
Data Labs の Bundo です。
私が所属するData Analysis チームでは、データを活用したLINEサービスの事業価値向上に取り組んでおります。
LINEには、社員の海外カンファレンスや学会への参加を推奨しており、会社がチケット費用や渡航費をすべて負担する支援制度があります。データサイエンスに関する最新の知見を得て業務に活用するために、 2018年11月17日〜20日に開催された国際会議 ICDM 2018 に聴講参加してきました。
ICDMについて
International Conference on Data Mining (ICDM)は、Institute of Electrical and Electronics Engineers (IEEE)が主催する国際会議の一つです。
2018年の今年は11/17~11/20の期間、シンガポールで開催されました。
1日目はテーマごとに分けられた22のワークショップや博士討論会があり、2~4日目からは本会議に入りました。本会議では、招待講演や180以上の論文発表などが行われました。
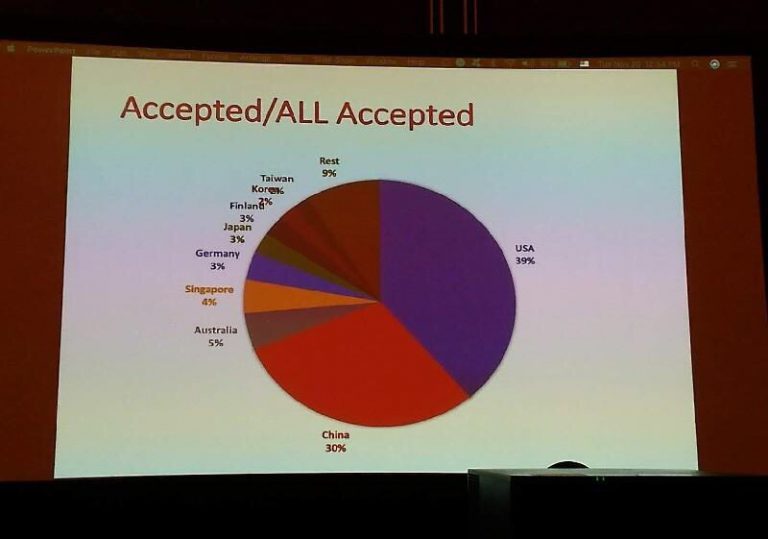
本学会は論文採択率が低く、コンピューターサイエンスを学ぶ学生が発表を目指すトップカンファレンスの一つです。発表者は企業よりも大学の関係者が多く、採択された論文の著者は米国出身が40%、中国出身が30%を占めており、日本出身は3%という比率でした。
業界はIT、バイオメディカル、都市計画、教育、金融など多岐に渡っており、扱われているトピックはレコメンドシステム、深層学習、転移学習、異常検知、時系列データの分類、ネットワーク、クラスタリングなどなどで、数理モデルの基礎研究から応用まで幅広いテーマをカバーしている学会でした。
聴講した発表について
今回私は最先端の研究に触れると共に、「ユーザー行動の理解と予測」に関する事例を学ぶことを主なモチベーションとして参加しました。そのモチベーションに適う、興味深かった発表を3つほど紹介します。
1. A Blended Deep Learning Approach for Predicting User Intended Actions
論文リンク : https://arxiv.org/pdf/1810.04824.pdf
Adobe Systems Inc.による論文で、ユーザーの離脱予測のモデリングと要因の可視化に関する内容でした。離脱の要因を理解し、それを事前に防ぐことは、事業の存続や拡大の観点で非常に重要な課題です。この目的での離脱予測はこれまで大きく二つの方法で実施されてきました。
一つ目はRandom Forestなどのアンサンブル学習器を使って、離脱か否かを予測する方法です。この手法は予測精度が高いものの、変数選択において課題がありました。ユーザーは複雑な行動をするため、どの期間を用いて変数を作成したとしても、全ての行動を網羅していなければ真のユーザー行動を捉えているとは言えません。モデル作成者が変数を選択する時点で、ユーザーの真の行動とは異なっている点が課題でした。二つ目は生存分析であり、ユーザーの初期状態に依存して離脱のタイミングを予測する方法ですが、途中の行動をモデルに組み込むことができないという課題がありました。またこれらの手法ではモデルを作成しても、解釈が難しいという課題も存在しました。
