
はじめに
こんにちは、電気通信大学 学部3年生の佐々木です。8/16から約6週間、技術職 就業型コースのインターンシップに参加しました。
私は、VRE(Verda Reliability Engineering)チームに配属され、Verda Resource Operatorの実装に取り組みました。
VerdaとVREチームについて
VerdaとはLINEがもつPrivate Cloudのことです。
Verdaでは、物理サーバーをOpenStackによって管理し、様々なサービスをLINEの開発者に提供しています。
提供するサービス毎にチームが存在し、Kubernetes as a Serviceを提供しているチームもいれば、LoadbalancerやNATを提供しているチームもあります。
VREチームでは、そういったチームが開発や運用を効率化するための施策を横断的に行っています。
より詳細な話はこちらの記事に詳しく載っているので、興味のある方は是非ご覧ください。
https://gihyo.jp/dev/serial/01/line2021/0008?page=1
Verdaのリソース管理について
インターンに参加してVerdaを触らせてもらったのですが、Verdaはユーザーの観点から扱いづらい点がありました。
それは、Verdaのリソースの操作はWebUIから行われることが想定されており、リソース管理のためのツールが提供されていないことです。
これでは、ユーザーはクラウドのリソースをWeb UIから直接操作することとなり、次のようなデメリットが発生します。
- オペレーションミスが発生しやすい
- リソースの作成、更新時にプロパティの指定を間違える
- リソースの削除時に削除する予定のないものを削除する
- リソースの変更を追いづらい
- 構成の全体感と依存関係を把握しづらい
これはVerda固有の問題ではなく、どのクラウドでも発生する話であり、それぞれのクラウド事業者はリソースをコードで管理するためのツールを提供しています。
例えば、このようなツールです。
- AWS Cloud Formation
- Deployment Manager(GCP)
- Azure Resource Manager
また、クラウドに依存しないツールではTerraformというツールが主流です。
もう1つ、近年流行しはじめているのが、Kubernetes Operatorによってリソースを管理する手法です。
各クラウド事業者も実装の提供を開始していますが、まだ全てのリソースに対応できてはいないようです。
- GCP: https://github.com/GoogleCloudPlatform/k8s-config-connector
- AWS: https://github.com/aws-controllers-k8s/community
- Azure: https://github.com/Azure/azure-service-operator
ただ、リソース管理の手法としてはTerraformよりもKubernetes Operatorの方が良い点がいくつかあるので、インターンではそちらを実装することにしました。
Kubernetes Operatorによるリソース管理
具体的に、Kubernetes Operatorによるクラウドリソース管理が従来の方式とどう違うのか、Terraformとの比較を例に説明します。
TerraformはHashiCorp社が開発しているIaCツールです。
拡張性が高く、主要なクラウドのリソースからSaaSのリソースまで様々なリソースを管理することができます。
リソース定義をconfigurationとしてHCLという特有の形式で記述し、applyコマンドを実行することでコードとクラウドリソースの差分を検出してクラウドリソースを定義した状態に調整します。
Kubernetes Operatorとは、カスタムリソースとカスタムコントローラーによってKubernetesを拡張し、アプリケーションの運用を自動化するためのデザインパターンのことです。
カスタムリソースに定義した「望ましい状態」=specを参照して、コントローラーが「現在の状態」=stateをspecに合わせるようにリソースの調整を実行する仕組みになっています。
これをクラウドリソースの構成管理に応用して、クラウドリソースをカスタムリソースとして定義し、その定義した内容とクラウドリソースの実体を比較して調整を実行することで、リソースの作成、編集、削除などを行ないます。
