
AI開発室のTrustworthy AIチームに所属している綿岡です。普段の業務は言語モデルの信頼性向上のための技術開発で、特に有害文検知に関する技術開発に注力しています。昨今の言語モデルの急速な発展に伴い、有害文検知の技術も急成長しており、Perspective API(有害文を検知するAPI)を提供するJigsawは有害文検知コンペティションを2018年から毎年開催しています。一方、我々Trustworthy AIチームは、日本語での有害文検知モデルの構築は今後最重要課題となるだろうと常々考えてきました。そのことから有害文検知の最先端に挑戦するとともに知見を深めることを目的として、2021年11月からKaggleで開催された「Jigsaw Rate Severity of Toxic Comments」にTrustworthy AIチームから綿岡が参加することにしました。最終結果を先に記載しておきますと、2,301チーム中147位で銅メダルを獲得しました。このブログでは、
本コンペの概要及び出場にあたって取り組んだ内容について報告します。
ルール
本コンペの目的
本コンペの目的は「文章の有害性をスコアリングできるモデルを構築すること」です。
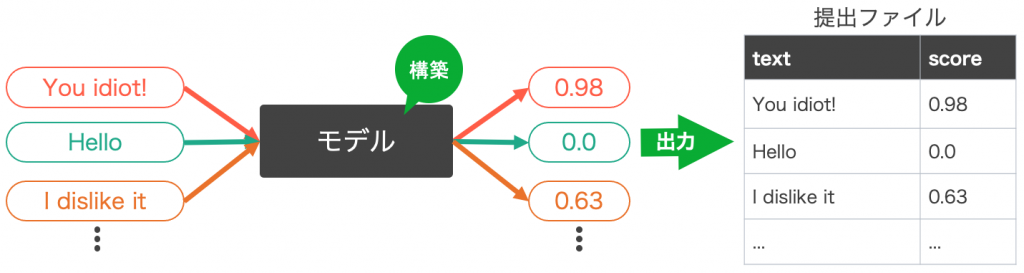
参加者は上図の通り、テキストに対してスコアを出力するモデルを構築します。それにより作成される提出ファイルは以下の手順でKaggleサーバー上で評価されます。
- 提出ファイルの所定のテキスト同士がペア化され、スコアの大小関係に基づきless_toxicとmore_toxicの列に振り分け
- あらかじめ人間により作成された正解データと比較され一致度を計算
もちろん参加者はペアの組み合わせを知ることができません。そのため、あらゆるテキスト同士のスコアの大小関係を正確に付与する必要があるというわけです。

提供データセット
本コンペでは、訓練用のデータセットは提供されておらず、以下の3つのデータが提供されています。
- 最終スコア用のテキストリスト
- 提出ファイルのサンプル
- validation用のペアデータセット(以下、validation_data.csv)
validation_data.csvは下の画像のように評価時に使用される正解データと同じ形式のデータとなっています。
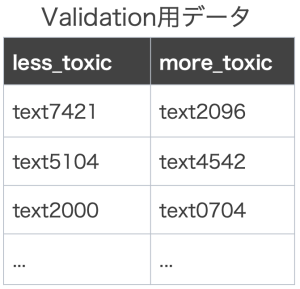
validation_data.csvはvalidationのために提供されたデータですが、コンペが始まると多くの参加者はそれを訓練データとして使用しました(ルール違反ではない)。このようなペア形式のデータでモデルを学習する際、以下のMarginRankingLossが広く使われました。後述する私の手法の中でもこの学習方法を用いたのですが、このようなデータ形式と学習形式があるという事実は本コンペに出場して得られた大きな知見の一つでした。
