
こんにちは、LINEのプライベートクラウドサービスであるVerdaのLoad Balancer as a Service (LBaaS) のチームでTech Leadをしている早川です。このエントリでは私が2019年4月にLINEに入社してからの約2年半で体験した大規模LBaaSならではの興味深い問題をピックアップしてご紹介します。
Verda LBaaSについて
VerdaのLBaaSは2016年ごろに稼働を開始したVerdaの中でも比較的歴史が長いサービスです。当時のLINEではハードウェアのアプライアンス製品を用いて提供されていたロードバランサのサービスを置き換える目的で開発されました。特徴としては実際にユーザのトラフィックを受けるいわゆるデータプレーンと呼ばれるコンポーネントも含めて全てがソフトウェアで実装されているということが挙げられます。
中でも個人的に気に入っているのは、L4LBのデータプレーンはLinuxのXDP (eXpress Data Path) という機能を用いて自前で実装されており、非常に高い性能が出せるという点です。2016年当初はXDPがmainlineカーネルに入ってから1年経つか経たないかというくらいの時期だったことを考えると、非常に先進的な技術を取り入れたプロダクトだと言えると思います。Verda LBaaSについての詳しい話が気になる方は、私がLINE DEVELOPER DAY 2019のプレゼンテーションで色々と紹介していますので、是非チェックしてみてください。
サービスの急成長
Verda室ではLINEの全てのインフラリソースをVerdaで提供するという "All Verda" のスローガンの元、ロードバランサも含めた旧来のインフラで提供されているサービスをVerdaに移行するキャンペーンを行ってきました。Verda LBaaSが東京のプロダクション環境で使われ始めた時期は2018年9月ごろです。そこから徐々にアプライアンスLBへの設定依頼と新規筐体の購買を廃止し、Verda LBaaSを使うようユーザにお願いをしてきました。以下は2018年からのインスタンス数 (≒ VIPの数) の推移を月ごとに表したグラフです。
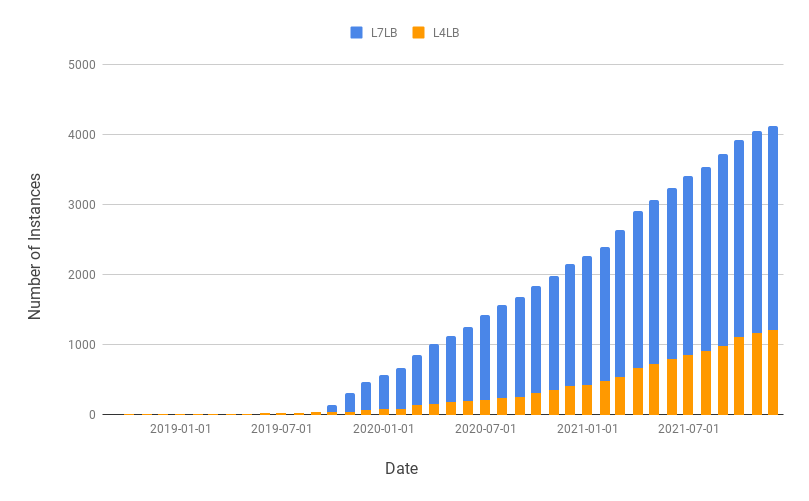
2019年の9月ごろから急激にインスタンス数が伸びているのがわかると思います。これはその頃にリリースされたL7LBサービスをユーザが使い始めたことがきっかけだと思われます。そこから2019年当初には約100弱だったインスタンス数が2年弱で約4000にまで膨れ上がりました。ちょうど成長期とも言えるこの時期、Verda LBaaSプロジェクトではこのスケールならではの色々な問題が起こりました。今回はその中から特に興味深かった (と同時に辛かった) 2つの問題とそれらに対して我々がどのように対処したかを紹介したいと思います。
