
こんにちは、新井康太と申します。東京大学大学院の修士1年で、普段は音色を直感的に可視化する研究などを行っています。私はフロントエンド領域の開発が好きで、今回のLINEの夏インターンでは、フロントエンド開発センター (UIT) Frontend-Dev9チームでフロントエンド開発の業務に携わらせて頂きました。主に任せて頂いた業務は、LINEバイト (https://baito.line.me/) のWebからの流入を強化する、といった内容で、具体的には、サイトマップや構造化データの整備、ページのパフォーマンス向上など、様々な観点からWebサービスとしての品質向上に取り組みました。 このブログでは、こういった施策全般を"Web最適化"と称し、まずWeb最適化に取り組む前のLINEバイトの現状及び課題を述べたのち、その課題に対する解決策をどのように検討し、実装したか、そしてその結果についてまとめたいと思います。
LINEバイトについて
はじめに、LINEバイトについて、サービスの概要や使用されている技術について簡単にまとめます。
LINEバイトは、LINEが提供する求人掲載サービスで、現在15万件以上の求人が掲載されています。LINEバイトのLINE公式アカウントを友だち追加してもらうことで、定期的に求人への案内が配信されるようになっています。従って、LINEバイトへのアクセスは、このLINE公式アカウントからのメッセージをタップした際などにLINEアプリ内で立ち上がるブラウザ (In App Browser : 通称IAB) からのものがメインとなっています。ですが、IAB以外の通常のWebブラウザからも、Google検索などを通じてアクセスすることが可能です。
通常のWebブラウザからアクセスする場合、ユーザーにおすすめの求人など、各ユーザーにパーソナライズされた情報を表示する部分についてはLINEアカウントでログインをしないと見ることができませんが、そうでない部分についてはログインをしなくても見ることが可能です。ログインなしで見ることができる主要なページとして、「求人一覧ページ」と「求人詳細ページ」をあげることができ、今回のブログではこれらのページを主として話を進めていきます。
求人一覧ページは、クエリパラメータに応じて求人の検索結果の一覧を表示するページです。例えば、https://baito.line.me/jobs?prefectureId=1 であれば、北海道の求人の一覧が表示されるようになっています。一方、求人詳細ページは、求人一覧ページから特定の求人をタップ (またはクリック) した時に表示されるページで、仕事内容や給与、企業情報など、その求人の詳細情報が載っており、その求人に応募するボタンも用意されています (応募するためにはログインが必要です) 。
実際に取り組んだ施策について話を進める前に、フロントエンドの技術的な構成にも触れておきます。LINEバイトは基本的には、React.js (https://reactjs.org/) で実装されたSPA (Single Page Application) を、Express (https://expressjs.com/) で立てたサーバーによってSSR (Server Side Rendering) するという構成になっています。バンドラにはWebpack (https://webpack.js.org/) が使われています。
では、ここまでの話を前提として、改善に取り組む前の課題や、それに対してどのような施策を行なったのかについて述べていきたいと思います。
LINEバイトの流入の現状
先程、LINEバイトへのアクセスはLINEアプリのIABからが主ではありますが、通常のWebブラウザでもGoogleなどの検索エンジンを通してアクセスすることができると述べました。しかし、現状としては、IAB以外からのアクセスは非常に限られています。具体的に数値として示すと、Googleを経由しての検索流入などのアクセスについては、一日当たり平均して約1,000セッション程度と非常に小さい規模にとどまっています。
今回自分が任せて頂いたWeb最適化の最終的な目標は、このIAB以外のWebブラウザからの流入を増やしていく、ということになります。
課題
