
こんにちは、Data Platform室Data Engineering 1チームの徐です。
Data Platform室では、大規模なHadoopクラスタを運用し、データ収集、分析、活用するためのプラットフォームを提供しています。Data Engineering 1チームのミッションの一つは、様々なストレージからのdata ingestionシステムを構築、運用することです。
本記事では、バッチ処理でデータ収集を行うシステムの概要を説明した後に、LINEのセルフサービスツールであるFreyをご紹介します。
従来のバッチ処理システム
概要
典型的なバッチ処理システムは以下の様な特徴が挙げられます。
- バッチタスクを実行するには、スクリプトを許可してスケジューリング・エンジンに保存する
- ユーザー向けにツールやライブラリの備わった一般的なプログラミングフレームワークが用意されており、標準化されたスクリプト記述が可能で、管理も簡単にできる
- GitHubなどのバージョン管理ツールとも連携可能
下図に示しているのは、LINEで4年以上使われていたバッチ収集システムの第一世代です。
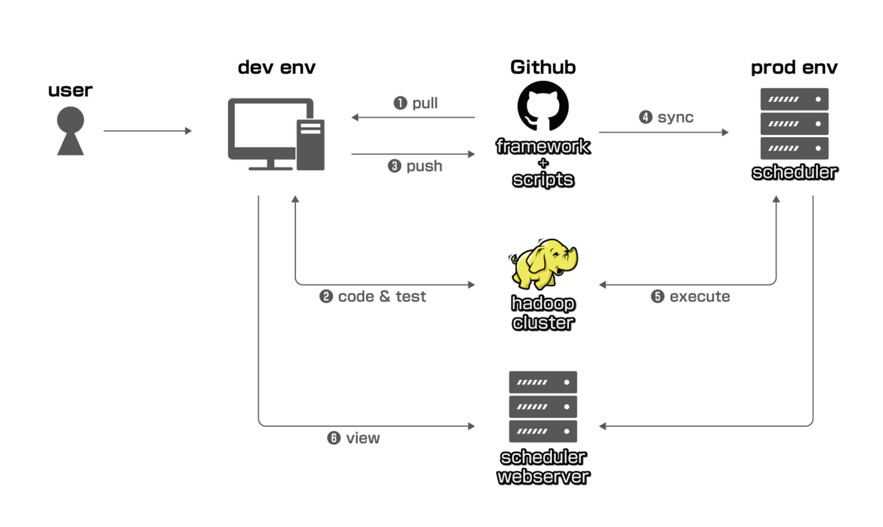
課題:
このシステムでもデータ収集のバッチ処理を実行・管理するという目的は果たせましたし、ユーザーとタスクの規模が小〜中程度であれば問題はありませんでした。しかし、LINEの全てのプロダクトまでスコープを広げるにつれ、次のような問題に躓くことが増えていきました。
コード記述(ステップ1、2、3)
バッチスクリプトを実行するには、ユーザーが、Git、GitHub、ターミナル、Linux、プログラミング、Hadoopなどに詳しいことが必須条件でした。データエンジニアやデータサイエンティストは良いですが、その他のユーザーからすると負担コストが高く、バッチ処理システムを使えるようになるために上記すべてをマスターするようお願いするのは現実的ではありませんでした。
それに加え、毎日大量にくるバッチ処理リクエストの対応は大抵私たち開発者に回ってきていたため、その対応に追われた結果、本来の仕事であるデータ収集システムの調査や開発にかける時間が取れなくなるという状況が続いていました。
実行(ステップ5)
このシステムは単一のサーバーにデプロイされているため、高可用性がなく、サーバーのスペックによってキャパシティが制限されていました。
確認とモニタリング(ステップ6)
タスクを管理したり、トラブルシューティングに必要なログを読んだりするためには、ユーザーがAzkabanやAirflowなどのスケジューリング・エンジンに詳しいことが前提条件でした。ステップ1〜3と同様、学習コストがあまりに高く現実的ではないため、結局こちらについても開発者が担当していました。
さらに、問題はそれだけではありませんでした。
権限管理
スクリプトや情報がプロダクトごとに切り離されておらず、全員に公開されている状態でした。これでは、誰でもGitHubリポジトリからファイル修正をしたり、他の人のタスクをスケジューリング・エンジンで実行したりできてしまいます。
