
Research Labsの戸上と小松です。LINEには海外カンファレンスや学会への参加を支援する制度があり,会社負担で学会に参加することが可能です。
今回は,音声・音響信号処理におけるトップカンファレンスである,IEEE Signal Processing Society主催のICASSP2019 (International Conference on Acoustics, Speech, and Signal Processing) に参加し,聴講と音源分離・音声強調技術に関する3件の発表を行ってきました。
ICASSPは今回で44回目となり,2012年には日本の京都でも開催されました。LINEはICASSP2019のBronze Patronとしてスポンサーになっています。Signal Processing Societyは,日本ではあまり知名度が高くはないですが,IEEEの全Societyの中で4番目に大きいSocietyであり,音声・音響処理の研究フィールドとしては世界最大です。
今回のICASSP2019の投稿数は約3700件とのことであり,前年度の約2800件を大幅に上回り,人工知能関連分野の過熱感がより一層高まっていることを強く感じました。当日の参加者数の公式発表は無かったと記憶していますが,5000人程度の来場者があったように思います。10以上のセッションがパラレルに進行し,どのセッションも賑わっており,特にポスターセッションは常に人であふれかえっていました。
会場の雰囲気
今年のICASSPの会場はイギリスの港町ブライトンにある会議場、The Brighton Centre。パブとナイトクラブで有名な街で、会場から出ると即ビーチ。まだまだ空気は肌寒かったですが、現地の方々がビーチでビールを談笑していたり、とても穏やかでゆっくりとした街でした。
 |
 |
(写真)桟橋(Brighton Pier)で行われたWelcome Receptionにて。
会議では、上で述べたように、人工知能分野の人気に伴い参加者が増加したのか、例年よりも賑やかで熱いディスカッションが行われていたように感じます。
会議中のコーヒーブレイクのときには珍しくお酒も振る舞われ、ポスターセッションや他の研究者の方々とのコミュニケーションも、さらに熱く親密になった気がします。
ほろ酔いでのディスカッションは白熱します。

聴講した発表
ICASSP2019では,戸上は主に音源分離を中心に,小松は,音響イベント検出を中心に,音響信号処理に関する研究発表を聴講いたしました。
1. 音源分離関連の動向
今回のICASSP2019で注目したのは,教師なし深層学習を用いた音源分離技術の出現と,時間周波数マスクを用いた音源分離技術の広がりです。一般的に,深層学習では入力データと正解データのペアデータを必要としますが,正解データは必ずしも手に入るわけではありません。このような場合に適用可能な技術として,従来の音響信号処理で使われている教師なし音源分離技術の結果に似た分離結果が出るようにDeep Neural Network (DNN)を学習するような方式が提案されています[1,2]。深層学習が空間情報を入力特徴量として用いないように制限することで,従来の空間情報を用いた教師なし音源分離技術で問題となる,空間モデルの不正確さに基づく音声歪みは学習せず,妨害音の抑圧性能だけを向上できる点が特徴でした。深層学習の入力特徴量を制限することが,分離性能向上につながるという構成は,とても新鮮であり,他の音響信号処理にも応用可能な構成だと感じております。
2. 音響イベント検出の動向
音データに対する教師あり識別問題であり、その音が何であるのか(イベント)、その音がどういった環境(シーン)で収録された音であるのかを理解するための技術です。今年はチュートリアルも開催され、300人以上の会場で立ち見が出るなど非常に熱気を感じました。毎年、専門のワークショップDCASE (Detection and Classification of Acoustic Scenes and Events) も開催されており、音声・音響分野において最もホットなトピックの一つです。

(画像)DCASEホームページより引用。
今年のICASSPで発表された手法で多く見られた課題設定としては、「低いクオリティのラベルを用いた学習方法」です。通常、音のラベリングは人が耳で聞き続けて行わなければならず、1時間の音のラベル付けに5時間以上かかることもあります。たとえばCDの音質の音ですと、44.1kHz、つまり1秒間に44100点の要素が含まれるデータに「○○秒から○○秒まではこの音がなっている」というラベルを付与せねばならず、常に集中力が要求される負荷の高い作業です。そこで、簡単に付与できるが不確かなラベル、たとえば時間区間が曖昧なラベル、クラウドソーシングなどで得られた間違いを含むラベル、などから、高精度な識別器を学習する技術の重要度が高くなります。今回、本トピックに関してLINEのResearch Labsからの発表はありませんでしたが、今後注力していきたい分野の一つです。