Case1: L4LBサービスのヘルスチェックの性能問題
Verda LBaaSではユーザのバックエンドサーバに対するヘルスチェック機能をサポートしています。各L4LBノードではデータプレーンと共にヘルスチェックエージェントが動作しています。ヘルスチェックエージェントは自身に登録されているバックエンドサーバに対して定期的にHTTP GET等を送信し、正常にサーバが動作しているかどうかを確認します。数回連続で正常なレスポンスを得られなかった場合、そのバックエンドを転送の対象から外すようにデータプレーンを設定します。こうすることによって異常なバックエンドによるサービス影響を避けることができます。
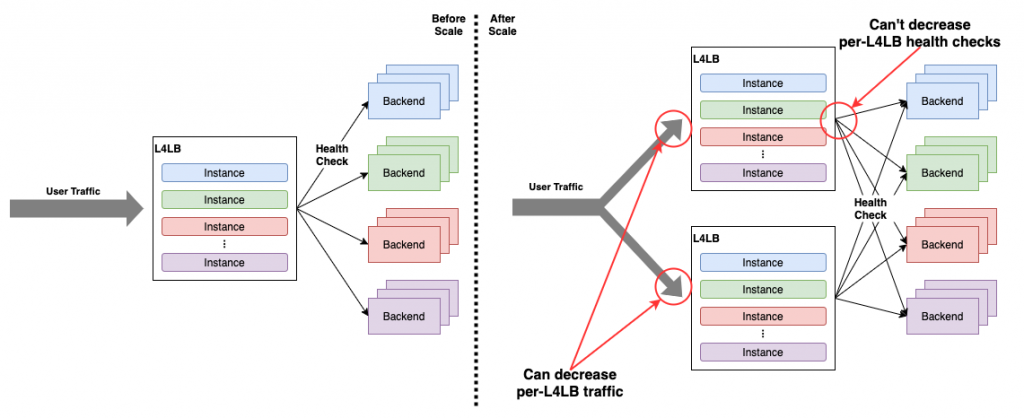
我々はこのL4LBのヘルスチェックエージェントの性能の問題にたびたび悩まされてきました。1つのヘルスチェックエージェントあたりのヘルスチェックの数はL4LBに収容されているユーザのインスタンス数にしたがって増えます。問題はその増え方です。ユーザは1つのLBインスタンスに対して、バックエンドサーバを最低でも2台、比較的規模の大きいサービスだと100台や200台紐づけることも珍しくありません。ヘルスチェックエージェントはその個々のバックエンドサーバに対してヘルスチェックをする必要があるため、収容インスタンスの数に対してヘルスチェックの数が増えてしまいやすいのです。
また、データプレーンのトラフィックとは異なり、個々のL4LBノードが持つヘルスチェックの数はL4LBノードのレプリケーションをしても減りません。これではせっかくデータプレーンが良くスケールしても、ヘルスチェックが足を引っ張ってしまいます。これを避けるためにはどうにかしてヘルスチェックエージェントの単体性能を上げる必要があります。
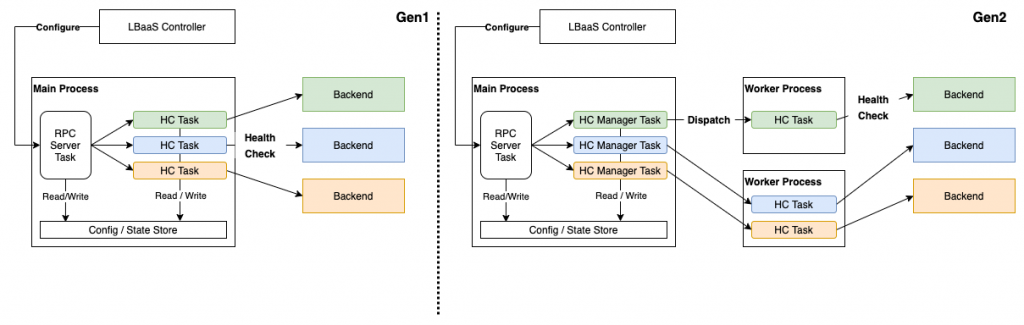
2019年9月頃、当時我々が使用していたヘルスチェックエージェントが負荷により、ヘルスチェックのインターバルが保てなくなったり、タイムアウトしたりするようになっていました。ちょうどその頃はL7LBのリリースなどでユーザが増え始めた頃だったため、その影響だったと思われます。当時のヘルスチェックエージェントはシングルスレッドで動くPython AsyncIOベースのものでした。このエージェントはおよそ800個のヘルスチェックしか捌くことができなかったため、ヘルスチェックの負荷を他のWorker Processに逃すことができる第2世代のエージェントを開発しました。
その当時は1へルスチェックエージェントあたりのヘルスチェック数は最大1Kほどでした。最初のベンチマークで、第2世代エージェントは少なくとも4Kほどのヘルスチェックを捌けることを確認していたので、安心してサービスに投入しました。しかし、その後のヘルスチェック数の増加は我々の想定を遥かに超えていたのです。
