
こんにちは、LINE株式会社 Verda 2チームの西脇です。先日の記事で聴講者としてコンテナ関連の発表を中心にいくつか気になるセッションを取り上げさせていただきましたが、2つ目になる本記事では我々がOpenStack Summit Vancounverで発表してきた「Excitingly simple multi-path OpenStack networking: LAG-less, L2-less, yet fully redundant」の内容をご紹介させていただきます。
弊社の発表について
今回のサミットでは、新しいリージョンで取り組んでいるEast-Westのネットワークトラフィックに強いデータセンタネットワークアーキテクチャとそれに対するNeutronインテグレーションに関して、私と同僚のサミルの2名で発表を行いました。英語にはなりますが下記に発表動画と資料のリンクを掲載させていただきます。
こちらのブログでも内容をご紹介させていただきます。
水平スケール可能なデータセンタネットワーク
今まで我々のPrivate Cloudで採用していたネットワークアーキテクチャは、Hypervisorを収容するToRスイッチのダウンリンクよりアップリンクの帯域が小さかったためToRをまたぐ通信にボトルネックがありました。VM間通信が多く発生する場合には、そのボトルネックによるスループット低下が顕著に現れていました。
もちろん、VM間の通信が少ない環境ではあまり問題にならないのですが、昨今のPrivate Cloud上のVMのユースケースにマイクロサービスアーキテクチャを採用したシステムやマシンラーニングなどVM間で通信をするようなシステムが増え、我々のPrivate Cloudでもそれらのユースケースに対応していく必要が出てきました。
最初にとった対策としては、VM間で通信が必要なVMを同じToR配下のハイパーバイザーにスケジュールするような仕組みを設け、ToRのボトルネックを回避するようにしていました。しかし、この回避策ではシステムをすべて同じ障害ドメインに収容する必要性があること、OpenStack Novaだけでは該当ワークロードに対してスケジューリングの強制ができないため、OpenStack Projectの1つであるwatcherのようなVM作成後にVMのワークロードに応じて収容されるHypervisorを変更されるような仕組みが必要になることなど課題が残っていました。

そのため、新しいリージョンでは根本的な解決を試みとして、RFC7938で推奨されているBGPを使ったClos Network構成を採用し、ノンブロッキングなネットワークを構築しました。
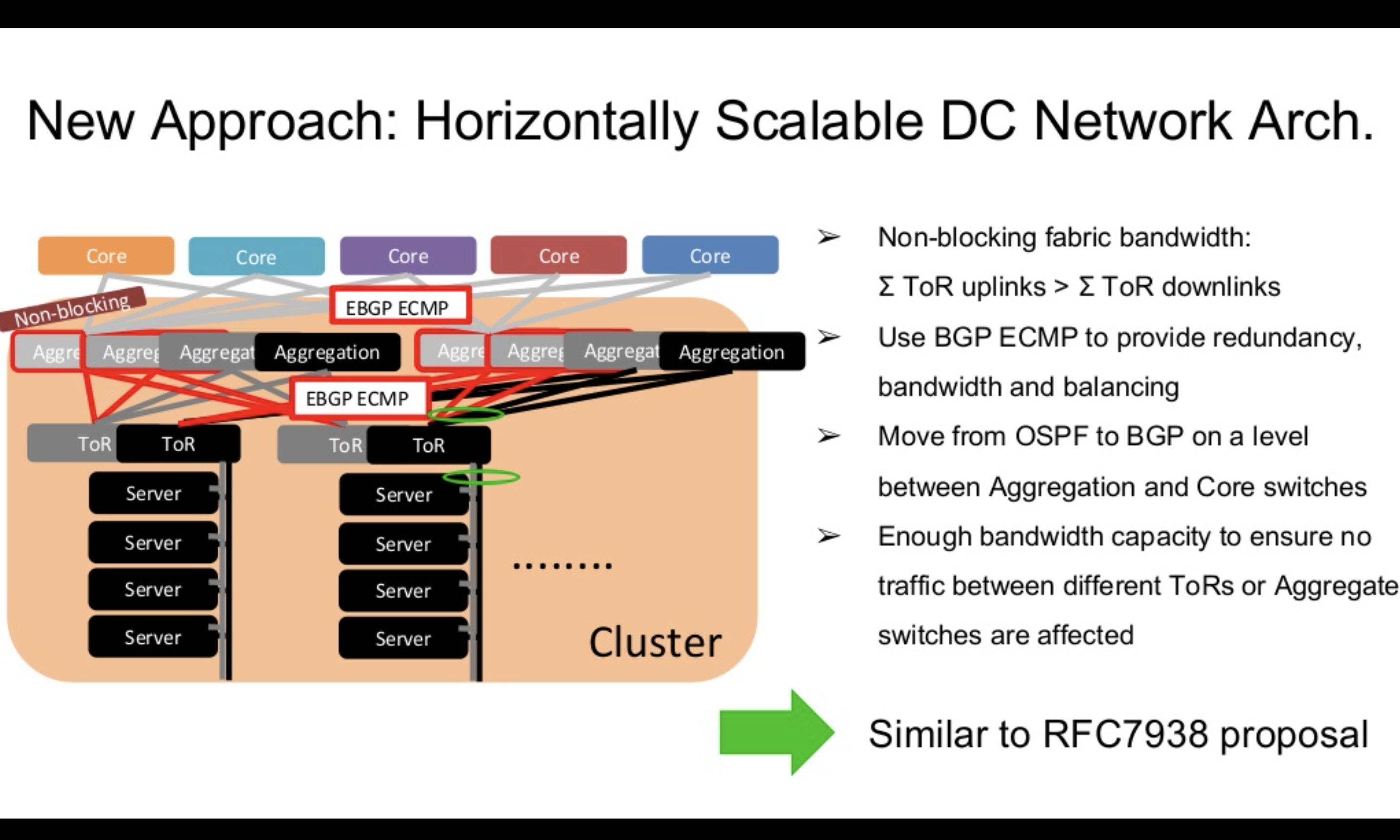
