
LINEの開発組織のそれぞれの部門やプロジェクトについて、その役割や体制、技術スタック、今後の課題やロードマップなどを具体的に紹介していく「Team & Project」シリーズ。今回は、LINEの機械学習を活用したサービス開発を担うMachine Learningチームを紹介します。Machine Learningチームのそれぞれのポジションで開発を進めている4名(菊地悠、齋藤祐樹、櫻打彬夫、境美樹)に話を聞きました。

―― まず、自己紹介をお願いします。
菊地:2017年10月にプロジェクトマネージャーとして入社しました。前職は携帯電話キャリアでソフトウェア畑の研究系業務からスタートし、転職直前は位置情報系サービスの分析・開発に携わっていました。現在はチームのマネージャーとして、プロジェクトや業務の管理を行なっています。
齋藤:前の会社では広告のCTR予測やショッピングサイトのランキングシステムのアルゴリズムの作成に携わっていました。LINEには2018年2月に中途入社し、現在は、Machine Learning エンジニアとして機械学習モデルの開発および事業導入を担当しています。
櫻打: LINEに2019年6月に中途入社し、Machine Learning Infrastructure エンジニアとして機械学習のための基盤システムの開発と運用を担当しています。前職には博士新卒で入社し、広告の配信やCTR予測に携わっていました。
境:私は、リファラルで2020年3月に中途入社しました。
LINEアプリのトークリスト最上部にある「Smart Channel」(スマートチャンネル)に露出する各種サービスのレコメンドや、LINEファミリーサービスのレコメンドの新規導入や改善のプロジェクトマネジメント及び、チーム内のMLOps導入の推進などの業務を担当しています。
―― みなさんがLINEに入った理由を教えてください。
菊地:私にとっては初めての転職だったので、転職者に対しての受容性があるかどうかを少し気にしていましたが、当時はチーム全員が中途入社でここなら大丈夫だ、と思いました。前職で数年間、アメリカに海外勤務していたのですが、そこでは多様性のあるメンバーと一緒に働くことがとても楽しかったです。LINEには色々な会社からの転職された方や、会社の合併などを経て様々なバックグラウンドとカルチャーの人が混ざった環境があり、多様性があって面白そうだと思い入社を決めました。
齋藤:前の会社では広告のCTR予測やショッピングサイトのランキングシステムのアルゴリズムの作成に携わっていたのですが、同じような形で、ユーザにサービスを提供している会社が良いと思い探していました。 LINEが扱っているデータの大きさ、その種類の多さに魅力を感じて転職を決めました。
櫻打:私の場合は、違うカルチャーの会社で仕事をしてみたくなり転職活動を始めました。LINEに決めたのは、一緒に選考を進めていた他社の中で、最も技術力の高さを感じたのが一番の理由です。また、チーム自体の拡大やシステムの移行を進めている時期というのも面白そうだと思いました。
