
(This is the 8th article of LINE Advent Calendar 2016)
Hello everyone, this is Neil Tu from Data Labs. I am in charge of Hadoop architecture at Line Corp. I construct and manage Hadoop clusters and their ecosystems, and supply a high availability, and high performance platform for the engineers and data analysts in our group.
Today, the topic we are going to talk about is "Comprehensive Security for Hadoop".
Abstract
Nowadays, Hadoop has become a popular platform for data storage, data analysis, reporting, and distributed calculations. Basically, Hadoop cluster is an open platform that supplies users with the required resources and HDFS capacity to execute queries. But as you know, Hadoop cluster comprises of many different componments with their own administration models, such as HDFS, Yarn, hive etc. It needs to access each componment to modify or edit access permissions. This is hard to manage, so a central management tool is necessary. Maybe it is better to name it 'Framework'. Currently, there are some united open source administration management frameworks. Ranger for Hortonworks, and Sentry for Cloudera. Beside this, Ambari, HDFS and Yarn all provide a UI to track the status of a job or the job history. Sometimes you don't want the information of a cluster to be seen by others, so you may need a tool which can do the user authentication for you. For this requirement, Knox can help you to achieve. You can regard Knox as a reverse proxy which provides a single REST API access point of authentication and access for Hadoop services.
Overlook

In our environment, LDAP works in tandem with Apache Ranger and Apache Knox. By intergrating these componments, we can easily supply a secured Hadoop platform.

In above picture, we could figure out where Ranger and Knox are located in the entire Hadoop ecosystem. Knox filers the http request like webhdfs, and Ranger administrates all the Hadoop accesses, not only HDFS reading or writing, but also YARN applications submition.
