
This is the 20th post of LINE Advent Calendar 2018.
My name is Kang Yu, Senior Software Engineer of LINE Core Message Storage Team. Today I will talk about the experiences about using Kafka Streams (KStreams).
1. Requirements
We are creating a real-time monitoring system, to monitor the whole traffic from internal and external users on LINE Core Messaging System related storages, and aim to find problems of Storage usages. Furthermore want it to be an infrastructure to help doing auto profiling, capacity planning for Store Platform.
It's the first time to apply Kafka Streams on a project to do complex processing on the very high QPS topic. And because of the open source, have to investigate and fix against when problems come.
Actually, Alibaba already done such of thing before: 2017 11/11 Core Tech Decryption – Ali Database entering second level whole traffic monitoring era
The idea would be same, but won’t be that complex as it as initial version. So we use Kafka Streams:
- Do monitoring by watching the stream, won’t block existing services
- NRT (Near Real Time) level monitoring, to find abusing actions on storage.
Why Kafka-Streams?
- For simple: it’s just a more high level wrapping of consumers on top of Kafka cluster ifself. We already have a strong Kafka cluster, so just use it
- Support DSL and LowLevel Processor at the same time.
- Support aggregations on different TimeWindows
- Support local state store based on rocksdb. And support distributed recovery by using changelog.
- Internal partition assign mechanism, will re-assign failed StreamTask to other node automatically.
System Requirements:
- Count different actions for all users indifferent time windows. Find abnormal actions on storages.
- Support tens millions QPS processing speed on LINE user scale.
What the users to be monitored?
- All LINE accounts, all internal users that use our core storages, all internal services, etc...
How to do it?
- Consuming existing user action logs from Kafka Cluster (called IMF internally)
- Replicate the Database logs to Kafka, then send to this monitor, it will handle to analysis metrics of different store server, region, row, column, Store Client, IP, etc...
- Cascade data from different time window, reuse intermedia results
- For short time window (less than 1 hour): use on heap hash map to handle the bursting and duplication
- For long time window (over/equals 1 hour): use KStreams – local state store (rocksdb)
- Make the components of counting, distributing and monitor rule processing separated.
2. Overview of the Architecture

If we see the internal of one process, would be like:
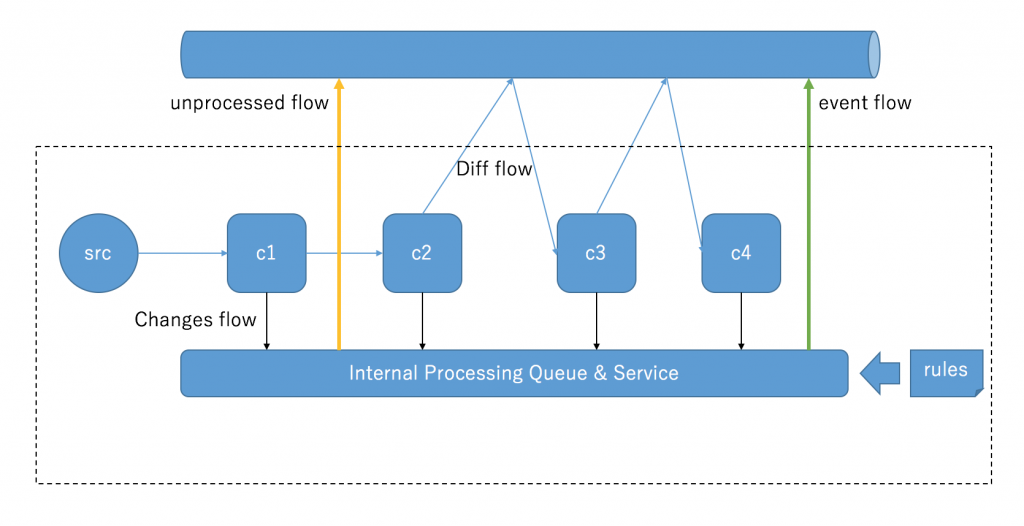
C is a counter component for general purpose. And I also hope that it can be composited as will. So a counter component will be like this:
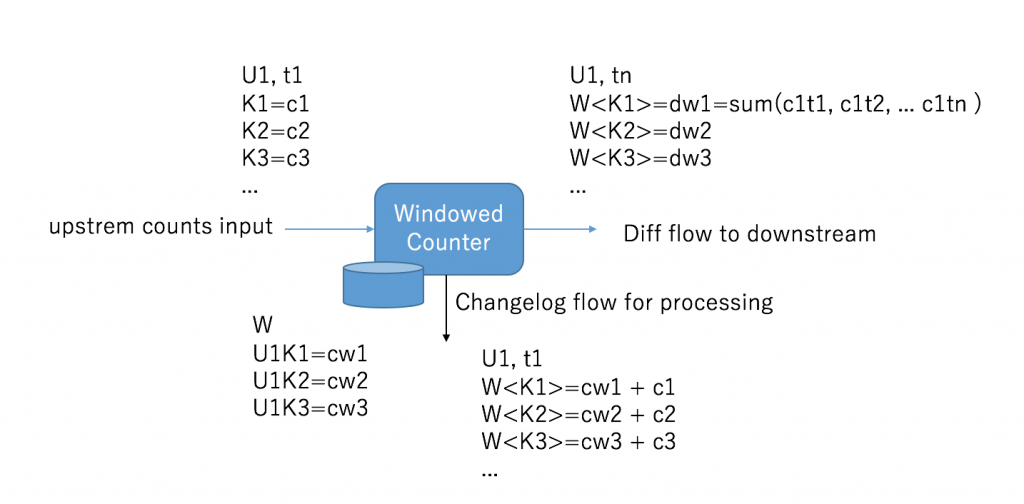
In each Counter:
- upstream: is a aggregated result on different ID at time: t1, from previous calculations (or from Kafka source). You can take is as a Diff results from previous counter in its time window W’
- downstream: is also an aggregated results in current Counter, it aggregated by ID and CountKey in time window W, but the result timestamp is tn. It equals to the sum of each ID-CountKey in the time range of t1 to tn.
- changelog flow: the latest value of aggregation for current counter in current time window W. So the latest value can give to rule processing component. And downstream diff flow will send to next counter to larger time window aggregation.