どちらの手法であっても、クラウドリソースの運用にあたって発生するオペレーションに違いはありません。
- Terraformであれば、コードを変更してterraform applyコマンドを実行することによりクラウドのリソースが更新されます。
- Operatorであれば、コードを変更してkubectl applyによってカスタムリソースを更新することでカスタムコントローラーによりクラウドのリソースが更新されます。
いずれにしろ、コードを変更してそれをコマンド等で実際に適用するという流れは同じです。
TerraformとOperatorの違いはオペレーションではなく、リソース定義を適用した後の管理方法にあります。
Terraformがリソースの操作を構成の適用時にのみ実施することに対して、Operatorは継続的にリソースが目的の状態であるように調整を行います。
これにより、人の手を介さずにクラウドの構成を正常な状態に維持することができます。
また、Operatorによる管理にはもう1つメリットがあります。
それは、Kubernetesによって全てを管理することができるということです。
アプリケーションはKubernetes上で動いて、Kubernetesのマニフェストで管理しているけど、MySQLやRedisはクラウドのリソースを使っているので、Terraformを使って管理しているというケースはよくあると思います。
ここでインフラの管理に複数のツールを使っていると、それぞれの使い方の学習、ツールに更新があった場合の追従、それぞれのツール用のCI/CDパイプラインの構築、それらのメンテナンスなど様々な点でコストがかかります。
しかし、全てをKubernetesに統一することでオペレーション手段を一本化し、それらのコストを下げることができます。
実装
Operatorをどのように実装するのがよいのか調べてみたところ、2021年9月現在では、kubebuilderかOperator Frameworkを使って構築するのが一般的なようでした。
Operator Frameworkはkubebuilderを内部的に使っており、kubebuilderをベースに追加の機能が提供されているようなので、Operator Frameworkを使って実装することにしました。
Operator Frameworkを使うことで、諸々の必要なコードは生成され、リソースの調整ロジックだけを記述するだけでOperatorを構築することができます。
今回実装したリソースはVirtualMachine, VirtualMachineGroup, LoadBalancerの3つです。
元々はVirtualMachine, LoadBalancer, DNSあたりのリソースを実装する予定でした。この3つのリソースはVerda内での使用率が他のリソースに比べて高く、それぞれのリソースが依存関係を持っているので、この仕組みで運用を楽にできるケースが多いと考えたためです。
Loadbalancerを例に挙げると、現在のVerdaのUIではWebUIもしくはhttp apiでの設定しかサポートされておらず、設定時に配下のVMのhostnameやIPなどを意識する必要があります。もしOperatorで設定できるようになると、LoadBalancerのリソースにVirtualMachineのリソース名を関連付けることで、具体的なホストネームを意識しなくともLBの設定を実施することができます。
DNSも同様にLoadBalancerのIPをレコードに登録するユースケースが多いので実装候補として挙げられましたが、「複数のVMを1つのLoadbalancerに登録する」ケースをもっと便利に扱えるように「複数のVMをグループとして抽象化する」という機能開発を優先することにしました。
各リソースの詳細について、実際のマニフェストを見つつ紹介していきます。
VirtualMachineリソースは、特別な処理は特にしておらずWebUIの設定項目をそのまま設定できるようにしたものです。
VerdaではVMの作成はOpenStackのcompute APIを使っているようなので、Operator側からもcompute APIを使ってVMの作成を行いました。
将来的に、initScriptは長くなるケースを想定して、ConfigMapで設定できるようにしようと考えています。
virtualmachine.yaml
apiVersion: verda.linecorp.com/v1alpha1
kind: VirtualMachine