境: 私は前職では研究職のマネージャをしていました。ユーザから遠い位置だったため、成果として作ったプロダクトがユーザに届くまでに非常に長い時間が必要であったり、実務データでの分析が限定的である点から転職を検討し始めました。。前職でもML関連のプロダクト開発にて開発管理などマネジメント業務を行っていたため、LINEでそのスキルを活かせると考えたのがLINEを受けたきっかけです。また、優秀なエンジニアとプロダクト開発を行っていきたいと思ったからです。

――trong>LINEで働くやりがいを教えてください。
菊地:LINEは、自分がやりたいと思ったら企画サイドやシステム開発など、どちらにも関われる自由度があります。またチームのエンジニアがとても優秀で、案件が良ければ何でも作る、という気概があります。
多様性と自由度の裏返しとして、まとめるのは難しく時間がかかることもありますが、一方で議論を経てまとまったものは良いものであるということも多く、やりがいに繋がっています。
齋藤:技術の選択の幅が広く、制約が少ない中で仕事ができることができます。チームメンバーのスキルも高く、議論を通じて参考になる意見やアドバイスをもらうことができます。すでに多くのユーザを持っているサービスが多いため、リリースした機能が多くのユーザに使ってもらうことができるのはやりがいになります。
櫻打:自由度や裁量が大きく、自己実現に近い形で仕事ができるのがやりがいです。
高い技術力や広い視野を持ったメンバーが多いのも刺激になっています。また、開発した内製ツールやAPIについて、利用者からのフィードバックがあるのもいいですね。
境:LINEという大きなサービスがあり、ユーザの行動ログを活用したMLプロダクトの開発に携われる点はとても面白いです。開発スパンも数ヶ月単位のものが多く、世に問う回数が多い点が良いですね。また、リリース後もMLモデルの改善活動を行うことができます。数字の動きを見ているのが好きだし、メンバーが頑張った結果としてビジネスに良い影響が出ていると純粋に嬉しいです。
サービスサイドとのやり取りが多く、コミュニケーションを取りながら、要望と現状でどこまで出来るかをすり合わせて要件に落とし込み実験・開発・リリースと進むと達成感があります。
―― チームの構成・役割などについて教えてください。
菊地:LINEでは数億ユーザを対象にしたレコメンドエンジンなど、大規模データを使った機械学習システムを開発運用しています。DSEセンターは2019年3月に発足し、データ活用、データのガバナンスと活用を推進、インフラ系システムおよびデータ関連の各種システムを開発管理する複数の組織から構成されています。
これらの組織が連携することでユーザのプライバシーを最大限守りながら、データによって新たな価値を生み出すために、様々な取り組みを進めています。
私たちのチームでは、データ活用を通して事業に貢献することを目指し、機械学習を用いたシステムを開発し、保守運用しながらエンジニアリングプロダクトを提供することを主な業務としています。
ML導入が社内に浸透していくにつれて、人員数も業務範囲も拡大傾向にある中、チームは主に4つのパートに分かれて開発を進めています。
具体的には、事業側や他チームとのハブになり仕様検討等を行うML Planning、共通機能の開発を行うML Development、各サービスへの導入を行うML Solution、サーバサイドの開発・運用を行うML Infrastructureです。
