
こんにちは。東京大学大学院修士1年の鈴木凌斗と申します。8月23日から6週間、技術職 就業型コースのインターンシップに参加しました。
今回のインターンではData Platform室 IU Devチームに所属し、LINE社内で利用している「IU Web」というデータカタログの検索機能改善に取り組みました。本ブログでは、その内容について紹介します。
背景
IU Webについて
参考:LINEがサービス横断で実現する"データ活用の民主化"
LINEでは全社横断でデータを活用するために「IU」(Information Universe) と呼ばれるデータプラットフォームを利用していて、LINEのほぼすべてのサービスのデータがここに集積されています。現時点でサーバ台数は2,000台以上、ストレージ使用量は約300PBとなっています。
「IU Web」はIUのデータを管理するデータカタログとして以下を提供します。
- どのようなデータが存在するか
- データの権限は誰にあるか
- データのメタ情報
- データの検索機能
社内ユーザは、IUに存在する大量のデータの中から目的のデータにアクセスするためにIU Webを利用します。
課題
多くの社内ユーザは目的のデータにアクセスするためにIU Webの検索機能を利用します。ここで問題となるのが、IUに格納されているデータは数が多く(例として、頻繁に検索されるTABLEカテゴリのデータはおよそ40,000件あります)、その中には似た名前のものも多いため、正確な検索キーワードを入力しないと目的のデータにたどり着くのが難しいということです。これではIUが掲げる「全社横断のデータ利活用」という目的の妨げとなってしまいます。
そこで、たとえユーザがデータ名を正確に覚えていなくても、一部分を検索欄に入力すれば候補の一覧を提示する「auto-complete機能」を実装することによりこの問題の解決を図りました。
データの検索にはElasticsearchという検索エンジンが用いられています。各データのメタデータがElasticsearchにJSON形式で格納され、格納時の設定や検索クエリの設定によって、検索条件や検索結果の優先度を指定することができます。今回のインターンでは、Elasticsearchでauto-complete機能を実現することを目標にしました。
どのような補完が望ましいか
auto-complete機能を開発するにあたり、まずはどのような入力に対してどのような検索結果を返すべきかということを考えました。
例えば、あるユーザが"app_log_beta"というテーブルを探しているとき、入力としてはどのようなパターンが考えられるでしょうか。
