
こんにちは、Data Platform室の小野です。Data Platform室では、昨年のLINE DEVELOPER DAYでも発表があったように、大規模なHadoopクラスタを運用しています。
先日、分析基盤に特化したデータセンターのルームが構築され、ここへクラスタの移行作業を行いました。このクラスタは全社的に使われており、毎日10万個以上のジョブが走っています。そのため、クラスタを止めずに移行することが求められました。
この記事では、そのときどのようにHadoopクラスタを移行したのか、そしてどのような問題が起こったのかについて、ご紹介します。
今回は、以下の4つのコンポーネントに絞って、ご紹介します。
- ResourceManager
- NameNode
- JournalNode
- Zookeeper
現在使用しているソースのバージョンについては、LINE独自でパッチをあてたり、いくつかバックポートを行なっていたりするため、オープンソースとして公開されているソースと完全に一致するものではないですが、Hadoopは3.1.2、Zookeeperは3.5.5がベースとなっています。
ResourceManager
ResourceManager(以下、RM)の移行は、以下のように行いました。
手順
- 移行先のRMを追加した設定ファイルを展開し、YARN Clientを使用しているコンポーネントをリスタート。
- 意図せず移行先のRMがActiveになっても問題が起こらないように、移行元のRMをリスタートする前にYARN Clientに対して新しい設定を反映させます。
- 移行元と移行先、合わせて4つのRMが存在する状態になるため、設定ファイル(yarn-site.xml)は以下のようになります。
... <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2,rm3,rm4</value> </property> ... <property> <name>yarn.resourcemanager.hostname.rm3</name> <value>new-rm003.linedev.com</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm3</name> <value>${yarn.resourcemanager.hostname.rm3}:28088</value> </property> ... - 新しい設定を反映後、HiveServerやSpark Streaming Jobなど、関係するすべてのコンポーネントをリスタートする必要があります。
- 移行元のYARNサービス (RMとNodeManager)をスタート後、移行先のRMをスタート。
- 移行元のRMをストップし、移行先のRMにActiveなRMが存在するようにする。
- 設定ファイルから移行元の設定を削除し、YARN Clientを使用しているコンポーネントとYARN サービスをリスタート。
移行に伴う設定変更
移行テスト時に、実行しているYARNのジョブが妙に時間がかかることがあったため、調査を行いました。その結果、RMのフェイルオーバーの処理に時間がかかることがわかりました。以下は、そのときのNodeManagerのログになります。
INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
INFO org.apache.hadoop.io.retry.RetryInvocationHandler: java.net.ConnectException: Call From line-nodemanager.linedev.com to line-rm2.linedev.com:8031 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused, while invoking ResourceTrackerPBClientImpl.registerNodeManager over rm2 after 1 failover attempts. Trying to failover after sleeping for 27237ms.
INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider: Failing over to rm3
INFO org.apache.hadoop.io.retry.RetryInvocationHandler: java.net.ConnectException: Call From line-nodemanager.linedev.com to line-rm3.linedev.com:8031 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused, while invoking ResourceTrackerPBClientImpl.registerNodeManager over rm3 after 2 failover attempts. Trying to failover after sleeping for 43897ms.
INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider: Failing over to rm4利用している "ConfiguredRMFailoverProxyProvider" の実装をみてみると、以下の2点のことがわかりました。
- 設定ファイルに記述した順番でRMへの接続を試みる。
- フェイルオーバーのリトライ時に、"yarn.client.failover-sleep-base-ms" の値をベースにスリープする。RMが2台の場合は、フェイルオーバーのリトライは基本的に起きないため、このスリープは無視できると思います。
"yarn.client.failover-sleep-base-ms"のデフォルト値は30秒なので、もしActiveなRMが"yarn.resourcemanager.ha.rm-ids"の4番目に記述されている状態の場合、2分以上NodeManagerがスリープ状態になる可能性があることがわかりました。
このような状態は、移行時にユーザーに影響がでる可能性があるため、"yarn.client.failover-sleep-base-ms"を30秒から5秒に変更しました。
NameNode
Hadoop 3.x から、NameNode(以下、NN)は2台以上Standby NameNodeを追加できるようになりました(HDFS-6440)。これを利用して、以下のように移行を行いました。
手順
- 移行先のNNを追加した設定ファイルを展開し、移行元のNNとHDFS Clientを使用しているコンポーネントをリスタート。
- 移行元のNNをリスタートをせずに移行先のNNへフェイルオーバーさせようとすると、既存のNNが新しいNNを見つけられず、フェイルオーバーに失敗してしまいます。
- 設定ファイルは、以下のようになります。
... <property> <name>dfs.ha.namenodes.ns01</name> <value>nn1,nn2,nn3,nn4</value> </property> ... <property> <name>dfs.namenode.rpc-address.ns01.nn3</name> <value>new-nn03.linedev.com:8020</value> </property> <property> <name>dfs.namenode.servicerpc-address.ns01.nn3</name> <value>new-nn03.linedev.com:8040</value> </property> ...
