カラフルな四角いオブジェクトは、テーブルに対してどのようにアクセスするかを示しています。 青からコストが低く、赤がコストが高いことを示しています。 下2つの赤い index と ALL はインデックスを考えるなどしてチューニングしようとよく言われてるやつですね。
色
オブジェクト中のテキスト
EXPLAINにおけるtype
Single row: constant
const
Unique Key Lookup
eq_ref
Non-Unique Key Lookup
ref
Fulltext Index Search
fulltext
Index Range Scan
range
Full Index Scan
index
Full Table Scan
ALL
Lookup: where col = 1 のような等価比較
VISUAL EXPLAIN でインデックスの挙動を確かめる(本題)
本題です。青→赤の順にコストが大きいことだけ分かっていれば、詳細に見方を覚えなくても使えます。
今回使うのは下の2つのテーブルです。どのユーザがコンバージョンしたかを持っておく cv テーブルと、それが紐付く広告の ad テーブルです。 今回実験のためにざっくり作成したデータについて下に列挙します。
インデックスは簡単のためこの時点で PRIMARY KEY のみ
cv は約100万件、 ad は約4000件
cv の status と ad の type はそれぞれ10種類で偏りなし
時刻を保存するカラムは UNIX TIME でここ一ヶ月のデータを格納
ER 図はせっかくなので MySQL Workbench で出力しました。 Workbench は外部キーを貼っておけば自動的にリレーションが図に描かれますが(公式、今回は説明を簡単にする為に PRIMARY KEY のみにしたので下図のようになっています。
インデックスなし(簡単に VISUAL EXPLAIN の見方)
SELECT * FROM cv WHERE status = 2 ORDER BY created_at LIMIT 100;
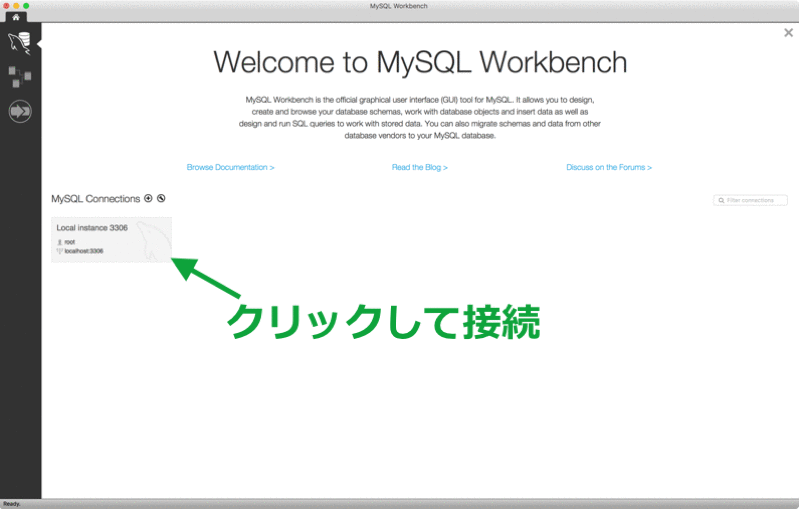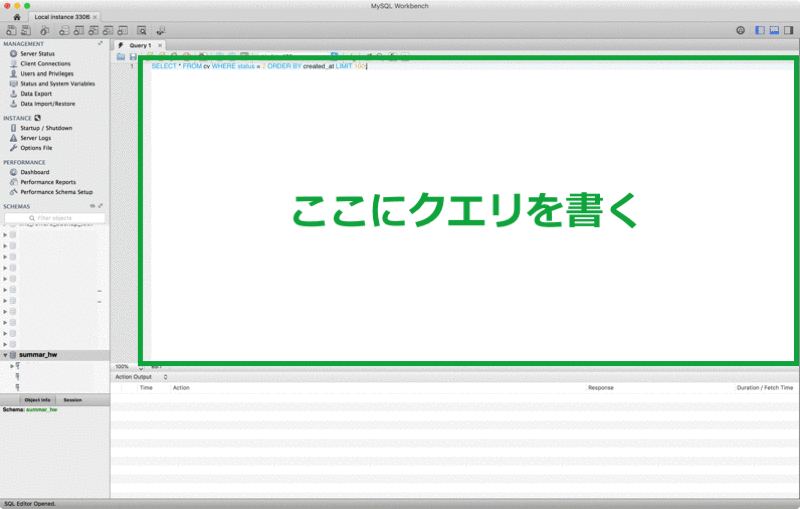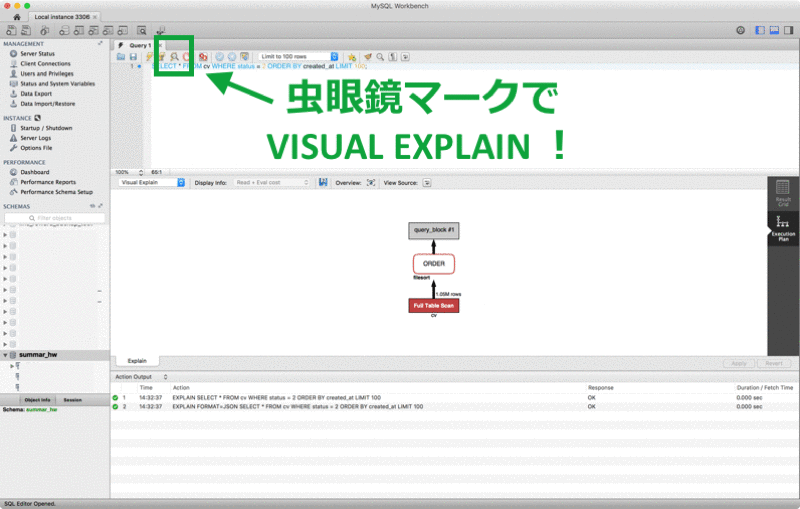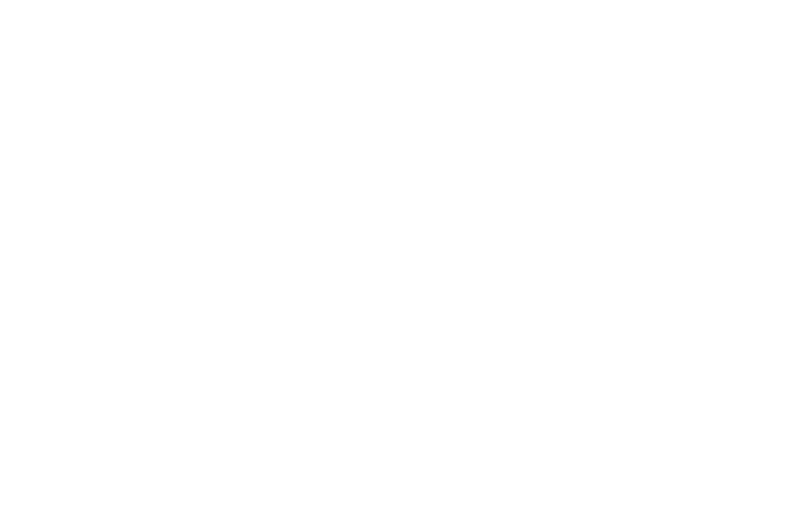
このクエリに対して VISUAL EXPLAIN を実行すると以下の画像が出ます。
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
矢印の通り読み、 cv テーブルの全テーブルをスキャンして得る100万行を ORDER BY でソートして結果を得ていることが分かります。 真っ赤ですね。100万行もスキャンして WHERE の条件にマッチする行を探して、全体をソートして100件を返しているので重い処理になっています。 インデックスを貼る必要があります。
WHERE の条件にインデックス