メンターの奥山さんと相談の上、以下のような入力パターンを想定することにしました。
- ap (先頭tokenの先頭)
- lo (途中のtokenの先頭)
- app_log (先頭から連続したtokenを_でつなげたもの)
- log_beta (途中から連続したtokenを_でつなげたもの)
- app log (先頭から連続したtokenをスペースでつなげたもの)
- log beta (途中から連続したtokenをスペースでつなげたもの)
- ap lo (複数のtokenを途中まで入力したもの)
- eta (tokenの途中)
一方、多くの入力パターンに対応しようとすると、無関係なデータ(ノイズ)を検索結果に含んでしまうという問題が考えられます。
そのため、ユーザの望むデータが検索結果の上位に表示されるように、次のような指標に基づいて検索結果に優先度をつけることにしました。
- (部分一致検索だけではなく)前方一致検索にヒットするか
- ユーザとの関連度
- ディスク使用量
auto-complete機能実現方法の調査・比較検討
目指すべき補完の形が固まったところで、Elasticsearchでそれを実現するための方法を調査しました。
その結果、次の4種類の方法があることが分かりました。
- Completion Suggester
- Edge NGram Tokenizer
- Edge NGram Tokenizer + Shingle Token Filter
- Wildcard Query
それぞれに長所・短所があるので、以下のような評価基準を定めそれに従って選択することにしました。
- 検索品質
- 望ましい補完とはで想定した入力パターンをなるべくカバーしたい
- 柔軟にランク付けできることが望ましい
- 速度
- IUのユーザ検索ページにはすでにauto-completeが実装されていて、そこでかかる時間が200ms~300ms程度だったので、そのあたりを目安にする
- 実装コスト
- 設定・挙動の複雑さ
- Elasticsearchの設定や挙動が複雑になると後のテストやデバッグ、チューニング等が大変になるので、あまり複雑でないことが望ましい
テストツールの実装
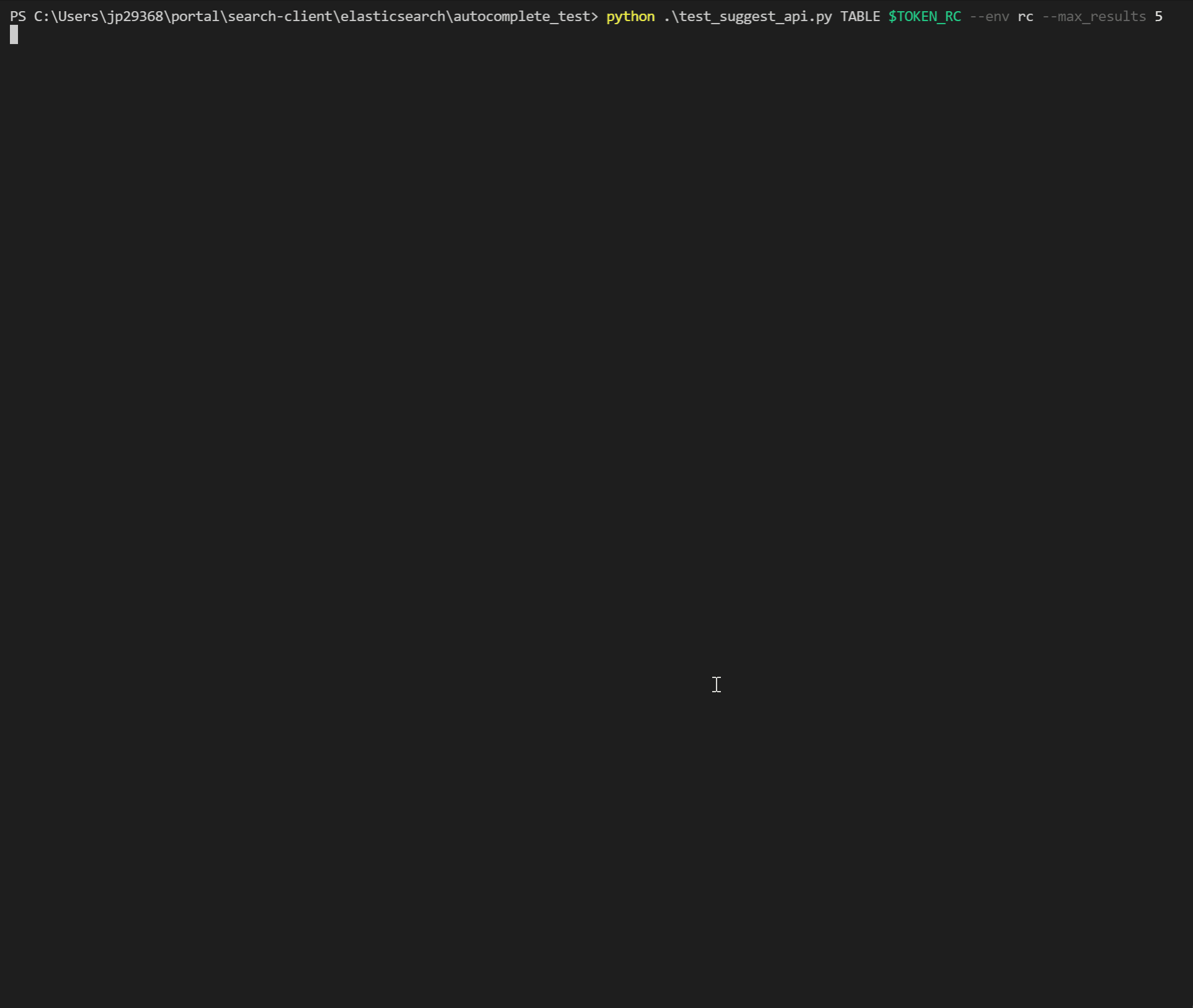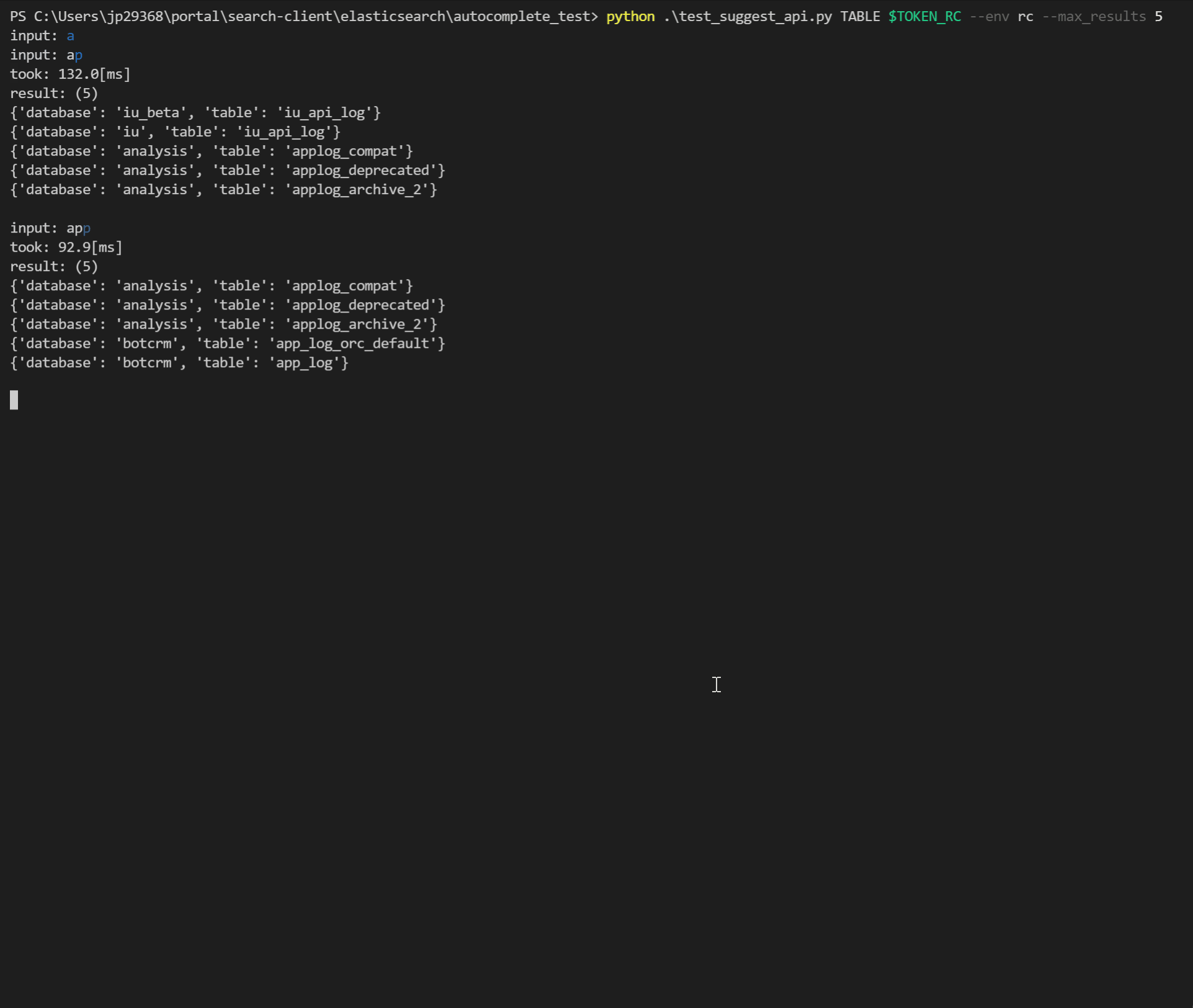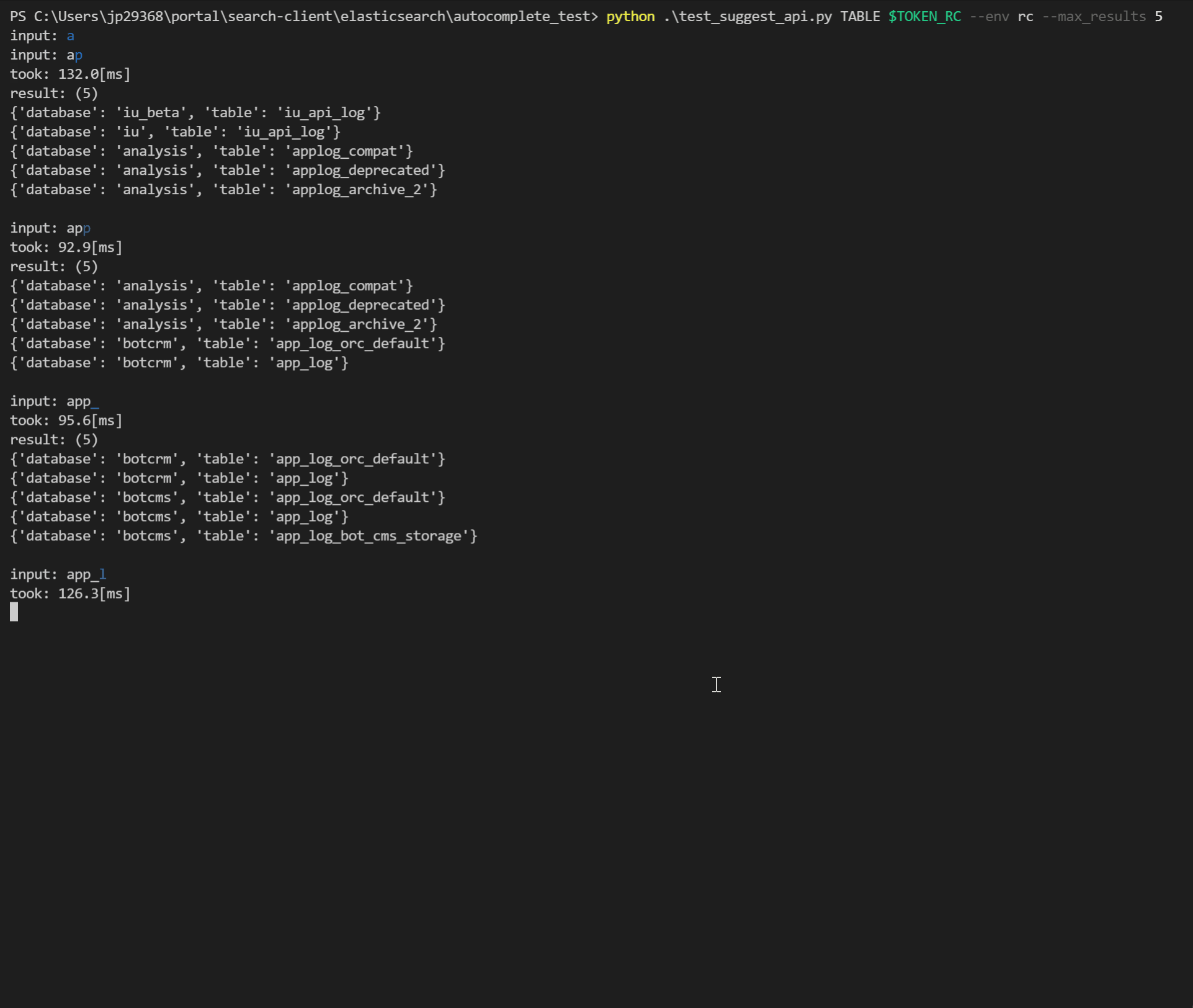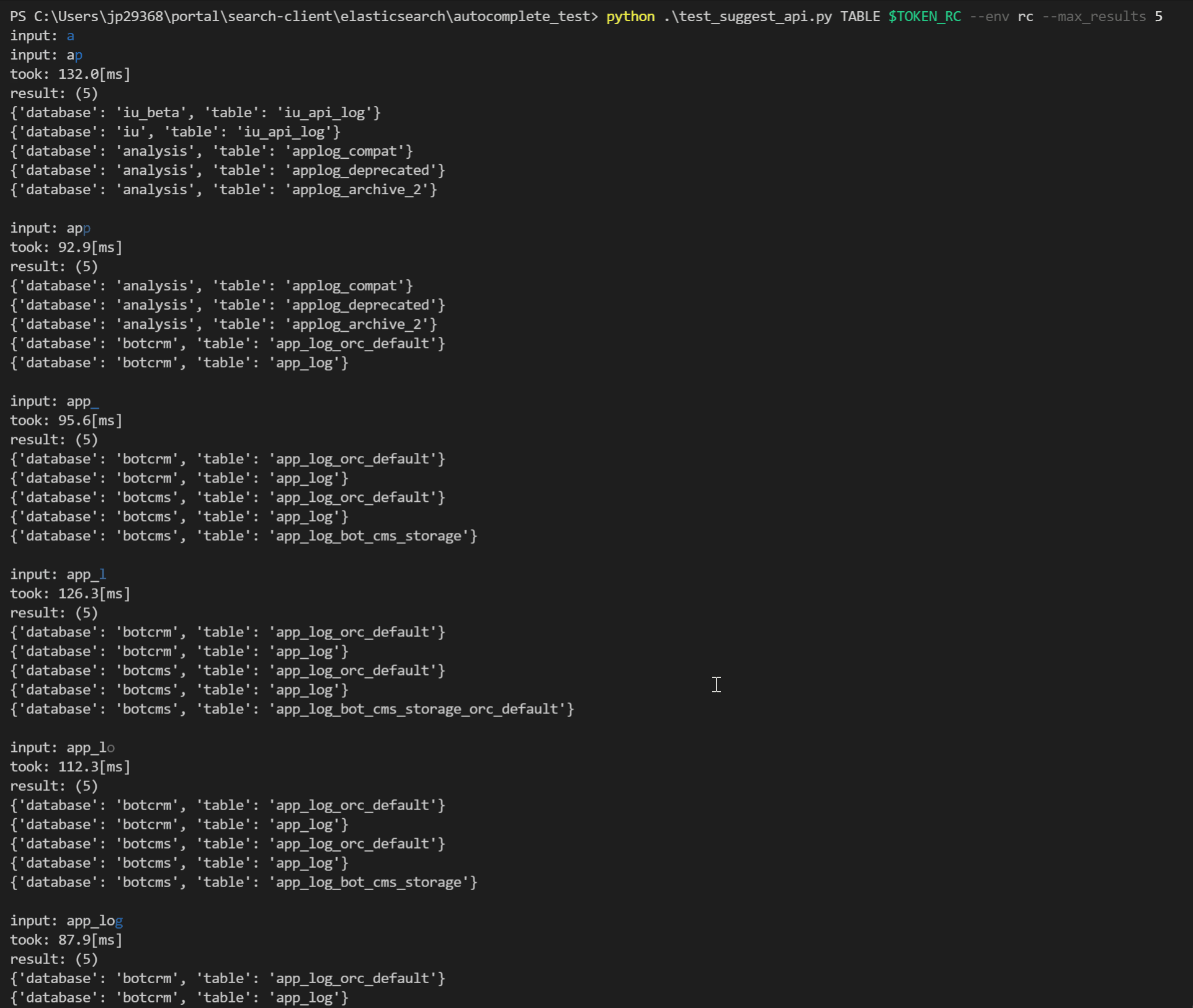
