
みなさんはじめまして。
8月にLINEに入社し、ITサービスセンター・システム室で主にサーバ構築/管理を担当している 久慈泰範 と申します。
こういう場が初めてですのでちょっと緊張しておりますが、 LINE Advent Calendar 2018 - 6日目の記事を担当させていただきたく思います。
はじめに
この記事では、LINE Advent Calendar ならではの技術の深掘り...というよりも、サービスの活用方法とその可能性について触れたいとおもっています。
Elasticsearch + Kibana は主にログ解析で使われることが多いと思いますが、本記事ではそれぞれの特性を活かし Excel のピボットテーブルの代わりに使えないか?というトライを紹介します。
できあがり
先にできあがったものを紹介すると、こんな感じです。
こういった、Excel〜って感じのデータをシステムに簡単取り込んで

↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
ブラウザでExcelのピボットグラフを作って、並べています。
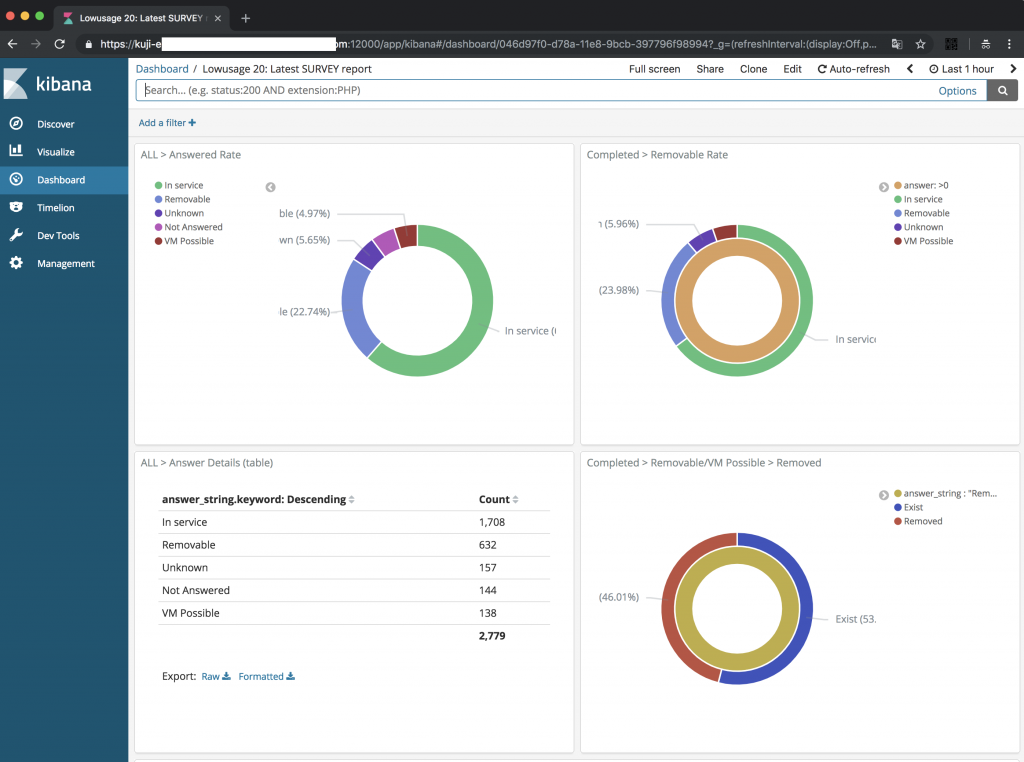
毎日勝手に Excel 内のデータが更新される 「オンラインピボットテーブル」(しかも勝手にデータ更新) という感じです。
(通常ピボットグラフは1シートにひとつしか置けないので、こうやって並べることができないんですよね。)
経緯
今回対象となったプロジェクトは、私が所属する IT サービスセンター(ITSC) で行った社内アンケートプロジェクト Low Usage Project です。ITSC は社内・社外関わらず LINE のインフラを一手に司っているインフラ専門部隊です。 我々の部署では常時数万台を超えるサーバを管理していますが、そのすべてが効率的に活用されているとは限りません。中には構築途中で手付かずになってしまったサーバや、サービスが分割したにもかかわらず冗長なクラスターが維持されたままのものがあります。
それらリソースに余裕があるサーバ群の縮小化、または VM への移行を推進するにあたり、現在の利用状況をサーバの管理者に問い合わせたのですが、その集計レポートを用意するに当たり、多方面から異なった目線でのレポート依頼が私のもとに舞い込みました。
- 未回答の部署が知りたい
- サーバの減価償却視点で集計して欲しい
- サーバのモデル別に見たい
- 担当者の上長の連絡先がほしい
- etc etc etc...
