
この記事は LINE Advent Calendar 2018 の 3 日目の記事です。
LINE Data Labs のデータエンジニアの吉田啓二です。私が昨年末から今年にかけて担当したデータエンジニアリング関連ソフトウェアの障害対応内容をいくつかご紹介します。
1. Apache Hadoop YARN : ResourceManager Failover
1-1. システム概要
Data Labs が管理している Hadoop クラスタの中で、各 LINE サービスのデータを収集して一元管理しているものがあります。 Apache Sqoop などを使用して各 LINE サービスのデータが HDFS へ取り込まれます。 YARN クラスタ上では MapReduce, Tez, Spark などのアプリケーションが実行され、これらのデータに対する集計・加工などの処理が実施されます。システム構成は以下の通りです。
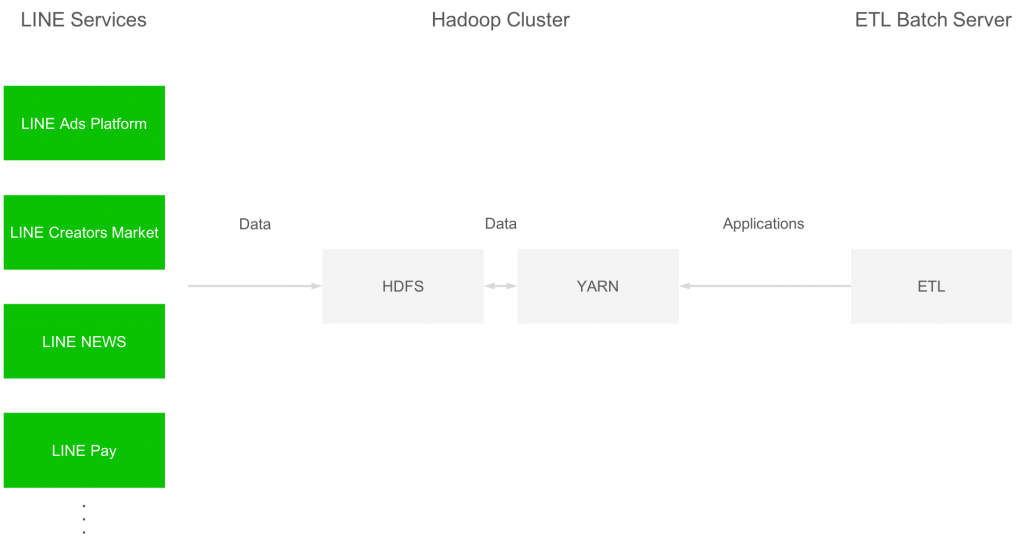
この Hadoop クラスタは HDP-2.6.2.0 (2.6.2.0-205) で構築されており、 YARN のバージョンは 2.7.3 です。
1-2. 発生事象
この Hadoop クラスタの構築・稼働後、実行アプリケーションの数が増えてきた段階で、 HA 構成となっている YARN クラスタの ResourceManager がたびたびフェイルオーバーするようになりました。フェイルオーバーが発生したときのアクティブ ResourceManager のログには以下の情報が出力されていました。
WARN resourcemanager.EmbeddedElectorService (EmbeddedElectorService.java:enterNeutralMode(175)) - Lost contact with Zookeeper. Transitioning to standby in 10000 ms if connection is not reestablished.
INFO resourcemanager.ResourceManager (ResourceManager.java:transitionToStandby(1070)) - Transitioning to standby state
INFO resourcemanager.ResourceManager (ResourceManager.java:transitionToStandby(1077)) - Transitioned to standby state
INFO resourcemanager.ResourceManager (ResourceManager.java:transitionToStandby(1066)) - Already in standby stateこのログ情報を見る限りは、アクティブ ResourceManager から ZooKeeper クラスタへ、ハートビートを規定の時間内 (この Hadoop クラスタでは yarn.resourcemanager.zk-timeout-ms = 10000 が設定されている) に送信できなかったことが、フェイルオーバーの直接的な原因となっていたようでした。ここから、「なぜアクティブ ResourceManager が ZooKeeper へハートビートを規定の時間内に送信できなかったのか?」を調査することにしました。
1-3. ログ調査
アクティブ ResourceManager の gclog を見ても、フェイルオーバー発生時に JVM が長時間停止したことは確認できず、 GC が原因である可能性は無さそうでした。また、 CPU 使用率などのサーバリソースの使用状況も、フェイルオーバー発生時と通常時で大きな違いがなく、 ResourceManager の内部処理に「 ZooKeeper へハートビートを規定の時間内に送信できなかったこと」の原因がありそうでした。
フェイルオーバー発生時のアクティブ ResourceManager のログを読み進めていくと、以下のような情報が大量に出力されていました。
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 1000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 2000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 3000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 4000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 5000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 6000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 7000
INFO event.AsyncDispatcher (AsyncDispatcher.java:handle(243)) - Size of event-queue is 8000
...このようなログ情報は org.apache.hadoop.yarn.event.AsyncDispatcher の内部処理で出力されており、フェイルオーバーの発生直前には、出力される Size of event-queue の値が約 400,000 まで増加していました。このようなログ情報は通常時には滅多に出力されないものであり、また、フェイルオーバーとの関連も当時不明であったため、「この event-queue はどのようなものであるのか?」を ResourceManager のソースコードを読んで理解することにしました。
1-4. ResourceManager のイベント処理の仕組み
ResourceManager では、 AsyncDispatcher において下記の通り、アプリケーションの開始・終了やコンテナの起動・破棄などの YARN アプリケーションに関する様々なイベントが、 LinkedBlockingQueue を使用して蓄積・処理されるようになっていました。

まず、アプリケーションの開始・終了やコンテナの起動・破棄などが発生した場合は、そのイベントが GenericEventHandler#handle へ渡され、このメソッド内でそのイベントが LinkedBlockingQueue へ登録されます。別の thread でこの LinkedBlockingQueue からイベントが順次取得されて、そのイベントの種類に応じた EventHandler の handle メソッドが実行され、そのイベントが処理されます。処理されるイベントの種類と、それに対応する EventHandler は、 ResourceManager のログから下記の通りであることがわかりました。
処理されるイベントの種類と、それに対応する EventHandler
前述の Size of event-queue is 1000 というようなログは、 GenericEventHandler#handle にてイベントを LinkedBlockingQueue へ登録する直前に出力されており、フェイルオーバーが起こる直前では、約 400,000 個のイベントが未処理のまま LinkedBlockingQueue 内に滞留していた、ということがわかりました。
1-5. イベント滞留と ZooKeeper ハートビートタイムアウトの関連性
ResourceManager から ZooKeeper へのハートビート送信は、 ResourceManager 内の ZooKeeper client である ClientCnxn というクラス内の SendThread という thread にて行われているようで、「大量のイベントが LinkedBlockingQueue 内に滞留していた」ことと「 ResourceManager から ZooKeeper へハートビートを規定の時間内に送信できなかった」ことに直接的な関連は無さそうに見えました。
1-6. JMX メトリクスのモニタリング
「通常時とフェイルオーバー発生時で ResourceManager の JVM の内部状態に違いは無いか?」を確認するために、 Prometheus JMX Exporter を導入し、 Grafana 上で各種メトリクスを時系列で可視化・グラフ化することにしました。
