
こんにちは。慶應義塾大学大学院 理工学研究科 修士1年の枡田 真奈です。8月から6週間、LINE株式会社の20201年度夏季インターンシップ「技術職 就業型コース」に参加させていただき、リサーチインターンとして、AIカンパニー/AI ResearchチームのComputer Vision Labチーム (CVL)に配属され、「2D/3D バーチャルヒューマンを機械学習モデルによって動かす」という研究に取り組みました。本レポートでは、我々が目標としている課題と、インターンシップにて取り組んだ内容・成果について説明します。
バーチャルヒューマンを動かすとは?
バーチャルヒューマンは、近年、2D/3Dともに発展してきています。現在は、このようなバーチャルヒューマンは人間の動きをキャプチャーしたり、体だけは実際のモデルを使うなどして動いている映像を作成していますが、それだと作成できる動きの数には限界があり、今後、AR/VRの世界にバーチャルヒューマンが進出していくには、より自然な動きを自動で生成できる技術が必要になります。今回のインターンでは、そのための基礎技術の研究に取り組みました。
この技術を作成するにあたり、私たちは問題を3つに分割しました。
- モデルに骨格を与える
- 骨格を動かす
- 動かした骨格をモデルにマッピングする
このように問題を分割し、「2.骨格を動かす」という部分にのみ機械学習を用いることで、より詳細な表現が必要になるモデルの表面形状を機械学習モデルで扱う必要がなくなるほか、1つの機械学習モデルが2D/3Dどちらにも適応可能となります。
