
こんにちは。LINEでモバイルゲームの開発を担当しているSTです。今回は、オープンソースのモバイル向けゲームエンジンの世界シェア1位(25%)を誇るCocos2d-xにおいて、マルチスレッドを利用して並列処理を行う方法をご紹介します。シングルスレッドで動作していた既存の物理演算をマルチスレッド化して並列処理するように構造を改善し、パフォーマンスを向上させる方法について説明します。
マルチスレッドを利用した物理演算の並列処理構造の設計
マルチスレッドを利用した物理演算の並列処理構造を説明する前に、まず既存のシングルスレッドを利用したCocos2d-xのアップデートのループを説明しましょう。
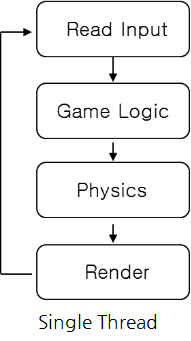
【図1】は、Cocos2d-xにおける既存のアップデートのループです。ユーザーの入力内容を取得してゲームロジックを実行した後、物理演算を行い、最後にレンダリングするという流れです。ここで重要なポイントは、シングルスレッドなので、物理演算が終わった後にレンダリングが実施されるという点です。つまり、物理演算が終わるまでレンダリングができない構造なのです。そのため、物理シミュレーションに多くの演算が必要な場合はレンダリングに遅延が発生し、結局はFPSが低下して、カクカクとした不自然な動きの画面になってしまいます。
その逆の場合も同じです。レンダリングの演算量が多くなると、次のユーザー入力で待機が発生し、物理演算結果の更新が遅延します。これは、すべての処理が一つのループで行われるからです。演算量が少なく、処理数が多くない状況ならシングルスレッドでも問題ありませんが、過負荷の状況ではこのような問題が生じやすくなります。
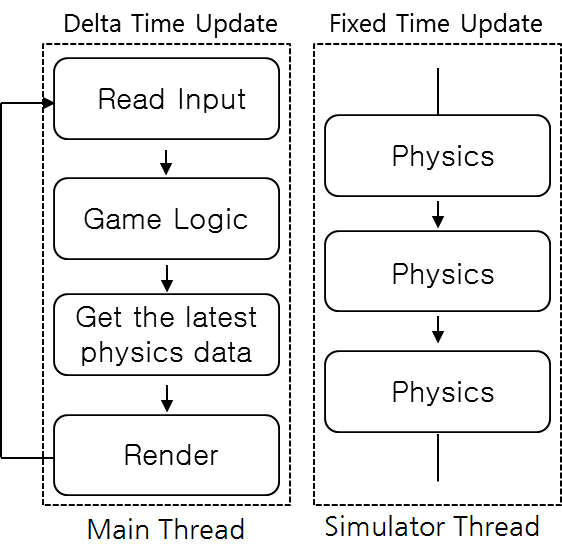
【図2】は、Cocos2d-xでマルチスレッドで動作する物理演算の並列処理の設計図です。【図1】との違いは、物理演算が別スレッドで実行されるという点です。メインスレッドでは、最新の物理演算結果のみ読み込んでレンダリングします。既存のシングルスレッドでは、物理演算が終わるのを待ってからレンダリングを行っていました。
一方、新たに設計したこの構造において最も重要なポイントは、物理演算は別スレッドで並列処理されており、メインスレッドではその物理演算が終わるのを待つことなく、最新の計算結果のみ読み込んでレンダリングするという点です。また、レンダリングに過負荷がかかって遅延が発生している状況でも、物理演算は別スレッドで一定のtick※注1を保持しながら独立して並列処理できます。
アップデート方法としては、メインスレッドではゲームのプレイ時間によって結果を表示する必要があるためDelta Timeアップデート※注2を使い、Simulatorスレッドでは物理演算の精度を高めるために一定時間ごとにアップデートするFixed Timeアップデート※注3を使います。こうすると、Unityのように物理演算が並列処理されるので、開発者はFixed Time値を変えながら、つまりゲームに適した物理演算の精度を調整しながらシミュレーションできるようになります。
