
はじめに
こんにちは、データベース室の小田です。
今回はLINEマンガのデータベースをシャーディングした作業について、サーバエンジニア編とデータベースエンジニア編に分けてご紹介したいと思います。
本エントリでは、シャーディングに至った経緯、データベースエンジニア側で検討したことについて書いていこうと思います。
シャーディングに至った経緯
サービスを引継ぐ
前段として少し昔の話をします。私がLINEマンガの担当データベースエンジニアとなったのは、2018年2月中旬のことでした。
LINEマンガのサービス開始が、2013年4月9日だということですので、ちょうど5周年を迎える直前ですね。前任者からは、いいタイミングだからということで、一緒に移行作業を実施してからサービスを受け継ぎました。
- この時の移行作業における主たる目的
- 保守切れサーバの排除
- データ増加への一時的な対応
- パフォーマンス面の改善
- 副なる目的
- これから担当となる私へのサービス引継ぎの一環
というわけで、私が引継ぎをした2018年2月の中旬時点で、
- as-is : NVMe-SSD 2.6TB/3.0TB 6台 (マスター 1台、参照専用 4台、バックアップ専用 1台)
- to-be : NVMe-SSD 2.6TB/6.0TB 6台 (マスター 1台、参照専用 4台、バックアップ専用 1台)
となっていました。
余談ですが、この時にもサービスの成長を見越してシャーディングを打診していました。ただ、諸々の事情(*1)により、上記の通りスケールアップのみの対応をしています。
サービスの成長速度に気付かされる
2018年10月。LINEマンガの担当として、だいぶ慣れてきた頃でした。
きっかけは、NAVER WEBTOONの無料ウェブマンガサービス「XOY」との統合による人気作の移籍と、全話無料キャンペーンによるアクティブユーザの急増でした。下のグラフは、参照専用機のレプリケーション遅延のグラフです。
x軸が時間経過、y軸が遅延時間を表し、時間の経過と共に遅延時間が増えています。
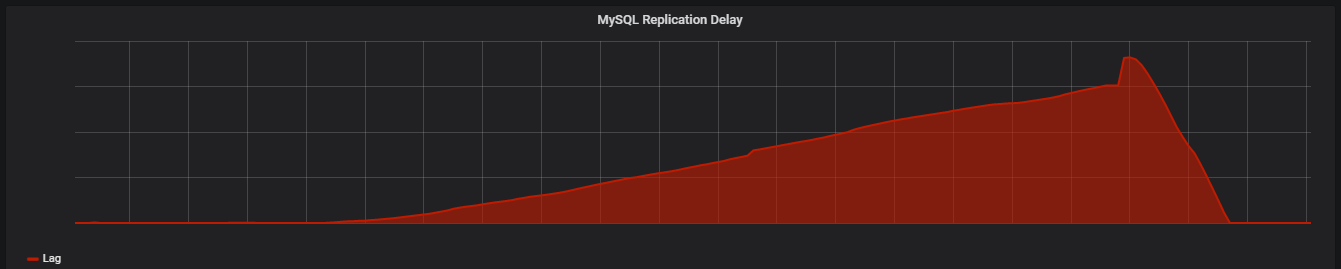
レプリケーション遅延は、不適切な実装が原因で発生することが多く、当時もそういったものがないか探しました。
ただ、きっかけはアクティブユーザの増加であって、不適切な実装の修正をすれば解決するような問題ではありませんでした。
調査時は、バイナリログのローテーション速度の変化などから、更新量が異常に増加していることに気が付きました。
LINEマンガでは、max_binlog_size=1Gで設定していたのですが、10分に1回のローテーション頻度となっていました。
前日のピーク時が40分に1回のローテーション頻度だったので、当時のアクティブユーザがかなり多かったことが分かります。
問題解決には、下記設定の変更を行いました。
- as-is : innodb_flush_log_at_trx_commit = 1
- to-be : innodb_flush_log_at_trx_commit = 2
後日追加の調査で判明したのは、データの増加速度が想定を超えていたことと残りディスク容量の問題でした。
引き継いだ当初2.6TBだったディスク使用量が、8ヶ月後の2018年10月には、4.6TBに達していたのです。
試算では、残り6ヶ月ほどでディスクフルとなることが判明したのです。
サービスの成長に置いて行かれない為のシャーディング
表面化した問題の整理
LINEマンガのMySQLが抱える問題の整理
- キャンペーンによる一時的なアクティブユーザの急増で、レプリケーション遅延が発生した
- 今後のユーザ増加で、同様の問題が想定される
- キャンペーンやプロモーションで再度同じ問題が発生する可能性がある
