
みなさんこんにちは。私は2020年7月から10月まで行われたLINEのサマーインターンシップでLINE Speech Teamに参加した辛 徳泰 (シン トクタイ, Detai Xin) といいます。このインターンシップで私はクロスリンガル音声合成のためのdisentangledな話者・言語表現を獲得する方法をテーマにして、研究成果をトップカンファレンスに論文投稿することを目標に研究開発を行ってきました。私はその3か月間で開発・実験・論文執筆を行い、そこでの成果をまとめた論文[1]は音声処理のトップカンファレンスであるICASSP2021(IEEE International Conference on Acoustics, Speech and Signal Processing)に採択されました。
このブログでは、今回行った我々の研究について簡単に紹介したいと思います。
[1] Detai Xin et al., Disentangled speaker and language representations using mutual information minimization and domain adaptation for cross-lingual TTS, ICASSP2021
はじめに
テキスト音声合成(TTS)とは、音声技術の一種で、言語テキストを音声に変換する技術のことです。例えば、Siriのような音声アシスタントの音声は、TTSシステムによって合成されています。
クロスリンガル音声合成とは、ある話者の目的言語の音声をシステムに合成させるタスクのことをいいます。本研究では、英語のネイティブスピーカーと同じ話者性を持った日本語音声への合成およびその逆方向の合成を行いました。このタスクを音声翻訳システムに適用すると、原言語のネイティブスピーカーの声で目的言語の音声を生成することが可能となります。例えば、日本語のネイティブスピーカーの声で英語の音声を生成することができます。
このタスクの実現には、バイリンガルデータセットを使用してTTSモデルを学習するのが最も簡単です。しかし実際には、バイリンガル話者によるバイリンガル音声を学習データとして数多く取得する必要があるため、データ収集自体が非常に困難です。そのため多くの場合、半教師あり学習のテクニックを使用して、収集が容易なモノリンガル複数話者データセットだけからマルチリンガル複数話者TTSモデルを学習させます。一般にそのような複数の話者や言語の音声を合成するためのTTSモデルは、単一話者のTTSモデルであるTacotron2を音声特徴量から抽出された話者表現(話者の違いを表す特徴)と言語表現(言語の違いを表す特徴)を用いて条件付けすることで学習されます。