ToRのボトルネックはClos Networkにより解消されましたが、ToRでL2ネットワークの終端をするので、ToRごとにsubnetを管理する必要があります。また、ToRスイッチの計画メンテナンス時にパケットロスが避けられない問題、ラックをまたぐLive migrationができない問題など前述している帯域の問題以外の課題が残っていました。そのため我々の新しい環境ではClos Networkを導入するだけでなく、HypervisorとToR間でもEBGPを用いて、L3 RoutingドメインをHypervisorまで広げそれらの問題も解決することを試みています。

HypervisorまでL3 Routingドメインに含めると、従来のようなVLANとサブネットをラックごとに作成する運用が難しくなりました。 同じ手法を本環境でも用いようとするとHypervisorの数だけネットワークとサブネットを作成してあげる必要があり、Live Migrationが使えない、Hypervisorの数だけsubnetを管理しないといけないなどスケーラビリティを著しく欠きます。そのため、VM同士を接続する方法とVMとデータセンターネットワークを接続する方法を別途検討する必要があります。
考えうる方向性として、VXLANやGREなどのオーバレイ技術を導入する方法と、データセンターネットワークに/32でVMのIPを動的に広報し直接ルーティングで接続性を担保する方法があります。前者を採用した際に発生するカプセリングのオーバヘッドやネットワークデザインの複雑化を防ぐために今回は後者を採用し、オーバレイ技術を用いることなくルーティングのみでエンドツーエンドの接続性を担保しています。

L2 Isolate Plugin
ここまで、OpenStackの文脈は特に触れずデータセンタネットワークの設計の文脈で話を進めました。Hypervisor上に作成されるクラウドリソース(VM)をデータセンタネットワークに接続することは、OpenStack Neutronの責任範囲になります。そのためNeutronで「/32のルーティングでVM間通信を実現する」ようなケースをサポートしないといけません。しかし、既存のlinuxbridge agentやovs agentはこれらのユースケースをサポートしていません。
そのケースを実現するために、我々の環境では自社製のNeutron Plugin/Agent(L2 Isolate Plugin)を開発し運用しています。本PluginはML2のプラグインのドライバーとして実装されており、3つのパートで構成されています
- l2isolate mechanism driver (ML2 Plugin)
- routed type driver (ML2 Plugin)
- l2isolate agent
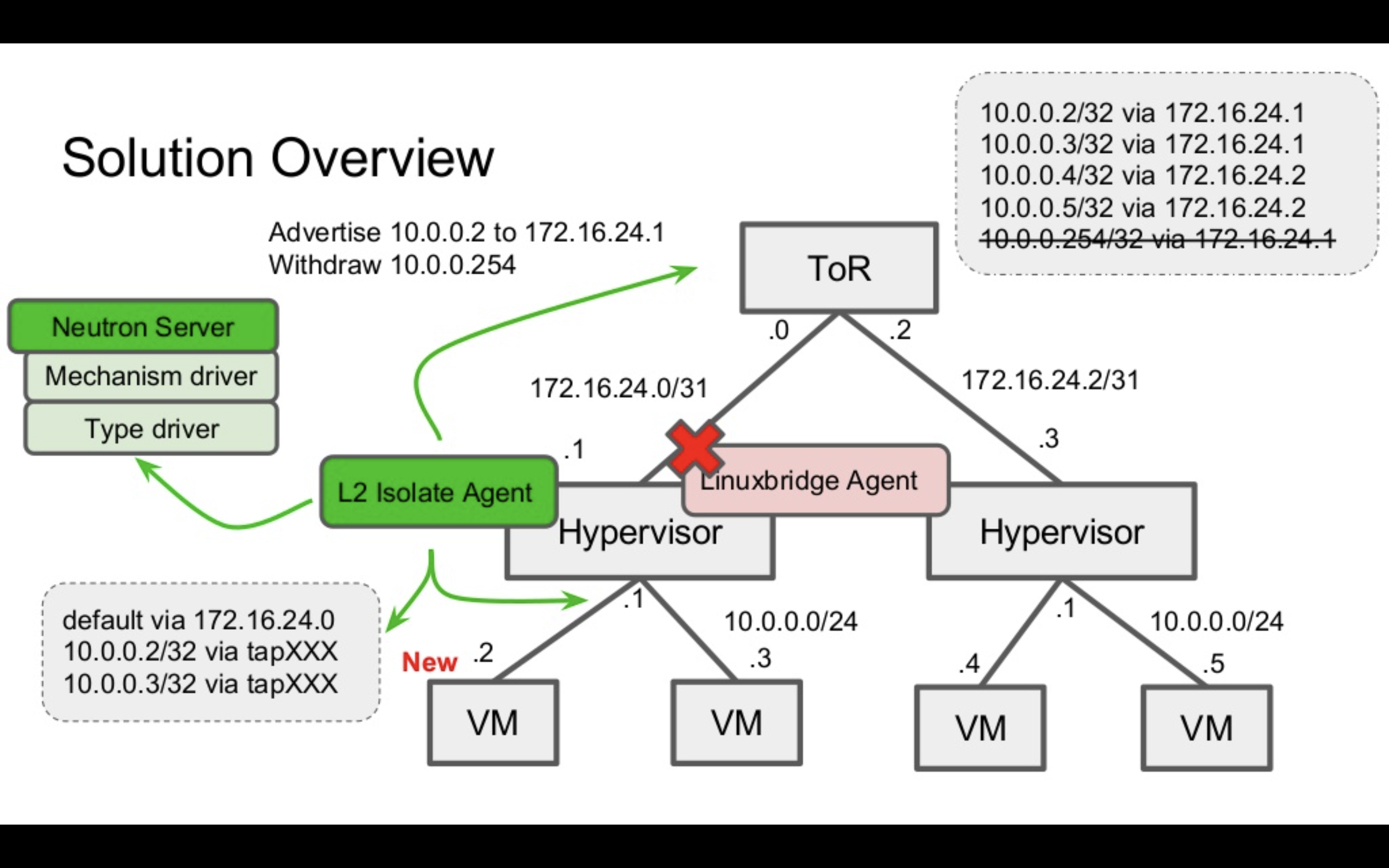