入社間もないこともあり、与えられた指示にその場しのぎ最速で対応しようとしていた私はこれらをいったんすべてExcelでさばくことにしました。Excel の Pivot Table(詳細は後述)は必要なデータを手軽にテーブル・グラフに可視化できる非常に便利な機能で、必要なoutputはそれでほぼ用意できました。が、すぐに壁にぶつかりました。
- データの不足と結合の手間
- 必要なデータをあちこちのDBから取得、Excel上で VLOOKUP してマージ
- データが5個なら5個を毎回 download して excel に貼り付けてグラフを更新して・・・
- Excelの計算時間が日に日に伸びる...
- 定型的な作成手順のドキュメント化
- 毎日同じ作業の繰り返し
もちろんVB(A)を使えばこれも自動化できますが、もともと Kibana をピボットテーブルとして使えないか? と考えていたので、早速取り組むことにしました。
Excelのピボットテーブルとは
Excelのピボットテーブルについてはたくさんのblogがヒットするので詳細はそちらに譲りますが、簡単に言うと key=valueの単純な行を書き連ねたデータを元として、同じ値の数を数えたり、グラフ化することができる機能です。 大事なのは「1行で1データ」であること。複数行にまたがるデータは置けないんですね。このルールは絶対に崩せません。
使い方はこのような感じです。
1. key=valueの単純なデータを用意して「ピボットグラフ」を挿入する
今回はアンケートの回答を1行1データとして用意しました。
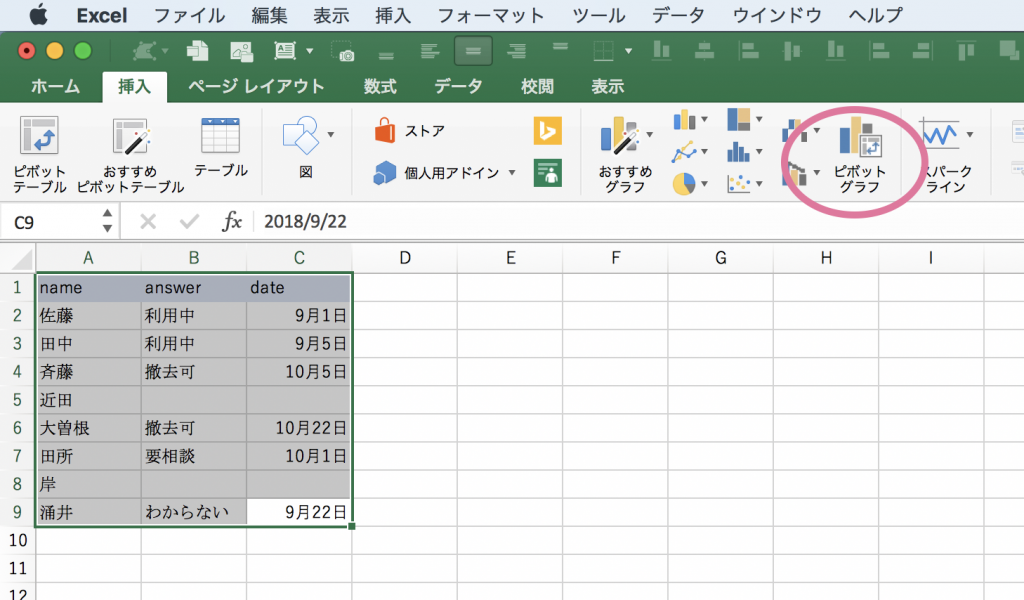
2. データの範囲を決める
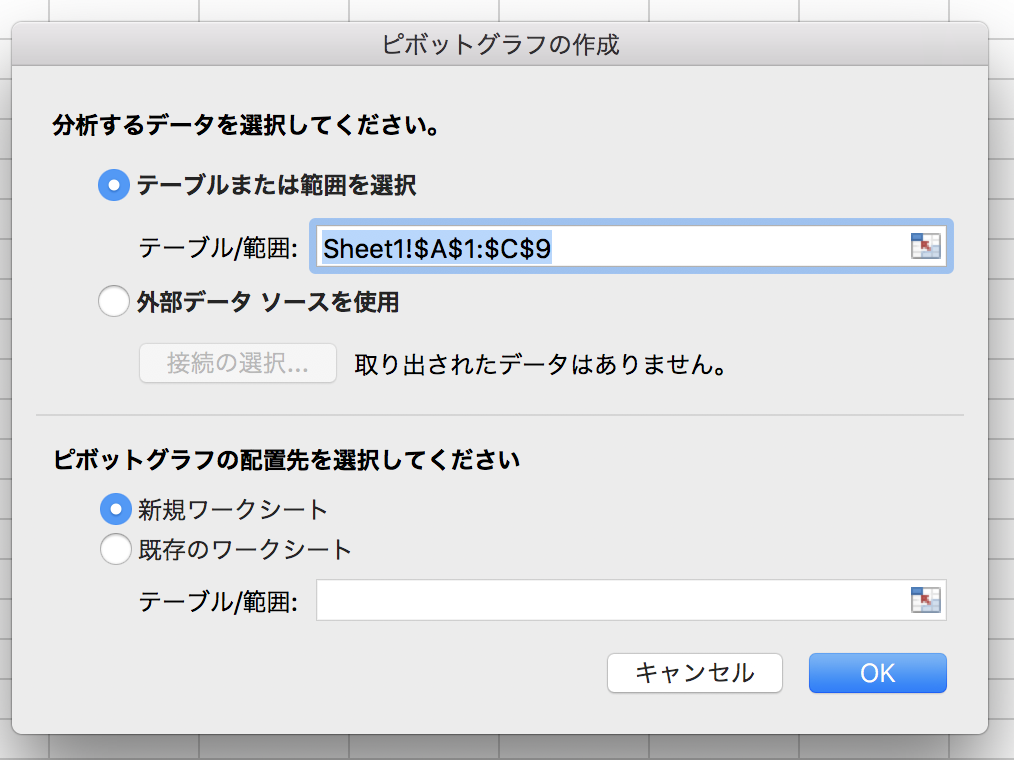
3. グラフ化/テーブル化したいデータを選べばできあがり
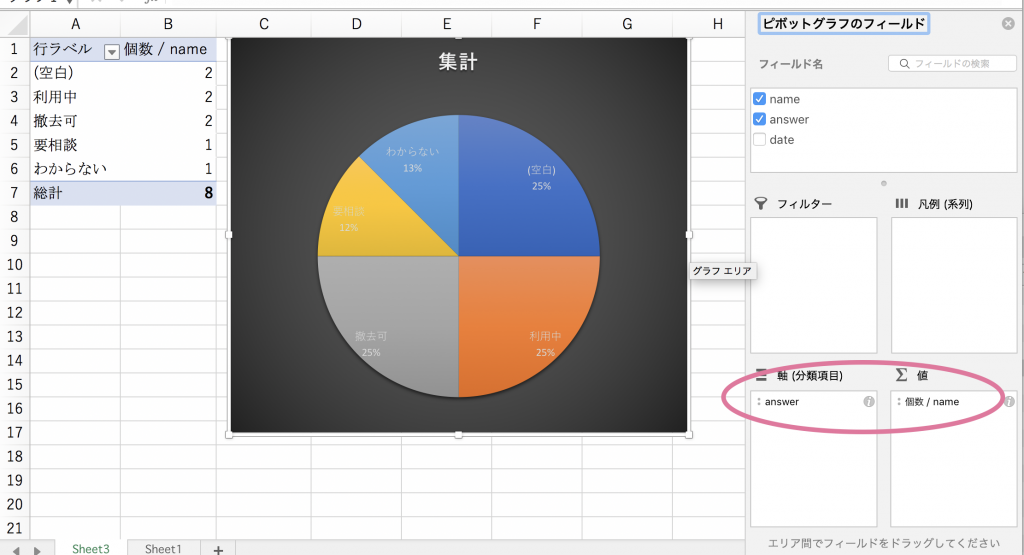
1行1データ、の法則はlogに最適な条件であるため、いまだにlog解析に用いているエンジニアも多いと思います。「1行1データ、リレーショナルしない」の条件は基本的に Elasticsearch でも同様です。
Elasticsearch + Kibana とは
Elasticsearch(エラスティックサーチ) は Elastic 社が開発しているデータベースの一種ですが、リレーショナルではない点が MySQL や Microsoft SQL server と異なります。検索スピードが非常に早いため、各種解析ではスタンダードな存在になっていると思います。Elasticsearch はデータを入れると即 API としても使える点が魅力で、その特徴は構築した Elasticsearch にブラウザでアクセスすると、まず json 形式のサーバ情報が表示される点が特徴的です。