それぞれの手法を実際に動かして比較するために、コマンドラインからElasticsearchのクエリを直接実行したりAPIを呼び出してauto-completeを試すためのツールをPythonで実装しました。
1文字キーボード入力を行うたびに検索クエリを実行し、
- 実行時間
- ヒット数
- 検索結果の一覧
を確認することができます。このツールは「比較検討」という目的以外にも実装後の実行時間の計測やデバッグなど、以降の開発で大いに役立ちました。
各手法の調査
各手法について調査し、長所・短所を整理しました。
Completion Suggester
概要
Completion Suggester | Elasticsearch Guide [6.8] | Elastic
Elasticsearchには「Completion Suggester」という補完のための機能があり、これを用いると前方一致検索やあいまい検索(指定した編集距離に収まる単語をサジェストする)が可能になります。auto-complete用に最適化されていて高速です。
評価
- 速度
- (pros) 前方一致のauto-completeに最適化されていて検索が速い
- 検索品質
- (pros) ノイズが少ない
- (cons) 部分一致検索ができない
- (cons) ドキュメントのインデックス格納時に優先度を指定する必要があり、検索時の柔軟なランク付けが難しい
- 実装コスト
- (pros) 実装上の障害は特になさそう
- 設定・挙動の複雑さ
- (pros) 前方一致のみなので単純
Edge NGram Tokenizer
概要
Edge NGram Tokenizer | Elasticsearch Guide [6.8] | Elastic
これは、あらかじめ検索対象となるデータを単語(トークン)単位に分割したのち、各単語の先頭文字から始まるn-gramを格納する方式です。例えば、"2 Quick Foxes."にこの方法を適用すると、
["2", "Q", "Qu", "Qui", "Quic", "Quick", "F", "Fo", "Fox", "Foxe", "Foxes"]が格納され、検索文字列として"Fox"を入力したときなどにヒットするようになります。
一方で、この方法では、"Fox Qui"のように、元の文章と異なる語順で入力してもヒットするという問題点があります。想定しない入力パターンを拾ってしまうとノイズが増える原因になるので、このようなことはなるべく避けたいです。