このL2 Isolate Pluginは単純にlinuxbridge agentの代わりにl2isolate agentを使えば動くわけではなく、OpenStackクラウドをどのようにデプロイするかについての変更も必要になります。
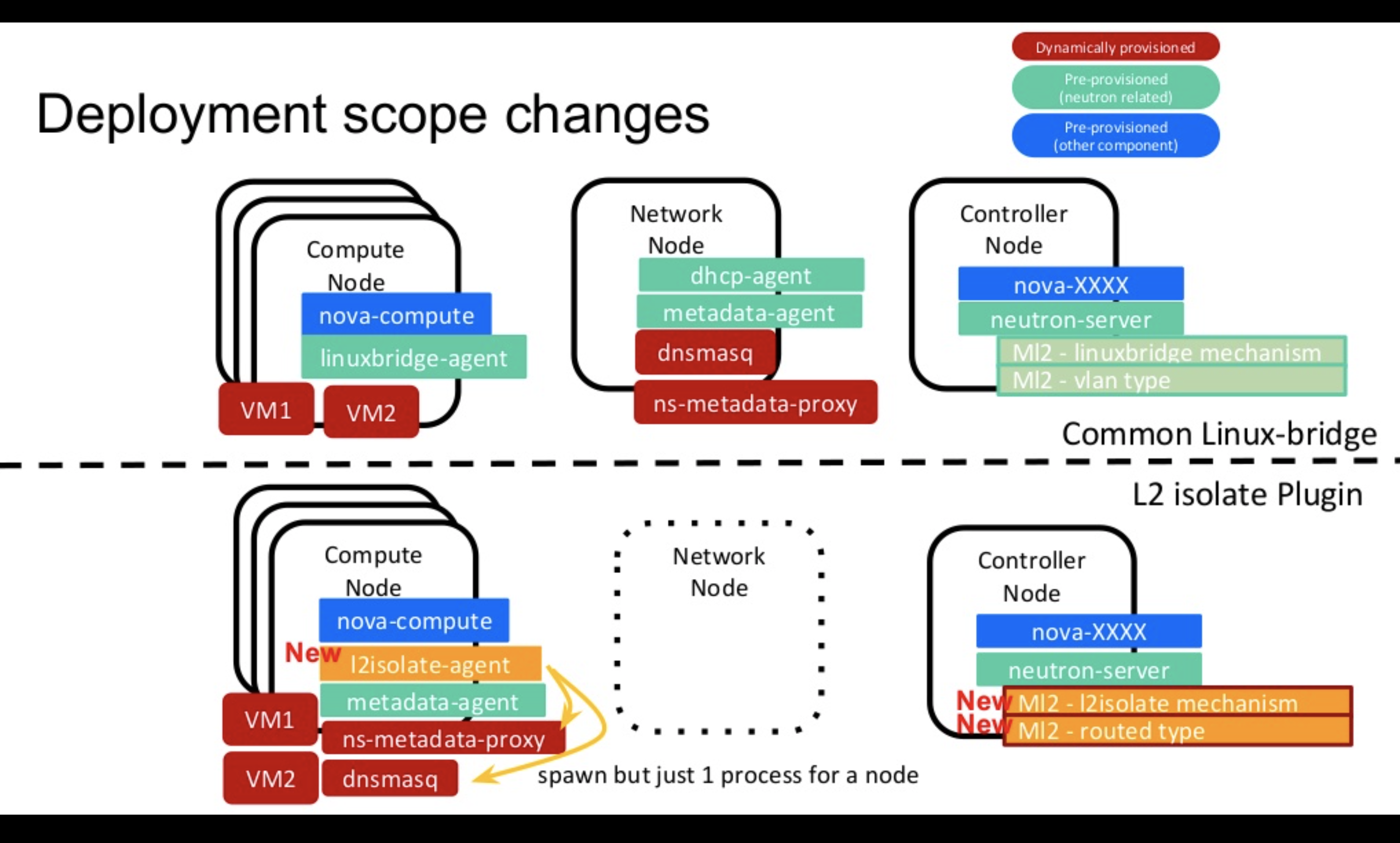
下記スライドで、上図が linuxbridge agentを用いたOpenStackのデプロイメントの例です。一方で下図がl2isolate agentを用いた例です。大きな変更箇所としては、l2isolate agentを用いた際は、ネットワークノードが必要なくなります。本環境ではコンピュートノードがL2ネットワークを終端するので、VMからL2到達性が必要なサービスは、各コンピュートノードで提供される必要があります。
そのためmetadata angetがネットワークノードからコンピュートノードに移動し、DHCPサービスが各コンピュートノードで動くl2isolate agentが設定するdnsmasqから提供されるようにデプロイメントの変更がなされています。
では、l2isolate agentは実際にどのようなコンフィグレーションをコンピュートノードで実施するのでしょうか、5つのパートに分けて解説させていただきます。
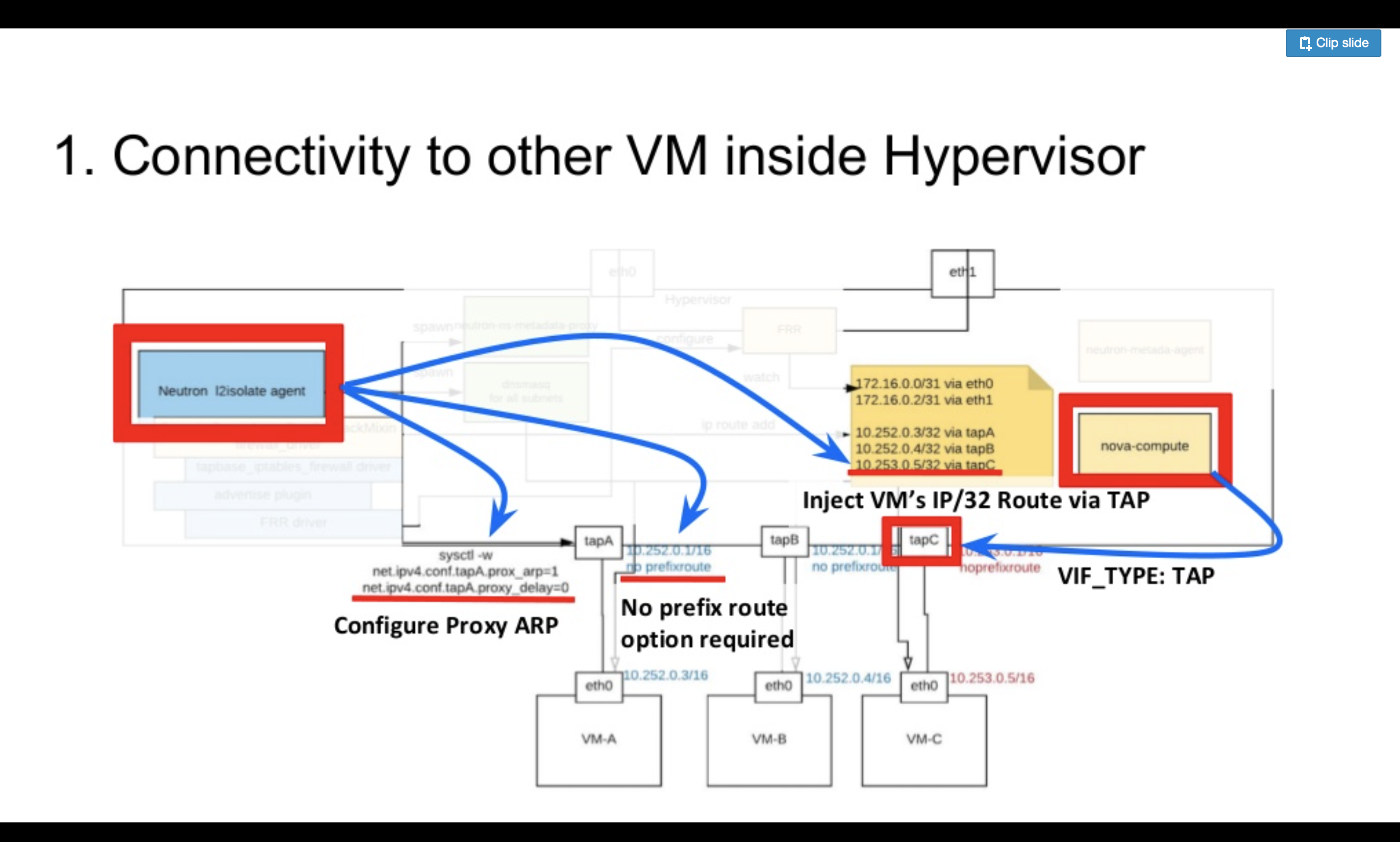
上記が、Hypervisor上のVM同士のL3の到達性を担保するための設定になります。
VM同士がL2の到達性を持たないようにVIF_TYPEにTAP(https://github.com/openstack/neutron-lib/blob/2b35c88495a2b500faad98880c3dc268f652cbf9/neutron_lib/api/definitions/portbindings.py#L91)を利用し、左側のAgentがProxy ARPを設定します。
すべてのVMには/32ではなく、同一の大きなプレフィック(スライドの例では10.252.0.0/16)からIPを払い出します。そのため、他のVMへパケットを送る際にL2の到達性があるとVM側に判断されるため、ARP解決に失敗してしまいます。このような条件下において、L3で隣接VMへ到達させてあげるためには、一度VMからHypervisorにIPパケットを送らせる必要があります。Proxy ARPを設定することで、対象VMのARPリクエストにHypervisorのMACアドレスを返答されるようになり、L3で到達性を持たせることが可能になります。
続いて、Gateway IPをno prefixrouteオプション付きでtapデバイスに設定します。これは、IPアドレスが設定されていないインタフェース上でのDHCPサービスをdnsmasqはサポートしない(https://github.com/imp/dnsmasq/blob/master/src/dhcp.c#L279-L285)、という制約に由来しています。また、前述した大きなプレフィックス(10.252.0.0/16)の経路がルーティングテーブルに追加されてしまうとHypervisorをまたぐVM間通信の到達性が失なわれるため、no prefixrouteオプションが必要になります。