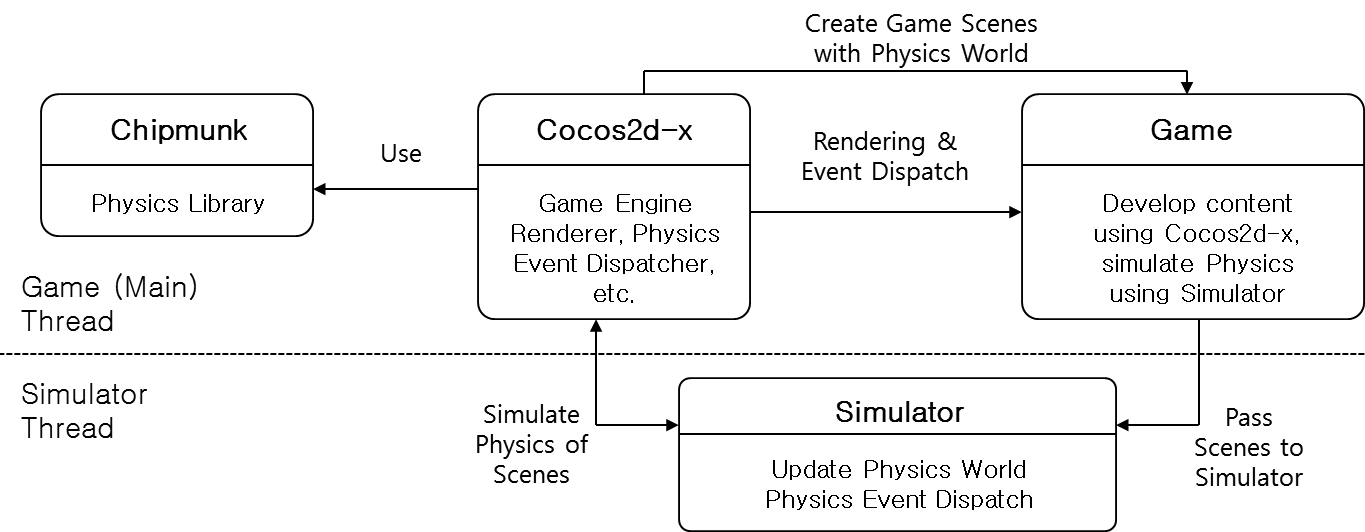
【図3】は、Cocos2d-xでマルチスレッドを利用して物理演算の並列処理ができるシステムアーキテクチャです。このシステムには、次の4つのモジュールがあります。
- Cocos2d-x
- Chipmunk Physics Library
- Game
- Simulator
Cocos2d-xにはChipmunk Physics Libraryという2D物理エンジンが標準で搭載されています。Gameは、Cocos2d-xを使ってゲームに必要なSceneを作成し、各種コンテンツを開発します。ここで、Scene情報を別スレッドであるSimulatorに渡すと、SimulatorはCocos2d-xにアクセスできるようになり、最終的にはCocos2d-xでChipmunkライブラリの物理演算を動的にコントロールできるようになります。ここでCocos2d-x、Chipmunk、Gameはメインスレッドで動作し、Simulatorは別スレッドで動作します。つまり、Gameと物理演算が並列に処理される構造なのです。
※注1:tickはアップデート関数が呼び出されることを意味し、tick countはアップデート関数が呼び出される回数のことです。前のアップデートから今のアップデートまでの時間差をDelta Timeといいます。Delta Time値が小さいほどアップデートのサイクルが早くなりますが、これは言い換えると、アップデートのtickの発生頻度が高くなるということです。
※注2:Delta Timeアップデートは、前フレームと現フレームの時間差の単位、つまりDelta Time(1/FPS)ごとにアップデートする方法です。
※注3:Fixed Timeアップデートは、一定時間ごとにアップデートする方法です。
マルチスレッドを利用した物理Simulatorの設計
物理演算をマルチスレッドで処理するためには、物理Simulatorの設計がとても重要です。

【図4】は、既存のCocos2d-xの物理構造を示した図です。ノードとPhysicsBody、SceneとPhysicsWorldはそれぞれ1対1の関係にあります。Sceneは複数の子ノードを持つことができ、PhysicsWorldも複数のPhysicsBodyを持つことができます。このように、ゲームの画面を格納する最上位オブジェクトであるSceneと複数の物理オブジェクトを格納する最上位オブジェクトであるPhysicsWorldが1対1の構造になっています。また、イベントハンドリングのための一つのEventDispatcher変数をグローバルに使用しています。