フェイルオーバーが発生したときのメトリクスを見てみると、以下のように、 ResourceManager の JVM thread の数が通常時と比べて急増していたことがわかりました。
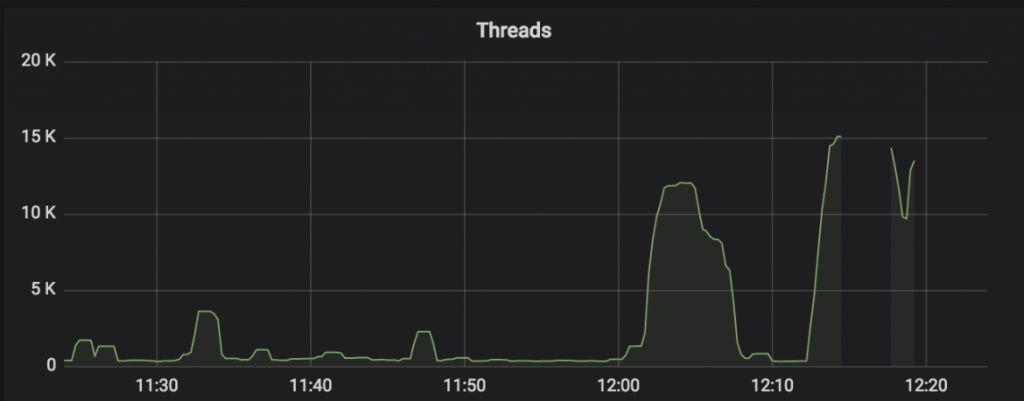
 このグラフ上の 12:20 頃にこの ResourceManager のフェイルオーバーが発生したのですが、thread 数が、通常は 1,000 未満であるところ、フェイルオーバー発生の直前には 15,000 ほどまで増加していたことがわかりました。
このグラフ上の 12:20 頃にこの ResourceManager のフェイルオーバーが発生したのですが、thread 数が、通常は 1,000 未満であるところ、フェイルオーバー発生の直前には 15,000 ほどまで増加していたことがわかりました。1-7. Thread の情報
「フェイルオーバー発生前には、どのような thread が増えていたのか?」を確認するために、フェイルオーバーが発生する直前に(前述の Size of event-queue の値が 10,000 を超えるとフェイルオーバーが発生する可能性がある、ということが経験的にわかっていました) thread dump を取得してその内容を確認してみました。 thread 名別の thread 数は以下のようになっていました。
| Thread 名 | 個数 | 全体に占める割合 |
|---|---|---|
| 合計 | 14,334 | 100.0 % |
| RegistryAdminService | 13,989 | 97.6 % |
| IPC Server handler | 155 | 1.1 % |
| ApplicationMasterLauncher | 50 | 0.3 % |
| AsyncDispatcher event handler | 13 | 0.1 % |
| その他 | 127 | 0.9 % |
上記の通り、フェイルオーバー発生直前には RegistryAdminService という名前の thread が、全 thread 数のほとんど (97.6 %) を占めていたことがわかりました。
1-8. RegistryAdminService Thread
今度は、「この RegistryAdminService thread はどのようなものであるのか」を確認することにしました。この名前の thread は RMRegistryService クラスにおいて、以下のいずれかのイベントハンドリング処理で生成されることがわかりました。
- RMStateStore への Application 情報の登録時( eventType =
RMStateStoreEventType.STORE_APPのイベント発生時)に、RegistryAdminServicethread を生成して、 ZooKeeper 上に user directory /registry/users/{username} を作成する- 前述の「処理されるイベントの種類と、それに対応する EventHandler 」の表の No. 13 のケース
- RMRegistryService.java#L129
- Application Attempt 削除時( eventType =
RMAppAttemptEventType.UNREGISTEREDのイベント発生時)に、RegistryAdminServicethread を生成して、 ZooKeeper 上の /registry 以下にある appattempt id ( appattempt_1523336070074_12345_000001 など)に match する record を削除する- 前述の「処理されるイベントの種類と、それに対応する EventHandler 」の表の No. 11 のケース
- RMRegistryService.java#L148
- Application 完了時( eventType =
RMAppManagerEventType.APP_COMPLETEDのイベント発生時)に、RegistryAdminServicethread を生成して、 ZooKeeper 上の /registry 以下にある application id ( application_1523336070074_12345 など)に match する record を削除する- 前述の「処理されるイベントの種類と、それに対応する EventHandler 」の表の No. 12 のケース
- RMRegistryService.java#L110
- container 停止時( eventType =
RMAppAttemptEventType.CONTAINER_FINISHEDorRMContainerEventType.FINISHEDのイベント発生時)に、RegistryAdminServicethread を生成して、 ZooKeeper 上 /registry 以下にある container id ( container_e102_1523336070074_12346_01_000221 など) に match する record を削除する- 前述の「処理されるイベントの種類と、それに対応する EventHandler 」の表の No. 11, 14 のケース
- RMRegistryService.java#L156
- RMRegistryService.java#L171
実運用上、前述の 4 つのイベントハンドリング処理のうち、最も多く実行されるのは、 4 番目の container 停止時のイベントハンドリング処理になります。例えば、 1,000 個の container を使用する MapReduce ジョブの終了時には、これら 1,000 個の container が停止し、それに伴って前述の 4 番目の container 停止時のイベントが同時に 1,000 個発生して「 1-4. ResourceManager のイベント処理の仕組み」で言及した LinkedBlockingQueue に登録され、それらが順次、 AsyncDispatcher で取り出されて前述の 4 番目のイベントハンドリング処理で処理され、イベントごとに RegistryAdminService thread が生成されて、 ZooKeeper へ record 削除のリクエストが送信されます。そして、 ResourceManager から ZooKeeper へのリクエスト送信は、 ZooKeeper client の ClientCnxn で単一 thread で実施されるため、大量の container の停止時にはその数の分だけ RegistryAdminService thread が生成されて、 ZooKeeper へのリクエスト送信がボトルネックとなり、大量の RegistryAdminService thread が ZooKeeper へのリクエスト送信完了待ちの状態で残存するようになっているようでした。


1-9. YARN Service Registry
ResourceManager のソースコードを読み進めていくと、RegistryAdminService thread を生成する、前述の RMRegistryService クラスの 4 つのイベントハンドリング処理は、 YARN の設定 hadoop.registry.rm.enabled の値が true であるときのみ実施されることがわかりました。この設定値が true であると、 YARN Service Registry という、 YARN アプリケーション同士がお互いにやり取りするための仕組みを使用するために、 ResourceManager のイベントハンドリング処理として、前述の 4 つが追加されるようでした。こちらは意図的に true へ設定したわけではなく、 Ambari での Hadoop クラスタの構築時に各種コンポーネントをインストールした際に、自動的に true が設定されてしまっていたようでした。我々のデータ基盤の用途としては、この YARN Service Registry を利用する必要は無かったため、 hadoop.registry.rm.enabled の値を false へ変更して、大量の container が同時に停止されても RegistryAdminService thread が生成されないようにして、 ResourceManager のフェイルオーバーが発生しないようになるかを検証することにしました。