最後に、VMのIPアドレス宛パケットをtapインタフェースに転送するような/32のstatic routeをルーティングテーブルに追加すると、同一Hypervisor上のVM間でL3フォワーティングによって到達性を保証するような環境が作られます。 実際にこれを試してみたい方は、namespaceやvethを使ってVMを模倣して試して見ることをオススメします。私たちも最初の検証は、namespaceとvethで同等の環境を作っていました。

では、VMとデータセンタネットワーク内のデバイスとの到達性はどのように保証されているのでしょうか。
我々の環境では、各コンピュートノードでルーティングソフトウェアをl2isolate agentとは別に起動しています。このルーティングソフトウェアがHypervisor上のルーティングテーブルを監視し、ルーティングテーブルの変更をトリガーにVMのIPアドレス(/32経路)をToRスイッチに広報しています。このようにしてHypervisorの外側からVMへのL3の到達性を保証しています。
またこの「VMのIPアドレスを外側に広報するロジック」の実装は、Pluggableになるようにデザインをしており、特定のルーティングソフトウェアに依存しないようにしています。そのためBIRD、FRRなど複数のルーティングソフトウェアと組み合わせることが可能になります。この背景には、RFC 5549など特定のルーティングソフトウェアではまだ実装されていない技術の利用が必要になることが想定されていたため、ルーティングソフトウェアの変更をなるべく柔軟にできるようにしたいという意図があります。
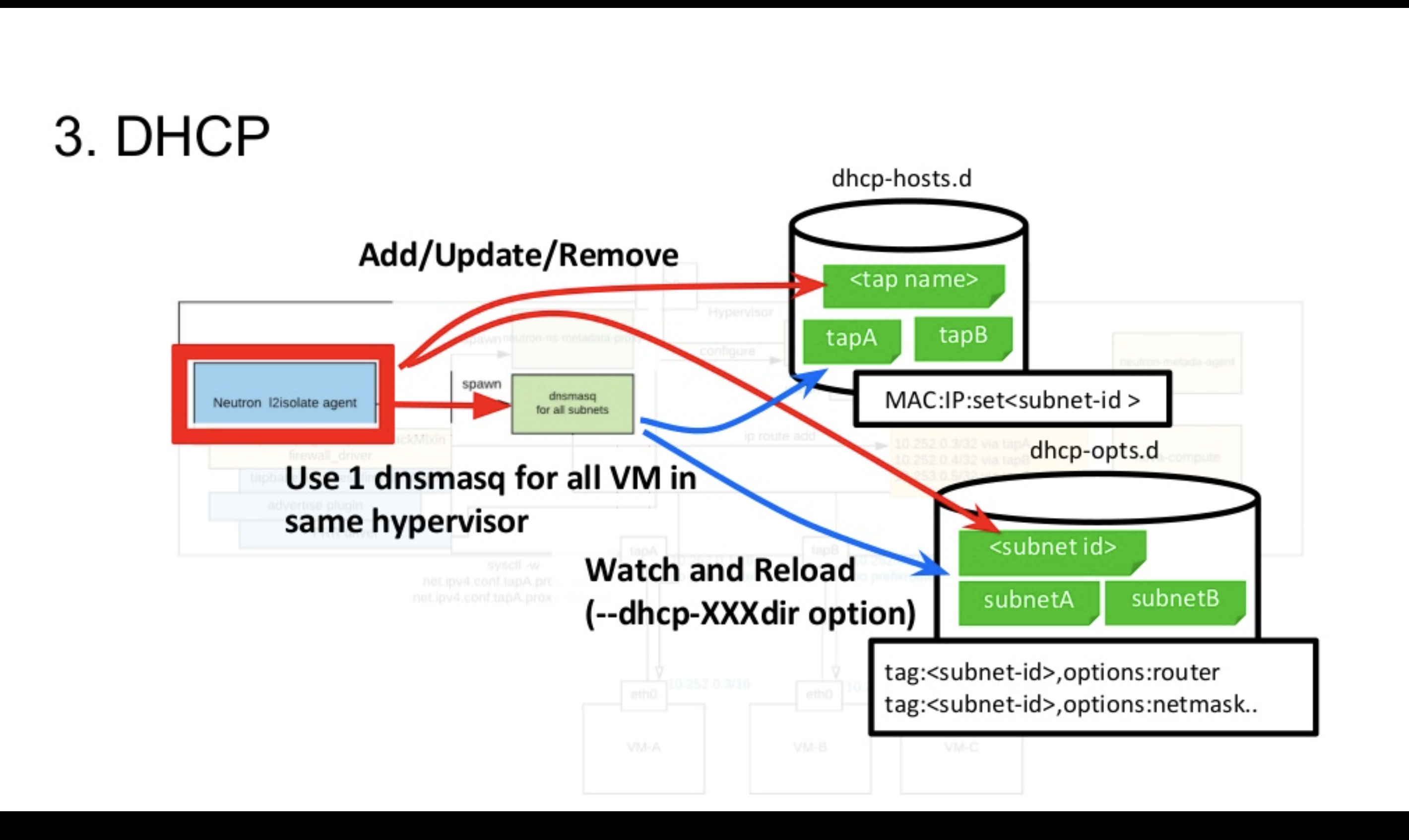
続いてDHCPサービスの実装です。先ほど少し触れたように、各コンピュートノードでL2ネットワークを終端するため各コンピュートノードでDHCPのサービスを提供する必要があります。
NeutronのデフォルトのDHCP Agentであるneutron-dhcp-agentでは1つのネットワークに対して1つdnsmasqを作成し、同一ネットワーク上のVMに対してDHCPサービスを提供します。一方で、l2isolate agentを利用する環境では、ネットワークの数に関係なく1つのdnsmasqが同じHypervisor上のすべてのVMにDHCPサービスを提供します。