エンジニアに関しては、MLモデルの設計が得意な人、事業貢献やモデル改善に熱意がある人、アルゴリズムの高速化、システムの堅牢性やオペレーション効率化ができる人など、多様性で支えてきた面を体制面でもわかりやすく整理している最中で、事業系のMLを見る人、システム系のMLを見る人、ML系のインフラ支える人と全体まとめられるPMというチーム構成に移行中です。
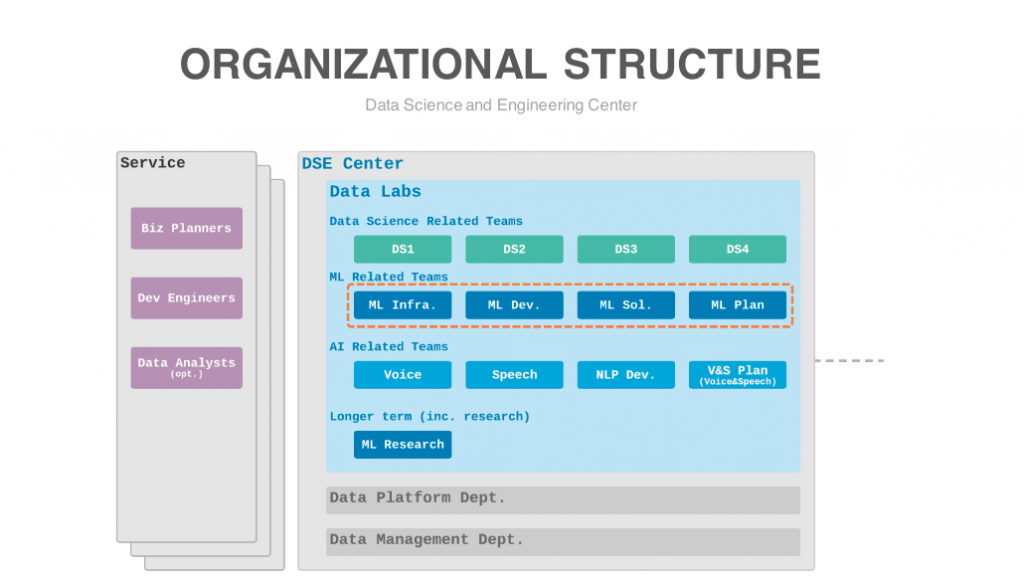
櫻打:ML Infrastructure(ML Infra.)は、現在は主務として私の他にマネージャーが1名と今年の新卒入社の方が1名、他に兼務の方を含め、計5名体制です。役割としては、機械学習エンジニアがモデリングに集中したり、他のシステムから機械学習を使いやすくする環境を提供することです。
具体的には、KubernetesやJupyterHub、MLflowといった基盤の運用から、内製ツールやAPIなどの開発まで幅広く行っています。
齋藤:ML Development(ML Dev.)は現在、私を含む6名体制で、サービス横断で利用することができるレコメンドエンジンとその基盤システムの開発をしています。たとえばあるサービスでレコメンデーションをしたいという要望があった場合、指針となるアルゴリズムとデータを与えコンピュータがデータを読み取ることで法則やパターンを見つけ出し、アルゴリズムをモデルとして発展させ、独自のレコメンドエンジンを開発します。
また、ML Solutioon(ML Sol.)は、私たちが作った堅牢な基盤システムの上で、色々なサービスに対して個別最適を測ったり、チューニングをかけたりして、機械学習を用いた事業応用と継続的改善を行なっています。
境: ML Planning(ML Plan)は、機械学習を活用したプロダクトやソリューションの企画・事業貢献が主な役割になります。様々なサービスの要望や共通化できそうな機能の抽出を行い、プロジェクトマネージャーとしてPlanを立て開発進行や導入進行をしています。
―― チームメンバーを紹介してください。
菊地:私たちのチームには、LINEで最初のMachine Learningエンジニアとして入社され、現在はフェローとして活躍されている方がいます。MLの数理面から大規模システムでの開発・オペレーションまでこなせるスーパーエンジニアで、LINE DEVELOPER DAY 2020でも「LINEではどのようにサービス横断でのデータ活用を実現しているのか」という内容で発表データ活用について発表しています。
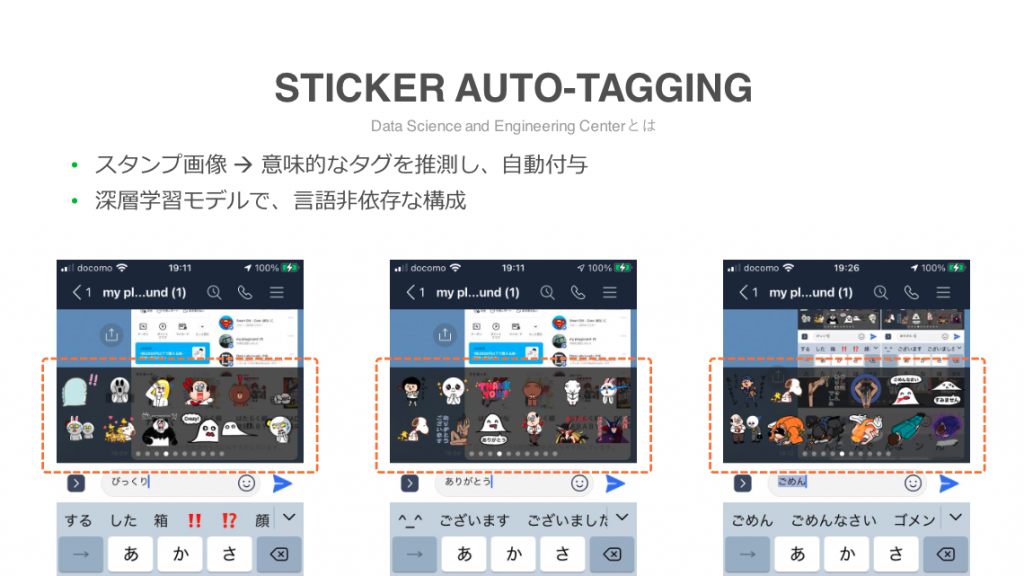
また、全世界で15万人ほどいる参加者のトップ20に入る成績を誇るKaggle GrandMasterのMachine Learningエンジニアもいます。
https://www.kaggle.com/haqishen
主に画像処理系のアルゴリズムに強く、業務においても画像を利用するLINEスタンプのオートサジェスト機能などのプロジェクトを牽引しています。
―― 利用技術・開発環境について教えてください。