1-10. 問題解決
YARN の設定 hadoop.registry.rm.enabled の値を false にしてしばらく様子を見たり、また、数千個の container を使用する MapReduce ジョブを意図的に何度も実行したりしましたが、以下のグラフの通り、 JVM threads の数は常に 300 程度となり、 ResourceManager のフェイルオーバーも発生せずに安定稼働するようになり、本件は解決しました。


RM frequent failover - Hortonworks の記事に、今回我々が直面した事象と同じことが書かれていたのですが、 YARN Service Registry を利用していると、 ResourceManager - ZooKeeper 間の通信に問題が発生してハートビートがタイムアウトし、 ResourceManager がフェイルオーバーしてしまう、というのは既知の事象のようでした。
2. Apache Hadoop HDFS : NameNode Failover
2-1. システム概要
Data Labs が管理している Hadoop クラスタの中で、 Fluentd 経由で各サーバのアクセスログ・アプリケーションログを受け取るものがあります。これらのログデータは、 hourly の ETL バッチ処理で Hive テーブルへ登録されます。システム構成は以下の通りです。
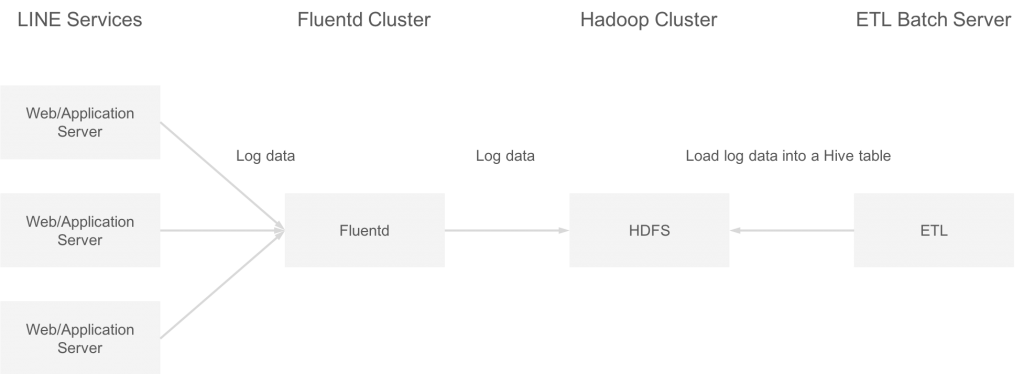

この Hadoop クラスタは HDP-2.6.1.0 (2.6.1.0-129) で構築されており、 HDFS のバージョンは 2.7.3 です。
2-2. データフロー
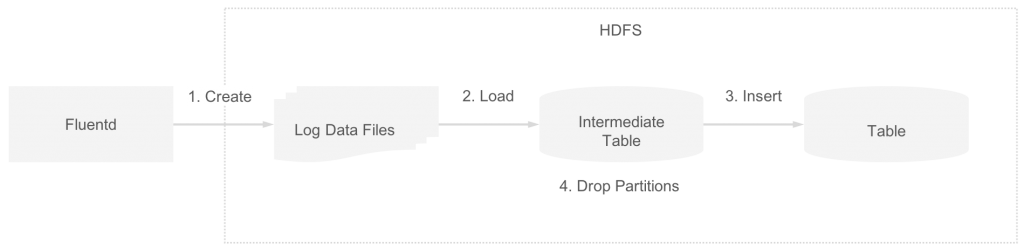
ログデータが Hive テーブルへ登録されるまでのデータフローは以下の通りです。
- Fluentd から HDFS のディレクトリへログデータファイルが書き込まれる。
- HIVE
LOAD DATA文の実行により、ログデータファイルが中間テーブルのディレクトリへ移動される。 - HIVE
INSERT ... SELECT文の実行により、中間テーブルのデータが最終テーブルへ登録される。(ファイルフォーマットを変更) - HIVE
ALTER TABLE ... DROP PARTITION文の実行により、中間テーブルへロードされたログデータファイルが削除される。

2-3. 発生事象
HA 構成となっている HDFS の NameNode が、特定の時間帯(午前 9 時頃)にたまにフェイルオーバーするようになりました。フェイルオーバー発生時の ZooKeeper Failover Controller のログを見てみると、以下のようなログが出力されており、 ZooKeeper Failover Controller から NameNode へのヘルスチェックがタイムアウト( 60 秒)で失敗し、その結果、フェイルオーバーが発生したようでした。
09:03:08,165 WARN ha.HealthMonitor (HealthMonitor.java:doHealthChecks(211)) - Transport-level exception trying to monitor health of NameNode at xxxx/xxx.xxx.xxx.xxx:xxxx: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/xxx.xxx.xxx.xxx:xxxx remote=xxxx/xxx.xxx.xxx.xxx:xxxx] Call From xxxx/xxx.xxx.xxx.xxx to xxxx:xxxx failed on socket timeout exception: java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/xxx.xxx.xxx.xxx:xxxx remote=xxxx/xxx.xxx.xxx.xxx:xxxx]; For more details see: http://wiki.apache.org/hadoop/SocketTimeoutここから、 NameNode 側のログや処理内容を調査して、 ZooKeeper Failover Controller から NameNode へのヘルスチェックがタイムアウトとなった原因を探ることにしました。
2-4. ログ調査
フェイルオーバー発生直前の NameNode のログを確認すると、以下の情報が出力されていました。
09:00:30,574 INFO fs.TrashPolicyDefault (TrashPolicyDefault.java:deleteCheckpoint(319)) - TrashPolicyDefault#deleteCheckpoint for trashRoot: hdfs://xxxx/user/hive/.Trash
09:01:06,673 INFO namenode.FSNamesystem (FSNamesystem.java:writeUnlock(1659)) - FSNamesystem write lock held for 36094 ms via
java.lang.Thread.getStackTrace(Thread.java:1559)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:945)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1659)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.delete(FSNamesystem.java:3975)
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.delete(NameNodeRpcServer.java:1078)
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.delete(ClientNamenodeProtocolServerSideTranslatorPB.java:622)
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:640)
org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2351)
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2347)
java.security.AccessController.doPrivileged(Native Method)
javax.security.auth.Subject.doAs(Subject.java:422)
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1866)
org.apache.hadoop.ipc.Server$Handler.run(Server.java:2345)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 36094このログ情報を読む限り、 .Trashディレクトリ配下の各サブディレクトリのファイルを削除する処理が開始されて(この Hadoop クラスタでは、前述 2-2. データフローの 4. により、削除されたログデータファイルが .Trash ディレクトリへ移動されます)、あるディレクトリの削除処理で FSNamesystem の write lock が長時間(約 36 秒間)取得されていたようでした。
その後も、以下のようなログがいくつか出力されており、ブロックの削除処理による 1~7 秒間の GC pause 、および、それに伴う FSNamesystem の write lock 取得が断続的に発生していたようでした。