L7LBのインスタンス数増加によるヘルスチェック数の爆発
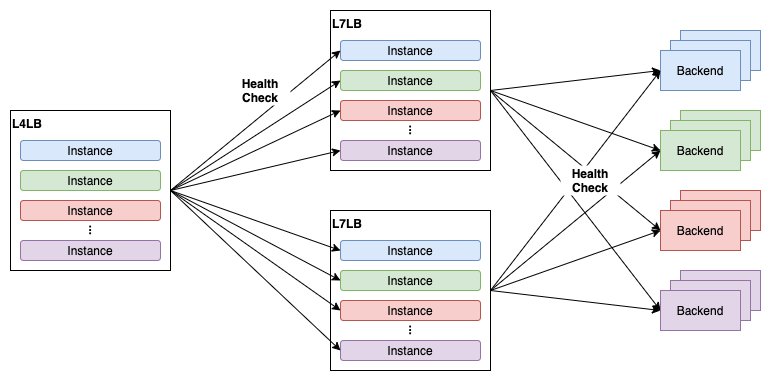
そこから1年が経った2020年9月ごろ、総インスタンス数は約1200、ヘルスチェックの数は多いところで8Kを超えていました。なぜ1年でこれほどまでにヘルスチェックの数が増えてしまったのでしょうか?実はこの背景には単純なユーザ数の増加に加えて、L7LBのサービス設計が関わっています。Verda LBaaSのL7LBサービスはL4LBのバックエンドとしてL7LB (HAProxyのKubernetes Pod) を紐づけた上で、L7LBにユーザのバックエンドサーバを紐づけるという構成を提供するサービスです。L4LBと同様、L7LBにも複数のユーザのインスタンスを1つのPodに収容するような作りになっています。L4LBはL7LBに収容されている個々のインスタンス (実体はインスタンスごとのHAProxy Frontend + Backend) に対してヘルスチェックをします。
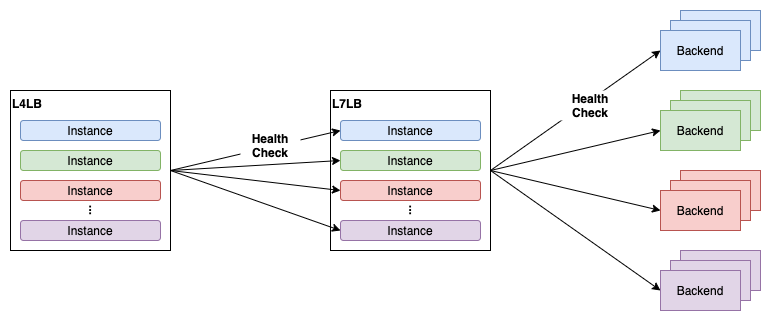
この構成には問題があります。この状況でL7LBへのトラフィックが増えて、L7LBのレプリカ数を増やすとヘルスチェックの数がL7LBのレプリカ数 × L7LBに収容されているインスタンスの数という掛け算で増えてしまいます。L7LBはL4LBと比較して非常に需要の高いサービスで、L7LBに収容されるインスタンスの数が当時増えてきていたこともあり、最悪のケースではL7LBのレプリカ数を増やすと1Kほどのヘルスチェックが追加されてしまうケースもありました。これが第2世代ヘルスチェックエージェントの開発当初の予想を超えてヘルスチェック数が増大した理由でした。
ヘルスチェック数の増大によって、第2世代エージェントにも限界が見えてくるようになりました。中でも大きな問題になったのはMain Processのイベントループで起きていたスケジューリング遅延です。第2世代エージェントはヘルスチェックのタスクの負荷をMain ProcessからWorker Processに逃すことによって下げる設計になっていました。しかし、Main Processは依然としてWorker Processから返ってくるヘルスチェック結果の回収をする必要はあります。この回収タスクにはWorker Processが応答不能になったときのためにタイムアウトを設定してあります。しかし、Main Processにあまりにたくさんのタスクを詰め込むとイベントループのスケジューリング遅延が起きます。その結果、Worker Processはヘルスチェックを正常に終えて結果を返しているのにもかかわらず回収タスクがタイムアウトするようになってしまったのです。
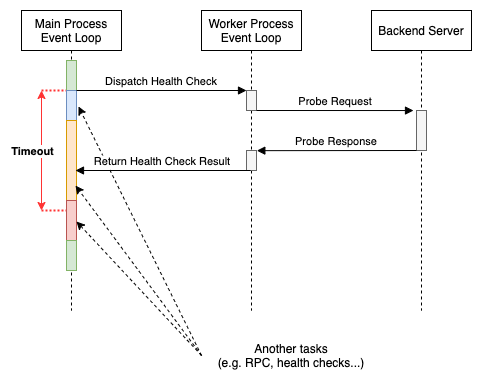