Elasticsearch にブラウザでアクセスした例:
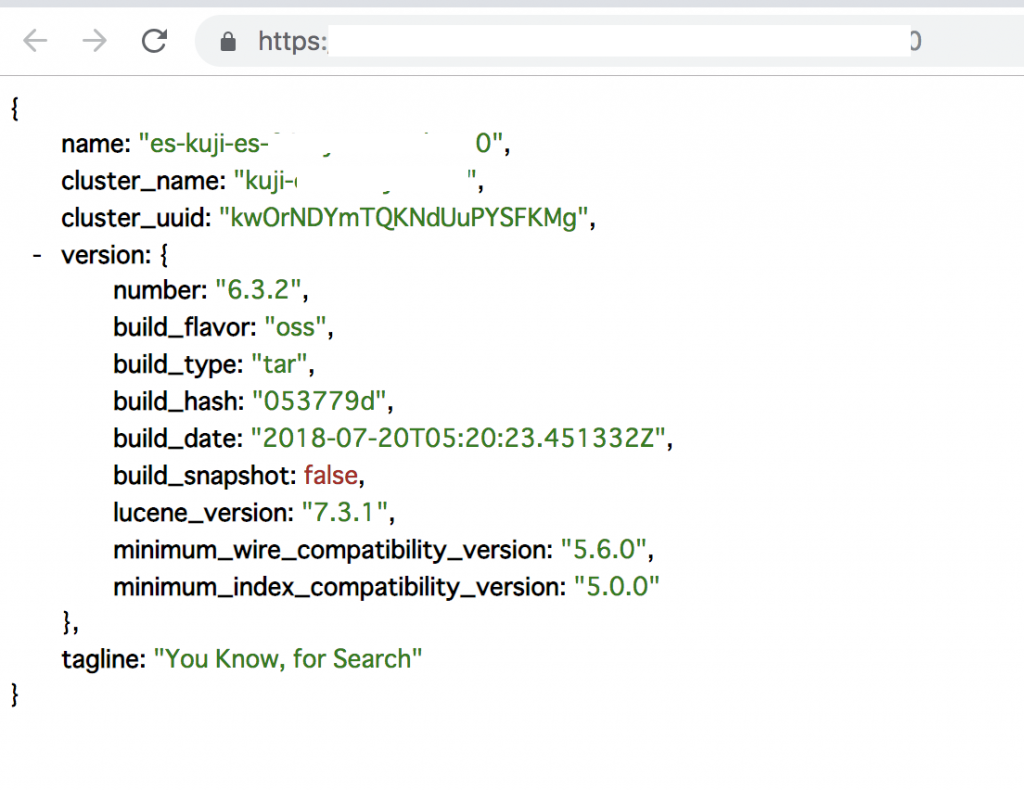
Elasticsearch の version が見えますね。
Kibana(キバナ) は Elasticsearch のデータを可視化するためのツールで、同じく Elastic 社によって開発されています。データの抽出クエリをブラウザから実行・テーブルやグラフ形式で保存することができ、基本的な操作は SQL の知識なく行うことが可能です。データさえ用意すればレポートを私以外の人間でも作ることができる、この点も採用に至った大きな理由です。

引用元:https://www.elastic.co/products/kibana
弊社には社内 Private Cloud の Verda に VES (Verda Elasticsearch) があり、kibana もセットで簡単に起動できるため、今回は VES を利用しました。AWS, GCP, Azure などの Public Cloud にも Elasticsearch + Kibana のサービスがあります。それらを使えば構築でつまづくことはないでしょう。
課題と対策
さて、本記事の要にあたる部分ですが、kibana をピボットテーブルとして扱うと問題になる点はなんでしょうか?それは、kibana はあくまで「生きたデータを扱う」ために作られたソフトウェアであるということです。それは kibana の特徴的な、画面右上のUIに現れています。
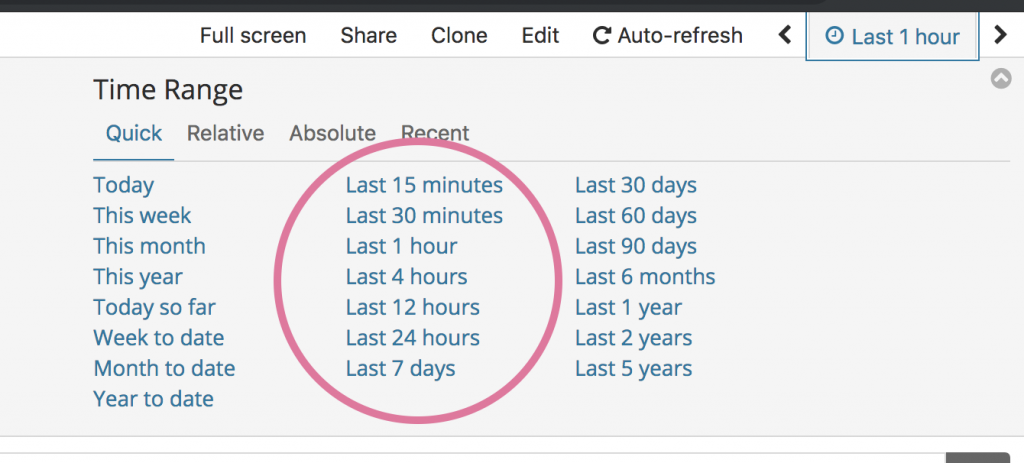
kibana は、解析を始めるに当たりまず「いつのデータが見たいのか」を指定して使います。その基本は「最新15分間のデータ」といった形です。Google Analyticsの期間設定と思えばわかる方も多いと思います。
Google Analyticsの期間設定の例:
Kibanaが想定している使い方は、「ひとつのデータは一度しか取り込まれない」というものです。
今日の 12:00:00 にあった apache のアクセスは、完全にユニークなものであり 13:00:00 に同じlogが入るということはありえません。
対して今回私が使っていたアンケートシステムは、あとから回答を差し替えることもできる仕様でした。ホスト名Aのサーバに対して、複数のレコードが存在する。それは前述の「1行1データ(言い換えると1ホスト1データ)」に反する仕様となります。
-
kibanaが想定するデータの例

-
私が持っているデータの例
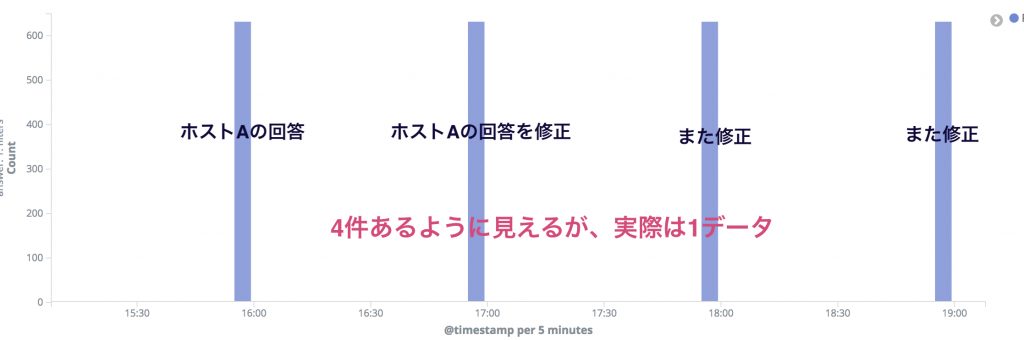
- 大きな問題

この課題に対する私の回答はこうでした。