$$ L(x_{1},x_{2})=max(0,f(x_{1})−f(x_{2})+λ) $$
本タスクでは、$$ x_{1},x_{2} $$がそれぞれless_toxic, more_toxicの文、$$ f $$が有害文スコアリングモデルにあたる。
私の手法概要
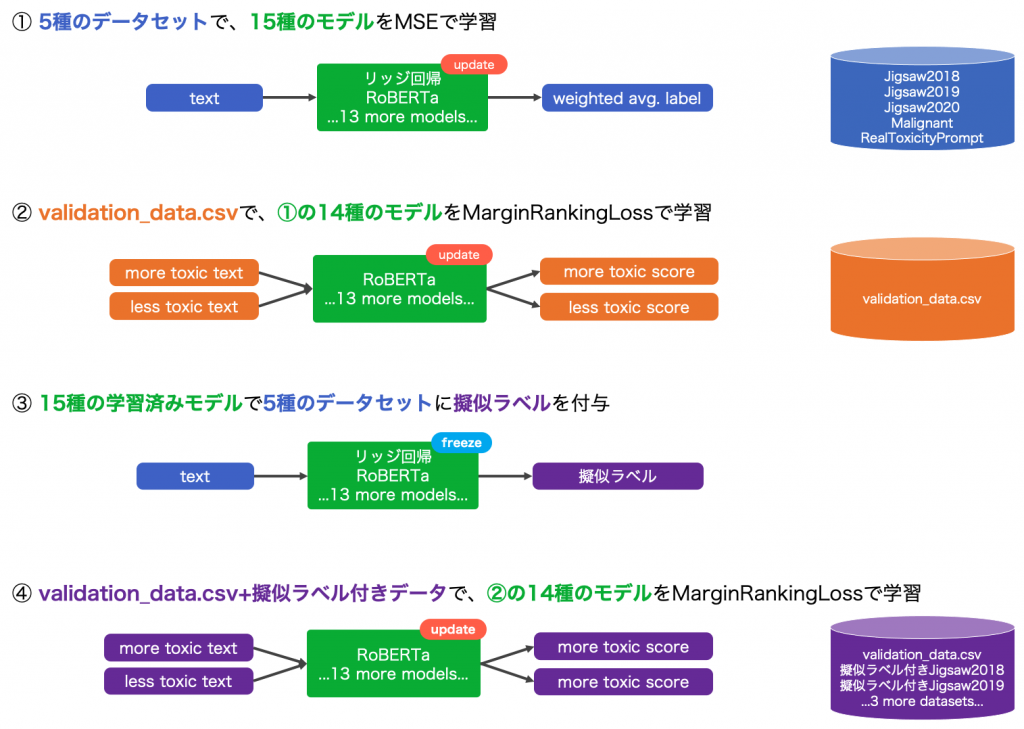
私の手法の概要を下の画像にまとめました。最終提出用モデルを構築するまで4つの工程に分かれています。初めに、5種のデータセットで15種のモデルを学習します。さらに、validation_data.csvを用いてfine-tuningを行います。学習済みモデルのアンサンブルでテキストに擬似ラベルを付与します。そのデータを用いてもう一度fine-tuningを行いました。
結果
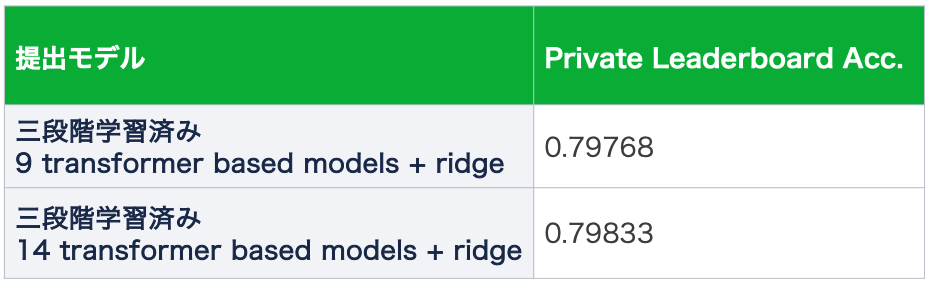
最終結果は2,301チーム中147位で銅メダルを獲得しました。最終順位を決定するPrivate Leaderboard Accuracyでは0.798程度でした。1位が0.814程度ですので、1.6%程度の差となりました。
最終提出モデルまでの道のり
データセット選定
英語には多くの有害性スコア付きデータセットが存在します。その中から、データセット毎のテキストの重複度合いやアノテーターの質や多様性などを考慮し、以下の5つのデータセットを採用しました。
- Jigsaw Toxic Comment Classification
- Jigsaw Unintented Bias in Toxicity Classification
- Jigsaw MultiLingual Toxic Comment Classification
- Malignant Comment Classification
- Real Toxicity Prompts
モデル選定
学習するモデルは多様であればあるほど良いだろうという考えのもと、できるだけ多くのモデルで実験しました。結果、最終的には以下の15種類のモデルを使用しました。
- リッジ回帰
- RoBERTa base
- DeBERTa base
- XLNet base
- GPT2
- mDeBERTa v3
- Toxic BERT
- DistilBERT base
- DistilGPT2 base
- DistilRoBERTa base
- ALBERT large v2
- Facebook BART base
