
はじめに
こんにちは、2020年4月に新卒としてLINE株式会社に入社した二又 航介です。テキスト音声合成システムの研究開発を担当するAI開発室 Voiceチームに所属し、音声合成システムにおけるテキスト処理部の研究開発やチームの機械学習基盤構築に取り組んでいます。
学生時代は機械翻訳や同時通訳に関連する研究に取り組んでいました。研究以外の活動としては、アルバイト・インターンでの対話システムや機械翻訳システムの研究開発、個人活動としてwebアプリケーション開発などを行っていました。このような活動を通じて、数多くのユーザーに利用される自然言語処理技術を活かしたサービスに携わりたいという思いからLINEを志望しました。学生時代は専ら自然言語処理に関連する研究に取り組んでいましたが、音声合成に興味を持ち始め、かつ音声合成システムの研究開発において自然言語処理の知見が活きるタスクが多くあるため、これらに取り組む形でVoiceチームに配属しました。
全体研修や集中開発研修を経て、去年8月にAI開発室 Voiceチームに配属となりました。エンジニアとして入社した同期が、配属部門での開発業務についての紹介記事を同ブログに投稿する中、研究開発業務に関する記事は上がっていなかったので、LINEの研究開発業務における雰囲気を掴んで頂きたくこの記事を執筆しました。この記事では、自然言語処理エンジニアとして入社し、AI 開発室 Voiceチームで過去半年間取り組んだ業務内容について紹介します。
AI開発室 Voiceチームについて
LINEのAI開発室は担当するドメイン毎に3つのチームに分かれており、音声認識を担当するSpeechチーム、自然言語処理を担当するNLP開発チーム、音声合成を担当するVoiceチームがあります。それぞれのチームは各分野に関連する研究開発業務を行っています。
Voiceチームは6人のチームで、テキスト音声合成システムを構成する言語処理部、音響モデル、ボコーダーのいずれかの研究開発を各自担当しています。かの有名なParallel waveGAN [1]の著者である山本龍一 (@r9y9)さんも所属しています。Parallel WaveGANの詳細についてはLINE Developer Day 2020の発表動画が公開されていますので是非ご参照ください。
働く環境について
Voiceチームではメンバーの大半が京都オフィス勤務であるため、東京勤務は私含め現在2人しかいません。コロナの影響もありますが、このような物理的な距離の問題を踏まえ、Voiceチームでは業務上必要なコミュニケーションは基本的にSlackを主としたオンラインで行っています。VoiceチームではSlackのtimes文化が根付いており、些細なことでもtimesチャンネルに投げれば有識者に回答して頂けるので円滑に業務を進めることができます。また、それ以外にも以下のような多くのコミュニケーション機会があります。
- 所属チームでの進捗共有会 (週1回)
- チームのオンラインお茶会(週1回)
- マネージャーとの1on1 (隔週)
- AI開発室での技術共有勉強会 (隔週)
- Voiceチームの技術共有会 (月1回)
私は学生時代専ら自然言語処理に関連する研究を行っており音声合成については素人だったので、チーム内やAI開発室の技術共有会によって音声合成や音声認識など、自身の強みとなるドメイン以外の知見を得ることができ、かつ各ドメインの有識者と議論ができるので非常に有意義だと感じています。研究という業務の性質上、基本的に1人でもくもくと論文を読んで実験を繰り返し、週1回の進捗共有回で議論するという形で進めていますが、学生時代は自宅でもくもくと研究を進めているタイプだったので、学生の頃と同じような生活を送ることができています。
研究環境について
LINEでは研究開発を円滑に進めるため、社内プライベートクラウドであるVerdaとGPUクラウドとしてNSMLという独自のインフラ基盤が構築されています。これらインフラ基盤を用いることでスムーズに研究活動に取り組むことができます。
各クラウド基盤は自由に使うことができるため、実験で使用するデータ管理や実験結果のロギングを行うサーバーを好きなように構築しています。また、NSMLでは、1人につきNVIDIAのV100 32GBが16台まで使用可能になっています。このような潤沢な研究リソースを自由に利用できため、円滑に研究活動を進めることができます。
音声合成システムにおける句境界予測モデルの導入
研修を終え配属後、はじめに取り組んだ「テキスト音声合成システムにおける句境界予測モデル」の研究開発について紹介します。音声合成システムの言語処理部において句境界の挿入位置を予測することで、実際に生成される合成音声の品質を向上させるといった内容です。
テキスト音声合成とは?
