
こんにちは、LINEでClovaの自然言語理解 (NLU) ユニットの開発をしている服部 (keigohtr)です。この記事は、LINE Engineering Blog 「夏休みの自由研究 -Summer Homework-」 の3日目の記事です。
はじめに
機械学習が流行ってます。みなさんも既に機械学習をやっていたり、上司から機械学習をやれと言われたりしているのではないでしょうか?幸いなことに、近年の機械学習の流行のおかげで機械学習まわりのツールやフレームワークはかなり充実してきました。線形回帰やロジスティック回帰、Perceptoron、Adaboost、Random Forest、Support Vector Machine、XGBoost、そして多様なDeep Learningのアルゴリズムなど、多くのアルゴリズムが誰でも簡単に利用できるようになりました。しかし「学習」まわりのツールやフレームワークが充実する一方で、構築した機械学習モジュールの「運用」まわりのツールやフレームワークは多くありません。そこで今回は、LINEのAIプラットフォームであるClovaで採用する機械学習モジュールの管理運用基盤Druckerをご紹介します。
Drucker GitHub
https://github.com/drucker/drucker-parent
背景
機械学習には大きく2種類のタスクがあります。
- 機械学習モデルの構築に関するタスク
- 機械学習モジュールの配信に関するタスク
機械学習モデルの構築に関するタスク
- Data
- Collection (e.g. supervised learning, unsupervised learning, distant supervision)
- Cleaning/Cleansing (e.g. outlier filtering, data completion)
- Features
- Preprocessing (e.g. morphological analysis, syntactic analysis)
- Dictionary (e.g. wordnet)
- Training
- Algorithms (e.g. regression, SVM, deep learning)
- Parameter tuning (e.g. grid search, Coarse-to-Fine search, early stopping strategy)
- Evaluation (e.g. cross validation, ROC curve)
- Others
- Server setup
- Versioning (data, parameters, model and performance)
「機械学習モデルの構築に関するタスク」は、例えばデータ収集やデータクレンジング、学習素性設計、アルゴリズムの選択、深層学習の場合はネットワークデザイン、パラメータチューニング、機械学習モデル評価などがあります。これらのタスクは機械学習エンジニアやデータサイエンティストの職務であり、専門性をフルに発揮して課題の解決にあたります。
