
こんにちは。この度、LINE夏インターンシップ技術職就業型コースに参加させていただいた小田川拓利です。所属は東京大学大学院情報理工学系研究科で、普段は金融時系列データ解析の研究をしたり、スタートアップでフロントエンド・バックエンドを担当したりしています。今回のインターンシップでは LINE LIVE の開発をしている開発3センター サービス開発1室 開発Hチームにお世話になりました。
背景
LINE LIVE では以前よりサーバーのロードテストを行っています。LINE LIVE ではライブ配信開始時に LINE への通知を送り、LINE内やブラウザからのアクセスが行われるため、APIへのリクエストがスパイクします。そうしたケースでサーバーがどれだけ負荷を受けるのかを擬似的に再現することにより、本番環境での負荷許容範囲を調査することが出来ます。
しかし、用意されていたロードテストシナリオは、ライブ配信視聴のアクセススパイクを想定したもののみで、アプリの起動の集中を想定したシナリオが存在しませんでした。そこで、私はアプリ起動に着目したシナリオを作成し、ロードテストを行いました。
こうしたシナリオが、どういったケースを想定しているかを説明いたします。
まず挙げられるのが、強制アップデート時です。多くのユーザーはバックグラウンドでアプリを起動したままにしていると考えられますが、強制アップデートを行うとアプリが一度閉じられてしまいます。その結果、アプリの再起動が多発し、サーバーに負荷がかかる可能性があります。
また、大型配信による視聴やSNS への告知などによる流入により、アプリのホーム画面へのアクセスが一挙に集中する可能性もあります。
そして、Elasticsearch に多大なリクエストが入ってしまい Elasticsearch が詰まったことにより API サーバも詰まってサービスが停止したという過去の事例もあり、それらを事前に防ぎたいということもありました。
環境
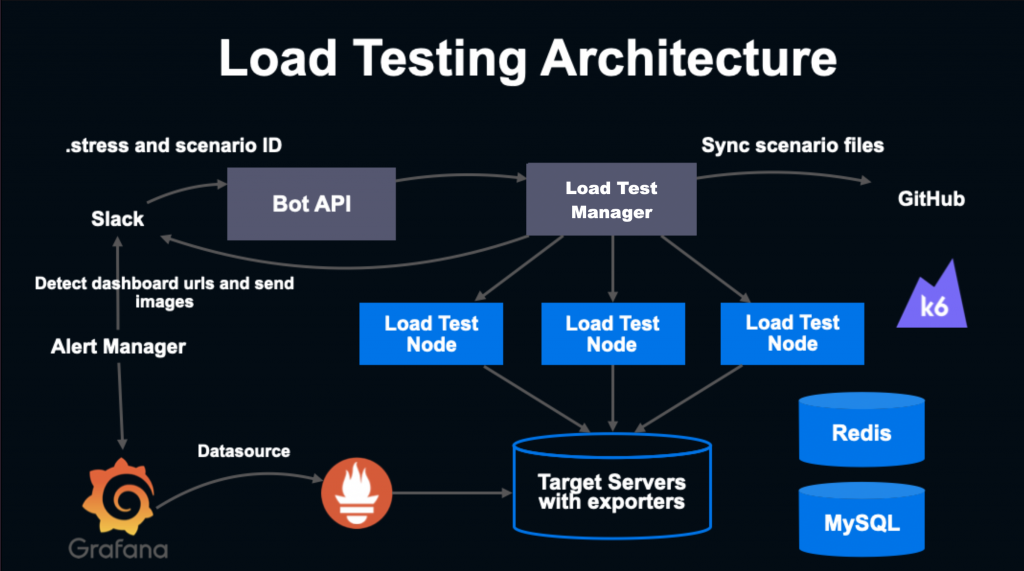
次に、LINE LIVE におけるロードテスト環境について説明いたします。
図の通りとなっていて、Slack の bot から簡単に実行でき、Grafana で可視化された実行結果も Slack に通知されるようになっています。また、 Load Test Manager はローカルでも実行可能なバイナリとなっていて、シナリオを書き換えながらロードテストを行うことも可能となっています。内部的には k6 を用いています。
