
2020年夏のインターンシップに参加した加藤郁之です.今回のインターンシップでは,多次元データに対する差分プライベートなデータ探索の実現に関する研究を行いました.また,インターンシップ終了後も,アルバイトとして半年間研究に携わりました.
本研究に関する論文は,2021年3月に開催される 第13回データ工学と情報マネジメントに関するフォーラム (DEIM2021) で発表予定です.
研究背景
企業や組織が多くのデータを収集し,データを活用することで多大な価値を産み出しています.一方で,個人の行動履歴やヘルスケアに関するデータなど,プライバシ性の高いデータの利活用はプライバシ保護の観点から大きく制限されます.このような背景から,データのプライバシ保証と利活用を両立するための枠組みが必要となっています.
本研究では、技術の有用性を確認するため、公開データを用いて評価検証に取り組みました.
差分プライバシは,2006年にDworkによって提案された数学的に厳密なプライバシ定義です.下図のように,データベースからの出力に対して精緻にデザインされたランダム化を行うことで,データベース内の任意のレコードに対するプライバシを保証します.このプライバシ保証は,ある確率値にバウンドされた識別不能性によって厳密に評価することができます.例えば,カウントクエリに対してはスケール1/εのLaplace分布からサンプリングされたランダムなノイズを加えることで,ε-差分プライバシを保証することができます.これは大雑把に言うと,どのようなデータベースからその出力が得られたのかに関する確信度がexp(ε)以下にしかならないというプライバシ保証を提供します.
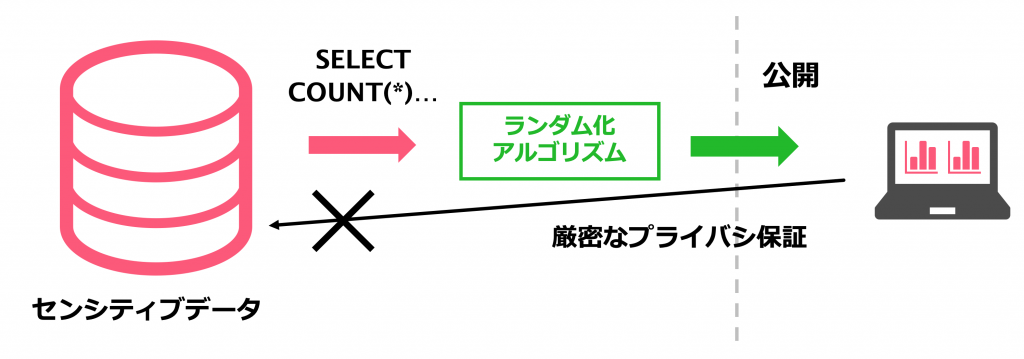
私がインターンシップで取り組んだ研究では,上記の差分プライバシを保証したデータ分析基盤を提供することを大きな目的としていました.
データ分析のワークフローには,最初にデータの分布や特徴を理解するデータ探索と呼ばれるプロセスが必要です.データ分析者はこの探索を通じて,成果物としての統計モデルやデータマイニングに用いる手法・アルゴリズムをデザインします.今回のインターンシップでは,特に差分プライバシ保護下で高精度にカウントクエリ(ヒストグラム)を公開する方法について研究しました.
研究課題
差分プライバシを保護してカウントクエリの結果を公開する既存手法には,主に,特定のワークロード(カウントクエリの集合)に対して摂動ノイズを最適化する手法と,データのパーティショニングとカウント値の集約によって摂動ノイズを縮小する方法があります.しかし,前者は事前にワークロードを決定する必要があり,データ探索には不向きと言えます.後者は,データの分布のみに依存し,差分プライバシを満たしたマテリアライズドビューを提供できる一方で,1次元程度の低次元データに対してしか有効ではありません.したがって多次元データに対するプライバシ保護型データ探索を提供する有効な手法はありませんでした.
主な課題としては,多次元のカウントテンソルにおいて最適なパーティショニングを発見する最適化のコストが大きすぎることがあげられます.また,差分プライベートなマテリアライズドビューのサイズがデータの次元に対して指数的に増加してしまい,多次元データに対しては空間効率の点から実現が困難であるという課題もあります.
今回のインターンシップではこれらの課題を克服する,「多次元データ」に対しても適用可能である,差分プライベートなマテリアライズドビューを生成するアルゴリズムを提案することを目標としました.下の図のように,データ分析者はこのビューに対するカウントクエリの発行やサンプリングを通じて差分プライベートなデータ探索を行います.