The basic design of the Counter Component is completed. Through different configuration of data source, different time windows, different data flush intervals, different storage media. This design can process different requirements of statistics. But we met some problems of using KStreams.
The problems:
- High QPS consuming
- How to achieve that WindowedCounter using DSL
- Storage efficiency
- Memory efficiency
- The performance problem and bug of Kafka Streams
- Have to tune rocksdb
- The extra load of Kafka cluster administration
3. High QPS Consuming
- Tens of millions of QPS
- IO makes processing super slow when processing large time window aggregation.
How to handle it?
- Scale Up: stronger CPU, more MEM; fast disk: SSD, fusionIO, NVMe, Intel AEP
- Scale Out: one Kafka partition can only be consumed by one consumer. If source topic’s partition number is not that high, one consumer cannot handle that level of QPS.
- Optimize from Business level: reduce QPS from business level. Make data more aggregated on buffering level. And do batch flushing to next calculator, to make more in-memory processing than processing on IO storage.
- Optimize from technical level: when the scale became large, more waste means cannot hold more. So have to considering more on profiling on memory efficiency, storage efficiency. And also have to improve the processing logic with the best effort.
Then look back to the design of WindowedCounter, See above picture again, Diff flow won’t be flushed to downstream for each message come from upstream input. It will wait for aggregation for a small interval (tn – t1). Then wait to flush till tntime. If many duplicated ID-CountKeys, the QPS of downstream will be far less than upstream’s.
The Diff flow won’t wait for a full time window gap to flush the aggregated results. Because the process duration of flushing will be very long, which makes the a larger pressure to downstream. This pressure also will be passed to Kafka cluster. If ALL the aggregation is in memory, would make OOM problem as concequent. If ALL in the data base, would cause many page cache miss, block cache miss, index cache miss.
How to achieve that WindowedCounter using DSL
I think current Kafka Streams cannot support WindowedCounter well. I’ve design many versions of it. Walking through all the versions between 1.1.1 and 2.0.0 of Kafka Streams, you cannot find a very suitable solution by using pure DSL.
You can use Transformer to make it happen, but the performance is not that controllable. Also you can use LowLevel Processor, but you will find it hard to make more generic.
Take a look at the graph below, the diff flow is hard, KStreams won’t support diff originally. You cannot simply using existing operations like map, groupBy, reduce to achieve it. But the counters cannot connect with each other without diff flow.
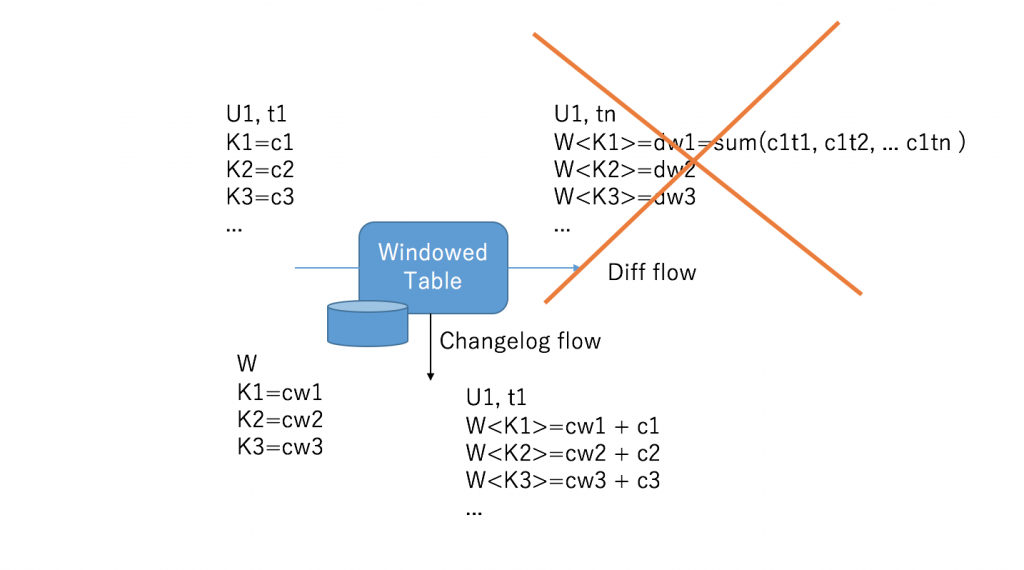
Or make each WindowedCounter consuming from source topic directly?
- I think it’s possible but has some QPS limitations.
For a normal rocksdb instance, the traditional supported QPS is about 15000. The original reduce operation of KStreams will read 1 time, write 1 time for each message. By ignoring the fact of read is slower than write, the highest performance of reduce is 7500 QPS. If want to count 3 different windows’ counters in one machine, the QPS have to be divided by 3, then you can see the max QPS of a server is 2.5K QPS. Then for example you will have 50 millions QPS with 100 partitions, each partition QPS is about 500K. Which is 200 times of a machine's upper limit. If you extend the partitions to 20000, you need 20000 servers with rocksdb!
So use in-memory calculation first then aggregate them by cascading, is better!
Then continue to implement WindowedCounter with DSL.
You will find it has to use a Transformer. Here’s the brief pseudocode:
changeLogStream = input.map(...)
.groupByKey()
.windowedBy(W)
.reduce(Reducer)
.toStream()
changeLogStream.forEach(ProcessNewCount)
diffOutPutStream = changeLogStream
.transform(DiffBufferingTransformerSupplier,
customStoreNames);- The reduce function of KStreams will return KTable. KTable.toStream() will return a changelog stream. But it isn’t a diff flow. So cannot be easily processed by downstream counter.
- Transformer can achieve diff flow: record current changelog and last changelog, then you can generate diff by subtract them. But this requires extra local state store.
The problem of using Pure DSL
- Many times of IO: internal implementation of reduce is KStreamReduceProcessor, for each KV, will read 1 time, write time local store; And in Transformer will read and write 1 times again.
- Cannot reduce QPS: default process of reduce won’t do caching and batching for downstream. Each the message come will generate a new message to downstream, so the QPS won’t be reduced. So can we use some scheduling flush?
- There is no default InMemory version of local state store: KStreams only allow to use CachingWindowStore by overlapping on RocksDBWindowStore. So if allow some data lost, whether can make a InMemoryWindowedStore? Or can we use CachingEnabled directly?