また、骨格を動かすというという部分において、まずは以下の図のように、現在の姿勢から目標となる姿勢までの間の動きを生成するという問題に取り組みました。そこには2つの理由があります。1つ目は、人間の言葉による指示から目標となる姿勢を求めるという問題と目標の姿勢までの動きを生成するという問題は全くの別物であること、2つ目は、人間の言葉による指示から画像検索にかけ、その画像から既存の骨格推定アルゴリズム[3]などを用いれば、目標となる骨格は得ることができると考えたからです。
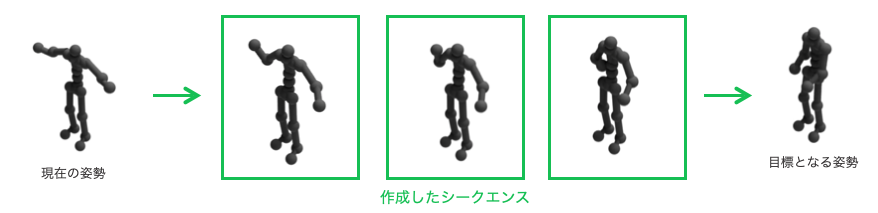
現在の姿勢から目標となる姿勢までの動きを生成する中でキーワードとなるのが「人間らしい」動きを生成することです。しかしこの「人間らしい」動きを生成するのは非常にむずかしく、以下のような課題があることがわかりました。
1.目標となる姿勢が同じだとしても、毎回同じ動きになるとは限らない
人間の動きは、元々の姿勢や、人によって異なります。また、同じ人が「手をあげて」と言われても、状況によって、動きが異なることもあり得ます。
2.知らない動きも作らなければいけない
人間の動き全てをAIが学習し切るのは不可能です。人間であれば、指示に応じて臨機応変に動くことが可能ですが、そのような動きを全て学習させるためには大量のトレーニングデータが必要な上に、とても大きな機械学習モデルが必要になってしまいます。
3.自然な動きとあり得る動きは全く別物である
単純にあり得る姿勢で姿勢間を補間しただけでは、人間の動きとしては不自然です。例えば、"手を上げて"と言われた時、人間は一度腕を折り曲げて肘から上にあげるのが自然だと思いますが、背泳ぎのように手を真っ直ぐ伸ばしたまま肩を回して腕をあげることも可能です。このように、人間がとり得る動きが自然な動きとは限りません。
また、与えられた情報から動きのシークエンスを生成するという既存手法はいくつかありましたが[4,5,6]、どれも、トレーニングデータと同じフレームレートでしか動きを作成できずAR/VRへの応用が期待できない、表現できる動きに制限があるなど、私たちの目的を果たすことができる手法はなく、全く新しい手法を考案する必要があることがわかりました。