上記 SQL の為にインデックスを追加していきます。 まずは WHERE の条件である status にインデックスを貼ります。 インデックスによって status = 2 の行だけを取ってくるのが簡単になります。
ALTER TABLE cv ADD INDEX idx_status (status);
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
cv テーブルが緑になりました。約21万件が取得されてソートされるので、先ほどの100万件と比べてかなり軽くなりそうです。 21万件という数字は MySQL の予測であって、実際 status = 2 のレコードは10万件程度です。 status に偏りがあって大半が status = 2 だとするとインデックスを使わない方が高速と判断されて Full Table Scan になりそうです(インデックスの使われ方の節参照)。そういう場合は ORDER BY の方にインデックスを貼りましょう。
補足:WHERE の条件にインデックス
status に偏りがあって大半が status = 2 だとするとインデックスを使わない方が高速と判断されて Full Table Scan になりそうです
上の記述を確かめるために実験をしましたが、大半どころかレコード数が100万件の cv テーブルの全レコードを status = 2 にして、 ANALYZE TABLE cv; を実行した後で SELECT * FROM cv WHERE status = 2; をしても status に貼ったインデックスが使われていました。レコード数を約1万件に減らすと同じクエリで Full Table Scan になりました。インデックスの使われ方の節に記述した通り、行数によっても変わるようです。 いずれにしても、ここでの status = 2 のように非常に偏りがあり大半の行を占める条件のカラムにインデックスを貼るのは避けた方が良いでしょう。
ORDER BY の条件にインデックス
(上で貼ったインデックスは DROP)
ALTER TABLE cv ADD INDEX idx_created_at (created_at);
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
今度は ORDER が黄緑になりました。テーブルの方は Full Index Scan となっています。 どういう処理が走っているかというと、 created_at のインデックスから順番にレコードを取り出し status = 2 であるかどうかを確認していきます。そして LIMIT の数だけ status = 2 のレコードが見つかった時点で探索を終了できます(created_at についてソート済みなので)。 それなのでテーブルから取得されるレコードの数も予測が100行となっています。 status = 2 のレコードが早く見つかれば良いですが、逆に最後の方まで見つからなければインデックスを全部読まなければなりません。 status = 2 がレアな場合はこの状況になってしまうので、 status にインデックスを貼って WHERE で取得されるレコードの数を減らすのが良さそうです(数が少なければソートのコストも低い)。 この辺りの話は雑なMySQLパフォーマンスチューニングが分かりやすかったです。