- 現状の増加量であっても半年持たない残りディスク容量
- 問題1に対する恒久対策をとる時間として足りない可能性がある
- 現行サーバ(NVMe-SSD6TB)が事実上の最高スペック
LINEマンガの体制が抱える問題の整理
- サービス統合と、キャンペーンによってユーザの利用に影響を与えてしまった
- サービス統合とキャンペーンの情報が前もってデータベースエンジニアに共有されていなかった
- 事前の検証ができない
- 問題発生時に原因の特定/対策に時間が掛かる
- サービス統合とキャンペーンの情報が前もってデータベースエンジニアに共有されていなかった
表面化した問題への対策
レプリケーション遅延とディスク容量問題。そのどちらも、書き込み量の増加が根本です。以前から話にあがっていたシャーディングについて、具体的に考える必要性が出てきました。
しかし、今までもシャーディングを検討して断念してきただけあって、全データを水平にシャーディングすることは困難でした。
そこで、レプリケーション遅延時に更新量が増加していた特定テーブルを中核に、機能的に取り出せないかをサーバーサイドエンジニアと検討しました(垂直シャーディング)。検討に当たって、performance_schema.events_statements_summary_by_digestから該当テーブルに対するクエリを抜き出し、サーバーサイドエンジニアに提供しました。
そして、実現性の有無を検討して頂きました。
LINEマンガのMySQLが抱える問題への対策
検討の結果、対象5テーブルをメインMySQLから取り出すこととなりました。
これらテーブルは、すべてをあわせると3TBほどあり、一番大きなテーブルで2TBもありました。
当然ですが、INSERTの性能劣化もあり、対象テーブルをさらに水平にシャーディングすることも検討しました。
対象テーブルはすべてユーザのログデータであり、ユーザID(member_id)で8個にシャーディングすることとなりました。
- $DB_SHARD_HASHSLOT = 65536
- crc32(member_id) % $DB_SHARD_HASHSLOT
- shard1 : 00000 - 08191
- shard2 : 08192 - 16383
- shard3 : 16384 - 24575
- shard4 : 24576 - 32767
- shard5 : 32768 - 40959
- shard6 : 40960 - 49151
- shard7 : 49152 - 57343
- shard8 : 57344 - 65535
そして、これらを実現する為にまず、喫緊の課題であるところのディスク容量の確保に取り組みました。
具体的には、現在は未使用となったテーブルの削除を実施しました。
- 未使用のテーブルの調査
- 未使用テーブルの算出には、下記2テーブルを使用してレイテンシーが0のものを対象としました(*2)
- performance_schema.table_io_waits_summary_by_tableperformance_schema.file_summary_by_instance
- 未使用テーブルの算出には、下記2テーブルを使用してレイテンシーが0のものを対象としました(*2)
- 永続バックアップを取得して、不測の事態に備える
- 未使用テーブルの削除
- 一時対応でテーブル名を変更して、影響がないことを確認するinnodb_buffer_pool_dump_now で影響が出ない状態であることを確認してテーブルを削除する
この対応によって、ディスク容量を500GBほど確保することが出来(下グラフ参照)、5テーブルの移行に十分な時間が出来ました。

LINEマンガの体制が抱える問題への整理