以下の実行例では、"log ap"と入力したときに"app_log"や"api_log"がヒットしていることが分かります。
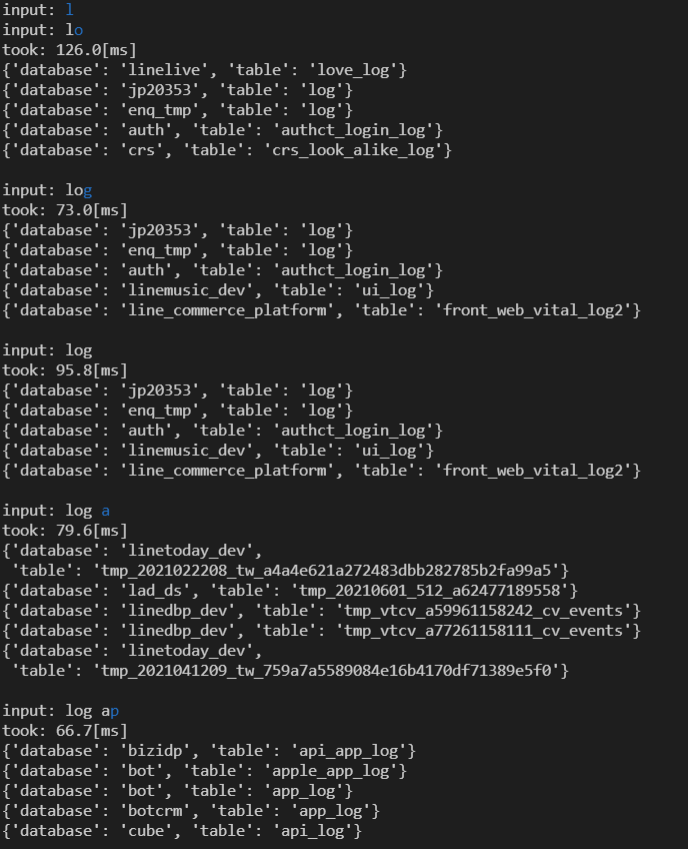
評価
- 速度
- (pros) 通常のmatchクエリなのでおそらく速い
- 検索品質
- (pros) 部分一致検索可能
- (cons) 複数単語にまたがる入力を与えた場合語順が保たれない
- "event_log"と入力すると"log_event"もサジェストされる
- 実装コスト
- (pros) 実装上の障害は特になさそう
- 設定・挙動の複雑さ
- (pros) 文章をスペースやアンダースコアで単語単位に分割し、各単語について「開始位置を先頭文字に固定したn-gram」(Edge n-gram)を作る という挙動で、そこまで複雑ではない
Edge NGram Tokenizer + Shingle Token Filter
概要
Shingle Token Filter | Elasticsearch Guide [6.8] | Elastic
Shingle Token Filterを併用することにより、Edge NGram Tokenizerの「複数単語にまたがる入力を与えた場合語順が保たれない」という問題が解決できることが分かりました。
Shingle Token Filterを用いると、連続したトークンをつなぎ合わせたものをトークンとして扱う事になります。つまり、"2 Quick Foxes."に適用すると、
["2", "2 Quick", "Quick", "Quick Foxes", "Foxes"]
などがトークンとして扱われ、このトークンをもとにEdge NGramを構築すると、
["2 Quic", "Quick Fox"]
などが格納され、検索文字列として"Quick Fox"を入力したときはヒットするが、"Fox Quick"を入力したときはヒットしない、ということが可能になります。
評価
- 速度
- (pros) インデックスのサイズは大きくなるが、matchクエリによる検索なのでおそらく速い
- 検索品質
- (pros) 部分一致検索可能
- (pros) ノイズが少ない
- 実装コスト
- (cons) 設定すべきFilter・Tokenizerが多い
- 設定・挙動の複雑さ
- (cons) Analyzerの設定も挙動も複雑
Wild Card Query
概要
Wildcard Query | Elasticsearch Guide [6.8] | Elastic
