
はじめに
初めまして!LINEの2021年度夏季インターンシップ「技術職 就業型コース」に、8月から9月の計6週間で参加させていただいた高島空良と申します。私は現在、東京工業大学情報理工学院情報工学系の修士1年で、大学では大規模データセットを用いた並列分散深層学習についての研究に勤しんでいます。
今回のインターンシップでは、LINE株式会社のAIカンパニー/AI開発室という部署に所属し、メンターとして同部署所属の四倉晋平さんにご指導していただきました。「AI開発室」というゴリゴリにAIの研究開発をしている部署ですが、私がインターンで取り込んだ内容はAIそのものの研究開発ではなく、既存AIを活用したアプリケーションやシステムを構築する上で必要な技術要素の開発で、職種としてはいわゆる機械学習エンジニアではなくインフラ/サーバーサイドエンジニアに近しいことをやりました。
今回のインターンでは、タイムラプス作成等の動画像処理や機械学習関連の処理のような「長時間を要する高負荷な処理」を複数同時に扱う大規模なサービスを提供するために、複数処理を複数サーバーに並列分散して高速化できるシステムを開発しました。本レポートでは、開発上使用した主要な技術要素に触れつつ、開発物についてご紹介したいと思います。
開発目的、要件
今回のインターンの目的は、機械学習関連の処理や動画像処理に代表されるような一つ一つの処理が重いタスクを、複数同時に捌くことが可能な分散処理システムを開発することでした。システムを実現するアーキテクチャを考えるところから、実際に利用可能なシステムを実装してデプロイするところまでを行いました。開発した分散処理システムの要件を以下にまとめます。
- 要件1:同時に発生し得る処理が重い複数タスクの非同期処理が可能であること
- クエリ受付サーバーが重いタスクの処理を待たなくていいこと
- 複数のサーバーで重いタスクを分散並列処理できること
- 要件2:システムを構成するサーバーの分散化、及びタスクの追加拡張や実装管理が容易に可能であること
- システムの各構成サーバーのスケーリングが簡単にできること
- 新しい機械学習モデルを用いた処理などの追加処理をシステムに組み込むことが容易であること
今回は、要件1を満たすために、処理が重いタスクを非同期かつ複数処理可能なアーキテクチャとして「タスクキュー」を用いました。また、要件2を満たすために、Docker コンテナで構成されたサービスを容易に管理できるプラットフォームである「Kubernetes」を用いました。それぞれの技術の詳細について次節で説明します。
タスクキューとは
タスクキューとは、複数タスクの非同期分散処理を得意とする、データ構造としてキューを採用したタスク管理アーキテクチャの一種です。タスクキューを用いたシステムの処理の概要図を以下に図示します。ここで、矢印は各要素間の通信方向を示しています。(タスクが移動する向きではないことに注意してください。)

タスクキューを用いたシステムを構成する各要素は、以下のことをそれぞれ行います。