- Funnel Transformer large
- Google Electra base
- HateBERT
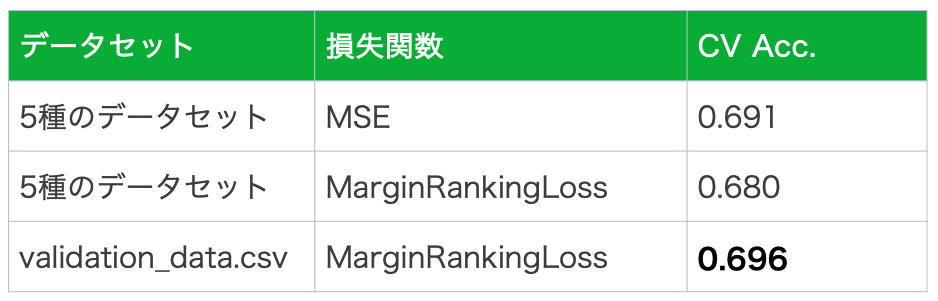
比較実験その1:MSE vs. MarginRankingLoss
MarginRankingLossの有用性を確かめるべく、平均二乗和誤差(以下、MSE)で学習した場合とMarginRankingLossで学習した場合を比較しました。結果、下の表の通りMSEで学習した場合の方がcross validation accuracy(以下、CV Acc.)が良かったことがわかりました。しかし、1%程度の差異なので、MarginRankingLossも使い物にはなるレベルだと捉えることもできます。

比較実験その2:5種のデータセット vs. validation_data.csv
採用した5種のデータセットはvalidation_data.csvよりサンプル数が多いのですが、validation_data.csvはアノテーションの形式が最終評価と同じであることから有用だとも考えられます。どちらの方がより良い学習ができるのかを確かめるべく、それぞれのデータで比較実験を行いました。結果、下の表の通りvalidation_data.csvで学習した場合が最も良いCV Acc.でした。
二段階での学習
上記の二つの比較実験結果から次のような仮説を立てました。
- 最終的にはvalidation_data.csvでドメインにフィットさせた学習をすることが重要
- しかし、先に大規模なデータセットで学習させてからドメインにフィットさせた方が良いのではないか?
そのことから5種のデータセット→validation_data.csvという二段階での学習を行いました。結果、下の表の通り、全てのモデルでCV Acc.の向上が見られました。ただし、時間の都合上で一部のモデルは実験を行えていません。
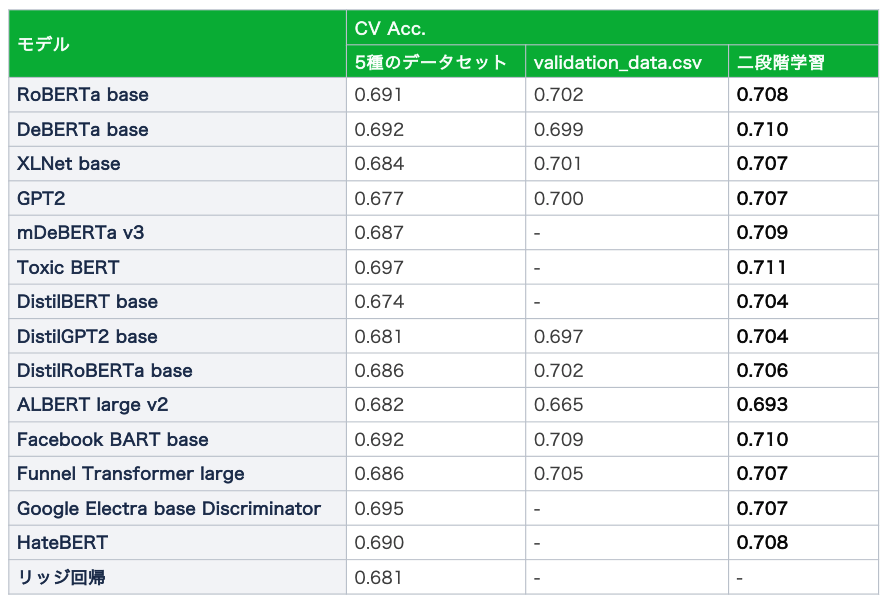
これが手法概要で記載した①と②にあたります。


モデルアンサンブル
二段階で学習したモデルをNelder-Mead法を用いてアンサンブルしました。結果、下の表の通り、CV Acc.が0.769となり単体モデルに対して約6.3%程度の向上が見られました。

擬似ラベルを用いたfine-tuning
これまでで構築したアンサンブルモデルで最終提出しようかと考えていたのですが、ここで次のような仮説が思い浮かびました。
- これまでで構築したアンサンブルモデルは本コンペのドメインにフィットした高品質なスコアリングができるはず
- この予測値を擬似ラベルとして利用するとCV Acc.が向上するのではないだろうか?