データ/タスクオーナー
システム設計上、各データやタスクの担当者がわかりづらいという問題もありました。
Frey
中心概念
従来のバッチ処理システム上で何百というスクリプトを分析した結果、それらのスクリプトはXをソース、YをデスティネーションとしたX2Yのパターンに分類できること、どの様なパターンであってもいくつかの特定のパラメータで表現できることがわかりました。そのため、新システムの中心概念は次のように打ち立てました。従来のシステムが実際のスクリプトを一つのタスク("Task as Script")としていたのに対し、新システムではconfigfileを一つのタスク("Task as Config")として表現することにしたのです。
ここでは、バッチフローは「ジョブ」と呼び、各「ジョブ」は1つ以上の「タスク」で構成されます。例えばAirflowでは、dagは「ジョブ」、dagの中にあるタスクは「タスク」です。
ジョブ構成のテンプレートは下記のようになっています。
id: job_id
name: job_name
description: job_description
owner: owner # comma split user names, e.g. "a.b,c-d"
owner_group: group # comma split group ids, e.g. "1,2"
mail_to: email # extra email addresses except for those of owners and groups, comma split, e.g. "a.b@linecorp.com"
start_date: yyyymmdd # fixed, '19700101'
end_date: yyyymmdd # fixed, '99991231'
schedule: 0 8 * * * # cron expression, can be empty
retry_time: 5
retry_interval: 10 # in minutes
service: line # can nearly be considered as hive database name
task:
- {{ x2y_0 }}
- {{ x2y_1 }}
dependency:
- {{ x2y_0.name }}
- {{ x2y_0.name }}->{{ x2y_1.name }}
task_config_global:
{{ global config for all tasks }}
タスクのタイプ(X2Y)によってフォーマットは異なります。以下はmysql2hiveの例です。
id: task_id
name: task_name ## generated by Frey
type: mysql2hive
origin:
server:
- [id0, db0, table0]