また、本環境ではL2障害ドメインを気にしなくても良いため、大きいサブネット配下に大量のVMが作成されることが想定されます。そのためneutron-dhcp-agentが生成するような1つの設定ファイルにサブネット配下の全VMの設定を記述するような方式では設定ファイルが肥大化してしまいます。それを回避するために、l2isolate agentは、設定ファイルをNeutron上のエンティティと1対1で紐づけて該当コンピュートノードで必要なエンティティの設定のみをdnsmasqに読み込ませています。dnsmasqには、ディレクトリを指定すると追加変更を監視してくれるオプションが存在するためのそれを活用しております。
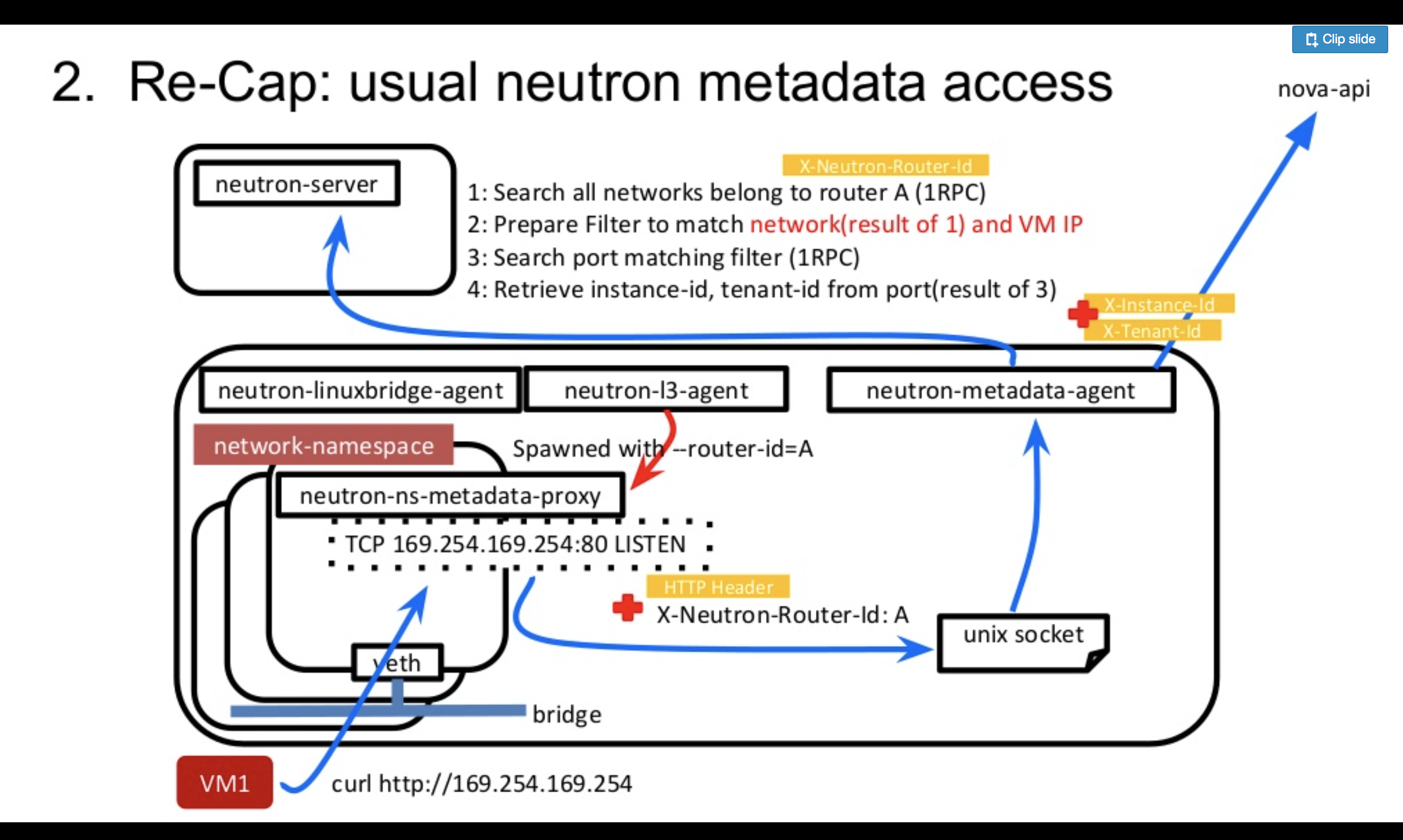
続いて、Metadata Serviceの実装に行きたいところですが、ここは少し奇妙なトリックを使っています。そのため実装の話に入る前に、一般的なOpenStack環境下でNeutronがMetadata APIをどのように中継しているのか少し振り返ります。
Metadata APIはNova APIの1種であり、nova-apiプロセスによって提供されます。NovaのMetadata APIを叩く際には、ヘッダにX-Instance-IDなどVM特有の情報を埋め込んでHTTP Requestを送る必要があります。しかし、VMから"curl http://169.254.169.254" とMetadata APIを叩く際にそれらを設定した記憶がない方は多いのではないでしょうか。それらの X-Instance-IDなどの付加情報は、実はAPIリクエストの過程でNova APIに到達する前に別のプロセスによって注入されているのです。
それを実施するのが、neutron-ns-metadata-proxyとneutron-metadata-agentの2つになります。
- neutron-ns-metadata-proxyは、neutron-dhcp-agentがネットワークごとに、またはneutron-l3-agentがルータごとに起動するプロセスでオペレーターが直接起動することはありません。また起動時に引数として、network idまたはrouter idを指定する必要があります。
- neutron-metadata-agentは、neutron-dhcp-agentやneutron-l3-agentが動くノードで一緒にオペレータによって起動される必要のあるプロセスになります。
Metadata APIがNova APIに中継されるまでの流れは、下記の通りです。(neutron-l3-agentを利用しているケースで話を進めます)
- neutron-ns-metadata-proxyがVMから直接 http://169.254.169.254 のAPIリクエストを受けて、リクエストを起動時のrouter idとVMのIPアドレスをヘッダに付与し、Unixソケット経由でneutron-metadata-agentに転送します。