インターンシップでの成果
今回のインターンシップの期間では,2フレーム間を滑らかに補間することができる手法を作成することができました。
実験には、Ubisoftのモーションキャプチャデータセット[7]を用いました。このデータは人間の骨格を以下のような21個の関節で表現しているデータセットです。
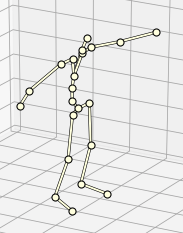
骨格データの検証
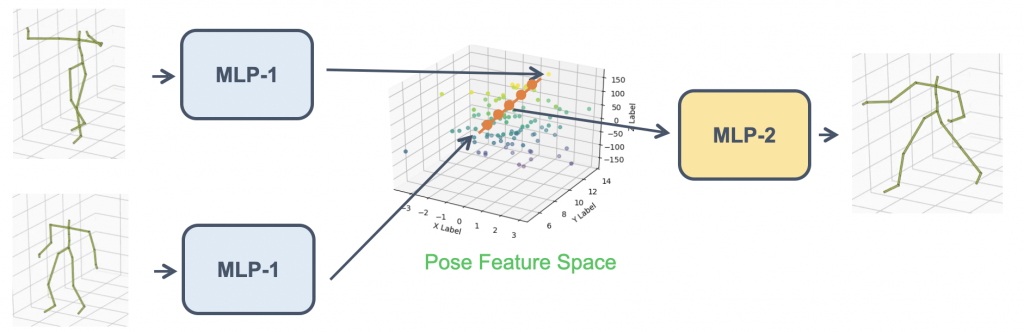
姿勢の特徴量空間
上の図のように、骨格のデータは21個の関節の座標値(関節角度)の63次元(84次元)程度の非常に軽量なデータであるため、MLPベースのネットワークを使用しました。MLPによって十分に姿勢の情報が学習可能であるかを確認するため、以下のようなモデルを用いて、MLPによって学習した姿勢の特徴量空間内を線形的に補間し、空間が滑らかであるかの検証を行いました。
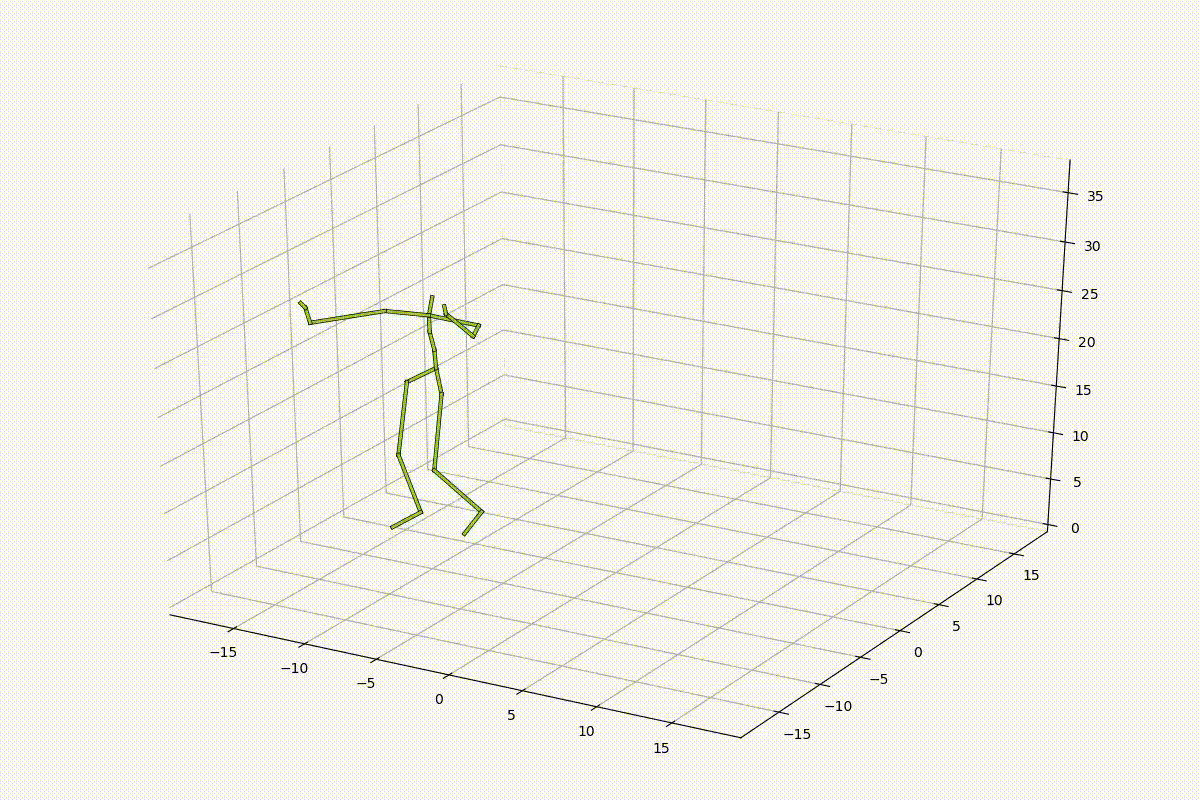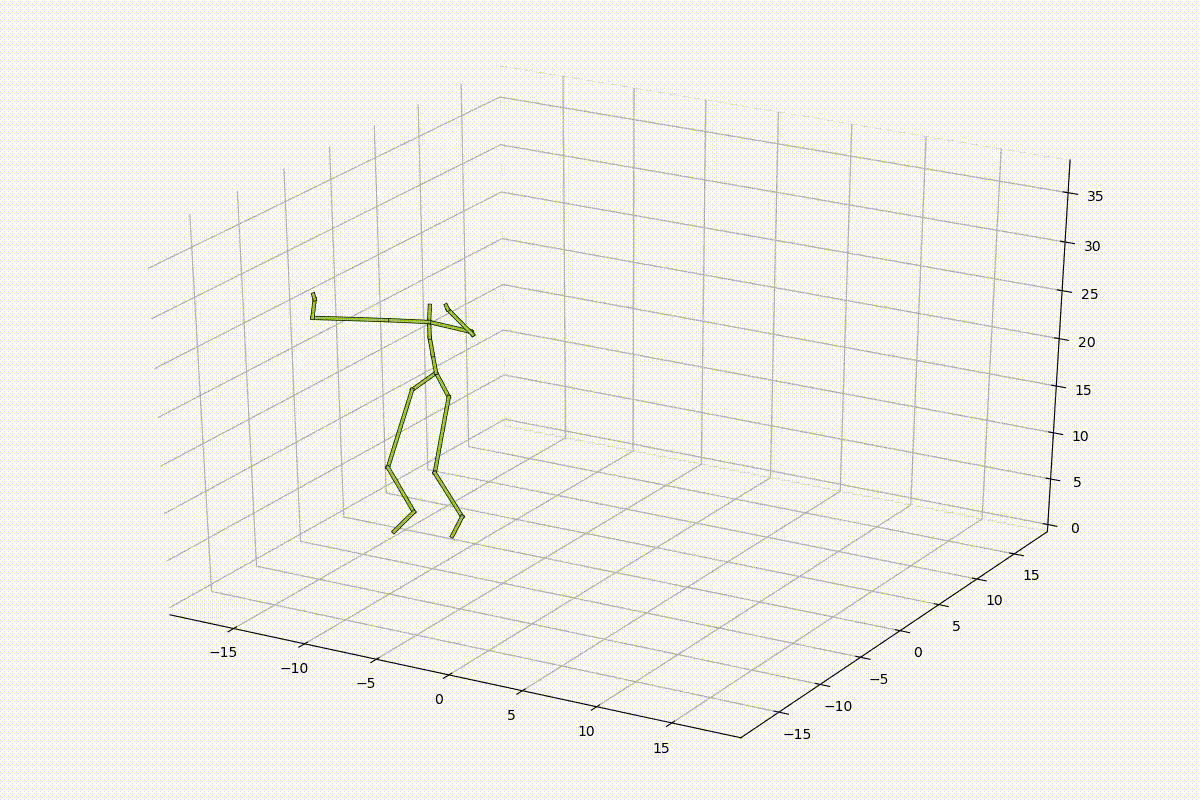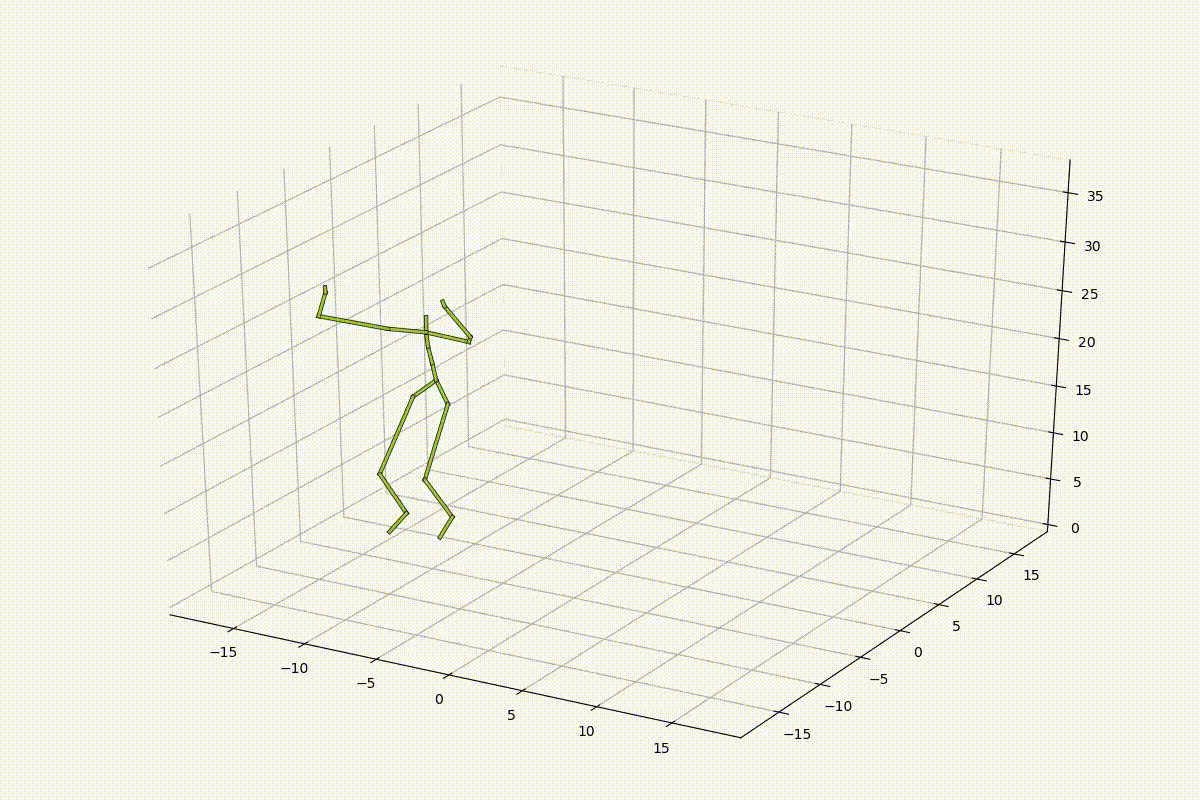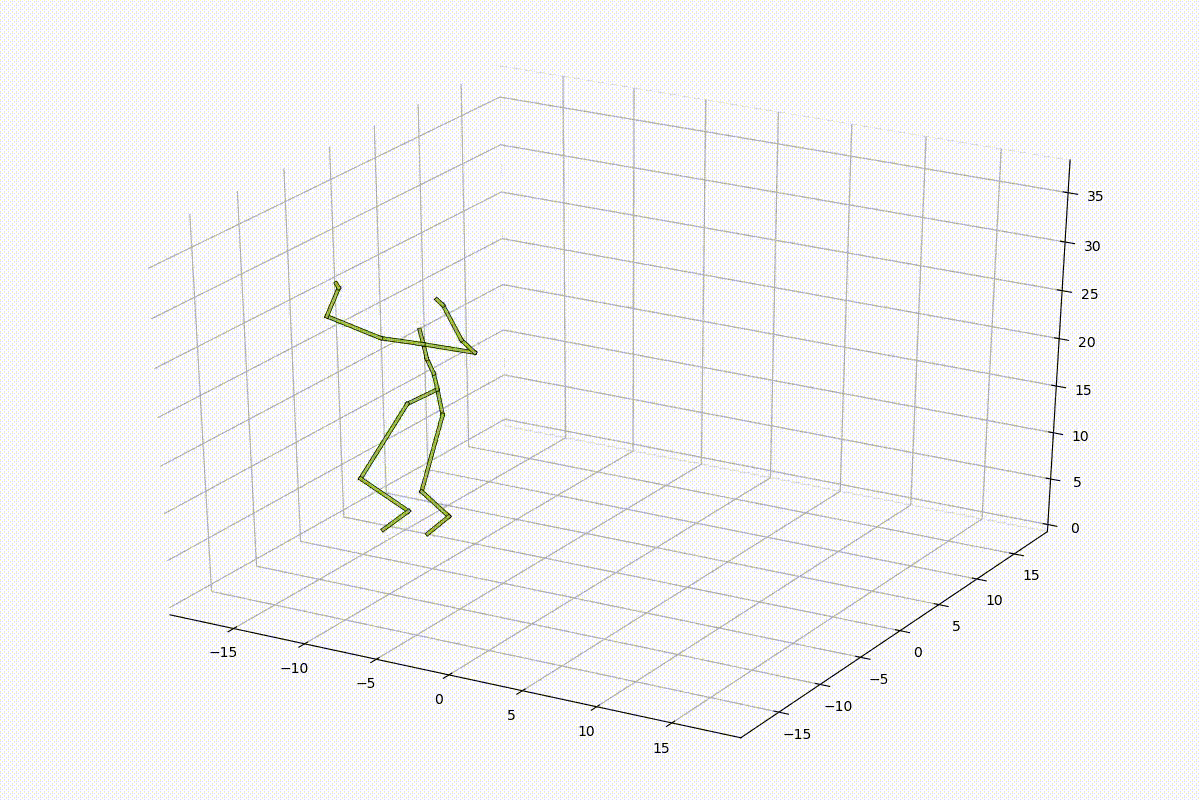
結果としては、以下のようになりました。姿勢が滑らかに補間されていることがわかります。しかし、足が滑っているような動きが入ってしまっており、動きとしては不自然さが否めず、特徴量空間内を線形的に補間するだけでは人間の動きとして不自然になってしまうことも同時に確認することができました。