- 移行先のNNをStandbyとして立ち上げる。
- 具体的には、以下のようなコマンドを移行先のNNで実行することになります。
$ kinit -kt nn.keytab nn/new-nn03.linedev.com@LINE.COM # LINEのHadoopはKerberos認証を有効にしているため、コマンドを実行する前にこの作業が必要になります $ hdfs namenode -bootstrapStandby $ sudo systemctl start zkfc $ sudo systemctl start namenode
- 具体的には、以下のようなコマンドを移行先のNNで実行することになります。
- 移行先のNNにActiveなNNが存在するようにする。
- 以下のようなコマンドで、 ファイルオーバーさせることが可能です。
$ kinit -kt nn.keytab nn/new-nn03.linedev.com@LINE.COM $ hdfs haadmin -ns ns01 -failover nn1 nn3
- 以下のようなコマンドで、 ファイルオーバーさせることが可能です。
- 設定ファイルから移行元のNNを削除し、NNとHDFS Clientを使用しているコンポーネントをリスタートする。その後、移行元のNNをストップする。
移行実施時に障害発生
手順1が終わった時点から、HiveServer2がスタックしたような状態になってしまいました。
HiveServer2のメトリクスを見てみると、Hive Metastoreとのやりとりに時間がかかるようになったことにより、クエリを捌き切れなくなっていることがわかりました。
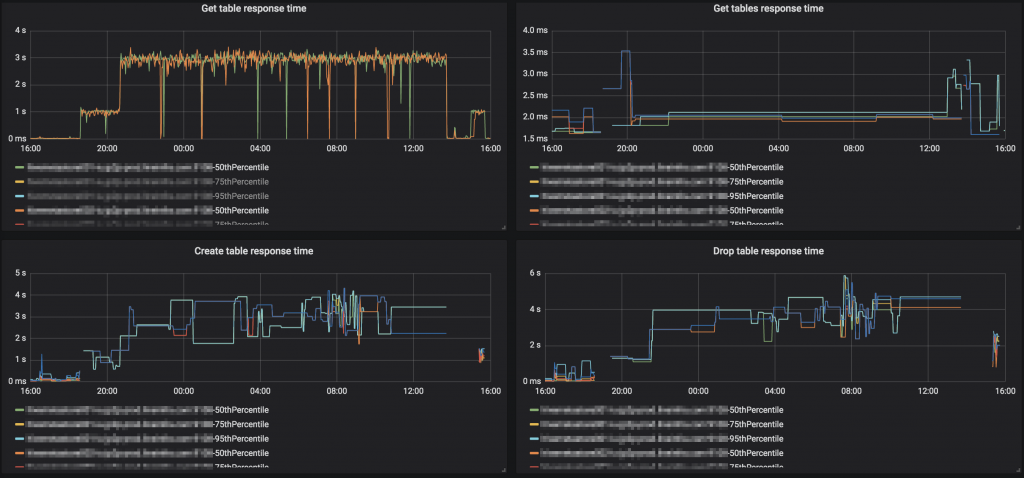
そして、その時のHive Metastoreのログには、以下のようなログが出力されていました。
INFO [pool-8-thread-159] retry.RetryInvocationHandler: java.net.ConnectException: Call From line-hivemetastore.linedev.com to nn03.linedev.com:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused, while invoking ClientNamenodeProtocolTranslatorPB.getFileInfo over nn3.linedev.com:8020 after 1 failover attempts. Trying to failover after sleeping for 1307ms.