- Client:タスクの受付/発行、Broker へのタスクのエンキュー要求
- Broker:キューを用いたタスクの管理
- Worker:タスクを持っている状態ではタスクの処理、タスクを持っておらず暇な状態では Broker に定期的な通信(ポーリング)を行って、キューにタスクが溜まっていれば Broker へのタスクのデキュー要求
タスクキューを使用する場合、以下に列挙するようなことが簡単に実現できるというメリットがあります。
- タスクの非同期処理
- 長時間かかるタスクの処理を Worker に委託して行えるため、Client はタスクの受付作業に専念できます。
- Worker がタスクを処理しきれなくなっても、タスクを実行しないでキューに取り敢えずためて待たせておくことができます。
- タスクの分散処理
- 上図のようにタスクキューは、Broker として用いられるメッセージキューイングプラットフォームと並列分散された Worker を組み合わせることによって、複数のタスクを複数の Worker に負荷分散させて処理する機能を獲得することが出来ます。このように Client と Worker の間のタスクの中間管理を Broker に委託させるため、Client は Worker の状態の如何に関わらずタスクのエンキューを Broker に要求するだけで負荷分散機能を実現できます。
- キューを用いずに Client から Worker に直接タスクを投げる非同期分散処理の場合、タスクをうまく分散させるためにタスクの投げ先 Worker の選定が必要であったり、Worker の状態を確認する必要があったりと、負荷分散機能の実装コストが高くなります。
- 自動リトライなどのタスク管理
- 例えば、タスクが Worker の緊急停止など不測の事態で失敗した場合、タスクをキューに入れ直してリトライ実行を行う必要がありますが、Broker として用いられるライブラリには、失敗に終わったタスクの自動リトライ機能があらかじめ備わっているものがあります。これを用いると、Client はタスクをエンキューした後はそのタスクについて気にせずに良く、Worker も同様にタスクの処理以外の部分に関してタスクの面倒を見る必要がなくなり便利です。例えば、Broker を構成する際に、メッセージキューイングプラットフォームとして Redis を、その Python ラップライブラリとして RQ を使用した場合、以下のコードのようにしてタスクのエンキューを行います。
enqueue task
# enqueue task
task = queue.enqueue(
task_function, # task function
args=(arg1, arg2), # arguments of task function
on_failure=tasks.report_failure, # if fail in task, call this function
retry=Retry(max=2), # retry up to 2 times
