
こんにちは。LINEでクライアント保護ソリューションであるAIR ARMORの開発を担当しているCHUNG SANG MINです。前回の記事では、サンプルソースコードのコンパイル過程を見ながら、難読化が行われる段階を確認しました。今回の記事では、ORKの難読化がどのように動作するか、またサンプル実行ファイルで見てみましょう。
実行ファイルの改ざん方法
まず、サンプルの実行ファイルをリバーシング(reversing)して、実現した内容と逆に動作するように改ざんしてみます。
リバーシングを実行する最も速い方法は、出力に使用されるシンボル(symbol)の情報を見つけることです。ディスアセンブラー(disassembler)を使用すると、実行ファイルの実現内容を確認できます。このようにして確認すると、結果の出力に使用した文字列の参照位置を簡単に把握できます。把握した後は、その近くで当該文字列の出力を区別する分岐文の位置さえ見つければ済みます。以下の例では、灰色で選択された行のjnzアセンブリ言語コマンドで出力が分岐されることがすぐに分かります。そうしたら、当該分岐を実行するコードを改ざんするだけで終わりです。

バイナリエディタでも当該位置を簡単に修正できます。修正するjnz(jump if not zero)アセンブリ言語のOpcodeは0F85で、逆に動作するjz(jump if zero)アセンブリ言語のOpcodeは0F84です。実行ファイルで0F95を0F94に修正してから保存すると、簡単に改ざん作業が完了します。
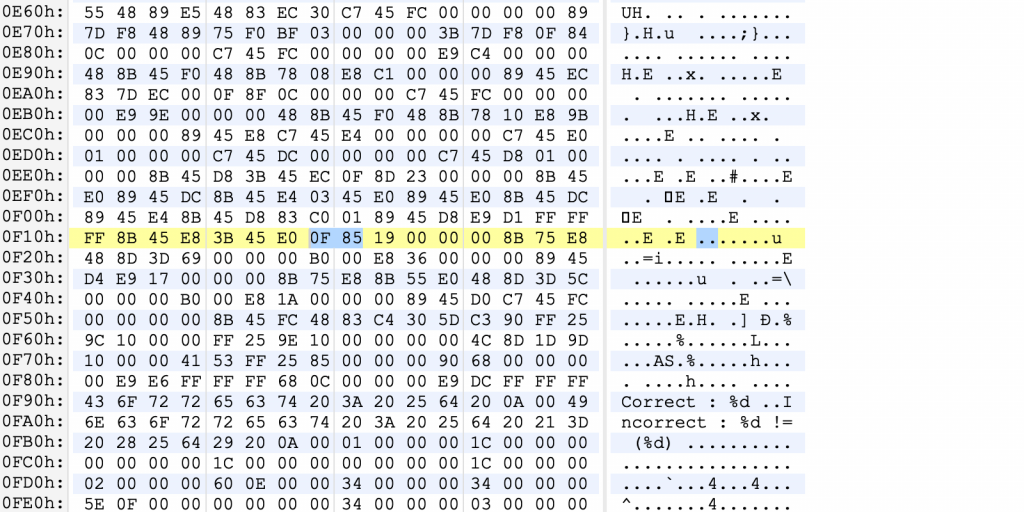
このように改ざんされたサンプルファイルを実行すると、以下のように結果が以前とは逆に出力されます。

ORKの難読化
上記のように実行ファイルが簡単に改ざんされてしまうことを防ぐため、ORKで難読化作業をしてみます。
ORKでは、すべての難読化作業を最適化パスで登録します。各機能を細分化し、個別のパスで実現しました。それぞれの難読化機能には特に個別の名称を与えなかったため、大体の説明で機能を並べてみます。ソースコードの文字列が露出されないように変更する文字列の難読化、定数アクセスを演算で行う難読化、分岐文や繰り返し文などの制御フローを変更する難読化、構成要素を毎回違う順番に再配置する難読化、 二項演算を他の形の演算に置き換える難読化、連続のコマンドが不連続に見えるように分離する難読化など、さまざまな難読化を実装し、新しい難読化機能を続けて追加しています。
サンプルファイルを保護するために文字列の難読化と再配置の難読化、制御フローの難読化をそれぞれ適用して、結果を見てみましょう。
文字列の難読化
ORKの文字列の難読化機能は、ソースコードで使用されている文字列を認識できない形に変更した後、参照される時に復元する方法で静的解析に露出される可能性のある文字列を保護します。実行コードに保存される文字列をLLVM IRから見つけて暗号化された文字列に取り換え、動的にヒープ(heap)メモリーを割り当てた後、復元された文字列を保存するLLVM IRを当該の文字列を参照位置に追加する方式で難読化します。
下図は、文字列の難読化機能を適用する前と後の制御フローを簡単に示したダイアグラムです。