- 1時間おきに、全回答を取り込みし直す
- 閲覧するときは、 必ず期間を「最新1時間」に固定 して閲覧する
一時間おきに、DBまるごとのスナップショットをElasticsearchに保存するイメージです。
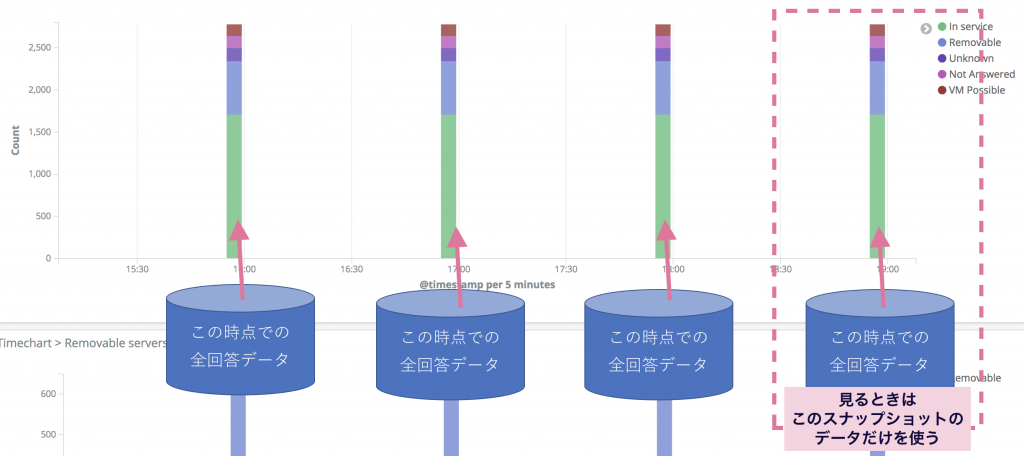
この手法には以下のメリットが存在します。
- ある日ある時点の回答状況を簡単にリコールできる
- 履歴を考慮したシステムでなければ困難
- データの動きを追うことが可能
- 再回答データを上書きするようなシステムでも、削除アクションでほんとにレコード削除しちゃうようなシステムでも動きが記録される
デメリットとしては、データ量が多くなることですが、そこは取り込み期間を伸ばしたり、古いデータを間引くなりすれば解消できます。
期間を固定して閲覧するという「運用でカバー」対策は、幸いにもkibanaのdashboardに期間を固定する機能があったので、メンバーにはdashboardのURLを共有することで未然に混乱を防ぐことができました。
ここが、本記事で私が提案したかった、「データまるごとのスナップショットをElasticsearchに取ると便利だよ」という本筋になります。
ECサイトであれば商品の売れ行きや在庫数調査を、Google Analytics などの機能を使って日々解析していると思います。 しかしこの手法を使えば、例えば DB をまるごと snapshot するだけで、 アプリ側の改修を伴わず にある程度の解析が簡単に、自由に、グラフィカルにできるようになります。
カテゴリ別に在庫数を合計した表にしたり、割合を円グラフにしたり、その変動を棒グラフで可視化したり、そういったことが kibana は得意です。 アプリでがんばらず、管理画面でがんばらず、DB を取り込むだけ でそれができたら、なかなか解析に工数を避けない EC サイトは嬉しいんじゃないかなぁ、と想像したりしています。
似たようなことができるサービスは世の中にあると思いますが、多くのサービスは過去の動きを見ることを苦手にしていると思います。
今回は社内に転がっている Elasticsearch をどう活用するか、という視点からスタートしたトライでもありますので、結果には非常に満足しています。
Elasticsearch へのデータ取り込み
さて、方針は決まりましたが実際に既存のデータをどうやって Elasticsearch に取り込むか悩みました。手元の元データはMySQL、またはそれを export した csv ファイルでした。非エンジニア層に使ってもらいたいという思いがあったため csv から簡単に upload できます、というスキームを用意したかったのですが、kibanaにかつてあったcsv取込機能が現在はいったん公開停止になっていたため利用できませんでした。 なんとなく悩みをつぶやいたらすぐにElasticsearch日本語版翻訳者の方からreplyをいただくことができました。