INFO [pool-8-thread-159] retry.RetryInvocationHandler: java.net.ConnectException: Call From line-hivemetastore.linedev.com to nn04.linedev.com:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused, while invoking ClientNamenodeProtocolTranslatorPB.getFileInfo over nn1.linedev.com:8020 after 2 failover attempts. Trying to failover after sleeping for 2644ms.これより、RMの移行時に発見した問題と同様に、hdfs-site.xmlに記載したnameserviceの定義の順番がパフォーマンスに影響していることがわかりました。
我々は手順1で、特にnameserviceの順番を意識せずに設定しており、実際の設定は以下のようになっていました。(nn01とnn02が移行元のNN、nn03とnn04が移行先のNN)
<property>
<name>dfs.ha.namenodes.[nameservice ID]</name>
<value>nn03,nn04,nn01,nn02</value>
</property>手順1が終わった時点ではまだnn03とnn04のNNは起動していない状態であるため、必ずフェイルオーバーによるスリープが発生する状態になっていました。
まとめると、以下のような状況が発生していました。
- Active NNがdfs.ha.namenodes.[nameservice ID]の3番目になったことにより、Hive Metastore内部のDFS Clientでスリープが多発していた。
- Hive Metastoreのレスポンスタイムが増加した。
- 1クエリあたりの処理時間が延びることでユーザーからのクエリがHiveServer2に積み上がり、HiveServer2の thrift worker スレッドが使い果たされた状態になった。
我々はProxyProviderとして "ConfiguredFailoverProxyProvider"を利用していたため、上記のようにフェイルオーバーが行われましたが、これを"RequestHedgingProxyProvider"に変更することで、この問題を防げると考えられます。
JournalNode
JournalNode(以下、JN)の追加については、公式にサポートされた機能はありません。このような機能について、Jiraのチケットは作成されていますが、今のところ進捗はなさそうです。そのため、手動で行う操作が多く発生します。
全体の流れを以下に示します。
手順
- 移行先のJNを用意。
- 新しくJNを追加する際には、既存のJNと同じVERSIONファイルを新しいJNに用意します。VERSIONファイルはnameservice毎に存在し、それぞれ内容が違うので注意する必要があります。
例えば、"dfs.journalnode.edits.dir"に"/data/hadoop/journalnode"が設定され、"nameservices"に"linehadoop"が存在する場合、新規追加予定のJN上で以下のような作業を行います。$ sudo -u hdfs mkdir -p /data/hadoop/journalnode/linehadoop/current $ sudo -u hdfs mkdir /data/hadoop/journalnode/linehadoop/current/paxos # HDFS-10659 が適用されていない場合、手動でこのディレクトリを作る必要があります。 $ cat <<'EOL' > /data/hadoop/journalnode/linehadoop/current/VERSION namespaceID=xxx clusterID=xxx cTime=xxx storageType=JOURNAL_NODE layoutVersion=-64 EOL - 移行先のJN2台を追加して以下のような状態になったhdfs-site.xmlも、この段階でNNと既存のJNに展開します。
<property> <name>dfs.namenode.shared.edits.dir.ns01</name> <value>qjournal://jn1.linedev.com:8485;jn2.linedev.com:8485;jn3.linedev.com:8485;jn4.linedev.com:8485;jn5.linedev.com:8485/journal</value> </property>
- 新しくJNを追加する際には、既存のJNと同じVERSIONファイルを新しいJNに用意します。VERSIONファイルはnameservice毎に存在し、それぞれ内容が違うので注意する必要があります。
- NNをリスタート後、JNをリスタート。
- 新規に追加したJNについては、NNのリスタート後JournalNodeSyncerスレッドによって過去分のログがsyncされます。
- 手順1と2と同様の作業を行い、JN3台をさらに追加する。
- 設定ファイルから移行元のJNを削除し、NNとJNをリスタートする。その後、移行元のJNをストップする。
Zookeeper
Zookeeper(以下、ZK)は、Zookeeper 3.5から導入された Dynamic Reconfigurationを利用して移行します。これは、ZKをリスタートせずに設定を変えられる機能です。どのように実現しているかについては、この論文を読むことで知ることができます。
この機能を有効にするためには、以下のような設定をzoo.cfgに入れておく必要があります。
