
はじめに
こんにちは。技術職 就業型コースのインターンシップに2021年8月2日から9月10日までの期間で参加しました松田光司です。私は大阪大学大学院情報科学研究科の修士1年生で、大学院ではFederated learningに関する研究をしています。
今回のインターンではData Science室のLINE Platform Data Scienceチームに所属し、高口太朗さんと大塚優さんにメンターになっていただきました。LINE Platform Data ScienceチームではLINEスタンプ事業に関わらせていただき、主にスタンプクリエイターの分析を行いました。
本記事では、インターン期間中に私が取り組んだことをご紹介します。
背景
スタンプ事業では、選抜されたクリエイターのスタンプ作成を支援する LINE Creators Support Program というプログラムを行っています。
具体的には、新作スタンプのプロモーション支援、専属担当の LINE社員による制作サポート、LINEサービスへの起用斡旋などを行います。
LINE Creators Support Program をはじめとする支援策を通じて、ユーザーから見たスタンプの価値向上とスタンプ市場の活性化を目指しています。
課題・仮説
LINE Creators Support Program では、一律のサポートをしたものの、売上の増加率は個々のクリエイターごとに大きなばらつきがありました。また、サポートのないクリエイターについても、何らかのきっかけで急に売上を伸ばして人気クリエイターとなる人が存在します。
そこで、「スタンプクリエイターのヒットを決める要因は何か」という大きな課題に取り組みました。
課題に取り組むにあたり、事業部の方とミーティングを行い仮説を立てました。
それは、世の中の流行りを作るのは若者であることを踏まえて、「若者に認知されていたクリエイターが、他年代の購買層女性に知られるのが1つの勝ちパターンである」という仮説です。
分析
この仮説を検証するべく、「スタンプクリエイターのヒットを決める要因は何か」という課題をブレイクダウンして以下の3つの分析を行いました。
- クリエイターごとのスタンプ購買層にはどんなパターンがあるか?
- ヒットと購買層のパターン変化にはどのような関係があるか?
- ヒットするにはどうすれば良いか?
これらについて詳しく説明していきます。
分析1:クリエイターごとのスタンプ購買層にはどんなパターンがあるか?
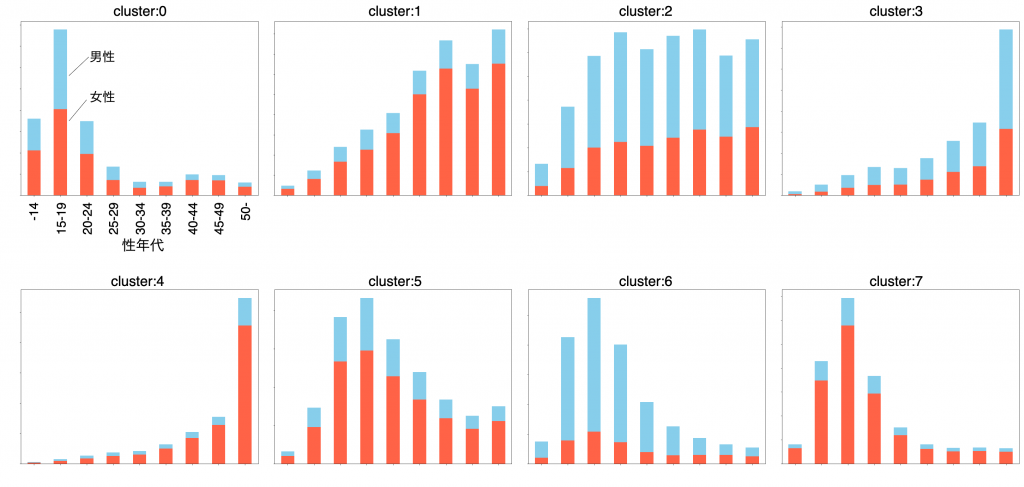
購買層のパターン化にはクラスタリングを使用しました。各性年代(機械学習による推定値)の売上割合に対して、kmeans++を使用してクラスタリングを行い、クラスタ数をエルボー法によって決定しました。
しかし、結果は上手くクラスタリングできませんでした。理由としては、kmeans++の距離メトリックが元々ユークリッド距離であり、確率分布間の類似度を測るものとしては不適切であることが考えられます。
そこで、距離メトリックをJensen–Shannon Divergenceに変更することを考えました。Jensen–Shannon Divergenceとは確率分布間の類似度を測る指標であるKullback–Leibler divergenceを双方向となるように拡張したものです。
scikit-learnのkmeans++では距離メトリックの変更ができないので、任意のメトリックに変更できるようにkmeans++の関数を自作し、クラスタリングを行いました。結果が下図のようになり、8つのパターンに分けることができました。例えば、クラスタ4は50代以上の女性に人気という特徴があります。
分析2:ヒットと購買層のパターン変化にはどのような関係があるか?