回収タスクがタイムアウトするとヘルスチェックの判定は「不明」となります。幸いにも「不明」はデータプレーンの挙動に影響を与えないという仕様になっていました。正常なバックエンドサーバを異常と判断することはありません。しかし、場合によってはバックエンドサーバの異常の検出に時間がかかり、サービスに影響が出てしまうこともあり得ます。これはユーザ視点で見るとある種の障害です。そこで我々は回収タスクのタイムアウトを伸ばす、ヘルスチェック数の多すぎるL4LBには新規のインスタンスを受け入れないようにする、などのWork Aroundを講じつつ、新たに第3世代のヘルスチェックエージェントを開発することを決めました。
サービスの危機
2021年5月ごろ、ついに第2世代ヘルスチェックエージェントの一部が限界を迎えました。この段階では先ほど紹介した回収タスクのタイムアウト問題の頻度がかなり上がっていました。さらに悪いことに同じくMain Processのイベントループのスケジューリング遅延の影響でLBaaSコントローラからのRPCがしばしばタイムアウトで失敗する状態になりました。これはユーザがLBのインスタンスを作成し、デプロイしようとしてもそれが失敗してしまうことを意味します。また、ヘルスチェックエージェントが原因不明の激しいメモリリークを起こし、週に1度は再起動しなければならない状態になりました。これは概ねヘルスチェック数が12Kを超えたあたりから起きました。
これは致命的な状態でした。ユーザの目に見えるサービス影響が出てしまったことに加えて、プロジェクトメンバがヘルスチェックエージェントの対応に忙殺されていました。本当に幸運だったのはこの時点で第3世代エージェントの開発を終えられていたということです。第3世代ヘルスチェックエージェントはベンチマークの結果、少なくとも80Kほどのヘルスチェック数に耐えられることがわかっていました。第3世代エージェントをデプロイした結果、サービスは以前の安定性を取り戻しました。本当にギリギリでしたが、危機は去りました。
第3世代ヘルスチェックエージェントの現在
2021年11月時点で、第3世代ヘルスチェックエージェントのデプロイから約半年ほど経ちました。最も多いところでヘルスチェック数は25Kを超えていますが、非常に安定して稼働できていると思います。キャパシティ約6.5倍 (12K => 80K) を叩き出した第3世代ヘルスチェックエージェントの詳細についてはそれだけで1つブログが書けてしまうので、ここでは割愛します。第2世代のパフォーマンス上の問題点を分析した上で新たな設計を考案する過程などは非常に興味深いので、いつか開発に携わったメンバがどこかで紹介してくれることを期待します。
Case2: L7LBアクセスログ収集基盤の負荷問題