Some attempt and related problems
- I tried to write a Processor. But find it hard to make generic, because it needs to give explicit topic for each Processor. It lacks of tools to make auto generate topology.
- Cannot make a special Reducer, to call reduce(Reducer, storeNames), because the reduce core logic cannot be changed. To avoid changing source code too much, then have to write a new ReduceProcessor.
- The default implementation of CachingWindowStore has performance issue during load test with high QPS. (Will talk later)
- Default punctuation has defect: cannot do accurate scheduling with the given interval if some operation take too much time; and the punctuation interval is not evently if process time longer.
- There’s no Async Processing mode in KStreams, so the punctuation and process(eachRecord) are on the same StreamThread. Long time punctuation would cause long offset lag. And also cause frequently revoke, rejoin, reassign, restore-from-changelog. Then make the system down.
- Once the punctuation happen, it won’t care the same IO processing from other StreamThreads, then the system load will be high at this time.
- Long punctuation will block heartbeat, then will also case frequently partition revoke.
How to handle the problems?
------ Let’s create a wheel:
- Give up trying original reduce functions base on DSL, to create a new ReduceProcessor: ScheduledDiffAndUpdateForwardWindowReduceProcessor
It seems a long class name, but it can describe itself:
- Support Diff flow and Changelog flow at the same time.
- Support different Windows
- Flush is scheduled
- Each Processor only use one Store, the Store will save two values for each key, one for latest value, and one for last flushed value. All IO operations will be reduced as much as possible.
- Buffering in a time of dirtyFlushInterval, then send Diff values by batch (Diff DirtyFlush), QPS to downstream will be reduced.
- Create a new store: InMemoryWindowStore, which implements the same WindowStore interface. It can handle high TPS in a short time.
- Tune rocksdb and use large cache, and give up to use CachingWindowStore
- Let punctuationInterval=dirtyFlushInterval/10, punctuationInterval will check time gap with a smaller interval, this will make the real flush time be more accurate.
- Use TimeSlot way during initialization of punctuations in different Processors. Then different flush time will be separate with each other as much as possible.
- Limit max flush item number and time, and continue to do when next time, to let heart beat work in time.
Additionally
Original way of map((k, ) -> {…}).groupByKey.reduce will create InternalTopic to do repartition. There’s forceRepartition mark in source code, when groupByKey operation happened, will do a repartition forcedly in the internal, because of the possibly shuffle.
RepartitionTopic would make impact to Kafka Cluster, but we can control the QPS of it using batch. But if using LowLevel API, you cannot do this, because it needs explicit topic. The auto repartition feature is decided by KStreams internal implementation of builder. And the Builder is none-public class, so have to use tricky way:
/**
* force to sink and re-partition the stream to internal topic. <br/>
* The name prefix is your given name of upstream name. <br/>
* e.g. <br/>
*
* S0 -> S1 -> SINK_INTERNAL_TOPIC -> S1' <br/>
* <br/>
* S1' can be queued on kafka if downstream processing is slower than processing S0. <br/>
* That means you have to ensure the QPS to S1' is far less than S0, to keep kafka broker won't have more much load. <br/>
* <br/>
* Because of using {@link DummyKeyValueStore}, there's no storage overhand on the tricky transformation.
*
*
* @see DummyKeyValueStore
* @return
*/
public static <K, V> KStream<K, V> repartitionByInternal(KStream<K, V> outputStream, String upstreamName) {
return outputStream.groupByKey()
.reduce((old, newCome) -> newCome,
QStores.dummyStore(getDummyStoreName(upstreamName)))
.toStream();
}Though such reduce function is deprecated, we can use it, because it’s a client side method, not the server related. But I want it be changed to upstreaming to our in-house version in future.
Then let’s talk about the efficiency problem of Kafka Streams.
4. Store Efficiency
Two ways to consider: Space Efficiency and Time Efficiency, and extendibility.
For solving this, let’s look back the definitions of Time Window in Kafka Streams:
- Tumbling Window: The windows are adjacent to each other, but no overlaps.
- Hoping Window: There’re overlaps of the Windows.
- Session Window: the Window is decided by each key itself, and the start/end is decided by a App Level Logic
- Sliding Window: Only used for join internally. There’re overlaps of the Windows for different records. No align to the epoch.
All typical implementations of WindowStore are listed here:

All create operations have to use Stores class, and have to use StoreSupplier to define different store details:
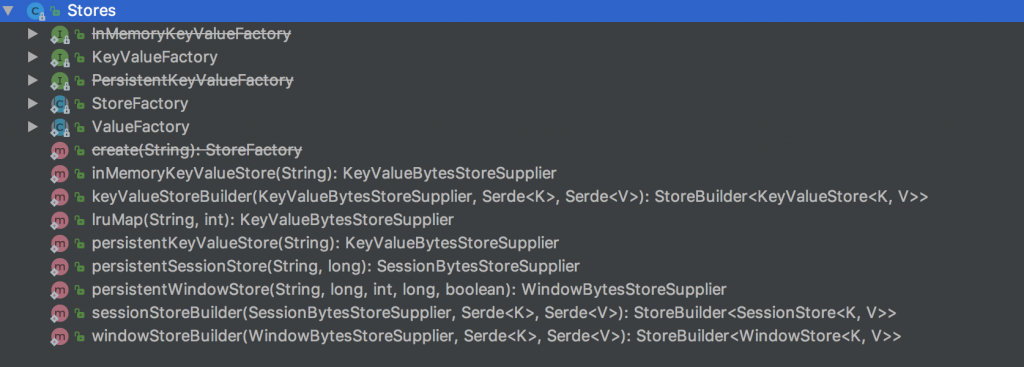
SimplePersistentWindowStore is a new implemented WindowStore. I’ve done some optimization towards Tumbling Window, it will be faster when using method fetch(key, from, to) than using any original classes.
I think for Quota Counter and Controlling, the Session Window would be the best one, but the implementation would be very complicated I think. And Hoping Window is less better, and Tumbling Window is the worst of accurate. But for engineering for a first implementation, the performance of Tumbling Window is best.
Space Efficiency
- Logic Efficiency:
- Save Keys as a bundle:
- To same Key(same User), to save all CounterKeys in the same data block, and give a timestamp.
- Add salt prefix to distribute different keys
- Use md5 digestion then take first 4 bytes. The prefix key space can be about 255^4, which is a large number to distribute keys.