そのことから以下のような実験を行いました。
- 外部データに対して学習済みアンサンブルモデルで予測値を付与
- validation_data.csv + 擬似ラベル付きデータでfine-tuning
- ただし、擬似ラベル付きデータから算出される損失値には0.01をかけて線形結合(0.01は0.001, 0.01, 0.1, 1.0を試した結果)
結果、下の表の通り、擬似ラベル付きデータで学習した場合(表中の三段階学習)、ほとんどのモデルで最も良いCV Acc.を記録しました。ただし、時間の都合上で一部のモデルは実験を行えていません。また、5種のデータセットの以外の新規テキストに擬似ラベルを付与することやそもそも5種のデータセットに付与されている値を使用した場合など試せていないことはたくさんあります。
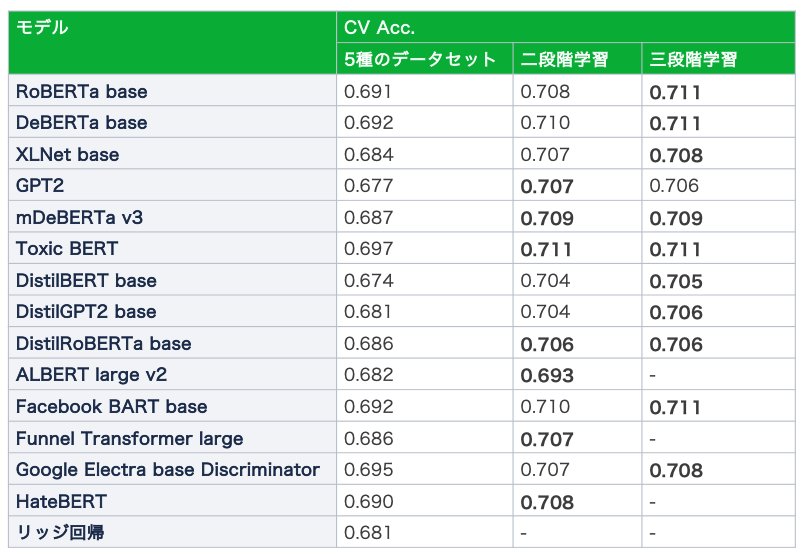
これが手法概要で記載した③と④にあたります。


再びアンサンブル
三段階で学習したモデルをNelder-Mead法を用いてアンサンブルしました。結果、下の表の通り、CV Acc.が0.774となり二段階で学習したモデルに比べて0.5%程度の向上が見られました。

私が最終提出したものはこの三段階学習を終えたアンサンブルモデルになります。また、Kaggleでは最終提出に2つのファイルを選択することができます。私は14種のtransformerベースモデルを9種に絞ってアンサンブルしたものも提出しました。9種に絞った理由としては、RoBERTaとDistil RoBERTaなどアーキテクチャが近いものをどちらかだけに残すことで、アーキテクチャの多様性を保ちつつ、CV最適化の探索空間を減らせるのではないかと考えたからです。結果、14種の場合と予測値は異なるが同じCV Acc.となったため、その予測ファイルを提出することとしました。
おわりに
本コンペに出場したことで、ペアで有害性を比較するデータ形式や安定して良い性能を発揮したDeBERTaなど、様々な知見を得ることができました。また個人的には、仮説と検証を素早く回す能力や効率的なMLOpsの構築能力など、今後の全ての業務に通ずる能力を高速に成長することができたと感じています。この経験をもとに、今後のLINEのサービスにおいてユーザーが有害文から守られるよう全力を尽くしたいと思います。
LINEのTrustworthy AIチームでは、言語モデルをはじめとするAIの信頼性を担保するための技術開発を今後も続けてまいります。本トピックに情熱を持って一緒に取り組んでいただける仲間を募集中です。
中途採用については以下をご参照ください。
https://linecorp.com/ja/career/position/3235
インターンシップも募集しています。2022年開催のインターンシップは4月中旬よりエントリー開始予定ですので、関心のある方は以下ページより公式アカウントにご登録ください。
https://linecorp.com/ja/career/newgrads/internship/