次に紹介する問題はL7LBのトラフィックが増えたことにより、アクセスログの収集基盤が高負荷になってしまう問題です。Verda LBaaSのL7LBではセキュリティインシデントやトラブルシューティングへの活用のためにアクセスログを収集しています。Verda LBaaSのL7LBの実体はHAProxyのKubernetes Podです。各Podから出力されるアクセスログはNodeごとにDaemonSetのFluentdを使って収集、加工し、そこからElastic Searchに直接書き込むという構成を採用していました。
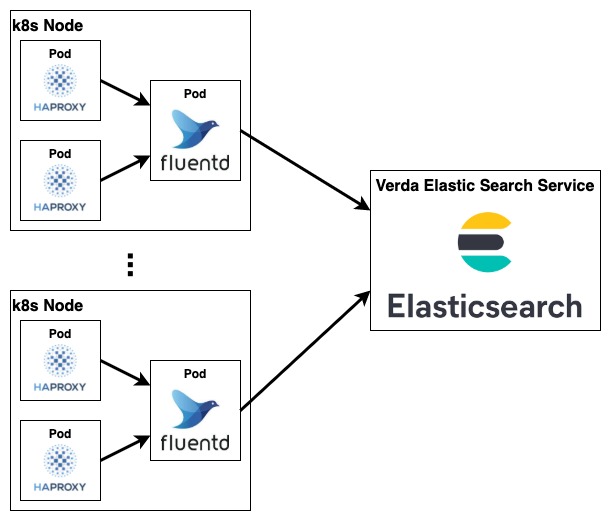
2020年3月ごろ、L7LBのユーザトラフィックが増加すると2つの問題が起きるようになりました。1つ目はFluentdがログ加工のための正規表現の処理でしばしばCPUを100%使い切ってしまうという問題です。正規表現処理は1アクセスログごとに実施するため、負荷はL7LBのリクエストの流量に比例して高くなります。その当時は利用者数がどんどん伸びる中で、トラフィック量も増えてくることが予想されていたので、何かしら手を打たなければログ収集が正しく機能しなくなるリスクがありました。
2つ目の問題はログの流量が増えるにつれElasticsearchの書き込みが詰まってしまうという問題です。Elasticsearchに書き込みリクエストをするとそのリクエストはキューイングされます。キューに入れられるタスクには上限があり、上限を超えて書き込みをしようとするとリクエストが拒否されます。Fluentdは書き込みが失敗した際にリトライするように設定できますが、当然の事ながらリトライしている最中はFluentd側にログをバッファリングしておく必要があります。そのため、あまりに長い間Elasticsearchへの書き込みが失敗し続けるとバッファが溢れてログ喪失が起きることがしばしばありました。
これらの問題に対処するために我々はk8s Node上のFluentdとElasticsearchの間にFluentdの中間層を置くことにしました。k8s Node上のFluentdはout_forwardモジュールでログを一切加工せずに中間層のFluentdに転送します。その後、中間層のFluentdが従来k8s Node上のFluentdで行われていたログ加工をした上で、Elasticsearchに書き込みを行います。
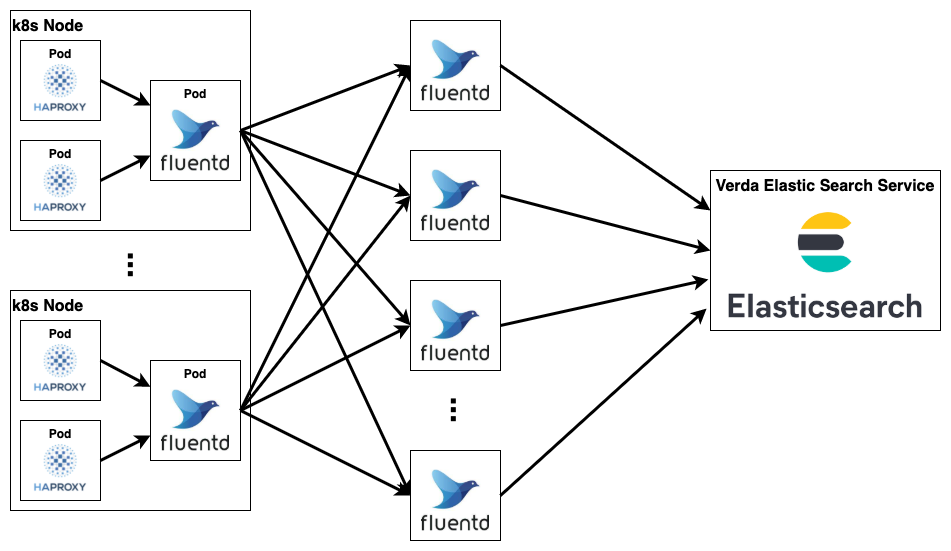
この構成の嬉しいところは、まずk8s Node上のFluentdはログ加工をせずにログ転送に専念することによって処理の負荷を大幅に下げることができたという点です。また、中間レイヤのFluentdは簡単に数を増やすことができるということもいい点です。例えば中間層のFluentdのログ加工の負荷が上がった場合は、数を増やして1台あたりで処理するログの量を減らすことで対処できます。また、Elasticsearchへの書き込みができず、長い時間バッファリングをしなければならないケースでも数を増やせばバッファの総量を稼ぐこともできます。これでk8s Node上のFluentdの処理負荷の問題は解決しました。