確かに便利ですね。まぁ、CSVにしろRDBにしろ、Logstashでデータ取り込むことができるんで、とりあえずLogstash触ってみていただくのをお勧めしますー
— Jun Ohtani (@johtani) October 24, 2018
やっててよかったTwitter。
今回の要件として複数のデータソースをマージしたい、というものがあるため MySQL → Logstash → Elasticsearch といったフローで流し込む方針に決めました。
元データを MySQL にしたのは以下の理由です。
- 既存のアンケートシステムが MySQL で動いていること
- 私が慣れていること
- MySQLで動いているサービスが社内でも多そう
- Elasticsearch に置き換えれば高速化できそうなものがある
- MySQL からの移行プロセスを作れたら嬉しい、その一歩目 - なんたってElasticsearchはデータを入れるだけでAPIできちゃいますから
- Elasticsearch なんとなく怖い、という人のきっかけになってほしい
- MySQL のスナップショットを Kibana で見たら幸せっていう記事が書けそう
Logstash とは
Fluentd を知っている方であれば、同じようなものと思えばわかりやすいです。データの input(fileやmysqlなどあらゆるもの)と output(Elasticsearch サーバの url, port 等) を指定するだけでうまいことデータを Elasticsearch に流し込んでくれます。
今回は Logstash と、MySQL からの読み込みを可能にする jdbc input plugin を使うことにします。
簡単に言うと、 SELECT 文の結果を Elasticsearch に取り込ませます。
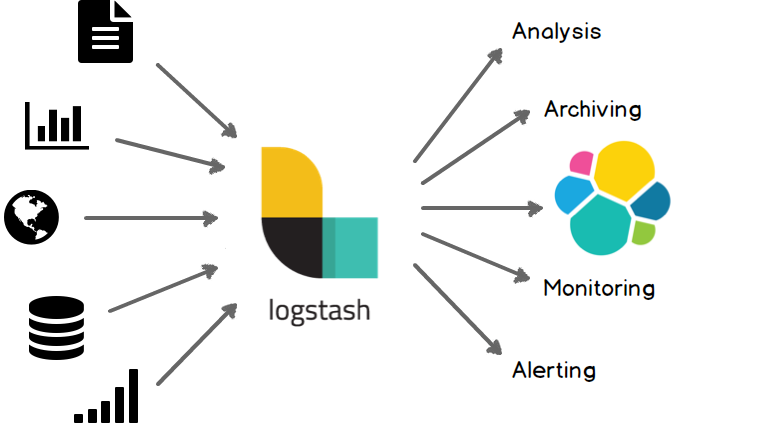
システム構成
全体の構成はこうなりました。手元のサーバに logstash コンテナを立て、Elasticsearch に取り込みを行います。

各種設定
MySQL
特に書くことはありません。やったことは、MySQL に Select 権限のみの logstash user を作成し、Logstash が動くサーバからのアクセスを許可したことです。
Logstash
docker-compose を使ってコンテナを起動するサンプルをここに置きました。
https://github.com/kujiy/mysql-logstash
起動する前に logstash の取り込み設定をあなたの設定に書き換えます。これがサンプルです。
