にいくつかのチームが結成され、IoT や VR、機械学習など、それぞれのチームで挑戦的なプロダクトが作られ、大いに盛り上がりました。今日は、その時に私たちのチームが作ったディープニューラルネットワークを使った以下のようなリアルタイム画風変換アプリケーションのお話をしたいと思います。
※ちょっとわかりにくいですが、下側のスマホのカメラに映っている映像に対してリアルタイムに画風変換処理を施し、それを上側のスマホで表示しています。
背景
2015 年の夏の終わり頃、ニューラルネットワークを使って画像の画風を変換するアルゴリズム A Neural Algorithm of Artistic Style が、 Gatys らドイツの研究者グループによって発表され、世界中で話題になりました。日本でも同時期に Chainer を使った実装 とその 解説記事 が出ましたので記憶にあたらしい方も多いのではないでしょうか。

ただ、Gatys らの提案したアルゴリズムでは、ニューラルネットワークへの入力として適当に生成したノイズ画像 (もしくはコンテンツ画像やスタイル画像) からはじめて、だんだんとコンテンツとスタイルが混ぜ合わさった画像に近づいていくようなアプローチです。イテレーション毎に毎回、誤差を逆伝搬させる計算をする必要があるため画像生成に時間がかかりすぎていました。その後、そのような問題を解決するために 2016 年になって非常に高速に画風変換を行うためのアルゴリズムが発表されていきました。
- Texture Networks: Feed-forward Synthesis of Textures and Stylized Images
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution
これらは CPU のみを使っても数秒〜数十秒のオーダーで変換処理が完了するような高速さで、まさしくタイトルにもある通りリアルタイム性すら求めることができそうです (※学習にはもちろん時間がかかります。高速なのは学習済みモデルを使った変換処理です。)
さらに、これらの変換を動画に適用してみようというアルゴリズムも登場しています。
このように様々な画風変換のアルゴリズムが発表されており、画風変換の人気の高さがうかがえます。
さて、私たちはこのような画風変換をスマートフォンのカメラを通してリアルタイムで処理できると面白いのでは、と考えました。Prisma というアプリをご存知でしょうか?静止画に対して様々な画風変換のフィルタをかけることができるものですが、ちょうどそれのリアルタイム版と考えてもらって問題ないでしょう。ハッカソンでは、リアルタイム画風変換アプリケーションを作るために、前述した Johnson らによるアルゴリズム Perceptual Losses for Real-Time Style Transfer and Super-Resolution を使いました (※この中には画像の高解像度化の手法も含まれますが、そちらは関係ないのでこの記事中では扱いません)。アプリケーションとして一般に公開できるレベルまで到達することはできませんでしたが、いろいろな試行錯誤と工夫を繰り返してなんとか形にだけはなったので、その取り組みを紹介していきたいと思います。
リアルタイム画風変換
まずは Johnson らによる画風変換のアルゴリズムの簡単な紹介をしたいと思います。
モデル
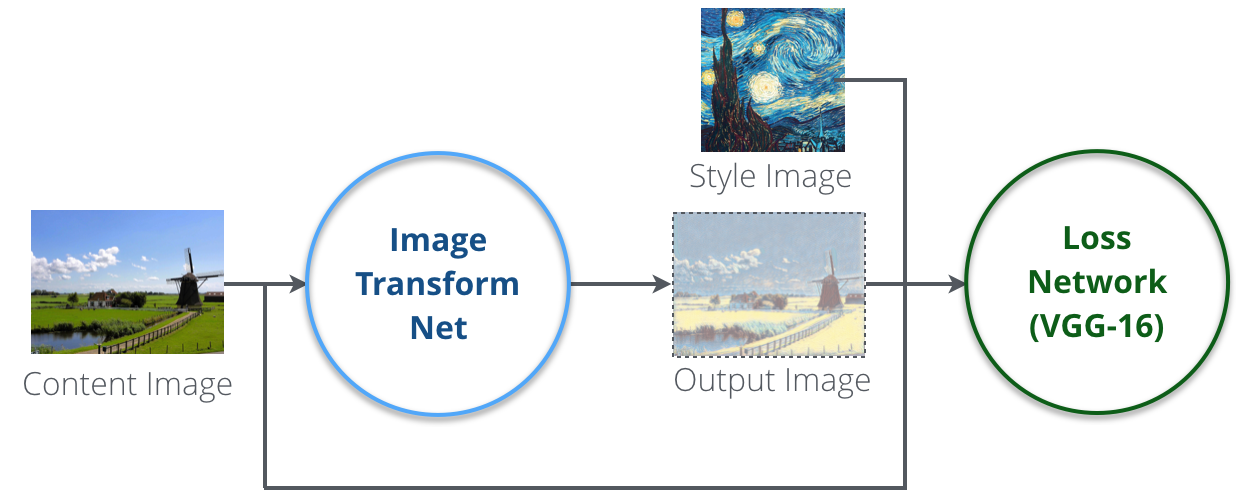