task_timeout=600 # default task timeout : 600 sec
)このように、オプショナルな引数と共にタスクをエンキューすることによって、簡単に自動タスクリトライ機能の実装やタスクのタイムアウト設定を行うことが出来ます。
Kubernetesとは
今回の開発では、システムを構成するサーバーの分散を含めたデプロイを容易に行うために、Kubernetes という、システムのリソースや環境を自動で管理運用するためのオープンソースプラットフォームを用います。Kubernetes を用いると、システムの構成要素を Docker image としてコンテナ化し、それぞれのコンテナに期待される仕様(必要な資源や容量、立ち上げるサーバーの数など)を deployment config として宣言的に記述するだけで、冗長性を持った分散サーバー群を簡単に構築してシステムとして運用することが出来ます。本来、サーバーを分散(スケーリング)させるために複数立ち上げる際には、手動で関連する VM を一つ一つ環境構築して起動する必要がありますが、Kubernetes を利用することでその手間を大幅に省くことが出来ます。
今回の開発に関連する Kubernetes の主要な機能として以下のようなものがあります。
- 分散処理可能な複数コンテナの立ち上げ
- 複数タスクの分散処理を実現するという今回の開発要件を満たすために、タスク処理を担う Worker の並列分散化やスケーリング数の変更を容易に行える必要があります。Kubernetes を使用すると、コンテナのスケーリングの適用やスケーリング数の変更は config 中の1行の記述変更のみで非常に簡単に行えるため、今回の開発に適しています。
- 異なる環境を使用する新規コンテナの追加
- 今回開発するシステムでは、異なる環境で動作する複数タスクの追加拡張を想定しています。この際には、異なる環境のコンテナも Docker image を使用して容易に立ち上げて管理することができる Kubernetes の機能が便利です。
実装した分散処理システムのアーキテクチャ
アーキテクチャ概要
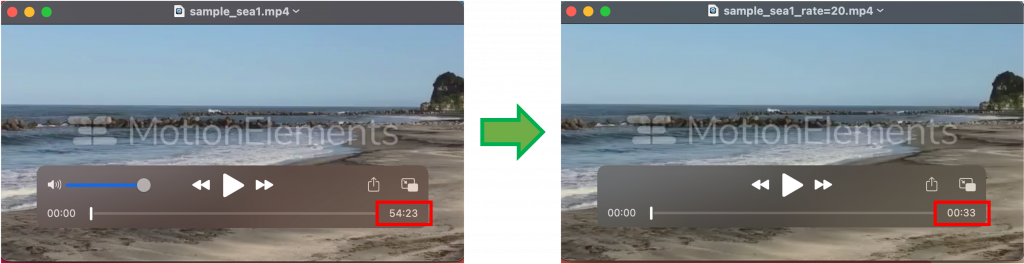
ここでは、実際に開発した分散処理システムのアーキテクチャの概要について説明します。今回は分散処理するタスクの一例として、長時間の動画を短時間のタイムラプス動画に変換してオブジェクトストレージ上に保存するタスクを取り扱いました。例えば、20フレームに1回のペースで元動画から画像を取得し繋ぎ合わせることによってタイムラプス動画を作成した場合、下図で示すような変換となります。この場合、動画を20倍速でコマ早送りさせるようなイメージで、作成するタイムラプス動画の長さは元動画の1/20の長さになります。
開発した分散処理システムのインターフェースは、HTTP クエリを受け付ける Web API となっています。API のクエリは以下の通りです。
- Upload Movie:ユーザーがオブジェクトストレージ上に処理したい動画をアップロードするクエリ