LINEの発表
今回,LINEからは戸上の3件の発表が採択され,ポスターセッションで発表してきました。戸上は2018年6月にLINEに入社以後,物理的にわかっていることは積極的に知識としてうまく活用し,分からない部分を深層学習でデータから学習する方針で,特に教師ありの深層学習と従来の教師なしの音響信号処理で使われているような音の空間伝搬モデルを用いた手法を如何に統合するかに注力して研究を進めてきましたが,その成果の一部を発表できたことが良かったと思います。1件目と2件目は,同一セッションでの発表となりました [3,4]。この2件は,いずれも深層学習に基づく音源分離技術(複数のマイクロホンを用いて,複数の音声を分離する技術)に関する発表で,最後の1件 [5]は,深層学習に基づく音声強調技術(複数のマイクロホンを用いて,音声と背景雑音とを分離する技術)の発表でした。
1.Multi-channel Itakura Saito Distance Minimization with deep neural network [3]
音声の音量が時間変動することと話者の場所が変わらない限り空間伝搬モデルは不変である事を利用した時変ガウスモデル[4]に基づいた音源分離技術で必要となる二つのパラメータ(音声の時間周波数毎の分散と空間相関行列)を深層学習で求める音源分離方式を提案いたしました。これらのパラメータを求めるDNNをパラメータ毎に正解値を定義して最適化するのではなく,最終的な分離音声の音質がよくなるように最適化する点が特徴で,DNN最適化のための損失関数として,今回,時変ガウスモデルの事後確率に相当するMulti-channel Itakura Saito Distance (MISD)を提案しました。提案する損失関数は設定した確率モデルとの一貫性があり,また正則化項を含む事から安定的にDNNを学習でき,二乗誤差規範の損失関数などの他の損失関数と比較して分離性能が向上することを確認いたしました。
2.Spatial Constraint on Multi-channel Deep Clustering [4]
昨年のICASSP2018で他研究機関より提案されたMulti-channel Deep Clustering (MDC) [7]をベースに,音の空間伝搬モデルに基づく2つの情報を用いた音源分離手法を提案しました。MDCは各マイクペアの位相差を入力特徴量の一部として用いるのに対して,提案法は,時間周波数毎の音源方向を入力特徴量として用いることで,計算量が用いるマイクペアの数に比例しないような構成になっています。また,二つのBidirectional Long Short Term Memory (BLSTM)層間に空間モデルに基づく音源分離を挟み込むことにより,DNNの潜在変数の推定値が空間伝搬モデルの観点で妥当な推定値になることを促進し,分離後の音声の歪を減らすことが可能となります。
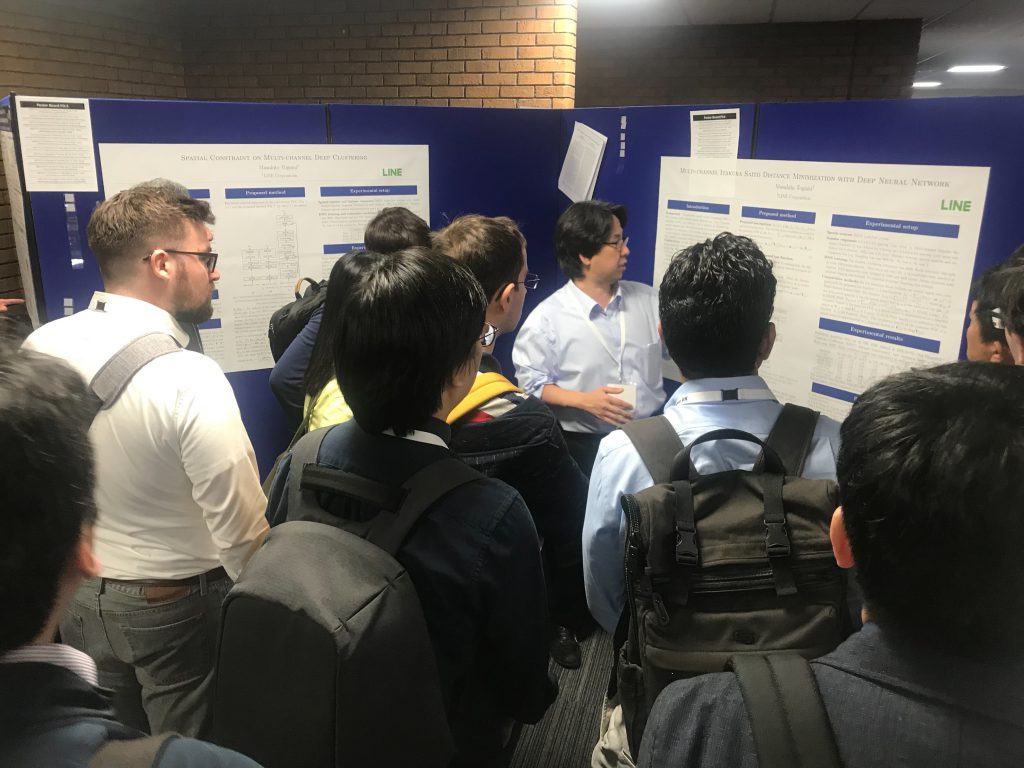
3. Simultaneous Optimization of Forgetting Factor and Time-frequency Mask for Block Online Multi-channel Speech Enhancement [5]
音声強調法には,一発話のデータが手に入った後に処理を始めるオフラインの音声強調法と,時々刻々データが手に入るたびに処理を進めるオンラインの音声強調法とがあります。オンラインの音声強調では 過去の情報をどのくらいのスピードで忘れるかを制御する忘却係数の設定がとても重要となります。忘却係数が小さいほど安定した音声強調が可能になりますが,一方環境変動があった際の追従速度が下がります。逆に忘却係数が大きいほど,環境変動の追従速度が向上します。本発表では,オンラインの音声強調法において,忘却係数と音声強調に必要な時間周波数マスクとをDNNで同時に推定する手法を提案しました。忘却係数を何を手掛かりに推定するかは自明ではなく、本研究では3つの特徴量(入力音の振幅スペクトル,過去のフィルタを用いた分離音の振幅スペクトル,過去の空間相関行列と入力信号との間の積)を提案し,過去のフィルタを用いた分離音の振幅スペクトルが最も良い結果をもたらすことを確認しました。

サリー大学訪問
国際会議参加に際し、近隣の大学へ訪問することも、研究者同士の関係性を構築するのにとても有効です。