Ranger - HDFS Authentication
In general HDFS permission only contains a directory for user, group, and others. Only three kinds of catagories. It couldn't determin the specific permission for a designated user. We can handle this easily through Ranger.
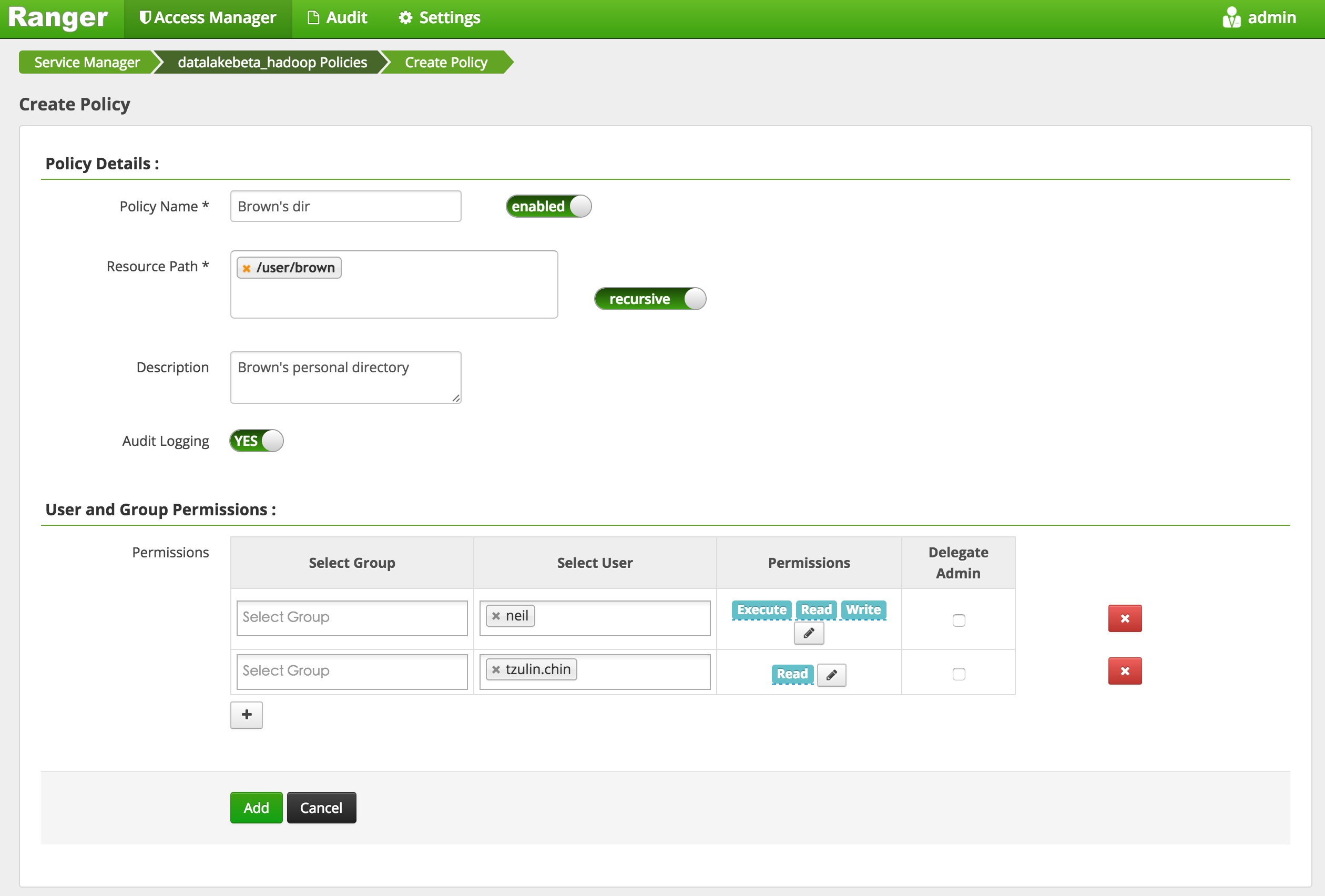
In the following picture, we grant 'neil' all permissions and 'tzulin.chin' read only for HDFS directory '/user/brown', and test the permission.
# sudo su - neil
[neil@{hostname} ~]$ hdfs dfs -mkdir /user/brown/test_create
[neil@{hostname} ~]$ hdfs dfs -ls /user/brown
Found 1 items
drwxr-xr-x - neil datalabs 0 2016-11-25 19:21 /user/brown/test_create
# sudo su - tzulin.chin
[tzulin.chin@{hostname} ~]$ hdfs dfs -mkdir /user/brown/test_create
mkdir: Permission denied: user=tzulin.chin, access=WRITE,
inode="/user/brown/test_create":brown:datalabs:drwxr-xr-x
In the above test, you can figure out that the user 'neil' could create a folder "test_create" by authorizing it's permission in Ranger. To use this method, we can grant the permission to specific users very simply.
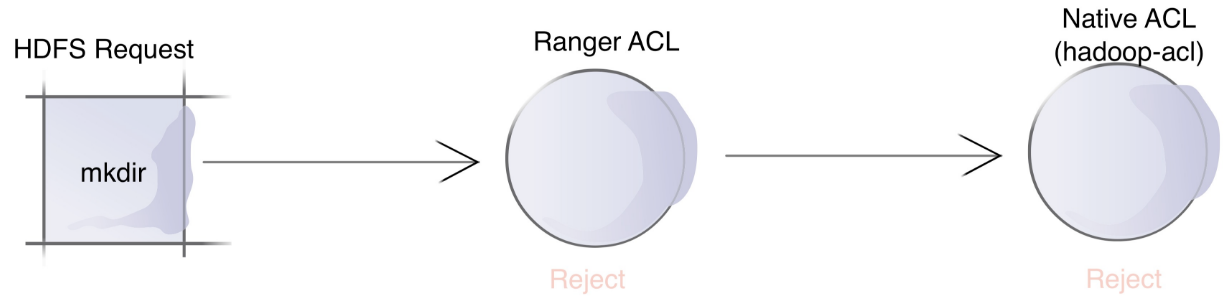
This HDFS authentication model was tricky to configure at the start. Ranger needs to cooperate HDFS permission. Let me use the following chart to illustrate it.
There are three use cases when a hadoop request is received.
- In the first case, the Ranger ACL accepts the request, and ignores the Native hadoop ACL. The request is accepted.

- In the second case, the Ranger ACL rejects the request, but the Native hadoop ACL accepts it. The request is accepted.

- In the third case, both the Ranger ACL and the Native hadoop ACL reject the request. The request is rejected.
In other words, we need to set the Native hadoop ACL as restricted as possible, and use the Ranger ACL to control the permission.For example:
- Case 1: Assume permission of /user/brown is 777 on hdfs, even we don't assign permission via Ranger.Any operation always be accepted by Native ACL.