- Keep a retention of all data
- Expire old Window data according the time window width
- Default will keep 3 latest window’s data to handle delay messages. If necessary, can adjust the number to only 1.
- Save Keys as a bundle:
- Physical Efficiency:
- Use platform independent format: protobuf
- Avoid to store String type. But to store int32, int64, enum data as much as possible.
- Use compression: if want CPU first, use LZ4; if balanced, use Snappy.
- Enable LZ4 compression on rocksdb.
RocksDBWindowStore will use RocksDBSegmentedBytesStore internally, and then use them to consist as Segments. But this one have poor performance on single key query, which makes each message process be slow in StreamTask.

The above picture shows the detail of Segments of KStreams local state store. It uses Iterator fo rocksdb, and no bloom filter for single key search in default rocksdb config, and no hash search as well (Rocksdb’s prefix hash search).
- SEE: https://github.com/facebook/rocksdb/wiki/Iterator
- SEE: https://github.com/facebook/rocksdb/wiki/Iterator-Implementation
- SEE: https://github.com/facebook/rocksdb/wiki/Prefix-Seek-API-Changes
Because using Tumbling Window, so no overlaps of the windows, then no necessary to get data across the windows. Each time window’s data only in one segment store, and only one key in the segment store. Then we can use rocksdb.get to speed up each message processing.
After investigating the source code, I find some core abstract implementation is none-public, so that’s hard to do customized extension on it. Then I decided to implement self StateStore of KStreams. I just implemented the existing interfaces, then developed SimplePersistentWindowStore and SimpleMemWindowStore. The same structure of window segments are the same as above picture.
5. Memory Store Efficiency
I use SimpleMemWindowStore for buffering changes.
And also can choose Redis, to void creating new storage implements. But it will increase the system complexity and maintenance cost. And will be still slow than local memory. Because it’s OK for losing some count data, so all in memory and without changelog is also acceptable.
JDK HashMap has poor Memory Efficiency
After investigation by VisualVM, I found that HashMap take too much heap memory, but store only a small set of data, because:
- K, V are all Object in HashMap, but not primitive types so take some overhead to store Object, even you just want to store int or long. Considering enabled pointer compression, one object head costs 12B, and costs 4B for reference type. Additionally HashMap won’t store KV directly, but HashMap.Node. I just want to store int32 and int64 as K, is it possible to store primitive type data?
- HashMap uses open link method to solve collision. Is it possible to use open address method to safe reference cost?
So I turn to use some different map implementations with compact structures.
And then I got an open source solution: Int2IntArrayMap:
This one is using Open Address Hash method. But will turn to O(N) lookup if many collision. Earn it to use CPU to exchange memory space in our case, and the load test shows that it works.
And I have another one, self-implemented one: CompatcInt2IntMap
I think the CountKey range is limited, not that large. I can use a internal mapping to map those CountKeys to 0~L range. Then I just keep an array to express such mapping relation of CountKey <--> int. This is very useful to store active users’ data. Because for each CountKey they have none-zero counter number. Then those CountKey->Count data can be save as bundle in a small space, and also can be compressed.
Through the measuring by org.openjdk.jol :
- Int2IntArrayMap saved 95% spaced than using JDK HashMap
- And CompatcInt2IntMap saved more 50% than using Int2IntArrayMap
So the heap memory usage reduce from 40GB to 2GB for each windowed memory store. For a normal counting for normal users, it only cost 4B to store int32 but not int64, then you just reduce half value size again.
For let the transform between different types of Maps, I designed some conversion flow as below picture showing.
- CountBundle, aggregate same user’s counts at one place. CountKey is a complex and agile structure. But will be transferred as String when you want to print it out.
- CompactCountBundle, will use Int2IntArrayMap and CompactInt2IntMap dynamically, and with int32 count number.
- PersistentCountBundle, will unbox the integer ID of CountKey to unique structured to store on disk or Kafka.
- PrintableCountBundle, will print with readable format. Easier to show when debugging or on monitoring web page.
Besides introducing proper data structure, also used some ways to make the young GC be easier:
- Avoid generate new those Maps again and again, just use primitive types
- Use ThreadLocal as much as possible
- Caching byte[], ByteBuff, DirectBuff as much as possible
- Use compress algorithm as much as possible
- Use BitSet for Boolean detection
- Use HyperLogLog to approximate count
- Use less Anonymous Class with outside object reference
- Avoid data copy, just use Iterators
6. Kafka Streams’ Defects
withCachingEnabled is slower?
We take a look of the Store Classes design on internal (Just listed part of important classes and interfaces.):

KStreams through Builder Pattern to create different Windowed Stores. And Decorated them with changelog layer or caching layer. And also use Compositor Pattern to make Segments of Windowed Stores, and do Iteration on them.
The store reference layer of the structures is as below picture:

The CachingWindowStore and ChangeLoggingWindowBytesStore are assembled by different configurations, then wrapping on top of RocksDBWindowBytesStore.
MeteredWindowStore is the most outside layer to user:
- Record different performance metrics if enabled. And also can provide data to JMX or Prometheus.
- The serialization and deserialization of KV. Under this layer, all components can only see Keys and Values as bytes.
CachingWindowStore:
- Buffering write and caching read, to speed up the operations.
- Batch output to under layer, to avoid the burst. The changes of the same key will be reduced to last one, then flush to next Process Node of the processing topology.(For details, SEE: https://kafka.apache.org/11/documentation/streams/developer-guide/memory-mgmt.html)
ChangeLoggingWindowBytesStore: Will pack KeyBytes, timestamp, seqNum to special structure, then send as Kafka Changlog format to Kafka cluster.
The store design is good , but not suitable for this project. We met problems when using CachingWindowStore:
- The memory configuration is the same for different time window size.
- The flush time configuration is the same, so cannot configurate it by different time window side too.
- The Range Iterator read will copy many data on caching layer, which makes processing be super slow.
- For #1: that’s another reason that why need to implement SimpleMemWindowStore.
- For #2: I want the flush can be controllable in different windows.
- For #3, has a problem when want to get data. Because original get API only support range scan by iterator by not point lookup if using Windowed Store.
Why? Let’s take a look at two pieces of the source code:


Then you can see that withCachingEnabled method will use NamedCache finally. And when each process a new message in WindowedReduce it has to read old data through this API:
fetch(final Bytes key, final long timeFrom, final long timeTo)For giving key, timeFrom and timeTo, then can make cacheKeyFrom and cacheKeyTo. Then fetch method will locate to the position then start iteration.