09:01:17,955 INFO util.JvmPauseMonitor (JvmPauseMonitor.java:run(196)) - Detected pause in JVM or host machine (eg GC): pause of approximately 1487ms
GC pool 'ParNew' had collection(s): count=1 time=1937ms
09:01:17,993 INFO namenode.FSNamesystem (FSNamesystem.java:writeUnlock(1659)) - FSNamesystem write lock held for 2038 ms via
java.lang.Thread.getStackTrace(Thread.java:1559)
org.apache.hadoop.util.StringUtils.getStackTrace(StringUtils.java:945)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.writeUnlock(FSNamesystem.java:1659)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.removeBlocks(FSNamesystem.java:4009)
org.apache.hadoop.hdfs.server.namenode.FSNamesystem.delete(FSNamesystem.java:3979)
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.delete(NameNodeRpcServer.java:1078)
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.delete(ClientNamenodeProtocolServerSideTranslatorPB.java:622)
org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:640)
org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2351)
org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2347)
java.security.AccessController.doPrivileged(Native Method)
javax.security.auth.Subject.doAs(Subject.java:422)
org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1866)
org.apache.hadoop.ipc.Server$Handler.run(Server.java:2345)
Number of suppressed write-lock reports: 0
Longest write-lock held interval: 2038この状況下の NameNode の RPC Client Port Queue Length を確認してみると、ファイル・ブロックの削除に伴う FSNamesystem の write lock の長時間の取得により、以下の通り、 Queue 上に未処理の RPC call が大量に( 3,500 個ほど)滞留している状態になっていました。

そして、 ZooKeeper Failover Controller のログを確認してみると、 NameName に対してヘルスチェックを送信する際の接続先ポート番号が、前述の RPC call が滞留している Queue のポート番号と同じになっていました。そのため、ヘルスチェックリクエストが Queue 上で長時間処理待ちの状態になってしまい、タイムアウトが発生して、 NameNode のフェイルオーバーが発生していたようでした。
2-5. 問題解決
以下の 2 つの対応を実施して解決することにしました。
1. .Trash ディレクトリ配下のファイルの削除間隔の短縮
もともと fs.trash.interval の値として 4320 が設定されており、 3 日おきに .Trash ディレクトリ配下のファイルの削除が行われていました。この設定値を 1440 へ変更して 1 日おきに削除するようにし、 .Trash ディレクトリ配下のファイルの削除に伴う FSNamesystem の write lock の取得時間を短縮するようにしました。
2. ZooKeeper から NameNode へのヘルスチェックリクエスト送信先ポート番号の変更
Scaling the HDFS NameNode (part 1) - Hortonworks を読むと、 Service RPC port という、 ZooKeeper Failover Controller (および DataNode )からのヘルスチェック(およびブロックレポート)専用のポート番号を設定できることがわかりました。ヘルスチェック専用のポート番号を使用することで、大量のファイル削除などで、たとえ NameNode の RPC Client Port Queue 上に大量の RPC call が滞留していたとしても、 NameNode は ZooKeeper Failover Controller からのヘルスチェックには遅延なく正常に応答できるようになるため、以下のような設定を追加して、 Service RPC port を使用することにしました。
dfs.namenode.servicerpc-address.mycluster.nn1=mynamenode1:8040dfs.namenode.servicerpc-address.mycluster.nn2=mynamenode2:8040
3. Apache Zeppelin : Notebook Scheduler Malfunction
3-1. 発生事象
現在は、社内用のデータ分析アプリケーションとして OASIS というものを独自に開発して使用しているのですが、これを開発する前は Apache Zeppelin (version 0.7.3) を社内で限定的に提供して運用していました。
Apache Zeppelin を運用している中で、「各 Notebook のスケジュール実行が実施されない」という事象が頻繁に発生するようになりました。 Apache Zeppelin を一度再起動するとこの事象は解消するものの、またしばらく運用していると、この事象が再発するようになっていました。
3-2. 原因調査
Apache Zeppelin のログからは原因特定のための情報は得られなかったので、 Apache Zeppelin JVM プロセスの thread dump を見てみました。以下の通り、 Notebook をスケジュール実行するための Quartz Scheduler Worker thread が全て TIMED_WAITING (sleeping) の状態になっていました。
"DefaultQuartzScheduler_Worker-10" #76 prio=5 os_prio=0 tid=0x00007fb41d3b4000 nid=0x1b521 sleeping[0x00007fb3daef1000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:889)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0a7dbf0> (a java.lang.Object)
Locked ownable synchronizers:
- None
"DefaultQuartzScheduler_Worker-9" #75 prio=5 os_prio=0 tid=0x00007fb41d3b2000 nid=0x1b520 waiting on condition [0x00007fb3daff2000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:889)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0a7a470> (a java.lang.Object)
Locked ownable synchronizers:
- None
...