ワイルドカードを利用して部分一致検索を実現することも可能です。この方法は上記の他の方法と比べて低速です。とはいえ、以下の実行例を見てもわかる通り、200~300msの目標には余裕をもって収まっています。
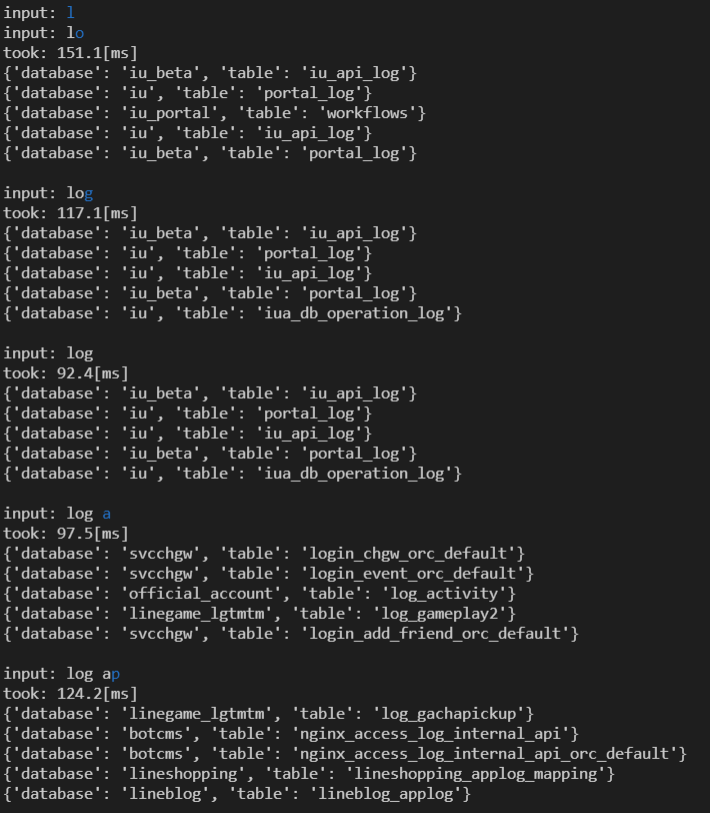
評価
- 速度
- (cons) 他の手法と比べると遅いが、目標の200~300msには収まっている
- 検索品質
- (pros) 部分一致検索可能
- (cons) ノイズが多い
- 実装コスト
- (pros) インデックスに変更を加える必要がない
- 設定・挙動の複雑さ
- (pros) 直感的
想定した入力パターンに対する検索結果
事前に想定した入力パターンを各手法がどの程度カバーできているか表に整理しました。Edge NGramとWildcard Queryが広い検索ワードに対応していることが分かります。
| 方法入力 | ap(先頭tokenの先頭) | log(途中のtokenの先頭) | app_log(先頭から連続したtokenを_でつなげたもの) | log_beta(途中から連続したtokenを_でつなげたもの) | app log(先頭から連続したtokenをスペースでつなげたもの) | log beta(途中から連続したtokenをスペースでつなげたもの) | ap lo(複数のtokenを途中まで入力したもの) | eta(tokenの途中) |
|---|---|---|---|---|---|---|---|---|
| Completion Suggester | ○ | × | ○ | × | × | × | × | × |
| Edge NGram | ○ | ○ | ○ | ○ | ○ | ○ | ○ | × |
| Edge NGram + Shingle Token Filter | ○ | ○ | ○ | ○ | ○ | ○ | × | × |
| Wildcard Query and Regexp Query | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
結論
各評価基準における比較結果を下の表にまとめました。
| 方法 | 速度 | 検索品質 | 実装コスト | 設定・挙動の複雑さ |
|---|---|---|---|---|
| Completion Suggester | ◎ 前方一致に限られてる分速い |
△ 前方一致のみに対応柔軟なランク付けが難しい |
○ 特に障害はなさそう |