Web最適化に取り組むための第一歩として、そもそも現状IAB以外のWebブラウザからの流入が少ない実態は何が原因なのかを、Google検索からの流入に注目して分析しました。
先ほどLINEバイト内でログインせずに見ることができるページとして、「求人一覧ページ」と「求人詳細ページ」を挙げました。本インターンでは特に、ページ数が多く求人の応募に直結するページである「求人詳細ページ」にフォーカスして改善を行なったため、まずここでは、求人詳細ページで明らかになった課題について述べたいと思います。なお、「求人一覧ページ」の課題や改善策については「今後への課題と展望」の章で述べているので、そちらも合わせてご覧いただけたら幸いです。
求人詳細ページの課題
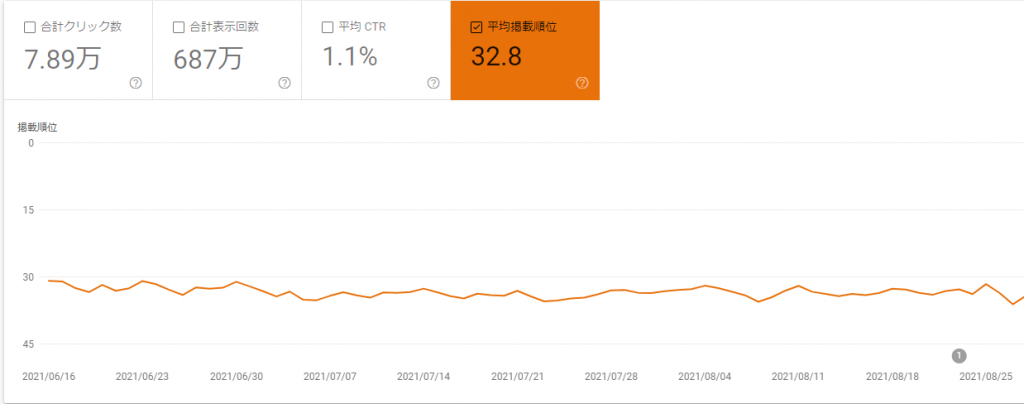
求人詳細ページへの流入が少ない直接的な原因は、求人詳細ページが検索結果の上位に出てこないことではないかと分析しました。下の図は、LINEバイトのGoogleに登録されている各ページ(基本的には求人詳細ページ)の平均掲載順位の遷移を示しています。
平均掲載順位は30位前後を推移しており、検索結果の1ページ目にすら表示されていない状態です。
このように検索結果の順位が低くなってしまう要因には様々なことが考えられるとは思うのですが、今回は、求人詳細ページの多くのページが Google に課題のあるページと認識されていることが主たる原因ではないかと分析しました。下の図は、Google Search Console によるページのステータスです。
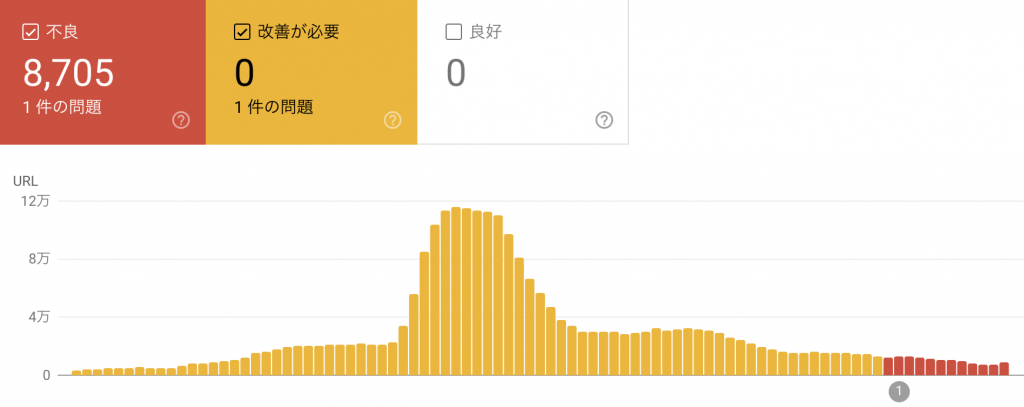
ご覧の通り、クロールされた多くのページが課題のあるページと認識されている状況です。このように認識されてしまう理由としては、GoogleがWebページの評価指標として提供している「Core Web Vitals」の値が低いことが挙げられます。
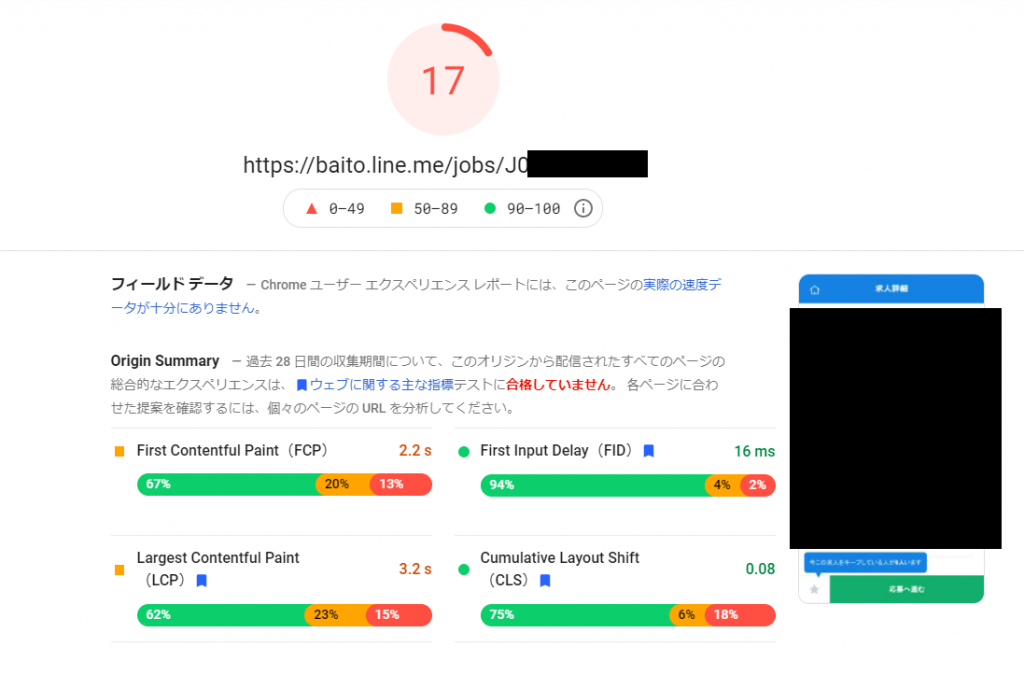
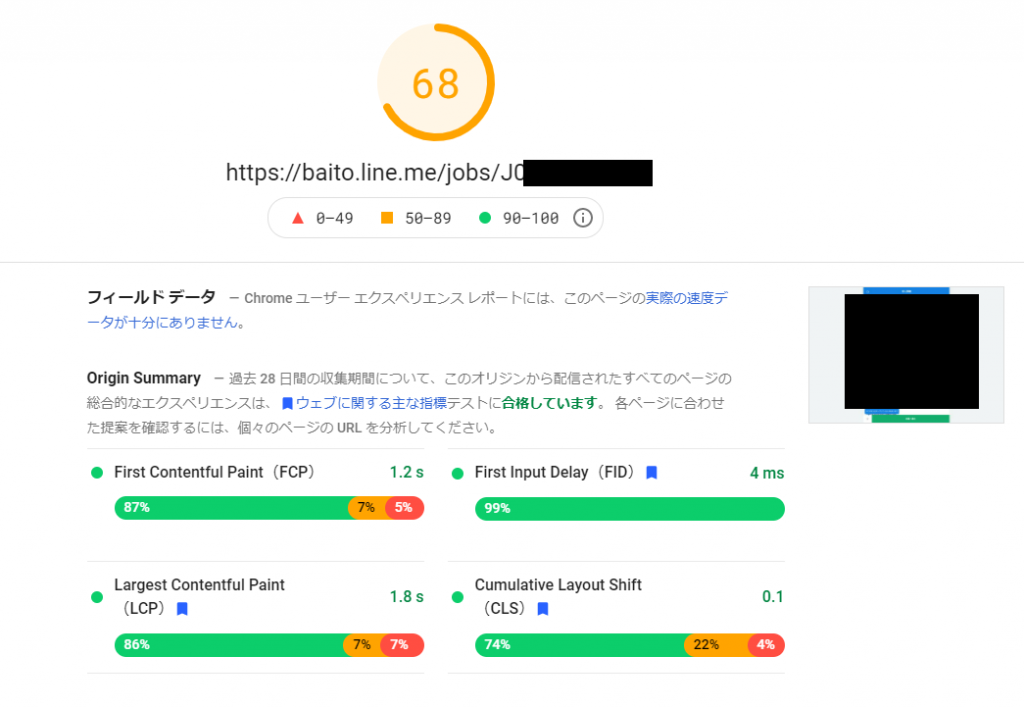
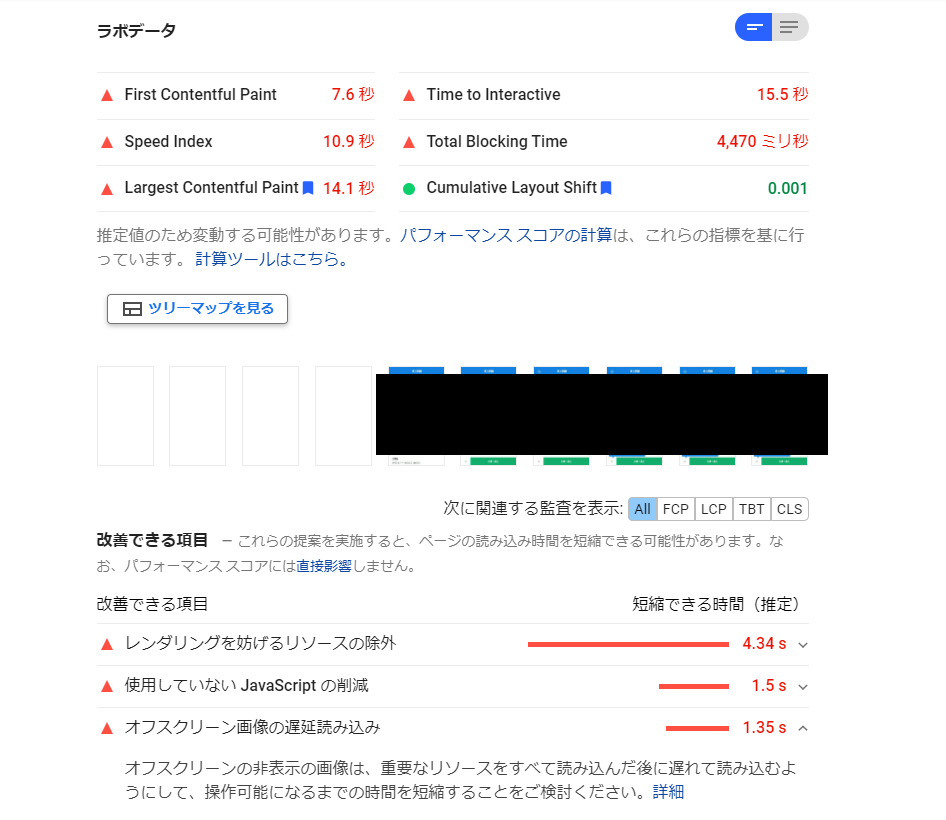
下の画像は、GoogleのPageSpeed Insights (https://developers.google.com/speed/pagespeed/insights/) で、とある求人詳細ページを調べた様子になります。実際の企業の情報が出てしまっている部分は、黒塗りで編集を施しています。
| Mobile | PC |
|---|---|
 |
 |
 |
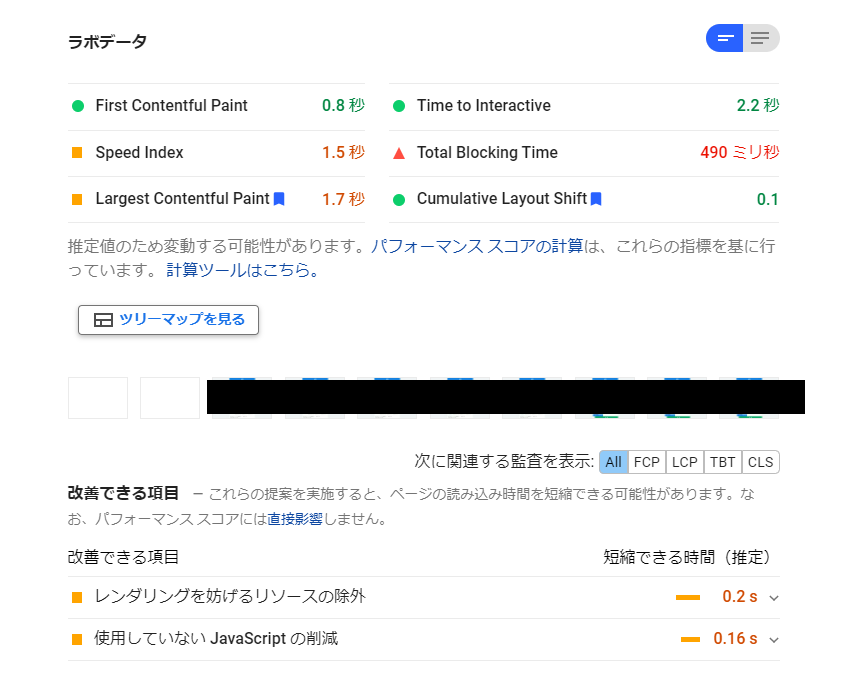 |
上の図を見て頂ければわかるように、求人詳細ページはあまりよいスコアとはいえません。また、これは特にモバイル版だと非常に顕著であることが分かります。検索順位の向上を図っていくうえで、パフォーマンスの改善は不可欠であるように思います。
解決策の検討と実装
では実際に、これらの課題に対してどのような解決を取り組んでいったのかについて述べていきたいと思います。
本インターンでは、先ほど課題としてあげた求人詳細ページのパフォーマンスの改善に主に取り組みました。
パフォーマンスを改善するうえで、まずは客観的な指標をとる必要があります。「課題」の章でも触れた指標ではありますが、ここではGoogleがパフォーマンスを測る指標として提唱している「Core Web Vitals」(https://web.dev/vitals/#core-web-vitals) を採用しました。Core Web Vitalsでは、ページの読み込みの指標として、LCP (Largest Contentful Paint) が挙げられています。これは、ビューポート内で最大の要素が描画されるまでにかかる時間のことです。「課題」の章に載せた図の通り、現状では特にモバイル版でLCPの値が悪く、改善が必要なことが分かります。
まずは、なぜモバイル版でのLCPがここまで悪いのかを調査しました。
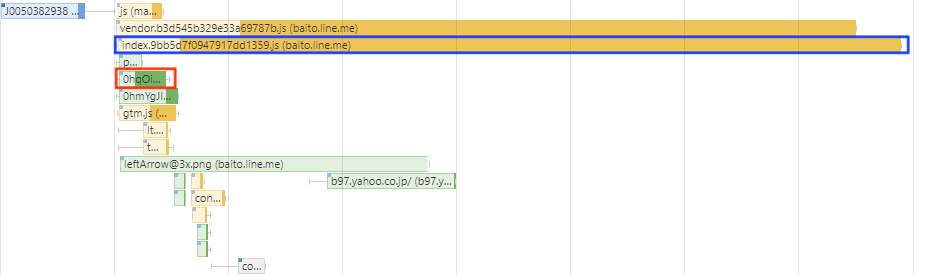
以下の図は求人詳細ページが描画されるまでの通信の様子になります。
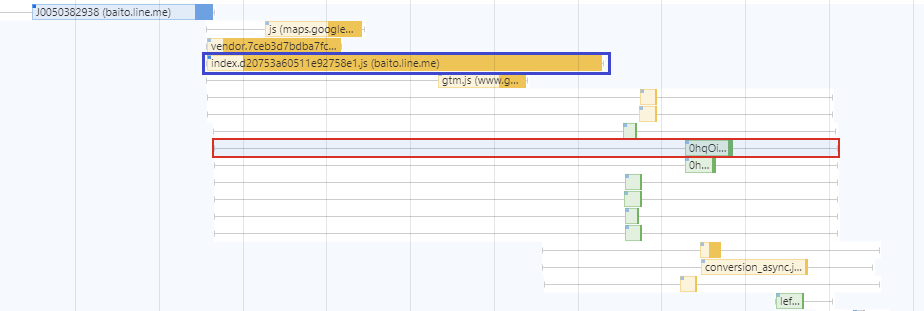