https://github.com/kujiy/mysql-logstash/blob/master/config/my-import.conf
logstashの設定ファイルは大きく3セクションに別れています。
input section
データの取り込み元となる MySQL サーバの設定を入れます。
input {
jdbc {
jdbc_driver_library => "/tmp/mysql-connector-java-8.0.13-1.el7.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://YOUR_MYSQL_SERVER:3306/YOUR_DATABASE_NAME" <-----------
jdbc_user => "YOUR_MYSQL_USER" <-----------
jdbc_password => "YOUR_MYSQL_PASSWORD" <-----------
statement => "SELECT * from YOUR_MYSQL_TABLE" <----------- SELECT 文を書く
type => "my_index"
## scheduleをアクティブにすると、cronライクに定時実行できる
#schedule => "00 * * * *"
}statement にいれた select 文の結果が Elasticsearch に取り込まれます。私の実際の config では、連携するデータベースなどの情報を UNION や 多段 JOIN を駆使して、リレーショナルを解除した「全部一行に詰め込んじゃったデータ」を取り出しています(600カラム以上あります ← やりすぎ)。でもこうしておくと、Kibana を使うときに本当に幸せになれます。 select文の結果が返った後に取込が行われるだけですので、slow query を気にする必要はおそらくありません。
schedule
1時間おきの取込に、私はこの jbdc input plugin のschedule機能を使っています。
## scheduleをアクティブにすると、cronライクに定時実行できる
schedule => "00 * * * *"この例では、コンテナを起動しっぱなしにしてくと毎時00分に取り込みを実行してくれます。とても便利です。
filter section
サンプルではすべてコメントアウトしていますが、ここでkeyを動的に追加したり文字列の置換を行ったりすることができます。解析に新たなデータが必要になったときは、MySQLでもこのFilterでも、楽な方でカラムを追加することができます。
output section
データを取り込む Elasticsearch の接続情報を書きます。