では、既存の構造をマルチスレッド化するには、どうすればいいでしょうか。【図5】には、Simulatorが追加されています。Simulatorは、SceneオブジェクトとEventDispatcherオブジェクトを持っています。SimulatorはSceneオブジェクトを使用してPhysicsWorldにアクセスし、最終的にはPhysicsBodyにアクセスして物理データにアクセスできるようになります。ここでPhysicsBodyは、Chipmunk Physics Libraryが提供する実際のRigidbodyオブジェクトであるcpBodyをラップしたクラスです。Cocos2d-xでは、PhysicsBodyオブジェクトが Chipmunk Physics Libraryの値にアクセスしています。つまり、Cosos2d-xで物理演算を並列処理するには、Cocos2d-xのソースコードのみならず、Chipmunk Physics Libraryのソースコードにも同期化ロジックを追加しなければなりません。
同期化のために、Chipmunk Physics Libraryのソースコードをダウンロードして、cpBody値の変更箇所にMutex同期化ロジックを追加しました。なお、Cocos2d-xでもcpBodyを使用するPhysicsBodyに同期化ロジックを追加しました。特にReadの場合は、TryLockを使用してロックがかかっているかをチェックしました。ロックがかかっていれば、リリースされるまで待たずに最新の計算結果を読み込んですぐにレンダリングを行い、別のタスクを処理できるようにしました。また、Cocos2d-xでは、EventDispatcher変数一つでイベントハンドリングを処理します。そのため、メインスレッドでEventDispatcherが発生した際にSimulatorスレッドからアクセスすると、プログラムにエラーが発生する可能性があります。
この問題の解決には2つの方法があります。一つ目は、Mutexを使用してクリティカルセクションを設定する方法です。二つ目は、Simulatorスレッドに独立したEventDispatcher変数をもう一つ生成する方法です。この設計では、パフォーマンス向上を図るためにMutexを極力使用していません。その代わり、Simulatorスレッドで物理衝突イベントを直接ハンドリングできるように、SimulatorでEventDispatcher変数を宣言し、メインスレッドとコンフリクトせずに独立してハンドリングできるようにしました。つまり、Chipmunkのソースコードに同期化ロジックを追加してビルドし、libchipmunk.aライブラリファイルを作成しました。このライブラリを修正されたCocos2d-xのソースコードとともにビルドしてリンクし、最終的にlibgame.soファイルを作成しました。こうすれば、libgame.soファイルを使ってゲームを駆動できるようになります。