ここで、図中赤枠で囲まれているのがLCPの対象となっている画像に関する通信を表しています。ここで注目したいのが、画像のfetchが始まるタイミング (図中箱ひげ図の箱の左端) が、そもそも非常に遅いということです。なぜここがこんなに遅くなってしまっているのかを調査した結果、図中青い枠で囲まれているバンドルファイルのfetchが後のhtmlのパースおよびほかのリソースのfetchを妨げてしまっているからだということが分かりました。
前述の通り、LINEバイトはReactアプリをExpressサーバーでSSRするという構成をとっています。SSRは、サーバー側で初期表示のhtmlを生成するため、初期表示までにかかる時間が短いということが大きな利点として挙げられます。しかし、このようにバンドルファイルのfetchがhtmlのパースを妨げてしまっては、せっかくSSRしている利点が半減してしまいます。
この課題の解決策としては、サーバーから返すhtmlの中のバンドルファイルを読み込むscriptタグに適切な属性を加えることで、読み込みを非同期にするということが挙げられます。まずはこちらを実装しました。
scriptの非同期読み込み
scriptタグに付与できる属性はdefault (何も付与しない), async, defer があり、これらには以下のような違いがあります (https://html.spec.whatwg.org/multipage/scripting.html#attr-script-async)
- default : scriptのfetchおよびexecutionの間htmlのパースはストップする
- async : scriptのfetchはhtmlのパースと並行して行われ、fetchが完了すると一度パースをストップしてexecutionが行われる
- defer : scriptのfetchがhtmlのパースと並行して行われ、htmlのパースが完了してからexecutionが行われる
今回の目的に合っているのはdefer属性で、このdefer属性を加えることで、scriptのfetchによって残りのhtmlのパースをブロックされなくなるため、初期表示を早めることができます。
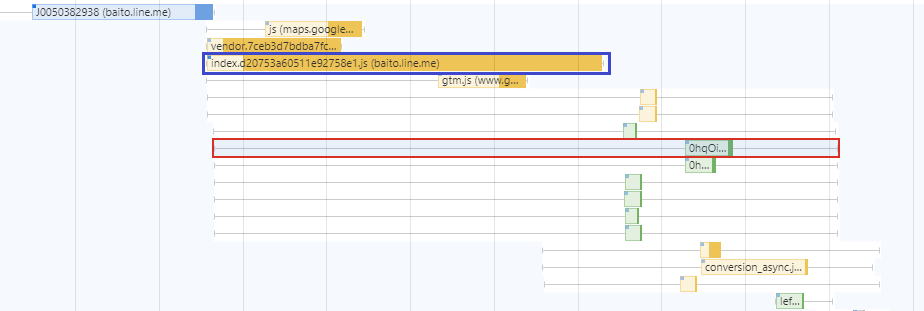
これを実装した結果、通信の様子は下図の様に変化しました。赤枠で囲ったLCP対象の画像のfetchが大きく早まっている様子がわかります。
| Before | After |
|---|---|
 |
 |
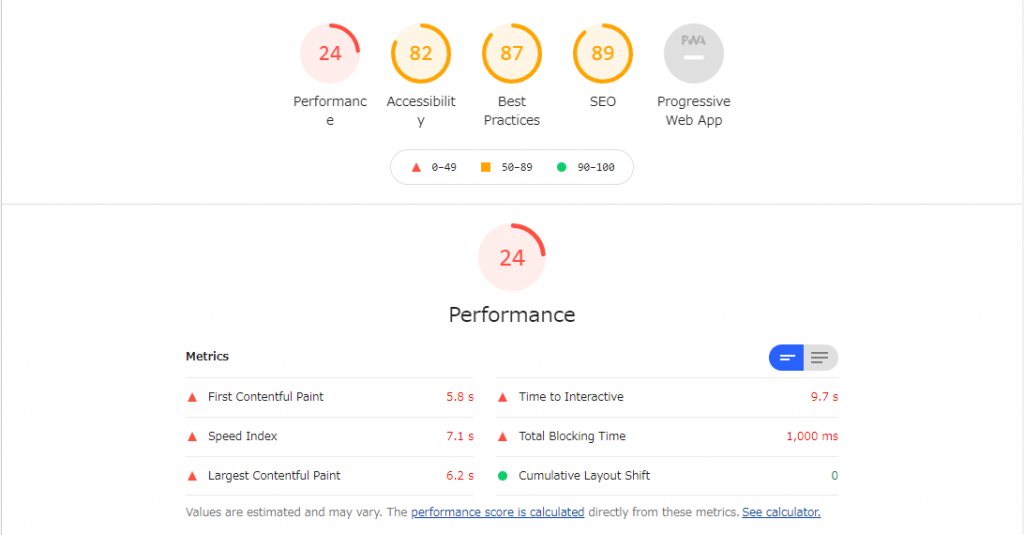
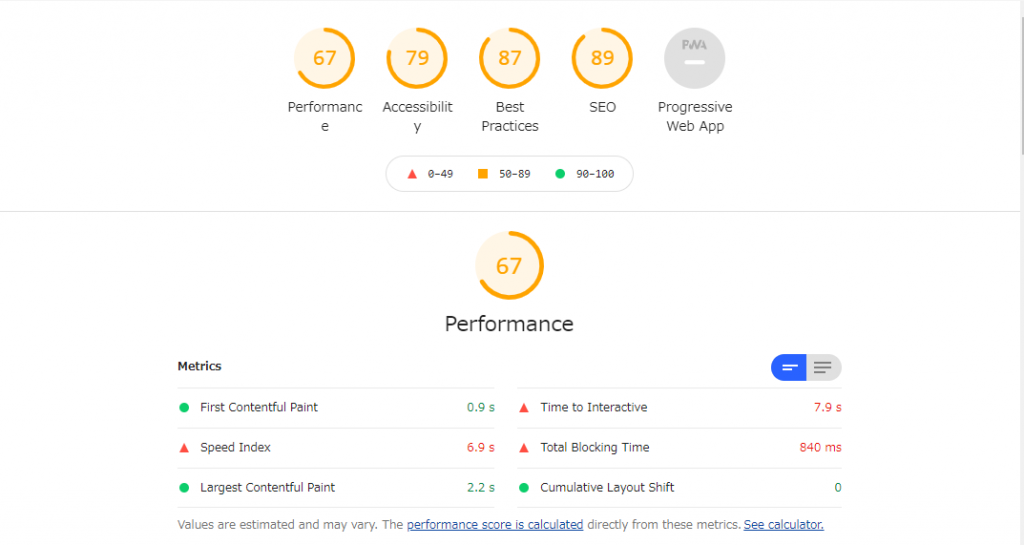
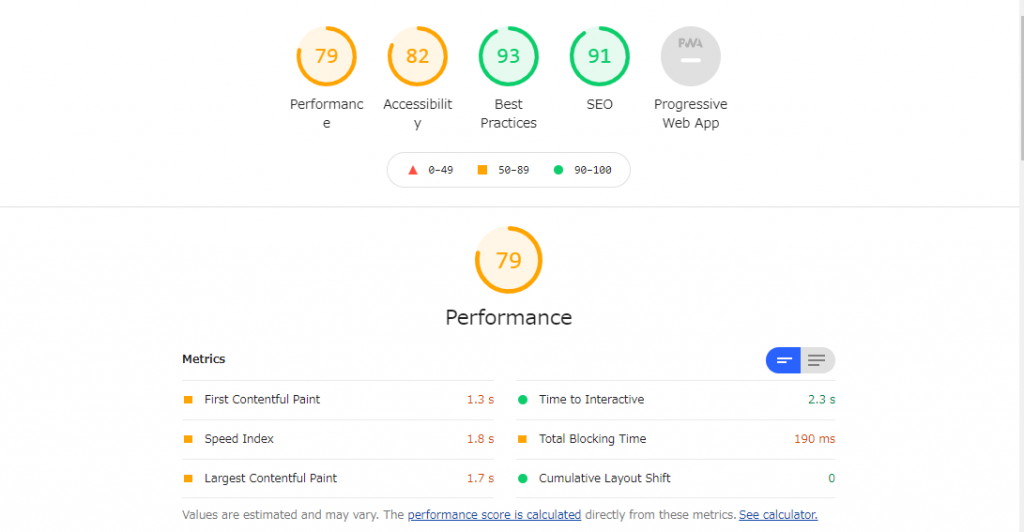
開発用のbeta環境でdefer属性をつける前と後でLighthouseでスコアを比較したところ、以下の表のようになりました。
| Before | After | |
|---|---|---|
| Mobile |
 |
 |
| PC |
 |
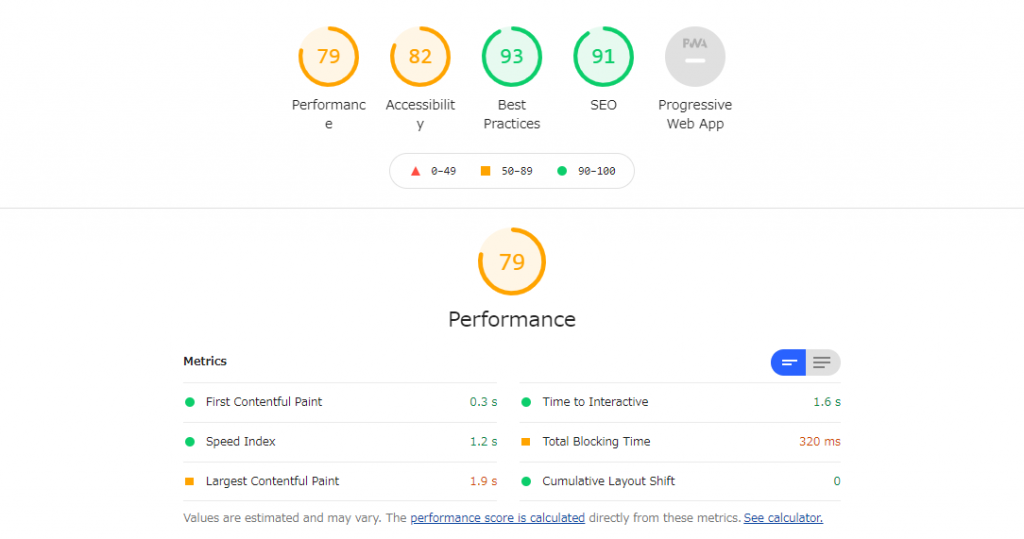 |
PC、Mobileともに、FCP(First Contentful Paint : 最初の要素が描画されるまでの時間) が大きく改善していることが分かります。これは、scriptのfetchによってhtmlのパースがブロックされなくなったことによって、Reactのhydrateを待たずに描画できる部分は先に描画できるようになり、SSRの長所が十分に生かされた結果であるということができます。FCPが大きく改善したことによって、MobileではLCPも大きく改善されていることが分かります。
しかし、PCではFCPは改善しているものの、LCPには改善が見られません。これはなぜなのでしょうか。
調査の結果、PCとMobileでは、ビューポートのサイズが異なることによって、LCPの対象となるビューポート内の最大の要素が異なることが原因であることが分かりました。前述のとおりMobileではLCP対象は画像であった一方で、PCではLCP対象は「求人情報内の段落」が対象となっていることが分かりました。この部分はちょうどデザインのABテストが実施されており、Reactのhydrateを待たずには描画できない部分であったため、画像のfetchやhtmlのパースが早まったとしてもLCPの改善は見られなかった、という事情があったのでした。