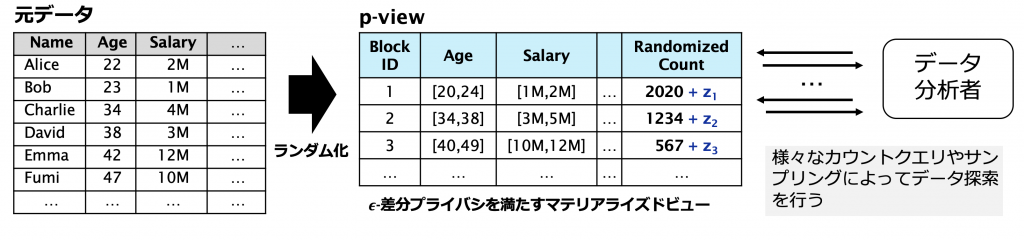
提案手法
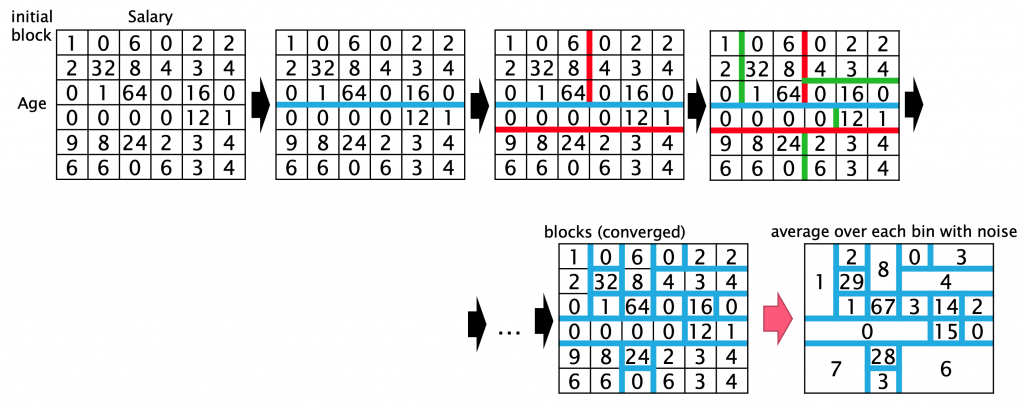
多次元データに対して,差分プライバシを満たしつつ,最適なブロック分割を効率よく探索するためにDP-Mondrianという手法を提案しました.さらに,提案手法はデータのブロック化によってマテリアライズドビューの空間効率の問題も克服しています.
DP-Mondrianは,下図のように多次元カウントテンソルに対して再帰的な2分割を繰り返しながら,有用性を保持するブロックを探索します.ここで重要な課題は,この効率の良い探索手法を差分プライバシの制約下でどのように実現するかということです.DP-Mondrianでは,分割点の決定とブロックの収束判定にそれぞれ差分プライバシを満たしている効果的なメカニズムを提案することでこれを解決しています.さらに,差分プライバシの並列合成定理を利用することで,各ブロックに対してプライバシ予算を無駄なく割り当てる方法を導入しました.
実データを用いた実験によってDP-Mondrianを評価しました.DP-Mondrianの生成する差分プライベートなマテリアライズドビューは,既存手法よりも高い精度で多様なカウントクエリに応答可能であることが分かりました(図(1)).また,ビューからサンプリングされたデータは,既存の差分プライベートな生成モデルと比較しても高い有用性を維持していることが示されました(図(2)).

図(1) カウントクエリに対する平均相対RMSE (こんな感じでcaptionをつけたい)
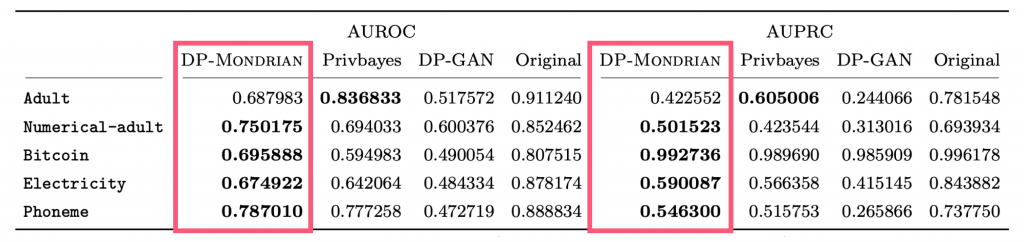
図(2) サンプリングされたデータに対するクラス分類結果
まとめ
本記事では,LINEのインターンシップで取り組んだ,多次元データに対する差分プライベートなデータ探索の実現の研究について紹介させて頂きました.
感想
最後に,感想としてインターンシップの中で特に印象に残っていることを2点共有させて頂きます.
1点目は,企業で研究することの面白さです.今回のインターンシップで取り組んだ研究は,「こういうことが実現したい」という漠然とした課題感からスタートしました.そこからメンターの方と多くの議論を重ね,取り組むべき研究課題や社会実装の実現性などについて網羅的に整理し,最終的に新しいアルゴリズムを提案して研究成果としてまとめることができました.そのプロセスの中で,大学での研究と企業での研究の違いを感じました.特に企業での研究は,議論の方向性が常に社会実装に向いているように思いました.実課題を研究によって解決していくということが普段の研究よりも強く意識され,人によっては研究へのモチベーションが高まるのではないかと思います.実際,私自身はそういうタイプでした.
2点目は,インターンを通じた成長です.インターンシップ中は,非常に濃い密度でLINEの研究者と議論をさせて頂きました.プロジェクトの話はともかく,研究者自身の研究の進め方や考え方をたくさん聞くことができました.特に今回のインターンシップでは,研究課題の発見から論文の執筆までの一連のプロセス全体に取り組むことができました.そのため,非常に広範囲に渡るアドバイスを頂くことができて,自分自身非常に成長できたと感じています.
興味のある方はぜひ次回のLINEのインターンシップに応募してみてください!