# elasticsearchサーバの設定
output {
if [type] == "my_index" {
elasticsearch {
manage_template => false
hosts => ["https://YOUR_ELASTICSEARCH_SERVER:9200"]
user => ["YOUR_ELASTICSEARCH_USER"]
password => ["YOUR_ELASTICSEARCH_PASSWORD"]
## ココ大事。これがelasticsearchのindex = mysqlで言うところのテーブルになる。
index => "my_index"
document_type => "%{type}"
#document_id => "%{id}"
}
stdout {codec => rubydebug {metadata => true }}
}
}取り込み実行

コンテナを起動すると、logstash の起動のあとに取込が始まります。私の環境では起動に1分近くかかります(途中何度か動きが止まったように見えますが、待てば動きます)。
この log が出れば起動に成功し、job が走る状態になっています。
[INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}MySQL / Elasticsearch につながらないといったエラーはコンソールに表示されるので、エラーを見逃さないようにしましょう。
一つ注意点としては、config の syntax error があると logstash の起動に失敗し、コンテナが落ちます。
statement に書かれた SQL の構文エラーでも起こるようです。ご注意ください。
起動が終わると、statement に記述したMySQLクエリが表示され、取込が始まります。取込は非常に高速ですが、流れる log でどのデータが取り込まれているのか状況を把握することができます。
kibanaでのデータ確認
Elasticsearch は Index と呼ばれる識別子で表示するデータの塊を選択します。これはMySQLでいうDatabase/Tableのようなものです。そのIndexがどんなカラムを持っているのかを最初に登録する必要があります。
kibana を開き、 Management > Create Index Pattern で Index patternを登録すればデータが利用できる状態になります。

Discover で Indexと期間を選び、データが表示されれば準備完了です。

あとはvisualizeからグラフを、dashboardでグラフを並ぶブラウザぽちぽち作業をするだけです。ここらへんの操作は一般的なkibanaの解説ブログに譲ります。