The key format in caching layer is:
SegmentId (windowId) + Key + Timestamp + Seq
Then your key length is not fix length, then will meet the problem of scanning lots of unrelated data rows. The the store have to filter the unrelated data one by one, which make the system slow. And I debugged related cases which shows the same problem. The problem is shown as below picture. If the key is string type, that mean it is hard to use withCachingEnabled.
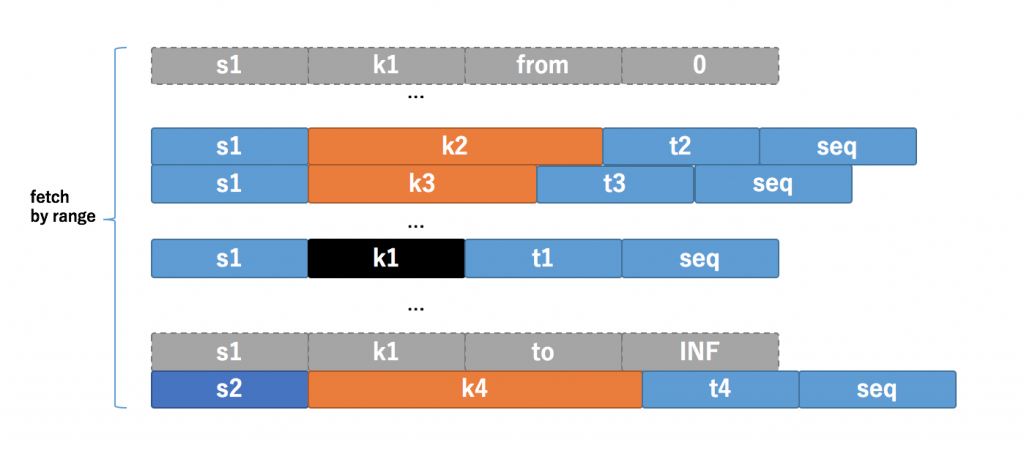
So the solution turn to be implement SimpleMemWindowStore again...
Poor performance of rocksdb with related version
During the load test, I find the Rocksdb:get operation cost lost of CPU, which is not a normal situation. Then I tried debug on it with gdb to native code of Rocksdb. I used gdb:
- get slow partition of kafka topic
- get thread name on the server according to the partition.
- get nid by jstack and grep by the thread name
- change int($nid, 16) to normal integer as tid
- use gdb.
- attach tid
- bt
- loop the steps above to find the cause
Then find the strange call stack of C++ side:
#1 0x00007f85f019b855 in _L_lock_16773 () from /lib64/libc.so.6
#2 0x00007f85f01988a3 in __GI___libc_malloc (bytes=140213238994784) at malloc.c:2897
#3 0x00007f85bd51eecd in operator new (sz=102736) at ../../../../libstdc++-v3/libsupc++/new_op.cc:51
#4 0x00007f85bdc1f4e0 in std::vector<char*, std::allocator<char*> >::reserve(unsigned long) () from /home/www/data/talk-storage-quota-monitor-etc/temp/librocksdbjni2738344878370664361.so
#5 0x00007f85bdc1f2d8 in rocksdb::Arena::AllocateNewBlock(unsigned long) () from /home/www/data/talk-storage-quota-monitor-etc/temp/librocksdbjni2738344878370664361.so
#6 0x00007f85bdc1f39f in rocksdb::Arena::AllocateFallback(unsigned long, bool) () from /home/www/data/talk-storage-quota-monitor-etc/temp/librocksdbjni2738344878370664361.so
#7 0x00007f85bdbf07a3 in rocksdb::BlockPrefixIndex::Create(rocksdb::SliceTransform const*, rocksdb::Slice const&, rocksdb::Slice const&, rocksdb::BlockPrefixIndex**) ()It means that in the method of BlockPrefixIndex::Create, it used method of std::vector::reserve, which has bad performance of copying data. Then I just turn to google and find a issue with it:
- https://github.com/facebook/rocksdb/pull/3508
- https://github.com/facebook/rocksdb/commit/0454f781c262f8134f6d976295a3290f02724197
And located the LOC in rocksdb: https://github.com/facebook/rocksdb/blob/v5.7.3/util/arena.cc#L200

This version of rocksdb is 5.7.3, which is depends by Kafka Streams 1.1.1 . Then I just used a newer version of rocksdb to replace it then the problem solved.
And the CPU load is still high, sometimes the get operation on rocksd would cost over 55% CPU resource.
The I start to profile it by using perf, here’s a picture of perf top result:
27.27% librocksdbjni7968754730768224896.so [.] rocksdb::BlockPrefixIndex::Create
4.11% [kernel] [k] try_to_wake_up
3.33% libc-2.17.so [.] _int_malloc
2.32% [kernel] [k] copy_user_enhanced_fast_string
2.19% librocksdbjni7968754730768224896.so [.] rocksdb::Arena::AllocateAligned
1.21% libjvm.so [.] InstanceKlass::oop_push_contents
1.14% libc-2.17.so [.] malloc
1.07% libc-2.17.so [.] __memcpy_ssse3_back
1.02% libc-2.17.so [.] __memmove_ssse3_back
0.98% libc-2.17.so [.] _int_free
0.92% librocksdbjni7968754730768224896.so [.] rocksdb::GetVarint32PtrFallback
0.88% librocksdbjni7968754730768224896.so [.] rocksdb::Hash
0.88% librocksdbjni7968754730768224896.so [.] 0x00000000004c549b
0.85% libjvm.so [.] PSPromotionManager::copy_to_survivor_space<false>
0.74% libc-2.17.so [.] __memset_sse2
0.69% [kernel] [k] __pv_queued_spin_lock_slowpath
0.60% librocksdbjni7968754730768224896.so [.] 0x00000000004c6586
0.58% libstdc++.so.6.0.19 [.] std::string::append
0.55% libjvm.so [.] CardTableExtension::scavenge_contents_parallel
0.55% librocksdbjni7968754730768224896.so [.] 0x00000000004c655b
0.54% librocksdbjni7968754730768224896.so [.] 0x00000000004c650d
0.53% libc-2.17.so [.] malloc_consolidate
0.43% [kernel] [k] system_call_after_swapgs
0.42% librocksdbjni7968754730768224896.so [.] 0x00000000004c6537
0.39% libjvm.so [.] PSPromotionManager::drain_stacks_depth
0.39% librocksdbjni7968754730768224896.so [.] 0x00000000004c6562
0.37% librocksdbjni7968754730768224896.so [.] 0x00000000005bfbe3
0.37% librocksdbjni7968754730768224896.so [.] rocksdb::MergingIterator::Next
0.36% [kernel] [k] __find_get_pageThen you will find the high CPU part with the previous picture: The problem is hide in rocksdb::BlockPrefixIndex::Create
The I check the internal usages by entering the assemble code of rocksdb::BlockPrefixIndex::Create
22.24 │ test %rcx,%rcx ▒
│ ↑ je 492808 <rocksdb::BlockPrefixIndex::Create(rocksdb::SliceTransform const*, rocksdb::Slice const&, rocksdb::Slice const&, rocksdb::BlockPrefixIndex**)+0x448> ▒
0.32 │ mov 0x10(%rbx),%edx ▒
0.35 │ sub 0x14(%rcx),%edx ◆
25.93 │ cmp $0x1,%edxAccording to related source code I located the problem:https://github.com/facebook/rocksdb/blob/6c40806e51a89386d2b066fddf73d3fd03a36f65/table/block_prefix_index.cc#L23-L25

And then to here :https://github.com/facebook/rocksdb/blob/6c40806e51a89386d2b066fddf73d3fd03a36f65/table/block_prefix_index.cc#L96-L114

It means that it’s too frequently accessing the method of BlockPrefixIndex::Create.