Johnson らの提案したモデルには、上図に示すような 2 つのネットワーク Image Transform Net と Loss Network (VGG-16) が存在します。
Image Transform Net は実際に入力画像にスタイルを適用して変換してくれるもので、複数の畳み込み層と Residual Block を組み合わせたディープニューラルネットワークです。そして Loss Network (VGG-16) の方は、Image Transform Net の学習に使われるニューラルネットワークで、複数の畳み込み層と全結合層が組み合わさったものです。
Image Transform Net

Image Transform Net は上図のようなネットワークです。このネットワークに入力として画像データを渡すと、出力として画風変換後の画像が生成されることになります。
このニューラルネットワークは Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks に記述されているアーキテクチャガイドラインに従っています (ちなみにこの論文は日本でも話題になった、イラストとかアイドル顔とかを自動生成してくれるあの有名なネットワーク)。即ち
- プーリング層は使わずに代わりにストライドによるダウンサンプリング及びアップサンプリングを行う
- Batch Normalization を使う
- 出力層以外の箇所で活性化関数として ReLU を使う
といった事項に従ったネットワークとなっています。
変換の途中の Convolution Layer と Residual Block のいくつかを出力してみるとこのようになります。

本当はもっとチャンネル数がありますが、全部表示すると多すぎるので適当に選んでいます。縦に並んだ画像は同じ層からの出力結果で、右に行くほど深い層からの出力となります。コンテンツ画像のエッジや位置情報などはしっかりと残ったまま、次第になんとなくスタイル画像の質感やポイントなどが強調されてきているように見えます。
Loss Network (VGG-16)
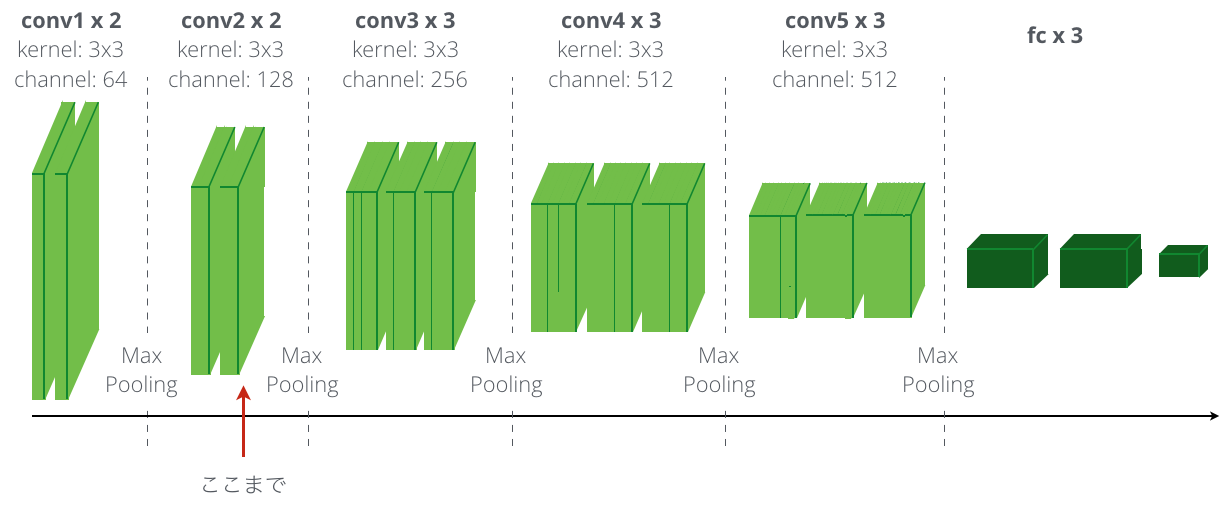
VGG-16 というのは、画像分類のための既存のディープニューラルネットワークです。実体は Very Deep Convolutional Networks for Large-Scale Image Recognition で提案されている、畳み込み層と全結合相を 16 層重ねた上図のようなネットワークで、これを Loss Network として使います。ただし実際に使うのは畳み込み層の部分だけで、全結合層の部分は使いません。
モデルの学習
Image Transform Net と Loss Network の 2 つのネットワークが存在しますが、Loss Network の方は公開されている学習済みの重みを利用するので実際に学習させるのは Image Transform Net だけになります。学習時には主に Feature Reconstruction Loss と Style Reconstruction Loss という 2 種類の損失関数を利用していくことになりますが、論文中ではこれらのことを論文のタイトルにもなっている Perceptual Losses と表現しています。(実際はこの 2 つの損失関数に加えて、Pixel Loss と呼ばれるより単純な損失関数及び Total Variation Regularization と呼ばれる正則化項も存在します)