(https://github.com/openstack/neutron/blob/805359d9a2b53db431c698e946ba62fe3b7213af/neutron/agent/metadata/driver.py#L127-L132) - neutron-metadata-agentは、router idから所属している全ネットワークのリストを取得します。
(https://github.com/openstack/neutron/blob/805359d9a2b53db431c698e946ba62fe3b7213af/neutron/agent/metadata/agent.py#L149) - 2の結果とVMのIPアドレスをもとに、VMのPortを検索します。(ネットワークも検索条件に入れることで、IPが被っていても特定できるようにしている)
(https://github.com/openstack/neutron/blob/805359d9a2b53db431c698e946ba62fe3b7213af/neutron/agent/metadata/agent.py#L154) - 検索結果のPortのdevice ownerからVMのInstance IDを取得します。
(https://github.com/openstack/neutron/blob/805359d9a2b53db431c698e946ba62fe3b7213af/neutron/agent/metadata/agent.py#L169) - neutron-ns-metadata-proxyから転送されてきたユーザリクエストのヘッダにInstance IDなどを設定し、Nova Metadata APIにアクセスします。
(https://github.com/openstack/neutron/blob/805359d9a2b53db431c698e946ba62fe3b7213af/neutron/agent/metadata/agent.py#L90)
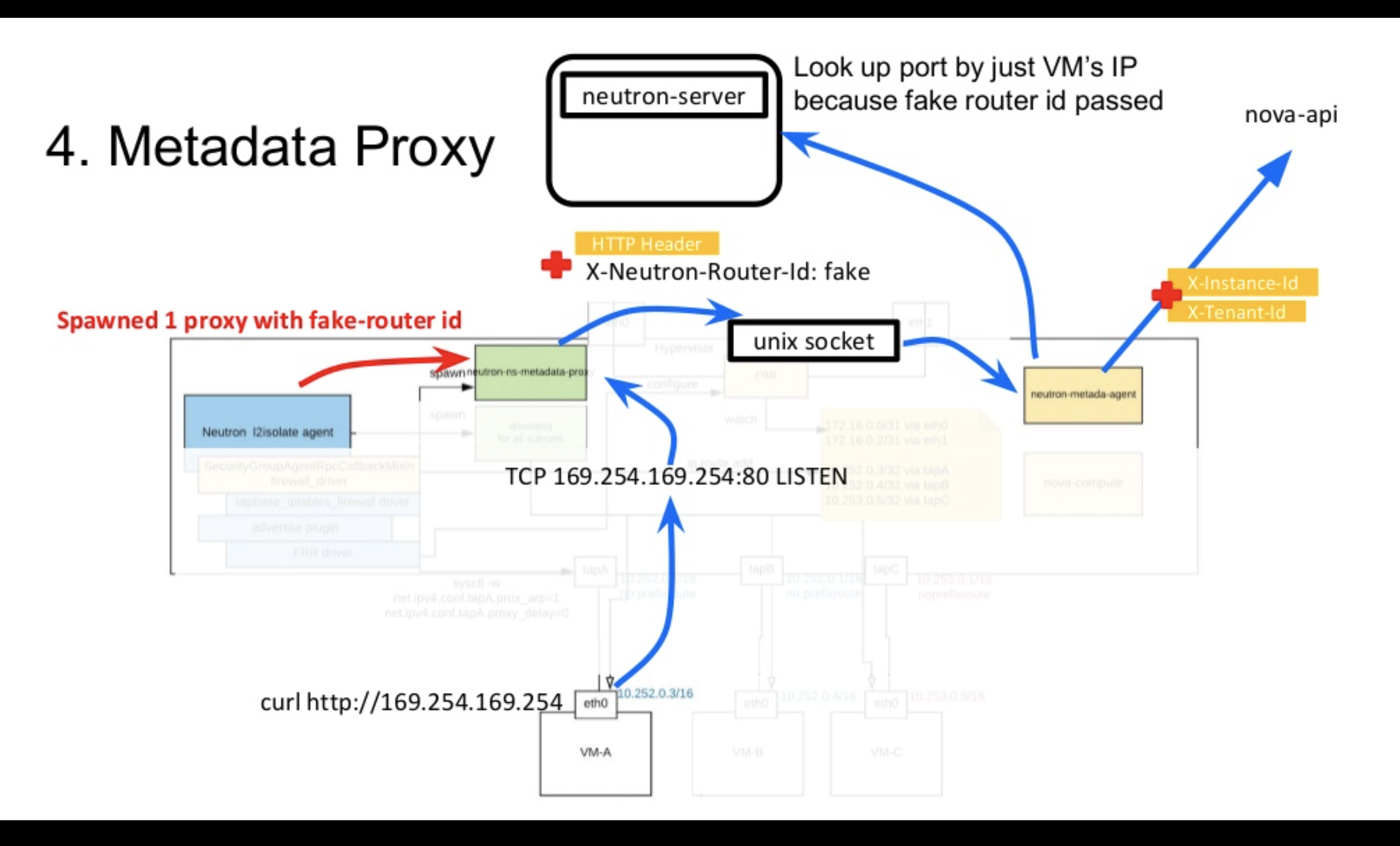
通常のMetadata APIの中継がどのように実施されるかをみていきましたが、neutron-dhcp-agentもneutron-l3-agentも利用していない l2isolate agentの環境ではどのように実現しているのでしょうか。
同じくneutron-ns-metadata-proxyをl2isolate agentが起動していますが、1つのneutron-ns-metadata-proxyで同じHypervisor上の全VMにproxyサービスを提供しています。これはネットワーク、サブネットが異なるVMが同じHypervisor上に存在していてもです。