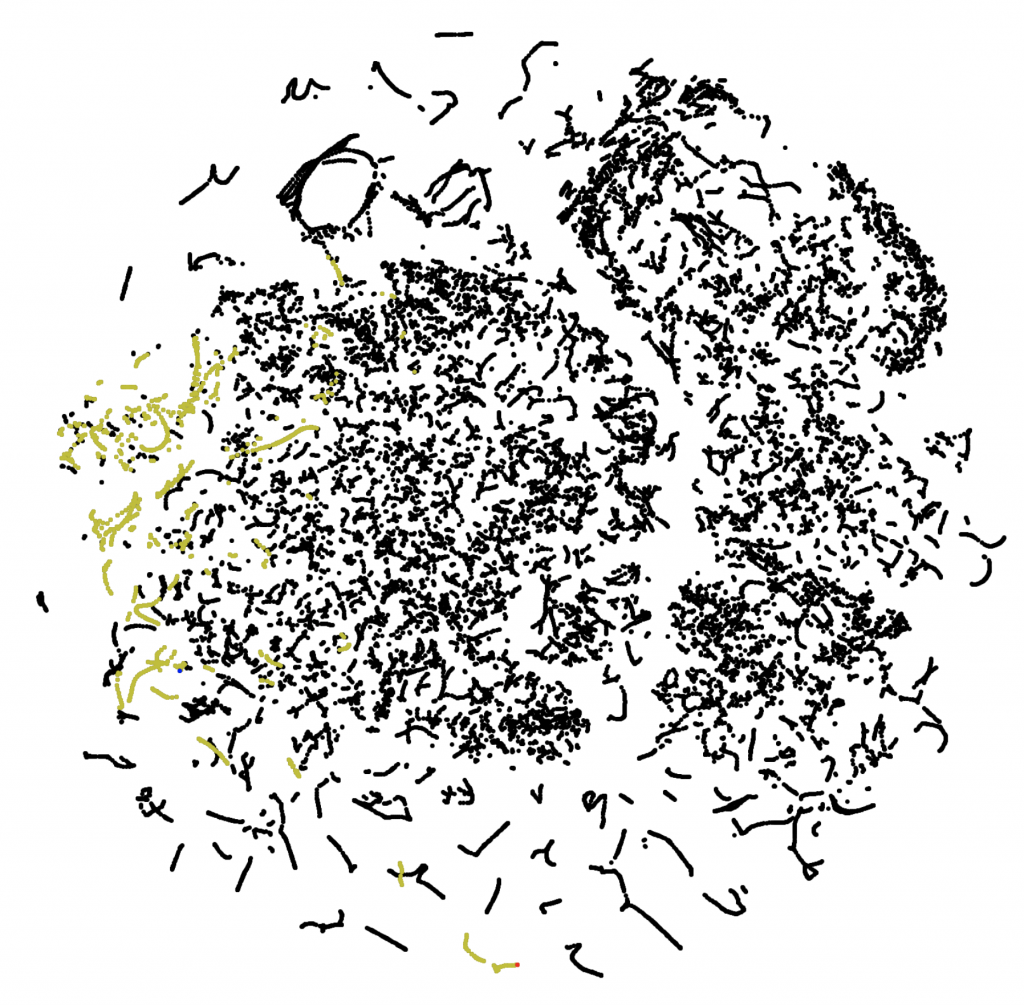
人間の連続動作に関する観察
研究を進める中で、人間の動きは見た目には滑らかなものの、特徴空間上では必ずしも連続的とはならないことがわかりました。下の右図は左にピンクで示された左足の4つの関節の動きをT-SNEで可視化した様子です。黄色で示されているのが、1つの動画での動きですが、部分的にしか繋がりがなく、滑らかには動いていないことがわかります。ニューラルネットワークは、滑らかな数値変化をモデリングすることはできますが、離散的な値をモデリングすることは非常に困難なため、人間らしい動きを機械学習モデルで学習するには工夫が必要であることがわかりました。
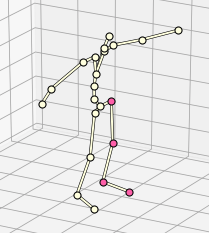
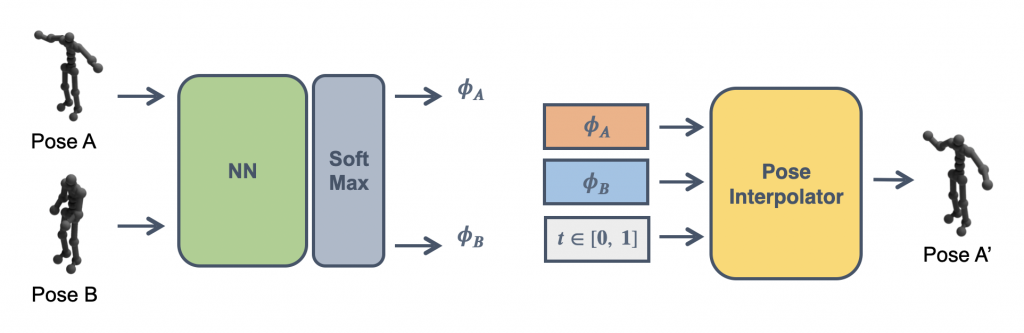
提案手法
2つの姿勢間を滑らかに補間するネットワークとして、以下のようなネットワークを考えました。フレームワークは以下の通りです。
- 最初の姿勢(Pose A)と目標の姿勢(Pose B)をMLPに入力する
- MLPが出力した特徴量ベクトルをSoftmax層に入力し、分類後特徴量ベクトルϕAϕA、ϕBϕBを得る
- ϕAϕA、ϕBϕBおよび時刻tを入力することで、Pose Aをt=0, Pose Bをt=1とした時の時刻t時の姿勢Pose A'を得る
tを[0,1]でいくつか入力することで、Pose A, Pose Bを滑らかに補間したシークエンスを得ることができます。
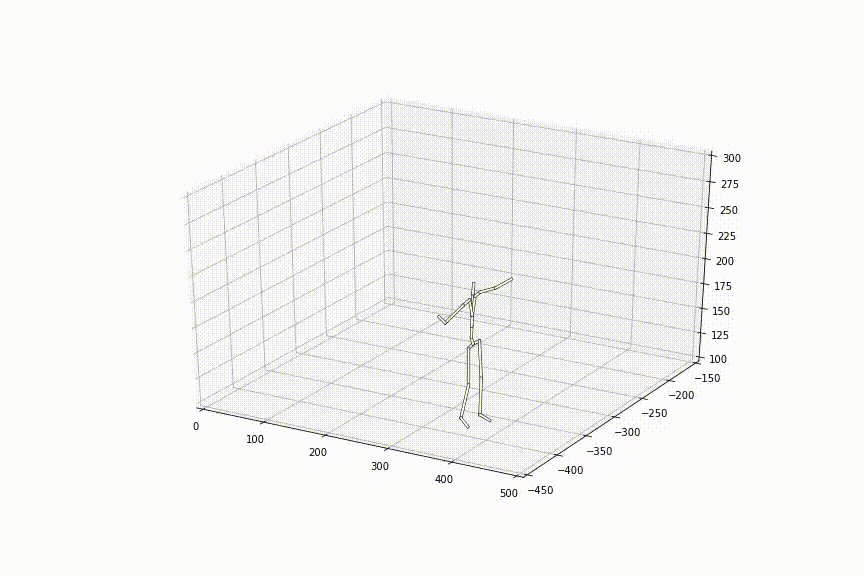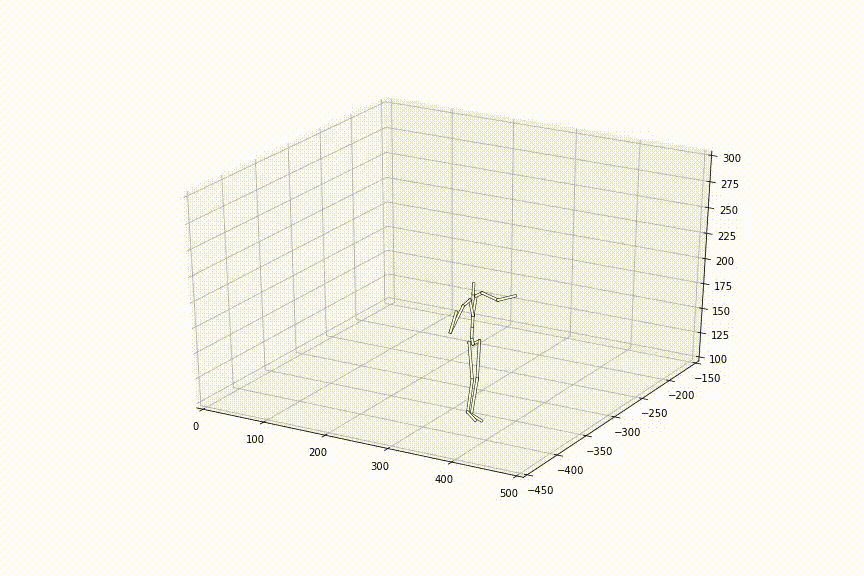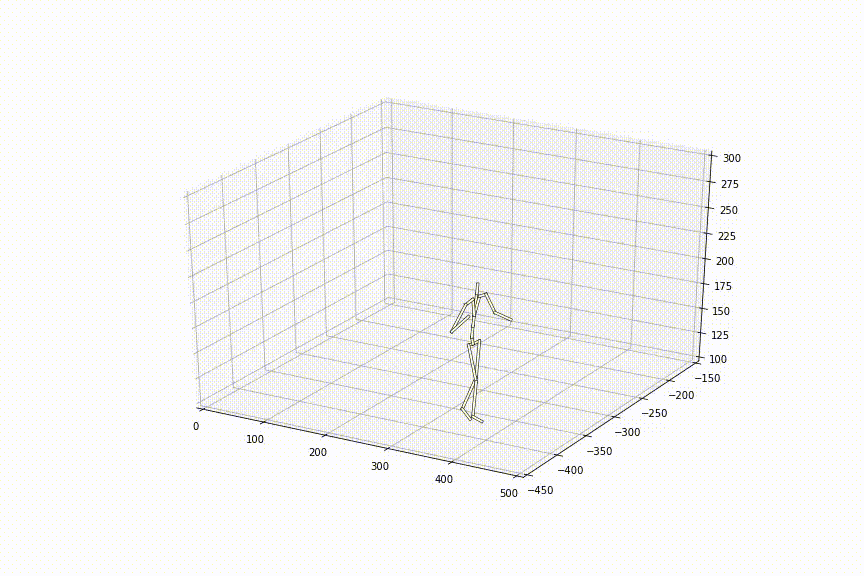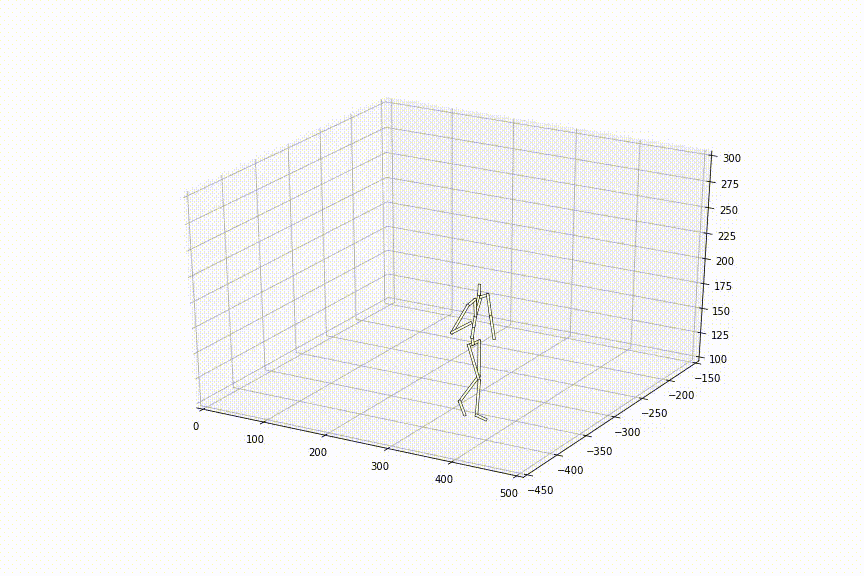