- [id1, db1, table1]
column: [c0, c1, ..., cN]
filter:
timezone: JST
destination:
cluster: datalake/iu
database: frey_dev
table: test
ddl: ddl_string
partition:
- {key: dt, value: '%Y%m%d'}
option:
jdbc_param: {k0:v0, k1:v1, ..., kN:vN}
partition_lifetime: ''
alert:
- {"key":"RowCount","op":"==","value":"0"}
アーキテクチャ
"Task as Config"の概念のもと、次世代のバッチ処理システムを構築しました。それがFreyです。
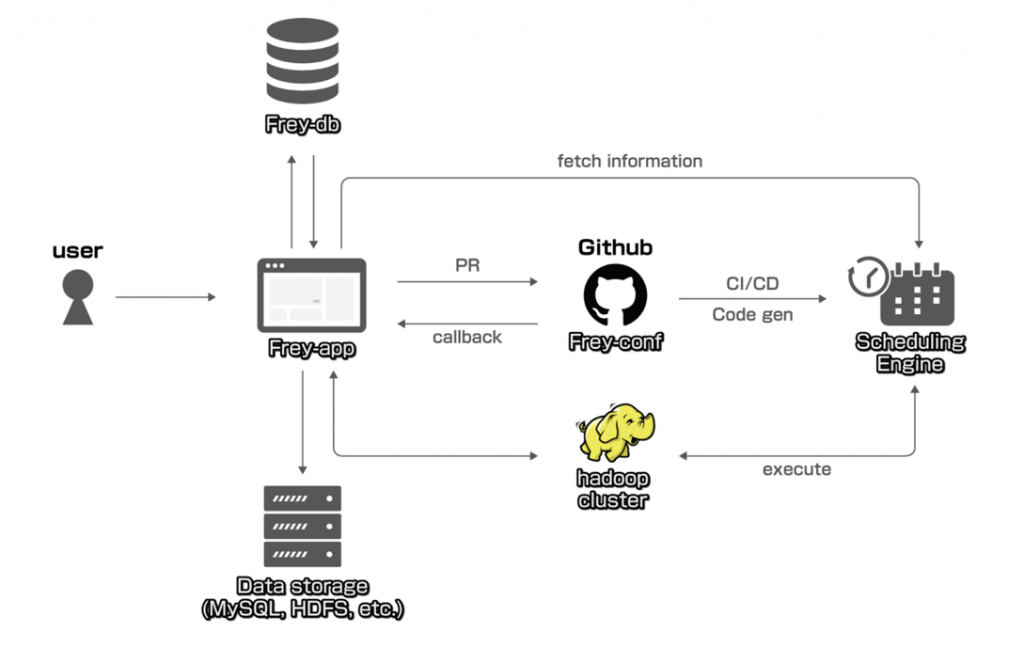
コンポーネントと主な機能
- Frey-app
Frey-appではユーザーにweb UIを提供しています。Frey-appを使えば、エンジニアリングの技術がなく、プログラミングやターミナル、Linux、スケジューリング・エンジンなどに詳しくない人でも、バッチでのデータ収集タスクを自分で作成できます。タスクのデータソースとデスティネーションに関する基本的な知識さえあれば、configを自動生成することが可能です。
Frey-appには、Airflowなどのスケジューリング・エンジンと連携するためのAPIも用意されています。ユーザーのジョブが作成・デプロイされると、実行ステータスやログをはじめとする全ての情報にアクセスでき、バックフィルや再実行などの操作も可能です。AirflowやAzkabanといったスケジューリング・エンジンの使い方を覚える必要はありません。
Frey-appでは、コネクション、ジョブ、タスク、ユーザー、グループなど、バッチ処理のあらゆる面でモデリングが利用可能なため、柔軟なスケールアウトが可能で、新しいタイプのX2Yにも対応できます。
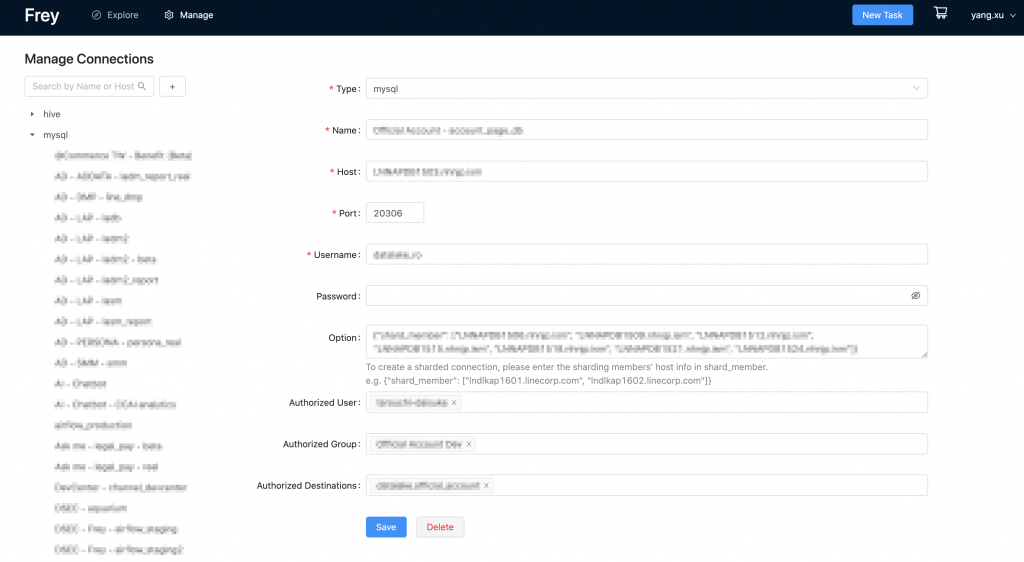
また、Frey-appでは権限管理が簡単にできる管理者ツールも提供しています。ユーザーやグループごとに権限を設定することで、自分が担当しているコネクション、ジョブ、タスクのみを閲覧・操作できるようにします。なお、コネクション権限設定では、一つのコネクション(ソース)からのデータは限られたデスティネーションにしか置けないようになっています。
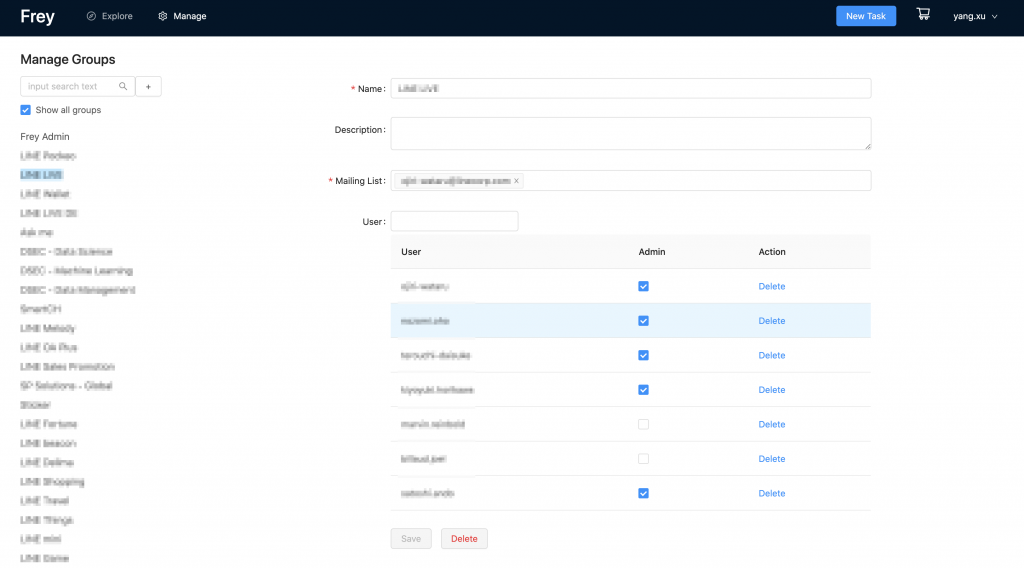
- Frey-conf
Frey-confは、すべての設定ファイルが保管されているGitHubリポジトリで、設定ファイルからコードを生成するためのレンダラーとテンプレートも入っています。
こちらはX2Yのタスクテンプレートのサンプルです。
{{ name }} = KubernetesPodOperator(