最先端の研究を行っている研究者たちと、会議中には行えないような濃いコミュニケーション、ディスカッションを行うことができます。
今回は、サリー大学(University of Surrey)の、音響イベント/シーン分析の大家 Prof. Mark Plumbleyの研究室へ訪問しました。一度ICASSP開催地のブライトンから一度ロンドンへ戻り、電車を乗り継ぎ30分ほどのところです。
 |
 |
Plumbley教授には、今回の我々の訪問を快く承諾していただいたうえ、彼の率いる研究センターCVSSP (CENTRE FOR VISION, SPEECH AND SIGNAL PROCESSING)のミニツアーも開催していただきました。
https://www.surrey.ac.uk/people/mark-plumbley
ツアーでは自由聴点オーディオ、環境音分析のデモンストレーション、学生や研究者の方々の研究紹介をしていただきました。

多くの研究者と意見交換ができただけではなく、最先端の研究を行っている研究室ならではの高度な設備やデモンストレーションを体験することができ、とても有意義な訪問であったと感じています。
Plumbley教授と研究者のみなさんとは、ぜひ日本に来る機会があれば次はLINEのオフィスにも遊びにきてください、と約束をしてお別れしました。
参考文献
[1] E. Tzinis, S. Venkataramani and P. Smaragdis, "Unsupervised Deep Clustering for Source Separation: Direct Learning from Mixtures Using Spatial Information," ICASSP 2019, pp. 81-85.
[2] L. Drude, D. Hasenklever and R. Haeb-Umbach, "Unsupervised Training of a Deep Clustering Model for Multichannel Blind Source Separation," ICASSP 2019, pp. 695-699.
[3] M. Togami, "Multi-channel Itakura Saito Distance Minimization with deep neural network," ICASSP 2019, pp. 536-540.
[4] M. Togami, "Spatial Constraint on Multi-channel Deep Clustering," ICASSP 2019, pp. 531-535.
[5] M. Togami, "Simultaneous Optimization of Forgetting Factor and Time-frequency Mask for Block Online Multi-channel Speech Enhancement," ICASSP 2019, pp. 2702-2706.
[6] N.Q.K. Duong, E. Vincent, and R. Gribonval, “Underdetermined reverberant audio source separation using a fullrank spatial covariance model,” IEEE Trans. Audio Speech Lang. Process., vol. 18, no. 7, pp. 1830–1840, 2010.
[7] Z.Q.Wang, J. Le Roux, and J.R. Hershey, “Multi-channel deep clustering: Discriminative spectral and spatial embeddings for speaker-independent speech separation,” ICASSP 2018, pp. 1–5.
お知らせ
7/5 19:30より,ミライナタワーのLINEオフィスにて,東京農工大学とLINE共催で,University of Southern CaliforniaのOrtega先生(東京農工大学の特任教授です)の講演会を実施いたします!!ICASSPでもホットトピックとなっておりますグラフ信号処理に関してご講演いただきます。また,東京農工大学のグローバルイノベーション研究院のご紹介を田中聡久先生より,LINEのResearch Labsのご紹介と本blogでも触れさせて頂いた音響信号処理技術のご紹介を戸上より致します!懇親会もございますので、皆様、是非ご参加下さい!!(https://line.connpass.com/event/135072/)申し込み期限は6/28 16:00です。