"DefaultQuartzScheduler_Worker-2" #68 prio=5 os_prio=0 tid=0x00007fb41d3c8800 nid=0x1b519 waiting on condition [0x00007fb3da473000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:889)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0a7a7b0> (a java.lang.Object)
Locked ownable synchronizers:
- None
"DefaultQuartzScheduler_Worker-1" #67 prio=5 os_prio=0 tid=0x00007fb41d3cc800 nid=0x1b518 waiting on condition [0x00007fb3da372000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:889)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0a7dd90> (a java.lang.Object)
Locked ownable synchronizers:
- Noneどの thread も、 org.apache.zeppelin.notebook.Notebook$CronJob.execute の、以下の処理の Thread.sleep(1000) で sleep 状態となっていました。
String noteId = context.getJobDetail().getJobDataMap().getString("noteId");
Note note = notebook.getNote(noteId);
note.runAll();
while (!note.isTerminated()) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
logger.error(e.toString(), e);
}
}前述の処理内容を見る限り、 Notebook をスケジュールしたものの、そのどこかの Paragraph でスタックして、 Notebook が実行完了状態にならず、結果として Thread.sleep(1000) が実行され続けているようでした。そして、以下の Notebook, Job の実行完了判定の実装内容を見てみると、
Notebook が実行完了状態となるための条件は、「その Notebook の全ての Paragraph の状態が、 Ready/Running/Pending のいずれでもない」こと、であることがわかりました。
その後も検証を続けていくと、 Notebook 内に disabled となっている(実行不可に設定されている) Paragraph があると、その Notebook のスケジュール実行時にその Paragraph の実行がスキップされて、その Paragraph の状態が Ready のままとなり、結果として前述の Notebook の実行完了状態の条件が満たされず、その Notebook のスケジュール実行が前述の Thread.sleep(1000) で sleep 状態のままスタックする、ということがわかりました。
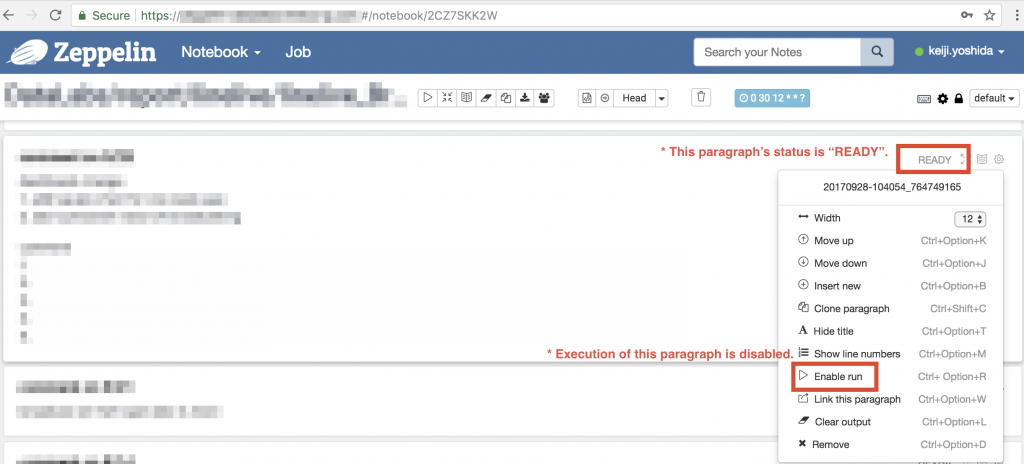

3-3. 問題解決
Apache Zeppelin の GitHub リポジトリに対して、今回の障害発生を解消するための Pull Request (そもそも Notebook のスケジュール実行時に Thread.sleep(1000) で実行完了を待つ必要が無かったので、当該処理を除去した)を送信し、同じ内容の修正を、社内で管理している Apache Zeppelin のソースコードにも適用して、本件は解決しました。
4. Apache Zeppelin : Deadlock
4-1. 発生事象
前述の Apache Zeppelin (version 0.7.3) を運用している中で、「突然 Apache Zeppelin が無応答となり、 Apache Zeppelin を再起動するまで全く操作できなくなる」という事象がたびたび発生していました。
4-2. 原因調査
Apache Zeppelin のログからは原因特定のための情報は得られなかったので、 Apache Zeppelin JVM プロセスの thread dump を見てみました。以下の通り、内部処理でデッドロックが発生していました。
Found one Java-level deadlock:
=============================
"pool-2-thread-63":
waiting to lock monitor 0x00007fd2fc0073e8 (object 0x00000000c04f9c50, a java.util.concurrent.ConcurrentHashMap),
which is held by "DefaultQuartzScheduler_Worker-2"
"DefaultQuartzScheduler_Worker-2":
waiting to lock monitor 0x00007fd28c0036c8 (object 0x00000000c16f4738, a org.apache.zeppelin.notebook.Note),
which is held by "DefaultQuartzScheduler_Worker-4"
"DefaultQuartzScheduler_Worker-4":
waiting to lock monitor 0x00007fd2fc0073e8 (object 0x00000000c04f9c50, a java.util.concurrent.ConcurrentHashMap),
which is held by "DefaultQuartzScheduler_Worker-2"
Java stack information for the threads listed above:
===================================================
"pool-2-thread-63":
at org.apache.zeppelin.interpreter.InterpreterSettingManager.get(InterpreterSettingManager.java:981)
- waiting to lock <0x00000000c04f9c50> (a java.util.concurrent.ConcurrentHashMap)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.getInterpreterSettings(InterpreterSettingManager.java:450)
at org.apache.zeppelin.interpreter.InterpreterFactory.getInterpreter(InterpreterFactory.java:382)
at org.apache.zeppelin.notebook.Paragraph.getRepl(Paragraph.java:255)
at org.apache.zeppelin.notebook.Paragraph.jobRun(Paragraph.java:361)
at org.apache.zeppelin.scheduler.Job.run(Job.java:175)
at org.apache.zeppelin.scheduler.RemoteScheduler$JobRunner.run(RemoteScheduler.java:329)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
"DefaultQuartzScheduler_Worker-2":
at org.apache.zeppelin.notebook.Note.stopDelayedPersistTimer(Note.java:789)
- waiting to lock <0x00000000c16f4738> (a org.apache.zeppelin.notebook.Note)
at org.apache.zeppelin.notebook.Note.persist(Note.java:725)
at org.apache.zeppelin.socket.NotebookServer$ParagraphListenerImpl.afterStatusChange(NotebookServer.java:2070)
at org.apache.zeppelin.scheduler.Job.setStatus(Job.java:149)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.stopJobAllInterpreter(InterpreterSettingManager.java:966)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.restart(InterpreterSettingManager.java:942)
- locked <0x00000000c04f9c50> (a java.util.concurrent.ConcurrentHashMap)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.restart(InterpreterSettingManager.java:956)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:907)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0ef6190> (a java.lang.Object)
"DefaultQuartzScheduler_Worker-4":
at org.apache.zeppelin.interpreter.InterpreterSettingManager.get(InterpreterSettingManager.java:981)
- waiting to lock <0x00000000c04f9c50> (a java.util.concurrent.ConcurrentHashMap)
at org.apache.zeppelin.interpreter.InterpreterSettingManager.getInterpreterSettings(InterpreterSettingManager.java:450)
at org.apache.zeppelin.interpreter.InterpreterFactory.getInterpreter(InterpreterFactory.java:382)
at org.apache.zeppelin.notebook.Paragraph.isValidInterpreter(Paragraph.java:701)
at org.apache.zeppelin.notebook.Paragraph.getMagic(Paragraph.java:690)
at org.apache.zeppelin.notebook.Paragraph.isBlankParagraph(Paragraph.java:354)
at org.apache.zeppelin.notebook.Note.run(Note.java:609)
at org.apache.zeppelin.notebook.Note.runAll(Note.java:596)
at org.apache.zeppelin.notebook.Note.runAll(Note.java:587)
- locked <0x00000000c16f4738> (a org.apache.zeppelin.notebook.Note)
at org.apache.zeppelin.notebook.Notebook$CronJob.execute(Notebook.java:885)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
- locked <0x00000000c0f4b800> (a java.lang.Object)
