
Reactive Streamsとは?
LINE PlusでオープンソースソフトウェアのArmeriaとCentral Dogmaを開発しているUM IKHUNです。私はReactive Streamsの概念と、Reactive Streamsをオープンソースの非同期HTTP/2、RPC、RESTクライアント/サーバーライブラリーであるArmeriaで使用する方法について紹介したいと思います。今回の記事では、まずReactive Streamsの概念について解説します。
Reactive Streamsは、公式ホームページであるreactive-streams.orgで以下のように定義しています。
Reactive Streams is a standard for asynchronous data processing in a streaming fashion with non-blocking back pressure.
ホームページでは、Reactive Streamは、ノンブロッキングバックプレッシャー(Non-blocking back pressure)を利用した非同期データ処理の標準であると言っています。では、「ストリーム処理」、「非同期(asynchronous)方式」、「バックプレッシャー」そして「標準」といったそれぞれの言葉が意味することをより詳しく見てみます。
ストリーム処理
下図は通常のデータ処理とストリーム処理を比較したものです。
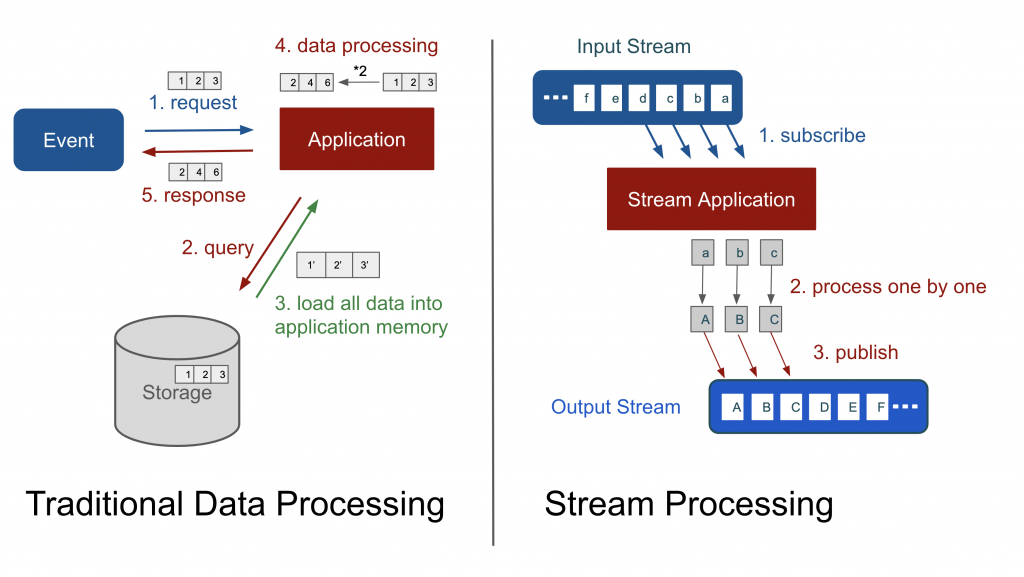
左の通常のデータ処理では、データ処理のリクエストが来ると、ペイロード(payload)をすべてアプリケーションのメモリーに保存してから次の処理を行います。追加で必要なデータもリポジトリから取得して、メモリーにロードします。この方式の問題点は、送信されたデータはもちろん、リポジトリから取得したデータまですべてのデータがアプリケーションのメモリーにロードされてから、応答メッセージを作成できるということです。もし必要なデータのサイズがメモリーのサイズより大きければ、「out of memory」というエラーが発生します。また、サービスを運用してみると、個別のリクエストが「out of memory」を発生させなくても、一瞬多くのリクエストが殺到してしまい、多量のGC(Garbage Collection)が発生してサーバーが正常に応答できない場合が多々発生します。