Feature Reconstruction Loss
Feature Reconstruction Loss は Image Transform Net で変換した画像とスタイル画像にどれくらい差があるのか、を表すものです。この損失を最小化することは、感覚的にスタイル画像に近づいているのがわかるけど、ただし実際にまったく同じものになるわけではない、そんな状態を作り上げることになります。
実際の詳しい計算式は省略しますが、計算には変換後の画像とスタイル画像をそのまま使うのではなく、それらを Loss Network に通したものを使います。Loss Network は先にネットワークの構造を図示したように全部で 16 層ありますが、このネットワークの最後まで伝搬させるわけではなく、このアルゴリズムでは実際には途中の conv2 のグループの 2 つ目の畳み込み層まで伝搬させたものを使います。
Style Reconstruction Loss
Style Reconstruction Loss も変換後の画像とスタイル画像の差を表すものです。Feature Reconstruction Loss の場合は変換後の画像とスタイル画像が大きくかけ離れそうな場合にペナルティとして損失が大きくなるようなものですが、スタイル (例えば色や質感、パターンなど) についてもペナルティを与えたほうが良く、それを実現するためのものが Style Reconstruction Loss です。
こちらも計算式は省略しますが、変換後の画像及びスタイル画像を Loss Network に通したものを使います。Feature Reconstruction Loss と違って、こちらは conv1 の 2 つ目、conv2 の 2 つ目、conv3 の 3 つ目、conv4 の 3 つ目、の 4 つの結果を足し合わせたものを使います。
アプリケーションへの適用
画風変換のアルゴリズムが理解及び実装ができたら、次はそれをどのようにアプリケーションへ適用していくかを考えていきます。私たちのチームには iOS の開発者がおらず Android の経験者が数人いたため、必然的に Android アプリケーションを作ることになりました。とはいえ、さすがにハッカソン本番の 2 日間だけでは開発できないだろうと考えて、ハッカソンの数週間前からチームメンバーと一緒に色々と調査・実験するところからはじめました。
Android 上で実行する
Android のカメラを通してリアルタイムに画風変換を行うために、まず一番最初に思いつくアプローチは Android 上で画風変換のニューラルネットワークを実行することです。学習は遅いですが、画風変換の処理自体は高速なのでなんとかリアルタイムで実行できるのではないかと考え、とりあえず組み込んで実行速度を測定してみました。
Android に組み込むために TensorFlow を使って画風変換アルゴリズムを実装しました。TensorFlow の計算部分は C++ で実行されるため、Android からは NDK の機能を使って TensorFlow の C++ 部分を呼び出すことができます。
しかし、なんとなく予想はしていましたが現実はそんなに甘くありませんでした。最近の端末のカメラは解像度が高いのでそのまま変換しようとするとまったく処理速度が追いつかず、リアルタイムはおろか静止画の画像 1 枚を変換するのにすら時間がかかる状態でした。解像度を下げればなんとかリアルタイムにはなるものの、もはや何を映しているのかわからなくなります。どのくらいまで解像度を下げたかというと...