近年では便利なツールやフレームワークが増え、例えばPythonにおける機械学習周りのライブラリではscikit-learn、gensim、Chainer、PyTorch、TensorFlow、Kerasなどが利用できます。また、学習経過の監視やレポーティングにはJupyter Notebook、JupyterLab、ChainerUI、TensorBoardなどが使えます。
最近では開発環境をセットアップしてくれるツールとして、Googleからkubeflowが登場しました。kubeflowはKubernetes環境上に構築する機械学習基盤で、並列計算環境を提供します。このように、機械学習エンジニアやデータサイエンティストをサポートするツールやフレームワークは大変に充実してきました。
機械学習モジュールの配信に関するタスク
- High Availability
- Management
- Uploading the latest model
- Switching a model without stopping services
- Versioning models
- Monitor
- Load balancing
- Auto healing
- Auto scaling
- Performance/Results check
- Others
- Server setup
- Managing the service level (e.g. development/staging/production)
- Integrate into the existing services
- AB testing
- Managing all ML services
- Logging
「機械学習モジュールの配信に関するタスク」は、例えば機械学習モジュールのサービス化、サービスの冗長化、既存システムへのインテグレーション、機械学習モデルの更新および機械学習サービスの更新、サービスの死活監視などがあります。サーバー周りのタスクはインフラエンジニアやサーバーサイドエンジニアの職務ですが、機械学習まわりのタスクは彼らの領分ではありません。また、機械学習にはそのモデルに特化した前処理や後処理が必要な場合もあるため、機械学習サービスの構築は機械学習エンジニア側がある程度作業する必要があります。ときには機械学習エンジニア自身が担当モジュールのサービス化を行う場合もありますが、専門外のため担当者によってサービス品質がばらついたり、サーバー構築やモジュールの保守運用の作業が恒常的に必要となり主担当の「機械学習モデルの構築に関するタスク」に専念できなかったりするため、課題も多くありました。
この課題を解決するひとつの方法としてTensorFlow Servingがあります。TensorFlow ServingはTensorFlowのモデルを自動的にgRPCサービスとして配信できます。しかし、前処理や後処理をサービスに内包できない点とTensorFlowのモデルのみが対象(2018年7月時点)である点で我々の要求を満たしませんでした。先述の通り、機械学習にはそのモデルに特化した前処理や後処理が必要な場合があり、機械学習モデルとセットで配信したいという要望がありました。さらに、scikit-learnやgensimなどで作った機械学習モデルも配信したいという要望もありました。Clovaではこれらの要望を満たすソリューションとしてDruckerとKubernetesを採用し、機械学習モジュールの管理運用基盤を構築しました。