実験 ①:アクセス集中時の API 応答時間の測定
上図の環境のように本番とは別の、ターゲットサーバーを用意し(本番環境が150台なのに対し今回は1台)、アクセスをスパイクさせた場合にどれだけAPIが遅延するのかを測定しました。
この1台のサーバーに対し1000端末からのリクエストを再現した実験を行いました。単純計算では、本番環境での15万端末によるスパイクと考えることが出来ます。
結果
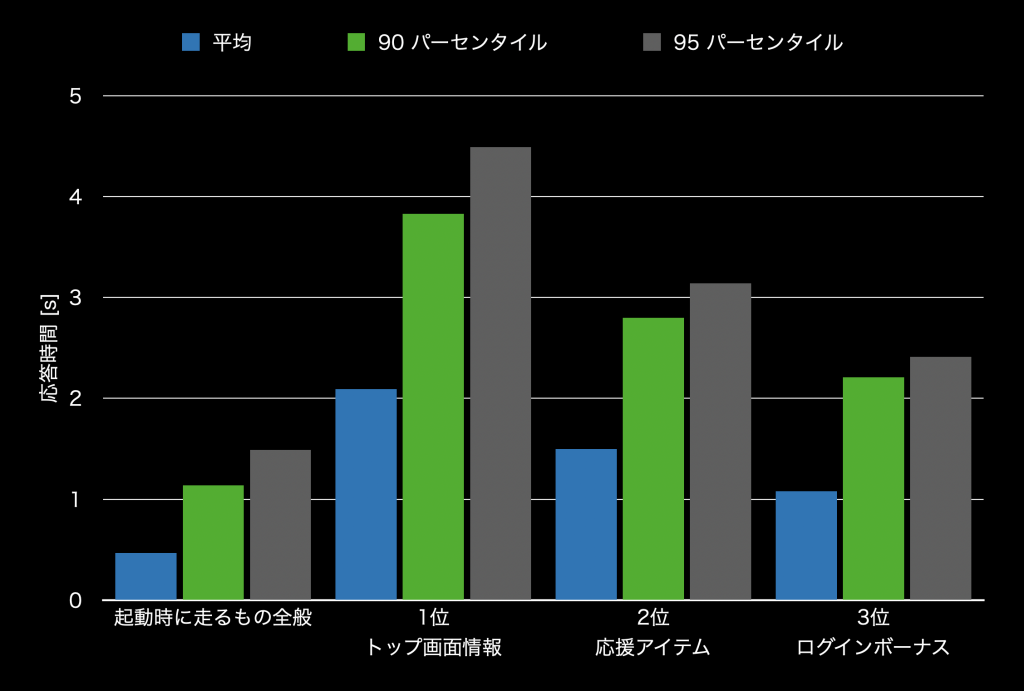
HTTPリクエストの応答時間は次のようになりました。「起動時に走るもの全般」が全ての API の平均を示しており、その他は、応答時間が長かった API を順に示しています。特定のAPIについて応答時間が長くなってしまい、全体としても応答までの平均秒数が長くなっていることが分かります。
考察
応答時間が 90パーセンタイルで1秒ほどであり、これは長すぎる結果といえます。実際の環境で障害が起こったケースは見られないので、環境の再現度が不足している可能性があります。
例えば、ロードテスト時にRedisの性能がボトルネックになった場合は、本番環境と同様の構成の負荷テスト用 Redis クラスターを構築すべきです。Kafka についても負荷テストはサポートしていないため、alpha, beta 環境と同じものを利用しています。
再現度をより高めたロードテスト環境が必要です。
もう一つの可能性として、ロードテスト環境での挙動は正しく、本番環境では本シナリオのような集中アクセスが起こっていないために今まで問題なく動作してきたという可能性もあります。この場合は、シナリオのアクセス集中が妥当なのかを検討し、妥当である場合には本番環境で対策を講じる必要があります。
また、ロードテスト環境の外部システムを模した mock サーバとの通信の部分で不具合が起きていないか検討する必要があります。
実験 ②:キャッシュの状況確認
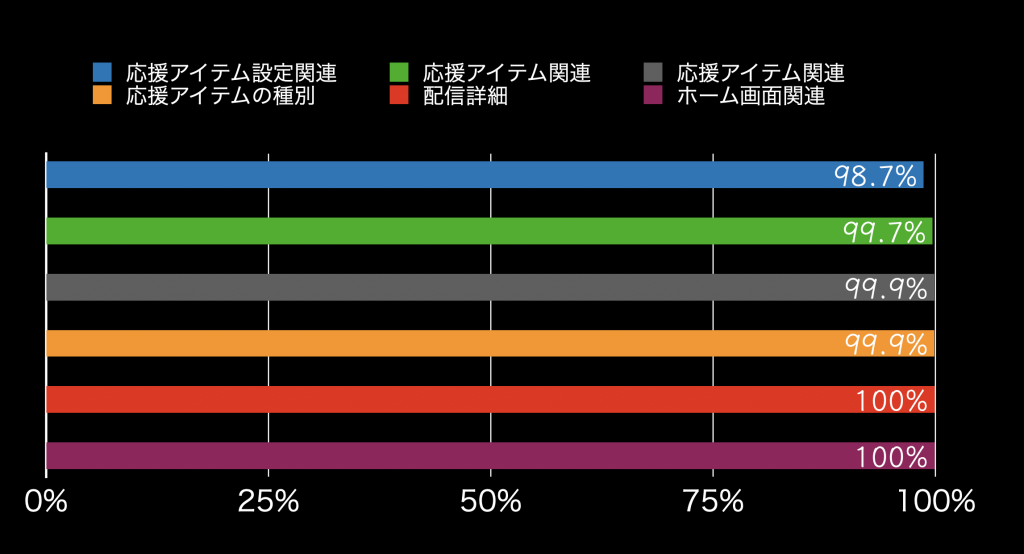
Grafana で各キャッシュのヒット率を確認したところ、以下のような6種類について、いずれも 98% 以上と適切にキャッシュが効いている事が確認できました。このことから、キャッシュのバグによる応答の遅延の可能性は低いと考えられます。