通常は、各ネットワークごとに作成されるneutron-ns-metadata-proxyをどのようにして、1つのプロセスで全VMをサポートしているのでしょうか。l2isolate agentは、Fakeなrouter idをパラメーターに渡し、 neutron-ns-metadata-proxyを起動します。Fakeなrouter idを渡すと、neutron-metadata-agentでPortを検索する際に、router idからネットワーク情報が取得できないためVMのIPのみでPort検索が実施され( https://github.com/openstack/neutron/blob/805359d9a2b53db431c698e946ba62fe3b7213af/neutron/agent/metadata/agent.py#L124 )、Instance idが取得可能になります。そのためIPの重複は許容できないソリューションではありますが、1つのneutron-ns-metadata-proxyで Metadata ServiceをVMに提供することが可能になります。コード量を減らすために既存の物を使い回したかったのでこのようにしています。

最後にセキュリティグループの実装になります、セキュリティグループは各AgentのFirewall Driverが実際のコンフィギューレション部分を定義しています(https://github.com/openstack/neutron/blob/master/neutron/agent/linux/iptables_firewall.py)。
しかし、NeutronのデフォルトのIpTablesFirewallDriverは、tapデバイスがbridgeに接続されていることが前提になっているため、bridgeを全く使わないl2isolate agentでは利用できませんでした。そのため、https://github.com/openstack/neutron/blob/master/neutron/agent/linux/iptables_firewall.py#L301 のようなトラフィックがVMに関係あるかどうかの判別のロジックを単純にin/outのインターフェースを見るだけにするような変更を加えたtapベースのFirewall Driverを書き実際に動かしています。
このような形でl2isolate agentを含むL2 Isolate PluginはNeutronと協調して動き、VM間、VMとデータセンタネットワークでL3の到達性を保証しています。 このカスタムPluginをテストを含めおよそ2ヶ月という期間で開発をし、プロダクションですでに使い始めています。
