
こんにちは。LINE Growth Technologyの宇都宮です。現在は出前館に出向して、主に出前館のコンシューマ向けアプリケーションのAPI開発を担当しています。
私が出前館の開発に携わり始めたのは昨年(2020年)の夏でした。当時、懸案事項となっていたのがメインDB(Oracle)の高負荷です。出前館のメインDBはオンプレミスで構築されており、スケールアップもスケールアウトも難しい状況にありました。
そこで、データ参照用DB(PostgreSQL)をAWSに構築し、データ取得のみ行うAPI(参照系API)のDBアクセスを参照用DBに向ける、というプロジェクトが発足しました。このプロジェクトについては、出前館のエンジニアブログに記事がありますので、興味のある方はぜひご覧ください。
本記事では、参照用DBへの移行後、店舗検索機能にElasticsearchを導入することで、パフォーマンス改善を行ったプロジェクトについて紹介します。
店舗検索機能Elasticsearch化プロジェクトの発足
参照系APIのクエリを参照用DBに向けるようにしたことで、メインDBの負荷は軽減しました。また、AWSに移行したことで、簡単にスケールアウトできるようになり、負荷に強いシステムにもなりました。
一方で、出前館の参照系APIの中でも特に重要なものの一つである店舗検索APIは、速度面に課題がありました。当時の店舗検索APIの平均レスポンスタイムは1.5秒で、お世辞にも速いとは言えない数字でした。店舗検索用のSQLはJOINするテーブルが20個近くあり、サブクエリが入れ子になっているなど、非常に複雑でした。そのためクエリのコストも高く、Oracleからのベタ移植直後は、結果が返ってくるまで30秒くらいかかっていました。これをPostgreSQL向けにチューニングして、実行時間1秒程度までは削りましたが、これ以上は難しそう、という感触がありました。
また、出前館の検索機能には、自然言語検索が弱いという課題もありました。
これらの課題の解決のため、Elasticsearchを導入して検索の性能と機能を強化するプロジェクトが発足しました。
なお、Elasticsearchを選定した理由は、LINEデリマで利用実績があったためです。
アーキテクチャと技術スタック
店舗検索APIのアーキテクチャは以下の図のようになります。

参照用DBにあるデータを、バッチでElasticsearchにロードします。参照用APIはElasticsearchに検索リクエストを送り、検索結果をクライアントに返します。
本プロジェクトでは、以下の技術スタックを使用して開発しました。
- Amazon Elasticsearch Service
- Amazon Aurora PostgreSQL
- Amazon Elastic Container Service
- APIサーバの実行環境
- バッチはScheduled Tasksで実行
- 参照用API、データ同期バッチ
開発で苦労したこと(1) スキーマ設計
店舗検索をElasticsearch化するにあたって、最も苦労したのはスキーマ設計です。
RDBでは正規化によってデータの重複をなくすように設計するのが一般的です。一方、Elasticsearchでは、データのバリエーションの数だけ非正規化を行って、フラットなデータの持ち方をした方が、上手くいくこともあります。非正規化にメリットのある事例を以下に紹介します。
出前館には注文種別(orderType)という概念があり、当日注文か翌日以降の注文かで配達可能エリアなどに違いがあります。このバリエーションを1つのドキュメントで表現すると以下のようになります。
{
"shopId": 1,
"services": [
{
"orderType": 0,
// 当日注文の場合の配達エリア、待ち時間等
},
{
"orderType": 1,
// 翌日以降注文の場合の配達エリア、待ち時間等
}
]
}店舗の検索時には、orderTypeは0か1のいずれかが指定され、当日注文か翌日以降注文のどちらかのデータのみを使用します。しかし、このデータの持ち方だと、注文種別に関わらずservices以下のデータを全部取得することになります。services以下には配達エリアなどサイズの大きなデータが含まれるため、この設計だとデータ取得のパフォーマンスが悪くなります。
このような場合、Nested型を使うと orderType = 0 の方のデータだけを取得するようなクエリを書けますが、クエリが複雑になります。
一方、以下のように非正規化すれば、単純なクエリで取得できますし、パフォーマンスも悪くありません。
[{
"shopId": 1,
"orderType": 0
},
{
"shopId": 1,
"orderType": 1
}]ただし、非正規化も万能ではなく、データのバリエーションが多い場合にはドキュメント数が増大し、パフォーマンスが劣化する可能性があります。
このように、RDBのスキーマ構造をそのまま移し替えるのではなく、検索のニーズに合わせてスキーマ設計をする必要があるのが難しいポイントでした。実際、プロジェクトの進行過程では何度か設計変更がありました。
開発で苦労したこと(2) パフォーマンスチューニング
検索APIとデータ同期バッチの双方でパフォーマンスの問題に突き当たりました。
検索APIについては、主に店舗の配達エリアのデータが膨大であることに起因して、レスポンスが遅いという問題が発生しました。こちらは、必要な項目だけを取得することで、十分な性能に改善することができました。