菊地:データプラットフォームを扱うエンジニアとの協業が増えてきているので、インフラ系の仕事は増えると思います。MLの新規導入先はまだまだ残っていますが、導入済みサービスのモデル改善などは増加する傾向にありますね。
A/Bテストの基盤整備が済んでいる領域は、検証のサイクルが早くなったことで、深層学習系のMLモデルへ順次置き換えを進めています。
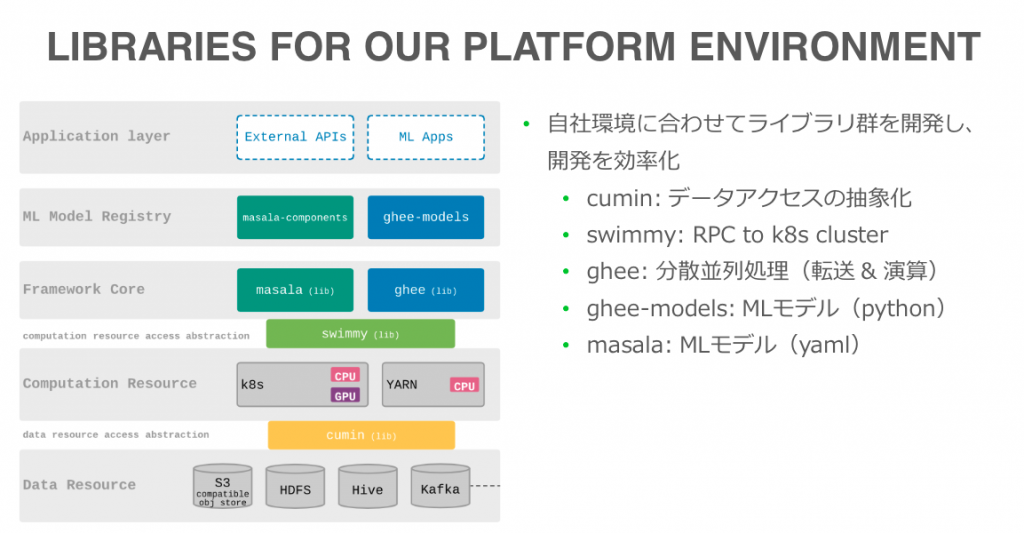
齋藤:データストアとしてHDFS, Hive、モデルの学習にはKubernetes上のGPUノードを用いています。ライブラリに関しては基本的に自由ですが、モデルの学習についてはpytorchを用いることが多いですね。
櫻打:インフラでは、KubernetesをはじめとしてCNCFプロジェクトのものが多く使われています。ジョブ管理もAzkabanからArgoに移行しようとしている最中です。また、別チームが運用しているHadoopクラスタやオブジェクトストレージ、DBaaSなどを利用しています。
開発言語については、機械学習向けライブラリはPython、Web APIはGo、Spark UDFはScalaで書かれることが多いです。よほどマイナー言語でなければ許されるので、Rustでリマインダーツールを書いたこともあります。
境:プロダクトの開発にエンジニアとして参加すること自体はあまりないのですが、プロジェクトマネジメントを担当するメンバーは、何らかのエンジニアリング経験がある人がほとんどです。社内のエンジニア向けツールを利用して、SQLやPythonで簡易ダッシュボードとかを作ることもあります。
―― 今のチーム課題と課題解決に向けた取り組みについて教えてください。
菊地: 機械学習を用いたシステムを開発し、保守運用しながらエンジニアリングプロダクトを提供する中で、サービス個別に要望を聞いていくと、似通ったニーズや課題が出てきます。
エンジニアリング観点で考えると、1度開発したソリューションをその他のサービスでも使うことができれば、様々なメリットがあります。何かを作るときには、共通化ができるか、横展開ができるかを常に考え、開発効率や保守性を上げていくことが私たちの課題の一つです。
齋藤: DSEセンターが発足する以前、私たちのチームは色々な事業やサービスから業務を委託され、その業務毎に一人ずつ開発を担当していました。サービス毎に必要なオーダーメイドのレコメンドエンジンを作成していのたので、特定の人でないとそのサービスのレコメンドエンジンを作ることができない、「属人化」という課題を抱えていました。
また機械学習によるデータ活用の重要性が高まる中、私たちチームメンバーも人数が倍以上になり、現在、属人化されたタスクや業務を共通化するために、開発体制の改善や整備などを行なっています。
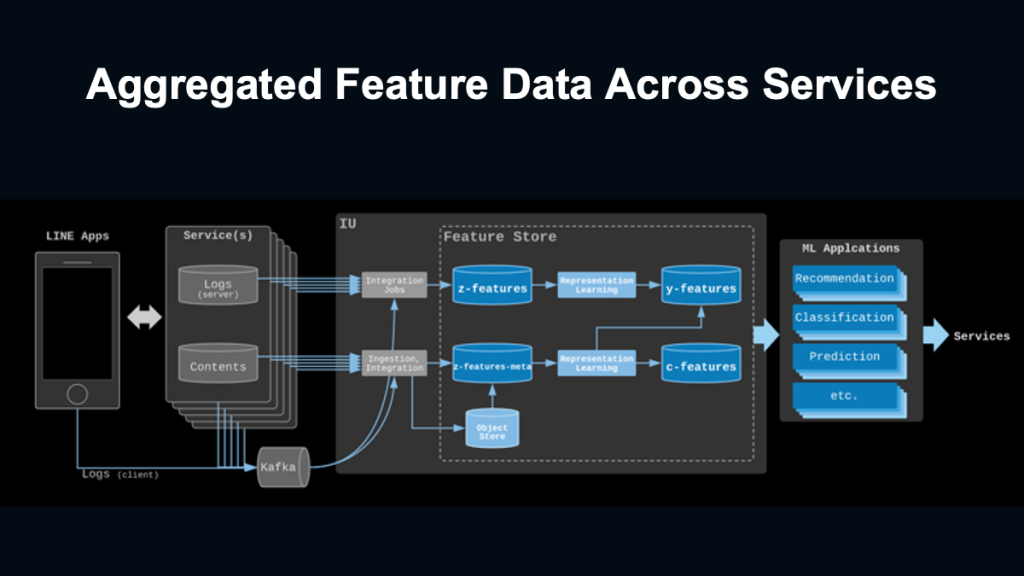
その一つの取り組みとして、特定のサービス向けではない、汎用的なレコメンドエンジンとその基盤を構築し、共通の基盤でレコメンドを行い、属人化をなくすことを進めています。
例えば、以下画像のような形で、LINE公式アカウントやタイムライン、OpenChat、LINE広告やLINE NEWS、LINE MUSICやLINEマンガなど、機械学習で共通して利用できるように様々なサービスのデータを一元管理し、共通のフォーマットで呼び出して、機械学習のモデルに入れることができるようにしています。