WHERE の条件と ORDER BY の条件のどちらにインデックスを貼るのが良いかは、 status の偏りなどを見てつけるのが良いと思います。 または、 idx_status と idx_created_at 両方つけてみてどっちが使われるか見るのも良いです。 今回の場合は両方つけると idx_created_at が選択されました。 ただし、 ORDER BY の条件の方にインデックスを貼る場合、 LIMIT の数が大きくなると WHERE の条件に合うレコードを探す為に多くの行を読まなくてはならない状況になります。 一方で、 WHERE の条件に貼ったインデックスを使う場合は LIMIT の数と探索のコストが無関係なので LIMIT の数が大きい場合は idx_status の方が良くなります。 今回のデータでざっと確認した所、およそ LIMIT 2100 より大きくすると idx_status が使われてました。
GROUP BY の条件にインデックス
(上で貼ったインデックスは DROP)
SELECT ad_id, COUNT(*) FROM cv WHERE status = 2 GROUP BY ad_id;
GROUP BY の条件である ad_id にインデックスを貼ると下図のように GROUP BY が黄緑になりました。
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
上図と下図を見比べると、 GROUP の下にあった tmp table, filesort が消えています。 GROUP BY の時になぜインデックスが使えるのかという話になるのですが、インデックスを貼っていない場合、テーブル全体をスキャンした後各グループの全ての行が連続する新しい一時テーブルを作成して(このときソートが必要)、この一時テーブルからグループを見つける処理が走ります(MySQL 5.6 リファレンスマニュアル / GROUP BY の最適化)。
GROUP BY の処理は早くなりますが、テーブルへのアクセスは Full Index Scan となっていて重いので WHERE の条件の方にインデックスを貼ることを検討した方が良さそうです。
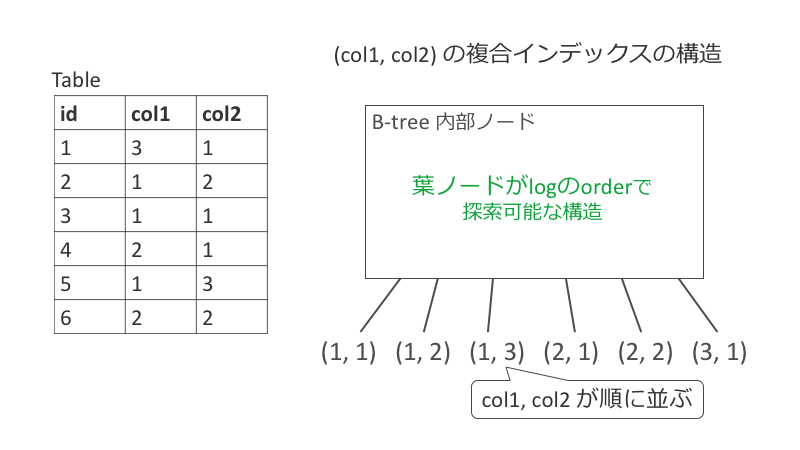
複合インデックス
(上で貼ったインデックスは DROP)
ALTER TABLE cv ADD INDEX idx_status_created_at (status, created_at);
この複合インデックスをつけて再び以下の SQL を VISUAL EXPLAIN します。
SELECT * FROM cv WHERE status = 2 ORDER BY created_at LIMIT 100;
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
テーブルへのアクセスも ORDER も緑になっていて良い感じです。 表形式の EXPLAIN と比較すると VISUAL EXPLAIN は一目でどの部分が改善したのかが分かります。