一方、大量のデータを処理するアプリケーションにストリーム処理を適用すると、サイズが小さいシステムメモリーでも大量のデータを処理できます。入力されたデータに対するパイプライン(上の図全体をパイプラインと表現しています)を作ってデータが入ってくるがままに購読(subscribe)し、処理した後、発行(publish)までノンストップで処理できます。このようにすると、サーバーは大量のデータも柔軟に処理できます。
非同期方式
非同期方式については、同期(synchronous)方式と比較しながら説明します。下図は、同期方式と非同期方式の処理過程を示したものです。
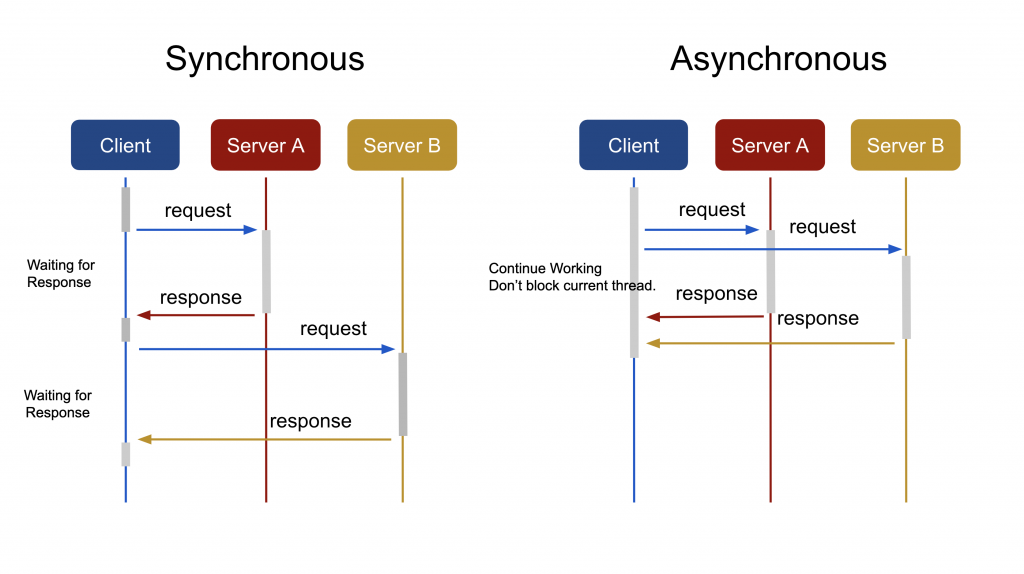
同期方式では、クライアントがサーバーにリクエストを送ると、応答を受けるまでブロッキング(blocking)されます。ブロッキングされるということは、現在のスレッド(thread)は、他のタスクを処理せずに、現在のタスクが終わるのを待っていることを意味します。そのため、2つのリクエストをAとBのサーバーに送るとしたら、Aの応答が終わって、ようやくBにリクエストを送ることができます。しかし、非同期方式では、現在のスレッドがブロッキングされないため、他のタスクを続けることができます。Aにリクエストを送った後に他のタスクを処理することや、あるいはBに他のリクエストを送ることもできます。同期方式と比較して非同期方式のメリットをまとめると以下のようになります。
- 速いスピード - 2つのリクエストを同時に送るため、応答スピードがより早くなります。
- 少ないリソースを使用 - 現在のスレッドがブロッキングされずに他のタスクを処理できるため、より少ない数のスレッドでより多くのリクエストを処理できます。
バックプレッシャー
バックプレッシャーについて説明するために、RxJavaで有名になったObserverパターン(observer patten)とプッシュ(push)型、そしてプル(pull)型について説明します。
プッシュ型
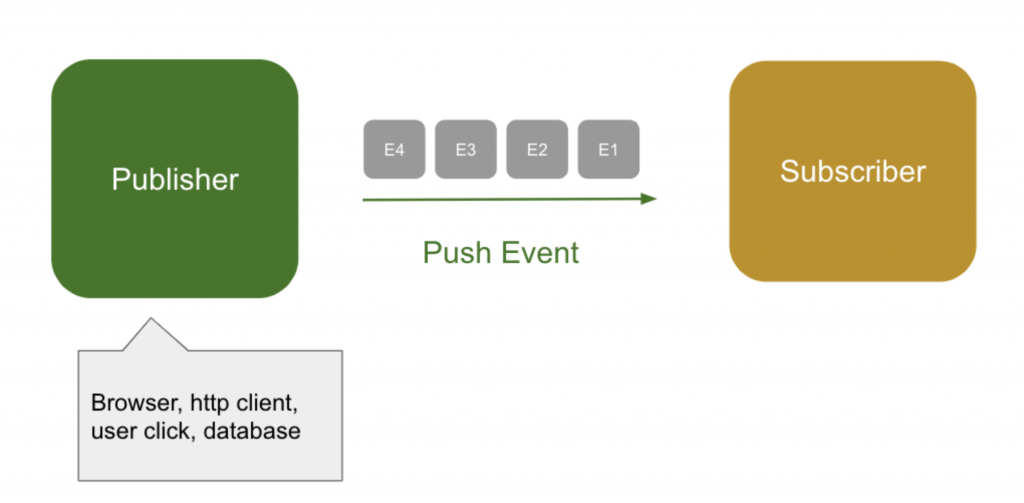