文字列を置き換える基本機能に加え、性能に与える影響を最低限に抑えるための遅延ローディング(lazy loading)機能と、ヒープメモリーの再利用および同期化処理などの機能を追加で実現しました。また、復元コードの予測とフッキング(hooking)、またはコードリフティング(lifting)などの攻撃を防ぐための機能も合わせて追加しました。

以下のように難読化されたサンプル実行ファイルからは、これ以上文字列を見つけることができません。

参考までに、リバーシングの観点からは、実行ファイルに存在するすべてのシンボルはソースコードと同じくらい重要な情報です。ところが、ソースコードで使用した文字列以外にも様々なシンボル情報が、開発者が認識していない状態で実行ファイルに含まれることがあります。静的に参照されるライブラリのファイル名と関数名はもちろん、C++のRTTI(Runtime Type Information)でクラス名まで露出されることがあります。今後、このような多様なシンボル情報も合わせて取り除くことができる機能を拡張する予定です。
再配置の難読化
既に確認したコンパイルの過程で、元のソースコードはASTでLLVM IRを経てアセンブリ言語、そして機械語に至る一連の変換過程を経ています。各段階は、前の資料の形を一定の方法で解析して変換するため、元のソースコードと最終の機械語の間には部分ごとに関係性が発生します。例えば、ソースコードで特定の分岐文を修正すると、実行ファイルでも該当する機械語の部分のみ変更されるという関係性が観察されることがあります。つまり、実行ファイルをアップデートしても、以前のファイルとの違いを見つけると、修正された内容をすぐ把握できるということです。それを再配置の難読化で補うことができます。
ORKの再配置の難読化は、非常に簡単な原理で実現しました。元のソースコードで一定の形で生成されるLLVM IRの構成要素を、難読化時点で任意に再配置し、コンパイラのバックエンドが毎回異なる形のアセンブリ言語を生成するようにします。元の実行ファイルと再配置の難読化を適用した実行ファイルのバイナリーを比較した結果は次のとおりです。非常に簡単なサンプルソースコードでしたが、全く構造の違う実行コードになりました。
- 原本の実行ファイルのバイナリー

- 再配置の難読化を適用した実行ファイルのバイナリー

制御フローの難読化
ORKの制御フローの難読化は、コードの各種分岐文と繰り返し文を1つの巨大なswitch 構文にして、全体の流れを分かりにくくする難読化方法です。特定の構文の動作を確認するためには、全体の場合の数を検証する必要があるため、解析に多くの時間を費やすことになります。この方法は「制御フローグラフの扁平化(Control Flow Graph Flattening)」と呼びます。これはかなり古くから研究されている難読化技術です。
関数内部のすべてのベーシックブロック(basic block)を任意の順番に並べ、各ベーシックブロックの実行条件をswitch 構文の条件に保存し、関数のエントリポイントが switch 構文のスタートポイントに繋がるようにLLVM IRを変更する方式で難読化を行います。
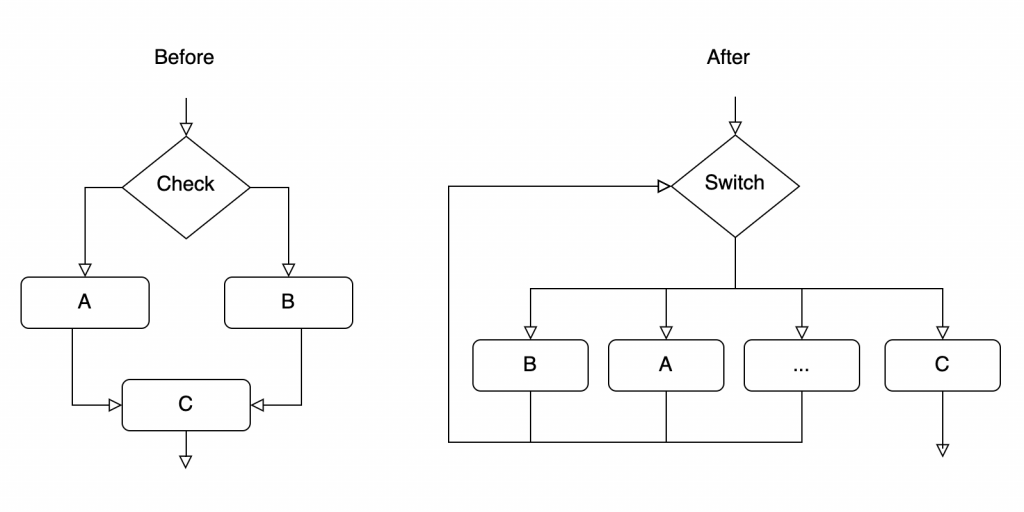
順番に従って配置されていたベーシックブロックを、同じレベルに並べるだけで強力な難読化効果を得ることができます。また、switch構文の同期化イシューを処理し、自動化された予測攻撃を防ぐためのさまざまな機能も合わせて適用しました。
制御フローの難読化は、他の難読化機能と合わせて使用すると、さらに大きな効果を得ることができます。例えば、連続のコマンドまたは関数呼び出しのような特定のコマンドを、別のベーシックブロックに分離した後、制御フローの難読化を適用すると、生成される switch 構文の複雑度がさらに高くなります。以下のように、元の実行ファイルでは簡単に見つけられる分岐条件文jnzですが、難読化された実行ファイルではもう見つけることができません。
- 原本の実行ファイル