○前方一致のみなので単純 |
| Edge NGram | ○ インデックスのサイズは大きくなるが検索は十分速い |
○ 複数の単語をまたいだ入力に対して異なる語順のものがサジェストされうる |
○ 同上 |
○ 文章をスペースやアンダースコアで分割し、各単語についてEdge n-gram を作る という挙動で、そこまで複雑ではない |
| Edge NGram + Shingle Token Filter | ○ 同上 |
○ 複数の単語をまたいだ入力に対して語順が保たれる |
△ 設定すべきFilter・Tokenizer(Elasticsearchにドキュメントを格納する際の設定)が多い |
△ 設定も挙動もやや複雑 |
| Wildcard Query | △ 他の手法と比べると遅いが、実験の結果実用上問題ない速さであることが分かった |
○ 単語の途中から入力してもサジェストされる |
◎ インデックスに変更を加える必要がない |
◎ 変更箇所が少ないので簡単 動作も直感的 |
速度に関してはWildcard Queryがやや遅いものの、どの方法でも目標の200~300msには余裕をもって収まりそうです。さらに、auto-complete機能の対象であるTABLEカテゴリとDBカテゴリのデータ数はそれぞれ39,564件, 1,149件となっていますが、データ数が869,349件あるCOLUMNカテゴリのデータに対して(最も遅い)Wildcard Queryによる検索を行ったところ同程度の実行時間で済んだので、仮に今後データ数が10倍に増えたとしても問題なく運用できると考えられます。検索品質に関しては、想定した入力パターンに対する検索結果を見る限りCompletion Suggester以外であればほとんどカバーできています。実装コストや設定・挙動の複雑さは、Edge NGram + Shingle Token Filterが大変そうです。これらを踏まえるとWildcard Queryが最も良さそうだという結論に至りました。実装に入る前に、以上の調査・比較結果をチームの方々に共有して合意を得るという過程を踏みました。
Suggest APIの実装
APIはJava+Spring Bootで実装し、ElasticsearchのCRUD操作はJava Hight Level REST Clientで行いました。
実装過程での動作確認には、事前に作ったCLIツールやSwaggerを使用しました。
さらに、部分一致検索にヒットしたドキュメントを、
- ディスク使用量
- ユーザとの関連度
- 前方一致検索でもヒットするか
