
はじめに
こんにちは、LINEマンガ開発の伊藤です。
今回はLINEマンガのデータベースをシャーディングした作業について、サーバーエンジニア編とデータベースエンジニア編に分けてご紹介したいと思います。
本エントリでは、シャーディングに至った経緯や対応方針、アプリケーション側で改修したことについて書いていこうと思います。
LINEマンガとは
「LINEマンガ」は、アプリやWEBブラウザ、LINE上でマンガ作品が楽しめる電子コミックサービスです。
2013年4月にサービスを開始し、2019年4月9日で6周年を迎えました(*1)。
250社以上の出版社・レーベルを通じて現在までに38万点以上のマンガを配信し、ダウンロード数は国内で2,300万件以上(2019年4月時点)、App Annieが発表した「Top Publisher Award 2018」の日本アプリ年間収益ランキング(非ゲームを除く)ではコミュニケーションアプリ「LINE」に続いて、なんと2位(*2)です!
シャーディングの背景
ありがたいことにユーザーが増え続けているので、以前からシャーディングは検討事項の一つでした。
しかしシャーディング前提の設計ではなかったことや、開発リソース等の問題もあり、データの増加にはスケールアップで対応していました。
2018年の2月にもNVMe-SSDの3TBから6TBに換装し、「これであと3年はいける!」と見込んでいた所でした。
その半年後、レプリケーション遅延のアラートが上がったことで状況が一変します。
遅延の要因は、NAVER WEBTOONの人気電子コミックサービス「XOY」との統合でした。
XOYで連載していた作品をLINEマンガへ移行し、全話無料にする施策をうった事によって、レコードのINSERTが急増したのです。
遅延は一時的なものでしたが、想定よりもデータの増加量が多く、このペースだと半年持たなそうな事と、テーブルの肥大化が原因でIO性能が劣化していることが分かりました。
肥大化していたのは主に以下のテーブルです。
連載マンガの閲覧履歴
マンガの未読・既読の機能に利用されていて、1話読むと1レコード作られます。これが全話無料キャンペーンによって大量のINSERTが発生したテーブルです。
未読・既読の情報は、サービスの様々な箇所に利用されています。
購入履歴
ユーザーが課金して購入した単行本を管理するテーブル(無料分も含む)です。
連載マンガのお気に入り
読んで字のごとく、ユーザーのお気に入りを管理するテーブルで、お気に入りを解除するとレコードを削除します。
配信されたマンガは基本的にずっと配信が続きますが、急遽停止することもあるため、これらのテーブルとmasterデータをJOINするような使い方をしています。
基本的にレコード削除のオペレーションはなく、ユーザー数、コンテンツ数、運用期間に比例してデータが増える性質を持っています。
今後もデータの増加は予想されるため、スペックアップで乗り切るのも難しく、抜本的な対策としてシャーディングに踏み切りました。
移行方法の検討
NAVER製のミドルウェア「NBase」を使う
これは無停止でシャードDBを追加できるMySQLライクなミドルウェアです。
しかし、NBaseはJava/C向けのAPIしか提供がなく、Perlで実装されているLINEマンガではそのまま使うことができません。
ライブラリを移植したり、LINEマンガをPerlからJavaで再実装するのは工数的に現実的ではなく、今回は導入を見送りました。
MySQL Spiderエンジンを使う
情報があまり多くなく、社内での運用実績もなかったため見送りました。
ダブルライト方式
既存DBとシャードDBでミラーリングし、両方に書き込み(ダブルライト)する。
ダブルライト後、読み込み、書き込みの順で既存DBからシャードDBに向けていく比較的オーソドックスなやり方です。
実装の修正が多く、二重に書き込み処理をすることによるレスポンスタイムの劣化や、データ不整合のリスクがありますが、不確定要素は少なかったので今回はこれを採用しました。
シャーディングまでの軌跡