Observerパターンでは、発行者(publisher)が購読者(subscriber)にプッシュする形でデータが送信されます。発行者は購読者の状態を考慮せず、データを送信するだけです。仮に、発行者が1秒に100個のメッセージを送るのに、購読者は1秒に10個しか処理できないとしたら、どうすればいいでしょうか。購読者が処理できないメッセージ(待機中のイベント)を、キュー(queue)を利用して保存するしかありません。

サーバーが使えるメモリーは限られています。仮に、1秒に100個のメモリーを続けてプッシュするとしたら、バッファは一瞬で使い切られるはずです。バッファを使い切ってオーバーフロー(overflow)が発生すると、どうなるでしょうか。固定長バッファと可変長バッファで、発生する事象が異なります。
- 固定長バッファ:オーバーフロー(overflow)が発生すると、新規で受信したメッセージを拒否します。拒否されたメッセージは再びリクエストすることになりますが、再リクエストの過程でネットワークとCPU演算のコストが追加で発生します。
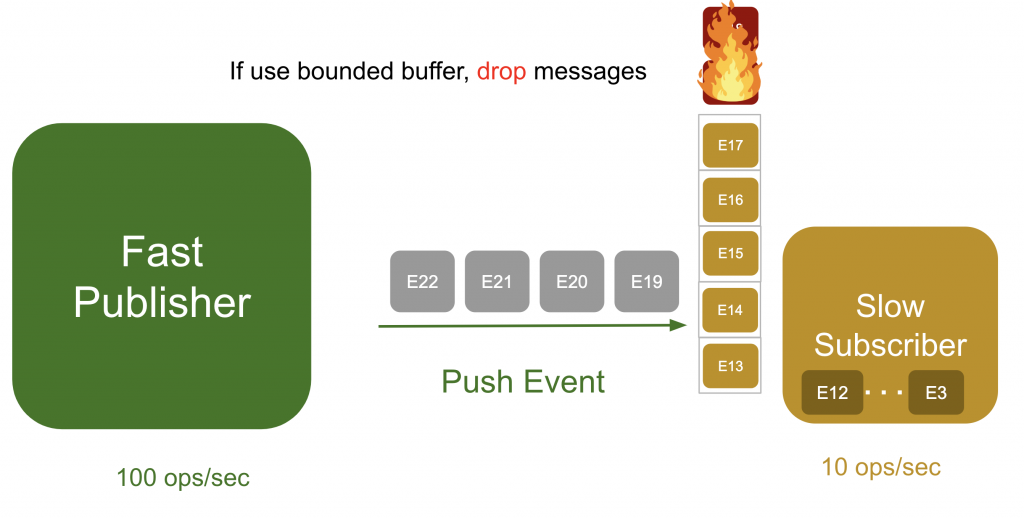
- 可変長バッファ:オーバーフロー(overflow)が発生すると、イベントを保存するときに「out of memory」エラーが発生し、サーバークラッシュ(crash)が発生します。「誰がそのように実装するんだ?」と思いがちですが、Javaで多く使用されるListが可変長データ構造型です。例えば、SQLで多量のデータを問い合わせすると、DBMSは発行者になり、皆さんのサーバーが購読者になります。そうなると、Listデーター構造型にデータを全部入れ込もうとして多量のGCが発生するため、サーバーが正常に応答できない状態になることがあります。
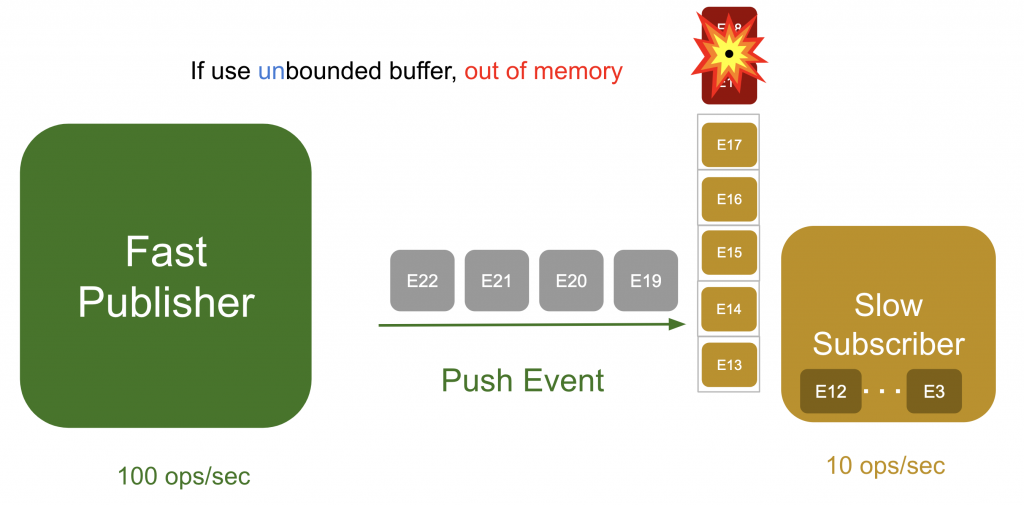
この問題をどう解決できるでしょうか。発行者がデータを送信する際、購読者に必要なデータだけを送ることができれば、解決できるのではないでしょうか。これが、バックプレッシャーの基本原理です。
プル型
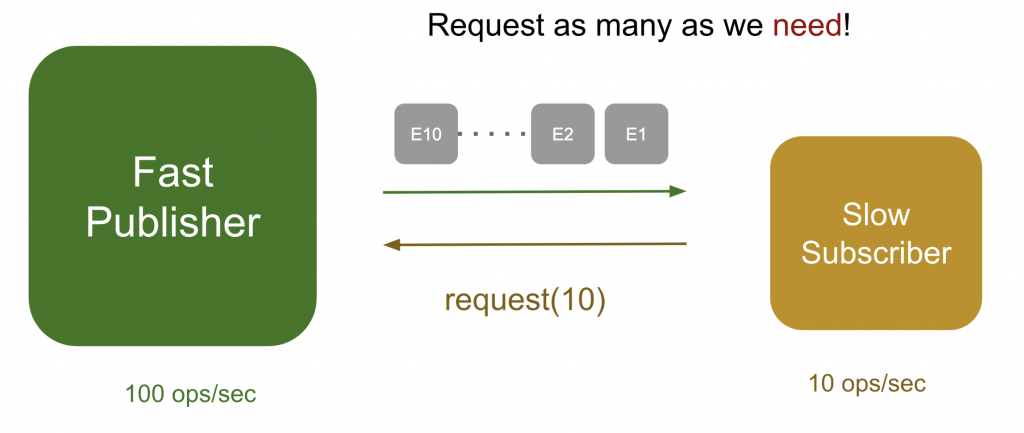
プル型では、購読者が10個を処理できるとしたら、発行者に10個だけリクエストします。発行者はリクエストされた分だけ送信し、購読者はそれ以上「out of memory」エラーを心配しなくて済みます。