Found 1 deadlock.Notebook のスケジュール実行を行う 2 つの thread (DefaultQuartzScheduler_Worker-2, DefaultQuartzScheduler_Worker-4) 間で、以下の通りデッドロックが発生しているようでした。
- [
DefaultQuartzScheduler_Worker-2] Notebook のスケジュール実行の完了後に Interpreter の再起動を実施する。その際にMap<String, InterpreterSetting> interpreterSettingsのロックを取得する。 - [
DefaultQuartzScheduler_Worker-4] Notebook のスケジュール実行を開始する。その際に、対象のNoteインスタンスのロックを取得する。 - [
DefaultQuartzScheduler_Worker-2] Interpreter の再起動実施のため、実行中の Notebook を停止して、その Notebook のステータスをAbortへ変更して保存する。その際に、 前述 2. でロック取得済みのNoteインスタンスのロックを取得しようとしてロック取得待ちの状態となる。 - [
DefaultQuartzScheduler_Worker-4] Notebook の実行のために、それに紐づく Interpreter 情報を取得する際にMap<String, InterpreterSetting> interpreterSettingsのロックを取得しようとしてロック取得待ちの状態となる。 DefaultQuartzScheduler_Worker-2とDefaultQuartzScheduler_Worker-4の間で、デッドロックが発生する。
上記の通り、「 Interpreter の再起動」と「 Notebook の実行」でロック取得の順番が逆になっている(「 Interpreter の再起動」では interpreterSettings -> note の順番でロックが取得され、「 Notebook の実行」では note -> interpreterSettings の順番でロックが取得されている)ため、これら 2 つの処理が同じタイミングで実行されると、 Apache Zeppelin 内部の thread 間でデッドロックが発生する可能性があるようでした。
4-3. 対応
根本的な対応には Apache Zeppelin のソースコードの大規模な改修が必要になるため、 Apache Zeppelin の JIRA で当該事象を報告しつつ、社内で管理している Apache Zeppelin のソースコードに対しては、 Notebook スケジュール実行後に Interpreter を再起動する "auto-restart interpreter on cron execution" の機能(以下のスクリーンショットの赤枠の部分)を使用不可にするように改修して、 Apache Zeppelin を運用することにしました。


5. Apache Spark : Spark SQL Performance Issue
5-1. システム概要
社内用のデータ分析用アプリケーションとして OASIS というものを独自開発して運用しており、ユーザは、 OASIS 上で自由に Spark SQL を実行して Hadoop クラスタからデータを抽出・分析できるようになっています。この Hadoop クラスタは HDP-2.6.2.0 (2.6.2.0-205) で構築されており、 Apache Spark のバージョンは 2.1.1 です。
5-2. 発生事象
ユーザから「クエリの実行が完了しない」という問い合わせを受け、原因を調査することにしました。問題となっているクエリを分解・修正して検証し、最終的には、以下のような、パーティションキーを全て指定した単純なクエリの実行でも、 Spark driver program のプロセスで CPU 使用率が 100% となり、クエリの実行が完了しない状態となることがわかりました。
クエリ
select
max(log_hour)
from
event_log
where
log_date = '20181101'
and log_hour = '00'
and log_name = 'xxxx'カラム log_date, log_hour, log_name は全て event_log テーブルのパーティションキーであり、パーティションの数はおよそ 1,300 * 24 * 140 = 4,368,000 ほどになります。
5-3. 原因調査
Spark Web UI 上には実行 Job の情報が何も表示されておらず、 Job 実行前の driver program におけるクエリ解析・最適化の段階で処理が止まっているようでした。また、 driver program のログには何も情報が出力されていない状態でした (log level = INFO)。
「 driver program のどのスレッドで CPU 使用率が高いのか?」を、以下のようなコマンドを実行して調べることにしました。(以下の 13300 は driver program プロセスの PID 。)
$ top -H -n 1 -p 13300
top - 00:32:28 up 96 days, 10:08, 1 user, load average: 3.33, 3.44, 2.83
Tasks: 71 total, 4 running, 67 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.5%us, 0.1%sy, 0.0%ni, 99.3%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 8193180k total, 7893796k used, 299384k free, 186164k buffers
Swap: 4194300k total, 0k used, 4194300k free, 1460808k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
13329 oasis 20 0 7961m 4.2g 25m R 96.6 53.7 25:32.43 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13331 oasis 20 0 7961m 4.2g 25m R 94.7 53.7 25:33.44 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13330 oasis 20 0 7961m 4.2g 25m R 92.7 53.7 25:33.37 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13332 oasis 20 0 7961m 4.2g 25m R 92.7 53.7 25:34.44 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13341 oasis 20 0 7961m 4.2g 25m S 2.0 53.7 0:00.73 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13300 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.01 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13328 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:06.24 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13333 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:21.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13334 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.01 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13335 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.02 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13336 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13337 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:07.10 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13338 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:06.49 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13339 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:03.08 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13340 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13347 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13358 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13359 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.11 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13360 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.07 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13361 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.14 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13362 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.07 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13363 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.24 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13364 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13365 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13366 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13367 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13368 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13369 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13370 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13371 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13377 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.01 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13378 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