テスト環境
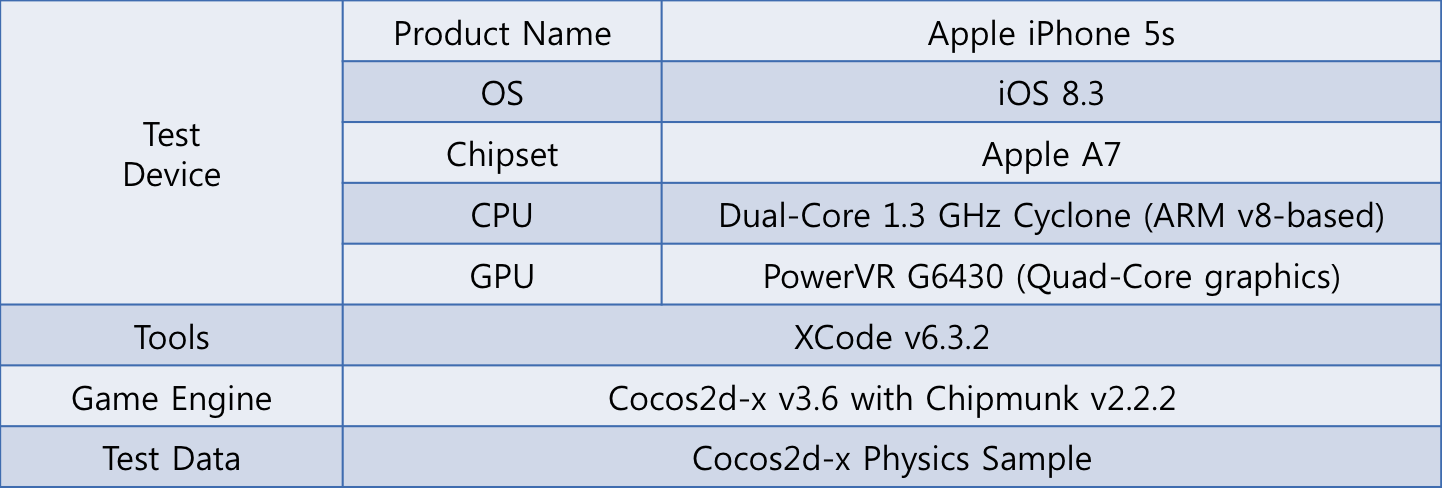
新たに設計したマルチスレッド構造で物理シミュレーションを行い、シングルスレッドのときに比べてパフォーマンスがどれほど向上したかをテストしてみました。テスト環境は下表のとおりです。テスト端末はiPhone 5sを使用し、Cocos2d-xのバージョンは3.6、Chipmunk Physics Libraryのバージョンは2.2.2を使いました。
同期化およびイベントハンドリングのテスト
物理演算をマルチスレッドで並列処理した場合、同期化およびイベントハンドリングが正常に動作するかを確認するためにテストプログラムを開発しました。テストプログラムは、Cocos2d-xに用意されているContact testの例題を活用しました。

【図6】は、テストプログラムで三角形と四角形のオブジェクトを大量に生成したものです。ここで、オブジェクト同士が衝突すると跳ね返り、画面の上下左右の端にある透明な壁に当たるとまた跳ね返ります。同期化およびイベントハンドリングをテストするために、各オブジェクトが衝突する度にコールバック関数でオブジェクトの色を緑色に変化させました。

シングルスレッドとマルチスレッドを同じ条件下でシミュレーションしました。その結果、【図7】の(a)と(b)のように両方とも緑色に変化していることを確認できました。オブジェクト同士が衝突して跳ね返るのは、同期化処理が行われたことを意味します。また、衝突したオブジェクトが緑色に変わったのは、イベントハンドリングが正常に動作し、コールバック関数でオブジェクトの色を緑色に変化させたことを意味します。こうして、同期化およびイベントハンドリングが正常に動作することを確認しました。では、次にパフォーマンス測定結果についてご紹介します。
パフォーマンス測定結果
既存のシングルスレッドに比べて、新たに開発したマルチスレッドによる物理演算がパフォーマンスをどこまで改善させたのかを測定してみました。
過負荷状態でのゲームのパフォーマンス測定結果
ゲームを開発していると、ゲーム自体が遅くなったり、過負荷がかかったりすることがあります。過負荷状態になりゲームのレンダリングの遅延が発生することがあります。その際、マルチスレッドの物理演算がどのような影響を与えるのかをテストしてみました。ゲームに負荷がかかるとCPUの演算量が多くなるので、次のとおりMatrixを複数回乗じた値を過負荷の度合いとして定義しました。
MAX_UPDATE_COUNT = 300000 updateForOverhead() for i ← 1 to MAX_UPDATE_COUNT do dstMatrix ← dstMatrix * srcMatrix