ここでより柔軟に、購読者がすでに8つのタスクを処理していたら、追加で2つだけさらにリクエストし、購読者が現在処理できる範囲内でメッセージを受け取るようにします。プル型では、このようにして送信されるすべてのデータのサイズを購読者が決めます。このようなダイナミックプル型のデータリクエストにより、購読者が受け入れられるだけのデータをリクエストする方式がバックプレッシャーです。
標準
Reactive Streamsは、標準化されたAPIです。なぜ標準化が必要で、どのような過程で標準になったかを説明します。
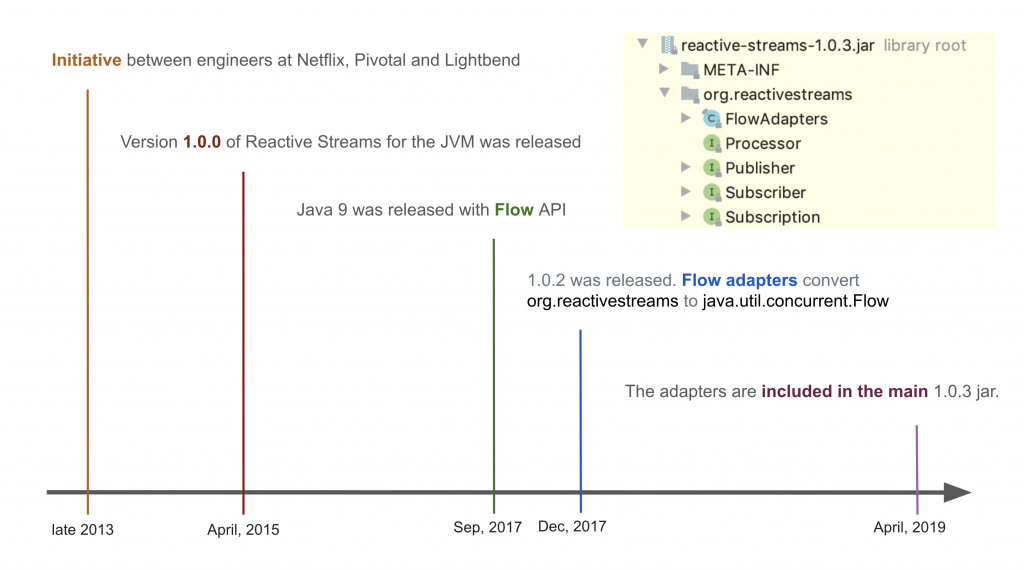
Reactive Streamsは、2013年にNetflixとPivotal、Lightbendのエンジニアらが初めて開発を手掛けました。NetflixはRxJavaを、PivotalはWebFluxを、そしてLightbendは分散処理アクター(actor)モデルを実現したAkkaを開発した会社です。これらの会社はすべて、ストリームAPIが必要な会社でした。しかし、ストリームはお互い有機的に絡まって流れてこそ初めて意味があります。データをストリームで流し続けるためには、別々の会社が共通の仕様を策定して、実装する必要があります。そのため標準化が必要でした。
Reactive Streamsでは、2015年4月にJVMで使用するためのReactive Streams 1.0.0をリリースしました。そして、2017年9月にReactive StreamsのAPIと仕様、プル(pull)型の使用原則をそのままポーティングして、Flow APIという名前で、java.util.concurrentパッケージの下に含めたJava 9がリリースされました。これは、コミュニティや一部の企業でリードして開発していたReactive Streamsが、Javaの公式機能になったことを意味します。さらに3か月後、Reactive StreamsでFlowと相互変換が可能なアダプターをリリースし、Flow APIで既存のライブラリーを使用できるようになりました。
Reactive Streams API
Reactive Streamsは、言葉だけを見ると複雑に見えますが、実際に中を見ると非常に簡単なAPIの組み合わせで構成されていることがわかります。