この件についてはシンプルですが、新規実装やプロモーション前などには、サーバーサイドへの事前の情報共有を徹底してもらうようにしました。
これによって、新規実装をする場合は事前に相談してもらって問題を排除できるようになりました。
また、デプロイタイミングでは、リアルタイムでモニタリングを実施し、デプロイ前後での差異などにも気を配っています。
直近では、[花樣年華 Pt.0<SAVE ME>]の掲載が始まりましたが、事前の共有をしてもらったので、あらかじめ参照専用機を追加するなどの対応が取れました。
シャーディング案検討
シャーディングに至った経緯を書いてきましたが、ここでは実際に検討した内容を書いていきます。
詳細は下に書いていきますが、まずは、検討した内容についてまとめたテーブルをご覧ください。

ダブルライトによるシャーディング環境への段階移行
移行案1詳細
- 5テーブルを対象にメインMySQLから移行
- 対象テーブルに対し、ユーザID(member_id)による8分割のシャーディングを実施
- シャーディングルールは、計算式の結果がどのレンジに属するかで決定する
- 計算式:crc32(member_id) % 65536
- 既存環境への配慮と作業の上での利点から中間MySQLを設置
- MySQL5.7から5.6にロールバックする際の問題への対策
- 現行のMySQL5.6では、binlogのAnonymous_gtid_log_eventをパースで出来ず、ロールバック出来なくなる為
- 全作業が終わった時のバックアップとしての役割を期待
- レプリケーション開始時に、一斉にシャード環境8台へのバイナリログ転送を実施してしまうことへの対策
- 対象テーブルのみ同期する為にレプリケーションフィルターを使用
- replicate-do-table=d1.t1
- replicate-do-table=d1.t2
- replicate-do-table=d1.t3
- replicate-do-table=d1.t4
- replicate-do-table=d1.t5
- MySQL5.7から5.6にロールバックする際の問題への対策
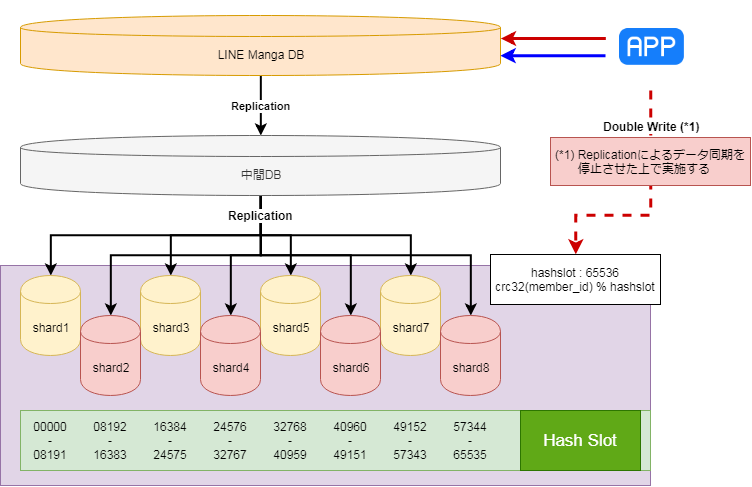
- 切り替えは段階的に実施する
- 1回目のメンテ
- MySQLのレプリケーションによる同期を停止
- 代わりにダブルライトを実装
- 2回目(デプロイのみ)
- 参照クエリをシャード環境に向ける
- 3回目(デプロイのみ)
- ダブルライト実装をはがす
- 事後作業
- 不要データの削除
- メインMySQLの5テーブルに対して、DROP TABLE文を実施
- 各シャードの自シャード以外のデータを対象に、DELETE文の実施
- 不要データの削除
- 1回目のメンテ
不採用理由
- 段階的移行することのコストの高さ
- 段階ごとのソースコードが存在し管理が煩雑になる
- ダブルライト中は書き込みを2度行うので、ユーザレスポンスに影響が出る
- 段階ごとの問題発生リスクを都度抱えることとなる
- 移行期間の長期化
- 移行後に不要データを削除するコストの高さ
- 各シャードの自シャード以外のデータの削除に時間が掛かる
- 数十億のレコードの8分の7をサービス影響なく削除する必要性
- 削除だけではibdファイルのサイズは変わらず、ALTER TABLE文などの発行が必要になる
- 各シャードの自シャード以外のデータの削除に時間が掛かる
生成カラムとレンジパーティショニングによるシャーディング環境への移行
移行案2詳細
- 5テーブルを対象にメインMySQLから移行
- 対象テーブルに対し、ユーザID(member_id)による8分割のシャーディングを実施
- シャーディングルールは、計算式の結果がどのレンジに属するかで決定する