本論文で紹介されているBlended Deep Learning Approach (BLA)という手法は、ユーザーのサービス開始から直近までの全てのデータを使ってこれまでの手法の欠点を解決した予測方法です。この手法の変数は「activity path」「dynamic path」「static path」の3つから構成されています。例えば音楽視聴アプリのサブスクリプションプランからの離脱を予測する例を考えると、「activity path」はアプリ使用開始から直近までの誰が、いつ、アプリを起動したか、アプリのある機能を使用したかというログです。「dynamic path」は誰が、いつ、どんなプランを使用しているか、どんな音楽を聞いたかというログです。「static path」は性別、誕生日、マーケットセグメントなどユーザーごとに一意の変数です。
本手法はこれらの3つ全ての「path」をブレンドしてDeep Learningによって離脱するか否かの二値分類予測を実施しています。まず3つの「path」それぞれを畳み込み、次元削減を行ってから、3つの「path」の変数を用いて、シグモイド関数によってスコアを算出しています。
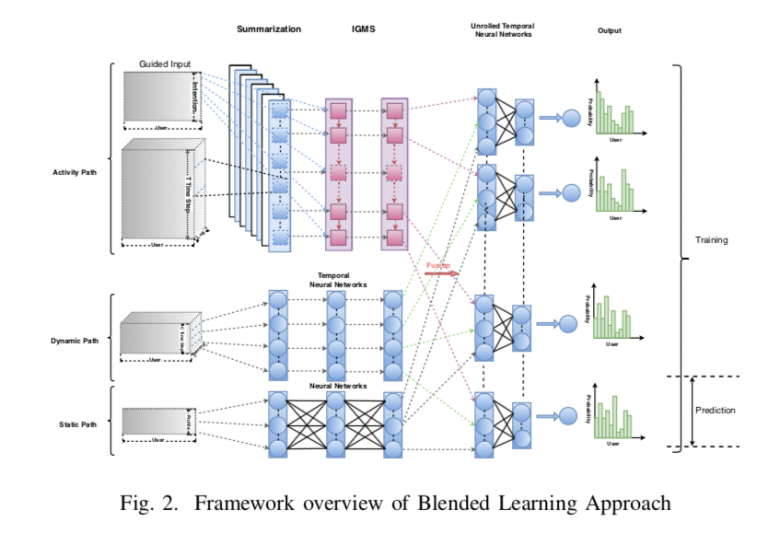
また離脱の要因解釈では、予測スコアに対して、どの変数がスコアの高低に寄与しているか偏微分を使って求めるSaliencyという手法を用いています。この手法を使うと、Deep Learningの予測スコアに対してどの変数が寄与しているかを理解することができ、ユーザーの行動理解も可能になります。
このように、今回のBLAとSaliencyという手法を用いることによって、従来の問題点であった、変数選択時にバイアスがかかることや、モデルを作成しても解釈ができないといった問題点を解決できたと主張しています。また実際のデータに対して適用してみたところ、Random Forestやそのほかの二値分類予測の手法よりも予測精度が高いという結果が得られていました。
全てを真似できないまでも、部分的にも非常に参考になる発表でした。
2. EPAB: Early Pattern Aware Bayesian Model for Social Content Popularity Prediction
論文リンク : http://chaoqiyang.com/source/ICDM2018.pdf
上海交通大学とTencentによる論文です。
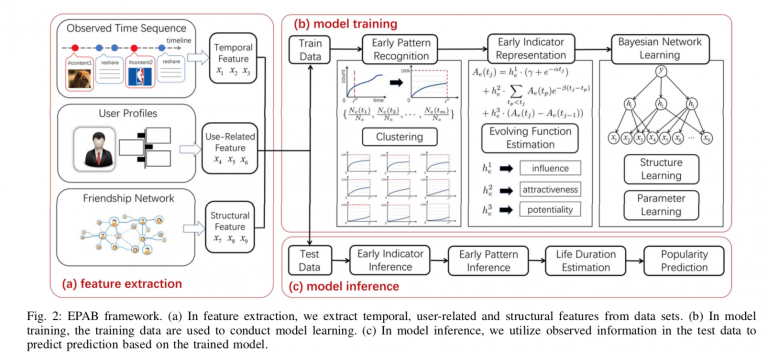
EPABとはTwitterにおけるハッシュタグ、ニュースの記事やブログのトピック、タイムラインでシェアされる投稿の文言などのコンテンツの人気度合いを早いタイミングで予測する手法です。またコンテンツの人気要因を分解することによって、キーとなるコンテンツのモニタリング、レコメンド、広告のターゲティングに活用できると主張している発表でした。この論文で用いられている「コンテクスト」とは、ユーザーの背景や心情まで理解できる文脈のあるコンテンツという意味です。マーケティング業界では、消費者の背景や心情(文脈)を理解して、ふさわしい商品やサービスを提供することを意味する「コンテクスト・マーケティング」という用語があり、EPABもユーザー行動の文脈を捉えた上で、人気を予測できる点で、コンテクスト・マーケティングに活用できる手法です。