| 解像度 | 処理時間 | 画質 |
|---|---|---|
| 64 x 64 | 1 秒程度 | もはや何が映っているかわからない |
| 128 x 128 | 4-6 秒程度 | まだよくわからない |
| 256 x 256 | 20 秒以上 | ボヤケながらも何となくわかる |
まだまだモバイルの CPU は弱そうです。このような結果となってしまいましたので、残念ながらこのアプローチはボツとなりました。この時点で本番まで残り 2 週間程度。
サーバー上で実行する
Android 上で実行できないのならと次に思いつくのが、ハイスペックなマシンを用意してそこで変換処理を実行させることです。Android からはフレーム毎にカメラからの映像をキャプチャしてそれをサーバーへ送信し、変換後の画像を受信するアプローチです。比較的最近のスペックのサーバーであれば、モデルを事前に読み込んでおけば 256 x 256 の画像を処理するのに 1 秒もかかりません。
しかし、単純に HTTP 経由でフレーム毎に画像を送信していたのでは今度はその部分がボトルネックになってしまい、リアルタイム性が失われてしまいます。ですので、クライアント - サーバー間の通信は RTMP というプロトコルを使って対応しました。ということで、最終的には以下の様な構成図になりました。

nginx-rtmp-module を使った Nginx を前段に置き、FFmpeg のフィルタに TensorFlow を組み込んだカスタムフィルタを自作して変換処理を実現しています。RTMP で変換後の映像をストリーミングしているので、RTMP に対応したアプリがあればどんなデバイスでも受信することができます。
FFmpeg といえばご存知、動画や音声などのマルチメディアデータのコンバート、ストリーミングなどを一手に引き受けてくれるソフトウェアです。フィルタの機能を持っており、色調の変換やスケーリングなど、ストリームに対して様々なフィルタを掛けることができます。さらにこのフィルタは自作することができますので、非常に高い拡張性を持っています。そこで、FFmpeg に流れてきたストリームのフレーム毎に自作フィルタを使って前述のニューラルネットワークで画風変換を行い、それをまた配信するための方法を調査。この手法がイケそうだとわかった時点で、本番まで残り 1 週間程度。そろそろ時間がなくなってきました...
FFmpeg のフィルタは C で開発しますが、ニューラルネットワークの実行部分は TensorFlow で実装されているので TensorFlow を組み込んだ状態でバイナリをコンパイルする必要があります。これが結構大変で、以下のような手順で TensorFlow を組み込んだフィルタを開発しました。実は、このように無事にリンクさせることができる、とわかったのがハッカソン本番前日。ギリギリでした。
- C を使ってフィルタの開発を行う。
- TensorFlow を make して、スタティックライブラリ libtensorflow-core.a を生成する (実は最近 make できるようになりました)。
- FFmpeg の Makefile を修正して、リンク時に libtensorflow-core.a をリンクさせるようにする。
結果
このように下調べにかなりの時間を費やしてしまいましたが、ハッカソン当日はそれまで色々と準備してきたお陰で一気にシステムを作り上げることができ、それを実行したデモンストレーションが冒頭の動画です。
実は、先の手順で make してできたスタティックライブラリは GPU をサポートしていないそうなので、変換処理は全て CPU で実行するようにしています。デモンストレーションでは、AWS のインスタンスを使いました。コンピューティング最適化のグループに含まれる c4.8xlarge というインスタンスです。結構お高いので、起動しっぱなしにしておくわけにはいかず、ハッカソン期間中及びデモンストレーション中だけ起動していました。
まとめ
いかがでしたでしょうか。想定通りに行かないところも多々ありましたが、とりあえず動くものが形にはなってハッカソンでも無事に成果発表ができました。ただし、まだ公開はしていないので、その点は今後の課題ではあります。
さて、話は変わって、つい最近 Google が Supercharging Style Transfer というタイトルのブログを公開しました。画風変換の新しい論文を発表したとのことです。1 つのニューラルネットワークで複数のスタイルを学習することができるようで、それによって複数スタイル間でのスムーズな補間もできるようになってるようです。論文はこちら A Learned Representation For Artistic Style。
アルゴリズム考案合戦はそろそろ終わるのかもしれませんが、リアルタイム性やここで紹介したようなスムーズ補間が現実となってきたので、個人的には今度はそれを使って新しいものがどんどん生まれて来て欲しいなーと感じます。ハッカソンでの私たちのチームのように、挑戦はしてみたけどうまくいかず試行錯誤を繰り返している人はたくさんいると思います。まあでもとりあえずやってみましょう。楽しい未来はすぐそこだ!
この記事を読んだ誰かの創造性を少しでも刺激できたなら幸いです。
来週の月曜日は Yappo さんによる 「YAPC::Hokkaido 2016 と Fukuoka Perl Workshop #27 の登壇報告」です。お楽しみに!