- 制御フローの難読化を適用した実行ファイル

ORKで難読化した実行ファイルの確認
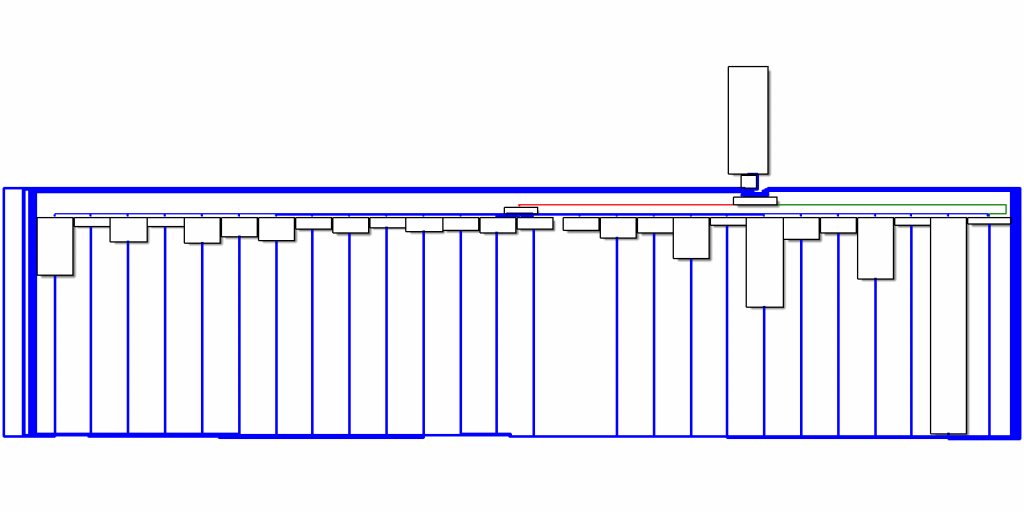
まず、原本のサンプル実行ファイルの制御フローグラフを改めて見てみましょう。以下のように動作の構造が簡単に把握可能であることが確認できます。

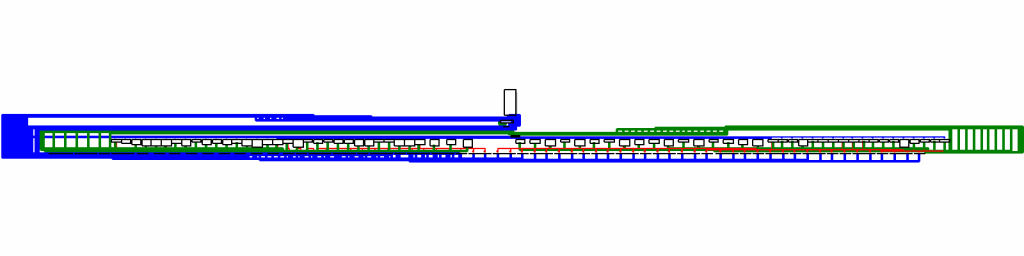
次は、サンプル実行コードにORKを利用し、前述で説明した3つの難読化機能、文字列の難読化と再配置の難読化、制御フローの難読化を適用した後の制御フローグラフを見てみます。以下のように3つの難読化をすべて適用した実行ファイルは 、制御フローグラフで動作の構造を簡単に把握できません。他の難読化機能のコードを含むすべての実行コードの制御フローが、同じレベルでソートされるため、単純なサンプル実行ファイルにも関わらず解析は容易ではありません。
他の難読化パスも合わせて適用すると、以下のようなレベルで強力に実行コードを保護することができます。
実装された内容によって、できるだけ強力な難読化を適用すべき部分もあり、性能を優先するため最低限に抑えて適用すべき部分もあります。そのため、ソースファイルや関数単位で難読化を追加したり除外できるように設定機能を提供しています。
おわりに
アプリの改ざんに対応する技術を実現するためには、多くの開発資源が必要です。今までは現実的な問題もあって短期的な技術を中心に対応してきました。しかし、現在は難読化コンパイラを他の保護技術と一緒に使用し、長期的な難読化ライフルサイクルを管理できるようになりました。
今後、新しい難読化アイディアを実現して追加することはもちろん、ORKがサービスプロジェクト全体において使用できるよう、Xcode、Android NDK、Unity、Unrealなどの開発環境へのサポートを改善していきます。また、SwiftやMSVCなどへとサポートするプラットフォームを拡大する計画です。