櫻打:私たちML Infra.は、社内に代替サービスがない頃からKubernetesやJupyterHubを運用しているため、運用コストや拡張性の問題を抱えています。また、現在はML インフラエンジニアが3名なので開発運用の標準化についての問題はそこまで大きくなのですが、チーム規模が大きくなっているので、課題感を持って標準化への取り組みを進めたいと思っています。
具体的には、Kubernetesの証明書更新や JupyterHub へのユーザ追加など、細かい運用対応を数多くあるサービス毎に対応していく必要があり、現在3名で運用するにはコストがかかり過ぎている状況です。さらに、GPUリソースの効率的な運用や古いストレージの容量問題があります。そこで、安定性や利便性を考慮しながら、別のチームが運用しているクラスタやサービスに移行を進めています
標準化についてはMLOpsを標榜し、既存システムのドキュメンテーション化や監視システムの統一など、まずは運用から取り組みをはじめています。新規開発するものについては、設計やテストなど、開発フローも標準化して行きたいと思っています。
境:事業側の開発者との仕事も多く、仕様を決めるために企画者ともコミュニケーションなど、プロジェクト進行についての課題はいろいろありますが、ML Planningのプロジェクトマネジメントの立場としては、リリース後のMachine Learningのモニタリング部分が少し弱い点に課題を感じています。
モデル構築やA/Bテストなど、リリースまでのモデル改善については、非常に粘り強くエンジニアの皆さんが実施してくれています。しかし、リリースした後、システム側のモニタリング以外の人的モニタリング体制がきちんと整っていません。改善の必要性を把握し、レコメンドの結果として、現時点でシステム側で取得できる以外のユーザの反応の計測など、モニタリングの体制を構築していく必要があります。
そこで私たちは、MLOpsの文脈に絡めて、リリース後のモニタリング自体をシステム化するなどの、取り組みを始めているところです。
―― 今後のロードマップを教えてください。
菊地:先ほどチームの構成・役割でもお話ししましたが、私たちのチームは多様性で支えてきた面を組織的に体制化している最中です。データの重要性、機械学習の役割や責任範囲がどんどん広がる中、チームメンバーも増え、組織も大きくなっています。少人数で見ることが出来る限度を超えてきている今、運用コストを減らし、作るものを共通化・システム化していくことが重要となってきています。
個別の事業からの要望を受けて開発をすすめることはこれまでもやってきましたし、これからも引き続き進めますが、開発したノウハウを「社内で広く横展開できるシステムとチーム体制」についても、改善に取り組んでいきます。