実験 ③:プロファイリング
内部的にどの部分で時間がかかっているかをプロファイリングするため、実行のフローをいくつかに分けた上で各部分に所要時間のログを仕込みました。そして、そのログを分析しその分布を可視化しました。
この際、実験 ① で計算時間がかかっている API に注目し、特に応答時間が長くなっている部分を割り出しました。その結果、
- ログインボーナスに関する処理
- レコメンドシステムとの通信
- 決済システムとの通信
で特に時間がかかっていることが示されました。
ログインボーナスに関する処理
ホーム画面の情報取得時に、アプリのログインボーナスに関する処理が走ります。この処理では、各ユーザー依存であるため必ず DB にアクセスする必要があります。さらに、場合によっては DB への書き込みも行います。このため重い処理となっていて、アクセス集中時にはパフォーマンス悪化の原因となっていました。
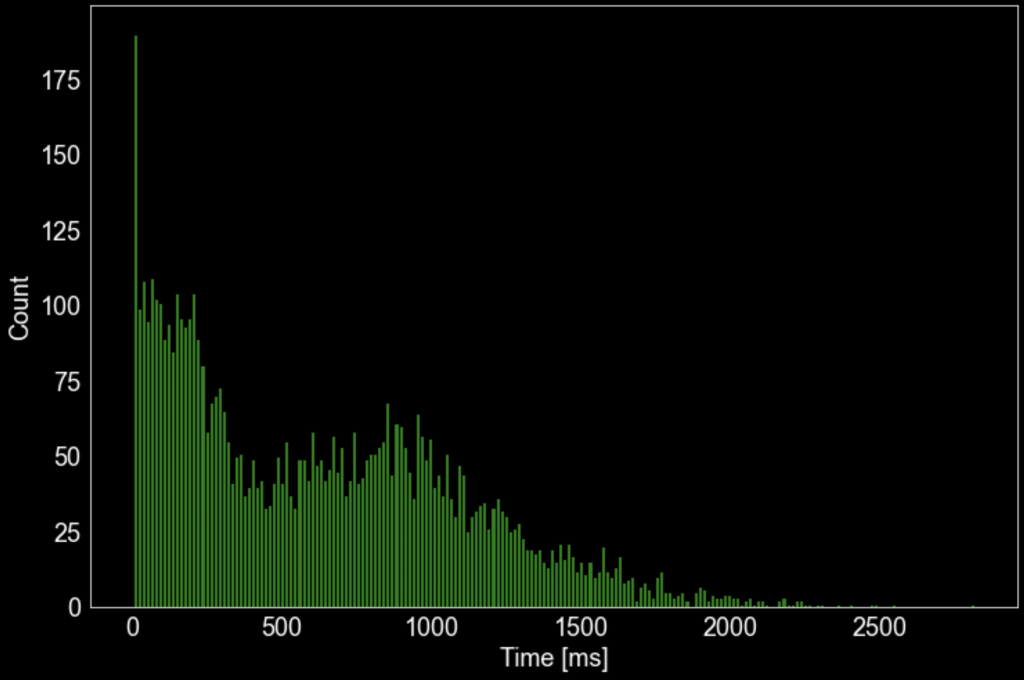
その時間の分布は下図のようになっています。平均は 627 ms、標準偏差は 487 ms でした。
これをチーム内に報告したところ、この部分を非同期化すべきなのではないかという話になりました。このようにロードテストを通じて、リファクタリングすべき箇所を発見することが出来ました。
レコメンドシステムとの通信
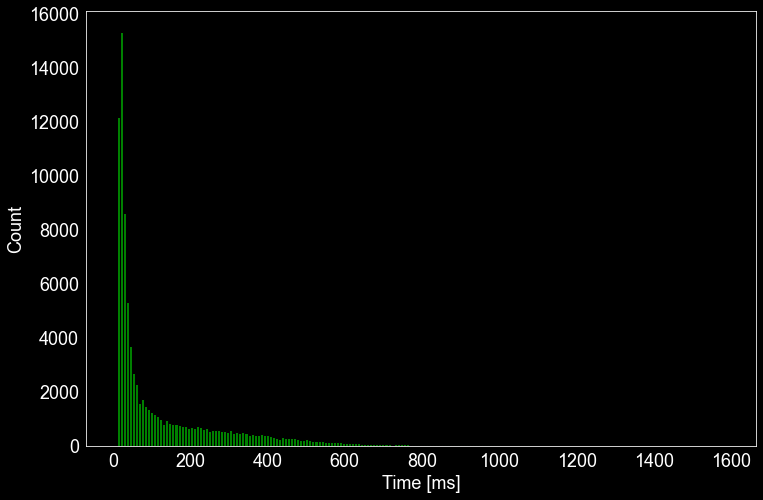
実験 ① における「トップ画面情報」を得るための API に着目してログを確認したところ、以下の略図のレコメンドを担うサーバー (Recommendation System) との HTTP 通信において時間がかかっていることが分かりました。この通信は、各ユーザーに合わせてアプリのホーム画面をカスタマイズするために必須のものとなっています。
Recommendation System との通信にかかった時間は平均 136 ms 標準偏差 178 ms でした。30 ms 以下のものと100 ms 以上のものが混在していますが、これにはサーバーの呼び出しにおいてキャッシュの有無が大きく影響していると考えられます。
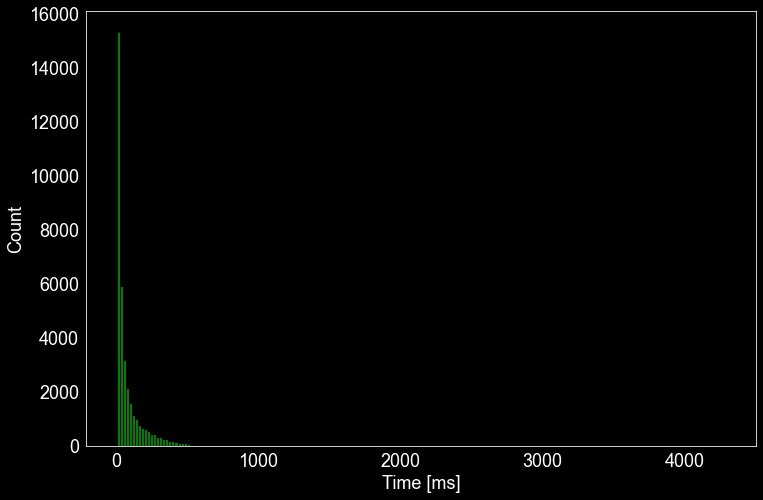
決済システムとの通信