- Case 2: Assume permission of /user/brown is 000 on hdfs, we assign permission via Ranger.Operation will be accepted by Ranger ACL.
- Case 3: Assume permission of /user/brown is 000 on hdfs, we don't assign permission via Ranger.
Operation will be rejected by Native ACL.
We MUST set native ACL reject all request. and set policy by Ranger.
Ranger - Yarn Authentication
From Ranger, we may just need to add the user account and grant it to the accurate permissions. There is no need to modify capacity-scheduler.xml.
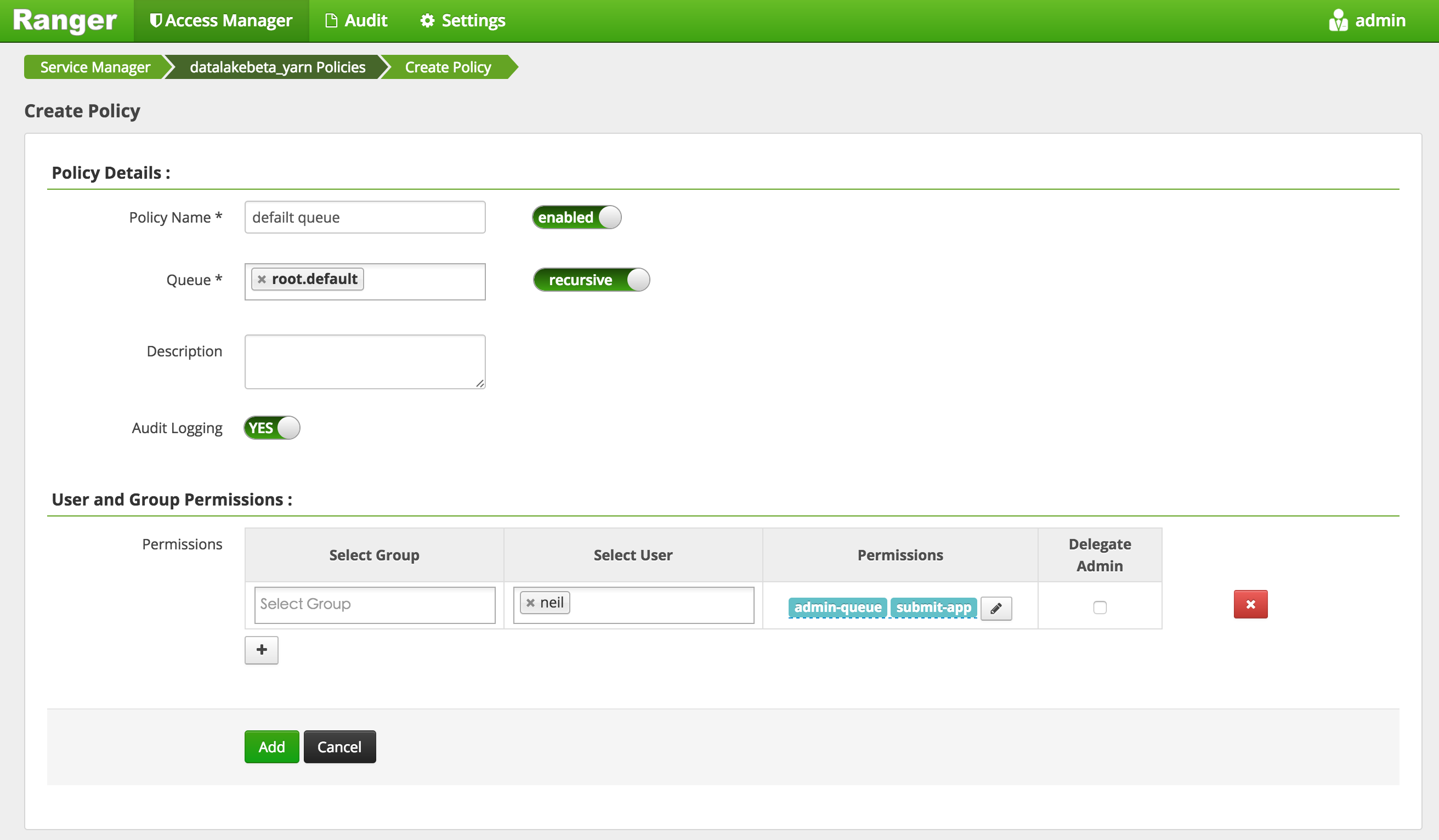
Here, we grant user 'neil' the app submission permission, and use 'neil' and 'tzulin.chin' to access the spark-shell.