齋藤:LINE DEVELOPER DAY 2020で発表しましたが、近年の機械学習は、分類やリコメンデーションなどタスクの種別に関わらず、GPUを使った深層学習が主流となってきています。このため、大規模データを使った研究開発において、機械学習エンジニアは、Hadoop上のデータ処からKubernetesにおける計算リソース管理など、幅広い業務に携わる必要があります。特に大規模データをGPU上で処理する際には、データアクセス管理、データ転送、計算リソースの効率活用、分散学習などが課題となってきます。これらの課題を解決するために、開発した内部ツール群に、より精度の高いモデルを組み込んでいったり、モデルだけではなく損失関数を登録し再利用することが出来るようにしたりなど、今後、様々な拡充を行なっていきます。
参考:機械学習アプリケーションのための、大規模データを分散処理するライブラリ
櫻打:LINEの全社的な展望として、MLU(Machine Learning Universe)構想があり、機械学習のプラットフォームを統一し、機械学習のエンジニアやデータサイエンティストがより快適に素早く成果を出せる環境を作ることが出来るように、機械学習の民主化を進めようとしています。
Machine Learning Infrastructureとしては、やることはまだ具体的に決まっていませんが、機械学習エンジニアがモデリングにより集中し、他のシステムから機械学習をより使いやすくすることができればと思っています。
境:私たちは、先ほど課題でもお伝えした通り、モニタリングの文脈でそれらを統一的なシステムとしていくことを目標としています。異常検知など機械学習観点の技術も導入するチャレンジを進め、レコメンドエンジンの性能をより良いものにしていくために、レコメンド結果の分析を進めていく予定です。

―― 最後に、Machine Learningチームに興味を持ってくれた人にメッセージをお願いします。
齋藤:Machine Learning Developmentは、LINEのユーザ数、データ量に耐えうるレコメンドエンジンの開発をしています。そのため大規模データだからこそ発生する課題や制約がたくさんあります。これらの課題に挑戦したいという方をお待ちしています。
櫻打:Machine Learning Infrastructureは、その名前の通り、ややインフラに重きを置いたフルスタックの開発運用が求められていると思います。私自身、Webフロントエンドはあまり得意ではありませんが、Vue.jsの保守開発もしています。少しでも興味を持たれた方は、まずはエントリーをお待ちしています!
境:PjMは、サービス側との接点も多くLINEを作っている人たちと協業していくこともできます。また、優秀なエンジニアをサポートし機械学習プロダクトを構築していくプロセスを楽しむこともできるし、自身でエンジニアリングしたければそういうこともできたり、幅広いことに挑戦できるところが良さです。
興味のある方はぜひお待ちしています。
Machine Learningチームではメンバーを募集しています!
機械学習エンジニア / Data Scienceセンター
DevOpsエンジニア / 機械学習チーム / Data Scienceセンター
サーバーサイドエンジニア / 機械学習チーム / Data Scienceセンター
プロジェクトマネージャー / 機械学習チーム / Data Scienceセンター
プロダクトマネージャー / 機械学習チーム / Data Scienceセンター