練習:もっと複雑な例
(上で貼ったインデックスは DROP)
一週間前からカウントして、コンバージョン数が多い順に ad テーブルのレコードを並べたい場合のクエリについて見ます。 細かい条件として cv の status は1、 ad の type は2のデータを抽出したいです。
SELECT
ad.id,
COUNT(DISTINCT cv.user_id) as cv_count
FROM
ad
INNER JOIN cv
ON cv.ad_id = ad.id
AND cv.status = 1
AND cv.created_at >= UNIX_TIMESTAMP(CURDATE() - INTERVAL 7 DAY)
WHERE
ad.type = 2
AND ad.end_at >= UNIX_TIMESTAMP(CURDATE() - INTERVAL 7 DAY)
GROUP BY
ad.id
ORDER BY
cv_count DESC
LIMIT 100
;
まずこの図を見ると cv テーブルの Full Table Scan をやめさせたい気持ちになります。 また、 ad テーブルは緑で PRIMARY KEY を使用しているので放っておいても良いような気持ちになりますが、 PRIMARY KEY は ad と cv を結合する為に使えているのであって ad 自体を type や end_at で絞り込む際にインデックスを使えていないので、この type や end_at の絞り込みは遅いはずです。 それなので ad の方にもインデックスを作って様子を見てみます。 以下のようなインデックスをつけて何が使われるか確認してみました。
色々変わってスッキリしました。 ad と cv の位置が入れ替わりました。 図から分かる事を列挙します。
ad テーブルが駆動表となり、 type や end_at の条件を絞るためにインデックス idx_type_end_at が使われる
cv テーブルの idx_ad_id_status_created_at を使って ad テーブルの対応する行を読み取っている
cv に関する status や created_at の条件をこのインデックスで絞れているかは分からない
一時テーブル buffer_result が消え、 GROUP BY の tmp table も消えました(GROUP BY は色もオレンジになった)
一時テーブル buffer_result が消える理由は、 GROUP BY の条件が駆動表(二重ループの外側)の ad.id であるため、あらかじめソートしてからループを回せば GROUP BY の条件にインデックスの節で説明した一時テーブルが不要になるためだと考えられます(参考:実例で学ぶ、JOIN (NLJ) が遅くなる理屈と対処法 / 高速化が難しいJOIN SQL)。 内部表で GROUP BY をすると一時テーブルが必須となります。実際、インデックスを貼る前の状態(cv が駆動表の状態)で、 GROUP BY を内部表の ad.id ではなく cv.ad_id とすると一時テーブルは出てきません。