サービスインに至るまで紆余曲折ありましたが、大きく6つのPhaseに分けて計画をたてました。
アプリケーション側としては、Phaseを分けることで修正範囲が明確になり、実装漏れやレビュー観点の明確化に繋がります。
この方針のおかげで、実装ミスはレビューでほぼ潰すことができ、QA工数の削減に成功しました。
Phase1 調査・準備
サービスとして使っていないテーブルを洗い出し、Read/Writeがないテーブルと突き合わせて削除するリファクタリングを実行。
少しでも容量を確保して時間を稼ぐのと、適度にリファクタリングをすることで、後のPhaseで修正箇所を減らす事が目的です。
また、外部キーやINDEXを見直し、INSERTの性能を改善するのもこのPhaseで行いました。
Phase2 冗長構成にする
シャード用のDBを新規に用意し、既存DBからレプリケーションを貼って冗長構成にしました。
その際、5.6から5.7へのバージョンアップも同時に行いました。
Phase3 既存DBとシャードDBの両方に書き込む
今回はシャードを8分割することにしました。
書き込み先のシャードは、ユーザーのID(LINEマンガではmember_id)からハッシュスロットを計算して決めています。
{
my $hashslot = crc32(member_id) % 65535;
# 0 〜 8191 => シャード1
# 8192 〜 16383 => シャード2
# 16384 〜 24575 => シャード3
# 24576 〜 32767 => シャード4
# 32768 〜 40959 => シャード5
# 40960 〜 49151 => シャード6
# 49152 〜 57343 => シャード7
# 57344 〜 65535 => シャード8
}ハッシュ値を分割する8の余りではなく、65535で割った余りでレンジを求めているのがポイントです。
このやり方の利点は、シャード数の増減が容易なところにあります。
(アプリケーション側はレンジを8分割から16分割にするだけで良く、MySQLは各インスタンスを2分割すれば良い)
Phase3.5 パーティショニング方式の登場
Phase3の実装が終わった段階で、MySQLのgenerated columnとパーティショニング機能を組み合わせれば、ダブルライトしなくても良いのでは、という話が持ち上がりました。
実装/QAは終わっていたものの、ダブルライトによる性能劣化は1番の懸念事項でしたし、面白そうなやり方だからチャレンジしてみたいという思いもあって、思い切って方針を変更しました。
こちらのアイデアについては「データベースエンジニア編」で詳細が解説されますので、ぜひあわせて読んでみてください!
Phase4 参照をシャードDBのみに向ける
実装の修正で一番の難所がこのPhaseでした。
修正パターンは大きく分けて3つあり、
- ユーザーに紐づくレコードを取得するような、修正自体は単純でも数が多いもの。
- 売れ筋ランキングのような、シャードに散らばったデータを集約しサマリーを作るバッチ系のもの。
- master情報とJOINしている箇所をバラして、クエリを分離するもの。
特に3つ目はクエリのバリエーションも多く、SQLの実行計画を見ながらクエリのチューニング、ロジック自体の見直しも行いました。
Phase5 書き込みをシャードDBのみに向ける
Phase3で対応した箇所を粛々と修正しました。
また、シャーディング対応と平行して定期リリースの開発も進んでいるため、関連箇所の修正漏れがないように注意を払う必要がありました。
Phase6 不要なレコードを削除する
最初に全てのデータをミラーリングしているため、本来不要なレコードが残っている想定でした。
こちらを削除するタスクも計画していましたが、パーティショニング方式に切り替えたため、タスクはスキップすることができました。
シャーディングでの課題
前述の通り、シャーディングするとmaster系テーブルとのJOINができなくなります。
その際、特に本棚の連載マンガ一覧を返すAPIが悩ましい所でした。
本棚の連載マンガ一覧について