13379 oasis 20 0 7961m 4.2g 25m S 0.0 53.7 0:00.00 /usr/java/jdk/bin/java -Dhdp.version=2.6.2.0-205 -cp /etc/spark2/conf/:/usr/hdp/current/spark2-client/jars/*
```PID 13329, 13330, 13331, 13332 (0x3411, 0x3412, 0x3413, 0x3414) のスレッドで CPU 使用率が高くなっていることがわかりました。「これらがどのようなスレッドであるか?」を thread dump を取得して確認してみると、以下の通り、これらは全て GC task thread でした。
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x00007fe0a4024000 nid=0x3411 runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x00007fe0a4026000 nid=0x3412 runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x00007fe0a4028000 nid=0x3413 runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x00007fe0a4029800 nid=0x3414 runnable
次に、「 driver program のどのスレッドでメモリが大量に消費されているのか?」を heap dump を取得して Eclipse Memory Analyzer で確認してみると、以下の通り、 `Thread-62` というスレッドでメモリが大量に消費されていることがわかりました。

thread dump の `Thread-62` の内容は、以下の通りでした。
"Thread-62" #118 prio=5 os_prio=0 tid=0x00007fe024007800 nid=0x352c runnable [0x00007fdffdfe8000]
java.lang.Thread.State: RUNNABLE
at org.apache.thrift.protocol.TBinaryProtocol.readStringBody(TBinaryProtocol.java:378)
at org.apache.thrift.protocol.TBinaryProtocol.readString(TBinaryProtocol.java:372)
at org.apache.hadoop.hive.metastore.api.Partition$PartitionStandardScheme.read(Partition.java:1009)
at org.apache.hadoop.hive.metastore.api.Partition$PartitionStandardScheme.read(Partition.java:929)
at org.apache.hadoop.hive.metastore.api.Partition.read(Partition.java:821)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$get_partitions_result$get_partitions_resultStandardScheme.read(ThriftHiveMetastore.java:64423)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$get_partitions_result$get_partitions_resultStandardScheme.read(ThriftHiveMetastore.java:64402)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$get_partitions_result.read(ThriftHiveMetastore.java:64336)
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:88)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.recv_get_partitions(ThriftHiveMetastore.java:1994)
at org.apache.hadoop.hive.metastore.api.ThriftHiveMetastore$Client.get_partitions(ThriftHiveMetastore.java:1979)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.listPartitions(HiveMetaStoreClient.java:1050)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.invoke(RetryingMetaStoreClient.java:156)
at com.sun.proxy.$Proxy30.listPartitions(Unknown Source)
at org.apache.hadoop.hive.ql.metadata.Hive.getAllPartitionsOf(Hive.java:2096)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.sql.hive.client.Shim_v0_13.getAllPartitions(HiveShim.scala:477)
at org.apache.spark.sql.hive.client.HiveClientImpl$anonfun$getPartitions$1.apply(HiveClientImpl.scala:561)
at org.apache.spark.sql.hive.client.HiveClientImpl$anonfun$getPartitions$1.apply(HiveClientImpl.scala:558)
at org.apache.spark.sql.hive.client.HiveClientImpl$anonfun$withHiveState$1.apply(HiveClientImpl.scala:279)
at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:226)
at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:225)
- locked <0x000000071665acc0> (a org.apache.spark.sql.hive.client.IsolatedClientLoader)
at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:268)
at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitions(HiveClientImpl.scala:558)
at org.apache.spark.sql.hive.client.HiveClient$class.getPartitions(HiveClient.scala:188)
at org.apache.spark.sql.hive.client.HiveClientImpl.getPartitions(HiveClientImpl.scala:78)
at org.apache.spark.sql.hive.HiveExternalCatalog$anonfun$listPartitions$1.apply(HiveExternalCatalog.scala:995)
at org.apache.spark.sql.hive.HiveExternalCatalog$anonfun$listPartitions$1.apply(HiveExternalCatalog.scala:993)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:97)
- locked <0x0000000716868228> (a org.apache.spark.sql.hive.HiveExternalCatalog)
at org.apache.spark.sql.hive.HiveExternalCatalog.listPartitions(HiveExternalCatalog.scala:993)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.listPartitions(SessionCatalog.scala:797)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery$anonfun$org$apache$spark$sql$execution$OptimizeMetadataOnlyQuery$replaceTableScanWithPartitionMetadata$1.applyOrElse(OptimizeMetadataOnlyQuery.scala:105)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery$anonfun$org$apache$spark$sql$execution$OptimizeMetadataOnlyQuery$replaceTableScanWithPartitionMetadata$1.applyOrElse(OptimizeMetadataOnlyQuery.scala:95)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$2.apply(TreeNode.scala:268)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$2.apply(TreeNode.scala:268)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:267)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$transformDown$1.apply(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$transformDown$1.apply(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$4.apply(TreeNode.scala:307)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:188)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:305)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$transformDown$1.apply(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$transformDown$1.apply(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$4.apply(TreeNode.scala:307)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:188)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:305)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:273)