なお、これは調査の副産物的に明らかになったことですが、もともとPCとMobileでパフォーマンスに大きく差があるのは、単にLCP対象が異なるという事情があるだけではなく、PCとMobileではパフォーマンスの計算に使われている回線やCPUの条件が異なっているという背景があることも分かりました(https://github.com/GoogleChrome/Lighthouse/blob/master/docs/throttling.md) 。
さて、この対応により (特にMobileのLCPを中心に) 大きな改善が見られた訳ですが、さらにパフォーマンスを向上させるために、再度performanceタブなどを見ながら次に注目したのが、「バンドルファイルのサイズが大きすぎる」という部分でした。
Dynamic Import を利用したRoute単位でのCode Splitting
先程の施策により、SSRをしている長所が活かされ、最初にコンテンツを描画するまでの時間を非常に早めることができました。しかし、今回のPCでの例の様に、Viewport内最大の要素がReactのhydrateを待たないと描画できない場合、LCPという観点から見るとその利点が十分に発揮されなくなってしまうことがあります。こういった状況でLCPを改善する(すなわちReactのhydrateの完了を早くする)ためには、バンドルファイルのサイズを小さくするという解決策が知られています。バンドルファイルサイズが小さくなることで、fetch及び評価にかかる時間が短縮されるため、結果としてReactのhydrateを早めることができるのです。
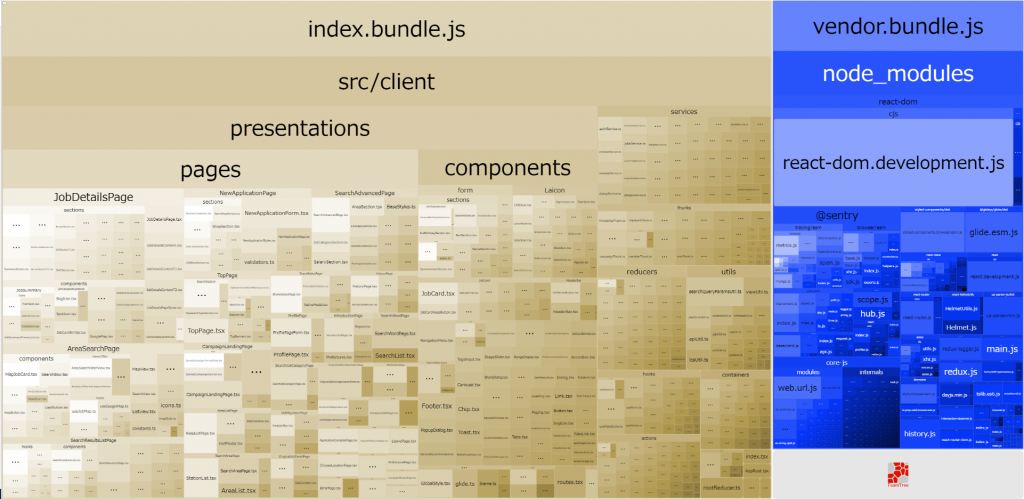
LINEバイトのバンドルは、Webpack (https://webpack.js.org/) を用いて行っており、アプリ全体のソースを1つにまとめたindex.jsのファイルと、node_modulesをまとめたvendor.jsのファイルの2つを生成する形でした。しかし、アプリ全体のソースを1つのjsファイルにバンドルするというのはパフォーマンスの観点から見ると勿体無いと言えます。なぜなら、そのファイルの中で初期表示に必要なのは、アクセスされたページで使用する部分のみであるためです。
したがって、初期表示のためにfetchするjsを最小限にするために、ルート単位でバンドルファイルを分けることを考えました。これは、WebpackがjavascriptのDynamic Importを見つけるごとにバンドルファイルを分けてくれる、という仕様を持っている (https://v4.webpack.js.org/guides/code-splitting/) ので、これを利用することで実現することができます。具体的には、各ルートにおける最上位のコンポーネントに対して、Dynamic Importを適用すれば良い、ということになります。しかし、単に各ルートの最上位のコンポーネントにDynamic Importを適用しただけだと、ルートを遷移したときに、新たなjsをfetchする間ブランクページが表示されてしまうため、フォールバックの対応が必要になります。
こういったDynamic Importの非同期処理にうまく対応してくれる枠組みとして、Reactはlazyという関数を提供しています (https://reactjs.org/docs/code-splitting.html#reactlazy) 。この関数は、コンポーネントのDynamic Importを行う関数を引数として取り、遅延コンポーネントを生成するというものです。この遅延コンポーネントを、Suspenseコンポーネントの内部に含めることで、遅延コンポーネントのfetchの間、Suspenseコンポーネントに指定したフォールバック用のコンテンツを表示することができます。