2ヶ月という期間に少し驚かれる方もいらっしゃるかもしれませんが、Neutronには、linuxbridge agentで実際に使われているAgent共通の処理を定義したフレームワークのようなものが存在し、弊社もそれをベースにカスタムAgentを作成しています。また他にもたくさんの使い回し可能なRPCやNeutronの内部的なライブラリが存在するため、Neutronの理解のコストは多少ありますが実装のコストはさほど大きくありませんでした。また、Neutronの動作をコードレベルで理解することは、今後起こりうるスケーラビリティの問題やバグのトラブルシューティングにも役立つため本取り組みから得た貴重な副産物です。
本取り組みで達成できたこと
ここまでL2 Isolate Pluginの実装について簡単にご紹介させていただきました。今回ご紹介した新しいネットワークアーキテクチャと弊社で開発したL2 Isolate Pluginは、全ての問題を解決する銀の弾丸ではありません。メリットもありますが、取り組み開始以前から認識していたデメリットもあります。しかし、弊社ではデメリットが顕著にならないような運用体制や仕組みの検討し、本番環境でこのアーキテクチャを採用しております。
ネットワーク管理者観点
良い点
-
ToRスイッチをまたぐようなVM間通信の平均的なスループットの向上
=> ToRのuplink帯域の改善
=> オーバレイネットワークを利用しない(L2 Isolate Plugin) -
ベンダーフリーなシンプルなデータセンタネットワークデザイン
=> L2ネットワークの冗長化技術を一切データセンタ内で利用しない
=> 全ての冗長化がBGPにより実装されている -
ToRスイッチのゼロダウンタイム計画メンテナンス
=> BGPによる柔軟なトラフィックエンジニアリング
悪い点
- スケールの大きいBGPネットワークを運用する必要がある
クラウド管理者観点
良い点
- ラックを跨ぐようなLive Migrationが可能に
- VM間通信の要件に応じたVMのスケジューリングが不要
=> ToRのボトルネックが解消されたため
悪い点
- カスタムのPluginを今後ともメンテナンスしていく必要がある
最後に
本記事では、OpenStack Summit Vancouverで我々が発表した「Excitingly simple multi-path OpenStack networking: LAG-less, L2-less, yet fully redundant」についてご紹介しました。
OpenStack Summitにおける弊社の発表は今回が初めてでしたが、我々のPrivate Cloudをさらに良いものにしていこうと様々な新しい検討が現在社内で行われてます。本PluginのOSS化、ネットワーク分離を目的としたオーバレイネットワークの導入、ベアメタル環境へ同じネットワークアーキテクチャを透過的に適用する手段の検討など改善すべき点はまだまだたくさんあります。これらの今後の取り組みについても、今後、カンファレンスやコミュニティへ定期的に公開していきたいと思っています。
少し長くなってしまいましたが、最後まで読んでいただきありがとうございました。