そうした学習により、言語表現を目的言語の言語表現へと置き換えるだけで、任意の言語の音声を合成できます。つまりクロスリンガル音声合成を実現することができます。しかし実際には、言語表現を置き換えると、合成された音声において話者固有の特徴や自然さが変化し、また、その結果として性能の低下を招く可能性があります。これを我々は、話者表現と言語表現がentangleしている(もつれあっている)状態であるのが原因であると考え、問題に取り組みました。図1の上半分に示すように、entangledな言語表現には他の話者の情報が含まれているため、この表現を使用して他の話者のクロスリンガル音声を合成すると、話者固有の特徴が変化する可能性があります。
そこで本研究では、disentangledな(もつれのない)話者表現と言語表現を取得することを目指しました。

図1 : 提案手法のアイデア
提案手法
私たちは、ドメイン適応と相互情報量最小化のテクニックを利用してdisentangledな話者表現と言語表現を目指しました。図1の下半分に示すように、これら2つの手法を使用すると、提案手法によって抽出された言語表現に含まれる話者情報は比較的少なくなります。すなわち、言語表現を置き換えても、音声に含まれる話者のアイデンティティはほとんど影響を受けません。
次の図2に、提案手法における話者・言語表現抽出モジュールのアーキテクチャーを示します。
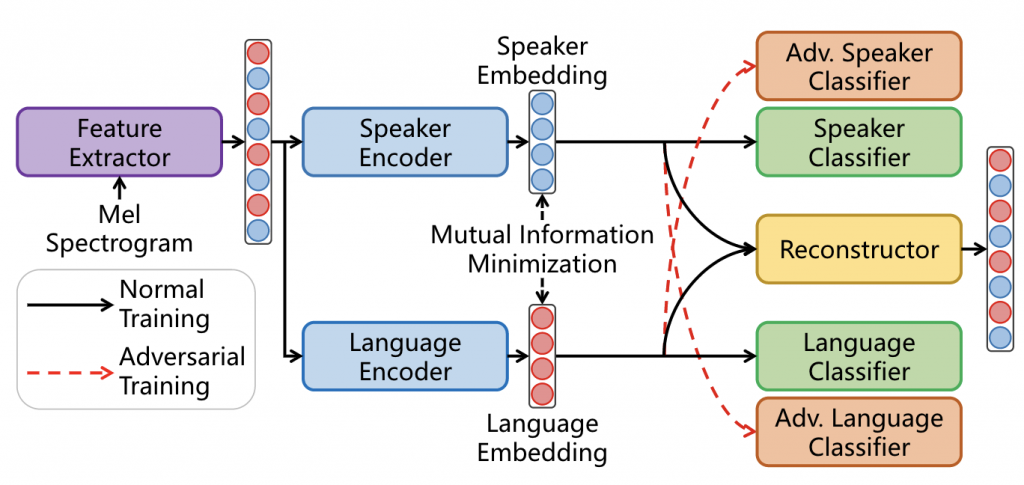
図2 : 提案した表現抽出モジュールの構成
私たちは、音声の特徴量であるメルスペクトログラムから固定長の特徴埋め込みを生成した後、話者エンコーダーと言語エンコーダーを使用して話者表現と言語表現をそれぞれ抽出しました。
ドメイン適応モジュールには、2つの通常の分類器と2つの敵対的分類器が含まれています。ここでは、話者分類器と敵対的言語分類器を例にとって説明します。話者分類器は、話者ラベルに基づいて話者表現を学習します。一方、敵対的言語分類器は、言語ラベルに基づいて話者表現を学習しますが、その際に敵対的分類器の勾配を反転させることで、話者表現が言語ラベルを分類できないようにします。つまり言語に関する情報を話者表現から取り除くことができます。同様に、言語分類器と敵対的話者分類器についても、話者に関する情報を言語表現から取り除くように学習を行いました。