しかし、React.lazyは、SSRに対応していないという課題があるため、今回使用することは困難です。SSRでCode Splittingを実現する場合、サーバー側で初期表示に必要なチャンクを認識し、サーバーから返すhtml内に含めた上で、クライアント側でそれらのfetchを行う必要があります。これらを行なってくれるパッケージとして、loadable-components (https://loadable-components.com/) や、react-imported-component (https://github.com/theKashey/react-imported-component) などが挙げられます。ここで、loadable-componentsは、バンドラがWebpackに限定されてしまうという欠点があります。現在LINEバイトではWebpackを利用していますが、将来的に変わっていく可能性があることも考えると、バンドラに依存しない方が好ましいということで、今回は、react-imported-componentを採用しました。
このパッケージでは、React.lazyと同様に、importedComponentという関数で、コンポーネントをDynamic Importする関数を受け取り、遅延コンポーネントを生成します。また、importedComponentの第2引数で、オプションとして、jsをfetchしている間のフォールバック用のコンポーネントを指定できます。ここで生成された遅延コンポーネントをImportedControllerコンポーネントの内部に含めることで、遅延読み込みやそのフォールバックの処理をうまく行うことができます。また、SSRへの対応として、サーバーサイドではprintDrainHydrateMarksという関数、クライアントサイドではrehydrateMarksという関数がそれぞれ用意されており、初期表示に必要なチャンクがうまく受け渡しされる様になっています。
今回はこのパッケージを利用し、各ルートの最上位のコンポーネントを遅延コンポーネントに置き換えた上で、各コンポーネントのフォールバック用のコンポーネントの開発も行いました。このような対応によって、1ルートにつき1バンドルファイルにすることができたうえに、ルート間の遷移においてもブランクページが表示されないということを実現しました。バンドルの様子は以下の様になりました。
| Before | After | |
|---|---|---|
| バンドルの様子 |
 |
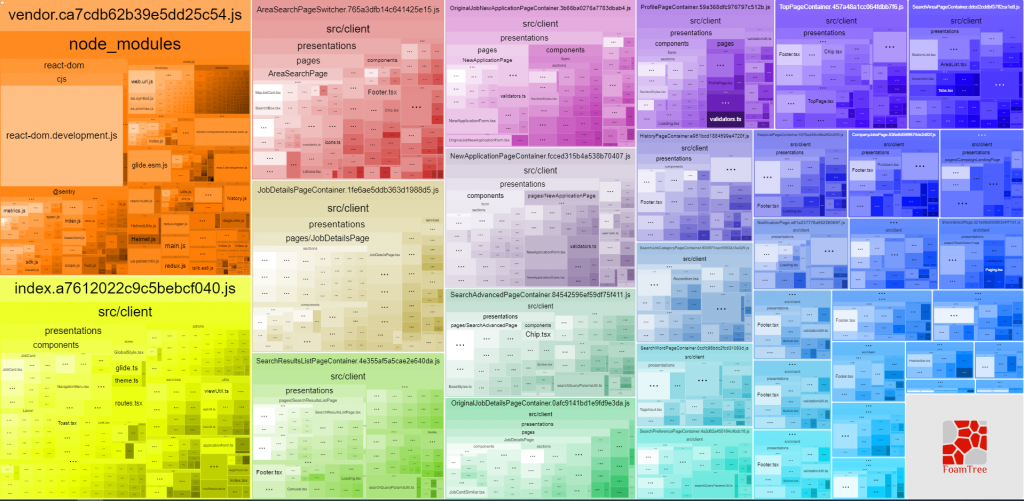 |
| 求人詳細ページでfetchするjsのファイルサイズ | 2.6Mb | 1.0Mb |
なお、この対応に併せて、node_modulesをバンドルしたvendor.jsのファイルサイズも縮小したいと考え、不要になっているパッケージの見直し、削除も行いました。結果として、求人詳細ページの読み込みの際にfetchするjsのファイルサイズは、2.6Mb => 1.0Mb と約1.6Mbの削減を行うことができました。
PrefetchやPreloadを用いた更なる改良
本インターンではさらに、preloadやprefetchを用いて、このCode Splittingによる施策の改善に取り組みました。
前述の通り、react-imported-componentでは、初期表示に必要なコンポーネントはrehydrateMarksという関数がよばれて初めてfetchされる訳ですが、これは下図の"before"のように、まずindex.jsとvendor.jsのfetchをして実行したのちに、初めて行われます。しかし、よく考えてみると、expressサーバーにリクエストが来た段階で、そのページで必要なコンポーネントというのはわかるので、該当するjsも、index.jsやvendor.jsと同時にfetchさせることができるはずです。まずはこれを実装しました。
この実装には、linkタグによってリソースをpreloadさせる方法を採用しました (https://developer.mozilla.org/en-US/docs/Web/HTML/Link_types/preload) 。実装としては、サーバーにリクエストが来たタイミングで、そのルートの最上位コンポーネントに該当するjsのバンドルファイルをサーバーから返すhtmlのheadタグの中にlinkタグとして挿入した、という形になります。これによって、下図のように通信時間の短縮を行うことができました。