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}
public interface Subscription {
public void request(long n);
public void cancel();
}- PublisherのAPIは、Subscriberの購読を受けるためのsubscribeが1つあるだけです。
- SubscriberのAPIは、受け取ったデータを処理するためのonNext、エラーを処理するonError、作業完了時に使用するonComplete、そしてパラメータとしてSubscriptionを受けるonSubscribeです。
- SubscriptionのAPIは、n個のデータをリクエストするためのrequestと購読をキャンセルするためのcancelです。
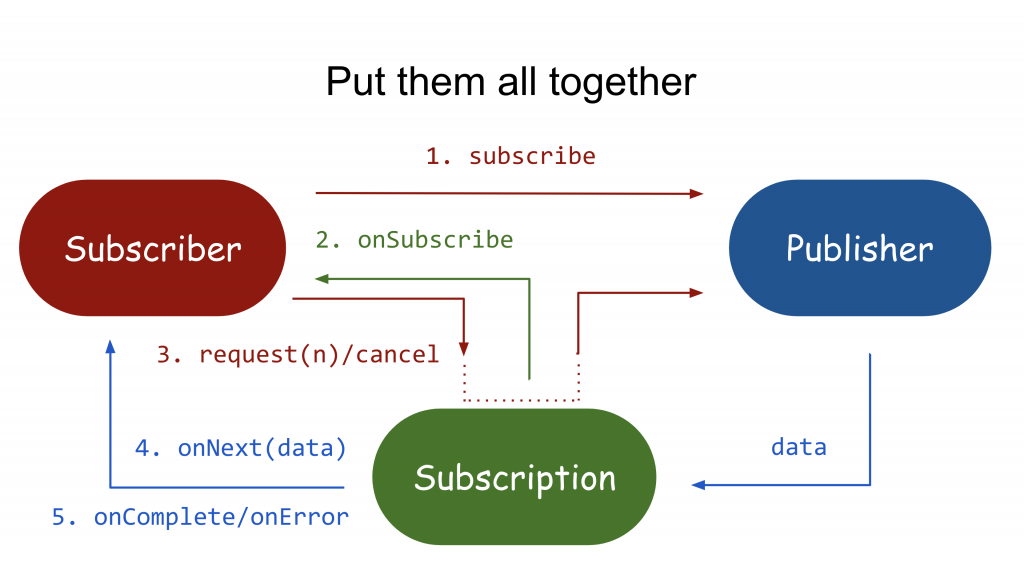
ここからは、Reactive Streamsで上記のAPIを使用する流れを見てみます。
- Subscriberが、subscribe関数を使用してPublisherに購読をリクエストします。
- Publisherは、onSubscribe関数を使用してSubscriberにSubscriptionを送信します。
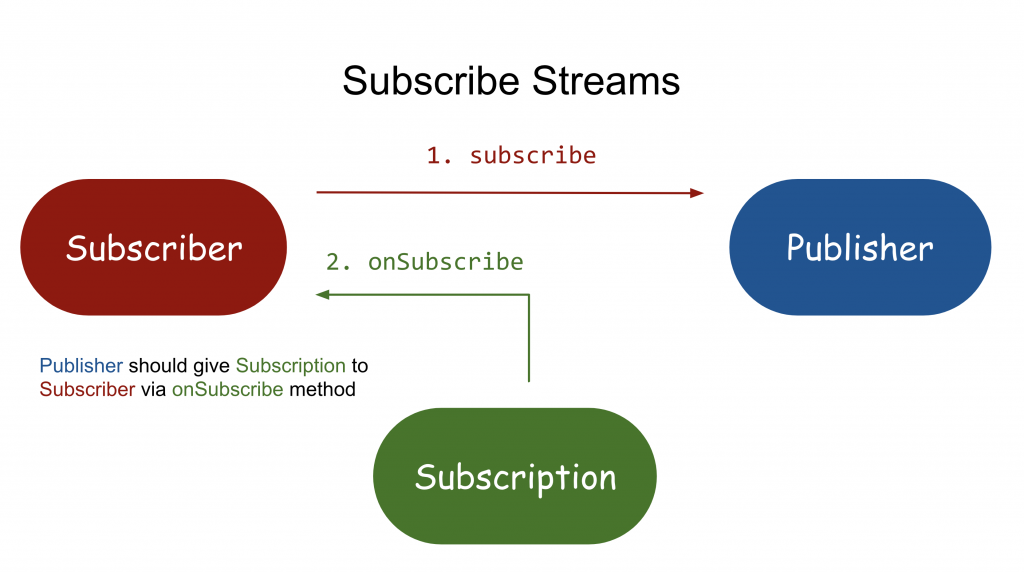
- これからSubscriberは、SubscriberとPublisher間の通信を媒介します。Subscriberは、Publisherに直接データをリクエストしません。Subscriptionのrequest関数により、Publisherに送信します。
- Publisherは、SubscriptionによりSubscriberのonNextにデータを送信し、完了するとonCompleteを、エラーが発生するとonErrorシグナルを送信します。
- SubscriberとPublisher、Subscriptionの3つがお互い有機的に繋がって通信をやり取りし、subscribeからonCompleteまで繋がります。このようにバックプレッシャーが完成されます。
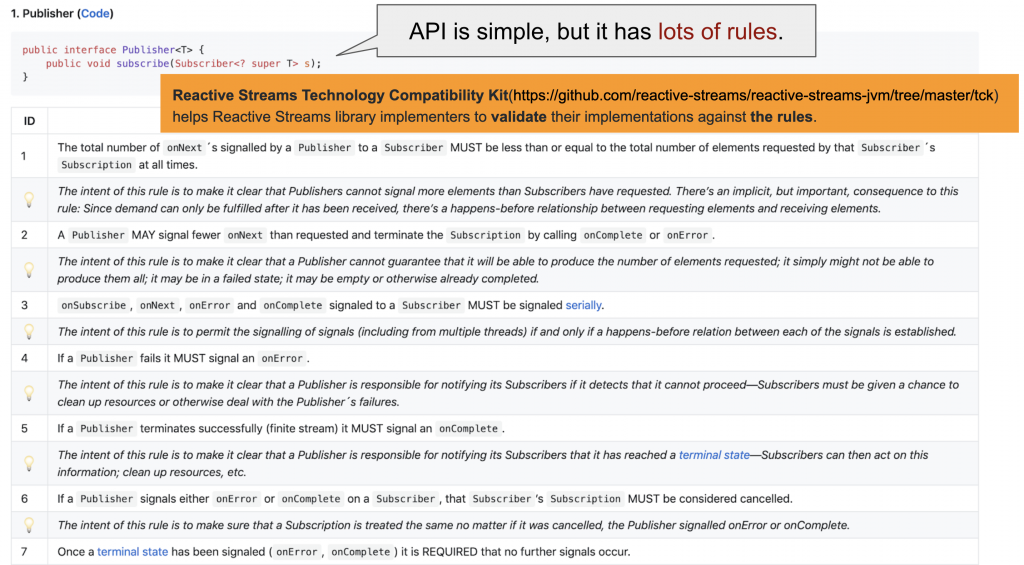