実験 ① における「応援アイテム」の応答時間が他の API に比べて時間がかかっていたため、詳細にログをとって確認しました。すると、内部的に決済情報を担うサーバー (上図 Billing System)との通信を行っている部分で時間がかかっていることが明らかになりました。
平均 112 ms 標準偏差 273 ms でした。
考察
これらの API ではいずれも、ユーザーにカスタマイズされたデータを渡すようになっていて、同一のユーザーが何度もアクセスするというのでなければキャッシュが効かせられなかったり、そもそも決済情報のため最新の情報が常に求められたりする部分です。こうしたパーソナライズされた情報処理はサービスにとって重要ですので、このように各 API でのある程度の負荷は許容すべきだと考えられます。
また、事前にアクセスがスパイクするような配信の予定が分かっている場合には、Recommendation system との連携を一時的に停止しサーバーの負荷を軽減させる、サーバー障害のリスク回避のための対応策とすることも考えられます。
結論
まず、実験 ① では、ロードテストにより、各 API の所要時間を把握しました。次に、実験 ② では、所要時間の長さがキャッシュに関連している可能性はないかと考え、キャッシュのヒット率を確認しました。その結果、キャッシュは適切に動作していることが確認されました。そして、実験 ③ にて、各 API の具体的にどの部分に時間がかかっているのか確認し、実装による改善ができるかどうかを検討しました。
その結果、DB の読み出し・書き込みの処理により、パフォーマンスを大きく阻害している箇所を特定することができ、リファクタリングの提案を行うことが出来ました。
また、パーソナライズされた、あるいは同期性が求められる外部システムと通信する部分について、ボトルネックがあることが可視化されました。そして、今後、アクセスが集中するような場合には、これらの機能を制限することも可能であると示唆されました。
また、ロードテストで応答時間が 90パーセンタイルで1秒ほどと、非常に長くなってしまっている問題で、シナリオが不適切なのか、本番環境との差異のためなのか、あるいは本番環境における問題があるのか、引き続き検討を行う必要があります。
感想
このインターンを通じて、数多くの貴重な経験をさせていただきました。その中でも特に印象的だったことを、3点書き連ねたいと思います。