| Before | After |
|---|---|
 |
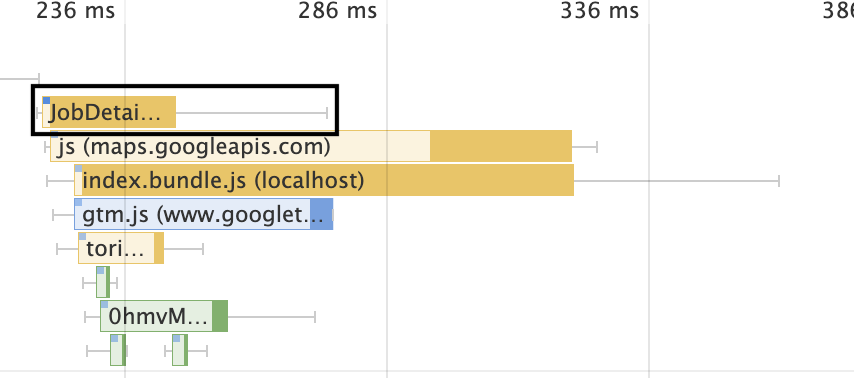 |
※黒の四角で囲われている部分が、そのページで必要なjsになります。
これによって、初期表示に関する通信はほぼ最適化されたのではないかと思います。
もう一点、これは初期表示には関係がないですが、ユーザー体験に影響を及ぼす改善として、ルート遷移の時間の短縮も合わせて行いました。Code Splitting を行うことによって初期描画を改善できた一方で、ルートの遷移時には分割されたコードを逐次読み込むため、待機時間が生まれてしまいます。フォールバック用のコンポーネントを表示したとしても、ユーザー体験を悪くしてしまう要因となるため、次のような戦略で解消しました。
概要は、ルートが変化したタイミングで、そのルートから次に遷移されやすいルートのコンポーネントのjsについてはprefetchを行なっておく、というものです。「ルートが変化したタイミング」の検知には、react-routerのuseRouteMatchフック (https://v5.reactrouter.com/web/api/Hooks/useroutematch) を利用しました。また、「次に遷移されやすいルートのコンポーネント」については、理想的には、Linkタグの検出などから自動で行いところではありましたが、今回はその各ルートに対して、依存関係を整理した配列を手動で作成し、該当するコンポーネントをprefetchさせるようにしました。
なお、遷移可能な全てのルートのprefetchを行なってしまうと、特に色々なページへ飛ぶことができるトップページなどではその大量のprefetchが逆にユーザー体験の悪化をさせてしまう可能性もあるため、今回prefetchの対象は、多くの人がアクセスする主要なページに限定しました。
さて、以上がCode Splittingの施策の全貌です。最終的な通信の様子は以下のようになります。赤枠がそのページで必要なjs、青枠がindex.jsとvendor.js、緑枠が次の遷移先で必要なjs となっています。

GoogleMapの遅延読み込み
以上のCode Splittingの施策と並行して、パフォーマンス改善の施策としてGoogleMapの遅延読み込みの実装も行いました。
求人詳細ページには、企業の位置を示したGoogleMapのiframeが配置されています。しかし、ほとんどの場合において、GoogleMapの位置はページの下部であり、初期表示の段階でGoogleMapを生成しておく必要はありません。GoogleMapの生成にはいくつかのリソースのfetchやAPIコールを伴うため、これを初期表示に合わせて行うことはパフォーマンスに若干の悪影響を及ぼすことになります。
したがって、GoogleMapは、スクロールが行われたタイミングで初めて生成するように修正しました。スクロールの検知にはいろいろな方法があるとは思いますが、今回はintersectionObserver (https://developer.mozilla.org/en-US/docs/Web/API/Intersection_Observer_API) を用いて実装しました。
結果
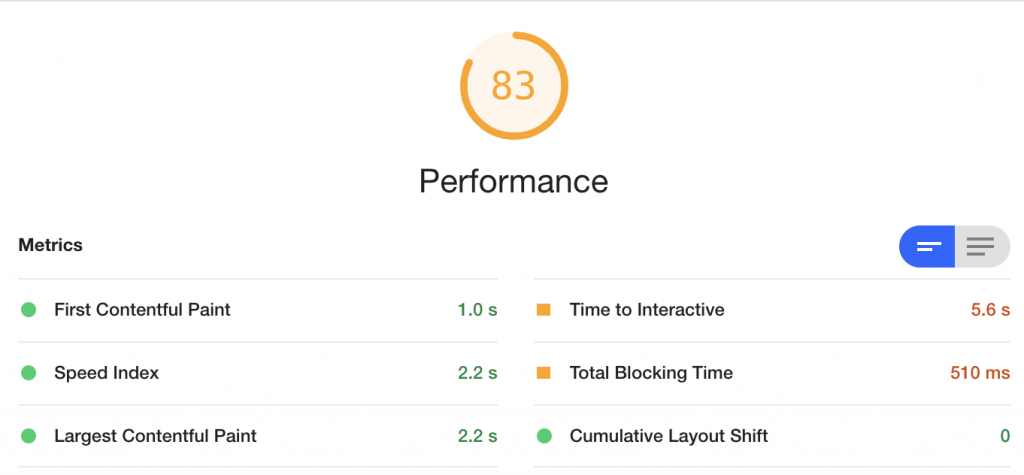
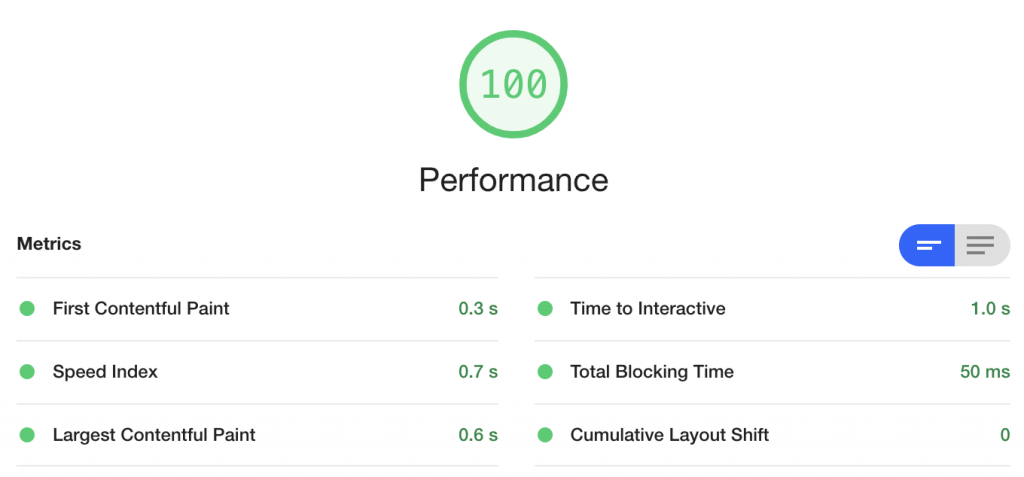
以上のような様々なパフォーマンス改善の施策によって、最終的なLighthouseのパフォーマンスは以下のようになりました。
もともとのパフォーマンスが20程度だったMobileでも80を超える数値に、そして、PCではなんと100を達成しました。
| Mobile | PC |
|---|---|
 |
 |
今回取り組んだこれらの施策はまだリリースされたばかりで、直接的に検索順位の向上につながったデータまではまだ取れていませんが、このパフォーマンス向上の施策によって、検索順位やユーザー体験が向上し、結果として流入のセッション数の増加にもつながっていくことが期待できると考えています。