さらに、話者表現と言語表現の間のentanglementをより強力に解消するため、相互情報量最小化を行いました。相互情報量(MI)とは、2つの確率変数の依存関係を情報量の観点で測定したものです。本研究では、対照的対数比上限(Contrastive Log-ratio Upper Bound: CLUB)を使用して、相互情報量の上限の近似と最小化を行いました。
最後に、entanglement解消の処理でそれぞれの情報が失われていないことを保証するため元の特徴量埋め込みの再構成も行いました。
実験結果
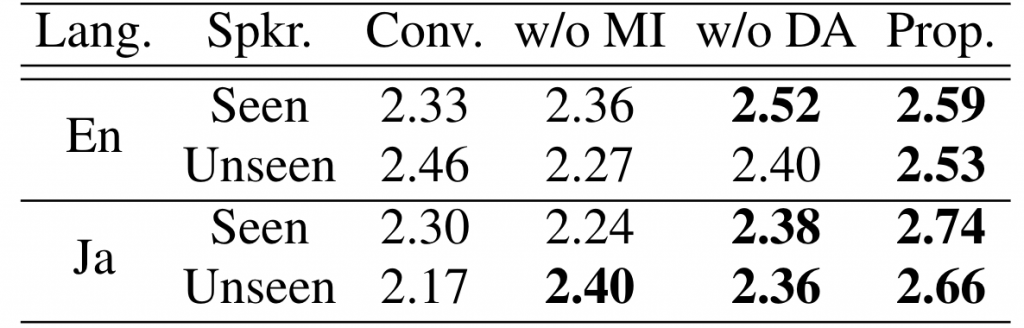
本研究では、英語のデータセットであるVCTK(日本語のページにリンク)と、日本語のデータセットであるJVSを使用して実験を行いました。この実験では、話者表現に対してドメイン適応のみを用いたモデルをベースラインモデル(表中の「従来手法」)として使用しました。ドメイン適応と相互情報量最小化を使用した提案手法(表中の「提案手法」)を学習させたものとは別に、ドメイン適応と相互情報量最小化の効果をそれぞれ評価するための実験として、ドメイン適応を使用せずに提案手法を学習させた場合(表中の「DAなしの提案手法」)および相互情報量最小化を使用せずに提案手法を学習させた場合(表中の「MIなしの提案手法」)についても実験を行いました。
本研究では、合成された音声を、自然さ、話者の類似性、話者の一貫性という3つの観点で評価しました。自然さについては、音声の流暢さを評価しました。話者の類似性については、合成された音声と真の音声との間で話者のアイデンティティを評価しました。話者の一貫性については、合成された同一言語音声とクロスリンガル音声の類似性の評価を評価者に依頼しました。その結果を表1~3に示します。これを見ると、すべての評価において提案モデル(表中の「提案手法」)がベースラインモデル(表中の「従来手法」)よりも優れていることが分かります。
表1 : 自然性に関するMOS評価の結果
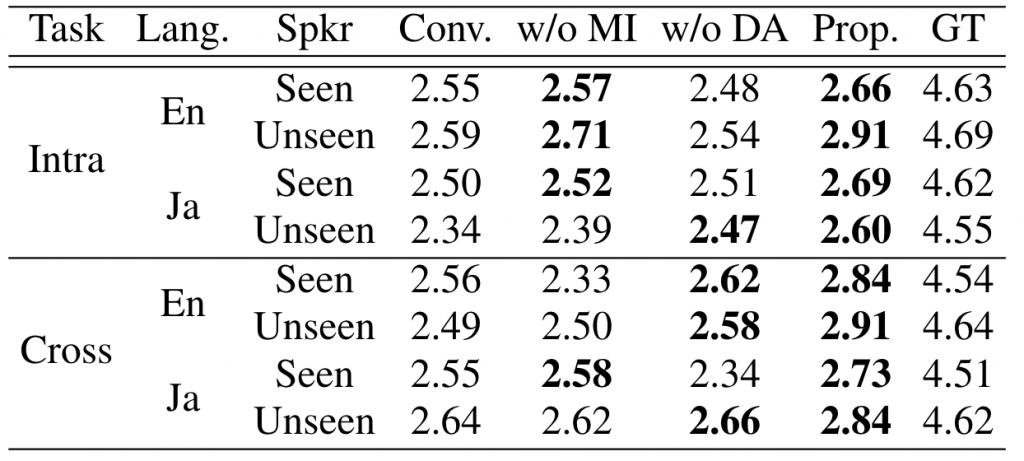
表2 : 話者類似度に関するXABテスト
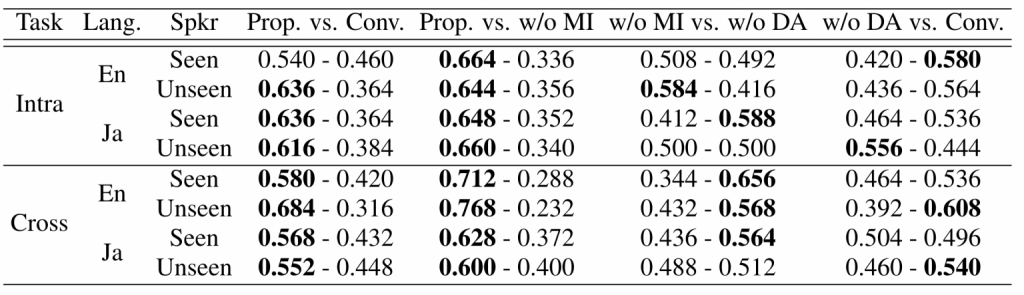
表3 : 同一/異言語間における話者性の一貫性に関するMOS評価の結果
インターンシップを振り返って
今回のインターンシップでは、非常にわくわくしながら自分のアイデアを仲間たちと議論して提案手法を実装でき、実験結果が出るのが非常に楽しみでした。コロナ禍のため、研究のほとんどの時間を家で費やさなければなりませんでしたが、仲間たちの思いやりと支えのおかげで、インターンシップが楽しく満足のいくものとなりました。