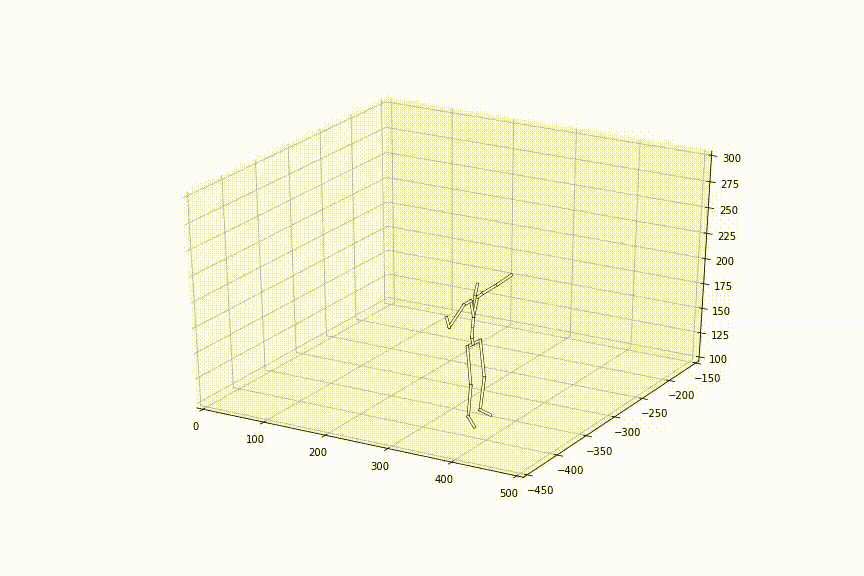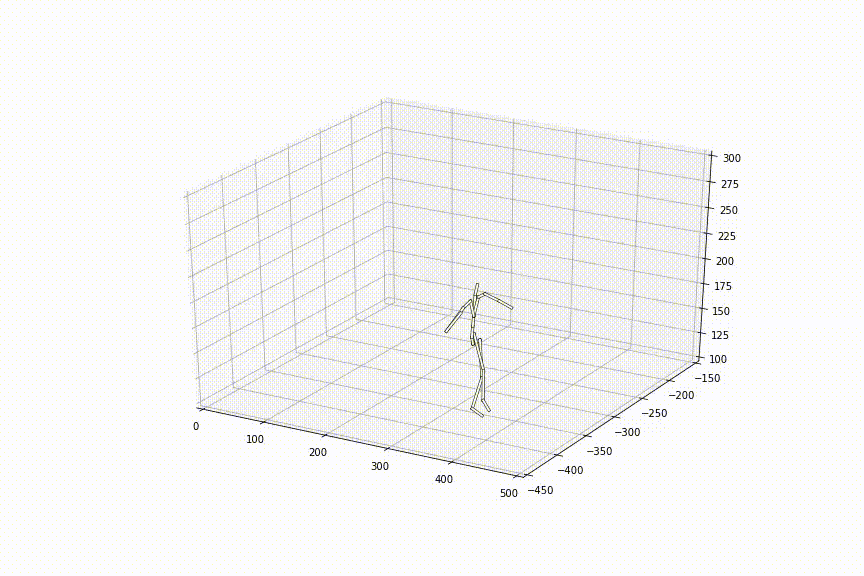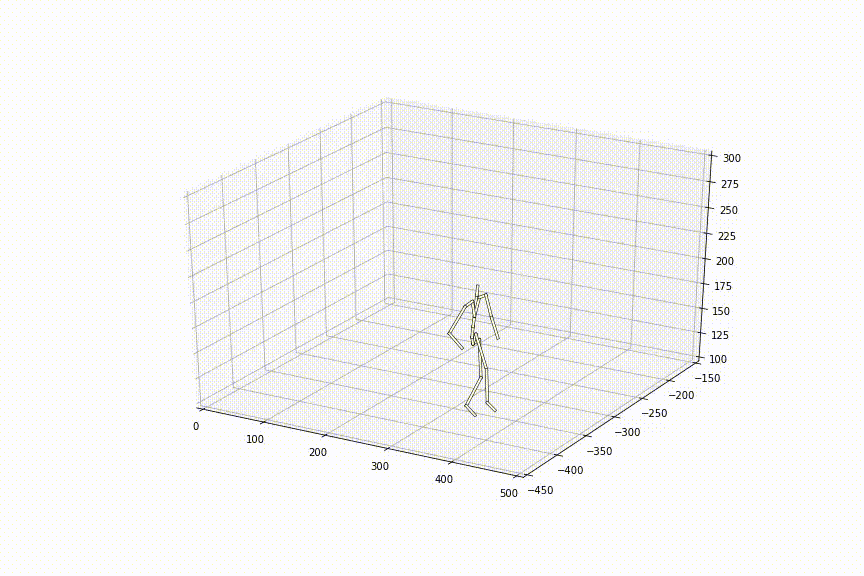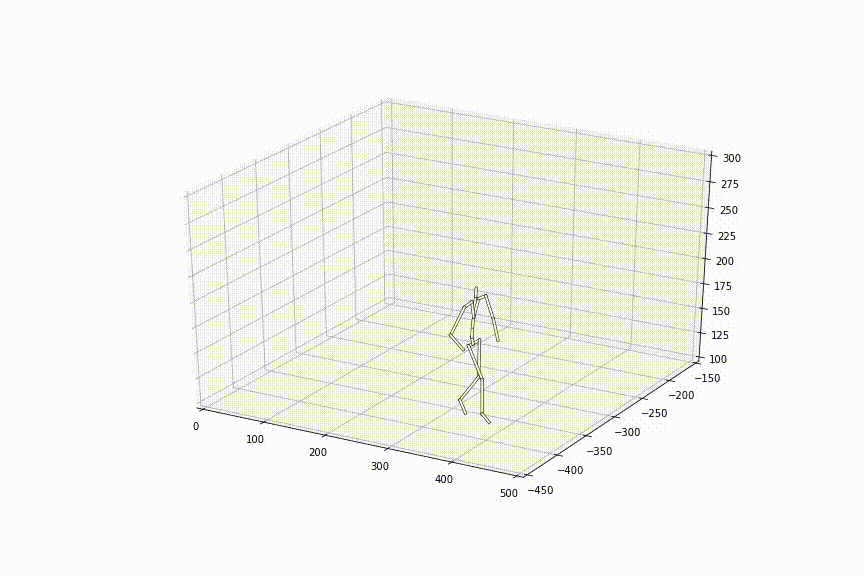
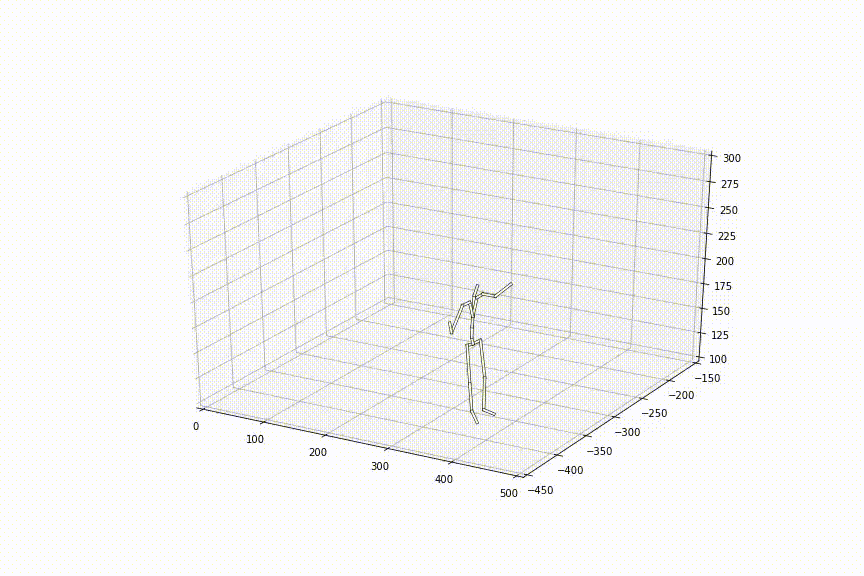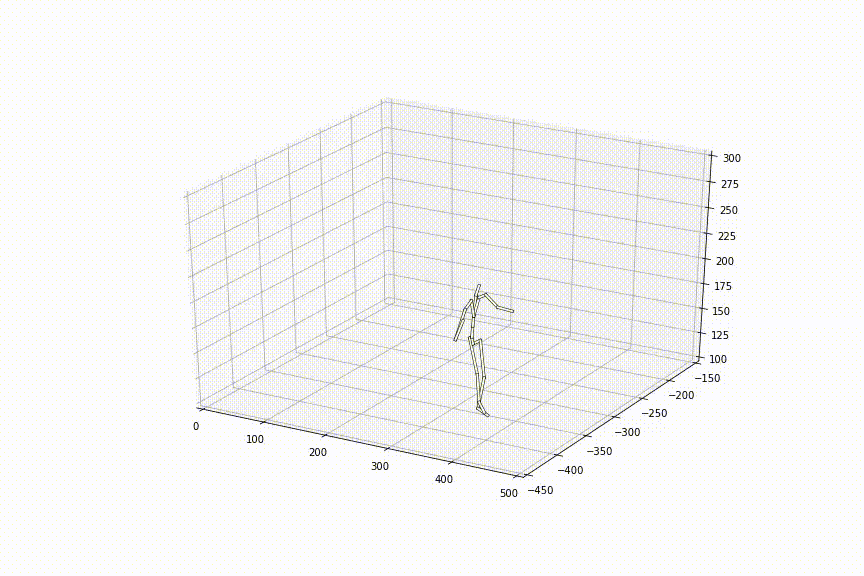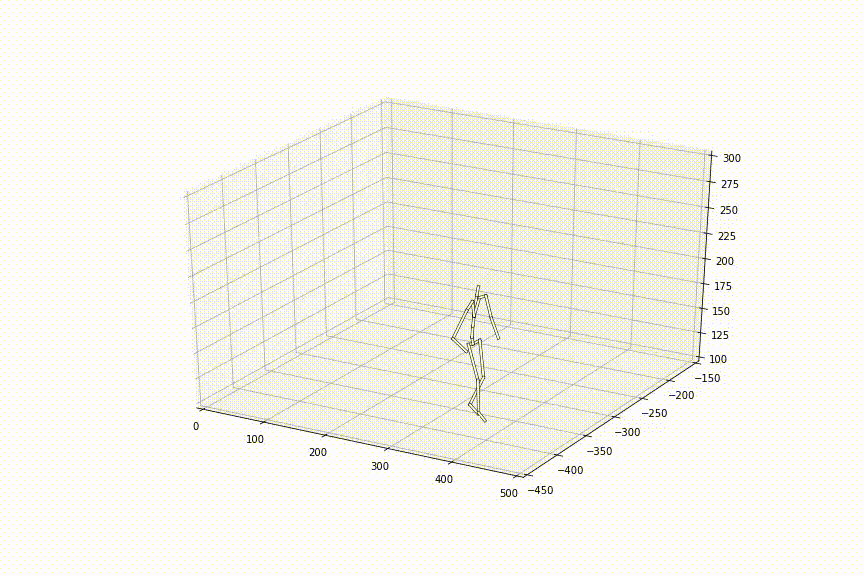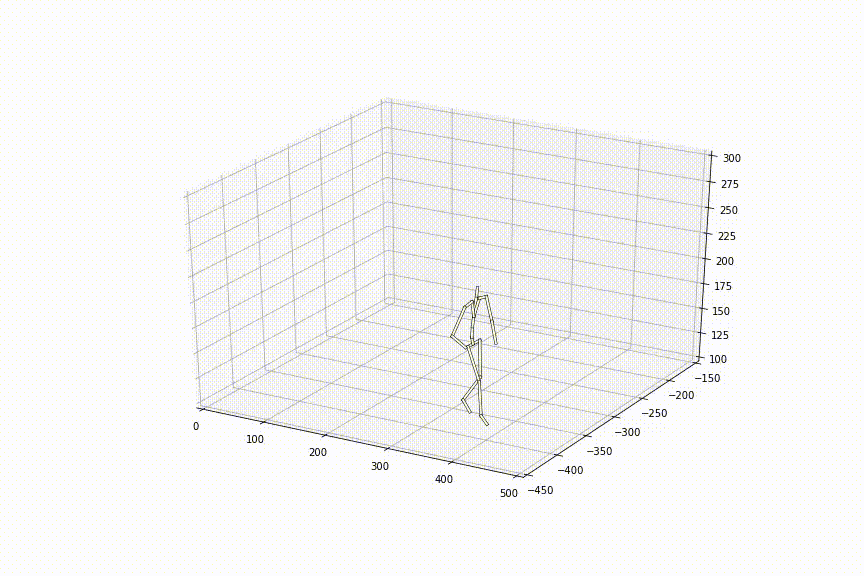
この手法を用いて観察されたことのない2姿勢間を補間した結果は以下のようになりました。滑らかに姿勢間が補間されており、ただ単純に線形補間した時とは異なり、足の動きもスムーズで、人間らしいスムーズな動きに近づいているように見えます。
提案手法の貢献部分
提案手法の貢献部分は大きく3つあります。以下、実験結果は全て観察されたことのない姿勢間を補間した結果です。
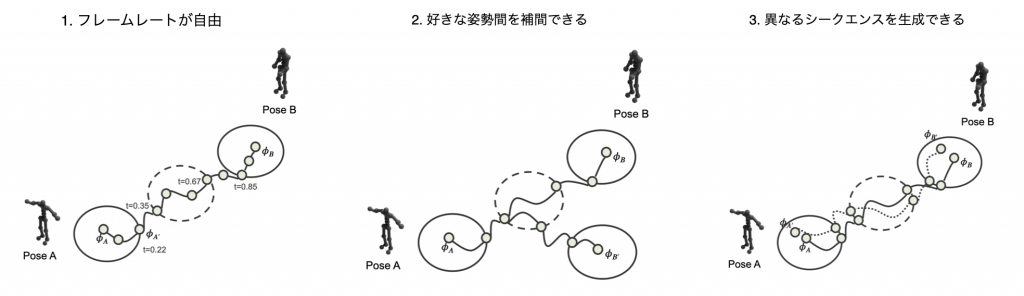
1.フレームレートが自由
tは0〜1の間で自由に定めることができるので、フレームレートを細かく設定可能です。左の動画はtを0.1毎に補間、右の動画はtを0.02毎に補間している動画ですが、確かに、フレームレートを細かく設定できていることがわかります。
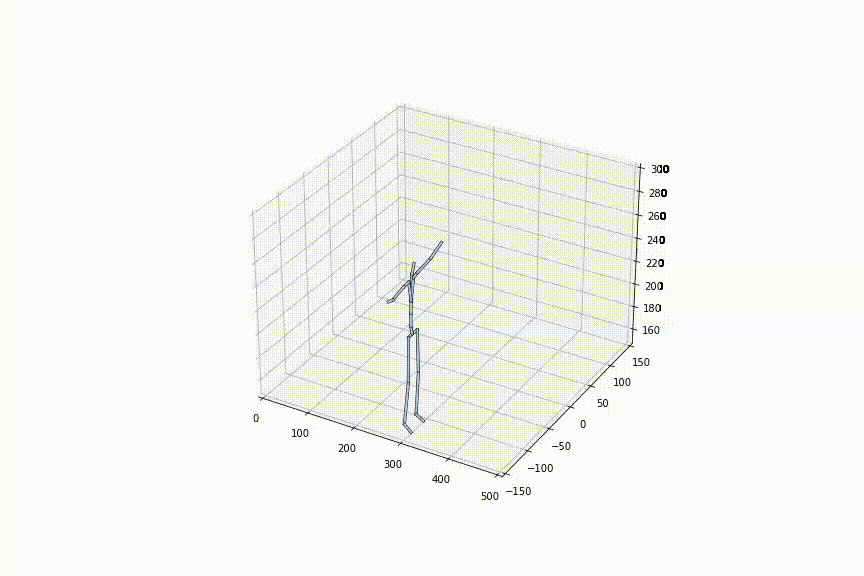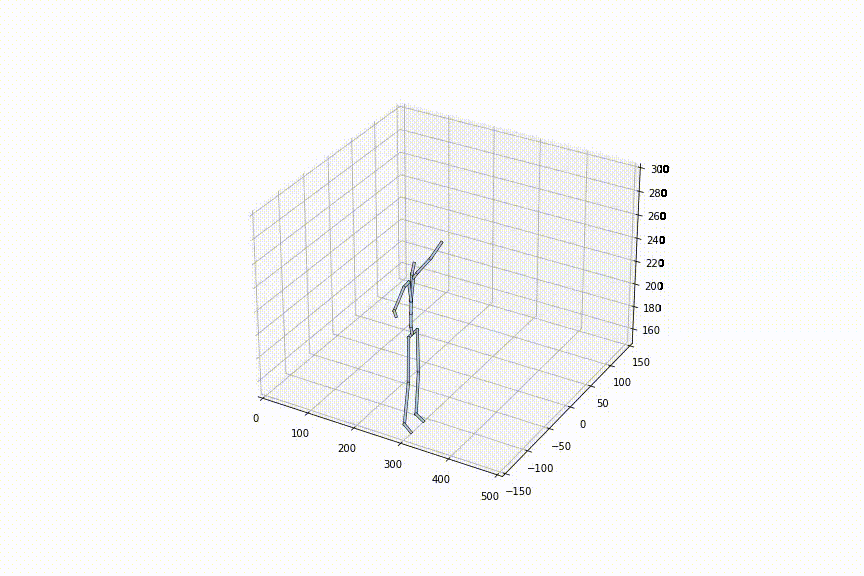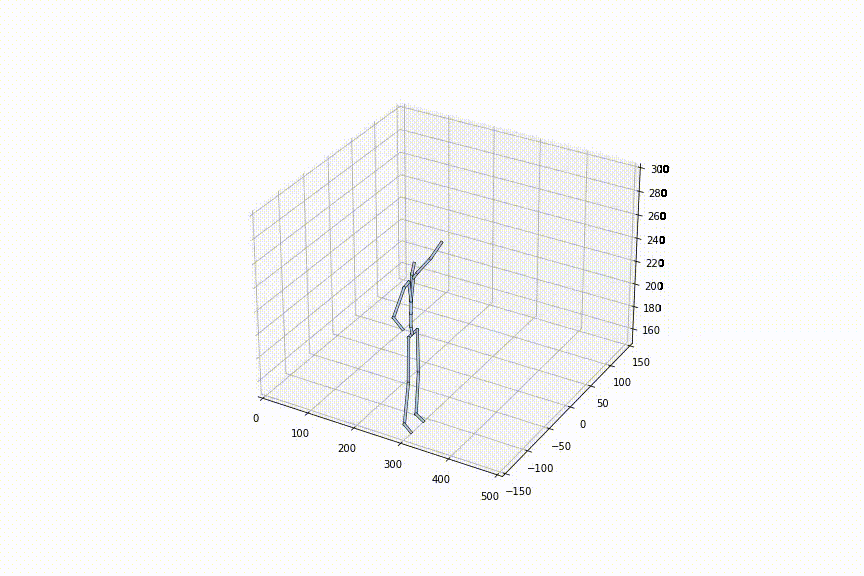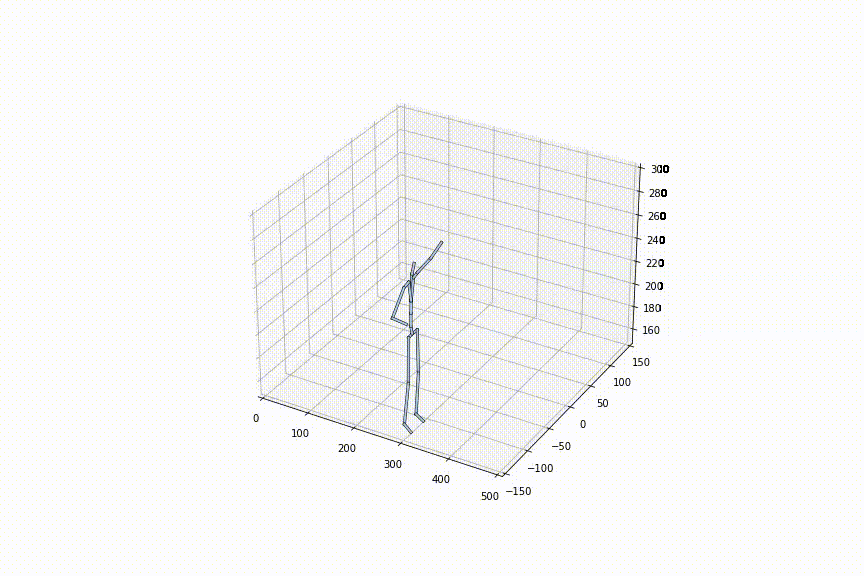