metadata:
name: vm-sample
finalizers:
- virtualmachine.verda.linecorp.com/finalizer
spec:
image: centos79
flavor: "n3-1vcpu-2gb"
initScript:
value: "ls"
description: "generated operator"次に、VirtualMachineGroupについて説明します。
このリソースは、VerdaのHAグループを拡張したリソースです。
Verdaではデータセンターレベルの障害があった場合でも、サービスを維持できるように複数のVMをグループとしてまとめて複数のデータセンターに散らばるように制御するためのHAグループという機能があります。
GCPやAWSのインスタンスグループのように、ここでグループとしてまとめらたVMは当然、同一の処理を実行するのですが、負荷が高くなった時に台数を増やして1台あたりの負荷を下げるためにスケールアウトを行うことが多いです。
こういったケースに対応するために、OperatorによるVirtualMachineGroupはもともとHAグループが持っていたHAの制御に追加してVMグループのスケールの機能を実装しました。
具体的なspecを解説すると、VirtualMachineGroupはspec.templateで定義されたVMの仕様でspec.replicasに定義された台数分VMが存在するように維持します。
ちょうどReplicaSetとPodのような関係のリソースです。
HAの制御のポリシーはspec.haPolicyによって定義されるのですが、これはOpenStackの機能に任せています。
virtualmachinegroup.yaml
apiVersion: verda.linecorp.com/v1alpha1
kind: VirtualMachineGroup
metadata:
name: virtualmachinegroup-sample
finalizers:
- virtualmachinegroup.verda.linecorp.com/finalizer
spec:
replicas: 2
haPolicy: "soft"
template:
image: centos79
flavor: "n3-1vcpu-2gb"
initScript:
value: "ls"
description: "generated operator"次に、LoadBalancerについて説明します。
こちらは基本的には、WebUIの設定項目に準じているのですが、VirtualMachineGroupのリソースを直接LoadBalancerに紐づけることが可能になっています。
これにより、VirtualMachineGroupをスケールさせた場合でも自動的にLoadBalancerに新しいVMを紐づけることができます。
実装的には、spec.ports[].realServersに関してVerda側とKubernetes側で同期が取れているか確認を取る際に、VirtualMachineGroupとそれに紐づくVirtualMachineをfetchしてそれらがVerda LoadBalancerに紐づけられているかを確認しています。
loadbalancer.yaml
apiVersion: verda.linecorp.com/v1alpha1
kind: LoadBalancer
metadata:
name: loadbalancer-sample
finalizers:
- loadbalancer.verda.linecorp.com/finalizer
spec:
description: "generated operator"
region: tokyo1
zone: dev
vipType: private
serviceType: generic
ports:
- port: 80
protocol: http
# option:
realServers:
protocol: http
port: 80
virtualMachineGroupRef: virtualmachinegroup-sample
monitors:
- protocol: http
port: 80
endpoint: "/health/alive"
- protocol: https
port: 80
endpoint: "/health/ready"