at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:257)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery.org$apache$spark$sql$execution$OptimizeMetadataOnlyQuery$replaceTableScanWithPartitionMetadata(OptimizeMetadataOnlyQuery.scala:95)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery$anonfun$apply$1.applyOrElse(OptimizeMetadataOnlyQuery.scala:68)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery$anonfun$apply$1.applyOrElse(OptimizeMetadataOnlyQuery.scala:49)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$2.apply(TreeNode.scala:268)
at org.apache.spark.sql.catalyst.trees.TreeNode$anonfun$2.apply(TreeNode.scala:268)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:267)
at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:257)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery.apply(OptimizeMetadataOnlyQuery.scala:49)
at org.apache.spark.sql.execution.OptimizeMetadataOnlyQuery.apply(OptimizeMetadataOnlyQuery.scala:40)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$anonfun$execute$1$anonfun$apply$1.apply(RuleExecutor.scala:85)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$anonfun$execute$1$anonfun$apply$1.apply(RuleExecutor.scala:82)
at scala.collection.IndexedSeqOptimized$class.foldl(IndexedSeqOptimized.scala:57)
at scala.collection.IndexedSeqOptimized$class.foldLeft(IndexedSeqOptimized.scala:66)
at scala.collection.mutable.WrappedArray.foldLeft(WrappedArray.scala:35)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$anonfun$execute$1.apply(RuleExecutor.scala:82)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$anonfun$execute$1.apply(RuleExecutor.scala:74)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:74)
at org.apache.spark.sql.execution.QueryExecution.optimizedPlan$lzycompute(QueryExecution.scala:78)
- locked <0x000000071de9cd78> (a org.apache.spark.sql.execution.QueryExecution)
at org.apache.spark.sql.execution.QueryExecution.optimizedPlan(QueryExecution.scala:78)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan$lzycompute(QueryExecution.scala:84)
- locked <0x000000071de9cd78> (a org.apache.spark.sql.execution.QueryExecution)
at org.apache.spark.sql.execution.QueryExecution.sparkPlan(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:89)
- locked <0x000000071de9cd78> (a org.apache.spark.sql.execution.QueryExecution)
at org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:89)
at org.apache.spark.sql.execution.QueryExecution$anonfun$simpleString$1.apply(QueryExecution.scala:218)
at org.apache.spark.sql.execution.QueryExecution$anonfun$simpleString$1.apply(QueryExecution.scala:218)
at org.apache.spark.sql.execution.QueryExecution.stringOrError(QueryExecution.scala:112)
at org.apache.spark.sql.execution.QueryExecution.simpleString(QueryExecution.scala:218)
at org.apache.spark.sql.execution.command.ExplainCommand.run(commands.scala:117)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:58)
- locked <0x000000071de9cef8> (a org.apache.spark.sql.execution.command.ExecutedCommandExec)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:56)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:74)
at org.apache.spark.sql.execution.SparkPlan$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$anonfun$execute$1.apply(SparkPlan.scala:117)
at org.apache.spark.sql.execution.SparkPlan$anonfun$executeQuery$1.apply(SparkPlan.scala:138)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:135)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:116)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:92)
- locked <0x000000071de9cfa0> (a org.apache.spark.sql.execution.QueryExecution)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:92)
at org.apache.spark.sql.Dataset.(Dataset.scala:185)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:64)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:600)
at com.linecorp.oasis.spark.SqlExecutor.run(SqlExecutor.java:54)
at java.lang.Thread.run(Thread.java:748)
内容を見てみると、このスレッドはクエリを解析・最適化する driver program のメイン処理が行われるもののようでした。この thread dump の内容の中でorg.apache.spark.sql.execution.OptimizeMetadataOnlyQueryというクラスが気になり、ソースコードを見てみると、以下のような記述がありました。
/**
* This rule optimizes the execution of queries that can be answered by looking only at
* partition-level metadata. This applies when all the columns scanned are partition columns, and
* the query has an aggregate operator that satisfies the following conditions:
* 1. aggregate expression is partition columns.
* e.g. SELECT col FROM tbl GROUP BY col.
* 2. aggregate function on partition columns with DISTINCT.
* e.g. SELECT col1, count(DISTINCT col2) FROM tbl GROUP BY col1.
* 3. aggregate function on partition columns which have same result w or w/o DISTINCT keyword.
* e.g. SELECT col1, Max(col2) FROM tbl GROUP BY col1.
*/
case class OptimizeMetadataOnlyQuery(
catalog: SessionCatalog,
conf: SQLConf) extends Rule[LogicalPlan] {
参照カラムが全てパーティションキーであり、かつ、前述の 1~3 のいずれかに合致する集計が実施されるクエリについては、実際のデータファイルへアクセスするのではなく、パーティションのメタデータのみを使ってクエリの検索結果を算出するような最適化が実施されるようでした。そして、このクラスのapply メソッドの処理を見ると、 Spark SQL の設定 spark.sql.optimizer.metadataOnly の値が true のときにこの最適化が実施されるようでした。Spark のドキュメント にもこの spark.sql.optimizer.metadataOnly の説明が記載されていましたが、この設定のデフォルト値が true のため、デフォルトの挙動ではこの最適化が実施されるようになっていました。
5-4. 問題解決
今回問題が発生したクエリの検索対象テーブルは、パーティション数が約 4,368,000 と多く、このような最適化が実施されると driver program において Hive Metastore からパーティション情報を取得する処理の負荷が高くなり、その結果、 driver program で GC が頻発してクエリの実行に時間がかかるようになっていました。
我々が扱っているテーブルには、今回のようにパーティション数が多いものがいくつかあるため、 OASIS で起動される Spark アプリケーションについては spark.sql.optimizer.metadataOnly=false を設定することで、今回の最適化が実施されないようにしました。
おわりに
今回のような、大規模分散環境に特有の障害(テスト環境で再現させることが難しい障害)に対しては、モニタリング、ソースコードリーディング、 thread dump/heap dump 解析、 OSS コミュニティへの働きかけ、などが重要になります。特に、 OSS コミュニティへの働きかけ・貢献に関しては、今後より一層積極的に行い、我々の経験・知見をフィードバックしていきたいと考えています。
明日は Ralph さんによる「LTOドライブを使ってみた」です。お楽しみに!