task_id="{{ name }}-{{ destination.cluster }}_{{ destination.database }}_{{ destination.table }}",
name="{{ pod_name }}",
image="{{ image }}",
image_pull_policy="Always",
namespace='{{ namespace }}',
affinity={{ affinity }},
in_cluster=True,
do_xcom_push=False,
secrets=[keytab, mysql_host, mysql_port, mysql_username, mysql_password, mysql_db, frey_iu_keytab],
cmds=["bash", "-i", "-c"],
arguments=['''
......
......
# script content
cat <<"EOF" > main.py
from datetime import datetime
import sys,os
from mysql2hive_plugin import *
from utils import *
{% if origin.server|length > 1 %}
t = MultiMysql2hiveOperator(
{% else %}
t = Mysql2hiveOperator(
{% endif %}
# operator parameters
......
......
)
t.execute({'execution_date': datetime.strptime("{{ '{{ execution_date }}'}}", "%Y-%m-%dT%H:%M:%S+00:00")})
EOF
pip freeze
exec python main.py'''],
dag=dag
)
"Task as Config"の強みの一つは、すべてのジョブとタスクが標準化されることです。タスクの内容を確認するにはいくつかの設定パラメータを見るだけでよく、見慣れないコーディングスタイルで書かれた他の人のスクリプトを読む必要はありません。プログラミング技術を持っていないユーザーでも使えるため、コード(config)レビューも簡単になります。
PythonやAirflowなどのコンポネートのバージョンをアップグレードする際にも非常に便利です。"Task as Script"のままでは互換性の問題が発生する懸念もあったでしょうし、修正や移行のコストも高くついたはずです。"Task as Config"を導入したことで、レンダラーとコードテンプレートさえ用意すれば簡単にすぐ作業できるようになったのです。