Druckerとは
Druckerは機械学習の配信フレームワークです。主な特徴を以下に示します。
- 機械学習モジュールの配信を簡単にできる
- 機械学習モジュールの管理と運用を簡単にできる
- 機械学習モジュールの既存システムへの統合を簡単にできる
- Kubernetes上で(も)動作する
Clovaでは機械学習配信基盤をDruckerとKubernetesで構成しました。構成の概略を以下に示します。
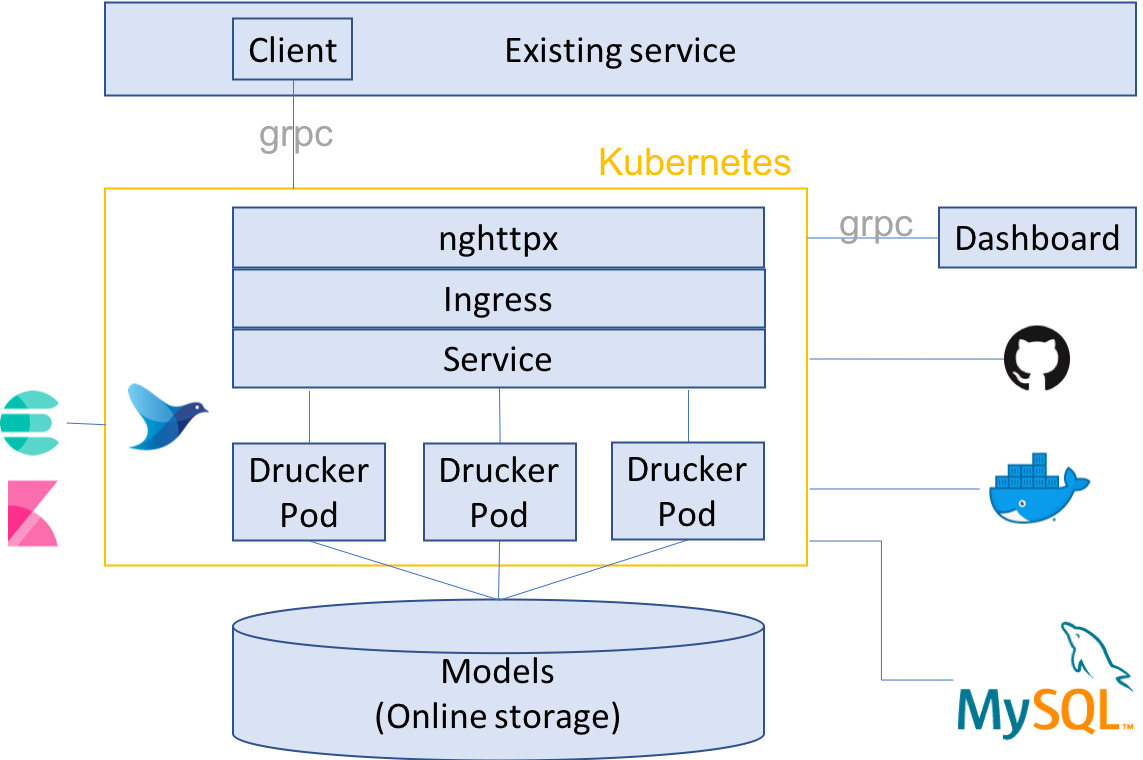
それでは各構成要素について見ていきましょう。以降では、機械学習モジュールをDrucker application、当該機械学習モジュールのWebサービスをDrucker service、当該Webサービスの冗長化で生成されたコンテナをDrucker Podと定義します。
Drucker
DruckerはgRPCサーバーのテンプレートです。テンプレートに機械学習モジュールを組み込み、機械学習モジュールをgRPCのマイクロサービスにします。Druckerの使い方はDjangoやFlaskなどのWebAPIフレームワークと似ていて、具体的にはDruckerのPredictInterfaceクラスのimplementationクラスを作ります(下記参照)。gRPCのスペックはDruckerで定義されているため、ユーザーはgRPCに詳しくなくてもDruckerでgRPCサーバーを立てることができます。
下記のpredictメソッドのinputフィールドはstring/bytes/list[int]/list[float]/list[string]のタイプのいずれかを取り、これは機械学習の標準的な入力になります。デバイス情報やユーザーIDなどの追加の情報を送りたい場合はoptionフィールドを使うことができます。optionフィールドはdictタイプで、階層の深さに制限はないので自由に使えます。
class Predict(PredictInterface):
def __init__(self):
super().__init__()
self.predictor = None
self.load_model(get_model_path())
def load_model(self, model_path: str = None) -> None:
assert model_path is not None,
'Please specify your ML model path'
try:
self.predictor = joblib.load(model_path)
except Exception as e:
print(str(e))
os._exit(-1)
def predict(self, input: PredictLabel, option: dict = None) -> PredictResult:
try:
label_predict = self.predictor.predict(
np.array([input], dtype='float64')).tolist()
return PredictResult(label_predict, [1] * len(label_predict), option={})
except Exception as e:
print(str(e))
raise e
詳細なサンプルはこちらを御覧ください。
Kubernetes
Kubernetesはコンテナ管理の有名なツールです。Kubernetesの紹介は本記事では省略します。今回の構成におけるKubernetesの利点は大きく以下の5点です。
- サービスの無停止更新(ローリングアップデート)
- サービスの自動復帰(オートヒーリング)
- サービスの冗長化(オートスケーリング)
- サービスレベルの管理(development/staging/sandbox/production)
- サービスの起動制御(サービスレベルの異なるPodを同じノードで起動しない、同じPodを同じノードで起動しない)
DruckerはKubernetes環境をサポートしているため、DruckerとKubernetesを組み合わせることで強力な機械学習配信基盤が作れます。Kubernetesについては、既存のサービス(e.g. Google GKE、Amazon EKS)を利用するか、Rancherなどを利用して自分で構築します。RancherによるKubernetesクラスタの構築方法についてはRancher公式ドキュメントを参照するかDruckerのドキュメントを参照してください。
Load balancing
Kubernetesの外からKubernetesの中にアクセスするために、Kubernetesのingressという機能を使います。まず、Kubernetesクラスタの全てまたは一部のノードにDNS(e.g. example.com)を割り当てます。次に、当該DNSのサブドメインにDruckerで構築した機械学習モジュールの名称またはIDを割り当て、ingressに登録します(e.g. http://<app-name>-<service-level>.example.com)。これにより、サブドメインでアクセスする機械学習モジュールを切り替えることができます。
ロードバランサーにはnghttpx ingress controllerを使います。nghttpxはhttp2のプロトコルを扱うライブラリで、nghttpx ingress controllerは80 portのhttp2のリクエストをロードバランスします。Kubernetes公式にあるnginx ingress controllerは80 portでhttp2を扱うことができない(※ nginx 1.13.10以降ではサポートので、現状ではnghttpx ingress controllerを使うのが最適解です。このエンドポイントは後述するDrucker clientで接続し、機械学習モジュールにアクセスします。