こうすることで、MAX_UPDATE_COUNTという変数を使ってゲームの負荷の度合いを定量的に数値化することができます。
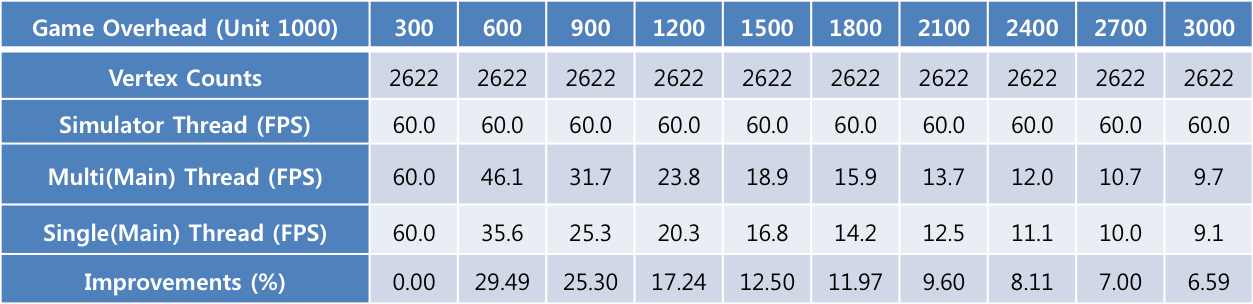
シミュレーションされるオブジェクトの数は360個に固定し、ゲームの負荷の度合いを最低30万から最大300万まで上げながらテストしました。【表2】のように、ゲームの負荷の度合いが30万のときは、シングルスレッドとマルチスレッド[Multi(Main) Thread、Simulator Thread]両方ともFPSの最大値として設定した60FPSに達していました。なお、300万のときは、シングルスレッドは9.1FPS、マルチスレッドのメインスレッドは9.7FPSと、ほぼ同等の数値を示していました。しかし、マルチスレッドのSimulatorスレッドでは60FPSとなっていました。
ゲームの負荷は物理演算と関係なくメインスレッドにかかるので、シングルスレッドもマルチスレッドのメインスレッドもともにパフォーマンスの低下が発生しました。一方、物理演算は、別スレッド(Simulatorスレッド)で動作するのでゲームの負荷による影響は受けず、30万のとき、300万のときいずれも60FPSとなっています。
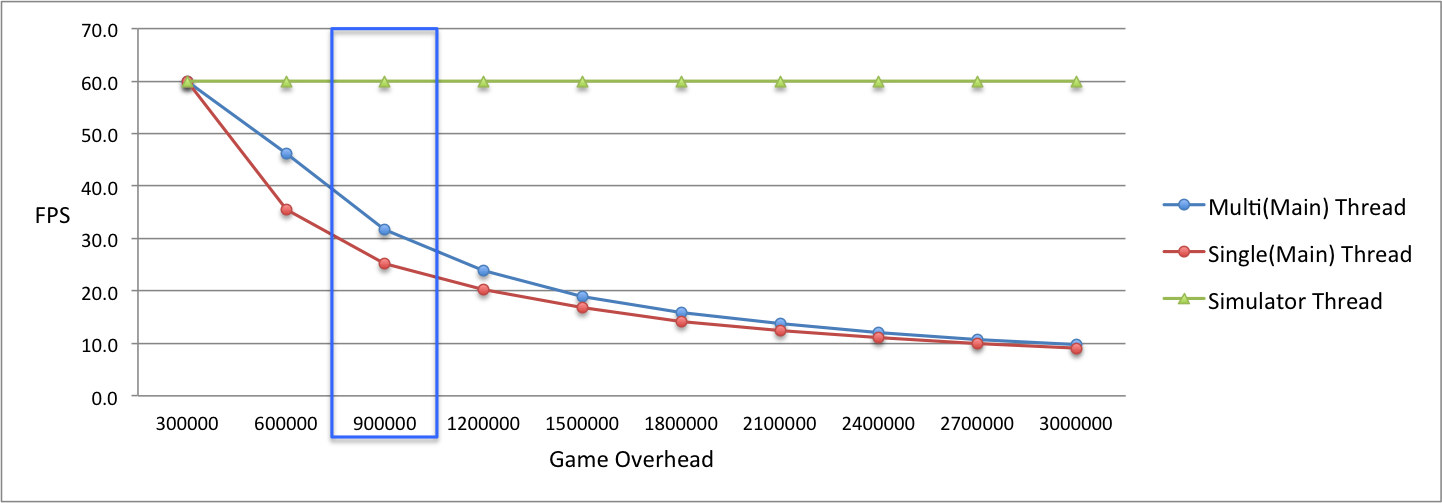
【図8】は、ゲームの負荷の度合いによるパフォーマンス測定結果をグラフにしたものです。シングルスレッドとマルチスレッドのメインスレッドの勾配(赤線・青線)を比較してみると、マルチスレッドのメインスレッドの方がパフォーマンスの低下が緩やかであることが分かります。これは、シングルスレッドでは物理演算とレンダリングを一つのループで処理するのに対し、マルチスレッドではSimulatorスレッドで物理演算を行うからです。このため、シングルスレッドのようなパフォーマンスの急激な低下は発生しません。
上記の測定結果はストレステストから得た数値ですが、実際に適用できる有意味な数値が得られるのはどの区間でしょうか。実際に適用できる数値は30FPSであり、ゲームの負荷が90万のときの区間です(【図 8】の青い四角で囲んだ部分)。この区間の数値は、シングルスレッドでは25.3FPS、マルチスレッドのメインスレッドでは31.7FPS、そしてSimulatorスレッドでは60FPSとなっています。
物理演算をDelta Timeでアップデートするケースを分析してみると、シングルスレッドでは約0.0395秒(25.3FPS)ごとに物理演算を行い、レンダリングします。それに対し、マルチスレッドでは、0.0167秒(60FPS)ごとに物理演算を行い、0.0315秒(31.7FPS)ごとにレンダリングします。つまり、マルチスレッドの方が約2.4倍小さい値で細かく物理演算を行うので当たり判定がより正確になる上、より高いFPSでのレンダリングもなめらかになり、クオリティの面で格段の差が出ます。また、Fixed Time値を0.0167秒に設定してFixed Timeでアップデートするケースを分析してみると、シングルスレッドでは約0.0395秒(25.3FPS)ごとに0.0167の値でstep※注4しながら当たり判定の処理およびシミュレーションを行います。