さらに"Taskas Config"を採用したことで、チームやメンバーごとの業務分担を明確にするという課題を遂に解決することができました。開発者は(Freyのような)システムやツールの開発に注力する一方で、ユーザーはバッチデータ収集のパイプラインを作成し、他方、管理チームのメンバーはデータと権限の管理を担当するようになりました。開発者がユーザーの仕事も管理チームの仕事も巻き取っていた日々はもう過去のものとなったのです。
- Frey-plugin
Frey-pluginは、特定のスケジューリング・エンジンと連動するツールで構成されています。現状ではAirflowを使っているので、X2Yのタスク用に様々なAirflowプラグインを開発しました。
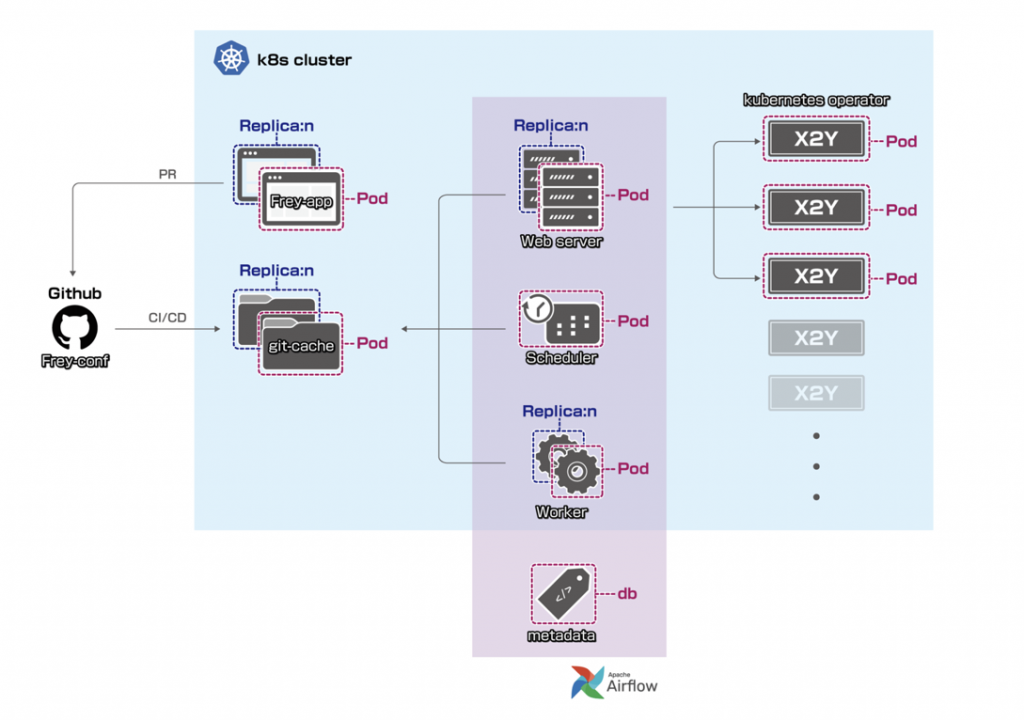
Kubernetes
FreyのWebアプリとスケジューリング・エンジンはK8S環境でデプロイしています。
これにより、以下を実現しています。
- 高可用性
- 開発/ステージング/本番環境への簡単なデプロイ
- 柔軟性のある構成と依存関係
スケジューリング・エンジンはAirflowを使っているため、それぞれのX2YタイプでDockerイメージを作成し、KubernetesOperatorを使ってタスクのpodを開始します。
FreyのK8Sアーキテクチャは以下のようになっています。
監査
Frey-appとスケジューリング・エンジンのログは、どちらもElasticSearchに送っています。
通知設定
タスク作成時、ユーザーは通知を受け取るかどうかを選択します。
現状、ほぼ全てのユーザー操作とジョブ実行に関して、Slackとメールで通知が可能です。
導入前後での比較早見表
| Frey | 旧システム | |
| ユーザー |
|
|
| オペレーション |
|
|
| スケーラビリティ |
|
|
| セキュリティ |
|
|
| HA |
|
|
まとめとこれから
Freyの構築は成功し、使い勝手の良いセルフサービス型のバッチデータ収集システムを作ることが出来ました。現在、LINE社員向けに稼働していますが、(Hadoopクラスターのメンテナンス時を除いて)ダウンタイムも発生していません。
Frey上では、2020年10月末までに
- 80以上のLINE関連サービスで200人以上のユーザーによって
- 毎日300以上のジョブと1,500以上のタスクが実行され
- 毎日240以上のコネクションから6TB以上のデータを収集しました。
また、以下の様な実績も出しています。
- 大量のバッチデータ収集パイプラインの構築コストを大幅に削減
- 関係組織の作業区分の合理化
- マニュアル作業を可能な限り自動化したことによる業務全体の効率化
現在、mysql2hive、oracle2hive、cubrid2hive、hdfs2hiveがFreyで利用可能で、mongodb2hiveとhbase2hiveについても開発中です。
今後は、ソースとデスティネーションの両方で、より多くのデータストレージをサポート予定です。さらにFrey-appでは、トラブルシューティングに関するサポート強化など、ユーザーの利便性を高めるための機能を追加予定です。