Because I used Prefix-Hash table type, the hash prefix index creation would cost many CPU, because of scanning all data to consistent prefix table. And once the missing rate of IndexBlockCache is high, each get operation will try to resolve a IndexBlock, then the IndexBlock will be created again and again. The default option is not enabled always caching IndexBlock!
Then I tired those to make it better:
- Make the configuration of prefix bits to make shorter Prefixes, then the total prefix hash item will be smaller. Which is fast for creating HashIndex in rocksdb.
- Pin IndexBlock in BlockCache by changing the default rocksdb configuration.
- User max_open_file=-1 configuration, which is mentioned in office site, it will cache index block as much as possible.
- Record the order list of key access in Java side, when during scanning on them when punctuation, do reverse iteration on them, which make the Cache Missing Rate better.
Bug of partition assignment -- unbalanced after each restart
This is the most serious problem of the bugs of Kafka Streams we met in the project.
Each time of restarting, would cause very unbalanced partition distribution, whatever restart the whole cluster or not!
And some machine can have tens of partitions, but some server have nothing.
The ideal status should be like: all partitions of all topics should be evenly distributed on all machines at any time.
Let’s look back the task architecture of KStreams:

SEE: https://docs.confluent.io/current/streams/architecture.html
The basic unit of task allocation is StreamTask in KStreams. Different StreamTask has different TaskId. One TaskIdhave unique matching with a TopicPartition.
TaskId := <topicGroupId, partition>
When you see the printed logs, the TaskId will looks like: 0_1, 0_2, 1_0, 1_1 ...
There’s a PartitionGrouper class in source code, in charge of mapping different Group, Topic, Partition to different TaskId.
The distribution is controlled by the consumers themselves, but not the Kafka Brokers. It designed by Kafka itself, implemented by ConsumerCoordinator running on all consumers. So different Kafka Consumer can have different distribution policy. In KStreams, it implemented by StreamPartitionAssigner and StickyTaskAssigner.
- StreamsPartitionAssigner response for allocating the StreamTask.
- StickyTaskAssignor response for how the tasks distributed to different servers.
Then we find a problem on StickyTaskAssignor:
- https://issues.apache.org/jira/browse/KAFKA-7144 (Kafka Streams doesn't properly balance partition assignment)
- And related PR: https://github.com/apache/kafka/pull/5390
- And related test cases: https://github.com/apache/kafka/pull/5390/files#diff-3cf77a4a8be4dc65221a87377c76ad33R171
Then we back port it to our in-house version. But still find the same problem.
Investigated more on it, then find more related issues already there, and not resolved yet till now:
- https://issues.apache.org/jira/browse/KAFKA-7203 (Improve Streams StickyTaskAssingor)
- https://issues.apache.org/jira/browse/KAFKA-4969 (State-store workload-aware StreamsPartitionAssignor)
This is a blocking issue, We can’t wait on it. Then fixed it by our own. Just make the task distribution evenly for all topics, no matter the CPU status or IO status. We have done a in-house patch, by following previous PR:
Many extra producing load to Kafka Cluster
After releasing the project, Kafka Team found that the whole QPS on it became very high than before, if cannot make it small, the cluster need expansion. Problems:
- The burst of flushing count number to next counters.
- Many active users contribute new data in each flushing, so in larger time window, the buffering won’t cover them. So will generate Kafka messages continuesly.
Possible ways:
- Batch the keys and values in each Kafka Message, each Key and Value is not that big size, so can make batch of them. But the problem is possible data lost if server down.
- Using Rate Limiter
- Reduce the unnecessary messages from business layer.
- Isolate the internal messages to another Kafka Cluster (But current version won’t support this)
We have done some test, and made the traffic be very smaller finally:
- For internal repartition topic, apply method #1 for and the batching set to 100, then the whole QPS became 1% of original.
- For changelog, apply method #3. It’s necessary to keep the compact feature on changelog, so cannot do batching on keys and value, then compact won’t happen. The logs on brokers will be very large, then make restoring very slow. Then we throw the data with small counter number, because they’re not the monitoring target at all, and we can throw 90% of the data.
- Don’t do #2 and #4 because they are very hard.
But if possible, separating the Kafka Cluster is the best choice in future!
7. Necessary Optimization on Rocksdb
How to config rocksdb on Kafka Streams
Let’s take a look at the original configurations of internal:

Some important configurations to be aware of the original configs:
- It using BlockBasedTable format
- This is the default sst file format
- BlockCache size is 50MB
- Too small as default
- Block size is 4KB
- We are using SSD, can use a larger block size, e.g. 32KB
- WriteBuffer(Memstore) is 16MB
- May cause larger write amplification, need to be larger as 64MB
- No compression as default
- No compression, will cost more disk size
- InfoLogLevel if ERROR_LEVEL
- Cannot get more useful logs in both beta and release env
- Disabled WAL
- Write fast, but will cause data lost here at storage layer. If want to be more strict on data quality, must change it
- Wait on Flush
- This is necessary, otherwise no back-press to application layer, then cause many write fail in the internal.