- 計算式:crc32(member_id) % 65536
- 既存環境への配慮と作業の上での利点から中間MySQLを設置
- MySQL5.7から5.6にロールバックする際の問題への対策
- 現行のMySQL5.6では、binlogのAnonymous_gtid_log_eventをパースで出来ず、ロールバック出来なくなる為
- 全作業が終わった時のバックアップとしての役割を期待
- 全作業が終わった時のバックアップとしての役割を期待
- レプリケーション開始時に、一斉にシャード環境8台へのバイナリログ転送を実施してしまうことへの対策
- 対象テーブルのみ同期する為にレプリケーションフィルターを使用
- replicate-do-table=d1.t1
- replicate-do-table=d1.t2
- replicate-do-table=d1.t3
- replicate-do-table=d1.t4
- replicate-do-table=d1.t5
- ALTER TABLE文にて、各テーブルに以下変更を実施
- ALTER TABLE t1
ADD `shard_hash` int(11) GENERATED ALWAYS AS ((crc32(`member_id`) % 65536)) STORED NOT NULL,
DROP PRIMARY KEY,
ADD PRIMARY KEY(c1, shard_hash);
- ALTER TABLE t1
- MySQL5.7から5.6にロールバックする際の問題への対策
- シャード環境
- ALTER TABLE文にて、各テーブルに以下変更を実施 (*3)
- ALTER TABLE t1
PARTITION BY RANGE (shard_hash)
(
PARTITION shard1 VALUES LESS THAN (8192) ENGINE = InnoDB,
PARTITION shard2 VALUES LESS THAN (16384) ENGINE = InnoDB,
PARTITION shard3 VALUES LESS THAN (24576) ENGINE = InnoDB,
PARTITION shard4 VALUES LESS THAN (32768) ENGINE = InnoDB,
PARTITION shard5 VALUES LESS THAN (40960) ENGINE = InnoDB,
PARTITION shard6 VALUES LESS THAN (49152) ENGINE = InnoDB,
PARTITION shard7 VALUES LESS THAN (57344) ENGINE = InnoDB,
PARTITION shard8 VALUES LESS THAN (65536) ENGINE = InnoDB,
PARTITION shardx VALUES LESS THAN (99999) ENGINE = InnoDB
);
- ALTER TABLE t1
- ALTER TABLE文にて、各テーブルに以下変更を実施 (*3)
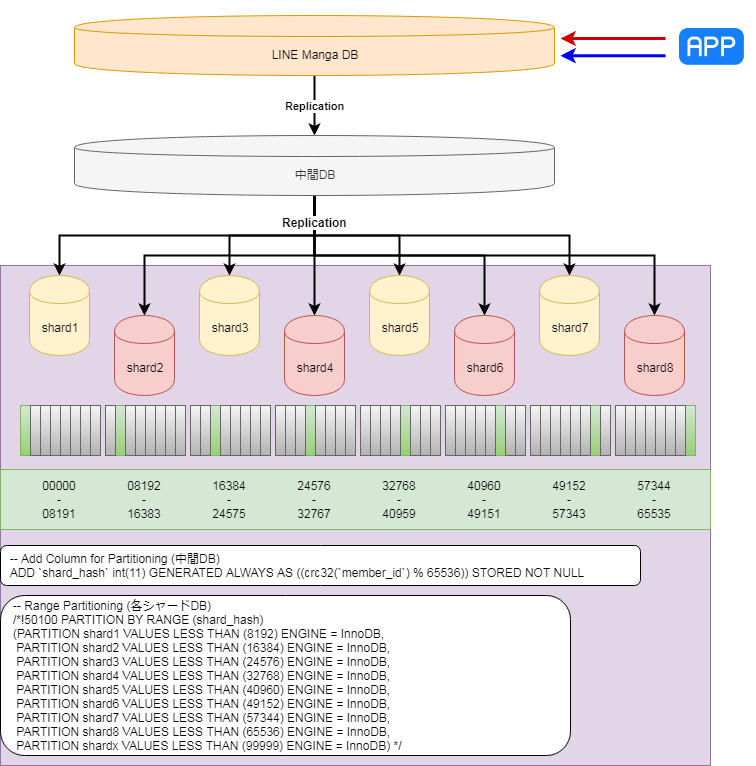
- 切り替えは1度に実施する
- 1回目のメンテ
- MySQLのレプリケーションによる同期を停止
- EXCHANGE PARTITION文で必要なパーティション(シャードデータ)だけ取り出す
- 不要データの削除
- メインMySQLの5テーブルに対して、DROP TABLE文を実施
- パーティションテーブルに対して、DROP TABLE文を実施
- 事後作業
- 主キーからshard_hashを抜く
- 各シャードMySQLに追加しているshard_hashカラムを削除する