に応じてソートする処理を実装しました。
テスト
実装後は、
- 出現頻度の高い入力に対してどのような挙動をするか
- 特定のワードに対して問題が発生しないか
- APIリクエストが集中した際に稼働を続けられるか
といったことを確認するため、各種テストを行いました。
Latencyのテスト
頻出ワードに対するテスト
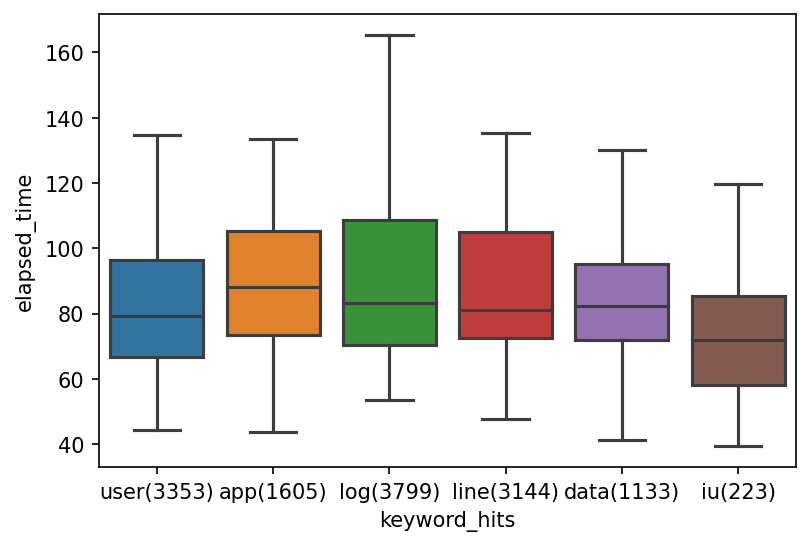
出現頻度の高い入力ワードに対する挙動を確認するため、IU Webでの検索ログをもとに頻繁に検索されるワードを抜粋し、それぞれのワードについて100回ずつSuggest APIを呼び出してLatencyを計測しました。
その結果を下図のようになり、どのワードに対しても安定して200ms以内に収まることがわかりました。(横軸ラベルのカッコ内は検索にヒットするテーブルの数を表す)
アルファベット2文字の組み合わせに対するテスト
次に、ある特定のワードに対して問題が発生しないかということを確認するために、アルファベット2文字の組み合わせすべてに対して10回ずつSuggest APIを呼び出すという網羅的なテストを行いました。
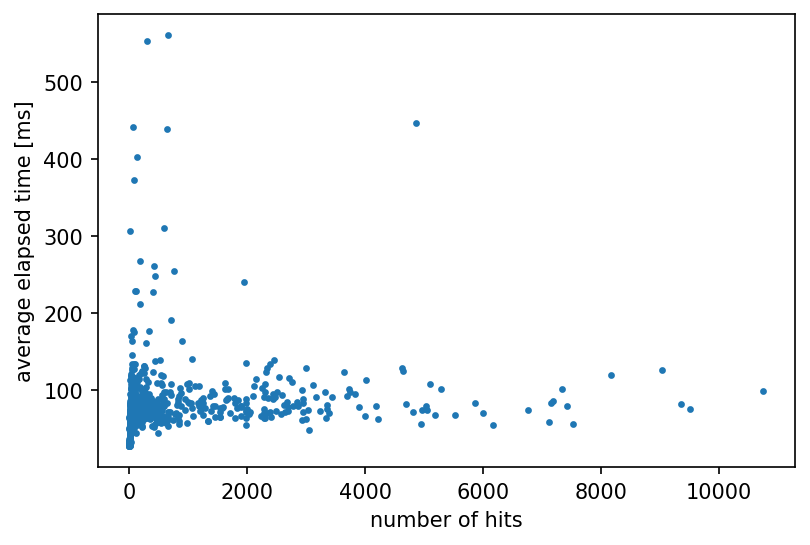
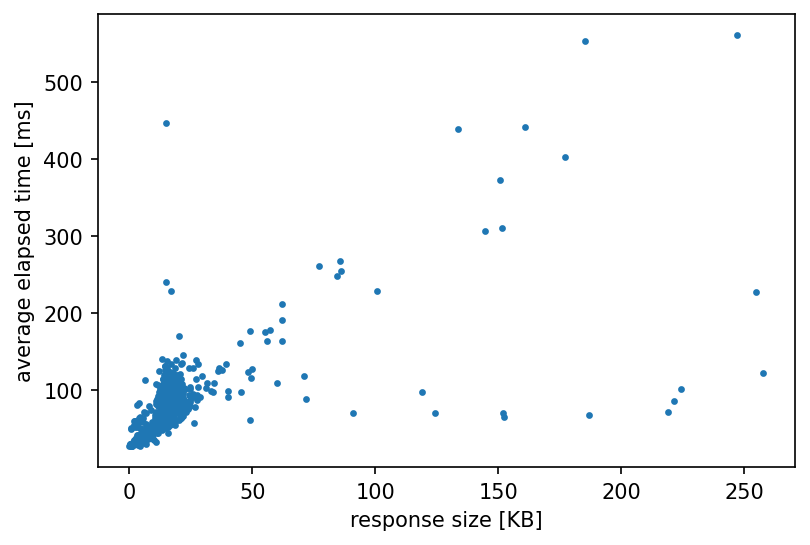
この結果から、
- 検索のヒット数とLatencyの間にほぼ相関はない
- レスポンスのサイズとLatencyには強い相関がみられる
- いくつかのワードに対してLatencyが非常に大きく(400ms以上)なっている
ことがわかりました。
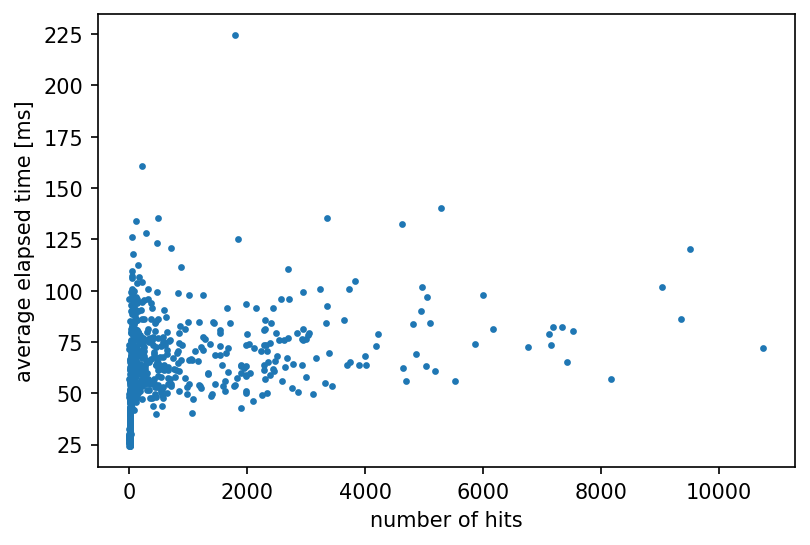
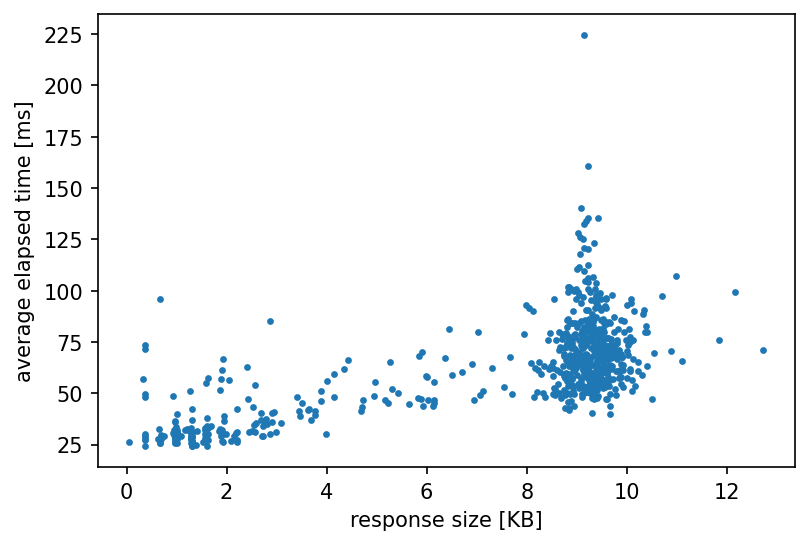
そこで、Latencyが大きくなっている検索ワードに対するレスポンスを確認したところ、auto-complete機能に必要ないフィールドのサイズが非常に大きくなっていることがわかり、このフィールドをレスポンスから除外しました。その結果下図のように、全体的にレスポンスのサイズが削減されLatencyが大きく改善しました。
これは入力ワードによっては2,000msを越えて遅くなる致命的な問題で、リリース前に気づけたのは重要なことでした。この一件で網羅的にテストを行うことの重要性を実感しました。
負荷試験
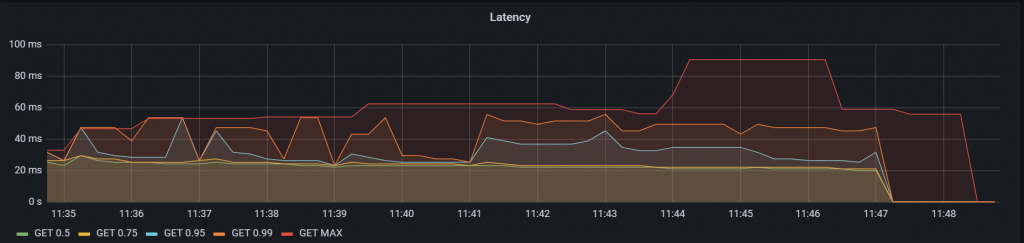
リリース後、APIのリクエストが集中したときに問題なく稼働することを確認するために負荷試験を実施しました。