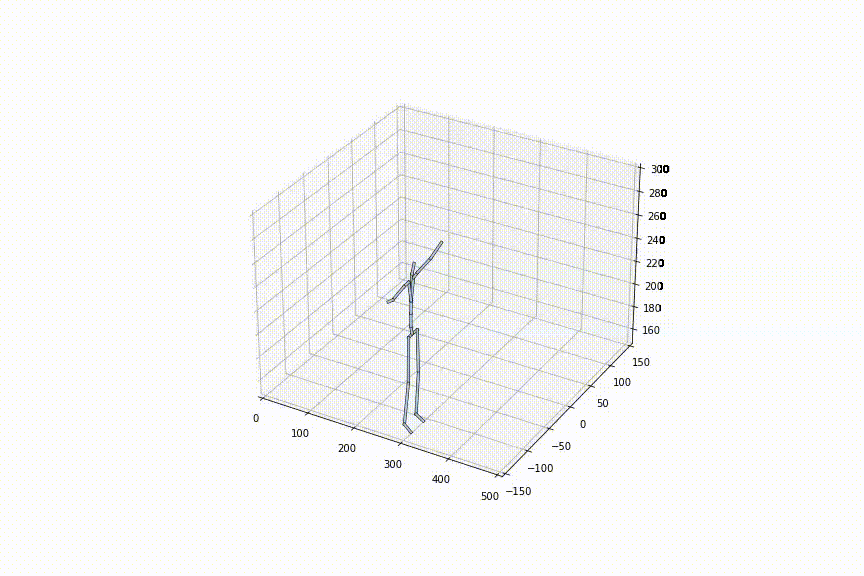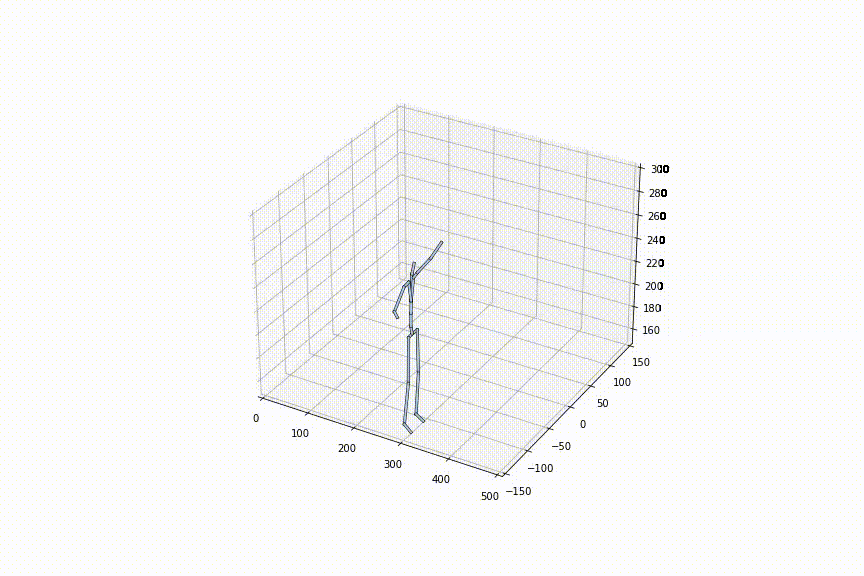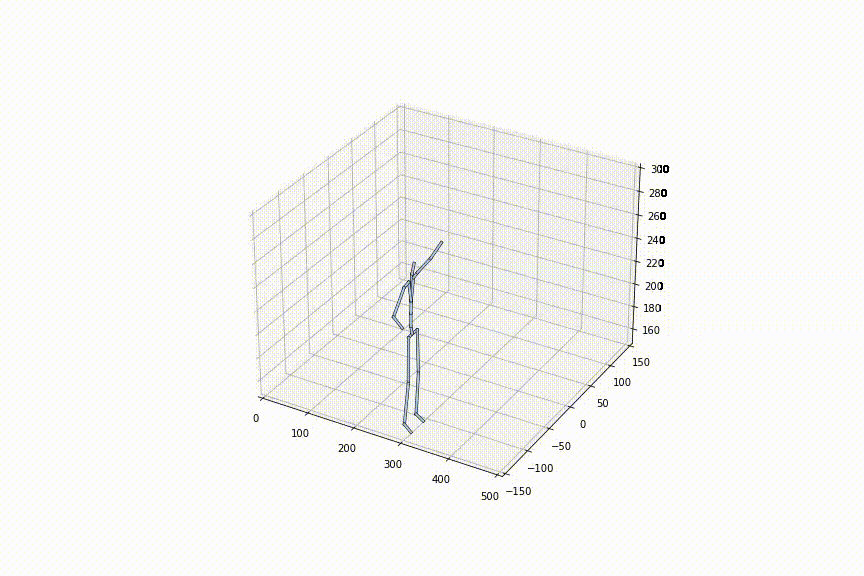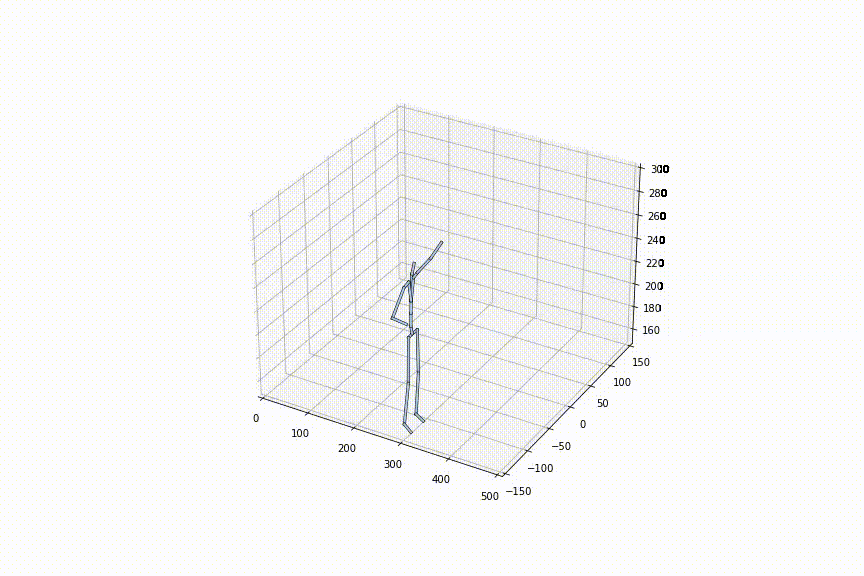
2.好きな姿勢から好きな姿勢への補間をできる初めての手法
最初と最後の姿勢は自由に入力可能なので、好きな姿勢から好きな姿勢の補間が可能です。下の動画は、同じ初めの姿勢から、異なる最後の姿勢までを補間させた様子ですが、どちらも滑らかに補間ができていることがわかります。
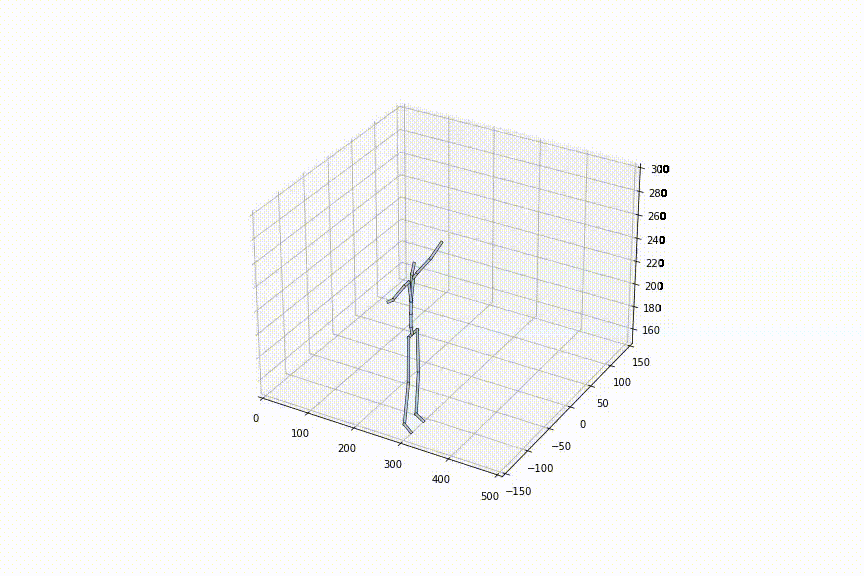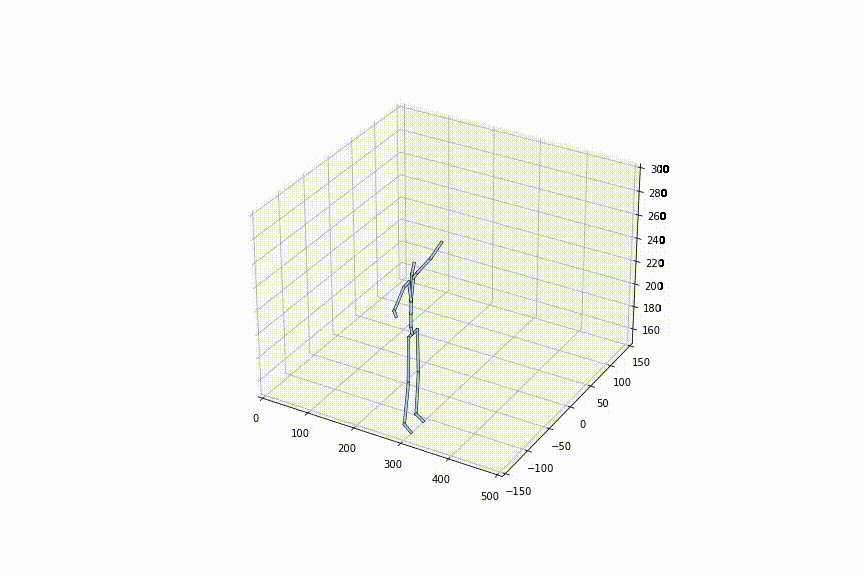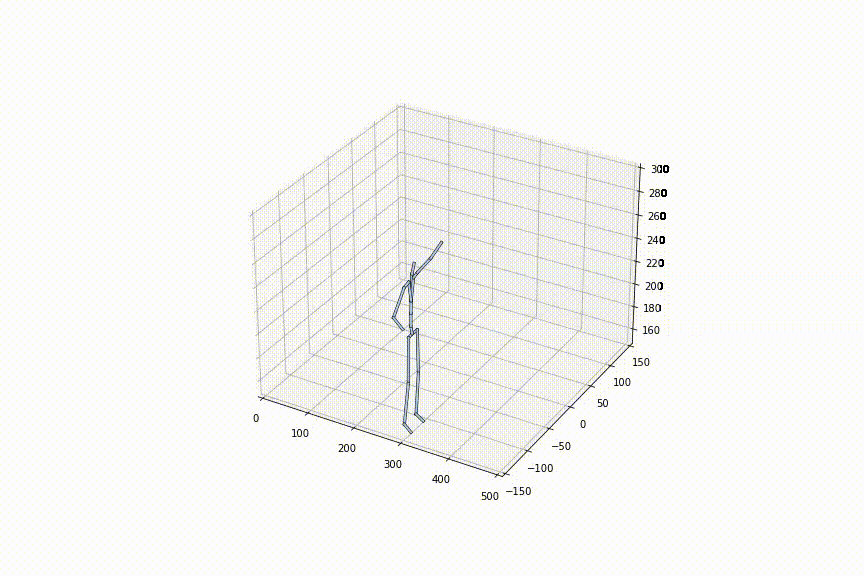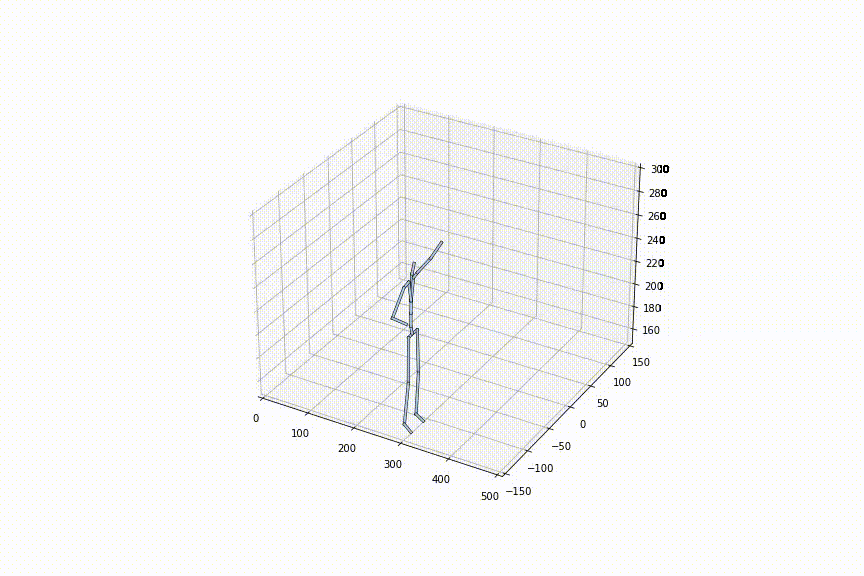
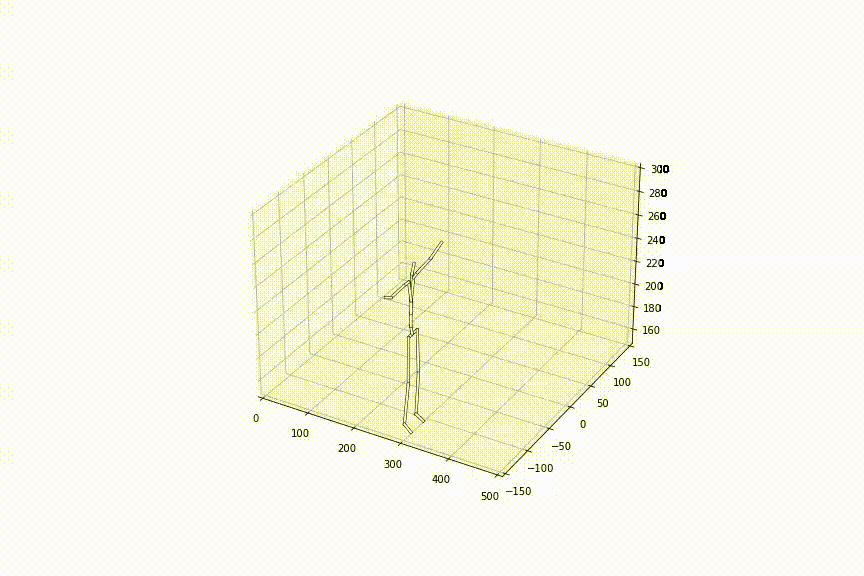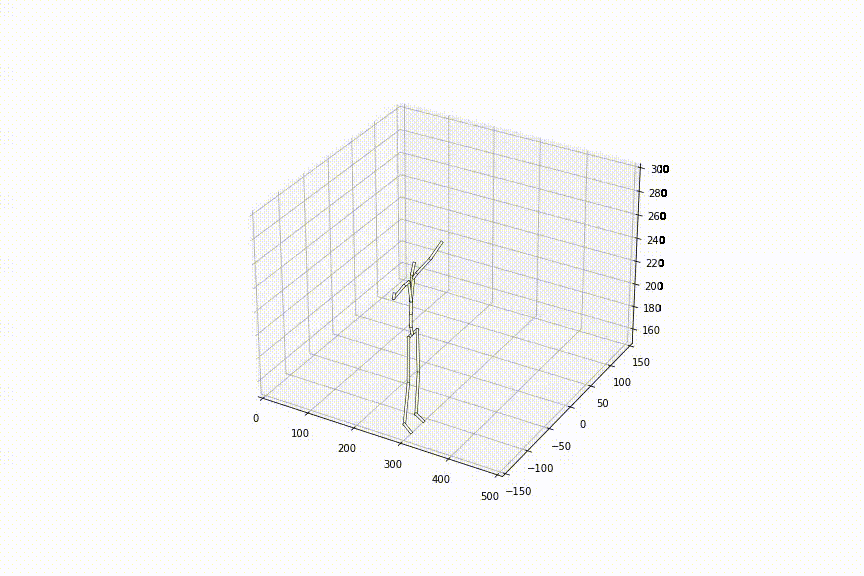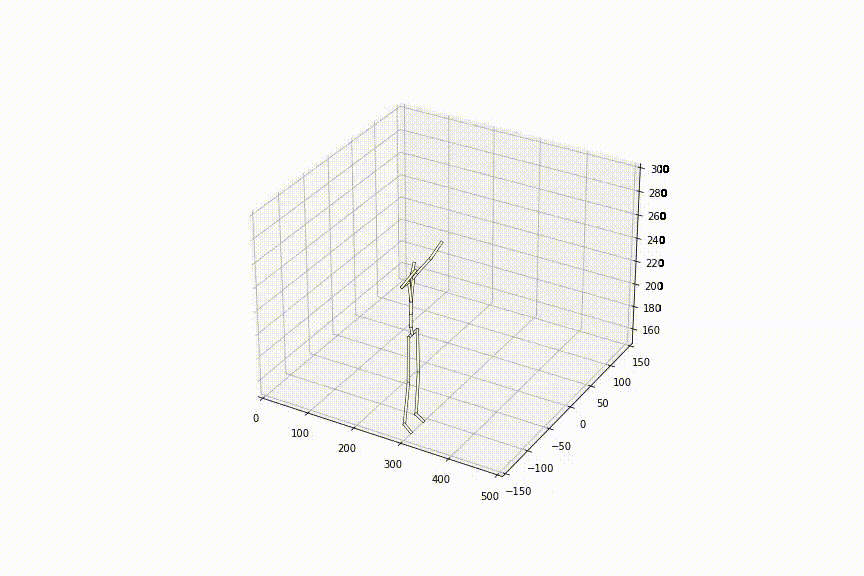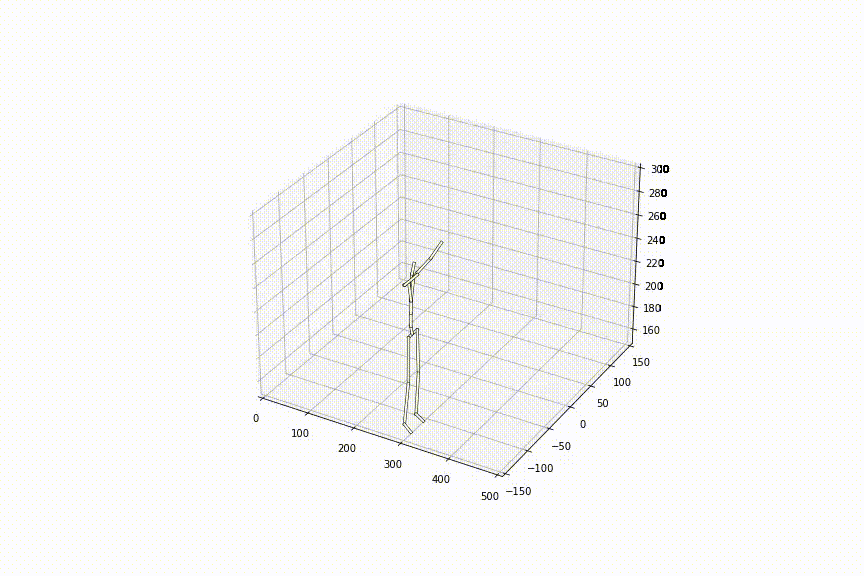
3.同じ初め/終わりの姿勢から、異なるシークエンスを生成できる