- 1回目のメンテ
不採用理由
- 想定した通りにパーティショニングされなかった為、不採用としました
- LINEマンガの環境では、バイナリログフォーマットにMIXEDを採用していました
- その結果、ローベースとなってレプリケーションされてしまい、ストアド生成カラムが反応しなかったのです
- 対策としては、主キーをユニークキーに変更して、仮想生成カラムを使用すればよかった
- 仮想生成カラムは主キーには組み込めない制約があります
- そして、パーティショニングには主キーを用いるか、主キーのないテーブルのユニークキーを用いる制約があります
- 通常の環境では、すべての主キーをユニークキーとして仮想生成カラムとあわせて実装すると良いでしょう
- ただし、私がこのことに気が付いたのは、この次の移行案を採用した後でした
追加したカラムとレンジパーティショニングによるシャーディング環境への移行
移行案3詳細
- 5テーブルを対象にメインMySQLから移行
- 対象テーブルに対し、ユーザID(member_id)による8分割のシャーディングを実施
- シャーディングルールは、計算式の結果がどのレンジに属するかで決定する
- 計算式:crc32(member_id) % 65536
- 既存環境への配慮と作業の上での利点から中間MySQLを設置
- MySQL5.7から5.6にロールバックする際の問題への対策
- 現行のMySQL5.6では、binlogのAnonymous_gtid_log_eventをパースで出来ず、ロールバック出来なくなる為
- 全作業が終わった時のバックアップとしての役割を期待
- レプリケーション開始時に、一斉にシャード環境8台へのバイナリログ転送を実施してしまうことへの対策
- 対象テーブルのみ同期する為にレプリケーションフィルターを使用
- replicate-do-table=d1.t1
- replicate-do-table=d1.t2
- replicate-do-table=d1.t3
- replicate-do-table=d1.t4
- replicate-do-table=d1.t5
- ALTER TABLE文にて、各テーブルに以下変更を実施
- ALTER TABLE t1 ADD shard_hash INT DEFAULT 65536,
DROP PRIMARY KEY,
ADD PRIMARY KEY(c1, shard_hash);
- ALTER TABLE t1 ADD shard_hash INT DEFAULT 65536,
- shard_hashを定期的に更新
- UPDATE t1
SET shard_hash = crc32(member_id) mod 65536
WHERE created_on > @前回更新時間;
- UPDATE t1
- MySQL5.7から5.6にロールバックする際の問題への対策
- シャード環境
- ALTER TABLE文にて、各テーブルに以下変更を実施
- ALTER TABLE t1
PARTITION BY RANGE (shard_hash)
(
PARTITION shard1 VALUES LESS THAN (8192) ENGINE = InnoDB,
PARTITION shard2 VALUES LESS THAN (16384) ENGINE = InnoDB,
PARTITION shard3 VALUES LESS THAN (24576) ENGINE = InnoDB,
PARTITION shard4 VALUES LESS THAN (32768) ENGINE = InnoDB,
PARTITION shard5 VALUES LESS THAN (40960) ENGINE = InnoDB,