まずEPABのポイントは、コンテクストが出現してから初めの1、2時間のデータのみで学習モデルを作成している点です。入力情報としては、ハッシュタグを例にとると、タグが使用された時刻と回数、使用したユーザーの属性情報、ユーザー間のネットワーク情報です。最終的な出力は、将来に渡る累計のハッシュタグの使用回数です。入力する特徴量は膨大なため、直接最終出力を予測するモデルを作成するのではなく、中間層に3つの変数を挟んでいます。3つの変数の潜在的な意味としては、1.コンテクスト自体のインパクト、2.コンテクストの伝播性、3.コンテクストの今後の可能性であり、この3つの変数の係数を推定してから最終的な人気度合いとパターンを出力できるようにベイジアンネットワークモデルを作成していました。
実際にTwitter、WeChat、Weiboのデータを用いて実験を実施したところ、従来の手法と比較して良い評価結果が得られていました。
精度を出すために長期間のデータを必要とせず、早い段階で人気度合いを予測できる点、人気が高まりそうなタイミングが分かる点、人気に影響する要因が分かる点が、このモデルの特徴であり、運用する上での利点と考えられます。ベイジアンネットワークを試してみたくなる発表でした。
3. Effective Steering of Customer Journey via Order-Aware Recommendation
論文 : Effective Steering of Customer Journey via Order-Aware Recommendation.pdf
Philips の「HUE」というスマート照明のレコメンドモデルに関する内容でした。
ポイントはユーザーのスターターキットから最終購入品までがどのようなパスで購入されているかを可視化するために、まずカスタマージャーニーを作成している点です。このカスタマージャニーをベースに、ユーザーがどのパスを辿ってきたかを説明変数とします。そして、同じような購入履歴を辿ってきた他のユーザーが購入している商品を推薦することによって、協調フィルタリングを用いたレコメンド手法よりも、ユーザーのLTVを上昇させることができたと述べています。
カスタマージャーニーを考慮することによって、「次に何を一番買うか」ではなく、「何を買わせればそのユーザーのLTVが最大化するか」という視点でレコメンドを作成していることを強調しておりました。この発表を聞いて、モデルやロジックを作る際に何を目的変数に置くべきかが重要であることを再認識しました。
最後に
同じ業界の方と情報交換をしたり、普段はお会いできない異分野の方とお話したり、優秀な学生から刺激を受けたりと発表の聴講以外でもとても有意義な時間を過ごすことができました。このような貴重な機会をいただけたことに感謝したいです。
Data Labs Data Analysisチームでは、データサイエンティストを積極的に募集しています。最新の研究動向を学んで業務に活かせる機会がたくさんありますので、興味のある方はぜひ応募をご検討ください。