同じ初め/終わりの姿勢を入力としても、中間の特徴量ベクトルに乱数などを加えることで、異なるシークエンスをいくつも生成することができます。これにより、当初の課題である、同じ人でも毎回動きは異なるはずだ、という人間の動きの特徴に対応することができます。下の動画は同じ姿勢を入力とし、加える乱数を変化させた結果です。少しわかりづらいですが、足をあげる大きさなど、少し動きが異なっていことがわかります。
今後の展望
今後の課題として、以下のようなことを考えています。
1.特徴量ベクトルに次元削減以上の意味を持たせる
特徴量ベクトルに可愛らしい・かっこいい・子供っぽい・大人っぽい・疲れている・元気になどの意味を持たせることで、そのような動きのニュアンスを加えるように特徴量ベクトルに値を加え、同じ指示でもそのキャラクターや状況に応じた動きをできるようになることができると考えています。このことが可能になれば、バーチャルヒューマンがそれぞれの個性をもった動きをさせることが可能になります。
2.さらに長いシークエンスを生成できるようになる
現在は単純な「手をあげる」などのシークエンスを生成できるに留まっていますが、より長い意味を持った指示(「走っていって、バスケットゴールにシュートして」など)から、キーフレームのシークエンスを作成し、そのキーフレーム間を補間することができれば、より長いシークエンスを生成することが可能になります。
おわりに
今回のインターンシップは、新型コロナウイルスの影響から、ほとんどリモートで実施されましたが、メンターの方にSlack上で頻繁にコミュニケーションをとっていただき、研究に必要になるGPUサーバーも専用のものを用意していただいたため、不自由さを全く感じずに業務を行うことができました。また、インターンの最初と最後にはCVLの方々とオンラインでの交流会を開いていただき、チームの方々とも交流をすることができた上、人事の皆様が、インターンシップ交流会を開催して下さったこともあり、インターン同期の方とも交流することができました。