バックプレッシャーが良いのは分かりますが、果たしてどのように使えばいいでしょうか。Reactive Streams APIは、GitHub repoにアクセスしてみても上記で確認したインターフェースがすべてです。他に実装がありません。
では、直接実装して使用すればいいでしょうか。前述のルール通りPublisherインターフェースを実装し、それを購読する際にSubscriptionを作成して送信するように実装することはできます。しかし、これがすべてではありません。Reactive Streamsでは、API以外にも仕様書があります。この仕様書には、シンプルなインターフェースとは違って、実装の際に従うべき複雑なルールが示されています。
この仕様に従って直接実装した機能は、Reative Streams TCKというツールで検証できます。当該分野の専門家でなければ、すべてのルールを満たすように実装するのはなかなか厳しいことです。特に、Publisherを実装するのが難しいです。Javaの有名なReactive Streams実装の1つであるProject ReactorのGitHubに登録されている課題(Issue)を見てみると、あるユーザーが自分が作ったカスタムPublisherがFluxとうまく繋がらないという内容で登録した課題があります(参照)。これに対してProject Reactorからは、「作らないでください!」ときっぱりと回答しています。学習の意味で、ミニプロジェクトとして作るのはお勧めします。勉強にもなりますし、いいと思います。しかし、実際の運用に使用するコードであれば、検証されてないコードよりは、Flux.create()のような作成者関数を活用してPublisherを作ったほうがいいと思います。Reactive Streamsを使用するためには、直接実装するよりは既にきちんと作られて検証までされている実装を使用することをお勧めします。では、このような実装には、どのようなものがあるでしょう。
Reactive Streamの実装と相互運用性(interoperability)
Reactive Streamsにはさまざまな実装が存在します。それぞれの実装は特性が少しずつ違うため、状況と必要に応じて選んで使用できます。
- 純粋に、ストリーム演算処理だけが必要なのであれば、RxJavaやReactor Core、Akka Streamsなどを使用します。