[neil@{hostname} ~]$ /usr/hdp/current/spark-client/bin/spark-shell
--master=yarn-client --queue=default
..
16/11/25 17:07:31 INFO SessionState: Created local directory: /tmp/17494525-caca-4dfa-
a0ce-58d02bf87580_resources
16/11/25 17:07:31 INFO SessionState: Created HDFS directory: /tmp/hive/neil/17494525-c
aca-4dfa-a0ce-58d02bf87580
16/11/25 17:07:31 INFO SessionState: Created local directory: /tmp/neil/17494525-caca-
4dfa-a0ce-58d02bf87580
16/11/25 17:07:31 INFO SessionState: Created HDFS directory: /tmp/hive/neil/17494525-c
aca-4dfa-a0ce-58d02bf87580/_tmp_space.db
16/11/25 17:07:31 INFO SparkILoop: Created sql context (with Hive support)..
SQL context available as sqlContext.
scala>
[tzulin.chin@{hostname} ~]$ /usr/hdp/current/spark-client/bin/spark-shell --master=yar
n-client --queue=presto
..
org.apache.hadoop.yarn.exceptions.YarnException: Failed to submit application_14690011
83802_0009 to YARN : org.apache.hadoop.security.AccessControlException: User tzulin.ch
in cannot submit applications to queue root.default
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.submitApplication(Yar
nClientImpl.java:271)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:148)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnCli
entSchedulerBackend.scala:56)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:
144)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:530)
at org.apache.spark.repl.SparkILoop.createSparkContext(SparkILoop.scala:1017)
at $iwC$iwC.<init>(<console>:15)
at $iwC.<init>(<console>:24)
at <init>(<console>:26)
at .<init>(<console>:30)
at .<clinit>(<console>)
at .<init>(<console>:7)
at .<clinit>(<console>)
at $print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:6
2)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImp
l.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:1065)
at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:1346)
at org.apache.spark.repl.SparkIMain.loadAndRunReq$1(SparkIMain.scala:840)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:871)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:819)
at org.apache.spark.repl.SparkILoop.reallyInterpret$1(SparkILoop.scala:857)
at org.apache.spark.repl.SparkILoop.interpretStartingWith(SparkILoop.scala:902
)
at org.apache.spark.repl.SparkILoop.command(SparkILoop.scala:814)
at org.apache.spark.repl.SparkILoopInit$anonfun$initializeSpark$1.apply(Spark
ILoopInit.scala:125)
at org.apache.spark.repl.SparkILoopInit$anonfun$initializeSpark$1.apply(Spark
ILoopInit.scala:124)
at org.apache.spark.repl.SparkIMain.beQuietDuring(SparkIMain.scala:324)
at org.apache.spark.repl.SparkILoopInit$class.initializeSpark(SparkILoopInit.s
cala:124)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:64)
at org.apache.spark.repl.SparkILoop$anonfun$org$apache$spark$repl$SparkILoop$
$process$1$anonfun$apply$mcZ$sp$5.apply$mcV$sp(SparkILoop.scala:974)
at org.apache.spark.repl.SparkILoopInit$class.runThunks(SparkILoopInit.scala:1
59)
at org.apache.spark.repl.SparkILoop.runThunks(SparkILoop.scala:64)
at org.apache.spark.repl.SparkILoopInit$class.postInitialization(SparkILoopIni
t.scala:108)
at org.apache.spark.repl.SparkILoop.postInitialization(SparkILoop.scala:64)
at org.apache.spark.repl.SparkILoop$anonfun$org$apache$spark$repl$SparkILoop$
$process$1.apply$mcZ$sp(SparkILoop.scala:991)
at org.apache.spark.repl.SparkILoop$anonfun$org$apache$spark$repl$SparkILoop$
$process$1.apply(SparkILoop.scala:945)
at org.apache.spark.repl.SparkILoop$anonfun$org$apache$spark$repl$SparkILoop$
$process$1.apply(SparkILoop.scala:945)
at scala.tools.nsc.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader
.scala:135)
at org.apache.spark.repl.SparkILoop.org$apache$spark$repl$SparkILoop$process(
SparkILoop.scala:945)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:1059)
at org.apache.spark.repl.Main$.main(Main.scala:31)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:6
2)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImp
l.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$r
unMain(SparkSubmit.scala:731)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:181)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:206)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:121)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
As you can see, user 'tzulin.chin' couldn't access spark-shell. This is because Application Master was started by 'tzulin.chin', and 'tzulin.chin' is not allowed to use this queue. So we may use this method to manage the resource of Yarn.