Drucker dashboard

Drucker dashboardは前述のDruckerに接続します。すべてのDruckerを一元管理できます。Kubernetesにも接続でき、Kubernetes上で可動するDruckerを管理することもできます。Dashboardの役割は以下になります。
- 機械学習モデルをアップロードする
- 機械学習モデルをバージョニングする
- 機械学習モジュールの読み込みモデルを切り替える
- (WIP) 機械学習モデルの性能を評価および可視化する
- Kubernetesに接続し、Druckerを立ち上げる
メリットは、機械学習モデルを一元管理してWebUIから柔軟に切り替えられる点と、Kubernetesに詳しくなくてもKubernetes上でDruckerを立ち上げることができる点があります。課題もあって、例えばDrucker dashboardの現バージョンv0.2.0では「性能の評価と可視化」機能が未実装である点、Kubernetes dashboardのようにサービスの現状(e.g. 死活状態、CPUやメモリ使用量)をモニタリングする機能が未実装である点、ユーザー認証機能がない点など、まだまだ足りない機能が多いですが、今後の開発に期待しています。
Drucker client
Drucker clientは前述のDruckerに接続するためのSDKです。DruckerはgRPCを使っているため、gRPCのスペックから任意の言語のSDKを自動生成できます。Drucker clientはgRPCスペックから自動生成されたPython SDKを拡張したものになります。Kubernetes上のDruckerにアクセスするためにはClientを以下のように使います。
logger = SystemLogger(logger_name="drucker_client")
domain = 'example.com'
app = 'drucker-sample'
env = 'development'
client = DruckerWorkerClient(logger=logger, domain=domain, app=app, env=env)
input = [0,0,0,1,11,0,0,0,0,0,
0,7,8,0,0,0,0,0,1,13,
6,2,2,0,0,0,7,15,0,9,
8,0,0,5,16,10,0,16,6,0,
0,4,15,16,13,16,1,0,0,0,
0,3,15,10,0,0,0,0,0,2,
16,4,0,0]
response = client.run_predict_arrint_arrint(input)
Logging
fluentdが提供する公式のKubernetes対応であるfluentd-kubernetesを使います。こちらをKubernetes上で立ち上げておくことで、Kubernetes上のすべてのPodの標準出力と標準エラー出力を任意のサーバーに転送できます。ClovaではDruckerのログをkibana x ElasticSearchのサーバーに転送しています。
Docker registry x Git repository