- No data TTL as default
- So more old data will be stored to take more disk size.
Kafka Streams Application can use RocksDBConfigSetter to do customized configurations.
/**
* An interface to that allows developers to customize the RocksDB settings
* for a given Store. Please read the <a href="https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide">RocksDB Tuning Guide</a>.
*/
public interface RocksDBConfigSetter {
/**
* Set the rocks db options for the provided storeName.
*
* @param storeName the name of the store being configured
* @param options the Rocks DB options
* @param configs the configuration supplied to {@link org.apache.kafka.streams.StreamsConfig}
*/
void setConfig(final String storeName, final Options options, final Map<String, Object> configs);
}Options is the interface to configure rocksdb. Configs is the configuration set of KStreams.
There’s an official guidance from Facebook:
You can find many optimization methods on the pages.
And in the application, just create a CustomRocksDBConfig class to implement that interface, then define it in your properties file:
rocksdb.config.setter=package.CustomRocksDBConfigBut please notice that:
- This is a global Class. All stores will use the same Class to create rocksdb instances. So no matter what the stores and window sizes will be like, the configurations are the same if won’t do special process.
- Once you want to optimize towards different stores by store names, you have to prepare a good NAMING CONVENTION. And have to know the internal store naming rules too. Then will make it easier to parse the store name.
- Have to use a static method to access your properties in Spring, ZK, or Central Dogma.
Four Types of Rocksdb Configurations
- TableFormatConfig: decide the table format when creating the database instance, and it will decide the base of the performance of the local state store. But it cannot be adjusted dynamically,
- Options: Dynamical Configurations, include the most runtime controllable configurations. Such as: PrefixExtractor, ratio of BloomFilter, compression, mmap read/write, DirectIO, WriteBuffer size, etc...; Those are changeable after DB creation.
- WriteOptions: decide the Options for each write
- ReadOptions: decide the Options for each Get or Iterator
KafkaStreams only allows to config TableFormatConfig and Options, the only two of the types. For some high performance cases (e.g have to use a better Iterator), ReadOptions became the performance killer and need to be tuned. But if you want to change ReadOptions, have to modify the source code of in-house version.
Write optimization on rocksdb
The writes in rocksdb
- Memstroe
- WAL (if enabled)
- flush Memstore (depends on memstore size and flush internal)
- Compaction in background write(depends on file size, time and policy)
The factors will affect write performance:
- Data size: is necessary to compress? Or make the store size smaller
- Disable WAL?
- Good size of Memstore(WriteBuffer): related to the total memory and disk type, typical value is in the range of 32~128MB.
- Async write?
Write Pause:
Rocksdb will adjust the write speed automatically, all stop write completely if meet those conditions:
- Too many memtables: this makes all write buffer full, all writes have to wait.
- Too many level-0 sst file: too many small files, if not let write wait, the read will be very very slow.
- Too many pending Compaction Bytes
SEE: https://github.com/facebook/rocksdb/wiki/Write-Stalls
For #1:
- Too small memtables (or too small MaxWriteBuffer), have to make it larger;
- Too slow flush: have to increase max_background_flushes
For #2:
- Reduce read amplification: increase write_buffer_size, but be aware long flush pause
- Speed up sst file compaction: increase max_background_compactions, and have to tune this value.
- Speed up sst file compaction: increase min_write_buffer_number_to_merge, to compact more files at one time.
For #3:
- Set higher compaction threshold, to delay the Compaction Operations
- Set higher speed threshold, to slow down the write speed degrade.
- Be aware to adjust max_background_compactions and min_write_buffer_number_to_merge, would make system slow.
Optimize read of rocksdb
Rocksdb will read from:
- Memstore
- BloomFilter
- Index
- BlockCache (if configured)
- sst file (including read from system Page Cache)
The factors will affect read performance:
- Total data size wrote: all sst files’ size are larger than the total cached or not? Is that BlockCache too small to cache all data? Is that KV size too large for each one?
- Distribution of data: are RowKeys distributed evenly? Are RowKey prefixes are not distributed well?
- Is Memstore hot enough?
- Is BloomFilter configured? Can BloomFilter fit in memory?
- Can all Indexes fit in the memory?
- BlockCache size is enough?
- Cached sst files in PageCache?
So the suggestions on read configuration:
1. Must have BlockCache :
- tableConfig.setBlockSize: 4KB~32KB
- tableConfig.setBlockCacheSize: to good fit with system memory and your data size
- tableConfig.setCacheNumShardBits: rocksdb are not shared across the StreamThreads, can set 0 to disable shards.
- tableConfig.setPinL0FilterAndIndexBlocksInCache(true): if use BlockCache instead of FileCache, must be true.
2. Must have BloomFilter, to optimize single point query:
- tableConfig.setFilter(new BloomFilter(10))
- tableConfig.setCacheIndexAndFilterBlocks(false)
- options.setMaxOpenFiles(-1)
Those two are conflicts, so configure any one is OK.
- setCacheIndexAndFilterBlocks and setMaxOpenFiles(-1)
If set BlockCache to cache Indexes and Filters, it will ignore File Cache. But the indexes are in BlockCache forever, and real data ratio is smaller, should notice this problem.
If you won’t cache Indexes and Filters in BlockCache, MaxOpenFile controls the whole file cache size. According to the official guide, there’s no limitation of file caches, the system will limit it automatically, this will make the best performance of caching Indexes and Filters.
3. Use HashIndex to optimize single query
This part is special. Rocksdb will use BinarySearch Index type db file format, which is not friendly to single point query. So it provides another type: HashSearch Index. It’s different DB format, based on hash of key prefix, and do binary search if meet the same prefix.(SEE Prefix Database: https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide#prefix-databases)
Related Configurations:
- tableConfig.setIndexType(IndexType.kHashSearch): must be configurated when creating database
- options.useCappedPrefixExtractor(4): unit is byte, 4 bytes supports 2^32 different prefixes, which is a very large number to make distribution well. But have to make a better Salt-Prefix for you keys.