PARTITION shard6 VALUES LESS THAN (49152) ENGINE = InnoDB,
PARTITION shard7 VALUES LESS THAN (57344) ENGINE = InnoDB,
PARTITION shard8 VALUES LESS THAN (65536) ENGINE = InnoDB,
PARTITION shardx VALUES LESS THAN (99999) ENGINE = InnoDB
);
- ALTER TABLE t1
- ALTER TABLE文にて、各テーブルに以下変更を実施
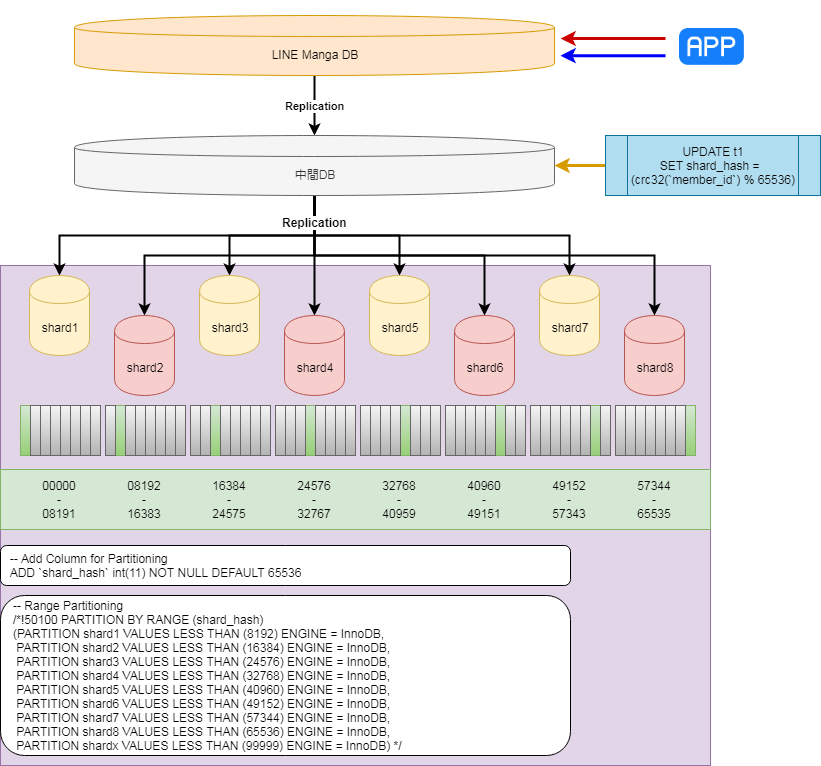
- 切り替えは1度に実施する
- 1回目のメンテ
- MySQLのレプリケーションによる同期を停止
- EXCHANGE PARTITION文で必要なパーティション(シャードデータ)だけ取り出す
- 不要データの削除
- メインMySQLの5テーブルに対して、DROP TABLE文を実施
- パーティションテーブルに対して、DROP TABLE文を実施
- 事後作業
- 主キーからshard_hashを抜く
- 各シャードMySQLに追加しているshard_hashカラムを削除する
- 1回目のメンテ
採用理由
- 想定した通りにパーティショニングされる
- 不要なデータの削除が、メンテナンス時間に実施可能
- メンテナンス時に発生する作業が、データ量に依存しない作業のみ
- レプリケーション停止
- EXCHANGE PARTITION文の実行
- DROP TABLE文の実行
- 事後作業のPK変更とカラム削除はデータ量に依存するが、オンラインDDLで実施可能
移行案3によるシャーディングの実施
データサイズに依存する準備はとにかく時間が掛かる
データの移行
データの移行は、中間MySQLで既存環境のフルバックアップ1TB(5TBのMySQLデータ)を展開するところからです。
Xtrabackupで取得されたもので、リストアには4時間ほど掛かりました。
リストア完了後、対象テーブル以外のテーブルを削除します。
削除対象が大体2TBほどだったので、3TBの中間MySQLとなりました。
そこからレプリケーション遅延の回復を行います。
レプリケーションフィルターを利用して、対象5テーブルのみを同期します。
バックアップ転送時間なども含めると、基本となる中間MySQLの構築にはほぼ1日掛かってしまいました。
パーティショニングキーの実装と更新
各テーブルに、パーティショニングキーとなるshard_hashカラムを追加し、主キーに構成していきます。
ALTER TABLE文を叩いて放置する日々が続き、完了日時の想定をサーバーサイドエンジニアに共有し続ける日々になります。
一週間に渡るshard_hashカラムの追加作業を終え、shard_hash値の更新作業に移ります。
初回は、100億レコードほどの全件更新でした。こちらにも1週間ほど掛かりましたが、以降は定期更新を実装しています。
member_idの変更はないサービス設計だった為(*4)、常に新しいレコードを更新し続ければ良かったのは非常に楽でした。
ここまで実施したタイミングでバックアップ(3TBのMySQLデータ)を取得し、シャード環境の構築に取り掛かりました。
パーティショニング
次に、前段で取得したバックアップを各シャードMySQLにリストアしました。
そしてパーティショニングです。パーティショニングは今回の作業でもっとも時間が掛かったポイントです。
一番大きなテーブルが2TBほどだったのですが、ALTER TABLE文の完了に5日も掛かりました。