- リポジトリのデータをReactive Streamsで取得したい場合は、ReactiveMongoやSlickなどを使用します。
- Webプログラミングと繋がっているReactive Streamsが必要であれば、ArmeriaやVert.x、Play Framework、Spring WebFluxを活用します。
このようにそれぞれ特性が違う実装ではありますが、すべてReactive Streamsでお互いに通信できます。
Reactive Streamの相互運用
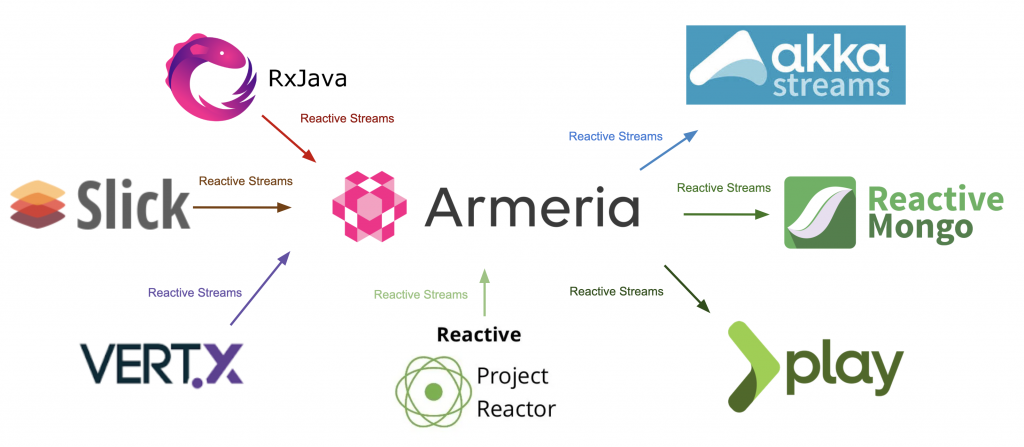
RxJavaのObservableは、Reactive Streamsにより、ArmeriaのHttpResponseやProject ReactorのFluxに変換できます。また、MongoDBのDataPublisherはAkka StreamsのSourceによってストリーム演算ができます。
仮に、MongoDBで取得したデータを演算処理した後、HTTPレスポンスで送信するとします。Reactive Streamsを利用してMongoDBでデータを取得すると、まずデータの購読ができるPublisherだけ返されます。next()関数の呼び出しと同時にデータが送信されるIteratorとは違って、PublisherではSubscriberからのリクエストがないと実際のデータが送信されません。
// Initiate MongoDB FindPublisher
FindPublisher<Document> mongoDBUsers = mongodbCollection.find();以下のコードのように、ObsevableのfromPublisherを使用して、MongoDBのFindPublisherと繋げることができます。また、map演算子を利用して取得結果からageフィールドを抽出できます。
// MongoDB FindPublisher -> RxJava Observable
Observable<Integer> rxJavaAllAges =
Observable.fromPublisher(mongoDBUsers)