通常Kubernetesを使ったサービス管理ではコンテナイメージを更新することでサービスの更新をしますが、ユーザーはコンテナイメージの作成に習熟している必要があります。Druckerではユーザーがコンテナイメージの作成に詳しくなくてもKubernetes上でサービスを提供できるようになっています。Druckerはベースとなるコンテナイメージを提供しており、コンテナ起動時にDruckerのコードをgit pullしてサービスを起動します。
sshによるgit pullにも対応しています。Drucker PodはKubernetesノードの/root/.ssh/をマウントしているので、ノードにsshキーを保存しておくことでPodがsshでアクセスできるようになります。
Online storage
機械学習モデルはオンラインストレージ(e.g. AWS EBS、GCS、WebDAV)に保存します。仕組みですが、Drucker PodはKubernetesノードをマウント(デフォルトでは/mnt/drucker-model/)しています。ですので、Kubernetesノードの当該ディレクトリにオンラインストレージをマウントすることで、全てのPodがオンラインストレージをマウントできるようになります。これにより、全ての機械学習モデルを全ての機械学習サービスで共有しています。
MySQL
MySQLはDruckerが読み込む機械学習モデルの割当を管理します。Drucker起動時にDruckerはMySQLを参照し、自身が読み込む機械学習モデルを把握します。Kubernetesでは障害や更新のときに現行Podを破棄して新しいPodを立ち上げます。なので、外部からコントロールするパラメータは参照先を外に設けておく必要があります。
使い方
Drucker x Kubernetesの環境構築については公式ドキュメントを参照してください。ここではDrucker dashboardによる機械学習モジュールの管理方法を紹介します。
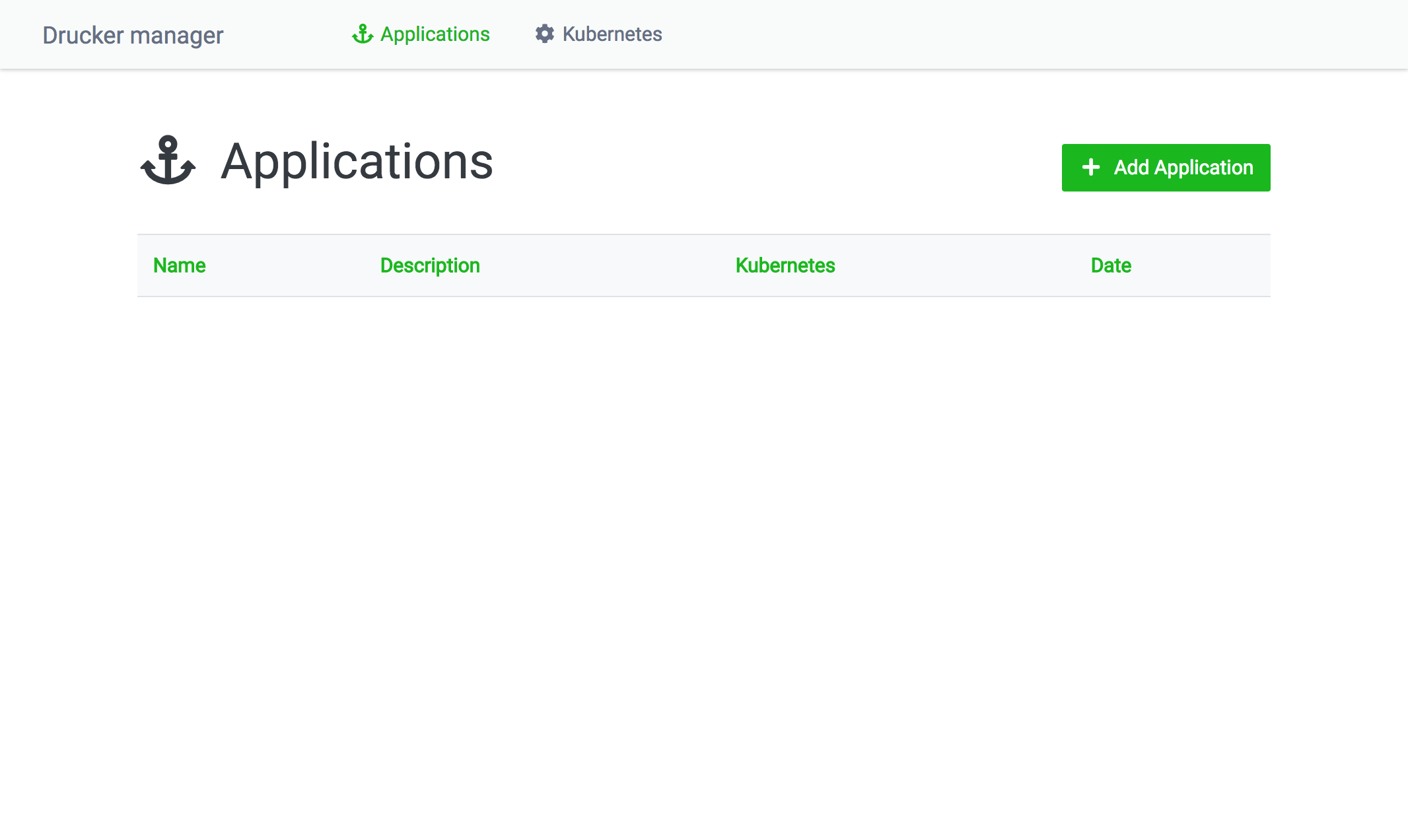
Drucker dashboardを起動し、dashboard (e.g. http://localhost:8080/) にアクセスします。トップ画面はdashboardで管理しているDrucker applicationの一覧が表示されます。
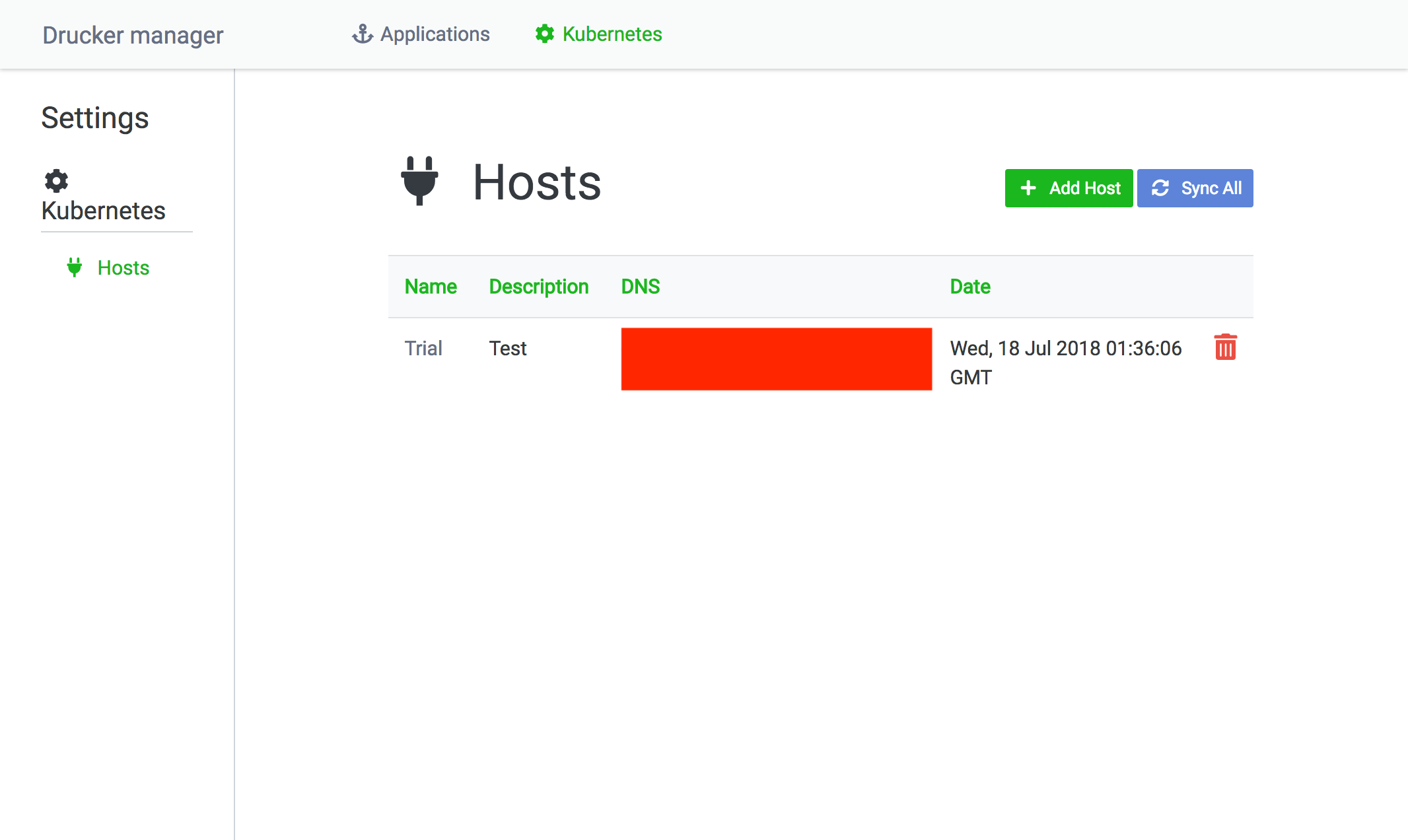
トップページのメニューにあるKubernetesをクリックすると、dashboardで管理しているKubernetesクラスタを一覧できます。Add Hostで新しいKubernetesクラスタを登録できます。Sync Allでdashboardに登録されているKubernetesクラスタに問い合わせ、起動中のDruckerの情報を取得します。これは、Drucker dashboard以外の方法でKubernetesを操作した場合に、Drucker dashboardの情報を最新に保つための機能です。
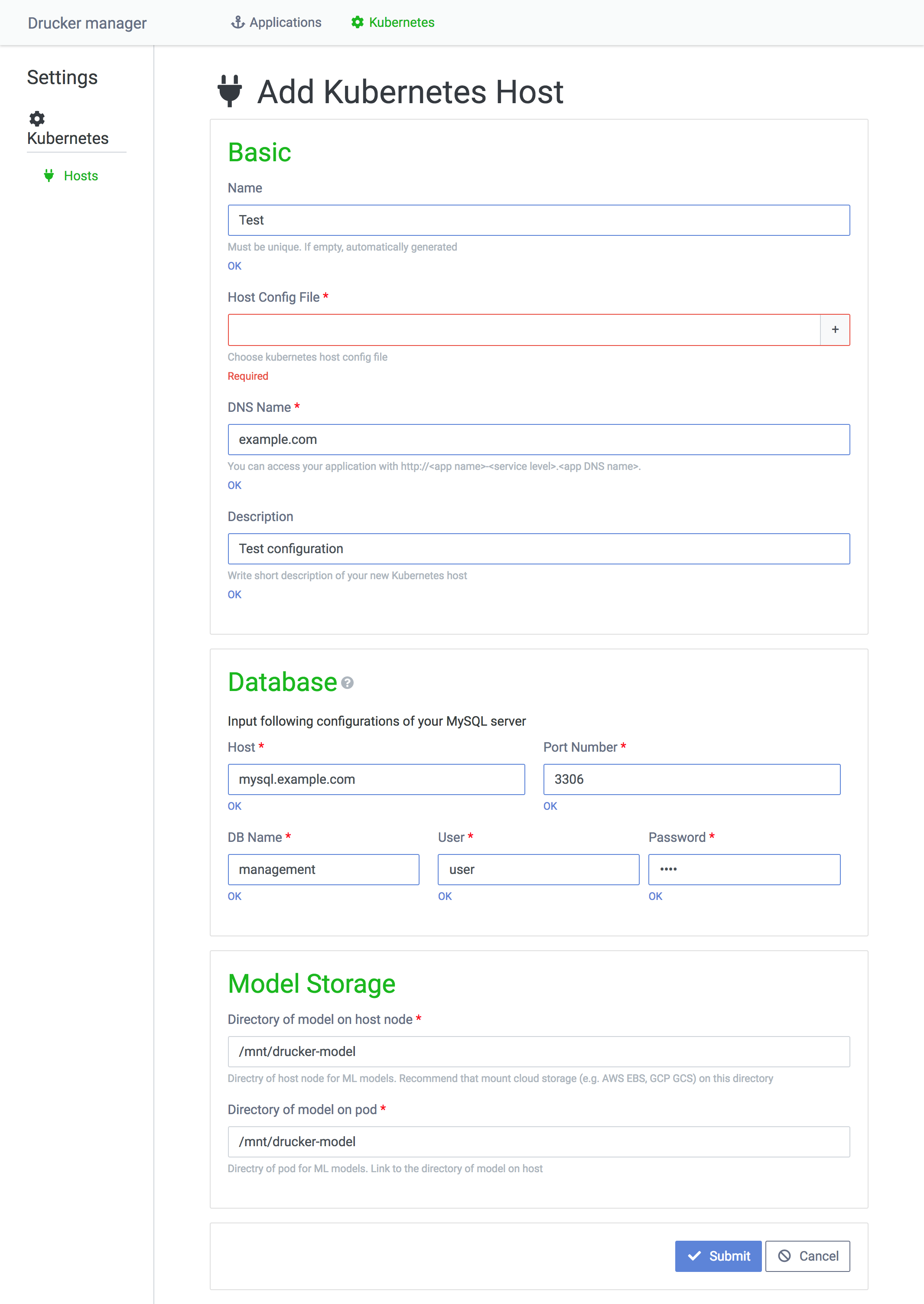