- port: 443
protocol: https
# option:
realServers:
protocol: https
port: 443
virtualMachineGroupRef: virtualmachinegroup-sample
monitors:
- protocol: https
port: 443
endpoint: "/health/alive"
- protocol: https
port: 443
endpoint: "/health/ready"今回の実装で、LoadBalacerの後ろにAPI Serverが動いているVMをぶら下げてそれらをスケールさせるというユースケースをOperatorによって制御することができるようになりました。
具体的な挙動を図に起こすと次のようになります。
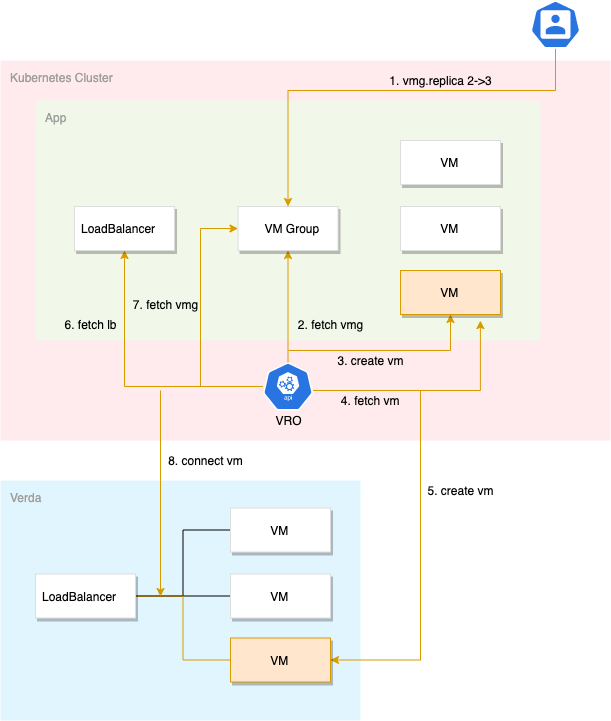
ユーザーはVM Groupのreplicaを2から3に変更します。
それによりOperatorはVM Groupの変更を検知して、VMリソースを1つ追加します。
また、その追加を検知してOperatorはVerda VMを1台作成します。
Operatorは定期的に各リソースに対して調整を行うので、一定のタイミングでLoadBalancerに差分がないか確認します。
今回の場合、Verda LoadBalancerに紐づいてるVMの数とVM Groupに紐づいてるVMの数に差分があるので、それの修正のために新しいVMをLoadBalancerに紐づけます。
以上により、ユーザーはVM Groupのreplicasを変更するだけでAPI Serverをスケールさせてそれを自動的にLoadBalancerに紐づけることが可能になりました。
今後の展望
今後の展望としては、次の2つを達成したいと思っています。
1つは利用できるリソースの種類を増やすことです。
システムを構築する上で、必要なリソースがOperatorで提供されていなければ、結局WebUIから操作する必要があり、Operatorを使う意味がありません。
そのため、Verdaで提供されているリソースを一通りカバーすることが必要です。
もう1つはこのOperatorを組み込んだアプリケーション基盤や運用プロセスの普及です。
このようなOperatorの一般的なユースケースとして、k8s上でアプリケーションと周辺のインフラリソースを一貫して管理するケースが挙げられます。
例えば、ArgoCDなどのCDツールを使うことでアプリケーションとインフラの構成情報をすべてk8sのmanifestとして管理することができ、必要なオペレーションをGit上の操作で完結させることができるようになります。
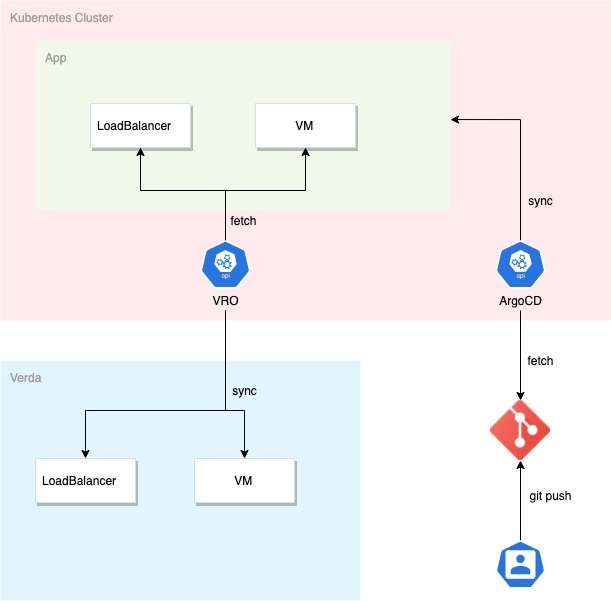
ただ、ユーザが上記のような実装を導入するためには、大きく分けて以下の3種類のオペレーションについてユーザが習熟している必要があります。
- Kubernetes Clusterの構築・運用
- manifestの記述、構成管理
- CD環境の構築
Verdaではk8s as a serviceを提供しており、1つ目については基本的にユーザが運用を実施する必要がありません。
また、最近Shared k8s clusterをユーザに向けて提供し始めており、Ingressなどのネットワーク周りの設定やコンテナビルドなどに便利なTekton Pipeline環境もマネージドなサービスとして一貫して提供できるようになりました。
ただ、上記のようなサービスはLINE社内でもアプリケーションインフラとして導入してないプロジェクトが多数あるのが現状のようです。
そのため、このOperatorをユーザ環境に簡単に導入できるような仕組み(コマンド1つでアドオンとして導入できるなど)やk8s運用をサポートするドキュメントの整理、社内のArgoCD基盤との連携もしくはユーザ環境へのArgoCDの導入の簡易化などを通して新しいサービス基盤の導入障壁を下げるような取り組みを進めることで、ユーザが積極的に信頼性と運用効率の高い仕組みを導入することを推進する活動が重要になっていくと考えています。
おわりに
今回のインターンでは、オペレーターを実装する中でVerdaに触れクラウドの内側がどのように作られているかが垣間見え最高のインターンでした。
クラウドに興味のある学生であれば、是非参加してみることをお勧めします。
最後に、受け入れてくれたVREチームの皆さんありがとうございました。