Googleリッチリザルトへの対応 (求人詳細ページ)
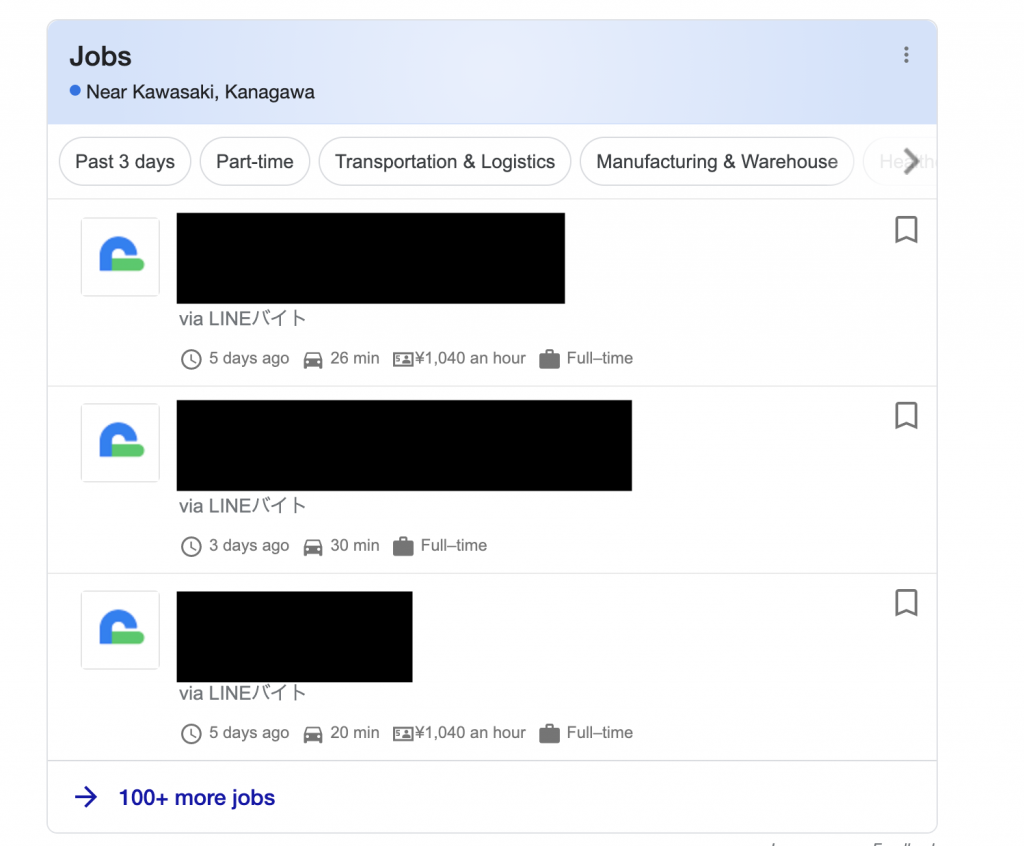
また、パフォーマンス改善とは違った文脈なのですが、求人詳細ページに関しての流入を強化するという部分で、Google のリッチリザルトへの対応を行いました。リッチリザルトとは、通常の検索結果とは別に、(例えば求人の例であれば) 求人が一覧となって表示される、というものです。htmlの中に、scriptタグで求人情報に関する構造化データ (JSON-LD) を挿入しておくことで、Googleがそのページをクロールした際にそれを認識し、リッチリザルトに表示をしてくれます。
実装としては、LINEバイトでは React Helmet (https://github.com/nfl/React Helmet) というパッケージを用いて、headタグをページごとに動的に作成していたので、そこにPropsとして構造化データを渡すようにしました。なお、構造化データの生成には、React Helmet とも相性が良く、構造化データの型を保証してくれる react-schemaorg (https://github.com/google/react-schemaorg) というパッケージを用いました。
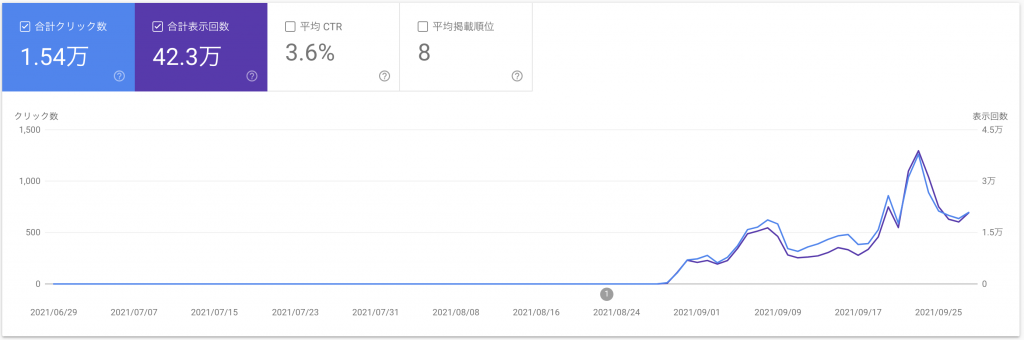
その結果下図のように、求人情報のリッチリザルトが表示されるようになり、流入としても1日500クリック程度は獲得できるようになりました。
今後への課題と展望
ここまで、求人詳細ページのパフォーマンス改善をメインとして様々な施策に取り組み、Web最適化に関して一定の成果を上げることができた旨を述べてきましたが、「LINEアプリ内ブラウザ以外のWebブラウザからの流入の強化」という最終目標を達成するためにはまだ課題が残されています。
ここでは特に、ここまでのブログでは触れてこなかった「求人一覧ページ」に残されている課題からスタートし、今後の改善の展望などについて述べたいと思います。
求人一覧ページの課題
一般に、Googleなどの検索結果からの流入について考える場合、求人掲載サービスとしては、「〇〇(職種) 求人」や「〇〇(場所) 求人」のような検索ワードで上位に掲載されることが、流入につながりやすい大きな要因であると考えることができます。LINEバイトでは、職種や場所に応じた求人の検索結果は「求人一覧ページ」で見ることができるため、このためには「求人一覧ページ」の検索順位が重要になってくることになります。
しかしながら、調査の結果、求人一覧ページについては、そもそもGoogleにほとんどインデックスされていないことが明らかになりました。インデックス登録がなされていなければ、検索結果の上位に出てくることはありません。
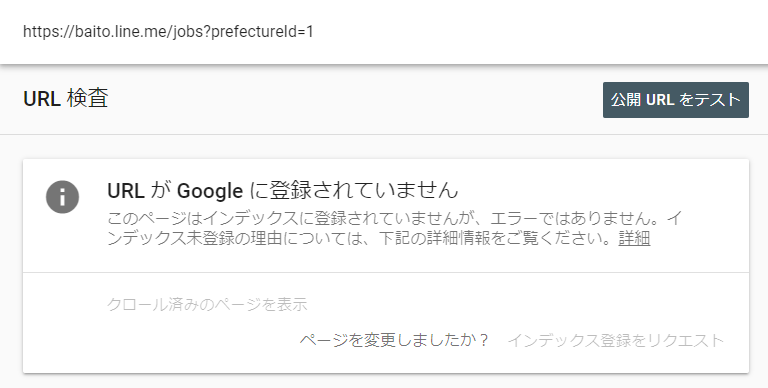
この原因としては、求人一覧ページがクエリパラメータによって表示させる求人を変化させるという設計をとっており、直接そのクエリパラメータのついたURLに飛ぶリンクが内部に存在しない (求人検索のページで適切な条件を設定して検索ボタンを押した場合にのみそのURLに飛ぶことができる) ため、クエリパラメータのついた各検索結果のページのURLをGoogleにクロールしてもらえないためではないかと分析しました。例えば、北海道の求人一覧ページのURL (https://baito.line.me/jobs?prefectureId=1) をGoogle Search Consoleを用いて調べてみても、下図のようにURLがGoogleに登録されていないことが分かります。
求人一覧ページに関してとり組んだ施策と、さらに明らかになった課題
この課題の解決として、まずは各県についての検索条件のクエリパラメータのついた求人一覧ページがGoogleにインデックス登録されることを目指しました。
Googleにインデックス登録をしてもらうには、そのURLがGoogleに認識され、クロールされる必要があります。ですが、各県の求人一覧ページについてより深く調査してみると、当初各県の検索結果のURLは、下図の様にGoogleに認識すらされていないことがわかりました。認識されていない状態では当然クロールもしてもらえず、インデックス登録もしてもらえません。