.map(document -> document.getInteger("age"));RxJavaのObservableはObserverパターンで実装されているため、これをReactive Streamsに変換するためには以下のコードのようにtoFlowable関数を利用する必要があります。変換の後、Fluxのfrom関数を利用し、RxJavaのFlowableとFluxを繋げることができます。
// RxJava Observable -> Reactor Flux
Flux<HttpData> fluxHttpData =
Flux.from(rxJavaAllAges.toFlowable(BackpressureStrategy.DROP))
.map(age -> HttpData.ofAscii(age.toString()));Fluxのデータ構造をHTTPレスポンスで使用するには、以下のようにデータの前にHTTPヘッダーを付与します。その後、ArmeriaのHTTPレスポンスとして使用するにはHttpResponse.ofを呼び出してFluxと繋げます。
// Reactor Flux -> Armeria HttpResponse
HttpResponse.of(Flux.concat(httpHeaders, fluxHttpData));前述しましたが、肝心なことは、一般的なIteratorとは違ってPublisherでは、まだSubscriberがないためデータが送信されず、実際の演算(変換、操作、計算など)はまったく行われていないということです。ただ、データがどのようにSubscriberに流れていくか、その行為を記述しただけです。Reactive Streamsでは、Subscriberがデータをリクエストする前までは、いかなるデータも送信してはなりません。
おわりに
今回の記事では、Reactive Streamsとその実装、そして相互運用性について解説しました。Reactive Streamsをウェブプログラミングで活用するためには、HTTPリクエストとレスポンスにバックプレッシャーを利用します。Reactive Streamsを利用する場合は、バックプレッシャーによって流入されるトラフィックの量に柔軟に対応する必要があります。次回の記事では、トラフィックの量に柔軟に対応するためにArmeriaでReactive Streamsをどのように使用しているかを詳しく解説します。お楽しみに!