はじめに、そもそもテキスト音声合成システムとはどのような技術であるか説明します。テキスト音声合成システムとは、テキストから人工的な音声を作り出す技術です。入力として与えられるテキストからテキストの内容を反映した人工的な音声発話を出力します。AppleのSiri、AmazonのAlexaなどに代表される活用される技術で、弊社から発売されるAIアシスタント、LINE CLOVAにも活用される技術です。
例えば、「今日もめっちゃいい天気ですね」という文章をテキスト音声合成システムへ入力すると、以下のような人工的に作られた音声へと変換されます。
3. 句境界が適切に挿入された音声
「ホッキョクグマは、<BR> クマ科 <BR>クマ族に分類される <BR> 食肉類です。」
3つの音声を聴き比べてどの音声が聞き取りやすかったでしょうか? おそらく多くの人にとって3つ目の句境界が適切に挿入された音声が聞き取りやすかったと思います。句境界が一切挿入されない1つ目の音声やルールベースで句境界を挿入した2つ目の音声では、息継ぎによる音声的なポーズが挿入されていないため、早口の印象を受け、必ずしも聞き取りやすい音声であると言えません。一方で3つ音声では、適宜句境界が挿入され、ゆっくりとした発話になっているため多くの人にとって聞き取りやすい音声であったと思います。
上記の例に示すように句境界予測は、音素系列への変換やアクセント予測と同様に合成音声の品質を向上させるために重要な要因の一つですが、voiceチームでは句境界予測モジュールが開発されていませんでした。このような句境界が適切に挿入された音声を生成するために、句境界の挿入位置を適切に予測するモデルの研究開発を行いました。
学習データの準備
上述したタスクを解決するモデルを開発するにあたって、学習に用いるデータセットを準備する必要があります。今回実現したい機能としては、「ホッキョクグマは、クマ科クマ族に分類される肉食類です。」というテキストに対して、「ホッキョクグマは、<BR> クマ科 <BR> クマ族に分類される <BR> 食肉類です。」といったように句境界(<BR>)が挿入されるべき位置を予測することです。
したがって、各形態素ごとに「形態素の後に句境界が挿入されるべきか否か」を予測する系列ラベリングの問題として解決できます。つまり、以下に示すように各形態素に対して非句境界(Non-break: <NB>)、句境界(Break: <BR>)を付与するタスクとして捉えることができます。
ホッキョク <NB>グマ <NB>は <NB>、<BR>クマ <NB>科 <BR>クマ <NB>族 <NB>に <NB>分類 <NB>さ <NB>れる <BR>食肉 <NB>類 <NB>です <NB>。<NB> |
データセットとしては、社内で収録したプロの声優の音声発話と書き起こし文がペアになったデータセットを使用しました。このデータセットは約120時間の音声発話および対応する書き起こし文約10万文から構成されます。このデータセットの音声発話において、200ms以上の無音区間が現れる箇所を句境界として認定して句境界予測モデル構築用のデータセットを作成しました。
どのようなモデルでやるか?
データセットの準備ができたところで、句境界予測を行うモデルを構築していきます。初めにベースラインモデルとして、英語を対象とした句境界予測の既存手法を2種類採用しました。
まず1つ目のベースラインモデルは、モデルは2層のBiLSTMと1層の全結合層から構成される比較的単純なものです。このモデルでは、入力としてテキストを形態素として分割したトークン系列のみを使用します [2]。次に2つ目のベースラインモデルは、1つ目のモデルと構造は同じですが、入力としてテキストのトークン系列だけではなく、品詞タグや依存構文情報を利用したものです [3]。また入力テキストの単語埋め込み層には事前学習済みのものを利用するため、日本語Wikipediaを用いて事前学習を行いました。
句境界予測モデルで用いるデータは、先程説明したように生テキストと句境界のペアからなるラベル付きのデータを人手で作成する必要があり、大規模コーパスを整備するには多大なコストがかかります。そこで、既存研究では事前学習済みの単語表現や文表現を活用することにより予測精度を向上させてきました [3,4]。しかし単語表現と文表現は独立して活用されており、両者を考慮した潜在表現は活用されてきませんでした。そこで上記既存研究の手法に加えて、多くのNLP分野で成功を収めている大規模言語モデルの一つであるBidirectional encoder representation from Transformers(BERT) [5]も実験対象に加えました。BERTの学習済みモデルはhuggingfaceの東北大学の乾・鈴木研究室が提供するcl-tohoku/bert-baseを利用します。
また、単にBERTのみを用いて句境界予測を行うのではなく、BERTと従来手法ベースラインモデルを組み合わせた手法を提案しました。以下にBERTと2つ目のベースラインモデルを組み合わせた提案手法の概略図を示します。
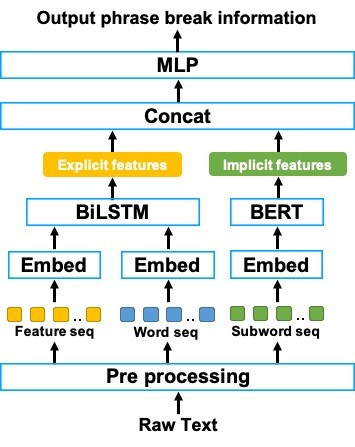