分析1によって、クリエイターごとのスタンプ購買層をパターン化することができました。そこで、次にヒットと購買層のパターン変化にはどのような関係があるのか分析しました。ここで、1年間の売上が前の1年間の売上から大きく伸びたクリエイターを「ヒットしたクリエイター」として抽出しました。
そして、分析1の各クラスタの中心点を用いてヒットしたクリエイターのクラスタを計算し、クラスタ間の推移を調べました。結果は下図のようになりました。まず対角線にあたる遷移のパターンが多いことから、ヒットしたクリエイターでも購買層のクラスタの推移は起きていないことが読み取れます。次に、クラスタ間の推移が起きている箇所についてその中心点を見てみると、購買層が似ているクラスタ間での推移であることがわかりました。
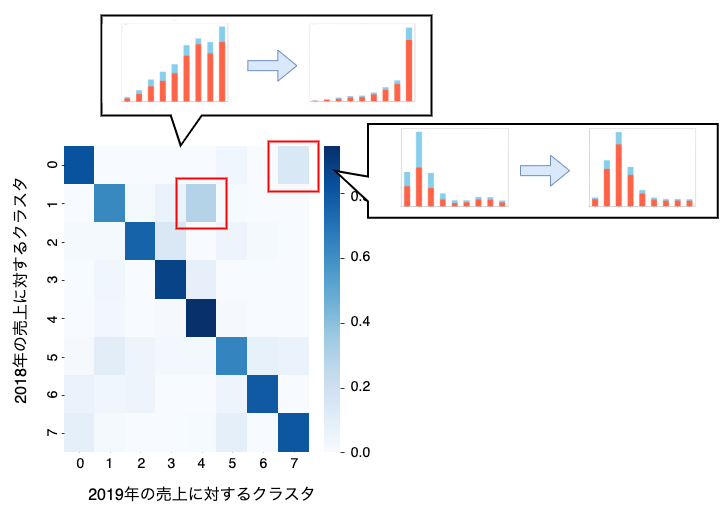
この結果より、当初設定した仮説は間違っており、購買層を保ったまま売上を伸ばすクリエイターが大多数であることが分かりました。
分析3:ヒットするにはどうすれば良いか?
分析2によって、ヒットには購買層の変化は関係ないことが分かりました。そこで、何がヒットの要因になるのかについて分析を行いました。
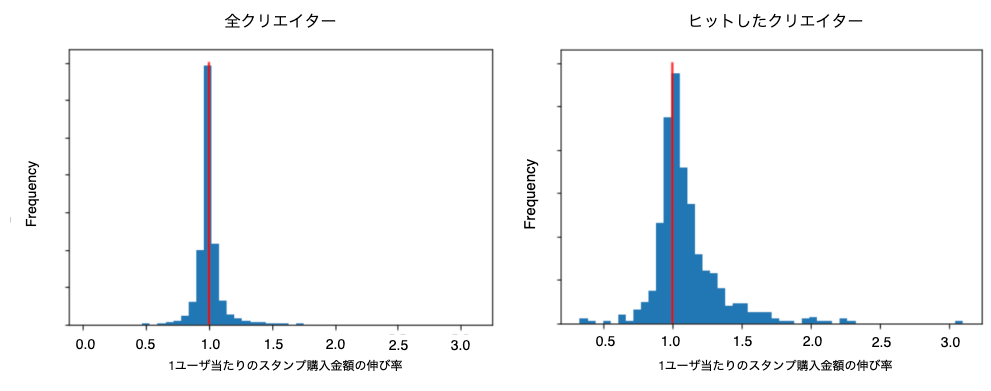
結論としては、1ユーザ当たりのスタンプ購入額が伸びたことが1つの要因ではないかと考えられます。下図は、1ユーザ当たりのスタンプ購入金額の伸び率のヒストグラムを表しています。
この図より、ヒットしたクリエイターは全体と比べて1ユーザ当たりのスタンプ購入金額の伸び率が大きく、多くのクリエイターが1を超えています。すなわち、ヒットしたクリエイターは新規顧客の獲得だけではなく、複数のスタンプを購入するという意味でのファンももしっかり構築していることが分かります。
結論
分析1,2,3によって、若者に認知されたクリエイターが他年代の女性に人気が出るという勝ちパターンは稀であり、無理に自分のスタンプのテイストを変えて新しい購買層の開拓に励むよりも、現在の購買層を維持しながら売り上げを伸ばす方が現実的であることがわかりました。その際、新規顧客を獲得するだけでなく、例えば季節特有のスタンプなど様々なバリエーションのスタンプを販売し、複数セットのスタンプを買ってくれるようなファンを構築することが大事ということが分かりました。
おわりに
LINEの保有する膨大なデータを使ってデータ分析をしたことは、とても良い経験になりました。
データを分析するだけでなく、事業部と二人三脚で進めるということも少し体験できて、データサイエンティストの業務理解が深まり、とても学びの多いインターンでした。
データ分析の経験が浅く、最初は不安だったのですが、メンターの方がとても優しく、しっかりと議論をしながら分析を進めることができたため、充実したインターン生活を送ることができました。
また、社員の方のレベルがとても高く、スキル面だけでなく思考法についてもとても学ばせていただきました。
データサイエンティストの業務を体験し、成長したいという方にはLINEのデータサイエンティストのインターンはとてもおすすめなので、興味のある方はぜひエントリーしてみてください!