一方、マルチスレッドでは、約0.0167秒(60FPS)ごとに0.0167の値でstepしながら当たり判定の処理およびシミュレーションを行います。この場合、シミュレーションするstep値が同じなので精度も同じと思われますが、マルチスレッドの方でtickが約2.4倍多く発生するので、シングルスレッドよりシミュレーションが高速化することが分かります。
※注4:stepとはアップデートと同じで、アップデートとは物理シミュレーションを行うという意味です。「1段階ずつアップデートする」ということを、「1段階ずつstepする」とも表現します。
過負荷状態での物理演算のパフォーマンス測定結果
ゲームを開発していると、ゲームロジックまたはグラフィックの問題ではなく、物理演算自体が遅くなることがあります。このように物理演算に負荷がかかった場合、どのような変化があるかをテストしてみました。
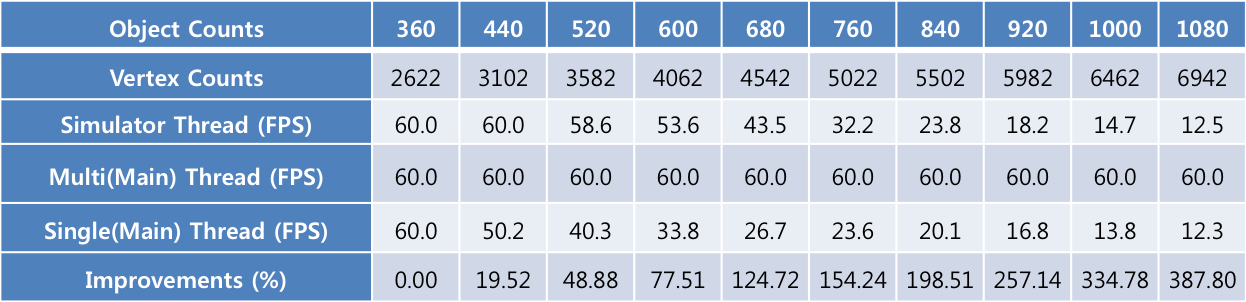
ゲームの負荷の度合いは30万に固定し、シミュレーションされるオブジェクトの数は最低360個から最大1080個まで増やしながらテストしました。【表3】から分かるように、オブジェクトの数が360個のときは、シングルスレッドとマルチスレッド[Multi(Main) Thread、Simulator Thread]両方ともFPSの最大値として設定した60FPSに達していました。一方、1080個のときは、シングルスレッドは12.3FPS、マルチスレッドのメインスレッドは60FPSでした。しかし、マルチスレッドのSimulatorスレッドでは12.5FPSと、シングルスレッドに近い数値を示しています。
物理演算に負荷をかけたため、シングルスレッドもマルチスレッドのSimulatorスレッドもともにパフォーマンスの低下が発生したのです。それに対し、マルチスレッドのメインスレッドでは、ゲームロジックとレンダリングがSimulatorスレッドとは別に動作するので、物理演算のコストが発生せず、360個のときと1080個のときいずれも60FPSとなっています。
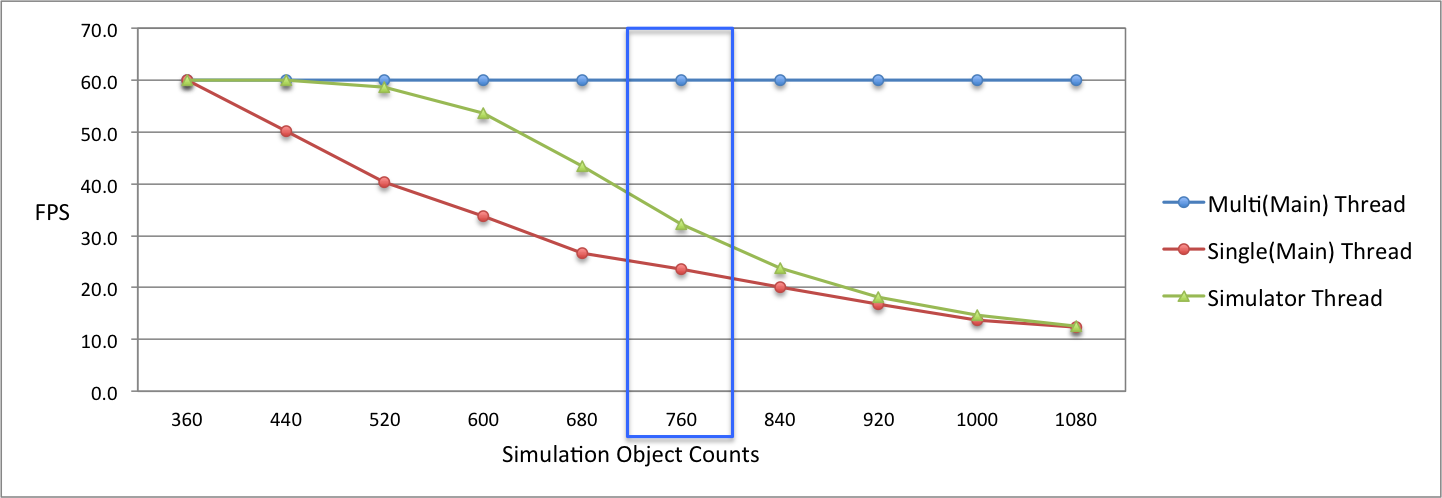
【図9】は、物理演算の負荷の度合いによるパフォーマンス測定結果をグラフにしたものです。シングルスレッドとマルチスレッドのメインスレッドの勾配(赤線・青線)を比較してみると、シングルスレッドではパフォーマンスが急激に低下しているのに対し、マルチスレッドのメインスレッドではFPSの最大値である60FPSを維持していることが分かります。なお、Simulatorスレッドではパフォーマンスの低下はあるものの、シングルスレッドほど急激な低下ではありません。シングルスレッドでは物理演算とレンダリングを一つのスレッドで行うのでパフォーマンスが急激に低下しますが、Simulatorスレッドでは物理演算のみ行うので、シングルスレッドよりはパフォーマンスの低下が緩やかになっていることが分かります。