上図の提案手法では、品詞タグや依存構文情報などの明示的な言語特徴量と句境界の関係をBiLSTMによってモデル化するだけではなく、事前学習済みのBERTによる暗黙的な言語特徴量と句境界の関係を同時にモデル化しています。このようにBiLSTMだけではなくBERTを活用することで、BiLSTM単体では捉えることのできなかった意味情報や構文情報を暗黙的に活用できるようになり、かつBiLSTMに入力する様々な言語特徴量から得られる明示的な特徴量を活用できるため、限られたデータにおいても精度の高い句境界予測が可能になることを期待します。
まとめると以下の5パターンのモデルで実験を行います。
| System | Model | 詳細 |
|---|---|---|
| 1 | BiLSTM (Tokens) | テキストのトークン系列のみを入力とした2層BiLSTMモデル |
| 2 | BiLSTM (Features) | テキストのトークン系列および品詞タグ、依存構文情報を入力とし、かつ事前学習済みの単語埋め込み層を用いた2層BiLSTMモデル |
| 3 | BERT | テキストのトークン系列のみを入力とした、事前学習済みBERT |
| 4 | BiLSTM (Tokens) + BERT | BiLSTM (Tokens)とBERTを組み合わせたモデル |
| 5 | BiLSTM (Features) + BERT | BiLSTM (Features)とBERTを組合わせたモデル (提案手法) |
実験結果と考察
提案手法の有用性を評価するため、F1スコアに基づく客観評価実験を行いました。上記5つのモデルに対する実験結果を以下の表に示します。
| System | Model | F1 | Precision | Recall |
|---|---|---|---|---|
| 1 | BiLSTM (Tokens) | 88.7 | 92.5 | 85.1 |
| 2 | BiLSTM (Features) | 90.2 | 92.3 | 85.1 |
| 3 | BERT | 92.1 | 94.6 | 89.7 |
| 4 | BiLSTM (Tokens) + BERT | 92.1 | 94.3 | 90.0 |
| 5 | BiLSTM (Features) + BERT | 93.4 | 94.3 | 92.4 |
上記の実験結果に示すように、提案手法であるBiLSTM (Features) + BERTは、従来手法であるBiLSTM (Tokens)やBiLSMT (Features)と比較して、句境界予測に対するF1スコアがそれぞれ4.7ポイント、3.2ポイント向上しました。また、BERT と BiLSTM (Tokens) + BERTの間にはF1スコアに差が見られないものの、BiLSTM (Toekns) + BERT と提案手法であるBiLSTM (Features) + BERTを比較するとF1スコアに関して1.3ポイント向上しました。したがって、BiLSTMのよる品詞タグや構文情報といった明示的な特徴量が句境界予測において有効に活用されていると考えられます。
また、主観評価実験により実際の音声の韻律に関する自然性が向上するかどうか評価を行いました。実験では、句境界情報を含む言語特徴量から音声を生成するため、Fastspeech2 [6]をベースとした音素列および句境界情報から音響特徴量を予測する音響モデル、音響特徴量から音声波形を生成するParallel WaveGANを用いたボコーダーの2つを訓練しました。評価対象としては、客観評価実験で用いた4番目のBiLSTM (Tokens) + BERTを除く4手法に加えて、Reference(Natural): テストデータに含まれる自然音声、Reference (TTS): テストデータを音声合成した発話、Rule-based: 読点の後にのみ句境界を挿入したルールベースの手法の合計7手法とし、各手法30発話の合計210発話を対象としました。
実験方法としては聴取実験による平均オピニオン評点(MOS)テストを用いて、音声の韻律に関する自然性について29人の成人日本人母語話者が評価を行いました。被験者はランダムに提示される音声サンプルを聴取し、韻律の自然性に関して 5 段階 (1: 非常に悪い、2: 悪い、3: 普通、4: 良い、5: 非常に良い) で評価を行います。
以下の表に各モデルによる音声とそれらに対応する95%信頼区間を示します。
| System | Model | MOS |
|---|---|---|
| 1 | Reference (Natural) | 4.70 ± 0.05 |
| 2 | Reference (TTS) | 4.37 ± 0.05 |
| 3 | Rule-based | 3.62 ± 0.07 |
| 4 | BiLSTM (Tokens) | 3.80 ± 0.07 |
| 5 | BiLSTM (Features) | 4.05 ± 0.06 |
| 6 | BERT | 4.26 ± 0.05 |
| 7 | BiLSTM (Features) + BERT | 4.39 ± 0.05 |
上記表に示すように、提案手法であるBiLSTM (Features) + BERTは、テストデータを音声合成した発話であるReference (TTS)と韻律に関して同程度の品質を達成しています。また、従来手法であるBiLSTM (Tokens)やBiLSTM (Features)と比較すると、それぞれMOS評価値が0.59ポイント、0.34ポイント上昇しており、従来手法より韻律の自然性が向上することが分かりました。