しかし、これだけでは2つ目の問題であるElasticsearchへの書き込みが詰まるという問題は解決しません。むしろ、書き込みのスループットが上がったためにより詰まりやすくなったとも言えます。また、我々のケースではElasticsearch側の書き込みの性能を大幅に改善することは現実的ではありませんでした。そのため何か別の安定したログの保存先を考える必要がありました。
そもそも我々はなぜElasticsearchを使いたいのかというとそれはElasticsearchの検索が優れていて、トラブルシューティングの際などに使い勝手が良いからです。しかし、ここでの優先事項はとにかくログを失わないことです。我々が最も避けたかったのは何か障害やセキュリティインシデントが起きた際にログが無いという状況でした。そこで、検索の機能などはないものの書き込みの安定性に優れたオブジェクトストレージで確実にログを永続化しつつ、Elasticsearchはベストエフォートで書き込みをできればいいというポリシにすることにしました。
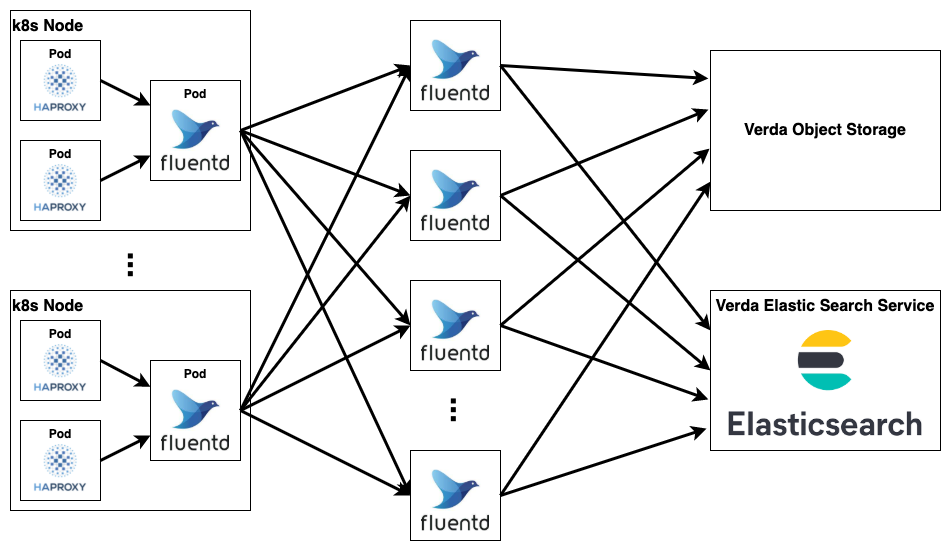
このようなポリシにすることで、Elasticsearchへの書き込みが詰まってしまった際にも積極的にログを廃棄するという思い切った運用にすることができました。また、保存したログの冗長化に関してもオブジェクトストレージのものに頼ることでElasticsearchのレプリケーションを切ることができました。それによって結果的にElasticsearchの書き込みパフォーマンスが上がり、書き込みが詰まる頻度も下がりました。
ログ収集の今後
現在、一旦ログ収集の問題は解決し、安定して運用できていると思います。しかし、これだけ大掛かりなログ収集基盤をLBaaSチームが自前で運用するのはやはり大変です。Verdaの他のコンポーネントでも同じような問題を抱えているチームが多いようです。そのため、最近は共通化されたログ基盤をVerdaのコンポーネントに提供する取り組みが進行中です。このような取り組みに興味がある方はSREチームの坂本によるLINE DEVELOPER DAY 2021や、CNDT2021の発表をチェックしてみてください。
学び: サービスが「良くスケールする」ということ
Verda LBaaSはサービス開始当初からデータプレーンのスループットに特に力を入れて作られたサービスでした。我々はL4LBとL7LBのデータプレーンを運用していますが、いずれのデータプレーンもレプリケーションによってスループットを稼げるようになっています。
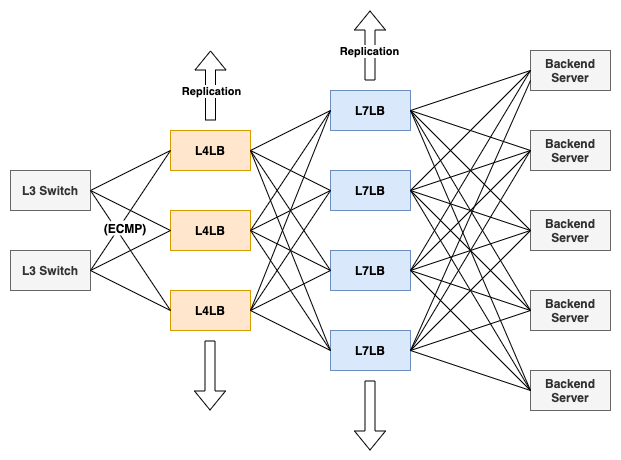