Kubernetesクラスタの登録画面です。Host Config FileはKubernetesクラスタにアクセスするためのトークンを保持するファイルです。Kubernetesクラスタのアクセストークンの取得方法はこちらを参照してください。
MySQLはDrucker Podの起動時に参照するデータベースで、Drucker Podが読み込む機械学習モデルの割当を管理します。Model Storageは機械学習モデルの保存先で、Drucker PodがKubernetesノードのディレクトリをマウントします。すべてのPodで機械学習モデルを共有するために、Kubernetesノードの当該ディレクトリはオンラインストレージをマウントしている必要があります。
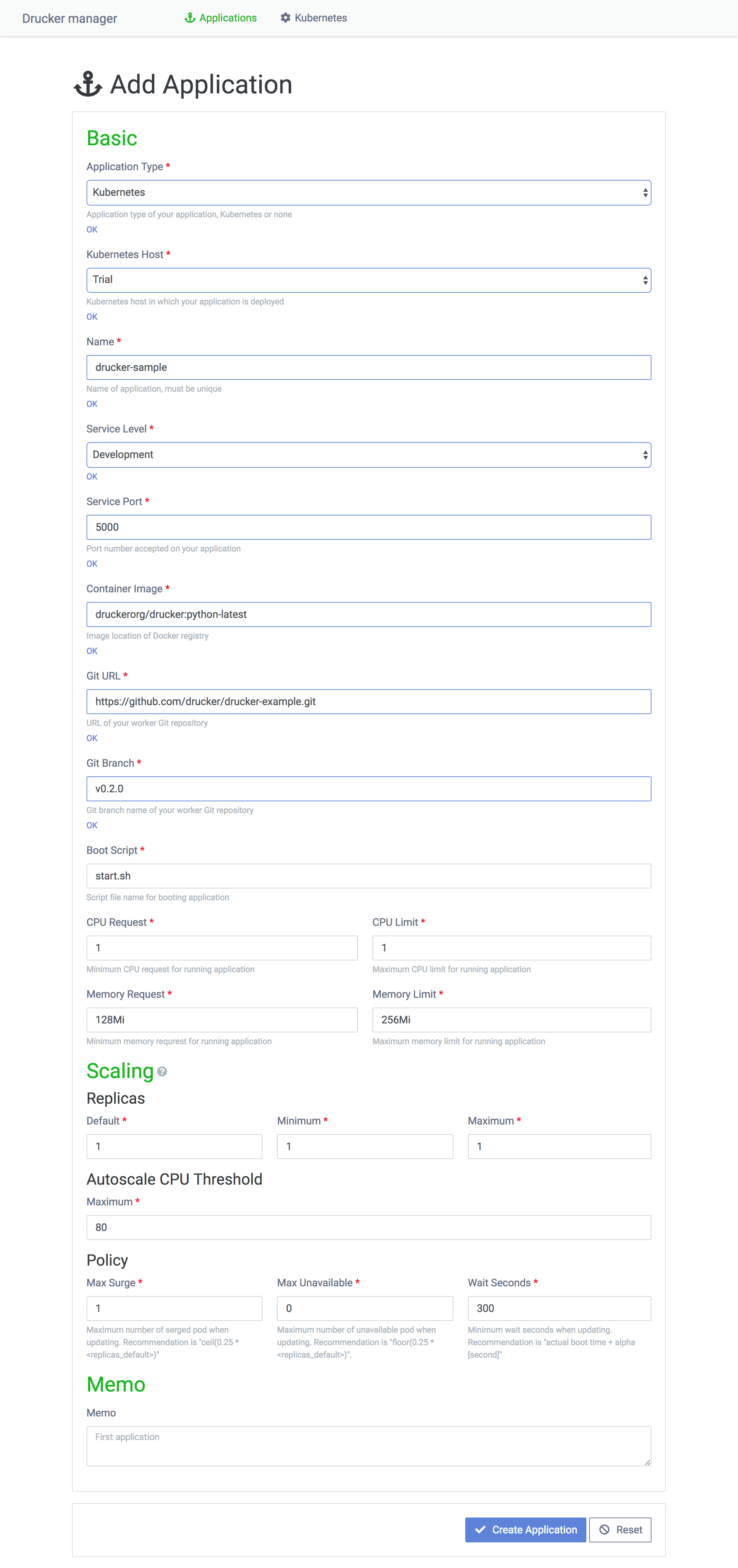
dashboardを介して新しい機械学習モジュールをKubernetesで起動する方法を説明します。トップページのAdd Applicationをクリックするとこちらの画面が開きます。Application TypeはKubernetesを選択し、Kubernetes Typeで起動したいKubernetesクラスタを指定します。
NameはDrucker applicationの名前を入力します。Drucker dashboardは機械学習モジュールをアプリケーションという単位で管理し、アプリケーションの下にサービスレベルや読み込む機械学習モデルが異なるDrucker serviceが管理されます。
Service Levelはサービスレベルで、developmentやproductionなど適切なサービスレベルを指定します。Service PortはサービスがKubernetes Pod上で起動するPortで、任意のPortを指定します。
Container ImageはDrucker Podが起動するコンテナイメージで、Drucker公式のDockerイメージを使うか、公式のDockerイメージを拡張した独自のイメージを使います。コンテナイメージはDocker Hubに登録するかPrivate Docker registryに登録します。
Git URLとGit BranchはDruckerによって機械学習サービスにしたあなたコードの保存先のgitリポジトリを指定します。Boot Scriptは当該gitリポジトリ配下にある起動シェルスクリプトを指定します。Druckerの公式Dockerイメージはコンテナ起動時にGit URLとGit Branchからコードをpullし、Boot Scriptを使ってDrucker Podを起動します。
CPU request、CPU limit、Memory request、Memory limitはそれぞれDrucker Podで使用するCPUとメモリの要求量と上限量です。CPU requestとCPU limitはfloatを取り、1.0はCPU1台を意味します。Memory requestとMemory limitはstringで128Miや1Giなどを指定します。