この間、レプリケーションを停止していたので、その後の遅延復帰にも多くの時間が掛かりました。
この工程で、当初予定していたメンテナンス日に間に合わないことが判明し、事業部に調整して頂くこととなりました。
メンテナンス作業当日
メンテナンス作業
メンテナンス作業は、データサイズに依存しない作業のみで構成することが大切です。
また、当日は複数環境で同時に作業を実施する為、すべてコピー&ペーストで完了できるような手順にすることを心掛けました。
その甲斐あって、当日作業はスケジュールどおりに進行できました。
メンテナンス開始から、データベース作業、アプリケーションのデプロイやQA作業に至るまで、問題はありませんでした。
メンテナンス終了直後の高負荷
メンテナンス終了直後、アプリが非常に重くなり、多くのユーザにご迷惑をお掛けしてしまいました。
原因は、キャッシュの実装ミスによるもので、MySQLサーバが高負荷状況に陥っていました。
特定のクエリが大量に実行されていた為、サーバーエンジニアに共有して対応して頂きました。
メンテナンス作業結果
メンテナンス前後の指標から
1日あたりのデータ増加量は8分割され、今後6年余りはデータの増加に耐えうる環境となりました。
また、ユーザが増加し続けたとしても、シャーディング機能の実装は終わっていますので、比較的簡単にリシャードが行える環境となりました。
- 8シャードから16シャードに変更する場合
- アプリケーションは、シャードの計算式を8分割から16分割に変更
- データベースは、各シャードのデータをshard_hashのレンジで2分割してデータ移行
また、サーバ負荷も大きく改善されました。
今回の移行で、JOINクエリが分割された為、多くのスロークエリがなくなりました。
ディスクサイズ
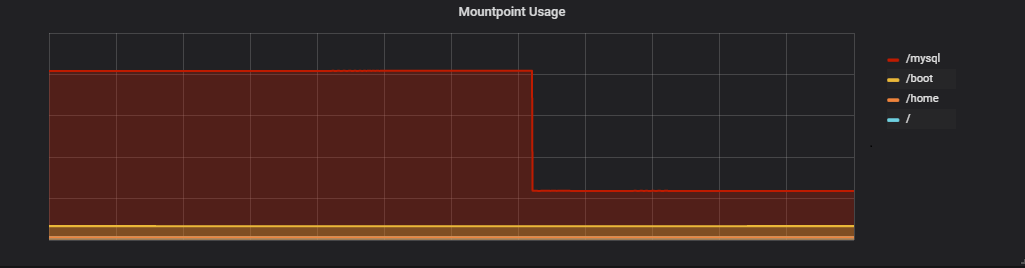
CPU使用率

ディスクIO

さいごに
LINEマンガのサービスは、今回の対応が終わったことでさらに加速していくでしょう。
データベースエンジニアは、サービスにどれだけ入っていけるかが時に重要になりますが、今回はその最たる作業だったかと思います。
進化し続けるサービスにおいていかれないように一層コミットしていきますので、今後とも、LINEマンガをよろしくお願いします!
というわけで今回は、LINEマンガのシャーディングをトピックにお話させていただきました。
いかがだったでしょうか。
LINEでは、他にもさまざまなサービスを提供していますが、その多くのサービスの裏側で私たちデータベースエンジニアも活躍しています。
一緒に働いてくれる方を募集していますので、もし興味がある方がいらっしゃいましたら、お気軽にご応募ください。
https://linecorp.com/ja/career/position/23
では、またの機会に!
注釈
- (*1)LINEマンガの大規模アップデートを目前に控え、開発リソースが不足した為
- (*2)注意点として、外部結合していてレコードが常に0件だったりするとレインテンシーも0になってしまいます。たとえば、実装だけが残っていて、定義だけ使ってしまっている場合などです。
- (*3)Range Partitionを活用した理由は、以下の3点です。
- 必要なデータの取り出しがExchange Partition文でデータ容量に依存することなく可能
- 不要なデータの削除が、Exchange Partition文実行後のテーブルに対するDROP文でまとめて実施可能
- Exchange Partition文で取り出したデータは、元テーブルのデータの1/8のサイズのibdファイルである為、ibdファイルのシュリンクが不要 - (*4)実際には、CS対応などでmember_id間のデータ移行をしていたことがメンテナンス直後に発覚し、対応しています。