このようなサービス設計のおかげで、Verda LBaaS (特にL4LBサービス) はサービス開始から今日に至るまでデータプレーンのスループットに関する問題に悩まされることはほとんどありませんでした。では、Verda LBaaS全体がずっと安定して運用できていたのかというと、これまで見てきた通り、全くそんなことはありません。現実にはLBaaSはデータプレーンだけでできているわけではなく、ユーザに提供しているAPIサーバ、データプレーンを制御するコントロールプレーン、ログ収集の仕組み、メトリクス収集の仕組みなど様々なコンポーネントが集まってLBaaSという系を成しています。
今回紹介したような問題を通して、「良くスケールする」サービスを作るためにはサービスの一部分のスケールだけに目を向けるだけでは十分ではなく、系に存在する様々なコンポーネントのスケールを総合的に考えてサービスの設計・運用をしなければならないのだということを学びました。世間一般でよく言われていることではありますが、身をもって実感できたということは個人としてもチームとしても大きな収穫だと思います。
まとめ
2019年4月の入社以降、私がVerda LBaaSチームで働く中で体験した2つの大きな問題を紹介しました。2019年 ~ 2021年はVerda LBaaSにとっては大きな成長の時期でした。2020 ~ 2021年はレガシーなHWLBのEoLによってユーザのマイグレーションが一気に促進されました。また、LINEの画像や動画などの配信を担うメディアプラットフォームサービスや、メッセンジャーの基幹サーバなどのLINEの中心的サービスの収容も達成しました。
しかし、サービスの成長とともに今回ご紹介した2つのケースのようにシステムの所々にスケールしない箇所が出てきていることも事実です。実際にはこれ以外にも問題が山積みで、我々は現在進行形でサービスの改善を続けています。今回挙げた2つの問題もこれで完全に解決したとは思っていません。これからも継続して取り組んでいく必要があるでしょう。また、LINEのサービス開発の生産性を上げるためにVerda LBaaSをもっと便利なものにしていくことも必要です。Verda室ネットワーク開発チームではこのような問題に一緒に取り組む仲間を募集しています。このポストを読んで少しでも興味を持っていただけたら是非以下のポジションに応募を検討してみてください。
ここまでお付き合いいただきありがとうございました。
Verda室ネットワーク開発チームの求人
- Software Engineer / Network Infrastructure / Private Cloud Platform
https://linecorp.com/ja/career/position/564 - Software Engineer / Network Orchestration / Private Cloud Platform
https://linecorp.com/ja/career/position/2118