- Create Timelapse:ユーザーが Upload Movie クエリでアップロード済の動画をタイムラプスに変換してオブジェクトストレージ上に新規アップロードする、分散処理が必要な今回のメインのタスク処理クエリ
- Check Task:ユーザーが投げたタスクの進行状況を確認するクエリ
- Download Movie:ユーザーがオブジェクトストレージ上に保存された動画をダウンロードするクエリ
開発した分散処理システムで使用した技術要素を以下の表にまとめます。
| 開発言語 | Python |
| APIフレームワーク | FastAPI |
| タイムラプス作成処理 | OpenCV |
| Broker | Redis |
| タスク情報管理DB | MySQL |
| API/Worker Server のコンテナ管理 | Kubernetes |
続いて、開発した分散処理システムのアーキテクチャの概略図を下に示し、大まかな処理の流れを説明します。
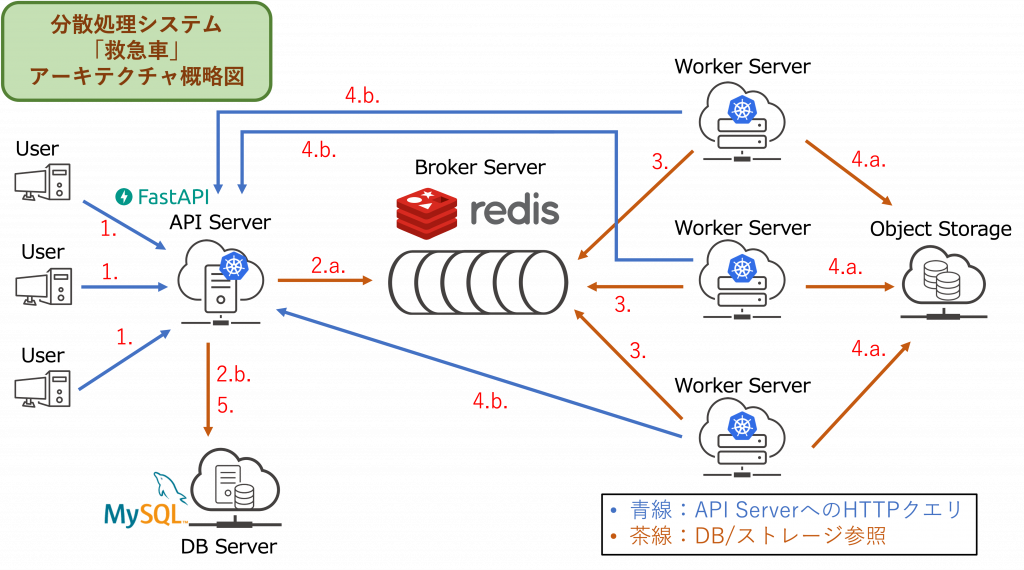
- 分散処理システムのタスク処理フロー(各処理は、上記概略図中の同じ番号の矢印の通信と対応しています。)
- ユーザーが API Server に対して Create Timelapse クエリを発行
- ユーザーから Create Timelapse クエリを受信した API Server は以下を実行
- Broker Server に対してタスクのエンキューを要求する。
- タスク情報管理DBにタスクを登録。タスクの処理状態を処理中にする。
- 1. で受信したクエリのレスポンスとして、タスクIDをユーザーに返答。タスクIDは、ユーザーがタスクの進行状況確認や保存動画のダウンロードを行う際に使用される。
- タスク待ちの Worker Server が Broker Server に定期的に通信して、タスクのデキューを要求。(それぞれタスクをデキューできたらタスク処理(タイムラプス動画作成)を開始する。)
- タスクが完了した Worker Server は以下を実行
- オブジェクトストレージ上に作成したタイムラプス動画を新規アップロード
- API Server にタスクの処理状態及び動画アップロード先PATHを通知
- Worker Server からタスクの終了通知を受信した API Server はタスク情報管理DB上のタスク情報を更新
上記タスク処理フローの 2.a. と 3 の処理が、タスクキューを用いた分散処理を行っている箇所です。
余談なのですが、上図の左上にも示されている通り、今回開発したシステムにせっかくなので名前をつけてみました。その名も『救急車(Queue-Queue-sya)』です。由来としては、単純に名前に「キュー」が含まれているのと、救急車が「複数の重症者を複数の病院に分散」して搬送するように「複数の重い処理を複数のサーバーに分散」してほしいという願いを込めました。テキトーにでも作るものに名前をつけると、なんだか愛着が湧いてきて頑張って良いものにしようという気になってきますね。