ScalingのReplicaのDefault、MinimumおよびMaximumはそれぞれ初期起動Pod数、最小起動Pod数、最大起動Pod数を意味します。Drucker serviceの利用頻度とKubernetesクラスタの規模を考慮して適切な値を設定します。Autoscale CPU Thresholdはオートスケールのトリガーです。80の場合はCPUの使用量が80%を超えた場合にオートスケールを実行します。Max Surgeはローリングアップデート時に一度に起動する新規Drucker Pod数です。Max Unavailableはローリングアップデート時に一度に削除する現行Drucker Pod数です。Wait Secondsはローリングアップデートで起動したPodが安定するまでにかかる時間を定義します。Wait Secondsは重要な値で、これが短かすぎるとDrucker Podの起動失敗に気づかずに次々と現行Podを削除してしまい、最悪の場合はサービスが停止します。
Memoは自由記入欄で、例えば「いつリリースしたか」「どのような変更でアップデートしたか」などを記入します。
トップページから任意のDrucker applicationを選択することでDrucker service一覧にアクセスできます。このページは表になっていて、縦軸が機械学習モデルで横軸がDrucker serviceです。この表を見れば、どのDrucker serviceがどの機械学習モデルを読み込んでいるかが一元管理できます。
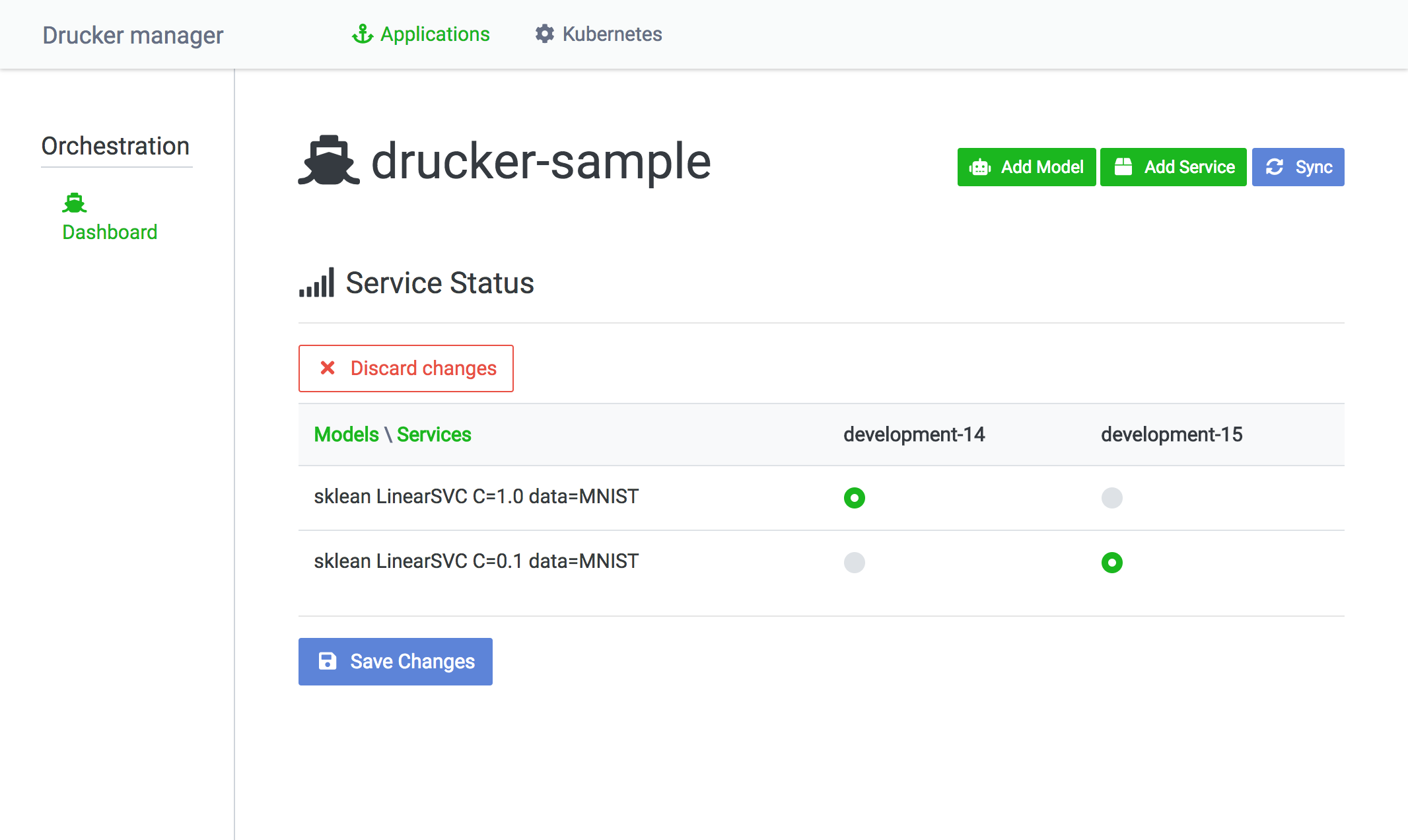
Switch ModelsをクリックするとDrucker serviceの機械学習モデルを切り替えることができます。Save ChangesをクリックすることでKubernetes上でローリングアップデートが実行されます。
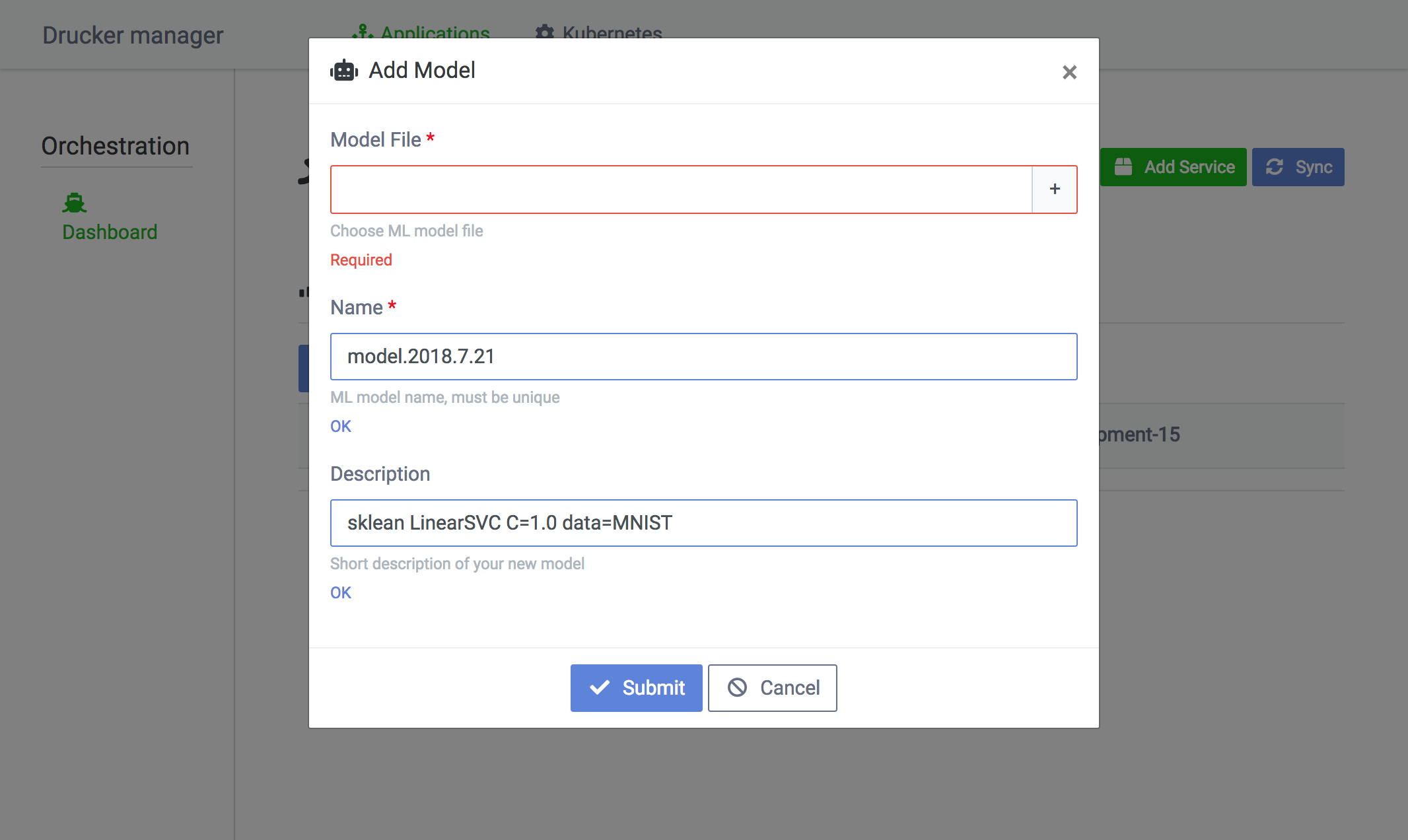
サービス一覧画面のAdd Modelをクリックすると機械学習モデルのアップロードができます。Descriptionにモデルの作成日や設定などを記入しておくとモデルの管理が捗ります。
おわりに
今回はClovaにおける機械学習モジュールの管理運営基盤Druckerの紹介をしました。Druckerは柔軟性が高い作りになっていて、あらゆるアルゴリズムを配信することができます。またDashboardによってWebUIで機械学習モデルを管理運用できます。バックエンドをKubernetesにすることによってサービスの監視とスケーリングを自動化できます。DruckerはgRPCサービスであるため、あらゆる言語のSDKを自動生成できます。また、Clientはアプリ名の指定によって接続する機械学習モジュールを切り替えられるため、ひとつのClientでDrucker x Kubernetesで配信するすべての機械学習モジュールにアクセスすることができます。Druckerはまだまだ発展途上のプロジェクトで足りない機能は多いですが、OSSなので積極的にプルリクをだして盛り上げていきたいと思います。
次回はJunさんによる「Write you a webpack for great good」についての記事です。お楽しみに!