成長を実感!
短期間のインターンシップではありましたが、自らの成長を実感する1ヶ月でした。今まで多くのスタートアップに携わってまいりましたが、ここまで大規模なシステムを扱うことがなく、得られた知見が数多くありました。例えば、アルファ・ベータ・ロードテストなどの開発環境を構築する上で、それらの環境をどのようにコードベースで管理してデプロイを自動化していくか、ということは大変参考になりました。前項の実験を進めるためには、デモ用データを Elascticsearch に注入する必要がありました。そのためにデプロイに関するコードの理解など、多くを学ぶことが出来ました。このように、大きなシステムを支える技術に触れられ、大変有意義な経験が出来ました。
遠慮せずに質問!
こうした大規模で複雑なシステムに携わることで、どのノードがどのように繋がっているのかなど、疑問点に直面しました。また開発の途中でなぜ発生するのか不明なエラーにも遭遇し、解決出来ないことが多くありました。しかし社員の方々のサポートに支えられ、完全にスタックしてしまうことはありませんでした。例えば、夕会と呼ばれる Zoom でエンジニア同士が雑談しながら質問し合う機会があり、そこで質問すれば、画面共有等を交えながら分かりやすい説明を受けることが出来ました。またチャットで質問した際の返信も非常に早く、在宅勤務であっても不明なことを尋ねやすい環境が整っていました。中には自分一人だったら1日でも費やしてしまいそうだったエラーを10分で解決したといったケースもあり、質問することの重要性を身をもって実感しました。
オフィスも最高!
週に一度ほど、感染対策を行いながら LINE のオフィスに出社し、作業をさせていただきました。美味しい朝食・お弁当やコーヒー等の飲み物が、無料または非常に安価に提供されていて、空間としても居住可能と感じるほどリラックス出来る快適な環境でした。これからの時代にはその時々で、在宅勤務と出社が選べるということは、企業の選択において重要だと考えており、両者とも快適な労働環境が整っている LINE の就業形態は大変魅力的だと感じました。
メンターの朱さんをはじめとした多くの方々の助けなしでは、インターンをこなすことはできなかったと考えています。ちょうどサーバーチームでの大きなプロジェクトが重なってしまい、ご多忙な時期にも関わらず丁寧なサポートをしていただき、本当にありがとうございました。