負荷分散実験 (Worker Server のスケーリング)
開発した分散処理システムのタスク分散による高速化効果を確かめるために、負荷分散実験を行いました。実験の中で、Worker Server をスケーリングした際に、複数のタスクが分散されて並列実行されていることを確認しました。また、Worker Server のスケーリング数を増やした際に、同量の複数タスクの総処理時間がスケーリング数と反比例するように減少することを確認しました。以下に実験の詳細を示します。
- 実験設定
- 1タスク約30秒で終了するタイムラプス動画作成タスクを128個同時に分散処理システムに投入し、総処理時間を計測しました。ここで総処理時間とは、1個目のタスククエリを API Server が受信してから、128個目のタスクの処理が終了するまでの時間を指します。
- 変化させるパラメータは Worker Server のスケーリング数のみで、スケーリング数を 1, 2, 4, 8, 16 と変動させて実験しました。
- 実験結果
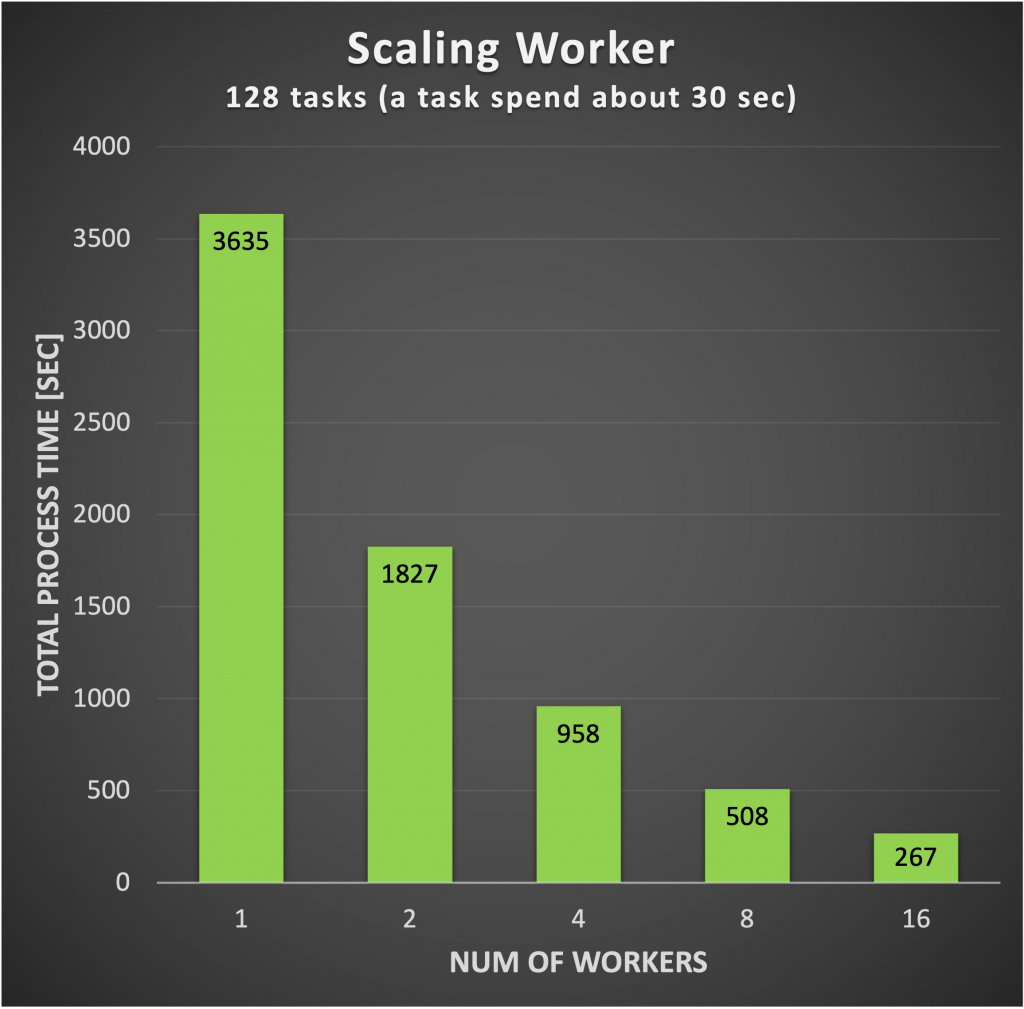
実験結果より、スケーリング数を2倍にすると総処理時間がほぼ半分になっていることが分かります。よって、タスクの総処理時間がスケーリング数と反比例するように減少することが実験的に分かり、開発した分散処理システムのタスク分散効果を確認することが出来ました。
今後の開発展望
今回開発した分散処理システムはタスクの拡張性や応用性が高く、タスクの一例として実装したタイムラプス動画作成タスクに限らず、様々な重いタスクの分散並列処理を行うことが出来ます。
新規タスクの追加は、以下のような手順で行うことが出来ます。
- 追加するタスク用に Broker で管理するタスクキューを1本新規追加
- 追加するタスクを関数として記述
- 追加するタスクのエンキュー先を1. で追加したタスクキューに指定
上記手順の 1. と 3. のタスクキューを増やしてタスクに対応させる実装は非常に容易であり、実質的には追加するタスクを関数として記述することさえ出来れば、簡単に新規タスクの追加拡張が可能です。
新規に拡張するタスクとして、機械学習の推論タスクなどを扱うことも出来ます。この時、異なる機械学習モデルを使用する複数のタスクをうまく分散処理するためには、異なるモデルごとにあらかじめモデルのビルドを完了させてある Worker Server が複数必要となります。このようなケースにおいても、今回実装した分散処理システムは Kubernetes によるデプロイを採用しているため、異なる環境で異なるタスクを処理する Worker Server を分散させた状態で立ち上げることが容易に出来ます。また、Kubernetes は深層学習モデルの学習や推論と相性の良い GPU などのアクセラレータをコンテナのリソースとして選択することも可能なため、その点でも機械学習との親和性が高いです。