reconfigEnabled=true
dynamicConfigFile=/zookeeper/conf/zoo.cfg.dynamic全体の流れとしては、以下のようになります。
移行の準備
移行の前に、super userの設定を行いました。super user は、JVM オプションとして "-Dzookeeper.superUser" を追加することで、設定できます。このユーザーは、移行作業時に使用する "reconfig" コマンドの実行ユーザーとして使います。
zookeeper-env.sh
export SERVER_JVMFLAGS="$SERVER_JVMFLAGS -Dzookeeper.superUser=zookeeper ..."また、ZKの監視用のダッシュボードがあると、ZKの状況が一目でわかるようになるため、便利です。弊社では、JMX exporter + Prometheus + Grafana の構成でZKの監視を行なっています。ZKのJMXポートは、"zookeeper-env.sh"に"export JMXPORT={jmx_port}"を追加することで有効化できます。
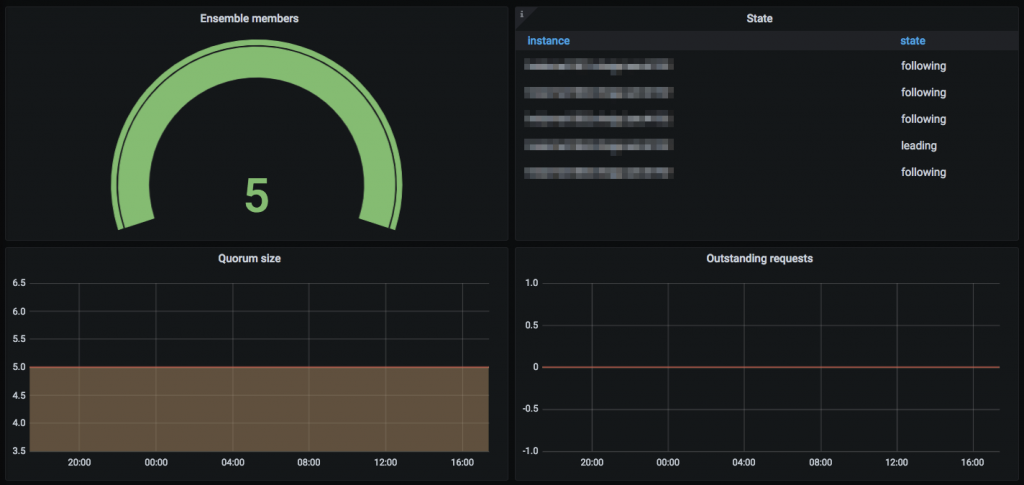
手順
- 移行先ZKをObserverとして追加する。
- 移行先ZKは、zoo.cfg.dynamicに以下のような記載をしてスタートさせます。
server.1=zk001.linedev.com:2888:3888:participant;2181 server.2=zk002.linedev.com:2888:3888:participant;2181 server.3=zk003.linedev.com:2888:3888:participant;2181 server.4=zk004.linedev.com:2888:3888:observer;2181 server.5=zk005.linedev.com:2888:3888:observer;2181 server.6=zk006.linedev.com:2888:3888:observer;2181 server.7=zk007.linedev.com:2888:3888:observer;2181 server.8=zk008.linedev.com:2888:3888:observer;2181
- 移行先ZKは、zoo.cfg.dynamicに以下のような記載をしてスタートさせます。
- 移行先ZKのsyncが終わったことを確認後、移行先ZKをParticipantに変更すると同時に、移行元ZKをアンサンブルを構成から外す。
- 新規に設定ファイルを作成し、そのファイルに対して"reconfig"コマンドを実行することで、構成を変更することができます。
新規の設定ファイル(newconfig.cfg)
"reconfig"コマンドの実行例server.4=zk004.linedev.com:2888:3888:participant;2181 server.5=zk005.linedev.com:2888:3888:participant;2181 server.6=zk006.linedev.com:2888:3888:participant;2181 server.7=zk007.linedev.com:2888:3888:participant;2181 server.8=zk008.linedev.com:2888:3888:participant;2181$ kinit -kt zk.keytab zookeeper/zk004.linedev.com $ {path-to-zookeeper}/bin/zkCli.sh -server zk004.linedev.com:2181 [zk: zk004.linedev.com:2181(CONNECTED) 0] reconfig -file newconfig.cfg - 移行元のZKはこの"reconfig"を実行後、"Non-voting follower"モードになります。これは、クライアントからのread/writeは受け付けるものの、クォーラムへの投票は行わないという状態です。
- 新規に設定ファイルを作成し、そのファイルに対して"reconfig"コマンドを実行することで、構成を変更することができます。
- 移行元ZKを利用していたコンポーネントの設定ファイル(core-site.xmlやyarn-site.xmlなど)を更新し、それぞれ必要に応じてリスタートする。その後、移行元ZKをストップする。
ちなみに、もしDynamic Reconfiguration機能がなかった場合、一時的に5台以上のアンサンブルを構成する必要があり、さらにその増やしたノードを減らす作業も発生します。その際、アンサンブルの構成を変更する度にZKのローリングリスタートとZK Clientのリスタートが必要になります。また、ZKのローリングリスタートは、フォロワーからリスタートする必要があります。したがって、Dynamic Reconfiguration機能がない状況で移行を行うとなると、気を使う作業を何度も行うことになります。
おわりに
本記事では、弊社で行ったHadoopクラスタの移行作業について紹介させていただきました。今回の移行は、クラスタのダウンタイムを発生させることなく、ユーザーにほとんど影響を出さずに実施できました。また、この移行は、普段の運用とは少し違う視点からシステムを見ることになり、今まで気付けなかった改善点を知る良いきっかけとなりました。Hadoopクラスタの移行は、オンプレミスで運用している場合出会う可能性の高い作業だと思います。かく言う私も、前職で1度経験したため、今回の移行は2度目の経験となりました。本記事が、これからHadoopクラスタの移行をする方の助けになれば嬉しいです。