データが表示されない場合
kibana の dev tool を使うと簡単にデータが入っているかを確認できます。
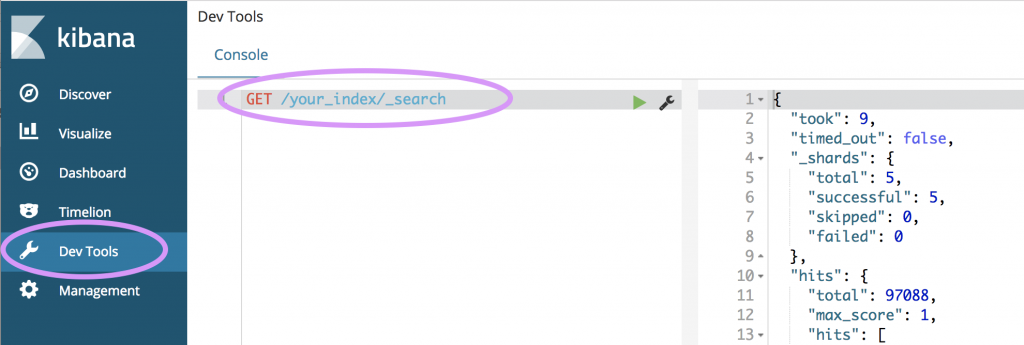
GET /<index名>/_search でデータを、
DELETE /<index名> で取り込んだデータをすべて削除することができます。
MySQL なんてわからない!という方へ
手元にあるデータが xls/csv しかない場合でも、phpmyadmin を使えば csv を MySQL に取り込むことは簡単です。

もしくは、 logstash で csv filter plugin を使えば csv ファイルを直接 Elasticsearch に入れることも可能なようです。これなら MySQL を用意する必要もありませんね。
一度取り込んでしまった後は、定時取り込みもせずに「全期間のデータ」で閲覧をすれば「オンラインピボットテーブル」は問題なく使えます。
さらに汎用的に・・・
今回 Elasticsearch にデータを取り込んだので、なんと勝手にそのデータを取り出せる 高速 API が用意されました。ここが Elasticsearch の魅力です。MySQL の複雑な Select文が高速に json で返ってくる、そう思えばいいです。
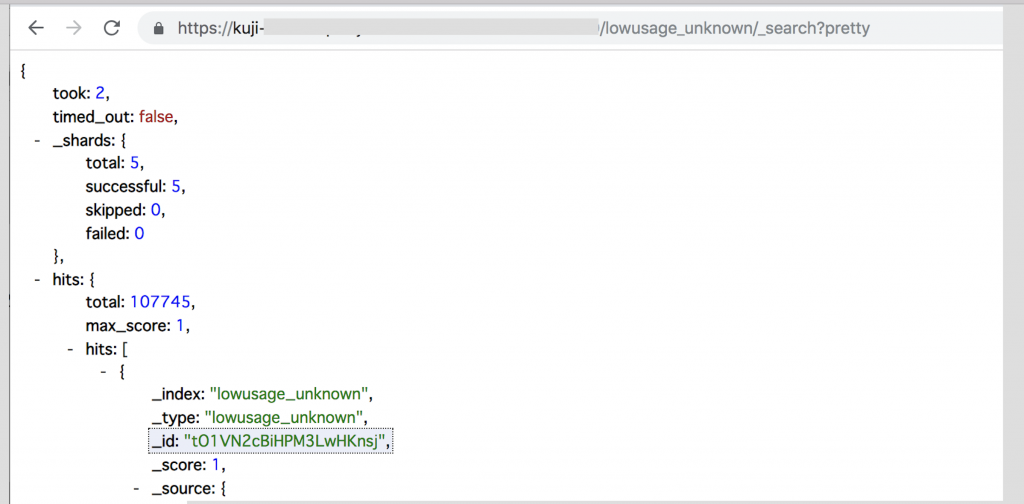
API はこんな URL にアクセスすれば使えます。
http://<Elasticsearch-domain>/<index名>/_search?pretty
-
ブラウザでアクセスした例:
-
Curl コマンドで query を投げている例:
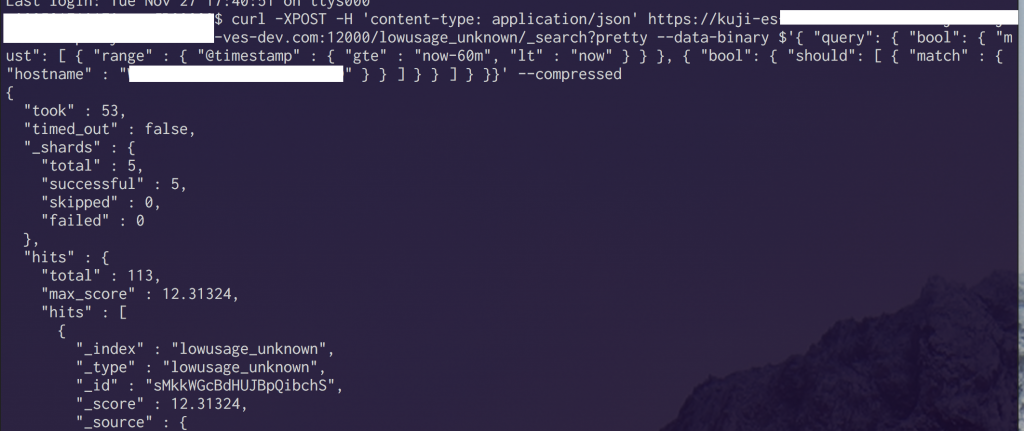
様々なデータを join した API が簡単にできてしまいました。これ、他のサービスで活用できると思いませんか・・・?
おわりに
いかがでしたでしょうか。ほとんど設定ファイルやコードを書くことなく、MySQL を Elasticsearchに取り込めることがわかっていただけたかと思います。
この記事は一般的に用途が決まっているサービスでも、発想次第で違う用途に活用できるのではないか?という視点で書きました。
ご意見や、もっといいアイデアがありましたらぜひ Kuji(@uturned0) まで教えてください。
最後に、システム室ではインフラサーバエンジニアやインフラ開発エンジニアのポジションを超!積極採用中です。
ご興味のある方はぜひご応募を、質問がありましたら Kuji(@uturned0) までお気軽にご相談ください。
- インフラ開発エンジニア(オペレーション)
- インフラサーバエンジニア【全事業対象】
- サーバーインフラ企画・管理【全事業対象】
- などなど