上記の測定結果はストレステストから得た数値ですが、実際に適用できる有意味な数値が得られるのはどの区間でしょうか。実際に適用できる数値は30FPSであり、オブジェクトの数が760個のときの区間です(【図9】の青い四角で囲んだ部分)。この区間の数値は、シングルスレッドでは23.6FPS、マルチスレッドのメインスレッドでは60FPS、そしてSimulatorスレッドでは32.2FPSとなっています。物理演算をDelta Timeでアップデートするケースを分析してみると、シングルスレッドでは約0.0424秒(23.6FPS)ごとに物理演算を行い、レンダリングします。それに対し、マルチスレッドでは、0.0311秒(32.2FPS)ごとに物理演算を行い、0.0167秒(60FPS)ごとにレンダリングします。
つまり、マルチスレッドのときは、別スレッドで0.0311秒ごとに物理演算を並列処理し、メインスレッドで0.0167秒ごとにすでに計算された物理シミュレーション値でレンダリングのみ実行します。そのため、パフォーマンスの面では当たり判定が正確になり、動きがよりなめらかになることを確認できます。また、Fixed Time値を0.0167秒に設定し、Fixed Timeでアップデートするケースを分析してみると、シングルスレッドでは約0.0424秒(23.6FPS)ごとに0.0167のstepで当たり判定の処理およびシミュレーションをしてからレンダリングします。一方、マルチスレッドでは、約0.0311秒(32.2FPS)ごとに0.0167のstepで当たり判定の処理およびシミュレーションを行い、0.0167秒(60FPS)ごとにすでに計算された値でレンダリングします。この場合、マルチスレッドの方がシングルスレッドより正確で速いだけでなく、レンダリングFPSが約2.5倍高いため、動きが遥かになめらかになります。
当たり判定の正確性テスト
上述の通り、シングルスレッドのときに物理演算をDelta Timeで行う場合、ゲームに負荷がかかるとtickが不安定になって衝突チェックが正確にできない可能性があります。マルチスレッドで物理演算を行った際、当たり判定の正確性がどれほど向上したかをテストしてみました。テストの条件は、実際に適用できる数値、つまりマルチスレッドのメインスレッドとSimulatorスレッドがいずれも30FPSになる状況としました。アップデート方法としては、シングルスレッドではDelta Time方法を使い、マルチスレッドではメインスレッドはDelta Time、SimulatorスレッドはFixed Timeをそれぞれ使用するように設定しました。オブジェクトが壁(Bound Box)にぶつかると跳ね返らないといけないのに、すり抜けてしまうケースがあるかをチェックし、シミュレーションが開始してから経過時間ごとにオブジェクトの数を観察しました。