最後に、主観評価実験に使用した音声のサンプルをいくつか記載します。提案手法では、既存手法と比較してポーズが適切に挿入され、音声の韻律に関する自然性が向上して いることが分かると思います。
Sample 1
1. Referemce (Natural)
2. Reference (TTS)
3. Rule-based
4. BiLSTM (Tokens)
5. BiLSTM (Features)
6. BERT
7. BiLSTM (Features) + BERT (提案手法)
Sample 2
1. Referemce (Natural)
2. Reference (TTS)
3. Rule-based
4. BiLSTM (Tokens)
5. BiLSTM (Features)
6. BERT
7. BiLSTM (Features) + BERT (提案手法)
その他の業務について
上記の研究開発に加えて、以下のような業務を並列して進めていました。研究開発という業務内容の性質上、開発を主としたチームと比較して、個人で進めるタスクの割合がかなり高いです。
- 研究開発を円滑に進めるための実験基盤の構築
- 研究成果を反映した音声合成システムのプロトタイプ開発
- テキスト合成音声に関する知見を得るための学会参加
学会や勉強会には申請さえ出せば各自自由に参加できるため、入社後INTERSPEECH2020や言語処理学会第26回年次大会 (NLP2020)、NLP若手の会 (YANS)に参加しています。
おわりに
本記事では、弊社のAI開発室 Voiceチームおよび新卒自然言語処理エンジニアとして過去に取り組んだ業務内容について紹介しました。本記事で紹介しました研究結果はNLP2021やINTERSPEECH2021に投稿しています。今回紹介しきれなかった、提案手法の詳細や追加実験の詳細についてはINTERSPEECH2021へ投稿済みの以下論文を参照して頂けますと幸いです。
- Phrase break prediction with bidirectional encoder representations in Japanese text-to-speech synthesis (arXiv)
LINEには豊富なデータだけではなく、優秀な研究者、エンジニアが多数在籍しているため、働く環境としても学ぶ環境としても非常に良いと感じています。LINEでは以下の各職種にて音声・音響・信号処理・自然言語処理の研究者を積極的に採用しています。興味がある方は応募をご検討下さい!
また、Voiceチームでは自然言語処理エンジニア、音声合成エンジニアの新卒採用も積極的に行っています。興味のある学生の方は、Voiceチームに所属するPark Byeongseonさんのインタビュー記事をご参照下さい。この記事を読んで、皆さんが少しでもLINEの自然言語処理エンジニア/音声処理エンジニアとしての仕事に興味を持っていただけますと幸いです。
参考文献
- [1]: R. Yamamoto, E. Song, and J.-M. Kim, “Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram,” in Proceedings of ICASSP
- [2]: A. Vadapalli and S. V. Gangashetty, “An investigation of recurrent neural network architectures using word embeddings for phrase break prediction", in Proceedings of INTERSPEECH 2016
- [3]: V. Klimkov, A. Nadolski, A. Moinet, B. Putrycz, R. BarraChicote, T. Merritt, and T. Drugman, “Phrase break prediction for long-form reading tts: Exploiting text structure information", in Proceedings of INTERSPEECH 2017
- [4]: Y.Zheng,J.Tao,Z.Wen,andY.Li,“Blstm-crfbasedend-to-end prosodic boundary prediction with context sensitive embeddings in a text-to-speech front-end,” in Proceedings of INTERSPEECH 2018
- [5]: J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre- training of deep bidirectional transformers for language under- standing,” in Proceedings of NAACL-HLT 2019
- [6]: R. Yi, H. Chenxu, Q. Tao, Z. Sheng, Z. Zhou, and L. Tie-Yan, “FastSpeech 2: Fast and high-quality end-to-end text-to-speech,” in Proceedings of ICLR