今回のインターンでは、インデックス登録の前に、まずは各県についてのクエリパラメータがついたURLをGoogleに認識してもらえるようにするため、サイトマップを作成することにしました。
サイトマップの作成
サイトマップの作成については、登録したいパスを与えるとサイトマップを自動生成してくれるスクリプトを作成しました。今後、各県の検索結果のみならず、路線や職種などについてもインデックス登録を目指していく可能性が高いことを踏まえて、分野ごとに分割した個別のサイトマップと、それらを統括する全体のサイトマップを同時に生成するようにしました。
このようにサイトマップを作成し、Googleに登録した結果、各県の検索結果のURLについては、「検出-インデックス未登録」という状態になりました。

この状態は、該当のURLはGoogleに認識自体はされているもののクロール対象になっていない、という状態です。GoogleのJohn Mueller氏が、Google Webmaster Central office-hours hangout にて、この状態になってしまう原因について、該当のURLに対して内部リンクがなくそのページが孤立してしまっている可能性があることや、そのページの中身のコンテンツがほとんどないか別のURLと重複しているとみなされている可能性があることなどを挙げています。
このJohn Mueller氏の話を踏まえると、現状のLINEバイトの求人一覧ページについては、サイトマップを作成はしたものの、やはりクエリパラメータつきのURLへの内部リンクが存在しないことが課題となり、インデックスされるまでに至ることができなかったのではないかと考えられます。またこのことに加えて、現状ではユーザーがLINEアカウントでログイン済みかどうかによって叩くAPIを分けている関係で、SSRの段階では求人が載っていないロード中のページが生成されてしまっており、Googleのボットには各ページが内容のないページであるとみなされてしまっている可能性があることも明らかになりました。
今後の改善の展望
求人一覧ページが検索上位にくることは、検索からの流入を考えるうえではやはり欠かせないことであるため、まずは前述の求人一覧ページの課題の解決をしていきたいと考えています。より具体的には、クエリパラメータ付きの各求人一覧ページへの内部リンクが存在しないことを解消するために、内部リンクを一覧として並べたサイトマップページを作成することや、サーバーから返ってくるHTMLが内容のないページでなくすために、SSRの段階で、求人の一覧が入ったページが返される様に修正していくことなどが挙げられると思います。
こういった施策に取り組んでいくことで、最終的には「〇〇(職種) 求人」や「〇〇(場所) 求人」のような検索ワードで上位に掲載されることを実現し、LINEアプリ内ブラウザ以外からの流入を拡大していきたいと考えています。
まとめ
今回のインターンでは、パフォーマンス改善を含む (広い意味での) SEOや、リッチリザルトへの対応など、非常に幅広い領域に取り組ませて頂くことができました。当初の目標であった流入の増加という点についていうならば、特に求人一覧ページについて大きな課題が残っていることなどあり、直接的に大きな成果をあげるまでに至ることはできませんでしたが、そのための第一歩としては大きな貢献ができたのではないかと思っております。また、これまで個人でフロントエンドの開発をしていた際には、今回取り組ませていただいたようなバンドルの設定やパフォーマンス最適化などについて考えることがあまりなかったため、自分自身としても様々なことについての理解が深まり、非常に勉強になりました。加えて、こういった技術面だけではなく、本インターンでは社員の方と全く同様にミーティングや交流会に参加させていただくことができたため、企業の雰囲気であったり、LINEでフロントエンドエンジニアとして働くということがどのようであるかといった点についても深く知ることができ、大変貴重な経験でした。
最後になりますが、今回自分を温かく迎え入れてくださった部署の方々、そしてお忙しい中頻繁にzoomで質問などに答えてくださったメンターの方に心から感謝申し上げます。ありがとうございました。