LINEマンガでは、出版社のコンテンツ、LINEマンガオリジナルのコンテンツ、一般の作家が投稿するインディーズマンガを「連載マンガ」として扱っています。
これらはお気に入り登録することで、LINEマンガのLINE公式アカウントから作品の更新通知を受け取る事が可能になります。
このお気に入り登録したマンガを一覧で見れるのが本棚機能です。
余談ですが、LINEマンガアプリにはDark Modeが実装されており(*3)、目に優しいUIでお楽しみいただけます。
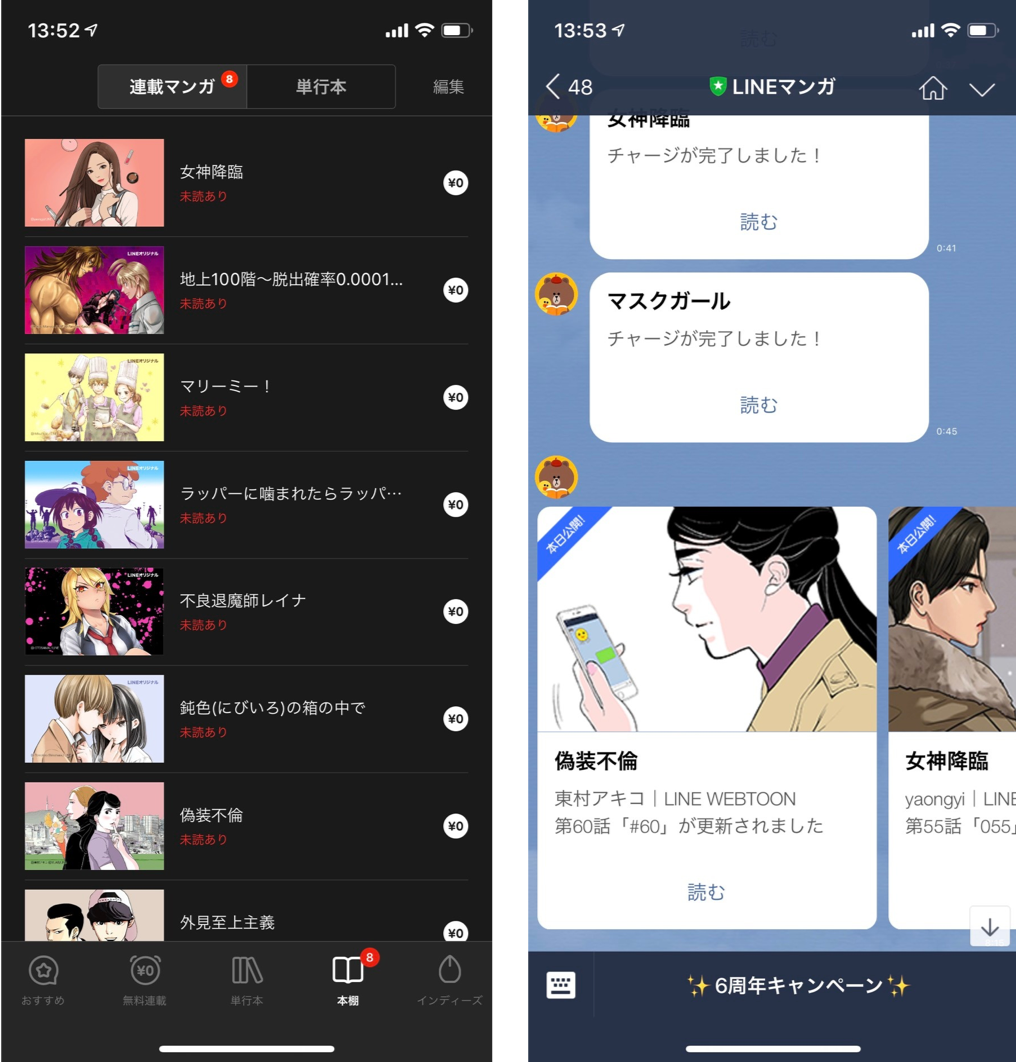
本棚の悩ましい仕様
本棚では更新されたものを探しやすいように、最新話が未読のものを上に表示しています。
今までは、お気に入りしているマンガ、マンガの最新話、最新話の閲覧履歴を全てJOINして並べ替えるという実装をしていましたが、シャーディングによってマンガの最新話がJOINできなくなりました。
並べ替えの要件が「最新話が未読のもの」である以上、どうにかロジックでカバーする必要があります。
対応したこと
JOINができないため、シャーディングされたテーブルと、既存DBからそれぞれSELECTしなければなりません。
最新話すべてを都度DBから参照するのは、負荷の観点から望ましくない事は予想されていました。
そこで、最新話のデータをRedisに保存し、HMSET()/HMGET()でやり取りするロジックに修正しました。
擬似コード
sub set {
my $redis_key = 'subscription';
my @products;
my $productA = {
id => 'Z0000000',
name => 'ハードボイルド園児 宇宙くん',
author => '福星英春',
};
push @products, $productA->{id} => JSON::XS::encode_json($productA);
my $productB = {
id => 'Z0000002',
name => 'マリーミー!',
author => '夕希実久',
};
push @products, $productB->{id} => JSON::XS::encode_json($productB);
$redis->hmset($redis_key, @products);
}
sub get {
my $redis_key = 'subscription';
my @fields = ($productA->{id}, $productB->{id});
return [ map { JSON::XS::decode_json($_) } grep { $_ } @{$redis->hmget($redis_key, @fields)} ];
}jsonをエンコード, デコードするコストはかかりますが、都度データベースを参照するよりかは遥かに高速です。
また、benchmarkをとったところCache::Memcached::Fastのget_multi()/set_multi()を利用した実装と比べて約2倍の速度が出たため、今回はRedisを採用しました。
終わりに
シャーディングを行ったことで既存DBの容量と負荷は激減し、APIのレスポンスタイムが以前よりも改善されました。
これでユーザーが増えても快適に使ってもらうことができそうです。ぜひLINEマンガでお気に入りのマンガをたくさん見つけてください。
LINEマンガは電子コミックサービスの圧倒的なNo.1を目指しています。
サーバーサイドエンジニアも絶賛募集中です。
どんどんスケールアウトしていくサービスを一緒に楽しみましょう!
https://linecorp.com/ja/career/position/829
*1 https://linecorp.com/ja/pr/news/ja/2019/2691
*2 https://www.appannie.com/jp/insights/app-annie-news/top-publisher-app-rankings-japan-2018/