異なる環境の Worker Server の複数立ち上げは、以下のような手順で行うことが出来ます。
- 環境ごとに Docker image を作成
- Kubernetes の deployment config の中に、異なる環境を使用する Worker ごとにコンテナの設定を記述して反映
- ここで、1. で作成した対応する Docker image を pull するように設定する。
- スケーリング数などもここで容易に指定可能。
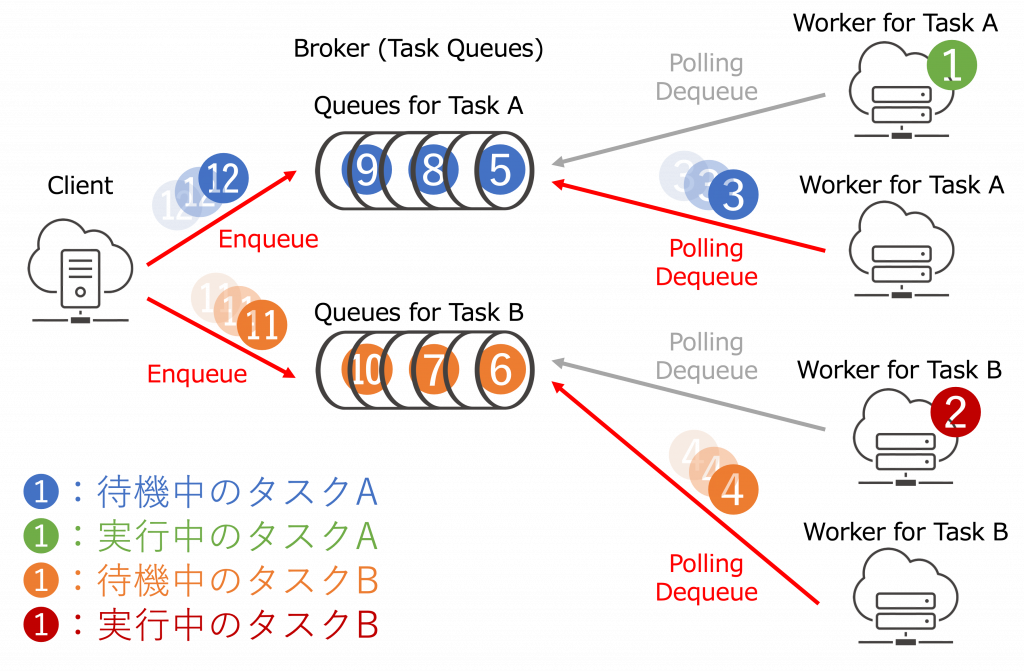
以上を踏まえて、例えば、「タスクA」を処理する分散処理システムに「タスクB」という新規タスクを追加拡張した際のタスクキューの処理は、以下のように図示出来ます。
おわりに
最後に今回のインターンシップで得られた学びや、所感を記します。
- 「なぜ」を考える重要性
- 今回のシステムを設計する段階で、「なぜこの実装方針を採用するのか」や「なぜこのソフトウェアを使用するのか」などの技術選定の理由を、各技術の調査をした上でじっくり考えました。「なぜ」を考えることは、関連技術の具体的理解を経て得られる知見や洞察を深化できる上に、開発目的をしっかり意識した上で高いモチベーションを持って開発を行うことにつながり、結果として開発そのものや成果物の質向上に貢献することを学べました。
- 迷ったら強い人に質問しよう!
- 自分だけで解決しようとすると1日潰れるような問題を知見のある方に質問すると10分で解決、みたいなケースは非常に多いです。30分〜1時間程度考えて「何もわからん」状態のままの場合は、間違った解にたどり着いたり時間を無駄にしたりすることを回避するためにも、萎縮せずに質問をするべきだなと感じました。
- リモートワーク最高!
- 完全リモートの形態でのインターンシップとなり実施前はコミュニケーション面で不安を抱えておりましたが、メンターさんのお計らいで、勤務日は毎日朝夜2回オンライン通話にて自由にお話しする時間を設けていただけるなど柔軟な対応をしていただいたこともあり、特にリモートで働くことに関して弊害を抱えることはありませんでした。むしろ真夏の通勤ストレスなどを避けてその分時間に余裕があったり、自宅にてリラックスした状態で悠々自適に仕事ができたりと、良い面が目立った所感でした。
今回メンターを担当していただいた四倉さんが非常に丁寧な方で、社内のサービス利用案内に始まり、仕事や技術に関する助言や就活等に関する個人的な相談事、本レポートの執筆に至るまで、優しくかつ的確にご指導をしていただけてとても助かり勉強になりました。この場をお借りして深く感謝申し上げます。また、色々興味深いお話しをしていただいたAI開発室の社員様方や、インターン生活を様々な側面からサポートしていただいた人事社員様方にも併せて感謝申し上げたいと思います。誠にありがとうございました。
6週間と長期のインターンシップでしたが、最高の環境でエンジニアの仕事を丸ごと知ることができるとても有意義で貴重な経験でした。エンジニア職種に興味を持っている方には、是非とも参加することをおすすめしたいです。