Ranger - Knox Authentication
It is very dangerous to reveal your webhdfs address, other people can access your cluster easily. If using Knox, user access is managed.

Request URL:
- Cluster: http://{webhdfs-host}:50070/webhdfs
- Knox Gateway: https://{gateway_host}:{gateway_port}/gateway/{TopologyName}/webhdfs
[neil@{hostname} ~]$ curl -iv -k -u neil:{password}
https://{hostname}:8443/gateway/datalabs/webhdfs/v1/?op=LISTSTATUS
* About to connect() to {hostname} port 8443 (#0)
* Trying xxx.xxx.xxx.xxx... connected
* Connected to {hostname} (xxx.xxx.xxx.xxx) port 8443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* warning: ignoring value of ssl.verifyhost
* skipping SSL peer certificate verification
* SSL connection using TLS_DHE_RSA_WITH_AES_256_CBC_SHA
* Server certificate:
* subject: CN={hostname},OU=Test,O=Hadoop,L=Test,ST=Test,C=US
* start date: Nov 25 10:06:33 2016 GMT
* expire date: Nov 25 10:06:33 2017 GMT
* common name: {hostname}
* issuer: CN={hostname},OU=Test,O=Hadoop,L=Test,ST=Test,C=US
* Server auth using Basic with user 'neil'
> GET /gateway/datalabs/webhdfs/v1/?op=LISTSTATUS HTTP/1.1
> Authorization: Basic xxxxxxxxxxxxxxxxx==
> User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic EC
C zlib/1.2.3 libidn/1.18 libssh2/1.4.2
> Host: {hostname}:8443
> Accept: */*
>
< HTTP/1.1 200 OK
HTTP/1.1 200 OK
[neil@{hostname} ~]$ curl -iv -k -u tzulin.chin:{password}
https://{hostname}:8443/gateway/datalabs/webhdfs/v1/?op=LISTSTATUS
About to connect() to {hostname} port 8443 (#0)
* Trying xxx.xxx.xxx.xxx... connected
* Connected to {hostname} (xxx.xxx.xxx.xxx) port 8443 (#0)
* Initializing NSS with certpath: sql:/etc/pki/nssdb
* warning: ignoring value of ssl.verifyhost
* skipping SSL peer certificate verification
* SSL connection using TLS_DHE_RSA_WITH_AES_256_CBC_SHA
* Server certificate:
* subject: CN={hostname},OU=Test,O=Hadoop,L=Test,ST=Test,C=US
* start date: Nov 25 10:06:33 2016 GMT
* expire date: Nov 25 10:06:33 2017 GMT
* common name: {hostname}
* issuer: CN={hostname},OU=Test,O=Hadoop,L=Test,ST=Test,C=US
* Server auth using Basic with user 'tzulin.chin'
> GET /gateway/datalabs/webhdfs/v1/?op=LISTSTATUS HTTP/1.1
> Authorization: Basic xxxxxxxxxxxxxxxxx==
> User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.19.1 Basic EC
C zlib/1.2.3 libidn/1.18 libssh2/1.4.2
> Host: {hostname}:8443
> Accept: */*
>
< HTTP/1.1 403 Forbidden
HTTP/1.1 403 Forbidden
As the examples shown above, if user permission is not granted, it is not allowed to access.
Conclusion
Today, I only shared how Ranger and Knox are used to manage access permissions. Neither are difficult to setup and configure, so I suggest you give them a try yourself! Integrating Ranger and Knox with LDAP is a very convenient way to adminstrate your Hadoop cluster. You do not need to access the administration environment of each component, and you can also audit their logs and usage history. Furthermore, you can quickly search those recorded logs from Slor. All these functions reduce the administrator's burden a lot.
If you are intertested in big data or data analysis, no matter whether you are a data analyst or big data experienced engineer, please feel free to contact Data Labs with any questions you may have, or if you are interested in working with us.
Next up is an article "Implementation of HBase Cross Row, Cross Table transaction process." from Zhao tomorrow.