また、本インターンシップでは、企業にてAIの研究開発がどのような目標のもとに行われているのか、AI研究とビジネスとのつながりなどについて、6週間を通してじっくりと経験させていただき、大きな学びとなっただけでなく、今後のキャリアを考える上でも非常に大きな経験となりました。また、交流会の際には、Computer Vision分野に携わる方々から、興味深いお話もしていただき、とても楽しく、有意義な時間を過ごすことができ、このインターンシップの期間中に関わっていただいた全ての方には感謝してもしきれません。
6週間という長期のインターンシップですが、長いようであっという間に過ぎてしまいました。今後も、このインターンシップで得た経験を、大学での研究、今後のキャリアに活かしていければと思います。本当にありがとうございました。
参考文献
- C3DPO: Canonical 3D Pose Networks for Non-Rigid Structure From Motion (Novotny+ ICCV2019 Oral)
- Language2Pose: Natural Language Grounded Pose Forecasting (Ahuja+ 3DV 2019)
- Action2Motion: Conditioned Generation of 3D Human Motions (Guo+ ACM 2020)
- Action-Conditioned 3D Human Motion Synthesis with Transformer VAE (Petrovich+ ICCV2021)
- Ubisoft motion capture dataset https://github.com/ubisoft/ubisoft-laforge-animation-dataset