データ同期バッチの方はより根が深く、データの取得・更新に関わる処理全般のチューニングが必要になりました。バッチのパフォーマンスチューニングにおいて重要なのは、どういう単位でデータを取得し、更新するかという設計だと思います。例えば、出前館の商品データの場合、商品を店舗単位で取得するのとチェーン単位で取得するのとでは5倍くらい性能が違います。ただ、このような知識はサービス固有になるため、他サービスに適用することは難しいでしょう。
一方、サービスを問わず汎用的に使えそうなチューニングもあったので、2つ紹介します。
1. 書き込み処理のBulk化にBulkProcessorを使う
データ同期バッチは当初からマルチスレッド化されており、書き込み時にはElasticsearchのBulk APIを使うなど、高速化が図られていました。
ただ、Bulk処理に関しては一度に送信するデータ量の制限(インスタンスタイプによって異なり、10MiBまたは100MiB)も考慮しながら送る必要があるなど、やや制御が煩雑になっていました。
そこで、Java REST Clientの便利クラス BulkProcessor を使うことで、Bulk処理の制御を簡単に行えるようにしました。BulkProcessorを使ったコードの流れは以下のようになります。
// BulkProcessor の設定
var bulkProcessorBuilder = BulkProcessor.builder(...);
bulkProcessorBuilder.setBulkActions(1000); // 1000件溜まったらflush
bulkProcessorBuilder.setBulkSize(new ByteSizeValue(5, ByteSizeUnit.MB)); // 5MB溜まったらflush
bulkProcessorBuilder.setConcurrentRequests(1); // 1件の並行リクエストを許可する(最大で2件のリクエストが並行して実行される)
var bulkProcessor = bulkProcessorBuilder.build();
// BulkProcessorにリクエストを追加
var request = new IndexRequest("shop");
request.source("{"shopId": 1,"orderType": 0}", XContentType.JSON);
bulkProcessor.add(request);
// BulkProcessor は追加されたリクエストの数またはサイズが閾値を超えると、自動でリクエストを送信する
// 未送信のリクエストを全て送信し、完了を待つ
bulkProcessor.awaitClose(60, TimeUnit.SECONDS);これによって、データ量の多い更新処理は15MB、細かくて数の多い更新処理は2万件ずつ、といった具合に各バッチの特性に合ったバルクサイズを設定できるようになり、データ同期バッチの実行速度と負荷を最適化しやすくなりました。
2. Graviton2インスタンスへの移行
2021年5月から、Amazon Elasticsearch ServiceでもAWS Graviton2インスタンスを選択できるようになりました。Graviton2はAWS独自のARMベースCPUです。Graviton2インスタンスは同サイズのIntel CPU搭載インスタンスよりも性能が良く、それでいて価格は1割ほど安いという特長があります。
出前館では2021年6月7日にElasticsearchをGraviton2インスタンスへ移行しました。これによってピーク時の最大CPU使用率が15ポイントほど下がりました。移行前はピークタイムには75%を超えることもありましたが、移行後は60%を超えるのも珍しくなりました。

バッチの実行時間や検索クエリのレイテンシは、目立った改善こそしなかったものの同程度の数字にはなっており、満足のいく結果といえます。
Elasticsearch化の成果
Elasticsearch化後に顕著な違いが生まれたのは、店舗検索APIのレスポンスタイムです。もともと平均1.5秒ほどかかっていましたが、現在は平均0.4秒程度になっています。まだ改善の余地はありますが、まずまずの数字だと思います。
以下は参照系API全体のアクセス数と平均レスポンスタイムのグラフです。3/25 14:00(店舗検索APIのElasticsearch化)を境に、平均レスポンスタイム(緑色の線)が大きく下がっているのが分かります。
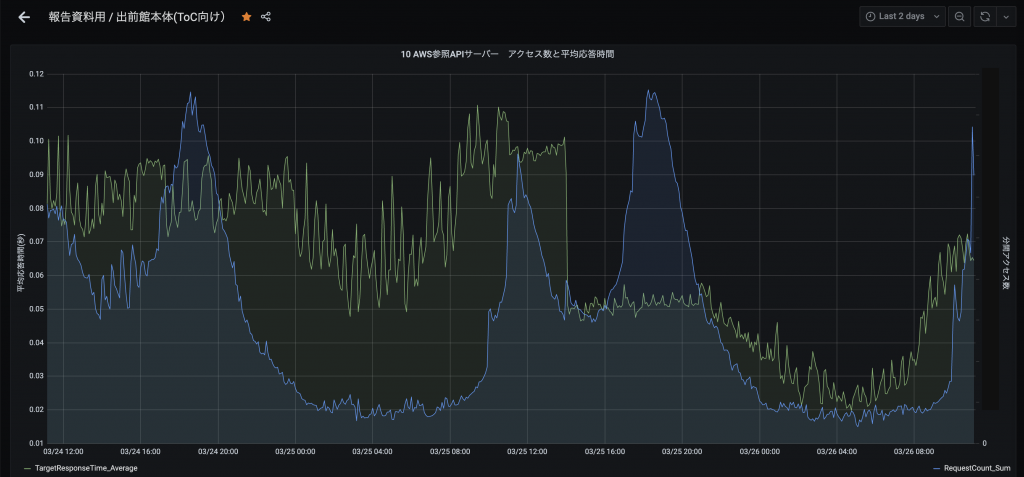
また、従来はパフォーマンスの問題で実現が難しかった機能についても、Elasticsearchを使って実装できるようになりました。例えば、店舗一覧画面の「過去に注文したお店」機能でもElasticsearchを使って店舗データを取得しています。
今後の展望
現在はElasticsearchを利用しているのは店舗検索機能だけですが、商品検索機能にも導入を進めています。また、フリーワード検索機能の強化も検討中です。
出前館でお店や商品をスムーズに探せるよう、引き続き改善を進めたいと思います。
採用情報
LINE Growth Technologyでは、LINEの各種サービスの成長を促進する開発を行っています。
サーバーサイドエンジニア / LINE Growth Technology / Tokyo