テストツールにはVegetaを用い、負荷試験実行中は以下の各指標をGrafanaで監視しました。
- CPU使用率
- メモリ使用量
- GC発生
負荷試験の結果、1秒あたり60回のリクエストを毎秒送ってもLatencyは100ms程度に収まりました。CPU使用率やメモリ使用量、GCの発生回数・時間に関しても問題ない結果となりました。
結果
動作の様子
無事リリースされたので、IU Webで動いている様子を確認します。期待通りの検索候補がサジェストされていて、動作も十分高速です。
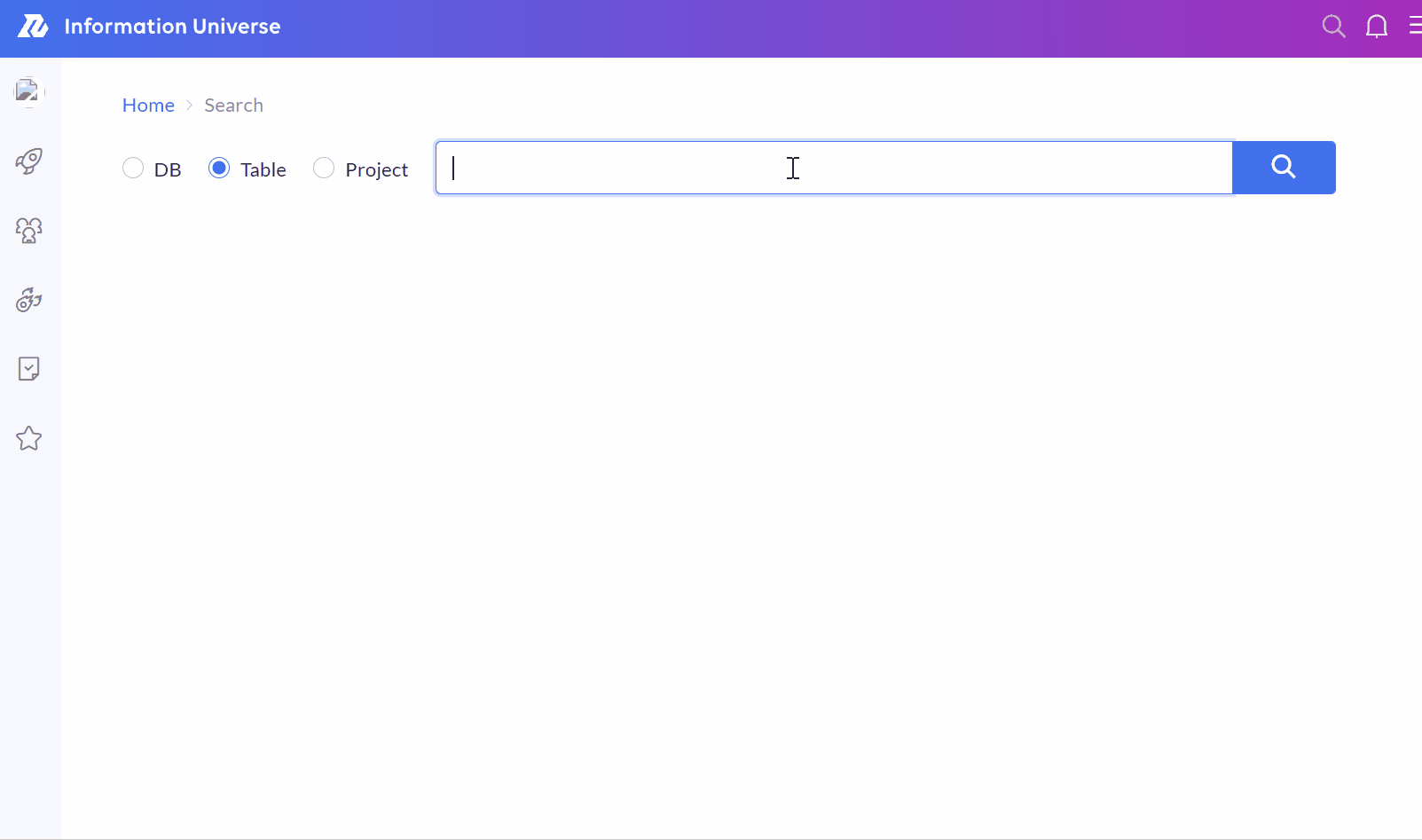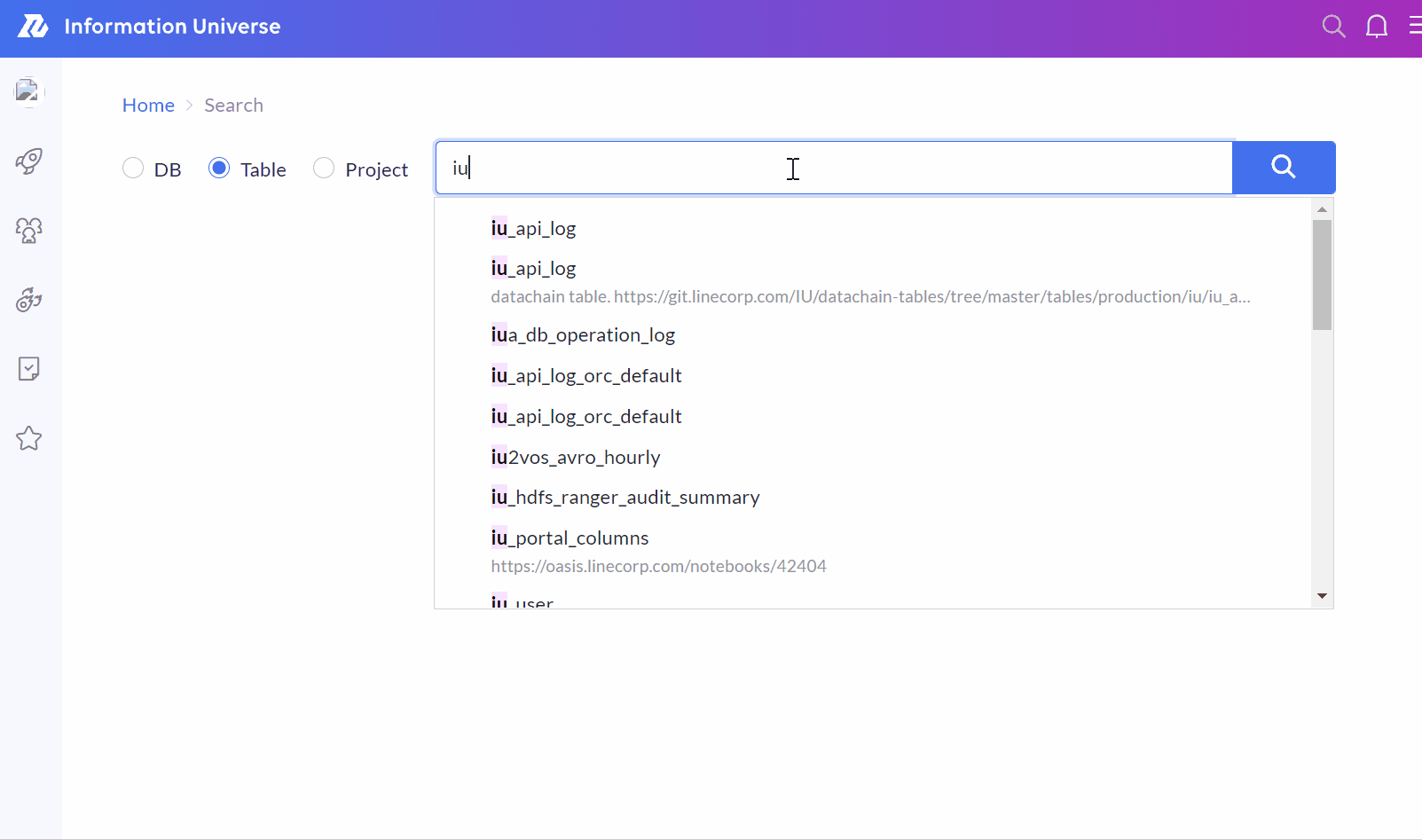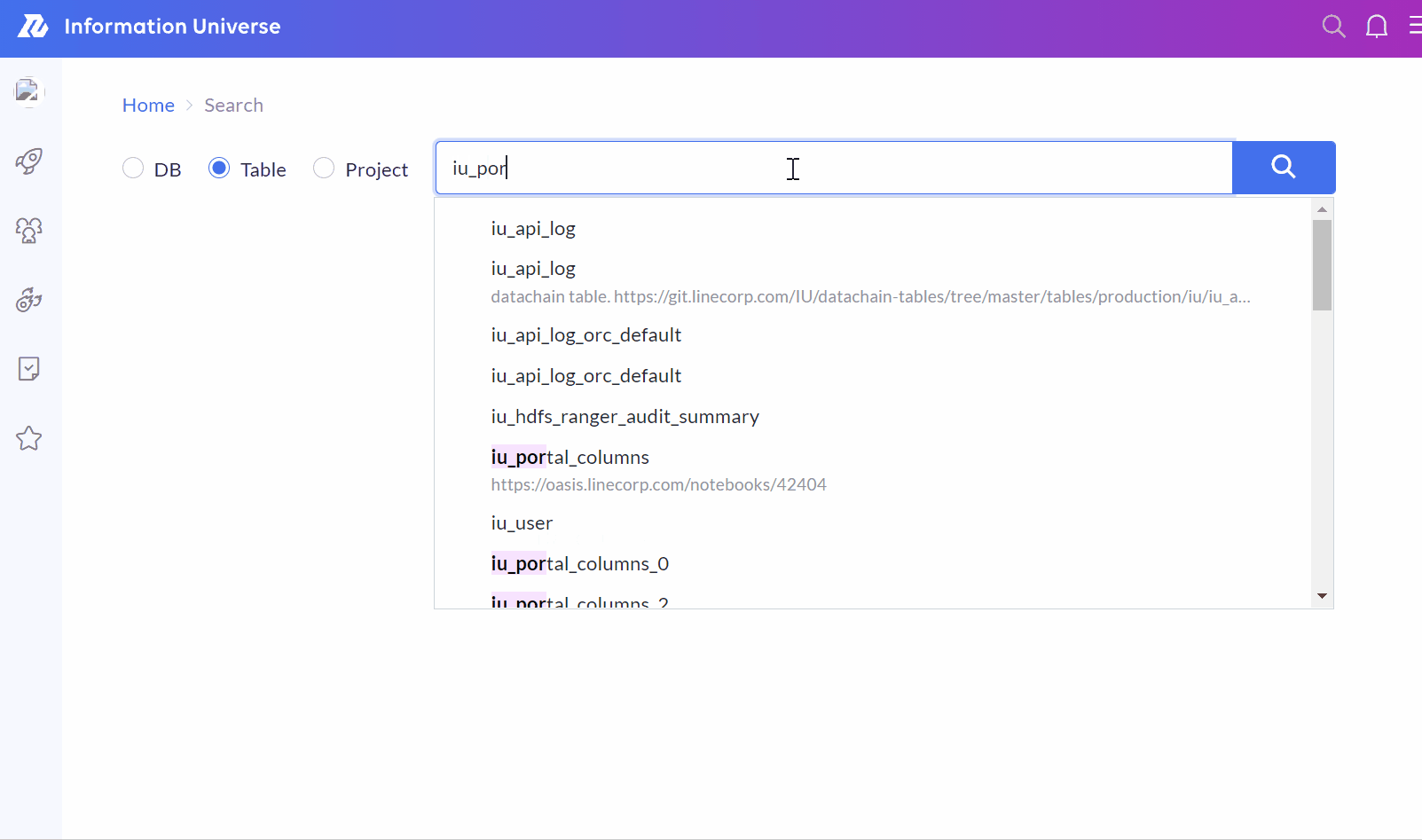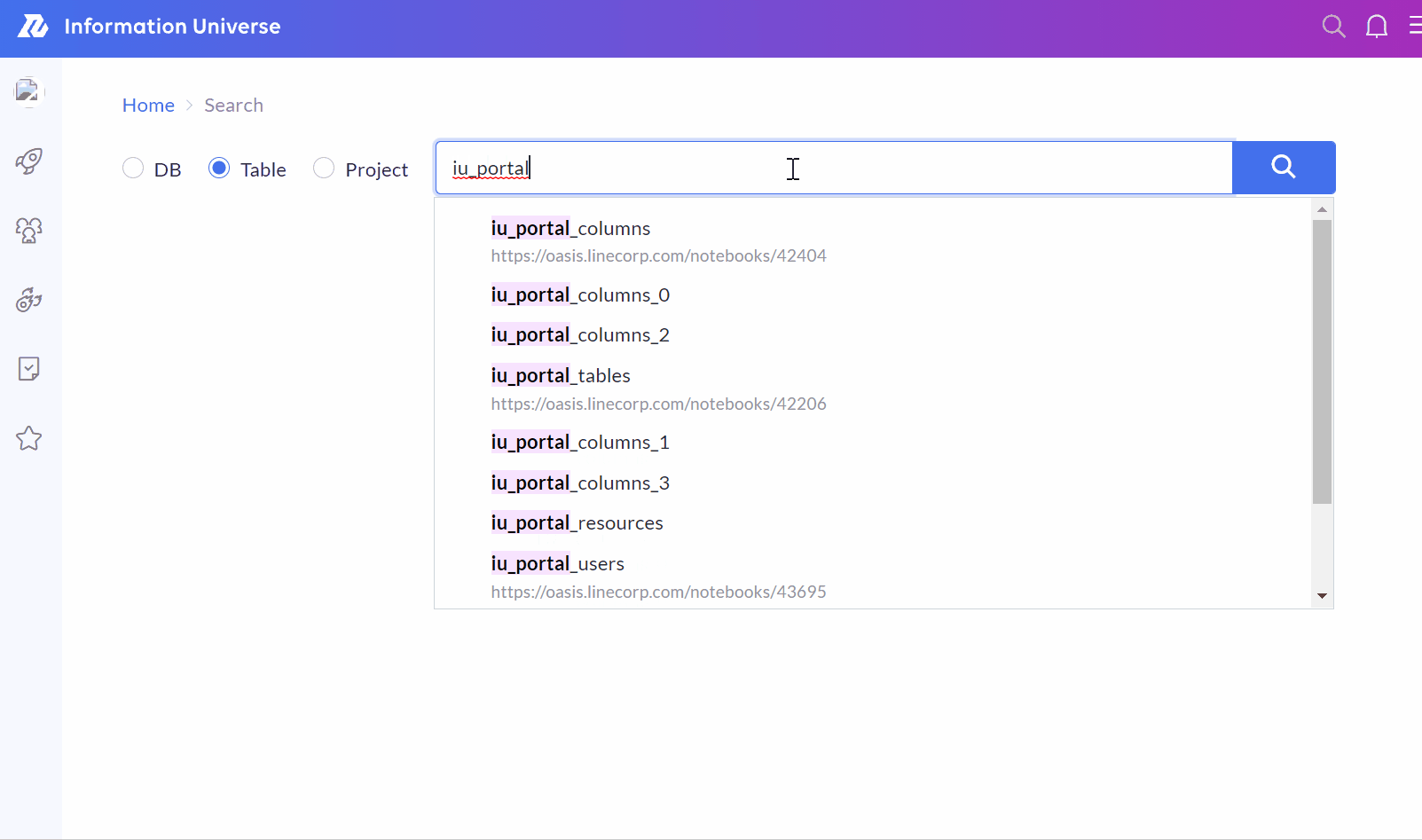
まとめ
このインターンシップでは、APIの仕様設計やauto-complete方法の選定からはじめ、IU Webの検索補完機能を実装しました。auto-completeの実装方法を決定する際には、事前に調査した各方法についてそれらのPros/Consをまとめ、チームの方々に発表してディスカッションを行いました。補完機能実装後は、Latencyのテストや負荷試験を行い、リクエストが集中したときにも問題なく稼働を続けられることを確認しました。
感想
本インターンでの主な使用技術であるSpring BootやElasticsearchについて予備知識がない状態でのスタートでしたが、キャッチアップのための期間を十分に設けていただき、またメンターの奥山さんの熱心なサポートもあって無事課題に取り組むことができました。
インターン中は、新しく触れた様々な技術に関してはもちろん、それ以外にも開発方針の選定やコードレビュー、本番環境へリリースされるまでの過程などを通じてチーム開発の進め方について広く学ばせていただくことができました。これは個人での開発では得られない非常に貴重な経験だったと思います。
今回はフルリモートでの参加となりましたが、メンターの奥山さんが忙しい中時間を割いてくださりZoomを用いて頻繁にコミュニケーションをとることができ、リモート特有の不便さはほとんど感じませんでした。また、週に2回のチームでのZoomランチ会や、インターン生交流会などの機会を多く設けていただき多くの方々と交流することができました。
以上6週間、とても有意義なインターンシップに参加させていただき、本当にありがとうございました。