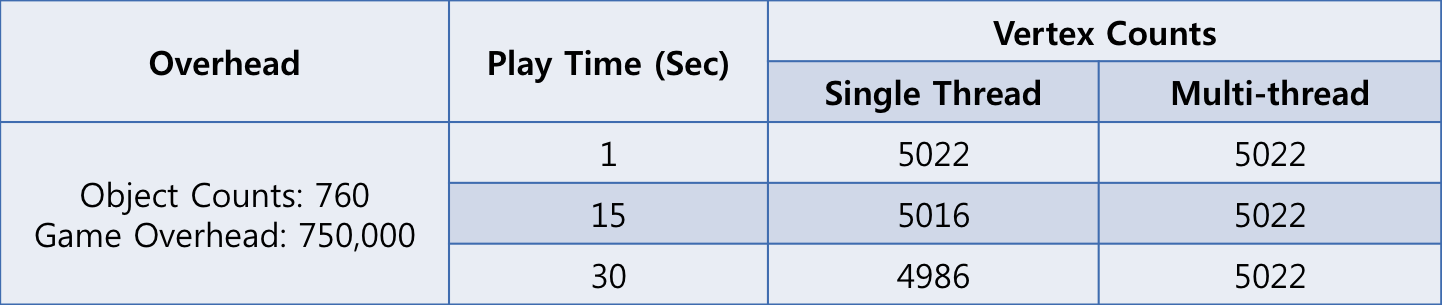
【表4】は、マルチスレッドで物理演算したとき、当たり判定の正確性がどれほど向上したかを測定した結果です。最初はシングルスレッドとマルチスレッド両方ともVertex(頂点)の数が5022個でしたが、15秒後にはシングルスレッドでVertexの数が6個減りました。三角形1個にはVertexが3個あるので、三角形2個が消えたことになります。さらに30秒後には4986個になり、36個が減少しました。これは、三角形12個が消えたと推定できます。一方、マルチスレッドでは、時間が経ってもずっと5022個であり、壁をすり抜けて消えたオブジェクトはなく、正確に当たり判定が行われていることが分かります。
結論および今後の課題
以上のとおり、シングルスレッドで動作する物理演算をマルチスレッド化して並列処理する方法について説明しました。結論としては、物理演算をマルチスレッドで並列処理することで、構造とパフォーマンスが改善されたと言えます。構造の面では、既存の物理演算の処理を別スレッドに分離することで、メインスレッドとは独立してFixed Time値、つまり精度を調整しながらシミュレーションできるようになりました。パフォーマンスの面では、マルチスレッドの方で当たり判定がさらに正確化・高速化し、動きがなめらかになることを確認できました。通常ゲームを開発していると、物理演算が遅いため機能をスペックアウトしたり、邪道な方法で実装することもあります。しかし、このように物理演算を並列処理することで、これまでは技術的な限界のため開発できなかったジャンル、新しいコンテンツを開発できる可能性が示されたのではないでしょうか。
現在、Simulatorはクライアントでのみ動作しますが、これをサーバで分散処理できるようにすれば、大規模なシミュレーションが可能になると思います。また、物理演算のみならず、ゲームロジックをも並列処理して、大規模な分散ゲームSimulatorを開発してみるのも面白い課題になるかもしれません。それが実現すれば、レンダリングとは別に、データを中心にゲームをシミュレーションできるゲームバランス調整ツールの開発にも活用できるようになるでしょう。
※この記事は、筆者の論文「Multi-threaded Parallel Processing Technique for Real-time Physics Simulation in Game Engine(2016, Yonsei University)」の一部を抜粋・脚色して作成しました。