- options.setMemtablePrefixBloomSizeRatio
Data Version Compatibility
According to the business growth, it’s very often that DB will be upgraded many times. The same problem to local state store in Kafka Streams:
- Have to support old data format or not?
- How to migrate data if want to support multi versions?
- If no necessary to support old format, how to clean old format data?
At first we just throw old data. The local state store path relates to Kafka Streasm application.id. So every time you change application.id the data path automatically changed, no old data will be read. But some problems of this way:
- All existing data will be lost, if has some long time window store. Thanks that the counter service can lose data. But if other business type, this is unacceptable.
- All changelogs will be lost, if some partition was re-balanced to other servers
- If application.id updated many times, will left many un-used topics, and relate logs on Kafka Cluster. If all Kafka Streams applications do like that, would cause heavy operation load to Kafka Cluster administrators.
So have to do data version compatibility on all Serds, at initial. And the method would be very simple: add a version header or version tail for each data to be stored.
We have a ONE BYTE version information in each stored data. Then it can support at most 255 different data formatat the same time. Because all data have its life time window, so 255 is super enough. When you done some version up online, the previous data won’t exist anymore.
Monitoring all rocksdb instances!
Statistics Monitoring
SEE: https://github.com/facebook/rocksdb/wiki/Statistics
Have to new some Statistics objects when CustomRocksDBConfig.setConfig, and have to invoke options.setStatistics method to register them to native instance of rocksdb. Then you can get Statistics information and export to Prometheus.
Here I listed some very useful keys:
- BLOCK_CACHE_MISS
- BLOCK_CACHE_HIT
- BLOCK_CACHE_INDEX_MISS
- BLOCK_CACHE_INDEX_HIT
- BLOCK_CACHE_DATA_MISS
- BLOCK_CACHE_DATA_HIT
- MEMTABLE_HIT
- MEMTABLE_MISS
- GET_HIT_L0
- NUMBER_KEYS_READ
- NUMBER_KEYS_WRITTEN
- BYTES_WRITTEN
- BYTES_READ
And you can know more about the metrics keys:
More detailed Internal Monitoring of rocksdb
Statistics only list some simple metrics. More status are hide in native implementations, and haven’t been public to Java side (The metrics’ keys). For examples: memory use ratio of memtables; total memory of sst files; the memory size of indexes; the usage of BlockCache, etc...
Java only provided an interface. But you have to find related keys in C++ code of rocksdb:
/**
* DB implementations can export properties about their state
* via this method. If "property" is a valid property understood by this
* DB implementation, fills "*value" with its current value and returns
* true. Otherwise returns false.
*
* <p>Valid property names include:
* <ul>
* <li>"rocksdb.num-files-at-level<N>" - return the number of files at
* level <N>, where <N> is an ASCII representation of a level
* number (e.g. "0").</li>
* <li>"rocksdb.stats" - returns a multi-line string that describes statistics
* about the internal operation of the DB.</li>
* <li>"rocksdb.sstables" - returns a multi-line string that describes all
* of the sstables that make up the db contents.</li>
*</ul>
*
* @param property to be fetched. See above for examples
* @return property value
*
* @throws RocksDBException thrown if error happens in underlying
* native library.
*/
public String getProperty(final String property) throws RocksDBException {
return getProperty0(nativeHandle_, property, property.length());
}Here I listed some useful keys:
- rocksdb.cur-size-all-mem-tables
- rocksdb.estimate-table-readers-mem
- rocksdb.estimate-live-data-size
- rocksdb.total-sst-files-size
- rocksdb.live-sst-files-size
- rocksdb.num-running-compactions
- rocksdb.num-running-flushes
- rocksdb.block-cache-capacity
- rocksdb.block-cache-usage
- rocksdb.block-cache-pinned-usage
And more definitions, please reference internal_stats.cc of rocksdb:
Unfortunately, those information cannot be retrieved through Kafka Streams’ original classes. Because Rocksdb class is none public too, you have to modify the source code.
But why those aren’t public ?
Because those metrics information handles have to be registered to native rocksdb manually, then have to release those related native resources as well. But the life cycle of rocksdb is managed by Kafka Streams, if the developer control the rocksdb themselves, also have to take responsibility to release those native handles. Otherwise, native memory will leak. So the designer do not want normal user to control such kind of things.
Please be aware the native memory usage!
Besides Heap Mem and Direct Mem, Kafka Streams Application may also cost many native memory on rocksdb. Your app may be killed because of OOM, so you have to monitor your native memory size and optimize on it. This is very useful for building strong Kafka Streams applications.
Facebook already wrote a detailed memory usage calculation method, please reference it for more details:
8. Summaries About Using Kafka Streams
- Make capacity plan before: how many partitions? How’s the QPS of each partition? How’s the processing Mem access, rocksdb access?
- Remember to change default path of local state store
- Plan well the partitions with each StreamThread, some partitions will run on the same thread, but some topics won’t.
- Control heap size and native size at the same time; Keep a good GC status.
- Watch the partition load balance problem, because it’s a unfixed bug (also in 2.0.0 version).
- Watch changelog restore process according the balance problem.
- If you won’t make you stream application be agile, or your team cannot handle force-repartition method, please use through method, to explicitly define you each internal topics well. This is good for your Kafka Cluster operations and capacity planning.
- Define different punctuation interval by different window size, but have to handle accurate time scheduling problem on you own.
- Separate different rocksdb configurations if big difference of different windowed stores.
- Watch produced message size and QPS to Kafka Cluster
- Notice the producer configurations: retries; ack; batch.size; linger.ms; max.in.flight.requests.per.connection, etc…
- Notice consumer configurations: session timeout, to avoid frequently revocation; better poll number for performance; considering auto.offset.reset
- To monitor them as much as possible: rocksdb, in-mem store, JVM-GC, JVM-Heap, KV-size, disk-size, serde-KV-size, punctuation time, punctuation duration, topic-consumer-group-offset-lag, AVG process time, QPS, internal-produce-QPS, changelog-restore-stats, etc…
This is just the start of adventure of using Kafka Streams, and just little experiences learned from the projects.
Hope it will be helpful if your are using it too. Thanks!
Tomorrow's topic is "PEG Parser Generator + Packrat Parserを実装してみた", from Masami Yonehara san. Please enjoy!